《动手学深度学习》笔记
简介
书籍附带的代码 是由MXNet 写的,后来又出了一个pytorch版本。
异步计算
广义来讲,MXNet 包括用户直接用来交互的前端和系统用来执行计算的后端。例如用户可以使用不同的前端编程语言来编写MXNet程序,如Python、R、Scala和C++。无论使用何种前端编程语言,MXNet 程序的执行主要都发生在C++实现的后端,后端有自己的线程在队列中不断收集任务并执行它们。
MXNet 通过前端线程和后端线程的交互实现异步计算,异步计算是指 前端线程无需等待当前指令 从后端线程返回结果就继续执行后面的指令。
a = nd.ones((1,2))
b = nd.ones((1,2))
c = a * b + 2
print(c)
在异步计算中,Python 线程执行前3条语句的时候,仅仅是把任务放进后端的队列里就返回了。当最后一条语句需要打印结果时,Python 前端线程会等待 C++ 后端线程把c 的结果计算完。因此无论Python 的性能如何,它对整个程序的性能影响很小。
可以使用同步函数 让前端等待计算结果
a = nd.ones((1,2))
b = nd.ones((1,2))
c = a * b
c.wait_to_read() // 等待某个 NDArray 的计算结果完成
d = c + 2
nd.waitall() // 等待所有计算结果完成
print(c)
异步减少了前后端通信,提高了性能,但反过来会占用较多内存。由于深度学习模型通常比较大,而内存资源通常有限,建议大家在训练时对每个小批量都使用同步函数。
单机多GPU数据并行
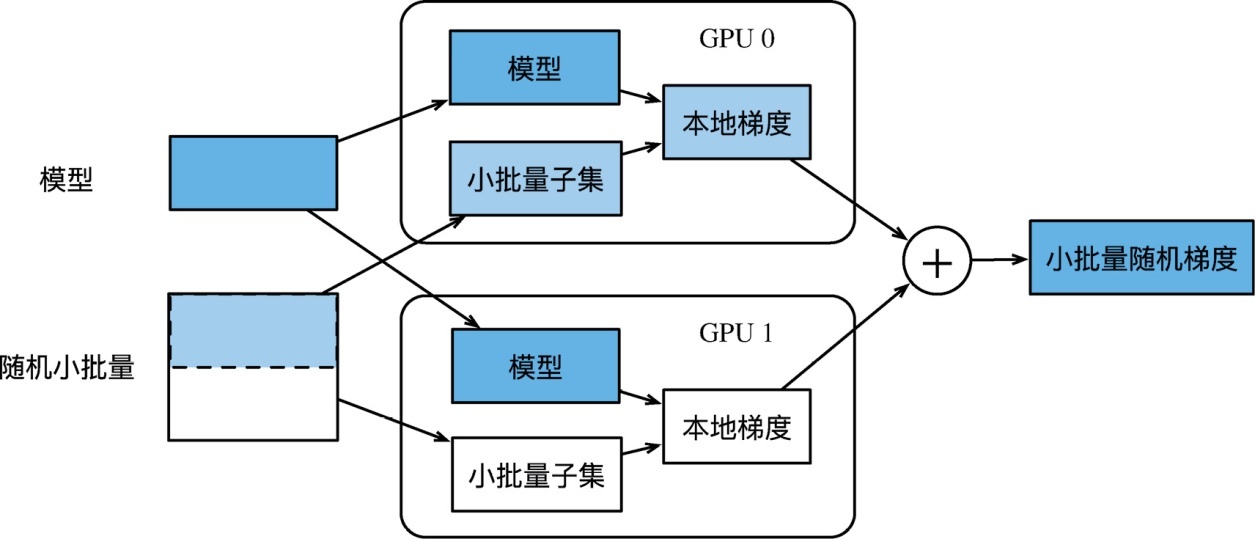
使用LeNet来作为本节的样例模型。这里的模型实现部分只用到了 NDArray
# 初始化模型参数
scale = 0.01
W1 = nd.random.normal(scale=scale, shape=(20, 1, 3, 3))
b1 = nd.zeros(shape=20)
W2 = nd.random.normal(scale=scale, shape=(50, 20, 5, 5))
b2 = nd.zeros(shape=50)
W3 = nd.random.normal(scale=scale, shape=(800, 128))
b3 = nd.zeros(shape=128)
W4 = nd.random.normal(scale=scale, shape=(128, 10))
b4 = nd.zeros(shape=10)
params = [W1, b1, W2, b2, W3, b3, W4, b4]
# 定义模型
def lenet(X, params):
h1_conv = nd.Convolution(data=X, weight=params[0], bias=params[1],
kernel=(3, 3), num_f ilter=20)
h1_activation = nd.relu(h1_conv)
h1 = nd.Pooling(data=h1_activation, pool_type='avg', kernel=(2, 2),
stride=(2, 2))
h2_conv = nd.Convolution(data=h1, weight=params[2], bias=params[3],
kernel=(5, 5), num_f ilter=50)
h2_activation = nd.relu(h2_conv)
h2 = nd.Pooling(data=h2_activation, pool_type='avg', kernel=(2, 2),
stride=(2, 2))
h2 = nd.f latten(h2)
h3_linear = nd.dot(h2, params[4]) + params[5]
h3 = nd.relu(h3_linear)
y_hat = nd.dot(h3, params[6]) + params[7]
return y_hat
# 交叉熵损失函数
loss = gloss.SoftmaxCrossEntropyLoss()
多GPU 之间同步数据
# 将模型参数复制到某块显卡的显存并初始化梯度
def get_params(params, device):
new_params = [p.copyto(device) for p in params]
for p in new_params:
p.attach_grad()
return new_params
# 测试:尝试把模型参数params复制到gpu(0)上
new_params = get_params(params, mx.gpu(0))
print('b1 weight:', new_params[1])
print('b1 grad:', new_params[1].grad)
输出
b1 weight:
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
<NDArray 20 @gpu(0)>
b1 grad:
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
<NDArray 20 @gpu(0)>
PS:原来数据 复制到gpu 之后,依然可以用 变量来访问。
def allreduce(data):
# 把各块显卡的显存上的数据加起来
for i in range(1, len(data)):
data[0][:] += data[i].copyto(data[0].device)
# 广播到所有的显存上
for i in range(1, len(data)):
data[0].copyto(data[i].device)
# 简单测试一下allreduce函数
data = [nd.ones((1, 2), ctx=mx.gpu(i)) * (i + 1) for i in range(2)]
print('before allreduce:', data)
allreduce(data)
print('after allreduce:', data)
PS:对于data 数据来说,data[0] 数据在gpu1 显存中,data[1] 数据在gpu2 显存中。
# 将 data 划分并复制到各块显卡的显存上。
def split_and_load(data, devices):
n, k = data.shape[0], len(devices)
m = n // k # 简单起见, 假设可以整除
assert m * k == n, '# examples is not divided by # devices.'
return [data[i * m: (i + 1) * m].as_in_context(devices[i]) for i in range(k)]
# 测试
batch = nd.arange(24).reshape((6, 4))
ctx = [mx.gpu(0), mx.gpu(1)]
splitted = split_and_load(batch, ctx)
print('input: ', batch)
print('load into', ctx)
print('output:', splitted)
单个小批量上的多GPU训练
def train_batch(X, y, gpu_params, devices, lr):
# 当devices包含多块GPU及相应的显存时, 将小批量数据样本划分并复制到各个显存上
gpu_Xs, gpu_ys = split_and_load(X, devices), split_and_load(y, devices)
with autograd.record(): # 在各块GPU上分别计算损失
ls = [loss(lenet(gpu_X, gpu_W), gpu_y)
for gpu_X, gpu_y, gpu_W in zip(gpu_Xs, gpu_ys, gpu_params)]
for l in ls: # 在各块GPU上分别反向传播
l.backward()
# 把各块显卡的显存上的梯度加起来, 然后广播到所有显存上
for i in range(len(gpu_params[0])):
allreduce([gpu_params[c][i].grad for c in range(len(devices))])
for param in gpu_params: # 在各块显卡的显存上分别更新模型参数
d2l.sgd(param, lr, X.shape[0]) # 这里使用了完整批量大小
对于 lenet(X, params) 函数来说,X 和 params 数据 在哪个GPU 上,lenet 中定义的运算便 在哪个GPU 上执行,执行完之后y_hat保存在 gpu 的显存中,loss(y_hat,gpu_y) 也是类似,在gpu 上计算损失值,成为ls 数据组的一部分。再分别在各个 gpu 上进行反向传播计算梯度。对梯度求和(就当是一个gpu 跑了 gpu_number 份batch 样本), 跨gpu 传播梯度,并梯度下降更新模型参数。也就是说,机器学习的所有过程(准备数据
;定义模型;确定损失函数;确定优化算法)都可以在gpu 上执行,只要数据在gpu 上,只是多了一个梯度的加和与广播过程。
定义训练函数
def train(num_gpus, batch_size, lr):
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
devices = [mx.gpu(i) for i in range(num_gpus)]
print('running on:', devices)
# 将模型参数复制到num_gpus块显卡的显存上
gpu_params = [get_params(params, c) for c in devices]
for epoch in range(4):
start = time.time()
for X, y in train_iter:
# 对单个小批量进行多GPU训练
train_batch(X, y, gpu_params, devices, lr)
nd.waitall()
train_time = time.time() - start
留下评论