从0到1构建一个db
简介
- 我们过去开发程序,不同的模块看到的环境是同构且确定的,即使近几年的分布式系统的兴起,但对于经典的分布式软件来说,大致还是单机软件设计思路的延伸,只是通过 RPC 将多台计算机连接在一起,但是仍然环境是相对确定的,尽管很多软件对于底层的环境变化做了一些适配:例如分布式数据库的动态扩容,数据重均衡 Re-balance 等,但是本质并未变化,只是能够操控和调度的资源变多了。但是在云上,这些假设都发生了变化:
- 多样且几乎无限的资源通过 Service API 的形式提供,对于资源的调度和分配可以通过代码完成,这是革命性的变革。
- 一切资源明码标价,所以程序优化的方向从过去的一维的榨取最好的性能(因为硬件的成本已经事先支付),变成一个动态的问题:尽量花小钱办大事。
- 假设的变化带来的技术上的变化:云上的数据库,首先应该是 多个自治的微服务组成的网络。放弃掉对于同步和单机的幻想
- 最近几年被聊烂的存算分离
- 对于数据库来说,一些内部组件的微服务化,比如:日志(CPU 使用少,但是对于存储要求高),LSM-Tree 存储引擎的 Compaction,数据压缩,元信息服务,连接池,CDC 等等,都是可以且很适合被剥离的对象。
How do you build a database
摘自How do you build a database? ,为防止链接失效,贴上原文。
Its a great question, and deserves a long answer. Most database servers are built in C, and store data using B-tree type constructs. In the old days there was a product called C-Isam (c library for an indexed sequential access method) which is a low level library to help C programmers write data in B-tree format. So you need to know about btrees and understand what these are. BTree 很重要
Most databases store data separate to indexes. Lets assume a record (or row) is 800 bytes long and you write 5 rows of data to a file. If the row contains columns such as first name, last name, address etc. and you want to search for a specific record by last name, you can open the file and sequentially search through each record but this is very slow. Instead you open an index file which just contains the lastname and the position of the record in the data file. Then when you have the position you open the data file, lseek to that position and read the data. Because index data is very small it is much quicker to search through index files. Also as the index files are stored in btrees in it very quick to effectively do a quicksearch (divide and conquer) to find the record you are looking for. 一个表单单数据文件是不够的,需要一/多个索引文件。
So you understand for one “table” you will have a data file with the data and one (or many) index files. The first index file could be for lastname, the next could be to search by SS number etc. When the user defines their query to get some data, they decide which index file to search through. If you can find any info on C-ISAM (there used to be an open source version (or cheap commercial) called D-ISAM) you will understand this concept quite well.
Once you have stored data and have index files, using an ISAM type approach allows you to GET a record based on a value, or PUT a new record. However modern database servers all support SQL, so you need an SQL parser that translates the SQL statement into a sequence of related GETs. SQL may join 2 tables so an optimizer(优化器最初是为了加快join表的速度么?) is also needed to decide which table to read first (normally based on number of rows in each table and indexes available) and how to relate it to the next table. SQL can INSERT data so you need to parse that into PUT statements but it can also combine multiple INSERTS into transactions so you need a transaction manager to control this, and you will need transaction logs to store wip/completed transactions.
It is possible you will need some backup/restore commands to backup your data files and index files and maybe also your transaction log files, and if you really want to go for it you could write some replication tools to read your transaction log and replicate the transactions to a backup database on a different server. Note if you want your client programs (for example an SQL UI like phpmyadmin) to reside on separate machine than your database server you will need to write a connection manager that sends the SQL requests over TCP/IP to your server, then authenticate it using some credentials, parse the request, run your GETS and send back the data to the client. So these database servers can be a lot of work, especially for one person. But you can create simple versions of these tools one at a time. Start with how to store data and indexes, and how to retrieve data using an ISAM type interface. There are books out there - look for older books on mysql and msql, look for anything on google re btrees and isam, look for open source C libraries that already do isam. Get a good understanding on file IO on a linux machine using C. Many commercial databases now dont even use the filesystem for their data files because of cacheing issues - they write directly to raw disk. You want to just write to files initially. I hope this helps a little bit.
概要内容:
- 知道BTree 很重要
- 一个表单单数据文件是不够的,需要一/多个索引文件,数据文件和索引文件分开存储
- 有了数据文件和索引文件,你就可以读写数据了,但你需要SQL parser 将sql 翻译成读写操作,需要optimizer加快join表的速度,需要Transaction manager 管理事务
- 备份儿/恢复数据文件、索引文件、Transaction log文件。如果支持客户端程序的话,还需要一个Connection manager
如何从零构建一个可存储/读取数据的”数据库”?
从零开始深入理解存储引擎 非常经典。
单机实现
我们先看如下这个最简单的”数据引擎”。
#!/bin/bash
db_set() {
echo "$1,$2" >> database
}
db_get() {
grep "^$1," database | sed -e "s/^$1,//" | tail -n 1
}
上面这个”数据引擎”写操作性能足够好,因为只需要数据文件追加写入一条记录即可;但它的读性能较差,因为需要全文件检索 (grep | sed),同一个key若有过多次写操作,在数据文件中会存在多行记录。
引入索引提高读性能。当前的第一个任务就是 提高读性能。我们可以引入单独维护的索引(内存中维护的Hash Map)提升查询性能;因此写入时除了写数据文件,还需要写索引,这会 降低写入的速度 ;这也是存储系统中很重要的权衡设计;到底关注读性能还是写性能,在技术选型的时候需要开发人员决定。添加了内存中的Hash Map来快速定位Key所在的位置,hash value是文件字节偏移量(byte offset);读取时直接从文件指定偏移位置读取到换行符即是Value值。此时可以提供高性能的读写,但需要所有的 Key 可以全部放在内存中供索引即可;写操作仍是一次追加写,读操作只需要一次磁盘寻址即可。引入了内存索引之后,很自然的一个问题就是机器重启,内存索引丢失怎么办? 可以重新遍历文件构建索引,后面再讨论其他更合理的方案。
如何避免磁盘耗尽?文件分段,分段压缩。假定数据文件写满1GB之后就可以关闭,创建新的数据文件供后续的写入,每个 segment 就是一个独立的文件;为实现区间查询和快速文件合并,对上面的日志段文件添加一个要求:Key有序。则该文件就可称之为 有序字符串表(SSTable - sorted string table);SSTable相比上述无序的哈希索引的日志段,有如下优点:
- 合并更高效:多个有序文件可以使用多路归并排序,简单高效; 文件合并过程中会去除相同的键;
- 内存中的hash map不需要保存所有键:得益于键有序,类似二分查找,找到最大的小于目标键的值之后顺序遍历即可; 现在有两个问题需要解决:
- 如何构造出来这个有序的数据文件,因为数据写入时乱序的,总要有个地方对数据进行排序
- 这个数据文件内部是如何存储和检索kv对的,也就是SSTable内部文件结构如何?
持续的数据写入排序不可能在文件中完成,因此我们使用内存来解决这个问题;基于内存的有序数据结构还是很多的,出于简单高效的原则,我们选择跳表作为有序数据的内存实现:数据写入时直接写入到内存中的跳表即可,当跳表数据量达到阈值时(如1GB)就可以持久化写入(dump)到磁盘文件中,因为跳表是有序的,因此生成的文件也就是有序的,符合 SSTable的要求;正在dump的跳表是不能够再接收写入的,但是系统还是要接收来自客户端的写请求,因此还需要一个能够接受写请求的跳表(一个活跃跳表接受写请求,一个不活跃跳表/dumping跳表)。
详解SSTable的文件格式。首先,需要思考一个问题:一对kv如何在文件中存储?比如name:zhengwei,如果在文件中直接拼接编码成namezhengwei, 我们不知道key是name,还是namezheng;若使用特殊字符区分,则kv对中也就不允许存在特殊字符;最合理的办法还是存储key和value的长度;读取指定长度的字节序列作为目标值。key_length,value_length,key,value,这样的一条记录,我们先称它为Entry。这里有一个小问题就是:key_length和value_length分别用几个字节来存储呢?1字节太少,只能存储256长度的字节序列,若有超长字符串就存不下;若字节太多,如4字节,又存在了很大的空间浪费;可以参照UTF-8变长字节编码的方式来实现,根据前几个比特位是否为0来表示使用几个字节表示字节长。

我们已经有了一条记录,那么这条记录如何组织进SSTable中呢?也为了利用磁盘的页缓存特性,我们将多条记录组织成块(Block)。在字典序上,Entry1 < Entry2 < ... < Entry n;虽然有序,但是每个Entry的长度是不相等的,所以就不能直接利用数组的下标索引直接进行二分查找;为了实现二分查找,我们在Entry后面附加和每条记录一一对应的的offset数组,数组的每个元素存储的是对应Entry的偏移地址;offset数组只记录对应Entry的偏移量,在offset中实现二分查找,需要查找对应key的时候,回溯到红色箭头所指向的Entry查找即可,类似于间接二分查找。
以上的Block存储的是数据,因此我们称它为DataBlock。将每个DataBlock经过压缩并生成CRC校验码,写入到文件之后我们就能得到每个DataBlock在文件中的偏移量offset和size。同时我们也知道该DataBlock中的 max key;因此,max key 、offset、 size就是该DataBlock的索引信息。随着向DataBlock添加数据达到DataBlock的阈值之后,就将DataBlock写入文件,等所有DataBlock持久化之后,Index Block也完成了构建,Index Block中的每一个Entry索引了一个DataBlock,Key就是DataBlock的最后一个Entry Key,Value就是DataBlock在数据文件中的起始位置和大小。IndexBlock本质上和DataBlock是一致的,无非存储的Value是DataBlock的索引信息,最后将Index Block也追加写入到数据文件中。
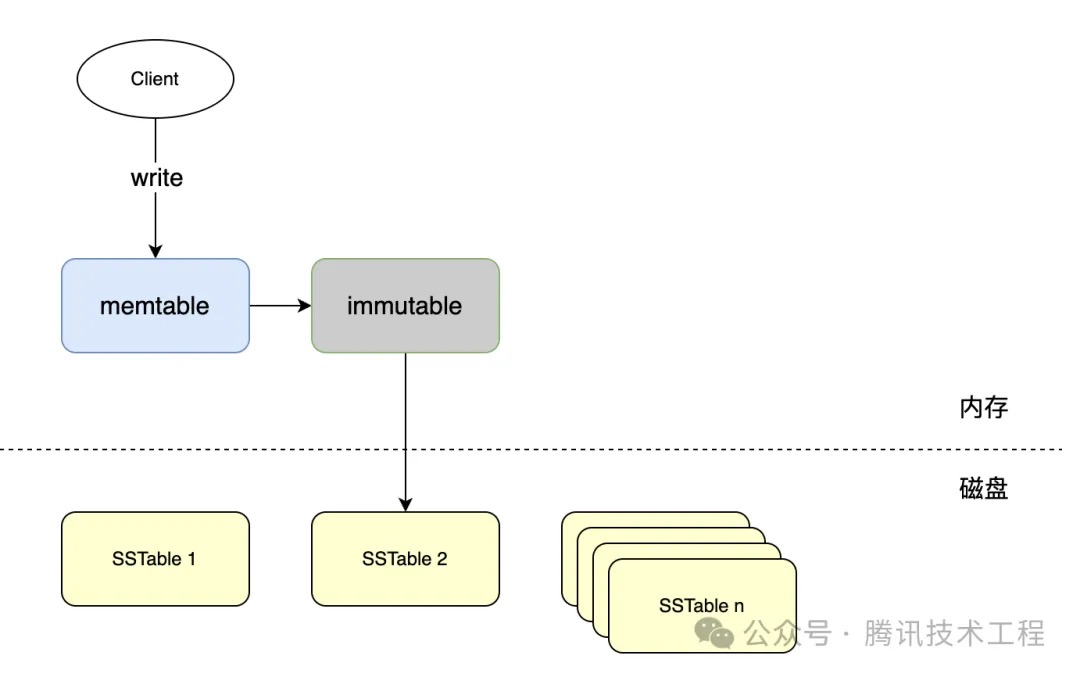
汇总一下我们目前的设计: 数据都落盘到了SSTable中,自然就会存在空间放大,而且虽然每个文件是有序的,但是并不能做到全部SSTable的整体有序,在读命令还是需要在所有文件中同时检索,读放大也很明显;每个immutable持久化到磁盘中的SSTable文件是有序且可能存在重复键的,如同一个key: name,可能在 SSTable1、SSTable2或其他SSTable中存在,如下图所示,每个SSTable都可以看作一段时间内写入值的有序集合。我们把从immutable直接生成的SSTable的集合称为Level 0。因此,Level 0中存在严重的磁盘空间放大问题,自然就会想到消除重复,而消除重复的方法就是合并(compaction)。
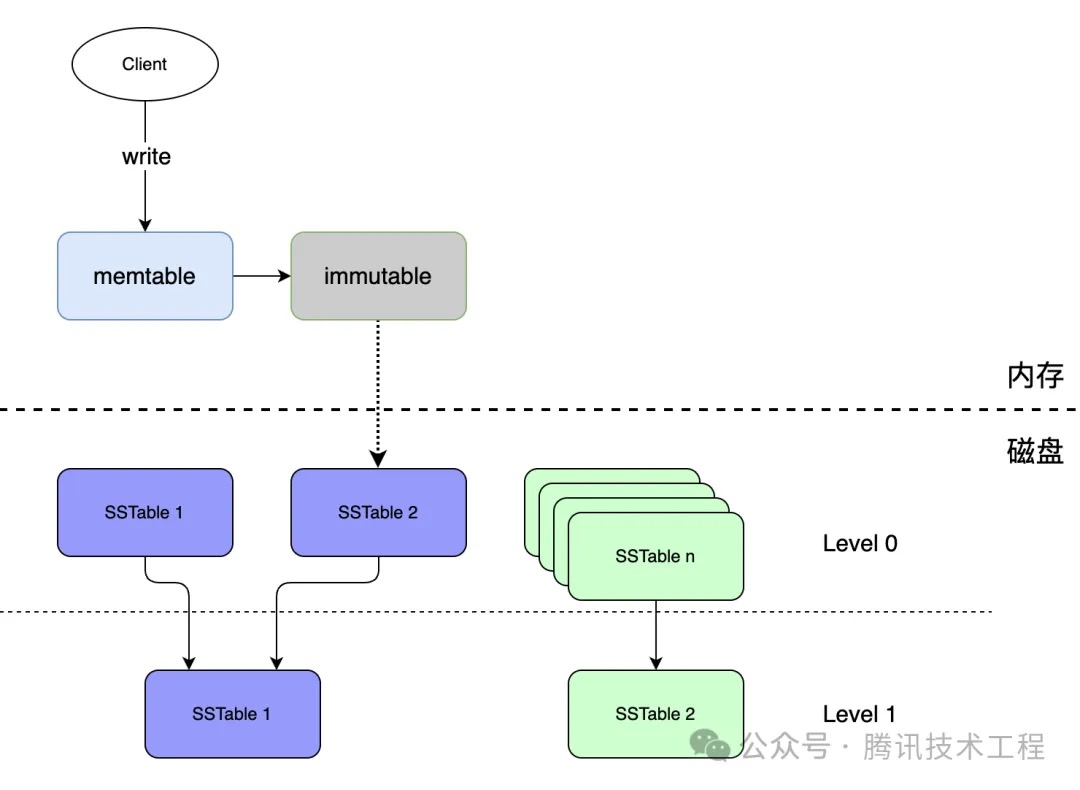 如上图所示,Level 0层的 SSTable 1 和 SSTable 2合并成Level 1层的SSTable1,Level 1层的SSTable 2同样由上层的SSTable和本层的SSTable合并而成。
如上图所示,Level 0层的 SSTable 1 和 SSTable 2合并成Level 1层的SSTable1,Level 1层的SSTable 2同样由上层的SSTable和本层的SSTable合并而成。
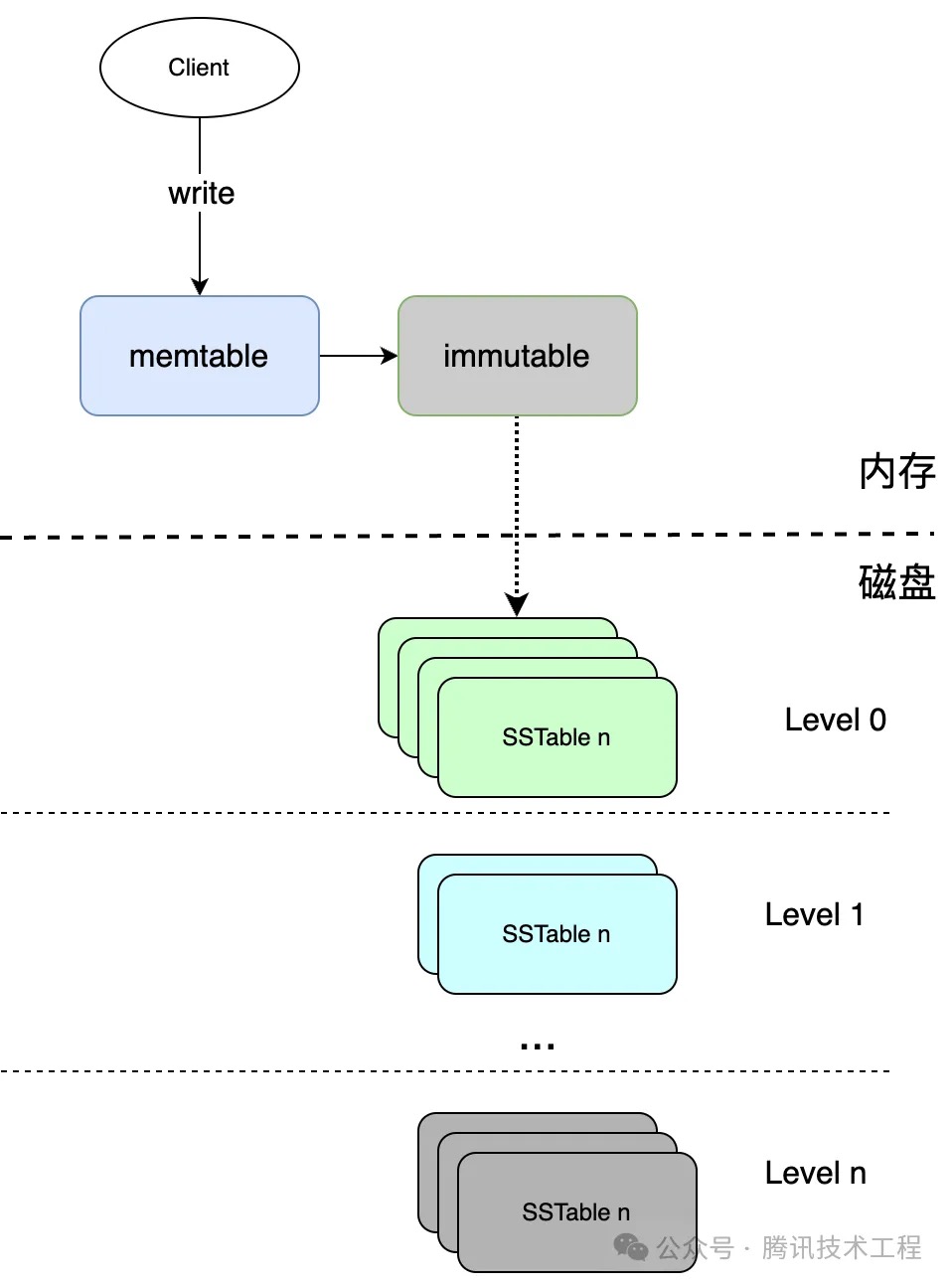
到这里
- 如何读取数据: 首先读取memtable,读到则直接返回;读不到则读取immutable,进而读取Level 0 -> Level 1 … 直到每一层的 SSTable都读完;若在其中的一步读到了数据,则不再往下读取,适时终止。
- 如何删除数据:需要删除的数据, Value中存入特殊值,若读取到特定值则返回不存在;在Compaction过程中也会跳过这些有特殊值的键(也称标记删除或“墓碑”)
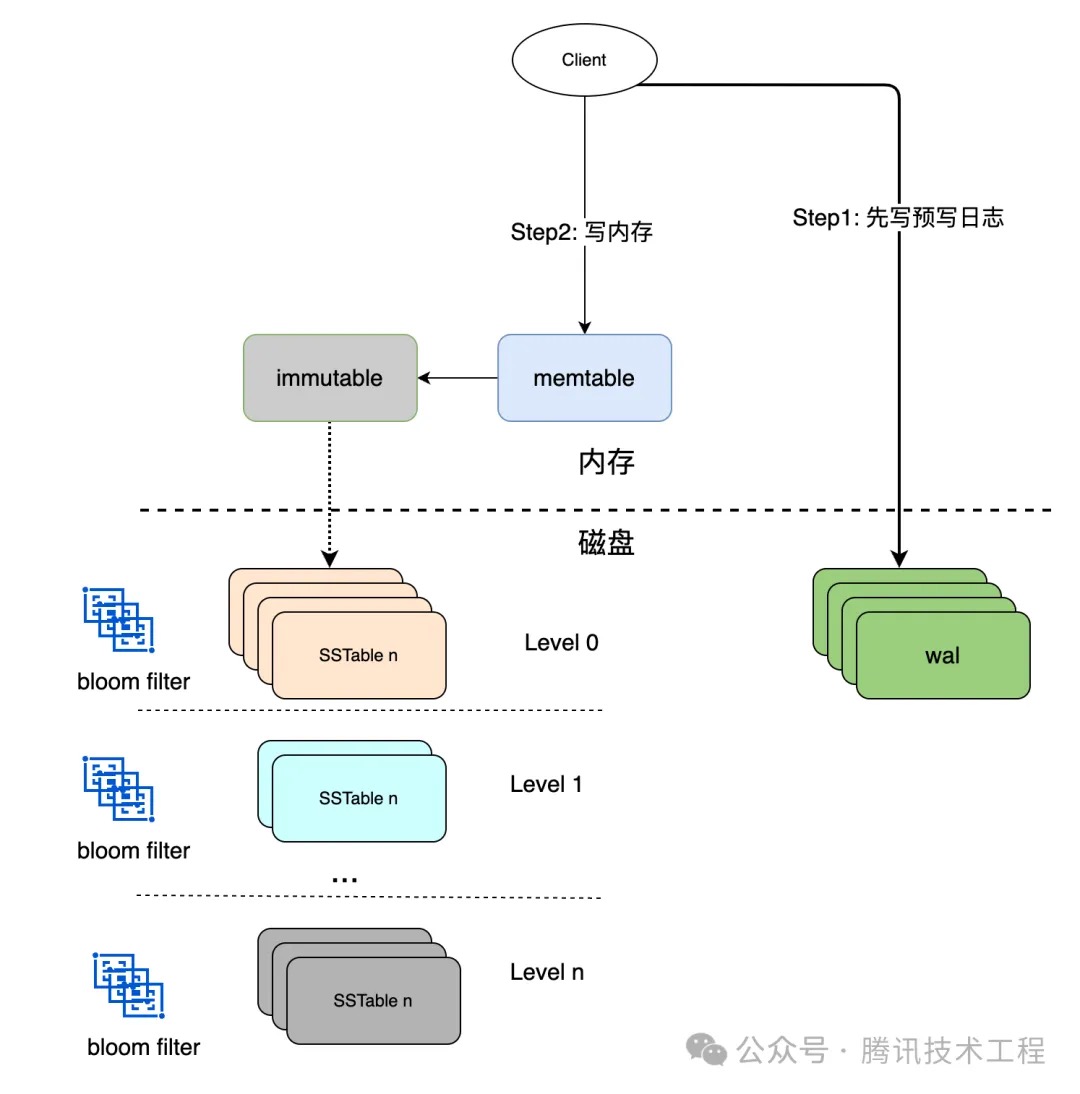
此时还有一个问题就是:数据初始是写入到:memtable中的,若还没来得及dump到文件中,发生了机器故障,重启之后内存丢失,memtable中写入的值也会丢失。要想保证不丢失数据必须要落盘,为了保证写入性能不受影响,以及磁盘顺序读写性能是最高的,我们可以引入预写日志(WAL-write ahead log)。数据首先顺序追加到预写日志中,待数据落盘落盘之后再写入到memtable中,待memtable中的数据持久化到磁盘时,该memtable对应的预写日志也就可以删除了。
讨论到此,我们已经有了一个单机存储数据的数据库,即使发生重启,数据也不会丢失。实际上这就是一个LSM Tree存储引擎。也是是LevelDB / RocksDB 所采用的方案;在 Cassandra/HBase 中也有该方案的身影;基于合并和压缩排序文件原理的存储引擎通常称为 LSM存储引擎;除了上面提到的基于LSM的存储引擎之外,还有基于B+树的存储引擎,它也几乎是关系数据库的标准实现,3-4层的B+树就可存储大量数据,不需要遍历太深(分支因子为500的4KB页的四级树可存储256TB)。我们来对比一下 B+ Tree 和 LSM-Tree
- B+树适合读多写少,LSM树适合写多读少;LSM树写入的时候只需要一次顺序写WAL日志文件及一次内存写操作即可,成本很小;但是读取却需要多层读取,只有所有的SSTable都不存在键才能返回不存在;B+树写入需要随机写磁盘,极端情况下面对页分裂还会有多次的随机写磁盘;而读取的时候从目标位置返回值即可;在有索引和页缓存的情况下,读性能表现更好;
- B+树至少写两次数据,一次WAL,一次页本身; LSM因为压缩及合并,也会存在写放大;B+树是原地更新数据,读放大较小,写放大较大。LSM树是非原地更新,同一条数据存在多条记录,会存在空间放大;数据读取需要检测多个文件,读放大比较严重,compaction/压缩缓解了读放大和空间放大,但是又引入了写放大;因此有很多技术用来优化写放大,比如 KV分离技术和延迟压缩技术,不再讨论。
- LSM树磁盘空间利用率更高,碎片更少;因为是顺序写,Block构建好之后顺序写磁盘即可。
- LSM压缩过程可能会影响正在进行的读写操作;后台压缩合并操作抢占业务进程对磁盘的读写操作;
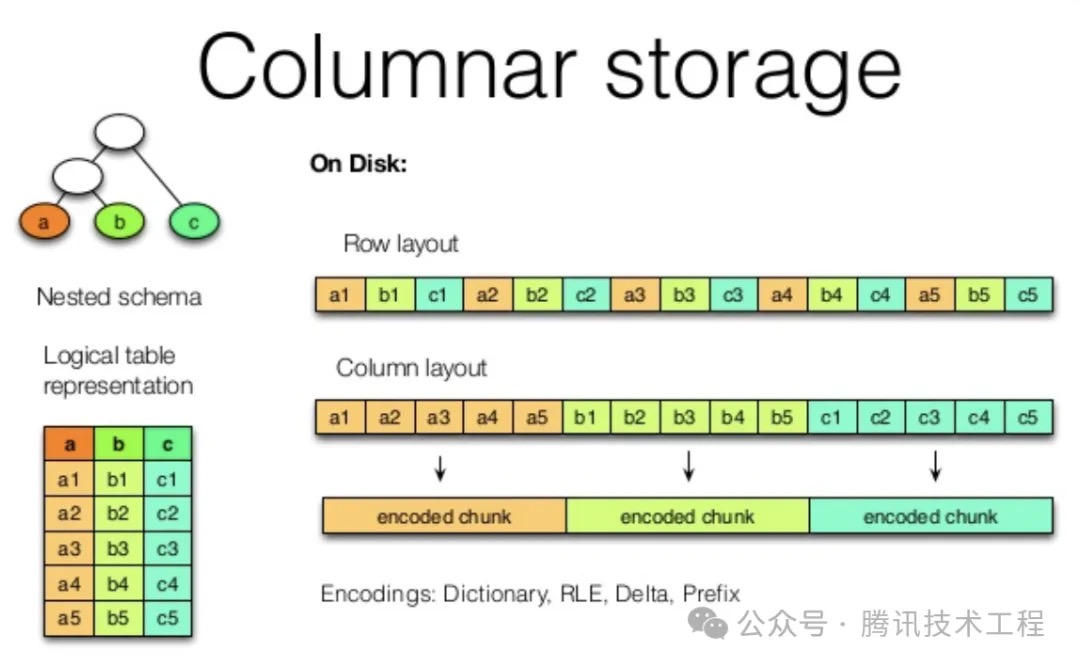
- B+树在事务方面表现更好,键只有一处,方便加锁; 我们详细的讨论了LSM 树,LSM 树,并简单对比了B+树,它们是OLAP(online analytic processing)和OLTP中日志结构流派和原地更新流派的代表;我们可以简单认为OLTP服务与在线业务,直接和C端用户交互;在线数据经过ETL之后存储到OLAP中一份用于商业分析或离线特征计算后再反哺到在线业务(比如TDW / 用户画像特征等)将不同业务系统的数据库经过提取之后转换为分析需要的数据结构,加载到OLAP等数据仓库中,供分析师使用;一般情况下供分析师使用的表通常很宽(有几百上千个字段/列,经过聚合多个数据源和业务数据得到),但是每次分析时可能只会使用其中很少的列(比如用户画像表,会有很多字段,但是一次sql可能只是涉及到很少的字段- select max(age) from table where gender = ‘male’);在OLTP数据库中,存储以面向行的方式来布局;为提高查询性能,面向列存储可优化分析场景下的查询性能;列存如下图所示:
留下评论