pv与pvc实现
简介
- 简介
- 为何引入PV、PVC以及StorageClass?——远程存储访问优化
- Persistent Volume(PV)和 Persistent Volume Claim(PVC)
- K8s 持久化存储流程
- Storage Classes——自动创建pv
- volume 插件设计
- ConfigMap
与CPU 和 Mem 这些资源相比,“存储”对k8s 来说更像是“外设”,k8s 提供统一的“总线”接入。Kata Containers 创始人带你入门安全容器技术OCI规范规定了容器之中应用被放到什么样的环境下、如何运行,比如说容器的根文件系统上哪个可执行文件会被执行,是用什么用户执行,需要什么样的 CPU,有什么样的内存资源、外置存储,还有什么样的共享需求等等。
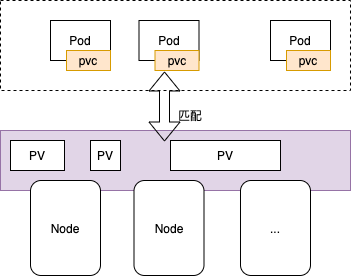
为何引入PV、PVC以及StorageClass?——远程存储访问优化
容器中的文件在磁盘上是临时存放的,这给容器中运行的特殊应用程序带来一些问题。首先,当容器崩溃时,kubectl 将重新启动容器,容器中的文件将会丢失。其次,当在一个 Pod 中同时运行多个容器时,常常需要在这些容器之间共享文件。Kubernetes 抽象出 Volume 对象来解决这两个问题。但是,当一个 Pod 不再存在时,Volume 也将不再存在。因此,Kubernetes 引入了 Persistent Volumes (PV)。PV 是集群中一块已经由管理员配置或使用 StorageClass 动态配置的存储。
Kubernetes云原生开源分布式存储介绍早期Pod使用Volume的写法
apiVersion: v1
kind: Pod
metadata:
labels:
role: web-frontend
spec:
containers:
- name: web
image: nginx
ports:
- name: web
containerPort: 80
volumeMounts:
- name: ceph
mountPath: "/usr/share/nginx/html"
volumes:
- name: ceph
capacity:
storage: 10Gi
cephfs:
monitors:
- 172.16.0.1:6789
- 172.16.0.2:6789
- 172.16.0.3:6789
path: /ceph
user: admin
secretRef:
name: ceph-secret
这种方式至少存在两个问题:
- Pod声明与底层存储耦合在一起,每次声明Volume都需要配置存储类型以及该存储插件的一堆配置,如果是第三方存储,配置会非常复杂。
- 开发人员的需求可能只是需要一个20GB的卷,这种方式却不得不强制要求开发人员了解底层存储类型和配置。
于是引入了PV(Persistent Volume),PV其实就是把Volume的配置声明部分从Pod中分离出来,PV的spec部分几乎和前面Pod的Volume定义部分是一样的由运维人员事先创建在 Kubernetes 集群里待用
apiVersion: v1
kind: PersistentVolume
metadata:
name: cephfs-pv
spec:
capacity:
storage: 10Gi
cephfs:
monitors:
- 172.16.0.1:6789
- 172.16.0.2:6789
- 172.16.0.3:6789
path: /ceph_storage
user: admin
secretRef:
name: ceph-secret
有了PV,在Pod中就可以不用再定义Volume的配置了,直接引用即可。但是这没有解决Volume定义的第二个问题,存储系统通常由运维人员管理,开发人员并不知道底层存储配置,也就很难去定义好PV。为了解决这个问题,引入了PVC(Persistent Volume Claim),声明与消费分离,开发与运维责任分离。
kind:PersistentVolumeClaim
apiVersion:v1
metadata:
name: cephfs-pvc
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 8Gi
通过 kubectl get pv 命令可看到 PV 和 PVC 的绑定情况
apiVersion: v1
kind: Pod
metadata:
labels:
role: web-frontend
spec:
containers:
- name: web
image: nginx
ports:
- name: web
containerPort: 80
volumeMounts:
- name: cephfs-volume
mountPath: "/usr/share/nginx/html"
volumes:
- name: cephfs-volume
persistentVolumeClaim:
claimName: cephfs-pvc
运维人员负责存储管理,可以事先根据存储配置定义好PV,而开发人员无需了解底层存储配置,只需要通过PVC声明需要的存储类型、大小、访问模式等需求即可,然后就可以在Pod中引用PVC,完全不用关心底层存储细节。
PS:感觉上,在Pod的早期,以Pod 为核心,Pod 运行所需的资源都定义在Pod yaml 中,导致Pod 越来越臃肿。后来,Kubernetes 集群中出现了一些 与Pod 生命周期不一致的资源,并单独管理。 Pod 与他们 更多是引用关系, 而不是共生 关系了。
Persistent Volume(PV)和 Persistent Volume Claim(PVC)
PVC 和 PV 的设计,其实跟“面向对象”的思想完全一致。PVC 可以理解为持久化存储的“接口”,它提供了对某种持久化存储的描述,但不提供具体的实现;而这个持久化存储的实现部分则由 PV 负责完成。这样做的好处是,作为应用开发者,我们只需要跟 PVC 这个“接口”打交道,而不必关心具体的实现是 NFS 还是 Ceph
pv
创建方式
- 集群管理员通过手动方式静态创建应用所需要的 PV;
- 用户手动创建 PVC 并由 External Provisioner 组件动态创建对应的 PV。
pv accessModes:支持三种类型
- ReadWriteMany 多路读写,卷能被集群多个节点挂载并读写
- ReadWriteOnce 单路读写,卷只能被单一集群节点挂载读写
- ReadOnlyMany 多路只读,卷能被多个集群节点挂载且只能读
pv ReclaimPolicy 当与之关联的PVC被删除以后,这个PV中的数据如何被处理
- Retain 当删除与之绑定的PVC时候,这个PV被标记为released(PVC与PV解绑但还没有执行回收策略)且之前的数据依然保存在该PV上,但是该PV不可用,需要手动来处理这些数据并删除该PV。
- Delete 待补充
pv&pvc绑定
PVC、PV 的一些属性:
- PVC 和 PV 总是成对出现的,PVC 必须与 PV 绑定后才能被应用(Pod)消费;
- PVC 和 PV 是一一绑定关系,不存在一个 PV 被多个 PVC 绑定,或者一个 PVC 绑定多个 PV 的情况;
- 消费关系上:Pod 消费 PVC,PVC 消费 PV,而 PV 定义了具体的存储介质。
这个PVC就会和上面的PV进行绑定,为什么呢?它有一些原则。PS: 有点 为pod 找到能够运行的node 的意思
- PV和pvc中的spec关键字段要匹配,比如存储(storage)大小。
- pv和pvc中的storageClassName字段必须一致
- 当pv的容量大于pvc的需求时,pvc可以成功自动绑定pv;
- 当pv的容量小于pvc的需求时,pvc无法绑定该pv;
- pv和pvc的绑定关系是一一对应的.
- pv/pvc的创建顺序是:pv -> pvc -> pod
- pv/pvc的销毁顺序是:pod -> pvc -> pv,顺序一定不要错
K8s 持久化存储流程
详解 Kubernetes Volume 的实现原理集群中的每一个卷在被 Pod 使用时都会经历四个操作,也就是附着(Attach)、挂载(Mount)、卸载(Unmount)和分离(Detach)。如果 Pod 中使用的是 EmptyDir、HostPath 这种类型的卷,那么这些卷并不会经历附着和分离的操作,它们只会被挂载和卸载到某一个的 Pod 中。
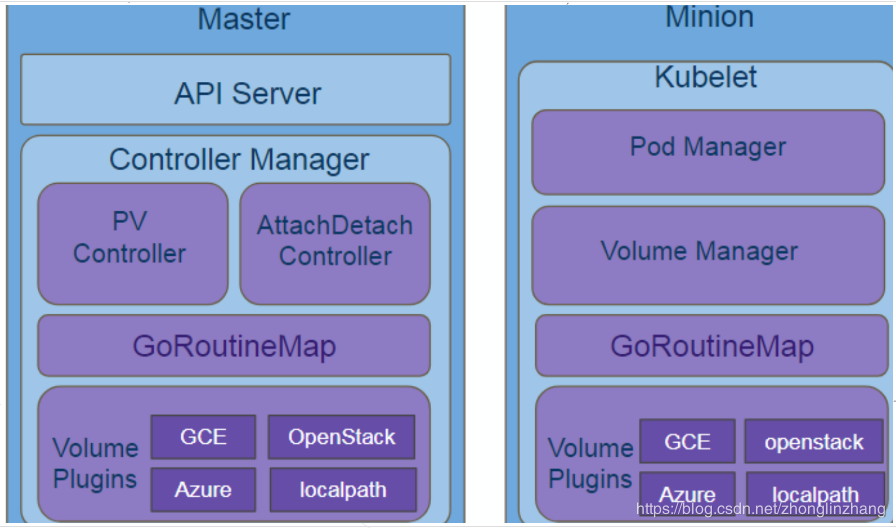
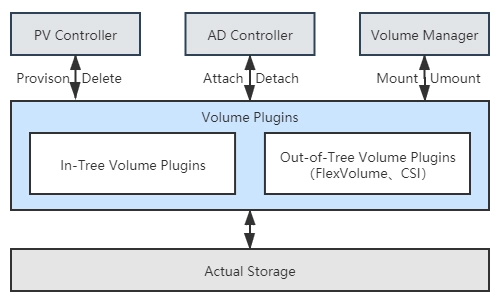
Volume 的创建和管理在 Kubernetes 中主要由卷管理器 VolumeManager 和 AttachDetachController 和 PVController 三个组件负责。
- VolumeManager 在 Kubernetes 集群中的每一个节点(Node)上的 kubelet 启动时都会运行一个 VolumeManager Goroutine,它会负责在当前节点上的 Pod 和 Volume 发生变动时对 Volume 进行挂载和卸载等操作。
- AttachDetachController 主要负责对集群中的卷进行 Attach 和 Detach
- 让卷的挂载和卸载能够与节点的可用性脱离;一旦节点或者 kubelet 宕机,附着(Attach)在当前节点上的卷应该能够被分离(Detach),分离之后的卷就能够再次附着到其他节点上;
- 保证云服务商秘钥的安全;如果每一个 kubelet 都需要触发卷的附着和分离逻辑,那么每一个节点都应该有操作卷的权限,但是这些权限应该只由主节点掌握,这样能够降低秘钥泄露的风险;
- 提高卷附着和分离部分代码的稳定性;
- PVController 负责处理持久卷的变更。 一文读懂 K8s 持久化存储流程
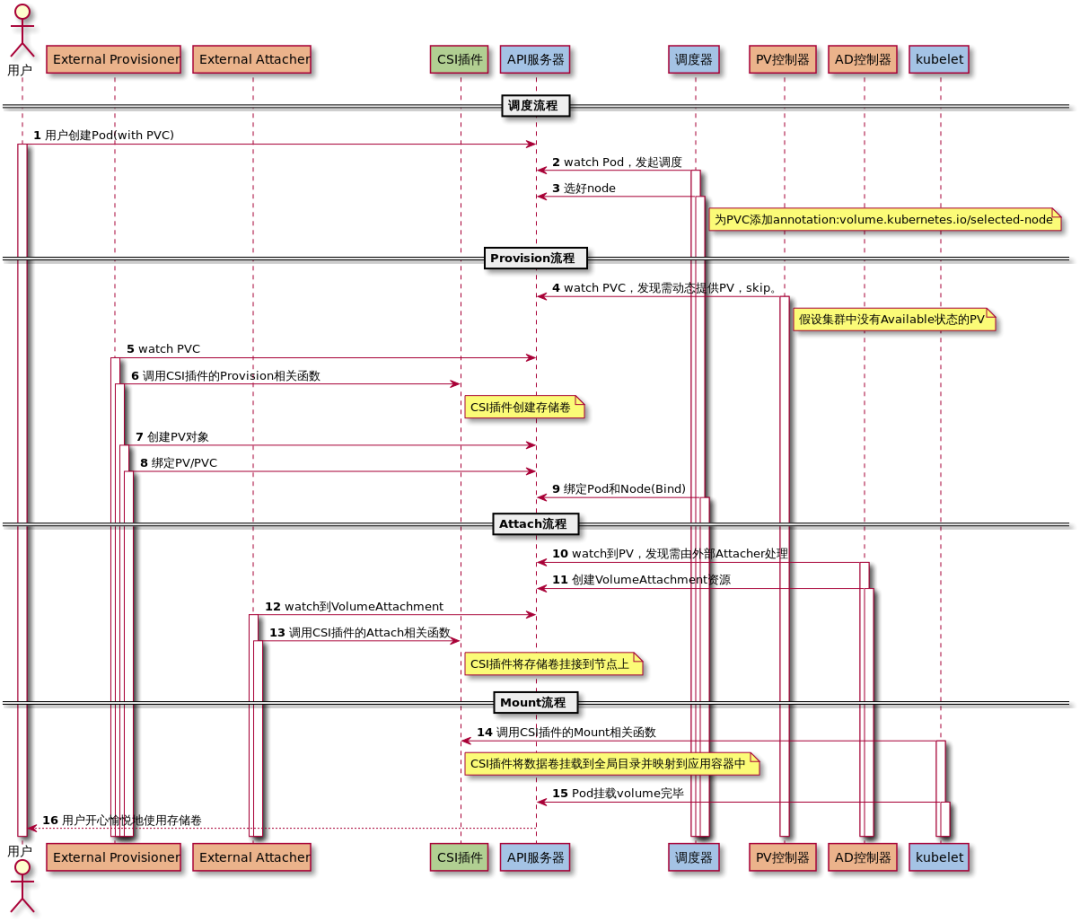
流程如下(本质还是先将nfs mount到本地):
- 用户创建了一个包含 PVC 的 Pod,该 PVC 要求使用动态存储卷;
- Scheduler 根据 Pod 配置、节点状态、PV 配置等信息,把 Pod 调度到一个合适的 Worker 节点上;
- PV 控制器 watch 到该 Pod 使用的 PVC 处于 Pending 状态,于是调用 Volume Plugin(in-tree)创建存储卷,并创建 PV 对象(out-of-tree 由 External Provisioner 来处理);
- AD 控制器发现 Pod 和 PVC 处于待挂接状态,于是调用 Volume Plugin 挂接存储设备到目标 Worker 节点上
- 在 Worker 节点上,Kubelet 中的 Volume Manager 等待存储设备挂接完成,并通过 Volume Plugin 将设备挂载到全局目录:
/var/lib/kubelet/pods/[pod uid]/volumes/kubernetes.io~iscsi/[PV name](以 iscsi 为例);PS:本质还是一个host目录 - Kubelet 通过 Docker 启动 Pod 的 Containers,用 bind mount 方式将已挂载到本地全局目录的卷映射到容器中。
在 Kubernetes 中,实际上存在着一个专门处理持久化存储的控制器,叫作 Volume Controller。这个Volume Controller 维护着多个控制循环,其中有一个循环,扮演的就是撮合 PV 和 PVC 的“红娘”的角色。它的名字叫作 PersistentVolumeController
Kubernetes 中 PV 和 PVC 的状态变化 |操作| PV 状态| PVC 状态| |—|—|—| |创建 PV| Available| -| |创建 PVC| Available| Pending| || Bound| Bound| |删除 PV| -/Terminating| Lost/Bound| |重新创建 PV| Bound| Bound| |删除 PVC| Released| -| |后端存储不可用| Failed| -| |删除 PV 的 claimRef| Available| -|
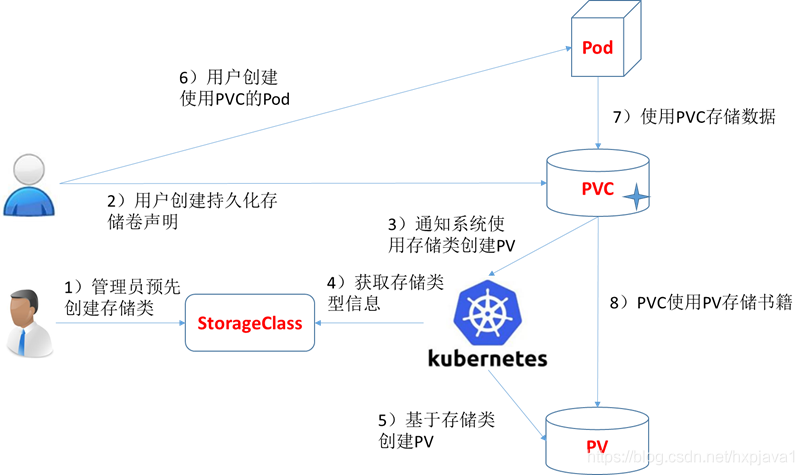
Storage Classes——自动创建pv
k8s PV、PVC、StorageClass 的关系前面我们人工管理 PV 的方式就叫作 Static Provisioning。一个大规模的 Kubernetes 集群里很可能有成千上万个 PVC,这就意味着运维人员必须得事先创建出成千上万个 PV。更麻烦的是,随着新的 PVC 不断被提交,运维人员就不得不继续添加新的、能满足条件的 PV,否则新的 Pod 就会因为 PVC 绑定不到 PV 而失败。在实际操作中,这几乎没办法靠人工做到。所以,Kubernetes 为我们提供了一套可以自动创建 PV 的机制,即:Dynamic Provisioning。
举一个需求的例子:对于分布式机器学习训练任务,由多个worker/pod组成,worker 之间需要共享读写一些文件,且训练任务完成后文件就没用了,此时每个训练任务都需要一个pv,这就到导致无法预先创建好所有的pv(因为任务是算法人员提交才创建的)。
Kubernetes Storage Classes动态存储卷供应使用StorageClass进行实现,其允许pv按需被创建。如果没有动态存储供应,Kubernetes集群的管理员将不得不通过手工的方式类创建新的pv。
- 回收策略,reclaimPolicy: Delete 或者 Retain
- 允许卷扩展,此功能设置为 true 时,允许用户通过编辑相应的 PVC 对象来调整卷大小。
- 挂载选项,mountOptions
- 卷绑定模式
- 允许的拓扑结构
volume 插件设计

ConfigMap
- ConfigMap 资源用来保存key-value配置数据,这个数据可以在pods里使用,或者被用来为像controller一样的系统组件存储配置数据。
- yaml data 包括了配置数据,ConfigMap中的每个data项都会成为一个新文件。每个data 项可以用来保存单个属性,也可以用来保存一个配置文件。
apiVersion: v1
kind: ConfigMap
metadata:
name: special-config
namespace: default
data:
SPECIAL_LEVEL: very
SPECIAL_TYPE: charm
demo.yaml: |
abc: 123
edf: 456
---
apiVersion: apps/v1
kind: Deployment
spec:
...
replicas: 1
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
...
volumeMounts:
- name: config-volume
mountPath: /etc/config
volumes:
- name: config-volume
configMap:
name: special-config
查看执行结果
root@nginx-deployment-6576c57d87-4vmk4:/etc/config# ls -al
total 12
drwxrwxrwx 3 root root 4096 Nov 9 06:06 .
drwxr-xr-x 1 root root 4096 Nov 9 04:00 ..
drwxr-xr-x 2 root root 4096 Nov 9 06:06 ..2020_11_09_06_06_22.828693221
lrwxrwxrwx 1 root root 31 Nov 9 06:06 ..data -> ..2020_11_09_06_06_22.828693221
lrwxrwxrwx 1 root root 20 Nov 9 03:56 SPECIAL_LEVEL -> ..data/SPECIAL_LEVEL
lrwxrwxrwx 1 root root 19 Nov 9 03:56 SPECIAL_TYPE -> ..data/SPECIAL_TYPE
lrwxrwxrwx 1 root root 16 Nov 9 06:06 demo.yaml -> ..data/demo.yaml
留下评论