大模型训练
简介
思路
《AWS上的生成式人工智能》书中对于训练模型所需的内存有一个很好的经验法则。正如他们解释的那样,对于模型的每10亿个参数,我们需要6GB的内存(使用16位半精度)来加载和训练模型。请记住,内存大小只是训练故事的一部分。完成预训练所需的时间也是另一个重要部分。举个例子,最小的 Llama2 模型(Llama2 7B)具有70亿个参数,它花费了184320 GPU 小时才完成训练(阅读更多)。
直接决定训练时间的数据量的Token个数,Token的数量=Epoch数据条数平均数据长度*token转换比。
总训练速度=单设备计算速度 * 计算设备总量 * 多设备加速比,其中
- 单设备的计算速度主要由单块计算加速芯片的运算速度和数据IO能力决定,对单设备训练效率进行优化,主要的技术手段有混合精度训练、算子融合、梯度累加等
- 多设备加速比是由计算和通信效率决定的,需要结合算法和网络拓扑结构进行优化,分布式并行策略的主要目标就是提升分布式训练系统中的多设备加速比。 分布式训练系统需要克服计算墙、显存墙、通信墙等挑战
- 计算墙,H100单卡FP16算力只有2000 TFLOPS,而GPT-3则需要314 ZFLOPS,两者差了8个数量级
- 显存墙,GPT-3 1750亿参数,如果推理阶段采用FP32格式进行存储,则需要700GB显存空间,而H100只有80G
- 通信墙,GPT-3训练中,如果有128个模型副本,则每次迭代过程中至少需要传输89.6TB的梯度数据。而单个InfiniBand 链路仅能提供不超过800Gps的带宽。 计算墙和显存墙源于单设备计算和存储能力有限,与模型所需的庞大计算和存储需求有矛盾,分布式的解决方法又会面临通信墙的挑战,随着集群规模增加,长时间训练还会收到设备中断、故障的影响,对分布式系统的问题处理也提出了很高的要求。
大模型训练1:模型训练的时间都花在哪了?无论是计算还是通信,我们都可以粗略估计所需时间。并且:
- 理论下限(Lower bound):就是计算和通信中耗时更长的那个;
- 理论上限(Upper bound):是两者耗时之和。
大多数时候,我们可以通过“通信和计算并行”来让实际耗时更接近下限。因此,优化的目标通常是让通信时间和计算时间尽可能重叠。而即使最坏的情况,也只是差一个因子 2(也就是最长不会慢两倍)。另外,如果计算时间远大于通信时间,那就说明硬件一直在计算、没有等数据,说明我们主要受限于计算能力,处于计算瓶颈(compute-bound)状态;如果反过来是通信时间大于计算时间,那就是我们大部分时间都在“等数据”,说明被通信瓶颈(communication-bound)限制了,FLOPs 的潜力没有完全发挥出来,有浪费。 那么我们怎么判断一个操作是计算瓶颈还是通讯瓶颈呢?看一个关键指标:算术强度(Arithmetic Intensity),也叫 Operational Intensity。这个值表示:“每搬一个字节,能做多少次浮点运算”(和显存交互平均每个字节所需要运算的次数)。直觉上来理解,如果算术强度高:说明每搬一次数据能做很多计算,计算时间就占主导,是计算瓶颈;如果算术强度低,说明大部分时间都在搬数据,计算单元在空转,是通信瓶颈;以点积为例,计算两个向量x*y ,假设它们的长度都是 N,每个元素是 bfloat16:
- 要从内存读出 x 和 y,每个都是2N 字节,一共 4N 字节(注意:bf16 每个元素是 2 字节,所以这里乘以 2);
- 做 N 次乘法,N-1 次加法,共 2N-1 个 FLOPs;
- 最后再写回 2 字节。 当 N 趋近于无穷大时,整体的算术强度 (2N-1) FLOPs / (4N+2) bytes 近似为 0.5 FLOPs/byte。假设你有两个矩阵:X,大小 bf16[B, D],Y,大小 bf16[D, F],得到结果矩阵 Z bf16[B, F]。为了计算这个 matmul,你得从内存里读取 2DF + 2BD 字节的数据,执行 2BDF 个 FLOPs(每次乘法+加法);然后把 Z 写回内存,要写 2BF 字节。如果我们假设 B(batch size)远小于 D 和 F,也就是 token 数相对 embedding size 和头数小得多(这在 Transformer 中很常见),那么算术强度大约就是:$\frac{ 2BDF}{2DF + 2BD + 2BF} \approx B$,换句话说,这个强度跟 batch size 成正比。在 TPU v5e 上,如果你用的是 bfloat16 类型,那么只要你的 batch size 超过 240 个 token,你就可以做到 compute-bound。当然,这些都是单卡内的 memory-bandwidth 限制,也就是看显存带宽能不能喂饱计算。但这其实只是最简单的一类 roofline,现实中我们更常遇到的瓶颈是多卡之间的通信带宽,尤其是在多个 TPU/GPU 上做分布式矩阵乘法时。
GPU硬件的算力和显存带宽是固定的,因此硬件的算力-带宽比(roofline)也是固定的。因此,当模型的“算术强度”高于硬件的“roofline”时,那么硬件的算力成为瓶颈,反之则内存带宽成为瓶颈。
深度学习训练中的显存问题
- 首先要弄清楚的是,消耗显存的都有哪些?
- 模型的参数 $P_p$。
- 前向过程中,一些中间计算结果以及激活值(即激活函数的执行结果)。
- 后向过程中,每个参数的梯度值 $P_g$。
- 优化器的状态$P_{os}$(Optimizer state)。比如 adam 算法,需要为每个参数再保存一个一阶动量和二阶动量。
- 接下来,思考如何解决内存不足的问题。核心思路其实很简单,主要有两个方向:
- 先不把全部数据加载到 GPU 显存,暂时存放在别的地方,需要的时候再同步到 GPU 显存中,用完就扔掉。把参数放到 CPU 内存中或者高速SSD中(支持NVMe的ssd,走的PCI-E总线),这就是 deepspeed 中的 offload 技术;多张GPU卡,每张卡保存一部分,需要的时候再从其他卡同步过来,这就是参数分割。
- 降低内存的需求。原来每个参数都是 float32 类型,占用4个字节。改成半精度,用2个字节的 float16 替代4个字节 float32,显存需求一下就降低一半。用量化技术,用2个字节的 int16 或者1个字节的 int8 代替4字节的 float32 。
显然,每种方法都不是完美的,都有一定的局限性并且会引入新的问题,比如:
- 参数进行多卡分割或者 offload,比如会增加大量数据同步通信时间,不要小看这部分时间消耗,相对于 GPU 的显存访问速度而言, 多机器之间的网络通信、单机多卡之间通信、cpu内存到GPU内存的通信,这些都是巨大的延迟。
- 模型运行中,大量的浮点数乘法,产生很多很小的浮点数,降低参数精度,会造成数据溢出,导致出问题,即使不溢出,也损失了数据准确性。 模型训练时,梯度误差大,导致损失不收敛。模型推理时,误差变大,推理效果变差。
参数分割策略
说到分割参数,无论是多GPU之间分割参数(比如ZeRO),还是 offload 到CPU内存(比如ZeRO-Offload),都需要对参数进行分割分组。 这就涉及到多种划分策略。
- 流水线并行(Pipeline Parallel,PP)。按照模型的层(Layer)进行分割,保留每一层(Layer)为整体,不同层存储在不同的 GPU 中。多个层(GPU)串行在一起,需要串行执行,时间效率很差(流水线气泡/Pipeline Bubble),并且如果某一层的参数量就很大并超过了单卡的显存就尴尬。当然可以通过异步执行一定程度解决时间效率差的问题,有兴趣的读者可以研读相关资料。
- 在并行推理过程中,仅需传输层间的激活值,而层间的KV-Cache是独立的,无需传递。单个GPU仅需承载模型的一部分,剩余显存可用于存储KV-Cache,从而支持更大的batch_size,提升GPU计算效率。从通信量的角度来看,大致排序为:TP(每次迭代中频繁交换被分割的张量) > DP(batch结束后交换梯度?)> PP。
- 张量并行(TP)。如果模型“胖”到某一层本身就大到一张卡放不下呢?典型例子就是 Transformer 中的 MLP Block。把参数张量切开,将一个变量分散到多个设备上。切开张量分开存储很容易,但切开之后,张量计算的时候怎么办?这里可以分两种策略。
- 张量的计算过程也是可以切割,这样把一个大的张量,切分成多个小张量,每张 GPU 卡只保存一个小片段,每个小张量片段(GPU卡)独立进行相关计算,最后在需要的时候合并结果就行了。这种思路就称为 张量并行(Tensor Parallel,TP) , Megatron 就是走的这个路线。
- 同样是把参数张量分割,每张卡只保存一个片段。但是需要计算的时候,每张卡都从其他卡同步其它片段过来,恢复完整的参数张量,再继续数据计算。Deepspeed 选取的这个策略,这个策略实现起来更简单一些。 TP通信非常密集,几乎只适用于单机内部,利用 NVLink 这样的高速总线进行通信。如果用在跨机器的普通网络上,延迟会高到无法接受。 PS:ZeRO是一种显存优化的数据并行(data parallelism, DP)方案,它可以显著降低模型训练所需的内存。ZeRO通过在多个GPU之间分散模型参数、优化器状态和梯度,从而降低了单个GPU上的内存需求。此外,ZeRO还通过高效的通信算法最小化了跨GPU的数据传输。
流水线并行、张量并行,把模型一次完整的计算过程(前后向)分拆到多个 GPU 上进行, 所以这两者都被称为模型并行(Model Parallel,MP)。 而如果每张卡都能进行模型一次完整前后向计算,只是每张卡处理不同的训练数据批次(batch), 就称为数据并行(Data Parallel,DP)。 deepspeed 对参数进行了分割,每张卡存储一个片段,但在进行运算时, 每张卡都会恢复完整的参数张量,每张卡处理不同的数据批次, 因此 deepspeed 属于数据并行。
最后总结一下, 针对大模型的训练有三种并行策略,理解起来并不复杂:
- 数据并行:模型的计算过程没有分割,训练数据是分割并行处理的。
- 模型并行:模型的计算过程被分割。把一个模型拆为两半,那么这两半的模型都得用同一批数据去跑才行,模型并行是模型太大不得已的对模型进行肢解的一种并行。
- 流水线并行:模型按照层(Layer)切分。
- 张量并行:把参数张量切分,并且将矩阵乘法分解后多 GPU 并行计算。只有在线性层中会出现张量并行。
- 训练一方面是要我们把本身算子的性能做好,把一张卡本身的计算效率做高。第二个我们做计算跟通讯的overlap,尽量让计算不要停止,不要等待通讯。
- 训练本身是一个并行计算,每计算一个step后会同步权重,这时就牵扯到框架层面的事情了。我们常说5D并行的策略,本质上是让计算跟通讯变得更高效。这里面核心的一个原理,其实就是让计算和通讯是overlap的,也就是说在通讯传递这些权重的时候,计算不会等待,也就是TP、PP、DP、EP这些并行的策略在通讯的时候,GPU已经进入下一次计算了,把计算跟通讯拆开。
在真实的千卡、万卡大模型训练中,这三者往往被组合使用,形成所谓的 3D 并行:机器内用张量并行,机器间用流水线并行,而由若干个流水线组成的整个“超级节点”,再和其他“超级节点”一起做数据并行。
其它并行
- 训练本身是一个并行计算,每计算一个step后会同步权重,这时就牵扯到框架层面的事情了。我们常说5D并行的策略,本质上是让计算跟通讯变得更高效。这里面核心的一个原理,其实就是让计算和通讯是overlap的,也就是说在通讯传递这些权重的时候,计算不会等待,也就是TP、PP、DP、EP这些并行的策略在通讯的时候,GPU已经进入下一次计算了,把计算跟通讯拆开。
在真实的千卡、万卡大模型训练中,这三者往往被组合使用,形成所谓的 3D 并行:机器内用张量并行,机器间用流水线并行,而由若干个流水线组成的整个“超级节点”,再和其他“超级节点”一起做数据并行。
- 序列并行(Sequence Parallelism),TP主要处理的是attention和FFN维度的并行,主要是对参数矩阵进行切分,而输入还是有冗余(的每个TP在attention和MLP中都有相同的输入)。SP则是对输入矩阵按sequence维度进行切分,体现在layernom和dropout层(layernorm和droupout对序列长度是无感的,SP不会影响计算结果),收益是减少了激活值。由于attention和mlp都需要完整的序列,所以在进入attention和mlp需要做allgather,反向时需要做reduce-scatter(从计算图中能看出是reduce-scatter);从attention和mlp出来时做reduce-scatter,反向做allgather。SP一般是基于TP的,一旦开启了SP,TP的算法也要有所改变,主要是通信操作,如下图
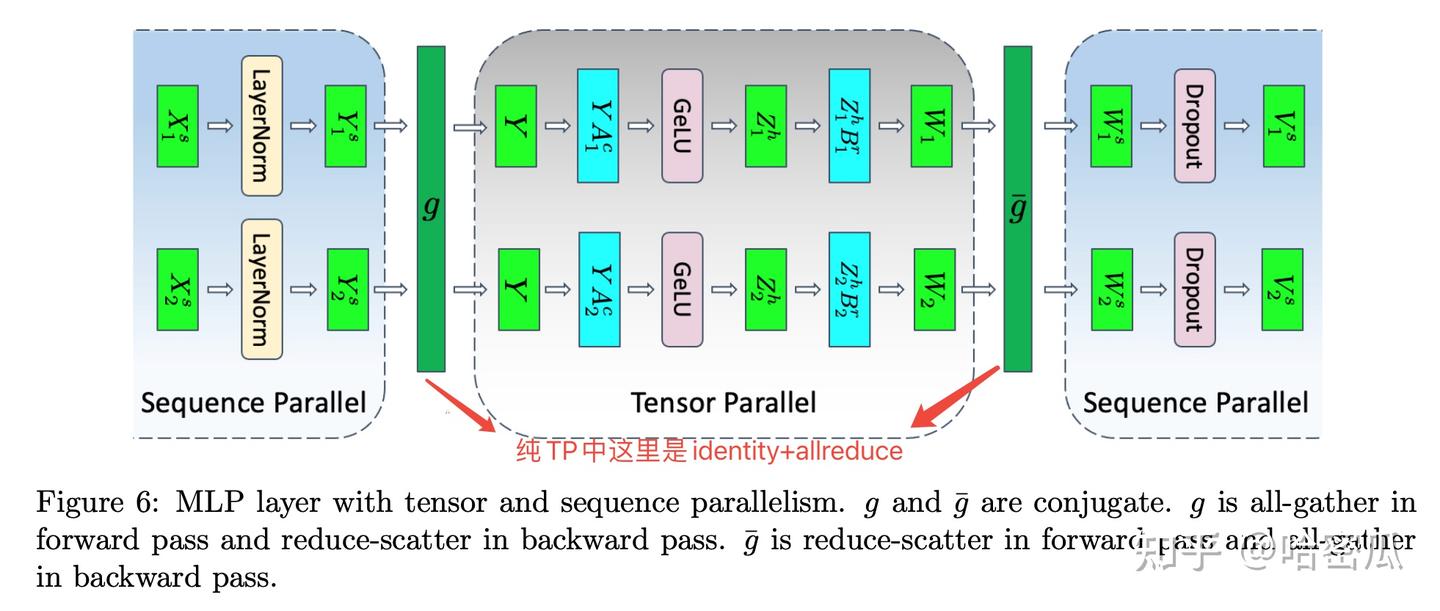 SP相比于TP不会带来更多的通信开销,这是因为TP的通信操作是allreduce,SP+TP的通信操作是reduscatter+allgather,两者开销相同。
SP相比于TP不会带来更多的通信开销,这是因为TP的通信操作是allreduce,SP+TP的通信操作是reduscatter+allgather,两者开销相同。 - 专家并行主要解决的是MoE模型的问题,由于每个token只会分发给topk个专家,导致每个专家(FFN)只处理一部分token,计算效率很低。当专家数量规模达到数千甚至上万时,单设备已无法容纳所有专家,且为了提升计算效率,会将专家分摊在不同的DP上。在之前的各种并行中,每个DP拥有完整的模型,在FWD和BWD时也是各自处理各自的数据,不会有任何通信(只会在梯度allreduce时涉及DP间通信)。而在EP中,专家被分摊到不同的DP里面,在前向和反向时DP之间便会有数据的通信。前向传播时,token 可能命中任意专家,我们必须把token发到目标GPU(all-to-all Dispatch),算完将专家的输出结果回传到原始设备并聚合结果(all-to-all Combine )。
 一般会通过all2all进行数据的分发,All-to-All 通信的核心优势在于全局协同的数据交换:每个设备可同时向所有其他设备发送数据,并从所有其他设备接收数据,且通信次数仅为 O (N)(N 为设备数)。这种特性完美匹配 MoE 中 “每个 token 可能被分配到任意专家或设备” 的稀疏激活场景。
一般会通过all2all进行数据的分发,All-to-All 通信的核心优势在于全局协同的数据交换:每个设备可同时向所有其他设备发送数据,并从所有其他设备接收数据,且通信次数仅为 O (N)(N 为设备数)。这种特性完美匹配 MoE 中 “每个 token 可能被分配到任意专家或设备” 的稀疏激活场景。
其它手段
降低精度:降低参数精度也有讲究,有些地方可以降低,有些地方就不能降低,所以一般是混合精度。 半精度还有另一个好处,就是 计算效率更高,两个字节的计算速度自然是高于4个字节的。 在模型训练过程中,参数的梯度是非常重要的,参数更新累积梯度变化时,如果精度损失太多会导致模型不收敛。 所以优化器的状态一般需要保留 float32 类型。实际上,GPU 显存不足的问题更多的是靠上面的参数分割来解决,半精度的应用更多的是为了提高计算速度。
模型并行细节
405B大模型如何炼成?-手撕张量并行 建议细读,尤其是想看代码的话。
- Row-Wise和Col-wise切分的前向和反向梯度推导
- 最小化TP代码实现
- 基于torch.distributed实现TP版本的线性层
- Llama-3 TP层分析
不同的TP策略:
- Row-Wise First:在遇到GeLU前需要gather所有卡上的激活者,增加通信消耗
- Col-Wise Firse:可以独立计算GeLU,不需要再Gather,而后再用Row-Wise的TP 由于TP不改变计算量,切分的原则是尽可能减少gather操作,减少通信消耗
分布式矩阵乘法
Transformer的模型并行主要作用于attention、MLP、embedding和最后的softmax这些层,又以attention和MLP最为重要。无论是attention还是MLP的模型并行,都涉及到分布式矩阵乘法,分布式矩阵乘法 Y = XA,分为行切和列切,这里的行切和列切指的是右侧A矩阵使用的是行切还是列切。
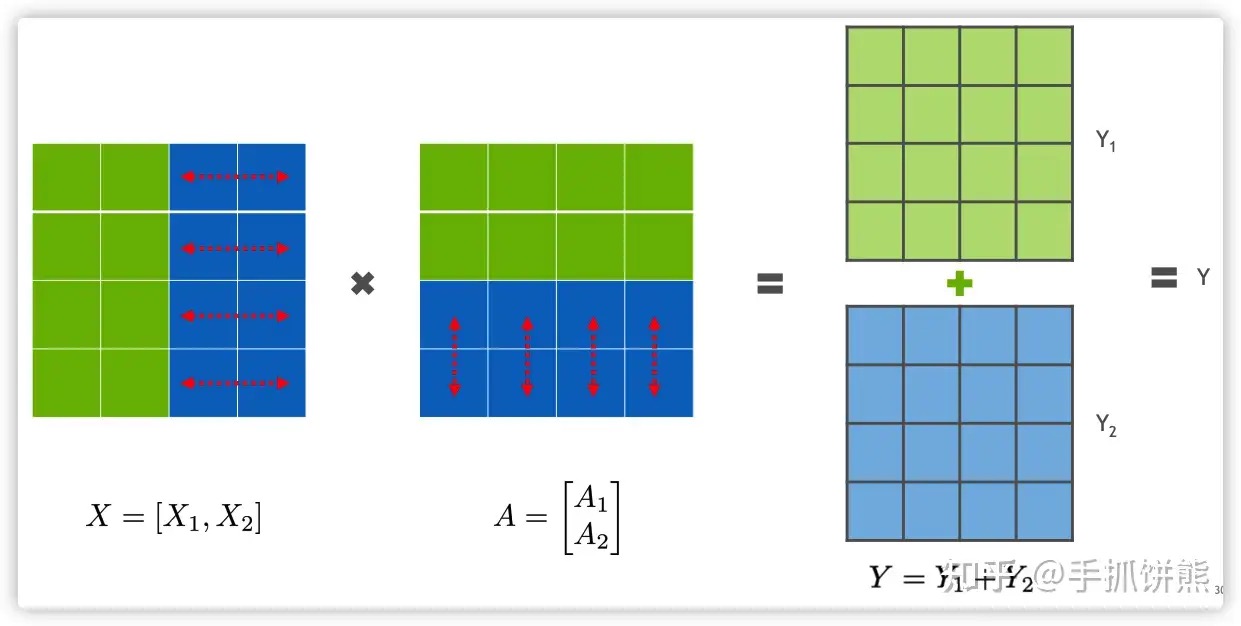
如上图展示了行切的例子,如果A使用了行切,那么X矩阵必须是列切的矩阵,由上图可以看出,绿色的矩阵在卡0,蓝色的矩阵在卡1,执行矩阵乘法之后,2张卡的数据均是全量(最终输出矩阵shape对的)不完整的数据,需要进行AllReduce才能得到完整正确的数据。
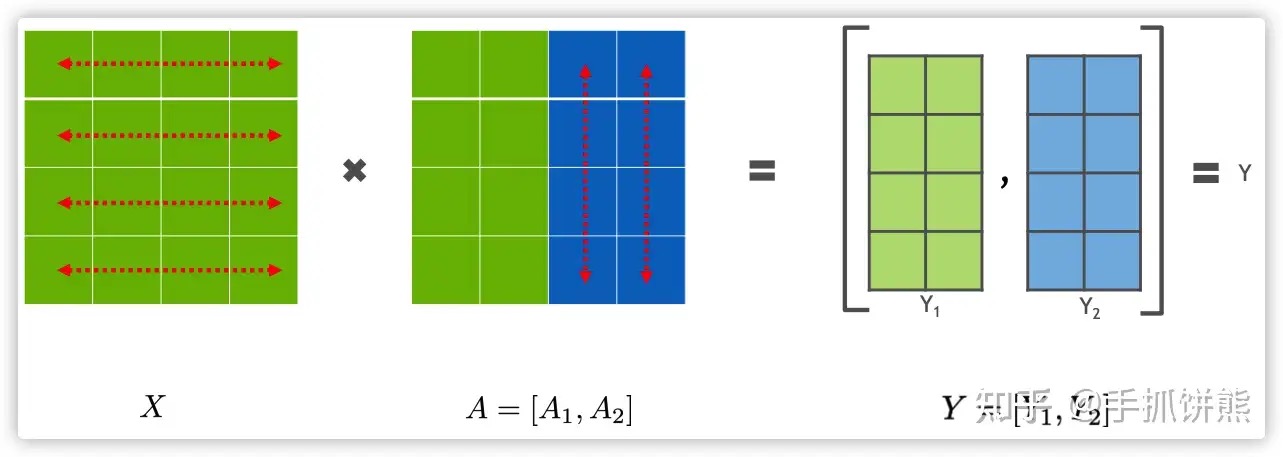
如上图展示了列切的例子,如果A使用了列切,那么X矩阵必须是全量未经过切分的矩阵,由上图可以看出,绿色的矩阵在卡0,蓝色的矩阵在卡1,执行矩阵乘法之后,2张卡的数据均是部分(最终输出矩阵shape是按照列切的)完整的数据,需要进行AllGather才能得到完整正确的数据。
要理解通信优化的精髓,没有比并行矩阵乘法更好的例子了。几乎所有大模型的计算瓶颈最终都归结为矩阵乘法(GEMM)。不同的并行矩阵乘法算法,其核心差异就在于它们如何组织计算与通信。假设 n=16384(一个中等规模的矩阵),显卡/核心数 p=256。
- 2D 算法 (SUMMA/Cannon)
- 通信次数: sqrt(256) = 16 次
- 通信量/核心 (量级):
16384² / sqrt(256) ≈ 16.7M
- 3D 算法:用空间换时间。(假设 p=216=6x6x6)
- 通信次数:
log(216) ≈ 8 次 (二进制log) - 通信量/核心 (量级):
16384² / 216^(2/3) ≈ 7.4M - 内存/核心 (量级):
16384² / 216^(2/3) ≈ 7.4M (比2D的 1.2M 大很多)
- 通信次数:
- 2.5D 算法:在空间和时间之间寻找最佳平衡。 (假设p=256, c=4)
- 通信次数:
sqrt(256/4) + log(4) = 8 + 2 = 10 次 - 通信量/核心 (量级):
16384² / sqrt(256*4) ≈ 8.4M这正是 Megatron-LM 和 Colossal-AI 等框架在张量并行中采用更复杂矩阵乘法算法的根本原因。
- 通信次数:
Transformer模型并行
由于层叠的Transformer Layer中,主要是Self-Attention和MLP,所以主要可分为MHA并行和MLP并行。
MLP的模型并行。我们知道MLP是由2个矩阵乘法组成的(wb 和 dropout,矩阵乘法结束后还有一些激活函数如GeLU等,如下图所示,不影响整体分析),MLP的输入是一个完整的X,输出也是一个完整的Z,这样并很容易利用上述分布式矩阵乘的结论设计MLP的模型并行。
如上图所示,输入X为全量数据,此时第一个矩阵乘法的A矩阵按照列切,XA之后的结果数据是[XA1, XA2]是一个列切的(XA1在卡0、XA2在卡1),此时不必进行AllGather,因为还需要和B进行矩阵乘法。由于左边的XA是按照列切的,故右边的B应该是按照行切的,XA和B进行分布式矩阵乘法之后,最终的结果进行AllReduce即可使2张卡均得到完整的结果。
Attention的模型并行。
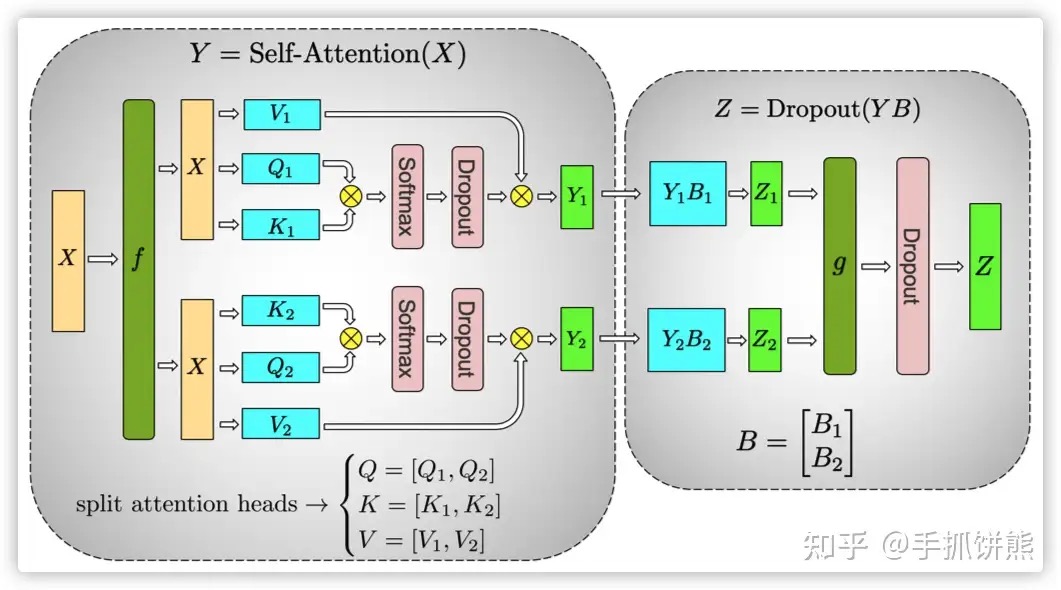
attention逻辑如下几个步骤:
- 首先attention是多个head的,如上图左部分,即有2个head的attention,最终不同的head算出的结果如果需要进行合并,在最后一维列方向合并,
- 如果attention需要进行多卡拆分,那么天然的可以按照head切分,如上图所示,Q1、K1、V1、和最终结果Y1在卡0,Q2、K2、V2、和最终结果Y2在卡1,Y1和Y2是按照列切分的矩阵;KV-Cache缓存也被均分;
- attention之后需要再乘矩阵o(图中是B),由于Y1和Y2是按照列切分的,B就是按照行切分的,YB之后的结果,进行AllReduce;
![]()
此时再来全局看一下引入模型并行之后transofmer的结构,如上图所示。
- MLP首先会有一个列切的层、然后再有一个行切的层,之后会有一个Allreduce同步结果;
- attention每张卡有不同的head,attention之后会有一个行切的层,之后会有一个Allreduce同步结果;
- 右图红色的部分是“驱动模型执行的调度器”,模型并行需要给不同的卡喂进去相同的数据,在训练的时候,其实就是trainner不断的读取相同的数据,将数据送到模型,执行模型的forward方法,这里模型并行维度为2,即有2个调度器驱动模型执行,调度器和worker在一个进程;
千卡训练难在哪?
360智算中心:万卡GPU集群落地实践 建议细读。
DeepSeek-V3 高效训练关键技术分析 DeepSeek-V3 之所以能够利用5%的算力训练出对标 GPT-4o 的先进模型,与其创新性的模型架构设计、高效的并行策略选择以及对集群通信和显存的极致优化密不可分。PS:双流并行计算优化这块可以细看下。
大模型千卡训练-经验指北千卡训练解决的问题是大模型&大数据问题。如果你的训练时间没有超过8192GPU日,那么你绝对不需要一千张显卡。千卡训练和八卡训练的区别是—显卡多了一百多倍。这意味着什么呢?
- 通信时间增加。时间上,PyTorch内部支持NCCL/Gloo/MPI三个通信后端(请务必使用NCCL。其中AllReduce操作会会根据具体硬件配置走Ring AllReduce和Tree AllReduce。Ring的时间复杂度是O(p n),Tree的时间复杂度是O(\log p n)。就算是理论上128节点也比单节点慢至少七倍,实践当中跨节点通讯要远比单节点慢得多。
- 故障概率增加。故障上,一个节点出问题的概率是p,128个节点就是1-(1-p)^128。也就是说如果一个操作在一个训练当中的出错概率是1%,那么在128节点当中的出错概率就是72.37%。
如何提高计算效率?这件事情其实是一个case by case的事情。因为通信、计算速度啥的受硬件影响更多。而每一个集群的硬件拓扑都是不一样的。同样是A100集群,我全DGX节点,每一张A100都是SXM接口并配一块儿专属的IB网卡。你一个小破普惠服务器插8张PCI-E A100,IB卡一个节点只给一张。那咱俩遇到的问题就完全不是一个问题。因此,要讨论如何提高训练效率、减少训练耗时,我们首先要了解训练耗时在哪里。那么,一个训练步的耗时在哪里呢?需要谨记,没有profile的优化是没有意义的。你可能会说,forward backward sync。很好,这说明你了解PyTorch的基本流程。不过现实当中要复杂得多。
- dataset读取数据,构建输出
- dataloader collate数据,进行数据预处理
- 模型forward计算输出
- loss compute
- 模型backward计算梯度
- 模型sync梯度。通信往往需要耗费大量时间。
- 优化器step更新权重
- 打印log
实际上当你的训练超过2048个GPU日时,在整个训练过程当中发生单个GPU甚至单个节点下线是再正常不过的事情了。PyTorch在1.10就引入了torchelastic弹性训练机制,用过的都骂娘。我印象当中在微软的最后一轮面试当中被问到了这个问题:如何设计一个弹性分布式系统。我的回答很教科书。每k分钟,系统会做一次AllReduce来统计存活进程数,然后选举出一个主进程。主进程会计算好每个进程的rank和local rank进行broadcast。所有进程每次forward开始时向主进程发送一个心跳包来汇报状态。主进程会根据心跳包来确定这一个step参与同步的机器有多少。但很可惜,2024年了。还是没人去写。
我一直认为梯度同步不应该以GPU/进程为单位。而应该分为大同步(节点间同步)和小同步(节点内同步)。小同步可以更高频的进行,大同步则可以更慢的执行。这样不仅能提高实际的梯度同步频率,降低同步总耗时,并且还能天然的去结合小batch和大batch训练的优点—节点内小batch关注个体,节点间大batch关注整体。PS: 果然还是大佬的思路牛逼。
训练框架
经过十年的洗牌(Theano、Torch、Caffe、Chainer、MXNet、TensorFlow等框架被淘汰后),当前框架已趋于稳定(也就是PyTorch)。围绕PyTorch,存在专门用于模型并行(将模型分片到多个硬件加速器上)的框架。这些框架可分为两个维度:
- 用途:专为训练设计(如PyTorch FSDP、DeepSpeed)、专为推理设计(如vLLM、SGLang、TensorRT-LLM),或两者兼顾;
- 通用性:通用型(适用于任意模型)或专为Transformer设计。由于Transformer的重要性与复杂性,它们值得拥有专用框架。
理论上来说,完全仅借助PyTorch来训练一个模型完全是可行的。然而,实际应用中可能会遇到代码复杂、计算效率低、过大模型无法训练等问题。因此绝大部分情况下,我们都会利用开源社区内的其他比较成熟的更高层框架来进行模型训练。
大模型训练工程那些事虽然支持大模型训练的分布式框架仍有不少,但是社区主流的方案主要还是
- DeepSpeed,这是一个用于加速深度学习模型训练的开源库,由微软开发。它提供了一种高效的训练框架,支持分布式训练、模型并行和数据并行。DeepSpeed 还包括内存优化技术,如梯度累积和激活检查点,以降低内存需求。DeepSpeed 可以与流行的深度学习框架(如 PyTorch)无缝集成
- Megatron,Megatron 是 NVIDIA 开发的一个专为用于训练大规模 transformer 模型的项目。它基于 PyTorch 框架,实现了高效的并行策略,包括模型并行、数据并行和管道并行。Megatron 还采用了混合精度训练,以减少内存消耗并提高计算性能。
- Megatron-LM:Megatron-LM 是在 Megatron 的基础上,结合了 DeepSpeed 技术的NVIDIA做的项目。它旨在进一步提高训练大规模 transformer 模型的性能。Megatron-LM 项目包括对多种 transformer 模型(如 BERT、GPT-2 和 T5)的支持,以及一些预训练模型和脚本, 主导Pytorch。
- Megatron-DeepSpeed : 采用了一种名为 ZeRO (Zero Redundancy Optimizer) 的内存优化技术,以降低内存占用并提高扩展性,提供了一些其他优化功能,如梯度累积、激活检查点等。Megatron-DeepSpeed 支持多个深度学习框架,包括 PyTorch、TensorFlow 和 Horovod。这使得 Megatron-DeepSpeed 对于使用不同框架的用户具有更广泛的适用性。
目前被采纳训练千亿模型最多的还是3和4, Megatron-LM(大语言模型训练过程中对显存的占用,主要来自于 optimizer states, gradients, model parameters, 和 activation 几个部分。DeepSpeed 的 ZeRO 系列主要是对 Optimizer, Gradients 和 Model 的 State 在数据并行维度做切分。优点是对模型改动小,缺点是没有对 Activation 进行切分。Megatron-LM 拥有比较完备的 Tensor 并行和 Pipeline 并行的实现。)。那么为什么大模型训练偏爱 3D 并行呢,比如Megatron-Turing NLG(530B), Bloom(176B)?相信对大模型训练感兴趣的同学,都会熟悉和了解一些使用分布式训练的具体策略和 tricks。我们不如来算一笔账,看看这些 tricks 是为什么。
- ZeRO-Offload 和 ZeRO-3 增加了带宽的压力,变得不可取
- 使用 3D 并行来降低每卡显存占用,避免 recomputation
- GA>1,主要是为了 overlap 和减少 bubble
- Flash Attention2 (显存的节省上面等效于 Selective Activation Recompute)
- ZeRO1 Data Parallel + Tensor Parallel(Sequence Parallel) + Interleave Pipeline Parallel
- 为什么不用 ZeRO2,因为在 GA 的基础上面 Gradient 切分反而多了通信次数
- FP16/BF16/FP8 训练,通信压缩
- Overlapped distributed optimizer
目前LLM训练有两大主流框架:Deepspeed和Megatron-LM。前者的主要提出和维护者是微软的工程师,后者是英伟达的工程师。两个框架从底层原理到设计语言可以说是大相径庭。megatron 和 deepspeed 该怎么选?直接说结论:从零开始的 pretrain 必须选 megatron,continue-pretrain 可以考虑使用 deepspeed, 换句话说,T 级别的 token 训练量必须是 megatron,B 的级别 token 训练量无所谓。
megatron
- megatron 的优点,基于torch重新实现每个模型的定义,实现了更高的性能以及更深的代码封装。
- 训练速度快:tensor_parallel 和 pipeline_parallel 被优化的炉火纯青,rope 已经被开发成了 apex 算子,速度远高于 llama 里的实现方案,据说 mlp 层的 apex 算子也正在开发。
- 参数清晰而明确:argument.py 里,你能看见上百个参数配置,哪些层使用 dropout 等细节,训练框架早就帮你考虑好了,可微操的空间很大。
- 启动训练的时候模型加载速度快,千亿级别的模型一分钟就加载完毕了,debug 十分方便。 megatron 的缺点
- 上手成本很高,新手学习起来比较吃力,对 torch 的多机通讯需要从头开始学。而且基建工作比较多,trans_megatron_to_hf.py,trans_hf_to_megatron.py 对新人也挺折磨的。
- Nvidia 的官方代码库,全是 bug,不预留个一周时间进行 debug,很难直接跑起来。我有一个同事,非常迷信官方,隔两天就要 git pull megatron 的官方代码库,只能说工作量一言难尽。 deepspeed
- deepspeed 的优点,本质上是torch的一个补丁,单卡上运行的代码是transformers定义的。
- 代码简单,超出想象的简单,而且有 model.trainer 这种大杀器框架。
- 用户群体多,alignment 阶段的开源代码 90% 都是 deepspeed 实现。
-
deepspeed 的缺点
- 训练速度慢,相比于 megatron 可能有 10% ~30% 左右的算力损失。当然,现在有很多工作已经实现了 deepspeed 的 pipeline_parallel 和 tensor_parallel,但相对的,用起来也就没那么简单了。
- 加载速度无敌超级十分很非常慢!!!!!从 bash train.sh 到 看见 loss 出现,小模型得十几分钟,大模型得半个小时,如果你需要 debug,一个下午只够 debug 个三五次。
- 代码简单的代价是“微操很难”,尤其是使用 model.trainer 训练,对源码几乎无修改空间。
- 微软的开源代码库在让人失望这件事上从不让人失望。megatron 有 bug 只是让你跑不起来,你修了就好了。deepspeed 的 bug 或者不合理的设置,并不影响你把代码跑起来,只有在你遇见解释不了的现象的时候才可能暴露。我的同事送给过我一句箴言:“遇见不合理的地方,不要质疑自己,无脑质疑 deepspeed 官方!” 哦对,无论是用哪个训练框架,都要记得把 attention 的默认方式换成 flash_attention。
训练框架的主要目标有2:一是在有限的GPU中尽可能地塞入一个大号模型,二是高效地利用多GPU进行训练。完成第一个目标主要依赖的是模型切分,或者更笼统地说是降低单卡显存占用。完成第二个目标依赖的是异步、高重叠度、高带宽的数据通信。
| Deepspeed | Megatron-LM | |
|---|---|---|
| 降低显存 | Zero-1、2、3, 序列并行、CPU Offload | 主要技术有Distributed Optimizer、Tensor Model Parallel、Pipeline Model Parallel、序列并行 |
| 高效通信 | 主要是依赖register_hook回调函数的异步通信、多cuda事件流、GPU计算重叠、连续锁页缓存。 | 主要的技术有P2P通信、重叠流水线并行、梯度缓存。 |
| 设计语言 | 外挂框架,框架并不介入模型前向的计算图,因此对模型结构一般没有特殊要求,核心代码通过大量回调函数和torch派生类封装,并不暴露给用户。好处是兼容性好,对新手友好,缺点是启动慢、计算速度略低,适合数据量不大、不关注训练加速技术,专注于模型和数据迭代的人。 | 内嵌框架,直接改变模型计算图,因此限制模型结构必须是类Transformer的结构,代码全部暴露在外,不怎么依赖回调函数。优点是启动、训练效率高一点,对于想魔改底层的人更友好,但是对于想轻微修改训练逻辑的不太友好,适合大规模训练和想要了解、改动并行训练代码的人。 |
DeepSpeed
DeepSpeed 实现的 ZeRO ,出发点是为了减少显存使用,跨机器跨节点进行更大模型的训练。按层切分模型分别载入参数,看起来好像是模型并行。但是运行时其实质则是数据并行方式,不同的数据会在不同的卡运行,且同一组数据一般会在一块卡上完成全部前向和后向过程。而被切分的参数和梯度等数据会通过互联结构在运行态共享到不同节点,只是复制出的数据用后即焚删除了,不再占用空间。
整体设计
普通数据并行时GPU 内存的占用情况
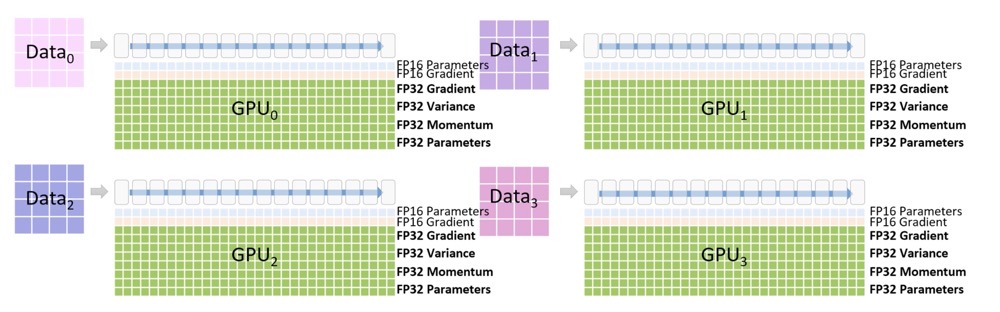
在DeepSpeed下,ZeRO训练支持了完整的ZeRO Stages1, 2和3,以及支持将优化器状态、梯度和模型参数从GPU显存下沉到CPU内存或者硬盘上,实现不同程度的显存节省,以便训练更大的模型。不同Stage对应的做法:
- Stage 1: 把 优化器状态(optimizer states) 分片到每个数据并行的工作进程(每个GPU)下
- Stage 2: 把 优化器状态(optimizer states) + 梯度(gradients) 分片到每个数据并行的工作进程(每个GPU)下
- Stage 3: 把 优化器状态(optimizer states) + 梯度(gradients) + 模型参数(parameters) 分片到每个数据并行的工作进程(每个GPU)下
- Optimizer Offload: 在Stage2的基础上,把梯度和优化器状态下沉到CPU内存或硬盘上
- Param Offload: 在Stage3的基础上,把模型参数下沉到CPU内存或硬盘上
假如GPU卡数为N=64,$\psi$是模型参数,假设$\psi$=7.5B,假设使用Adam优化器,在64个GPU下K=12,则:
- 如果不用ZeRO,需要占用120GB的显存,A100最大才80GB,塞不下
- 如果用ZeRO Stage1,则占用31.4GB,A100 40GB或者80GB卡都能跑,单机多卡或多机多卡训练的通信量不变
- 如果用ZeRO Stage2,则占用16.6GB,大部分卡都能跑了,比如V100 32GB,3090 24GB,通信量同样不变
- 如果用ZeRO Stage3,分片到每个数据并行的工作进程(每个GPU)下),则占用1.9GB,啥卡都能跑了,但是通信量会变为1.5倍
PS:从计算过程的角度讲,先正向后反向,再优化器,正向的时候,反向所需的数据不需要在显存中。从层的角度讲,正向反向的时候,计算前面的层时后面层的参数不需要在显存中,所以就可以用通信换省空间。
ZeRO & DeepSpeed: New system optimizations enable training models with over 100 billion parameters 建议查看官方博客动图。
源码分析
DeepSpeed 使用
config = {
"train_batch_size": 8,
"gradient_accumulation_steps": 1,
"optimizer": {
"type": "Adam",
"params": {
"lr": 0.00015
}
},
"fp16": {
"enabled": True,
}
"zero_optimization": {
}
}
model_engine,optimizer, _, _ = deepspeed.initialize(config=config, model=model, model_parameters=model.parameters())
for step,batch in enumerate(data_loader):
loss = model_engine(batch) # 前向传播
model_engine.backward(loss) # 反向传播
model_engine.step() # 参数更新
if step % args.save_interval:
client_sd['step'] = step # 新增当前step信息与模型一并保存
ckpt_id = loss.item() # 使用loss值作为模型标识
model_engine.save_checkpoint(args.save_dir, ckpt_id, client_sd = client_sd) # 保存模型
deepspeed.initialize 会选择不同的engine(对应不同的模式),DeepSpeedEngine分布式训练引擎 是最基本的模式, 它本身是 torch.nn.Module 的子类,也就是说它是对输入模型的一个封装。 DeepSpeedEngine 的 __init__ 方法中进行了大量的初始化操作, 其中最重要的就是对优化器(Optimizer)的初始化, ZeRO 的核心特性的实现都在优化器(Optimizer)中。
class DeepSpeedEngine(Module):
def __init__(self,args,model,optimizer=None,model_parameters=None,training_data=None,config=None,...):
...
# 优化器的初始化
if has_optimizer: # 入参传入了 optimizer 或者配置文件中指定了 optimizer
self._configure_optimizer(optimizer, model_parameters)
self._configure_lr_scheduler(lr_scheduler)
self._report_progress(0)
elif self.zero_optimization(): # 启用 zero 优化,即 zero_optimization_stage > 0
# 创建 ZeRO 优化器
self.optimizer = self._configure_zero_optimizer(optimizer=None)
elif self.bfloat16_enabled(): # bf16 模式
self.optimizer = self._configure_bf16_optimizer(optimizer=None)
...
参数分割之后,在执行前向、后向之前,需要先把参数再还原回来。 同理,在执行前向后向之后,还要释放掉各自不需要的参数。 这里利用 pytorch 的 hook 功能在上述四个关键节点插入相关的动作。 pytorch 的 Module 类型提供了一系列 register_xxx_hook 方法来实现 hook 功能。PS:deepspeed 的优化主要是参数的存取,不用动模型结构本身。
Megatron-LM
Megatron-LM是一种优雅的高性能训练解决方案。Megatron-LM中提供了张量并行(Tensor Parallel,TP,把大乘法分配到多张卡并行计算)、流水线并行(Pipeline Parallel,PP,把模型不同层分配到不同卡处理)、序列并行(Sequence Parallel, SP,序列的不同部分由不同卡处理,节约显存)、DistributedOptimizer优化(类似DeepSpeed Zero Stage-2,切分梯度和优化器参数至所有计算节点)等技术,能够显著减少显存占用并提升GPU利用率。Megatron-LM运营着一个活跃的开源社区,持续有新的优化技术、功能设计合并进框架中。
多卡进行高维度模型并行时,每一张卡需要装模型的哪一部分,又需要喂入哪一部分数据。在这个过程中,每张GPU的调度是非常复杂的。而Megatron-LM在这个地方的封装和处理已经非常完善了,作为用户只需要提前指定好不同维度模型并行的size大小,code会自动handle各种数据和模型参数的调度。
ATorch
ATorch:蚂蚁开源PyTorch分布式训练扩展库,助你将硬件算力压榨到极致
Atorch-auto_accelerate 基于贝叶斯优化的自动训练优化升级
DLRover 在故障自愈技术上的两大核心功能:首先,通过 Flash Checkpoint 能够在几乎不停止训练流程的前提下快速保存状态,实现高频备份。这意味着一旦遇到故障,系统能够立即从最近的检查点恢复,减少数据丢失和训练时间损耗。其次,DLRover 利用 Kubernetes 实现了智能化的弹性调度机制。该机制能够自动化应对节点故障,例如在 100 台机器的集群中若有一台失效,系统会自动调整至 99 台机器继续训练,无需人工介入。此外,它兼容Kubeflow 和 PyTorchJob,强化了节点健康监测能力,确保在 10 分钟内迅速识别并响应任何故障,维持训练作业的连续性和稳定性。
资源调度
DLRover 在 K8s 上千卡级大模型训练稳定性保障的技术实践 OpenAI 在 1024 个 NVIDIA A100 GPU 上训练 GPT-3 大约需要 34 天。训练节点越多,耗时越长,训练期间节点故障概率就越大。据我们在蚂蚁 GPU 训练集群上观察,一个月内,单卡的故障率约 8%,那么一天单卡的故障率约为 0.27%。常见的故障原因有 Xid、ECC、NVLINK error 和 NCCL error 故障等。对于一个千卡训练作业来说,卡故障导致一天内训练失败的概率高达到 93%。所以训练作业几乎每天都会失败。作业失败后,用户需要手动重启作业,运维成本很高。如果用户重启不及时,中间间隔的时间就会导致 GPU 卡空闲,浪费昂贵的算力资源。
弹性训练是指在训练过程中可以伸缩节点数量。当前支持 PyTroch 弹性训练的框架有 Torch Elastic 和 Elastic Horovod。二者显著的区别在于节点数量变化后是否需要重启训练子进程来恢复训练。Torch Elastic 感知到新节点加入后会立刻重启所有节点的子进程,集合通信组网,然后从 checkpoint 文件里恢复训练状态来继续训练。而 Elastic Horovod 则是每个训练子进程在每个 step 后检查新节点加入,子进程不退出的情况下重新集合通信组网,然后有 rank-0 将模型广播给所有 rank。
- 集合通信动态组网。动态组网是指训练进程可以自动根据动态变化的节点数量来组网集合通信,无需固定给各个节点指定集合通信的 rank 和 world size。动态组网是弹性容错训练必须的,因为弹性容错作业中,节点的失败、扩容或者缩容都会导致节点的 rank 和 world size 变化。所以我们无法在作业启动前给节点指定 rank 和 world size。PS: Rendezvous 机制:Rendezvous Manager/Rendezvous Agent/共享存储。 DLRover ( ElasticJob )会启动一个Master 存CPU pod,负责运行Rendezvous Manager,且会踢掉用不到的pod(让worker pod 进程退出?)。
- 分布式训练容错,训练容错是指训练出现故障后能在无人工介入的情况下快速恢复训练。训练恢复需要如下步骤:定位错误原因,判断错误是否可以恢复;启动训练进程加载训练代码,训练进程能重新集合通信组网;训练进程能加载模型导出的 checkpoint 来恢复训练状态;如果存在故障机,要及时将故障机排除,以便新节点继续调度在故障机。
- 对于无故障机的错误,DLRover 重启进程来恢复训练。
- 对于故障机的错误,DLRover 会通知 SRE 隔离故障机并重新拉起 Pod 来替换出错的 Pod
- 对于正常运行的 Pod 重启其训练进程,减少 Pod 调度时间开销。
- 在训练进程恢复后,DLRover 为了方便用户恢复训练dataset 的消费位点,提供了ElasticDistributedSampler方便用户在对模型做checkpoint时也对 Dataloader做checkpoint。从而实现模型和训练样本数据的一致性。
- 故障机检测
- Agent 收集各训练进程的错误信息,将这些错误栈汇总至 master 节点。随后,master 节点分析汇总的错误数据,以准确定位问题所在机器。例如,若某机器日志显示 ECC 错误,则直接判定该机器故障并将其排除。
- 此外,Kubernetes 的退出码也可以用来辅助诊断,如退出码 137 通常指示底层计算平台因检测到问题而终止该机器运行;退出码 128 则意味着设备不被识别,可能是 GPU 驱动存在故障。还有大量的故障是不能通过退出码来检测的,常见的比如说网络抖动的 timeout。
- 还有许多故障,如网络波动导致的超时,无法仅凭退出码识别。我们会采用更通用的策略:无论故障具体性质,首要目标是迅速识别并踢掉故障节点,然后通知 master 去具体检测问题出在哪里。
- 自动节点检测:首先,在所有节点上执行矩阵乘法运算。随后,将节点配对分组,例如在含 6 个节点的 Pod 中,节点被分为(0,1),(2,3),(4,5) 三组,并进行 AllGather 通信检测。若 4 和 5 之间有通信故障,而其他组通信正常,则可断定故障存在于节点 4 或 5。接下来,将疑似故障节点与已知正常节点重新配对以进一步测试,例如将 0 与 5 组合检测。通过对比结果,确切识别出故障节点。此自动化检测流程能在十分钟内准确诊断出故障机器。前面讨论了系统中断与故障检测的情况,但还需解决机器卡死的识别问题。NCCL 设置的默认超时时间为 30 分钟,允许数据重传以减少误报,然而这可能导致实际卡顿时,每张卡白白等待 30 分钟,累计起来损失巨大。为精确诊断卡死,建议采用一种精细化的 profiling 工具。当监测到程序暂停推进,例如一分钟内程序栈无变化,即记录各卡的栈信息,对比分析差异。例如,若发现 4 台 rank 中有 3 台执行 Sync 操作,而 1 台执行 wait 操作,即可定位该设备存在问题。进一步,我们将关键的 CUDA 通信 kernel 和计算 kernel 进行劫持,在其执行前后插入 event 监控,通过计算事件间隔来判断运算是否正常进行。例如,若某运算超过预期的 30 秒仍未完成,可视为卡死,并自动输出相关日志及调用栈,提交至 master 进行对比,迅速定位故障机器。
- 错误日志收集,在 PyTorch 分布式训练中,一个节点的进程出错后,Torch Elastic 会停止所有节点的进程。各个进程的日志都是单独存在各自日志文件中。为了找到训练失败是哪个进程出错导致的,我们需要搜索所有进程的日志。这个工作对于千卡作业是十分耗时且繁琐的。为此,我们在 ElasticAgent 中开发了错误日志收集供功能。当 ElasticAgent 发现子进程失败后,后将其错误日志的 message 发送给 Job Master。Job Master 会在其日志中展示具体哪个节点的那个进程失败了,以及错误日志。这样用户只需看下 Job Master 的节点日志就可以定位训练失败原因了。 PS:
- 故障检测,踢掉故障worker,踢掉多余worker(有时用户要求worker数必须是N的整数倍),worker 被踢掉之后,由controller来创建新的pod? 若worker 被踢掉之后,新的pod 因为资源不够一直pending,当前集群不满足客户要求的最小worker数,如何处理呢?
- 除了controller、crd等,代码上,DLRover 提供了 ElasticTrainer 来封装训练过程,dlrover-run 来启动训练代码(只要是能用 torchrun 启动的任务,都是支持用 dlrover-run 来跑的。dlrover-run 是扩展了torchrun,所以原生的torchrun的配置都支持。)。
Flash Checkpoint on DLRover 正式发布:千亿参数模型训练秒级容错训练程序一般采用周期 checkpoint 方案来将训练状态持久化到存储。为了保证训练状态的一致性,checkpoint 的时候训练需要暂停。常规的 checkpoint 当前面临以下问题:
- 耗时与模型大小和存储的 IO 性能密切相关,需要几分钟到几十分钟。
- 太频繁的 checkpoint 会大幅降低训练可用时间。
- 低频的 checkpoint 的间隔太长,会导致故障后浪费的迭代步数太多。
DLRover 推出了 Flash Checkpoint (FCP) 方案,同步将训练状态写到共享内存(比如每 10 步一次),然后异步从共享内存写到存储系统(每隔 250 步持久化到 CPFS),将 checkpoint 时间开销降低到秒级。如果非机器宕机故障,DLRover 可以直接重启训练进程,这时可以直接从主机内存中加载 Checkpoint,省去读存储文件的 IO 开销。在进行模型 Checkpoint 的创建时,还有一个细节值得留意。模型的训练基于数据,假设我们在训练进程的第 1000 步保存了 Checkpoint。如果之后重新启动训练但未考虑数据进度,直接从头开始重新消费数据将导致两个问题:后续新数据可能被遗漏,同时前期数据可能会被重复使用。为解决这一问题,我们引入了 Distributed Sampler 策略。该策略在保存 Checkpoint 时,不仅记录模型状态,还会一并保存数据读取的偏移位置。这样一来,当加载 Checkpoint 恢复训练时,数据集会从之前保存的偏移点继续加载,继而推进训练,从而确保模型训练数据的连续性和一致性,避免了数据的错漏或重复处理。
告别资源浪费!DLRover Brain如何基于数据建模优化训练任务?在蚂蚁,日常有 2000 多个推荐模型训练任务,需要 10 万核 CPU 资源。通常这些训练任务由用户配置后提交到集群运行。但是,相当部分提交的任务存在资源配置不当的问题,从而导致了难以忽视的问题:
- 训练任务资源配置不足,可能导致训练任务 OOM 错误或是训练性能低下。
- 训练任务资源配置超额,任务利用率低下,导致集群资源紧张,大量训练任务 pending。 DLRover 的弹性功能能够实现对训练任务的运行时资源调整。DLRover Brain基于训练任务的运行状态,生成相应的资源配置优化方案,从而优化训练任务。PS: 建议细读。
其它
大模型训练为什么用A100不用4090大模型训练需要多少算力?训练总算力(Flops)= 6 * 模型的参数量 * 训练数据的 token 数。
- 6 * 模型的参数量 * 训练数据的 token 数就是所有训练数据过一遍所需的算力。这里的 6 就是每个 token 在模型正向传播和反向传播的时候所需的乘法、加法计算次数。
- 正向传播的时候: l 把它的输出乘上 l 和 r 之间的权重 w,发给 r;r 不可能只连一个神经元吧,总要把多个 l 的加到一起,这就是 reduce,需要一次加法。
- r 把它收到的梯度乘上 l 和 r 之间的权重 w,发给 l;l 也不可能只连一个 r,需要把梯度 reduce 一下,做个加法;别忘了权重 w 需要更新,那就要计算 w 的梯度,把 r 收到的梯度乘上 l 正向传播的输出(activation);一个 batch 一般有多个 sample,权重 w 的更新需要把这些 sample 的梯度加到一起。
- 一共 3 次乘法,3 次加法,不管 Transformer 多复杂,矩阵计算就是这么简单,其他的向量计算、softmax 之类的都不是占算力的主要因素,估算的时候可以忽略。
- 有了模型训练所需的总算力,除以每个 GPU 的理论算力,再除以 GPU 的有效算力利用比例,就得到了所需的 GPU-hours,这块已经有很多开源数据。
- 训练需要的内存包括模型参数、反向传播的梯度、优化器所用的内存、正向传播的中间状态(activation)。
- 优化器所用的内存其实也很简单,如果用最经典的 Adam 优化器,它需要用 32 位浮点来计算,否则单纯使用 16 位浮点来计算的误差太大,模型容易不收敛。因此,每个参数需要存 4 字节的 32 位版本(正向传播时用 16 位版本,优化时用 32 位版本,这叫做 mixed-precision),还需要存 4 字节的 momentum 和 4 字节的 variance,一共 12 字节。如果是用类似 SGD 的优化器,可以不存 variance,只需要 8 字节。
- 正向传播的中间状态(activation)是反向传播时计算梯度必需的,而且跟 batch size 成正比。Batch size 越大,每次读取模型参数内存能做的计算就越多,这样对 GPU 内存带宽的压力就越小。划重点:正向传播的中间状态数量是跟 batch size 成正比的。
- 大家也发现正向传播中间状态占的内存太多了,可以玩一个用算力换内存的把戏,就是不要存储那么多梯度和每一层的正向传播的中间状态,而是在计算到某一层的时候再临时从头开始重算正向传播的中间状态,这样这层的正向传播中间状态就不用保存了。如果每一层都这么干,那么就只要 2 个字节来存这一层的梯度。但是计算中间状态的算力开销会很大。因此实际中一般是把整个 Transformer 分成若干组,一组有若干层,只保存每组第一层的中间状态,后面的层就从该组第一层开始重新计算,这样就平衡了算力和内存的开销。
- 当然有人说,GPU 内存放不下可以换出到 CPU 内存,但是就目前的 PCIe 速度,换出到 CPU 内存的代价有时候还不如在 GPU 内存里重算。
- 对于 LLaMA-2 70B 模型,模型参数需要 140 GB,反向传播的梯度需要 140 GB,优化器的状态(如果用 Adam)需要 840 GB。
- Tensor、Pipeline、Data Parallelism 就像是这样的不可能三角,相互牵制,只要集群规模够大,模型结构仍然是 Transformer,就很难逃出内存容量和网络带宽的魔爪。
- 推理所需的计算量大概就是 2 * 输出 token 数量 * 参数数量 flops。
- 70B 推理的时候最主要占内存的就是参数、KV Cache 和当前层的中间结果。当 batch size = 8 时,中间结果所需的大小是 batch size * token length * embedding size = 8 * 4096 * 8192 * 2B = 0.5 GB,相对来说是很小的。70B 模型的参数是 140 GB,140 GB 参数 + 40 GB KV Cache = 180 GB
- 算子拆分 单个矩阵乘法可以分到两个device上计算
Y = WX = [W1,W2]X = [W1X,W2X]。我们在工程上要做的就是:将切分到两个device上,将复制到两个device上,然后两个device分别做矩阵乘法即可。有的时候,切分会带来额外的通信,比如矩阵乘法切到了reduction维度上,为了保持语义正确,就必须再紧跟一个AllReduce通信。 这里复杂之处在于,你不能无脑地将所有算子全部做拆分,因为拆分可能会引入一些额外通信,降低总体吞吐。所以你得做些分析,决定哪些算子被拆分,现在大部分框架都不支持这种全自动化策略,要么是半自动或纯手工,要么是针对某种模型把它的拆分方案写死。所以只能造轮子解决这个事 - 流水并行 不切算子,而是将不同的Layer切分到不同的Device上,就可以形成Pipeline方案,GPipe就是这样一种方案,提出了将一个batch拆分成若干个micro-batch,依次推入到Pipeline系统中,即可消除Bubble time。和算子拆分类似,全自动化方案工作量不小,比如Pipeline怎么切,才能让通信量小,计算还能均匀,这需要一定的算法和工程量
我们的模型可能会很大,或者数据量会很大。仅仅用一块GPU卡可能连模型都放不下,或者batch size只能设置的很小,但是我们知道有些情况下大的batch size往往会提供更好的效果。
- 假设我们只有一个GPU,我们的模型一次只能输入batch size为8的数据,那么我们怎么样实现batch size为32的更新呢?那就需要时间换空间了,即我们训练32/8=4步才去更新模型,也就是所谓的梯度累积。
- Gradient-Checkpointing, 那么如果你的GPU连batch size为1都跑不了怎么办?我们在训练深度学习模型的时候,需要先做前向传播,然后将中间得到的激活值存储在内存中,然后反向传播的时候再根据loss和激活值计算梯度。也就是说内存消耗其实跟模型的层数线性相关。那么怎么减少这个内存消耗呢?最简单的想法就是我不存这些中间信息,计算梯度的时候,到了某一层我重新计算它的激活值,这个方法虽然可以让内存消耗是个常量,但是运行时间会是
O(n^2),这是没法接受的。那么就有一个折中的办法,我不存全部的中间数据,只存部分,那么我们在计算梯度的时候不需要从头计算了,只需要从最近的checkpoint点计算就好。 - 我们训练模型一般都是用单精度(FP32)的参数,但是其实我们还使用半精度(FP16)。半精度可以降低内存消耗,从而训练更大的模型或者使用更大的batch size;同时运算时间受内存和算术带宽的限制,在有些gpu(Tensor cores)上可以为半精度提供更大的算术带宽,从而提高训练效率,减少inference用时。
面向大模型的存储加速方案设计和实践 未细读。
飞桨大模型分布式训练技术 未细读。
DeepSpeed结合Megatron-LM训练GPT2模型笔记(上) 未读
图解大模型训练系列之:DeepSpeed-Megatron MoE并行训练(原理篇)
经验
聊一聊做Pretrain的经验在模型训练中,要始终谨记一条大原则,一条训练数据的训练速度:卡内通迅 > 卡间通讯 > 机间通讯。能减小模型的通讯量就去减小,能避免机间通讯就去避免。在显存够用的情况下,能不引入 tensor_parallel,pipeline_parallel,sequence_prallel 就不要去引入,同样地、能不开 offload 就不要开 offload,能不开重算就不开重算。总结下来就是:
- data_parallel 几乎是唯一不牺牲算力的并行方式;
- 让数据在显存和内存之间切换,也是很耗时的,这种操作能避免就避免;
- 同样的结果多次计算,傻子都知道速度会变慢,因此能存储就别重算。
训练 loss 分析 pretrain 训练环节中,最最最最最重要的中间产出,就是 tensorboard 的那条 loss 曲线。记住几条:
- 一定要有 channel_loss,至少,中文知识,英文知识,代码这三类数据的 loss 得分开观察;
- loss_spike 不可忽视,虽然目前还没有工作去证明说 loss_spike 会对模型造成不可逆的效果伤害,但不出现 losst_spike 总是好的啊。无论是 loss 突然激增还是激减,都要重点留意,大概率是数据问题(脏数据不仅 loss 高,也会 loss 低,全是乱码的数据 loss 很高,全是换行符的数据 loss 很低)。如果数据过脏,就回退到上个 checkpoint 进行训练;
- 即使数据没有问题,也是有可能出现 loss_spike 的,这时候要留意下数据的 grad 有没有异常,大概率和优化器有关,参考 llama 等的技术报告,好好调整 adamw 优化器的 这两个参数,基本上能解决大部分训练初期的 loss_spkie 问题。一旦熬过了训练初期,loss 平稳下降到了 2 ~3 左右,后续的训练也基本不会再有幺蛾子了。
pretrain 训练流程目前基本是固定的,当训练数据和训练代码都准备就绪后,按照以下四个流程来设置学习率和超参数就可以啦:
- 开局 warmup,学习率缓慢上升到最大;
- 中间 cos / cos_decay / constant / constant_decay ,学习率比较大,是否 decay 自己决定,多翻翻别人的技术报告,或者在小模型上做实验决定;
- 后期改变 rope base + seq_len,开始让模型适应长文本;
- 收尾 anneal,用高精数据、IFT数据等来给强化模型的考试能力,做完退火就该上考场刷 benchmark 了。
- 一般 pretrain 只要启动了,大家就可以去做别的工作了,只要模型训练没停,一般都不需要再有人为干预。烧卡了, loss 爆炸了,loss陡然下降了(数据大概率重复了),就回退到上一个 checkpoint 重启。
评估篇
- PPL,机器学习的基本课:看测试集的 loss 来衡量模型效果。准备一些百科、逻辑、code 等数据,每天观察模型在这些测试集合上的 loss 表现,偶尔浮动是正常的,但整体趋势肯定是持续下降,最后趋于稳定的。只要训练集中没这些语料,和训练曲线应该是基本一致的。特别地、ppl 只能是自己的模型和自己比,前面说过,由于 tokenizer 的压缩率不同,不同模型的 loss 没有明确可比性,全是字没有词的 tokenizer,loss 一定是最低的。不过另一方面,不管你的 tokenizer 压缩率多少,在通用知识测试集上的 loss 也是应该能降低到 2 以下的,否则就说明有点训练不充分。
-
Benchmark。如果 pretrain 阶段全程是自己在负责,那么 benchmark 还是有一定可信程度的。但无论是继承同事的 checkpoint,还是下载开源模型的 checkpoint,一律视为它们刷过榜。除了模型完全给自己用的公司,只要是有宣发需求的 pretrain 团队就一定会刷榜,否则根本和别的模型比不了。这种情况下,benchmark 考察的就是谁遗忘的少,而不是谁具有的知识多,训的越多模型得分就越低。即使排除了刷榜问题,现在最主流的 benchmark,形式也都实在是有点单一了。全是选择题,而且是没有 cot 环节的选择题,衡量模型的能力肯定是有偏颇的。cot 就是模型的草稿纸,就算是我们人,拿到一个选择题,不去演算一下就直接说出 A、B、C、D 该选哪一个,也是很匪夷所思的。可是话说回来,benchmark 毕竟是现成的具有高密度知识的 question-answer 的高质量语料,不使用着实可惜。这里我的建议是改造 benchmark,无论是评估自己的模型还是评估别人的刷过榜的模型,尽量用生成式的方法去使用 benchmark,而不是看 A、B、C、D 哪个概率高。改造可以是任意形式的,我举几个例子
- Question + Answer_A,Question + Answer_B,Question + Answer_C,Question + Answer_D。请结合上述文本,回答 Question;
- 把 Question 的正确答案丢弃,假设 B 选项是正确的答案,那就把它改成“B. 其他答案全错”,看模型还能不能把 B 选出来;
- 把原始 benchmark 的 A / B / C / D 改成 一 / 二 / 三 / 四;
- 把多选题改造成单选题;
- Question + A / B / C / D,先把这个知识让模型不知道答案的情况下训一遍,然后让模型直接说出 Question 的正确答案; …… 如果担心模型不 follow 格式,那就用 few_shot 的方式让模型去抄袭格式,通常都能 follow 住;如果担心模型停止不了,就限制 max_new_token,或者是使用 StoppingCriteria,让模型见到换行符就停止。总之,我们要灵活善变的来利用 benchmark,既然你训过了,那我就各种花式改造 benchmark 的使用方法,来跳过你训过的数据,最起码让模型背过的背答案失效——考纲不变,考卷换了。改造方式大家可以自己多多揣测,找到自己最喜欢的那一款,反正是用来证明模型能力的,不是打榜的,得分高低没有意义,得分是否持续升高才有意义。还有,不管改造成什么形式,一定要用 ACC 来衡量评估结果。BLEU 和 Rouge 的得分还是太抽象了,连做 case 分析都不行。
-
概率探针。从概率的角度来监控模型的知识能力有没有遗忘或者提升,适用于我们要观察模型的某一项具体能力。思路也非常简单,我们就观察某个 token 的概率是否增加,某个句子的概率是否增加,唯一麻烦的地方是探针测试集往往需要训练者一条一条亲自去构造,而不能批量生成。比较抽象,我举几个例子:
- Prob(‘北京’|’中国的首都是’),就看一下这个概率值随着 pretrain 推进是否持续在增大;
- PPL(‘台湾属于中国’),这个句子的 ppl 是否持续在增大;PPL(‘台湾不属于中国’),这个句子的 ppl 是否持续在减小;
- 对比探针,PPL(‘尊重同性恋’) > PPL(‘反对同性恋’) 是否成立;
- 指令 follow 能力,Prob( ‘{ ‘| ‘以 json输出’); …… 和 benchmark 改造类似,概率探针是可以根据自己的喜好任意构造的。我们重点观察的也是指标的变化趋势,而不是指标的绝对大小。
pretrain 的全环节大抵如此,我列出来的每个环节我认为都是同等重要的。之前看见有种说法说洗数据是脏简历的工作,恕我不能认同。如果 infra 团队已经帮忙调通了 megatron 的训练代码,那么训练才是真的最没技术含量的工作,改几个参数,然后 bash train.sh,训练挂了就重启,这些工作谁做不来呢?反倒是洗数据时的灵光一现,往往能大大提升模型的效果。因此,“数据篇”也是我笔墨最多的篇章。
留下评论