golang io使用及优化模式
前言
net 库要考虑的几个问题
- io 模型,一般是nio/epoll。ET 还是LT 触发?
- 线程模型,一个con 一个goroutine 还是其它?
- 内存管理/ buffer 设计
业务层一般处理逻辑
tcp 代码示例
func handleConn(c net.Conn) {
defer c.Close()
for {
// read from the connection
// ... ...
// write to the connection
//... ...
}
}
func main() {
l, err := net.Listen("tcp", ":8888")
if err != nil {
fmt.Println("listen error:", err)
return
}
for {
c, err := l.Accept()
if err != nil {
fmt.Println("accept error:", err)
break
}
// start a new goroutine to handle
// the new connection.
go handleConn(c)
}
}
TCP 连接上的数据是一个没有边界的字节流,但在业务层眼中,没有字节流,只有各种协议消息。因此,无论是从客户端到服务端,还是从服务端到客户端,业务层在连接上看到的都应该是一个挨着一个的协议消息流。
对应到 代码上就是对 handleConn 进一步抽象/逻辑拆分,将业务逻辑转化到 handlePacket 上。handleConn 和 handlePacket 可以进一步拆分为 “粘包”(Frame) 和 “序列化”(Packet)两个部分
// handleConn的调用结构
read frame from conn
->frame decode
-> handle packet
-> packet decode
-> packet(ack) encode
->frame(ack) encode
write ack frame to conn
这个层次就很清晰了,复杂逻辑/需求逐层分解,也为分析类似 代码提供了分析的切入点(结构化思维)不会被带到细节里面去。
type Packet interface {
Decode(io.Reader)(Packet,error)
Encode(io.Writer,Packet) error
}
func handleConn(c net.Conn) {
defer c.Close()
packet = new ...
for {
// read from the connection
packet, err := Decode(c)
ackPacket, err := handlePacket(packet)
// write to the connection
err := Encode(c,ackPacket)
}
}
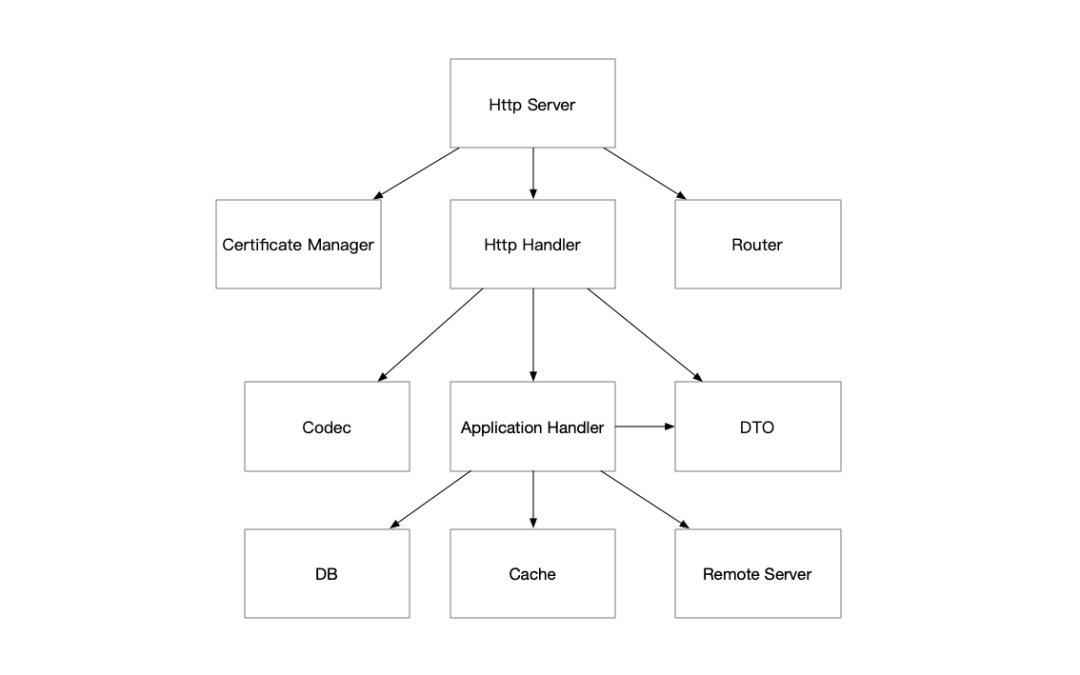
各个场景下的代码示例
http 代码示例
func helloHandler(w http.ResponseWriter, req *http.Request) {
io.WriteString(w, "hello, world!\n")
}
func main() {
http.HandleFunc("/", helloHandler)
http.ListenAndServe(":12345", nil)
}
两个大循环。PS:有点netty bossGroup 和workGroup的感觉了。
- 处理连接:http.ListenAndServe ==> server.ListenAndServe ==> rw := l.Accept(); c := srv.newConn(rw) ==> go c.serve(connCtx)。 一个 for 循环里面在不停地 Accept,这个 Accept 在没有连接时是阻塞的,当有连接时,起一个新的协程来处理。
- 处理请求:conn.serve ==> c.readRequest; DefaultServeMux.ServeHTTP; w.finishRequest() 。 也是一个for循环,循环里面主要是读取一个请求,然后将请求交给 Handler 处理。因为每个 serve 处理的是一个连接,一个连接可以有多次请求。
// src/net/http/server.go
// 封装 bind、listen、accept
func ListenAndServe(addr string, handler Handler) error {
server := &Server{Addr: addr, Handler: handler}
return server.ListenAndServe()
}
func (srv *Server) ListenAndServe() error {
if srv.shuttingDown() {
return ErrServerClosed
}
addr := srv.Addr
if addr == "" {
addr = ":http"
}
ln, err := net.Listen("tcp", addr)
return srv.Serve(ln)
}
func (srv *Server) Serve(l net.Listener) error {
origListener := l
l = &onceCloseListener{Listener: l}
defer l.Close()
if err := srv.setupHTTP2_Serve(); err != nil {
return err
}
ctx := context.WithValue(baseCtx, ServerContextKey, srv)
for {
rw, err := l.Accept() // 接收客户端请求
c := srv.newConn(rw) // 创建一个新的连接
go c.serve(connCtx) // 起一个goroutine处理客户端请求
}
}
// src/net/http/server.go
func (c *conn) serve(ctx context.Context) {
// HTTP/1.x from here on.
c.r = &connReader{conn: c}
c.bufr = newBufioReader(c.r)
c.bufw = newBufioWriterSize(checkConnErrorWriter{c}, 4<<10)
for {
// 读取一个请求,然后将请求交给 Handler 处理
w, err := c.readRequest(ctx) // 从连接中获取HTTP请求并构建一个 http.response
serverHandler{c.server}.ServeHTTP(w, w.req) // 处理请求
w.finishRequest()
}
}
func (sh serverHandler) ServeHTTP(rw ResponseWriter, req *Request) {
handler := sh.srv.Handler
if handler == nil {
handler = DefaultServeMux
}
handler.ServeHTTP(rw, req)
}
请求如何路由?注册处理器
- HandleFunc 将
<pattern,handler>注册到 Mutex 中 - ServeHTTP 负责 从Mutex 拿到url 匹配的handler 并调用执行
使用map进行存储,本质是一个静态索引,同时维护了一个切片,用来做前缀匹配,只要以/结尾的,都会在切片中存储。
// src/net/http/server.go
func HandleFunc(pattern string, handler func(ResponseWriter, *Request)) {
DefaultServeMux.HandleFunc(pattern, handler)
}
type ServeMux struct {
mu sync.RWMutex
m map[string]muxEntry
es []muxEntry // slice of entries sorted from longest to shortest.
hosts bool // whether any patterns contain hostnames
}
func (mux *ServeMux) HandleFunc(pattern string, handler func(ResponseWriter, *Request)) {
if handler == nil {
panic("http: nil handler")
}
mux.Handle(pattern, HandlerFunc(handler))
}
func (mux *ServeMux) ServeHTTP(w ResponseWriter, r *Request) {
if r.RequestURI == "*" {
if r.ProtoAtLeast(1, 1) {
w.Header().Set("Connection", "close")
}
w.WriteHeader(StatusBadRequest)
return
}
h, _ := mux.Handler(r) // 进行路由匹配,获取注册的处理函数
h.ServeHTTP(w, r) // 这块就是执行我们注册的handler
}
服务端监听端口本质也是使用net网络库进行TCP连接,然后监听对应的TCP连接,每一个HTTP请求都会开一个goroutine去处理请求。所以如果有海量请求,会在一瞬间创建大量的goroutine,这个可能是一个性能瓶颈点。
这在java 里就是一整个tomcat干的活儿了。
grpc 代码示例
demo helloworld helloworld.proto helloworld.pb.go ## 基于helloworld.proto 生成 server main.go client main.go
服务端main.go 示例
package main
const (
port = ":50051"
)
// server is used to implement helloworld.GreeterServer.
type server struct{}
// SayHello implements helloworld.GreeterServer
func (s *server) SayHello(ctx context.Context, in *pb.HelloRequest) (*pb.HelloReply, error) {
log.Printf("Received: %v", in.Name)
return &pb.HelloReply{Message: "Hello " + in.Name}, nil
}
func main() {
lis, err := net.Listen("tcp", port)
if err != nil {
log.Fatalf("failed to listen: %v", err)
}
s := grpc.NewServer()
helloworld.RegisterGreeterServer(s, &server{})
if err := s.Serve(lis); err != nil {
log.Fatalf("failed to serve: %v", err)
}
}
helloworld.pb.go 中定义了RegisterGreeterServer 方法,除传入grpc.Server外,第二个参数是定义好的 GreeterServer interface。 由此可见,grpc 与java thrift 异曲同工
- 定义thrift 文件
- thrift 命令基于thrift 文件生成 对应语言的 代码文件,包含了服务 接口
- 开发者提供 接口实现类
上层封装——以getty 为例
Go 语言网络库 getty 的那些事 对go netpoller 的信心:Getty 只考虑使用 Go 语言原生的网络接口,如果遇到网络性能瓶颈也只会在自身层面寻找优化突破点。
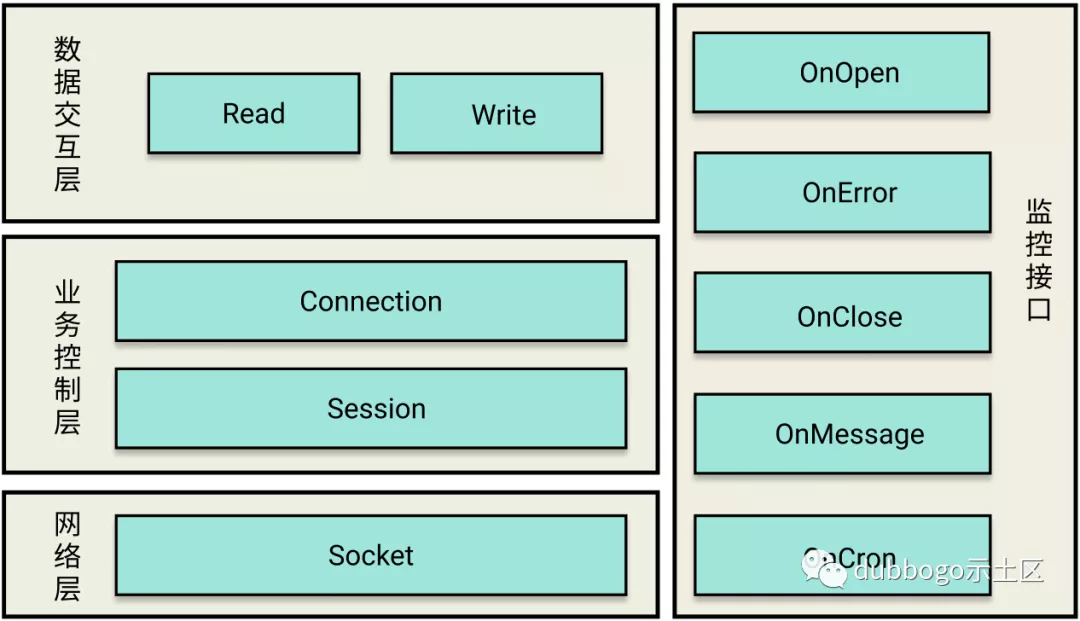
go 通过netpoller 可以在保持异步化运行机制的同时,用同步方式写代码(goroutine-per-connection)。但毕竟代码拿到的还 是字节流,对于上层业务处理 编码工作量仍然非常大,于是 就像netty 之于java 一样 国内大佬 开发了 getty。Getty 严格遵循着分层设计的原则,主要分为数据交互层、业务控制层、网络层,同时还提供非常易于扩展的监控接口。 无论是基于getty 开发上层服务 还是 学习getty 之后再去 学习类似mosn/dubbo-go 等 都会大大降低 心智负担。
Go 语言网络库 getty 的那些事 后续性能优化部分未细读
分层
| 分层 | 接口 | 用户需要做的工作 |
|---|---|---|
| EventListener/业务处理 | onOpen/onError/onClose/onMessage/onCron | 在onMessage 中写入业务逻辑 |
| 数据交互层/编解码 | ReadWriter | 机型byte[] 和 Message 的转换 |
| 业务控制层 | Connection/Session | |
| 网络层 | Socket |
In getty there are two goroutines in one connection(session), one reads tcp stream/udp packet/websocket package, the other handles logic process and writes response into network write buffer. If your logic process may take a long time, you should start a new logic process goroutine by yourself in codec.go:(Codec)OnMessage.
// Reader is used to unmarshal a complete pkg from buffer
type Reader interface {
// Read Parse tcp/udp/websocket pkg from buffer and if possible return a complete pkg.
// When receiving a tcp network streaming segment, there are 4 cases as following:
// case 1: a error found in the streaming segment;
// case 2: can not unmarshal a pkg header from the streaming segment;
// case 3: unmarshal a pkg header but can not unmarshal a pkg from the streaming segment;
// case 4: just unmarshal a pkg from the streaming segment;
// case 5: unmarshal more than one pkg from the streaming segment;
//
// The return value is (nil, 0, error) as case 1.
// The return value is (nil, 0, nil) as case 2.
// The return value is (nil, pkgLen, nil) as case 3.
// The return value is (pkg, pkgLen, nil) as case 4.
// The handleTcpPackage may invoke func Read many times as case 5.
Read(Session, []byte) (interface{}, int, error)
}
// Writer is used to marshal pkg and write to session
type Writer interface {
// Write if @Session is udpGettySession, the second parameter is UDPContext.
Write(Session, interface{}) ([]byte, error)
}
// ReadWriter interface use for handle application packages
type ReadWriter interface {
Reader
Writer
}
见过的最好的协议层定义:ReadWriter 接口定义代码如上。Read 接口之所以有三个返回值,是为了处理 TCP 流粘包情况:
- 如果发生了网络流错误,如协议格式错误,返回 (nil, 0, error)
- 如果读到的流很短,其头部 (header) 都无法解析出来,则返回 (nil, 0, nil)
- 如果读到的流很短,可以解析出其头部 (header) 但无法解析出整个包 (package),则返回 (nil, pkgLen, nil)
- 如果能够解析出一个完整的包 (package),则返回 (pkg, 0, error)
session 负责客户端的一次连接建立的管理,会持有buffer、channel 等用于 工作流中 数据暂存、协程间沟通. session 的listen、accept方法返回值 都赋值给session 自己的成员,“自产自销”。
- 向下 Session 对 Go 内置的网络库做了完善的封装,包括对 net.Conn 的数据流读写、超时机制等。
- 向上,Session 提供了业务可切入的接口,用户只需实现 EventListener 就可以将 Getty 接入到自己的业务逻辑中。
Connection 根据不同的通信模式对 Go 内置网络库进行了抽象封装,Connection 分别有三种实现gettyTCPConn/gettyUDPConn/gettyWSConn。 PS Session Interface 和 session struct 都聚合了Connection,屏蔽不同的传输层差异, 可能是Connection 和 Session 拆开的原因。
启动流程
在 Getty 中,server 服务的启动流程
server := getty.NewTCPServer(options...)
server.RunEventLoop(newSession NewSessionCallback)
// type NewSessionCallback func(Session) error
// 用户需要通过该函数,为 session 设置好要用的 Reader、Writer 以及 EventListener。
func newSession(session getty.Session) error {
...
session.SetPkgHandler(echoPkgHandler) // 在 echoPkgHandler 中实现编解码
session.SetEventListener(echoMsgHandler) // 在onMessage 中实现业务逻辑
ession.SetReadTimeout(conf.GettySessionParam.tcpReadTimeout)
session.SetWriteTimeout(conf.GettySessionParam.tcpWriteTimeout)
...
}
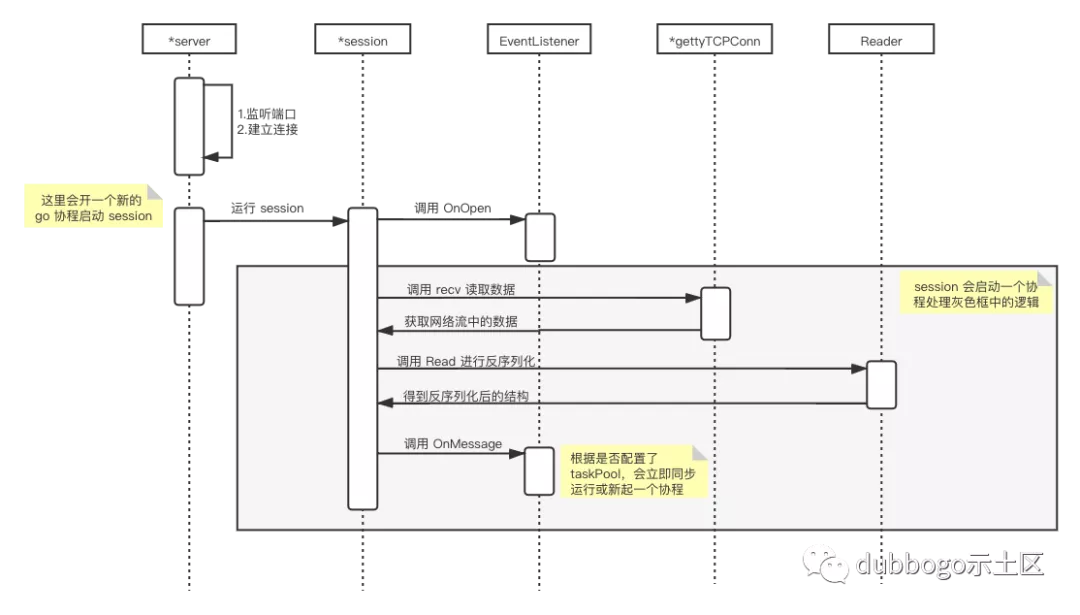
数据读取
RunEventLoop.RunEventLoop 收到新的连接 session 即执行 session.run
- 处理byte[]: session.handlePackage ==> session.handleTCPPackage
- 处理协议消息: reader.Read 得到pkg ==> session.addTask ==> session.listener.OnMessage
// github.com/AlexStocks/getty/transport/server.go
func (s *server) RunEventLoop(newSession NewSessionCallback) {
err := s.listen() // ==> server.listenTCP ==> server.streamListener = net.Listen("tcp", server.addr) 开启监听
switch s.endPointType {
case TCP_SERVER:
s.runTcpEventLoop(newSession)
...
}
}
func (s *server) runTcpEventLoop(newSession NewSessionCallback) {
s.wg.Add(1)
go func() {
defer s.wg.Done()
for {
client, err = s.accept(newSession) // conn = server.streamListener.Accept(); session := newTCPSession(conn, server)
client.(*session).run()
}
}()
}
// github.com/AlexStocks/getty/transport/session.go
func (s *session) run() {
err := s.listener.OnOpen(s)
go s.handleLoop() // 发送网络字节流、调用 EventListener.OnCron() 执行定时逻辑
go s.handlePackage() // 读取字节数据,转为message,移交给 Goroutine Pool 处理业务逻辑
}
读取数据
func (s *session) handlePackage() {
...
err = s.handleTCPPackage()
...
}
func (s *session) handleTCPPackage() error {
conn = s.Connection.(*gettyTCPConn)
for {
bufLen, err = conn.recv(buf)
pktBuf.Write(buf[:bufLen])
for {
pkg, pkgLen, err = s.reader.Read(s, pktBuf.Bytes()) // 将字节流转为pkg
...
s.addTask(pkg) // 交给业务逻辑处理
pktBuf.Next(pkgLen)
}
}
return perrors.WithStack(err)
}
func (s *session) addTask(pkg interface{}) {
f := func() {
s.listener.OnMessage(s, pkg)
s.incReadPkgNum()
}
if taskPool := s.EndPoint().GetTaskPool(); taskPool != nil { // 交给协程池执行
taskPool.AddTask(f)
return
}
f() // 直接执行
}
发送数据
发送网络字节流、调用 EventListener.OnCron() 执行定时逻辑
func (s *session) handleLoop() {
for {
select {
case <-s.done: ...
case outPkg, ok = <-s.wQ:
iovec = iovec[:0]
for idx := 0; idx < maxIovecNum; idx++ {
pkgBytes, err = s.writer.Write(s, outPkg) // 编码
iovec = append(iovec, pkgBytes)
}
err = s.WriteBytesArray(iovec[:]...)
case <-wheel.After(s.period):
if flag {
s.listener.OnCron(s)
}
}
}
}
cloudwego/netpoll
cloudwego/netpoll 认为 One Conn One Goroutine 有很大问题,大量的goroutine 上下文切换成本高,net.Conn 没有check alive的api 导致go 连接池 问题也比较多。
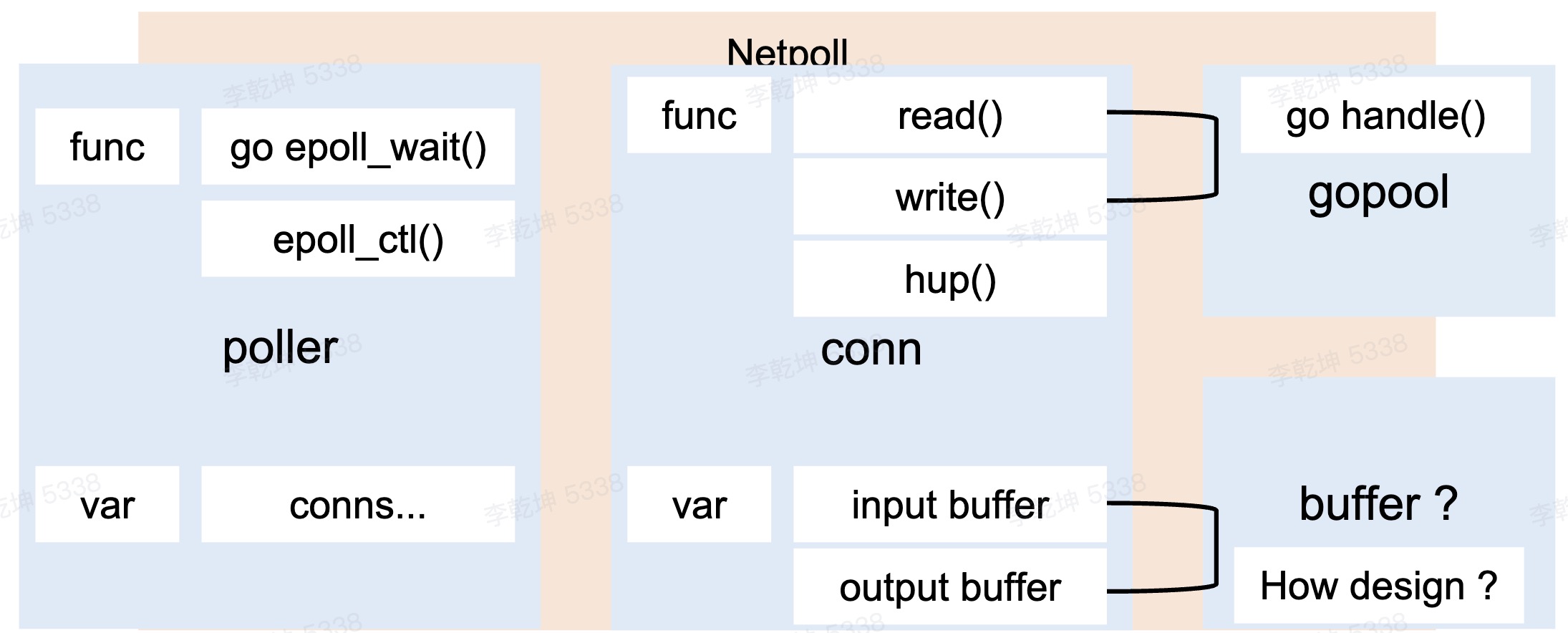
go func(){
events := make([]event,128)
for {
n,_ := epoll_wait(epoll_fd,events,wait_msec)
for i:=0;i<n; i++{
read()/write()/catch(error) // 这些方法放在哪里呢?因为都是操作连接的,所以直接抽象一个conn 实现这三个方法
}
}
}
常见优化
带缓存的网络 I/O
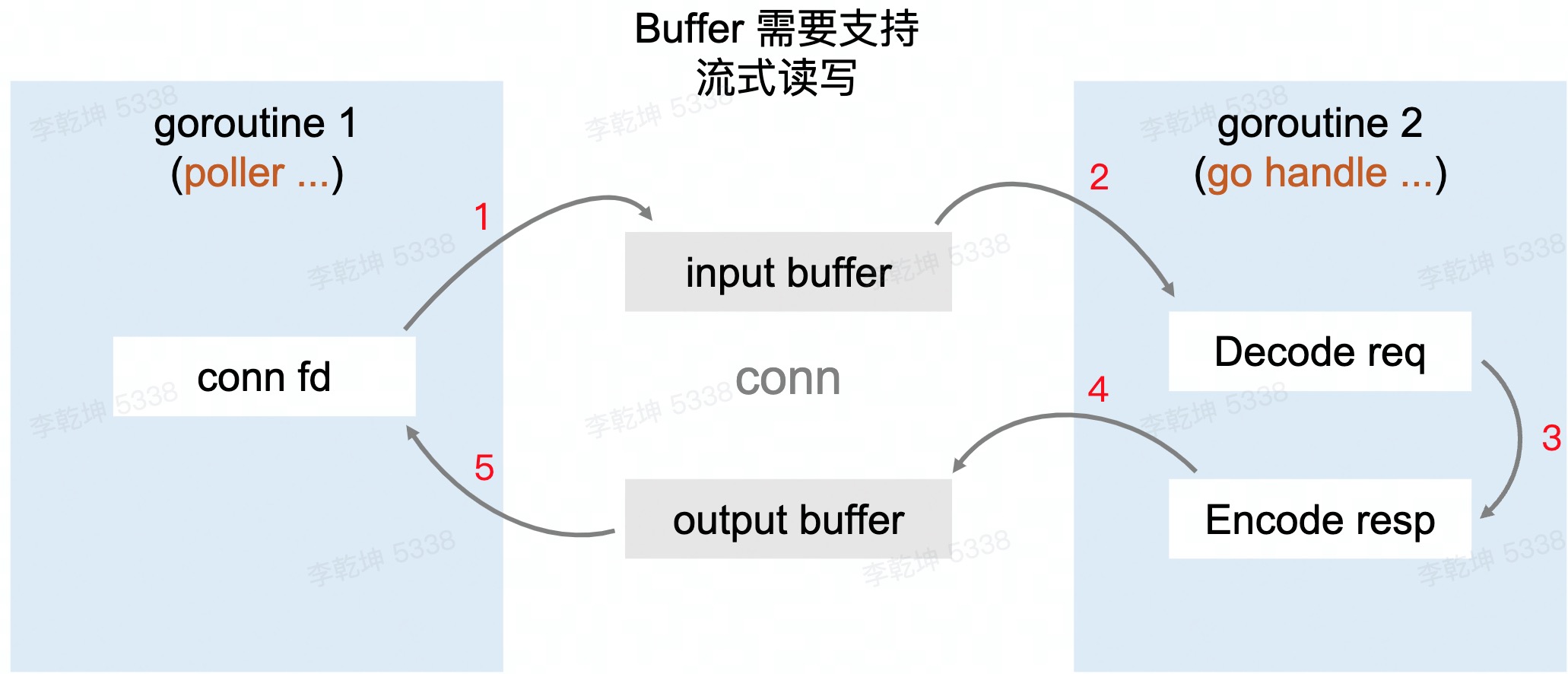
每次从 net.Conn 尝试读取其内部缓存大小的数据,而不是用户传入的希望读取的数据大小。这些数据缓存在内存中,这样,后续的 Read 就可以直接从内存中得到数据,而不是每次都要从 net.Conn 读取,从而降低 Syscall 调用的频率。 有一个 生产-消费 []byte 过程:netpoller 协程 从connection/socket 读[]byte 到buffer,业务协程 从buffer 中读取[]byte decode 处理。这个“队列” 如何实现?
RingBuffer 天然合适,但是RingBuffer 存满后需要扩容,扩容需要copy,copy 会造成data race(read/write 指针不能碰面)。再进一步,如何实现一个无锁的ring buffer?使用链表解决扩容问题;使用sync.Pool 复用链表节点;维护一个length字段,通过atomic 避免data race。
重用内存对象
go tool pprof 可以观测占用内存最多的函数 和 代码(哪一行)。比如 每次服务端收到一个客户端 submit 请求时,都会在堆上分配一块内存表示 Submit 类型的实例
s := Submit{}
// 改为
var SubmitPool = sync.Pool{
New: func() interface{} {
return &Submit{}
},
}
s := SubmitPool.Get().(*Submit) // 从SubmitPool池中获取一个Submit内存对象
...
SubmitPool.Put(submit) // 将submit对象归还给Pool池
留下评论