Python协程实现
简介
从 yield 到 await:Python 协程的进化史 未细读。
在异步程序中,用户编写的程序通过asyncio.run 调度最初的协程(启动事件循环),用户编写的各个协程使用await表达式驱动下一步。 await链最终到达一个底层可异步调用对象,返回一个生成器,由EventLoop驱动,对计时器或io等event做出响应。
创建协程 ==> asyncio.create_task(coroutine)协程转为task并注册到eventloop ==> eventloop 驱动task 执行。
铺垫
协程系列(1) 什么是协程协程的协指的是主动协作,每个协程在完成前可以暂停和恢复,在代码块中可以将执行权交给其他协程。协程的本质是一个状态机,有多个状态,每个状态都可以暂停,然后再继续往下走。一个语言支持协程,就是指这个语言提供了创建协程的语法。但是这个语法,并不是协程的本质,只是为了方便用户使用协程而已。保存状态可以用状态机,也可以用栈空间。如果把我们的状态机改造成一个栈,那么我们就可以把状态保存在栈里,然后切换协程的时候, 保存和恢复栈空间就可以了。PS:操作系统负责内核线程上下文的的存储、恢复、切换;同理,在协程中,关键问题就在于怎么存储、恢复、切换协程的上下文。从协程的实现原理来区分,大致可以分为有栈协程和无栈协程。
- 有栈协程(Stackful Coroutine),协程有自己的栈空间,比如像 Go 的话,一个协程就对应了一个程序栈,切换协程的时候,就需要切换程序栈。有点像那个线程切换,不同之处在于可以主动换出。而Go的虚拟机就承担了调度器的角色,有兴趣可以了解一下 Go 的 GMP 抽象.
- 无栈协程 (Stackless Coroutine) ,协程对象没有自己的栈空间。用户写起来更加麻烦,因为需要显式写出 await 语句,来让协程切换到其他协程,不然只是创建了协程对象,但是协程对象不会运行。而且 await 需要一个协程 Event Loop,所以只能在 async 函数里面调用。这就是大家所说的无栈协程染色问题。Python 协程库asyncio/Rust协程库 tokio/C++20 协程库 asio都是典型的无栈协程。
调度方式上要区分两类:Python asyncio 是协作式——协程只在显式 await 处才让出执行权,一个迟迟不让出的协程(CPU 密集循环、或误用了阻塞调用)会一直霸占事件循环,把同线程其他协程“饿死”。而 Go 的 goroutine 是抢占式——运行时可在函数调用/安全点强制切走,单个 goroutine 跑太久也不会饿死别人,代价是调度由运行时接管、无需手写 await。
协程离不开调度器,调度器 (Scheduler) 是协程的运行时的重要组成部分,它负责调度协程的运行。一个调度器管理多个协程,调度器需要有一个队列,用来存放等待运行的协程。调度器的 run 方法, 就是一个事件循环 (Event Loop)。 它会不断地运行协程, 直到所有协程都运行完毕。我们还需要给 Scheduler 提供一个 add_coro 方法,用来向队列中添加协程。大家一般把这个方法叫做 spawn 或者 create_task。
当把这些设计实现出来后,我们会发现,这个调度器的性能很差。现在我们要对它做一些优化
- 阻塞系统调用。如果协程里有阻塞的系统调用, 比如 sleep, 那么这个线程就会一直等待, 直到系统调用返回,才可以运行下一个协程。这会大大影响协程的工作效率。所以说, 协程里的阻塞系统调用,不能阻塞整个工作线程。常见的解决方法有两种:
- 把阻塞的系统调用,放到一个单独的线程里运行, 然后让协程等待这个线程的结果。
- 提供一套 async 的替代品,把阻塞系统调用替换掉,比如 asyncio.sleep 等。
- 协程的调度。如果我们有 1000 个协程,每次都从队列里随机选一个协程,也会导致每个协程都要等待 1000 次, 才能运行一次。所以我们需要一个更加合理的办法, 来找出哪些协程是可以运行的。上面说过, 协程库需要提供系统调用接口, 比如 sleep, send_request 等。这些系统调用接口可以向操作系统注册事件, 比如 sleep 可以注册一个定时器事件,send_request 可以注册一个网络事件。当这些事件发生时,操作系统会通知协程库,然后协程库再通知相应的协程。这样的话, 协程库就可以知道哪些协程是可以运行的了, 效率被极大地提高了。 比如你有十万个协程,但是只有 100 个协程是可以继续跑的, 那么调度器就只需要运行这 100 个协程, 而不需要处理其他的 99900 个协程。 有了上面说的这两点想法,我们就可以实现一个高效的协程库了。当然具体做起来还有很多细节需要处理,比如协程的异常处理,协程的返回值等等。
历史
早在 Python 2.2(2001年),语言引入了 yield 关键字,用于创建惰性计算的序列,此时,yield 被视为一种增强版的 return,主要用于节省内存地遍历大数据集或无限序列。
def counter():
i = 0
while True:
yield i
i += 1
gen = counter()
print(next(gen)) # 输出 0
print(next(gen)) # 输出 1
2006 年的 Python 2.5,加入了 .send(value) 方法,使外部可以向生成器内部传递数据。这一特性彻底改变了生成器的角色:它不再只是“产出值”,而是能接收输入、维护状态、主动暂停的独立执行体。这正是“协程(Coroutine)”的核心定义——一个可中断、可恢复、能与调用方协作的过程。
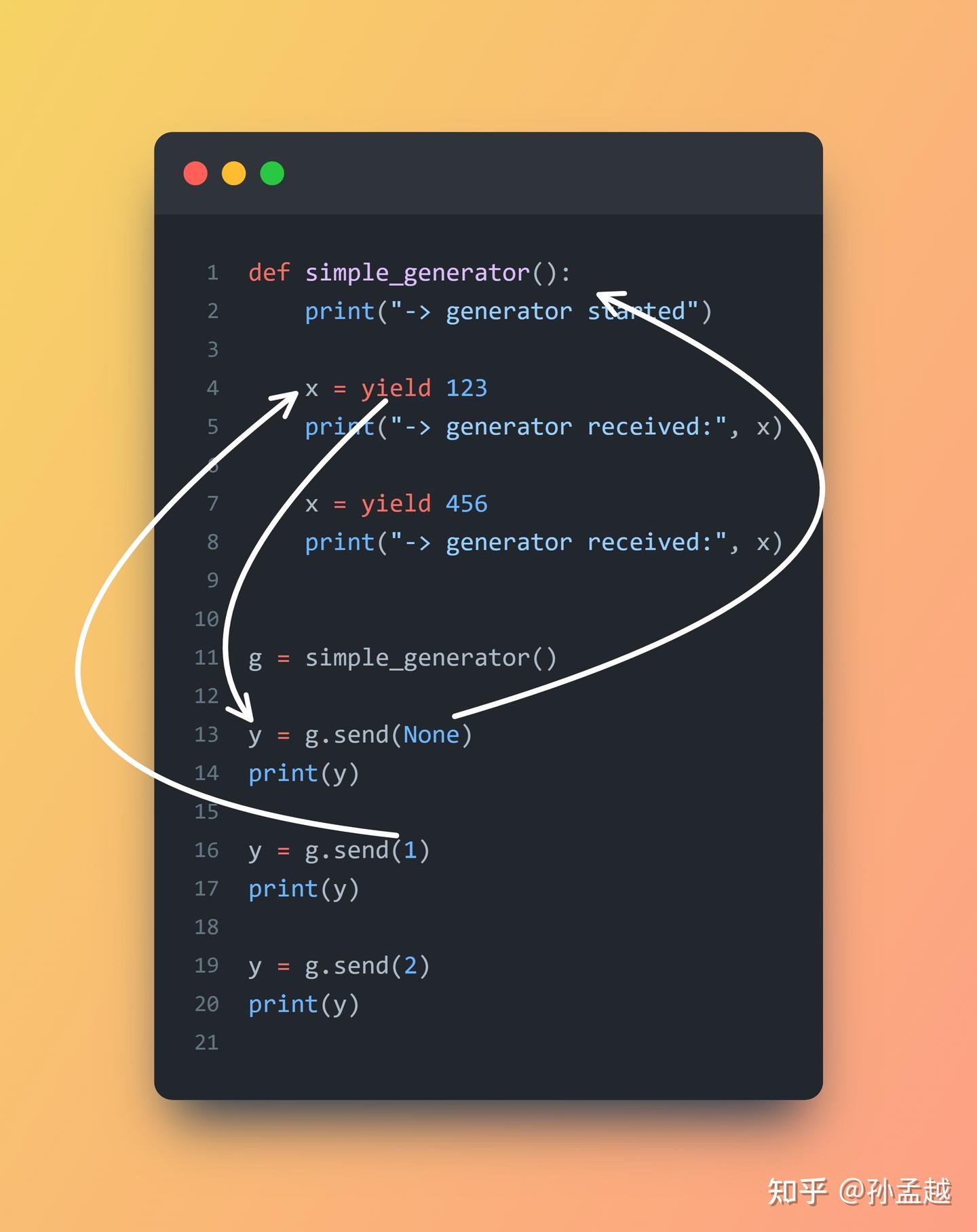
随着异步模式在实践中应用加深,开发者开始尝试用生成器模拟复杂任务流。然而很快遇到了一个经典问题:如何在一个生成器中“发起/调用”另一个生成器,并正确转发所有控制信号(数据输入、数据产出、异常处理、返回值捕获)?
- 2012 年,随着 Python 3.3 发布,PEP 380 正式引入 yield from,一举解决了嵌套生成器问题,但它仍属于普通生成器语法,难区分“真协程”与“假生成器”;
- 因此,PEP 492 (2015年,Python 3.5)提出了更高级的抽象:async def 与 await,async def 明确定义一个 原生协程函数;await 替代 yield from,只能用于 awaitable 对象;本质上,await 是 yield from 在异步上下文下的专用化版本——去除了通用性,换取更强的语义清晰度。
- 最后,配合 async/await 的语义升级,官方标准库 asyncio 成为现代异步编程的核心。至此,Python 完成了从“生成器兼职协程”到“原生异步优先”的全面转型。可以看到技术演进不是跳跃式的,而是遵循 “hack → 模式 → 库 → 语法 → 生态” 的升维路径。
PS:一般情况下,协程是一个独立的并发执行体,其它执行体在协程执行期间可以与之交互数据。但大多数时候,比如用fastapi async 写业务逻辑,此时虽然用await执行的async方法,但与async的方法的交互仅限于入参和出参,此时就仅有一个提高并发(I/O 处理能力)的作用。但是在底层,多个请求的协程在交替执行。
事件循环/EventLoop
EventLoop是用于在单个线程中执行协程的环境。EventLoop是异步程序的核心,是中央总控。Eventloop实例提供了注册、取消和执行任务和回调的方法。事件循环,顾名思义,就是一个循环。它管理一个任务列表(协同程序)并尝试在循环的每次迭代中按顺序推进每个任务,以及执行其他任务,如执行回调和处理 I/O。“asyncio”模块提供了访问事件循环并与之交互的功能,这不是典型应用程序开发所必需的,asyncio 模块提供了一个用于访问当前事件循环对象的低级 API,以及一套可用于与事件循环交互的方法。
Asyncio 和其他 Python 程序一样,是单线程的,它只有一个主线程,Future 是一个可以被等待的对象,Task 在 Future 的基础上加入了一个 coroutine。他们都是 asyncio 的核心,但是他们都需要一个 EventLoop 来运行。任务只有两个状态:一是预备状态;二是等待状态。event loop 会维护两个任务列表,分别对应这两种状态;并且选取预备状态的一个任务(具体选取哪个任务,和其等待的时间长短、占用的资源等等相关),使其运行,一直到这个任务把控制权交还给 event loop 为止。当任务把控制权交还给 event loop 时,event loop 会根据其是否完成,把任务放到预备或等待状态的列表,然后遍历等待状态列表的任务,查看他们是否完成。如果完成,则将其放到预备状态的列表;这样,当所有任务被重新放置在合适的列表后,新一轮的循环又开始了:event loop 继续从预备状态的列表中选取一个任务使其执行…如此周而复始,直到所有任务完成。
# 简化的事件循环实现示意
class EventLoop:
def __init__(self):
self._ready = deque() # 就绪任务队列
self._scheduled = [] # 计划任务队列
self._stopping = False
async def run_forever(self):
while not self._stopping:
# 执行就绪任务
while self._ready:
current_task = self._ready.popleft()
await self._run_task(current_task)
# 检查计划任务
self._check_scheduled()
# 等待新的事件
await self._poll_for_events()
协程实现的几种方式?
- python2.X:利用生成器通过yield+send实现协程
- python3.4:利用asyncio+yield from实现协程
- python3.5:asyncio+async/await(比较熟悉)
- python3.7:引入了asyncio.create_task和asyncio.run两个高级接口
几个理解
- 在go里没有同步方法异步方法一说,同步里调“异步方法” 只是go 启动了一个同步方法。但在python 里从语法上区分了同步方法和异步方法,异步方法只能在EventLoop里执行,可以认为同步方法和异步方法 runtime 不同。
- 所以在python里,同步方法里调用异步方法,要把异步方法封为task 交给loop执行,比如loop.run_until_complete(task)。异步方法可以直接执行同步方法,但如果不想让同步方法阻塞EventLoop,则需要
result = await loop.run_in_executor(sync_func),将sync_func交给专门的线程executor。PS:实际是executor执行sync_func
Future
Future是协程的封装,对于用户而言, Future 是同步代码和异步代码之间的桥梁,表示一个可以被等待的对象。它记录了如下变量: PS:所谓桥梁,说白了就是调用方和执行方都可以持有、 访问它
- state: 任务的状态, 分别是 PENDING , CANCELLED , FINISHED .
- loop: 事件循环, 用于执行回调函数.
- callbacks: 回调函数列表, 用于存储回调函数.
- result: 任务的结果.
- exception: 任务的异常.
可以想见,Future 记录了任务的状态,并储存了任务的结果或异常。用户可以等它,并获取结果,也可以取消他。Future并不一定要和协程绑定在一起,有时候我们只是等待一个 IO 完成, 或者等待一个定时器到期。 这时候我们就可以用 Future 来表示这个等待。
def c():
print('Inner C')
return 12
future = loop.run_in_executor(None, c)
future.done()
future.add_done_callback(...)
await future
Task
Task 是 Future 的子类,它的作用是把协程对象包装成 Future,在 Future 的基础上加入了一个 coroutine。PS:类似java的FutureTask,协程离不开调度器,一个调度器管理多个协程,调度器需要有一个队列,用来存放等待运行的协程。现在看,是不是可以认为,调度器队列里的基本单元是Task?单纯一个 coro 则调度器无法设置coro的状态。PS:Task类似go 里的G,Event Loop类似go的P。Task 是Event Loop的调度对象。Python 的 Task = 跑一条固定 await 链的执行环境(context + stack + state)。在 Python 中:只有遇到 await,当前协程才会把控制权交回Event Loop。Event Loop不是自由地抢占协程、切换协程(传统调度器),而是:await 遇到 I/O future → 让出控制权; future 完成 → 恢复协程执行,完全协作式,不是调度器想调哪个async 方法就调, async 方法之间的调用顺序由代码结构决定(A await B await C)。FastAPI 每个请求对应一个 Task。
调用异步函数并不能执行函数,异步函数就不能由我们自己直接执行(这也是函数与协程的区别),异步代码是以 Task 的形式去运行,被 EventLoop 管理和调度的。result = async_function() 协程对象 result 虽然生成了,但是还没有运行,要使代码块实际运行,需要使用 asyncio 提供的其他工具。
- 最常见的是 await 关键字。当我们await一个Coroutine,这个异步函数就会被提交给asyncio底层,然后asyncio就会开始执行这个函数。
- 如果一个对象可以在 await 语句中使用,那么它就是 可等待 对象。许多 asyncio API 都被设计为接受可等待对象。可等待 对象有三种主要类型: 协程, Task 和 Future.
- 使用 await 关键字时,当遇到耗时操作时,将暂停当前函数的执行,并等待耗时操作完成,同时它会释放出事件循环来处理其他任务。
result = asyncio.run(async_function())。 这是程序入口处专用的,作为程序中所有异步代码的入口。run里边就不能再run了。asyncio.create_task(async_function()),创建一个 Task 对象实例,异步函数被包在了Task,Task 对象实例立即被运行。这一点与await不同,如果我们有一个Coroutine,我们必须await它,才能把相应的异步函数提交给asyncio(然后才开始运行)。当然了,虽然Task不await也能执行,但我们通常还是需要await各个Task。因为这可以确保它们执行完成并收集运行结果,不然我们就得用Future。- 任务可以便捷和安全地取消。 当任务被取消时,asyncio.CancelledError 将在遇到机会时在任务中被引发。
- 任务组合并了一套用于等待分组中所有任务完成的方便可靠方式的任务创建 API。class asyncio.TaskGroup,持有一个任务分组的 异步上下文管理器。 可以使用 create_task() 将任务添加到分组中。 async with 语句将等待分组中的所有任务结束。 。当该上下文管理器退出时所有任务都将被等待。当首次有任何属于分组的任务因 asyncio.CancelledError 以外的异常而失败时,分组中的剩余任务将被取消。一旦所有任务被完成,如果有任何任务因 asyncio.CancelledError 以外的异常而失败,这些异常会被组合在 ExceptionGroup 或 BaseExceptionGroup 中并将随后引发。PS: 有点像go中的waitgroup,启动多个任务,发生异常、等一个任务执行完、等待所有任务都完成、限制某个任务执行过程都提供了接口。
result = await async_function() 和普通的同步函数没有任何区别,主要原因是:这里其实没有将协程放到 EventLoop 中,这用到了asyncio.create_task()。
async def main():
task1 = asyncio.create_task(async_function())
task2 = asyncio.create_task(async_function())
# await task 等待 Task 执行结束
print(await task1)
print(await task2)
asyncio.run(main())
Task 对象有以下api,非常直观。
done() # 如果 Task 对象 已完成 则返回 True。
result() # 返回 Task 的结果。
exception() # 返回 Task 对象的异常。
add_done_callback(callback, *, context=None) # 添加一个回调,将在 Task 对象 完成 时被运行。
get_stack(*, limit=None) # 返回此 Task 对象的栈框架列表。
print_stack(*, limit=None, file=None) # 打印此 Task 对象的栈或回溯。
cancel(msg=None) # 请求取消 Task 对象。
cancelled() # 如果 Task 对象 被取消 则返回 True。
uncancel() # 递减对此任务的取消请求计数。返回剩余的取消请求数量。
EventLoop工作原理
Python 3.4 加入了asyncio 库,使得Python有了支持异步IO的官方库。这个库,底层是事件循环(EventLoop),上层是协程和任务。每个线程都有一个被称为事件循环(Event Loop)的对象(可以理解成 while True 循环),Event Loop 中包含一个称为任务(Task)的对象列表。每个 Task 维护一个堆栈,以及它自己的 Instruction Pointer。在任意时刻,Event Loop 只能有一个 Task 实际执行,毕竟 CPU 在某一时刻只能做一件事,当 Task 遇到需要等待的事情,比如 IO bound 应用需要等待数据到达。此时,Task 中的代码不再等待,而是让出控制权。Event Loop 暂停正在运行的 Task。未来的某个时刻,当这个 Task 所等待的事情已经成熟,Event Loop 将再次唤醒这个 Task。Task 让出控制权后,Event Loop 唤醒某个休眠的 Task,并将这个新唤醒的 Task 设置为当前执行的 Task。线程会遍历各个任务,在前面任务IO等待的过程中,进行后面任务的CPU计算,使得 CPU 闲置的时间更少。循环往复,直到所有任务执行完毕。Python在3.5版本中引入了关于协程的语法糖async和await,Python 3.7 又进行了优化,把API分组为高层级API和低层级API,把EventLoop相关的API归入到低层级API。
深入理解Python异步编程(上)通过epoll 把I/O事件的等待和监听任务交给了 OS,那 OS 在知道I/O状态发生改变后(例如socket连接已建立成功可发送数据),它又怎么知道接下来该干嘛呢?只能回调。异步编程最大的困难:异步任务何时执行完毕?接下来要对异步调用的返回结果做什么操作?上述问题我们已经通过事件循环和回调解决了。但是回调会让程序变得复杂:回调层次过多时代码可读性差;错误处理困难;回调地狱等。要异步,必回调,又是否有办法规避其缺点呢?那需要弄清楚其本质,为什么回调是必须的?还有使用回调时克服的那些缺点又是为了什么?答案是程序为了知道自己已经干了什么?正在干什么?将来要干什么?换言之,程序得知道当前所处的状态,而且要将这个状态在不同的回调之间延续下去。多个回调之间的状态管理困难,那让每个回调都能管理自己的状态怎么样?链式调用会有栈撕裂的困难,让回调之间不再链式调用怎样?不链式调用的话,那又如何让被调用者知道已经完成了?那就让这个回调通知那个回调如何?而且一个回调,不就是一个待处理任务吗?任务之间得相互通知,每个任务得有自己的状态。那不就是很古老的编程技法:协作式多任务?然而要在单线程内做调度,啊哈,协程!每个协程具有自己的栈帧,当然能知道自己处于什么状态,协程之间可以协作那自然可以通知别的协程。不用回调的方式了,怎么知道异步调用的结果呢?先设计一个对象,异步调用执行完的时候,就把结果放在它里面。这种对象称之为未来对象Future。
class Future:
def __init__(self):
self.result = None # 存放未来的执行结果
def set_result(self, result):
self.result = result
for fn in self._callbacks:
fn(self)
asyncio 提供了如下三个接口来获取或设置事件循环:
default_loop = asyncio.get_event_loop() # 获取当前线程的事件循环
default_loop = asyncio.get_event_loop_policy().get_event_loop() # 与上一行等效
asyncio.set_event_loop(loop) # 为当前线程设置事件循环
asyncio.get_event_loop_policy().set_event_loop(loop) # 与上一行等效
new_loop = asyncio.new_event_loop() # 根据当前事件循环策略生成一个新的事件循环
new_loop = asyncio.get_event_loop_policy().new_event_loop() # 与上一行等效
- 调用 get_event_loop() 得到的是默认事件循环。如果是 Unix-like 系统,会调用asyncio.SelectorEventLoop()得到基于epoll或kqueue选择机制的事件循环;
- 每个线程可以设置不同的事件循环,但是每个进程又只能有一个事件循环策略。使用默认策略时,主线程能够 asyncio.get_event_loop() 得到默认事件循环,但是子线程内做此操作却不行。会报RuntimeError,提示当前线程无事件循环。子线程中有异步时,需在子线程内先设置事件循环,或将主线程中获取到的循环对象传递给子线程。
- Event Loop 不能中断正在执行的协程
- 程序以 Task 的形式放到 EventLoop 中,EventLoop 管理多个 Task,唤醒某个 Task 或者暂停某个 Task 。
Python Asyncio调度原理 未细读。 task 注册
def create_task(coro, *, name=None):
"""Schedule the execution of a coroutine object in a spawn task.
Return a Task object.
"""
loop = events.get_running_loop()
task = loop.create_task(coro)
_set_task_name(task, name)
return task
class BaseEventLoop(events.AbstractEventLoop):
def create_task(self, coro, *, name=None):
"""Schedule a coroutine object.
Return a task object.
"""
if self._task_factory is None:
task = tasks.Task(coro, loop=self, name=name)
if task._source_traceback:
del task._source_traceback[-1]
else:
task = self._task_factory(self, coro)
tasks._set_task_name(task, name)
return task
# 把一个调用封装成一个Handle,并添加到self._reday中,从而实现把调用注册到事件循环之中
def call_soon(self, callback, *args, context=None):
# 检查是否事件循环是否关闭,如果是则直接抛出异常
self._check_closed()
handle = self._call_soon(callback, args, context)
return handle
def _call_soon(self, callback, args, context):
# 把调用封装成一个handle,这样方便被事件循环调用
handle = events.Handle(callback, args, self, context)
# 添加一个handle到_ready,等待被调用
self._ready.append(handle)
return handle
class Task(Future):
def __init__(self, coro, *, loop=None, name=None):
super().__init__(loop=loop)
...
self._loop.call_soon(self.__step, context=self._context)
_register_task(self)
BaseEventLoop 执行。PS:这不就是netty eventloop嘛
class BaseEventLoop(events.AbstractEventLoop):
def run_forever(self):
while True:
self._run_once()
if self._stopping:
break
def _run_once(self):
"""Run one full iteration of the event loop.
This calls all currently ready callbacks, polls for I/O,
schedules the resulting callbacks, and finally schedules
'call_later' callbacks.
"""
sched_count = len(self._scheduled)
if (sched_count > _MIN_SCHEDULED_TIMER_HANDLES and
self._timer_cancelled_count / sched_count > _MIN_CANCELLED_TIMER_HANDLES_FRACTION):
# Remove delayed calls that were cancelled if their number is too high
...
else:
# Remove delayed calls that were cancelled from head of queue.
...
...
event_list = self._selector.select(timeout)
self._process_events(event_list)
# Needed to break cycles when an exception occurs.
event_list = None
# Handle 'later' callbacks that are ready.
end_time = self.time() + self._clock_resolution
while self._scheduled:
handle = self._scheduled[0]
if handle._when >= end_time:
break
handle = heapq.heappop(self._scheduled)
handle._scheduled = False
self._ready.append(handle)
# This is the only place where callbacks are actually *called*.
# All other places just add them to ready.
ntodo = len(self._ready)
for i in range(ntodo):
handle = self._ready.popleft()
if handle._cancelled:
continue
if self._debug:
try:
self._current_handle = handle
t0 = self.time()
handle._run()
dt = self.time() - t0
if dt >= self.slow_callback_duration:
logger.warning('Executing %s took %.3f seconds',_format_handle(handle), dt)
finally:
self._current_handle = None
else:
handle._run()
handle = None # Needed to break cycles when an exception occurs.
像netty eventloop一样,可以为eventloop 设置执行器executor,把包含阻塞调用的任务包装成协程。
Asyncio 库同步原语
- asyncio.Lock
- asyncio.Event
- asyncio.Condition
- asyncio.Semaphore
结构化并发
传统asyncio.gather()存在两大痛点:
- 无法动态添加任务。任务列表必须在开始时确定
- 错误处理粗糙。一个任务失败会导致整个任务集取消
import asyncio
async def fetch_data(url):
print(f"开始获取 {url}")
await asyncio.sleep(1)
print(f"完成获取 {url}")
return f"{url}的数据"
async def main():
task1 = asyncio.create_task(fetch_data(" https://api/users "))
task2 = asyncio.create_task(fetch_data(" https://api/products "))
results = await asyncio.gather(task1, task2)
print(f"用户数据: {results[0]}")
print(f"产品数据: {results[1]}")
asyncio.TaskGroup应运而生,提供了更安全、更灵活的并发管理模式:
- 动态添加任务
- 精细错误处理
- 自动资源清理
- 结构化任务管理
async def main():
async with asyncio.TaskGroup() as tg:
task1 = tg.create_task(fetch_data(" https://api/users "))
if should_fetch_more_data(): # 动态任务管理
task2 = tg.create_task(fetch_data(" https://api/products "))
print(f"用户数据: {task1.result()}")
print(f"产品数据: {task2.result()}")
协程上下文
使用 contextvars 管理上下文变量Python 在 3.7 的时候引入了一个模块:contextvars,从名字上很容易看出它指的是上下文变量(Context Variables)。contextvars 的值是绑定在当前协程(Task)的执行上下文(Context)上(后续对 contextvars 的修改只影响当前Task的副本),不是绑定在线程全局,也不是绑定在函数的全局变量上。contextvars = asyncio 下正确处理上下文状态的唯一方式。
先讲下 ThreadLocal,从名字上看可以得出它肯定是和线程相关的。没错,它专门用来创建局部变量,并且创建的局部变量是和线程绑定的。
import threading
# 创建一个 local 对象
local = threading.local()
def get():
name = threading.current_thread().name
# 获取绑定在 local 上的 value
value = local.value
print(f"线程: {name}, value: {value}")
def set_():
name = threading.current_thread().name
# 为不同的线程设置不同的值
if name == "one":
local.value = "ONE"
elif name == "two":
local.value = "TWO"
# 执行 get 函数
get()
t1 = threading.Thread(target=set_, name="one")
t2 = threading.Thread(target=set_, name="two")
t1.start()
t2.start()
"""
线程 one, value: ONE
线程 two, value: TWO
"""
可以看到两个线程之间是互不影响的,因为每个线程都有自己唯一的 id,在绑定值的时候会绑定在当前的线程中,获取也会从当前的线程中获取。可以把 ThreadLocal 想象成一个字典:
{
"thread_id1": {"value": "ONE"},
"thread_id2": {"value": "TWO"}
}
ThreadLocal 就可以理解为是一种上下文,只是 threading.local 是针对线程的。如果是使用 async def 定义的协程该怎么办呢?如何实现每个协程的上下文隔离呢?所以终于引出了我们的主角:contextvars。该模块提供了一组接口,可用于在协程中管理、设置、访问局部 Context 的状态。
ContextVar 提供了两个方法,分别是 get 和 set,用于获取值和设置值。我们看到效果和 ThreadingLocal 类似,数据在协程之间是隔离的,不会受到彼此的影响。和 Go 在 1.7 版本引入的 context 模块比较相似。
import asyncio
import contextvars
c = contextvars.ContextVar("只是一个标识, 用于调试")
async def nested_task():
# 获取值
return c.get() + "~~~"
async def main_task(val):
# 设置值
c.set(val)
ret = await nested_task()
print(ret)
async def main():
coro1 = main_task("协程1")
coro2 = main_task("协程2")
await asyncio.gather(coro1, coro2)
asyncio.run(main())
"""
协程1~~~
协程2~~~
"""
await main_task() 相当于是开启了一个新的协程,那么意味着设置值和获取值不是在同一个协程当中?Python 的协程是无栈协程,通过 await 可以实现级联调用。
当我们调用 c.set 的时候,其实会返回一个 Token 对象:
import contextvars
c = contextvars.ContextVar("context_var")
token = c.set("val")
print(token)
"""
<Token var=<ContextVar name='context_var' at 0x00..> at 0x00...>
"""
Token 对象有一个 var 属性,它是只读的,会返回指向此 token 的 ContextVar 对象。
import contextvars
c = contextvars.ContextVar("context_var")
token = c.set("val")
print(token.var is c) # True
print(token.var.get()) # val
print(
token.var.set("val2").var.set("val3").var is c
) # True
print(c.get()) # val3
Token 对象还有一个 old_value 属性,它会返回上一次 set 设置的值,如果是第一次 set,那么会返回一个 <Token.MISSING>。那么这个 Token 对象有什么作用呢?它最大的用处就是和 reset 搭配使用,可以对状态进行重置。PS: 比如fastapi_sqlalchemy 将db session 对象保存在ContextVar中,api handler开始时存入,api handler 结合时重置。
ContextVar 除了可以作用在协程上面,它也可以用在线程上面,可以替代 threading.local。“绝大多数”情况下,使用 contextvars意味着应该配合上下文管理器一起使用(set+reset)。
应用场景
多线程还是 Asyncio?如果是 I/O bound,并且 I/O 操作很慢,需要很多任务 / 线程协同实现,那么使用 Asyncio 更合适。如果是 I/O bound,但是 I/O 操作很快,只需要有限数量的任务 / 线程,那么使用多线程就可以了。如果是 CPU bound,则需要使用多进程来提高程序运行效率。I/O 操作 heavy 的场景下,Asyncio 比多线程的运行效率更高。因为 Asyncio 内部任务切换的损耗,远比线程切换的损耗要小;并且 Asyncio 可以开启的任务数量,也比多线程中的线程数量多得多。但需要注意的是,很多情况下,使用 Asyncio 需要特定第三方库的支持。
使用 asyncio 并不是将代码转换成多线程,它不会导致多条Python指令同时执行,也不会以任何方式让你避开所谓的全局解释器锁(Global Interpreter Lock,GIL)。有些应用受 IO 速度的限制,即使 CPU 速度再快,也无法充分发挥 CPU 的性能。这些应用花费大量时间从存储或网络设备读写数据,往往需要等待数据到达后才能进行计算,在等待期间,CPU 什么都做不了。asyncio 的目的就是为了给 CPU 安排更多的工作:当前单线程代码正在等待某个事情发生时,另一段代码可以接管并使用 CPU,以充分利用 CPU 的计算性能。asyncio 更多是关于更有效地使用单核,而不是如何使用多核。python协程单线程内切换,适用于IO密集型程序中,可以最大化IO多路复用的效果。协程间完全同步,不会并行,不需要考虑数据安全。PS:与Go协程不同的地方。
其它
# 同步函数,同步函数本身是一个 Callable 对象,调用这个函数的时候,函数体内的代码被执行。
def function():
return 1
# 生成器函数
def generator():
yield 1
# 异步函数,也是一个 Callable 对象实例,调用这个函数的时候,函数体内的代码不会被执行。相反,Python 创建了一个 Coroutine 对象实例,并将其分配给返回值。
async def async_function():
# 当 time.sleep() 被调用,整个程序都会暂停,什么都做不了。asyncio.sleep()是异步的,或者说是非阻塞的。
await asyncio.sleep(3)
return 1
# 异步生成器,调用方一般await for 生成器
async def async_generator():
yield 1
print(async_function())
# <coroutine object async_function at 0x102ff67d8>
- async with 可以处理实现了
__aenter__和__aexit__方法的对象,二者返回可异步调用对象,通常是协程对象。__enter__和__exit__两个方法都是不支持await调用的,为了解决这个问题,Python引入了async with语法。
- async for 可以处理实现了
__aiter__方法的异步可迭代对象,返回异步迭代器。异步迭代器提供__anext__协程方法,返回一个可异步调用对象,通常是协程对象。 - 若想实现 异步迭代器,可以编写一个类,实现
__anext__和__aiter__,不过还有更简单的方法:以async def 声明一个函数,在主体使用yield。 PS:从调用方视角看,async def 一旦具备 yield,其「Generator 特性」在语义和用法上完全压过 「协程特性」。
留下评论