Storm 学习
前言
像上海这样的一线城市,公共场所的摄像头规模在数百万级,即使只有重要场所的视频数据需要即时处理,可能也会涉及几十万个摄像头,如果想实时发现视频中出现的通缉犯或者违章车辆,就需要对这些摄像头产生的数据进行实时处理。实时处理最大的不同就是这类数据跟存储在 HDFS 上的数据不同,是实时传输过来的,或者形象地说是流过来的,所以针对这类大数据的实时处理系统也叫大数据流计算系统。
其实大数据实时处理的需求早已有之,最早的时候,我们用消息队列实现大数据实时处理,如果处理起来比较复杂,那么就需要很多个消息队列,将实现不同业务逻辑的生产者和消费者串起来。这个处理过程类似下面图里的样子。
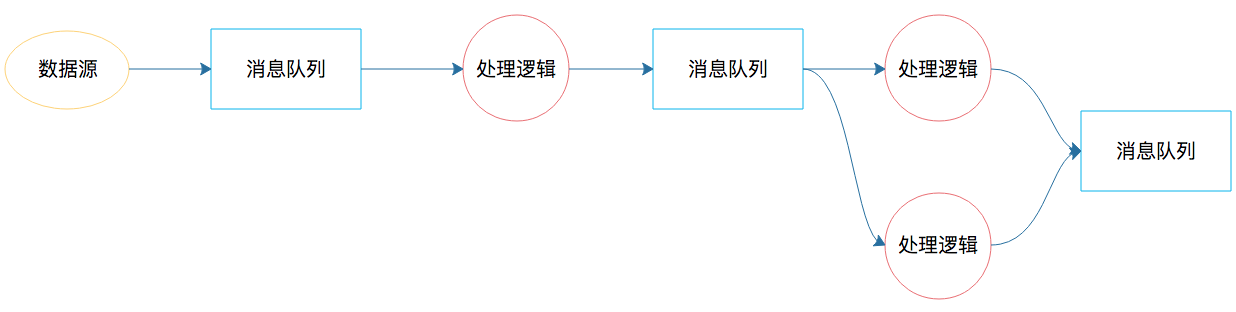
图中的消息队列负责完成数据的流转;处理逻辑既是消费者也是生产者,也就是既消费前面消息队列的数据,也为下个消息队列产生数据。这样的系统只能是根据不同需求开发出来,并且每次新的需求都需要重新开发类似的系统。因为不同应用的生产者、消费者的处理逻辑不同,所以处理流程也不同,因此这个系统也就无法复用。之后我们很自然地就会想到,能不能开发一个流处理计算系统,我们只要定义好处理流程和每一个节点的处理逻辑,代码部署到流处理系统后,就能按照预定义的处理流程和处理逻辑执行呢?Storm 就是在这种背景下产生的,它也算是一个比较早期的大数据流计算框架。
storm 解决什么问题?JStrom 概叙 & 应用场景 一文中总结的 非常好,可以参考下。
JStorm Chinese Documentation apache 接受了 阿里jstorm 的捐赠,传言 因为storm 原来的开发语言clojure 太小众,影响了社区的发展,因此正在将jstorm merge到 storm项目中
本文的主要 内容也参照 JStorm Chinese Documentation 来阐述
storm 趣闻
History of Apache Storm and lessons learned 是Storm作者Nathan Marz写的,文章讲述了Storm的构思、创建过程和Storm的市场营销,沟通交流和社区开发的故事。 有以下几个基本要点
- 作者称storm 是 the hadoop of realtime。 组件组成 上跟hadoop 非常相像,但针对realtime 做了一些调整。如果你观察 alibaba/jstorm 会发现有一个jstorm-on-yarn,资源管理与调度 二元架构,有没有发现一切都是套路。
- 作者在创业公司 BackType 时候,设想的是storm 谁用谁搭集群就行了(或者说BackType 也用不了几个集群),使用和维护一体的。BackType 被Twitter 收购之后,storm 在各个团队中使用,使用方不想管维护的事儿,只是提交任务就完事了。这样storm 就要做资源管理,并减少Application 之间的相互影响,也就是multi-tenancy 多租户。这也是其它 类似spark 等的共同思路。
- 作者写storm的时候就打算开源,所以虽然clojure写的,但百分百兼容java(因为用java的人多)。Topologies are defined as Thrift data structures, and topologies are submitted using a Thrift API. Additionally, I designed a protocol so that spouts and bolts could be implemented in any language
抽象概念
topology is a network of spouts and bolts.
spout 产生的消息tuple 发送到 哪些 botls中,可以通过Stream Groupings 来设定,rabbitmq 的订阅模型 storm 都支持。
下面用一个简单的例子来描述下topology 的拓扑结构
TopologyBuilder builder = new TopologyBuilder();
// Kestrel 是一个消息队列,1 是spout 的id
builder.setSpout(1,new KestrelSpout("kestrel.backtype.com",22133,"sencence_queue",new StringScheme()));
// 表示SplitSentence 通过shuffle Grouping 读取组件1 发出的所有消息
builder.setBolt(2,new SplitSentence(),10).shuffleGrouping(1);
builder.setBolt(3,new WordCount(),20).fieldsGrouping(2,new Fields("word"));
有了 Storm 后,开发者无需再关注数据的流转、消息的处理和消费,只要编程开发好数据处理的逻辑 bolt 和数据源的逻辑 spout,以及它们之间的拓扑逻辑关系 toplogy,提交到 Storm 上运行就可以了。PS:Hadoop、Storm 的设计理念,其实是一样的,就是把和具体业务逻辑无关的东西抽离出来,形成一个框架,比如大数据的分片处理、数据的流转、任务的部署与执行等,开发者只需要按照框架的约束,开发业务逻辑代码,提交给框架执行就可以了。而这也正是所有框架的开发理念,就是将业务逻辑和处理过程分离开来,使开发者只需关注业务开发即可,比如 Java 开发者都很熟悉的 Tomcat、Spring 等框架,全部都是基于这种理念开发出来的。
运行
- master 节点运行进程 Nimbus
- slave 节点 运行进程 Supervisor
一个运行中的Topology 由分布在不同slave节点上的多个 Supervisor 组成。具体的说:对一个topology,JStorm最终会调度成一个或多个worker,每个worker即为一个真正的操作系统执行进程,分布到一个集群的一台或者多台机器上并行执行。而每个worker中,又可以有多个task,分别代表一个执行线程。每个task就是上面提到的组件(component)的实现,要么是spout要么是bolt。
Nimbus 和 Supervisor 进程都是快速失败和无状态的。所有的状态要么在zookeeper里面,要么在本地磁盘上。这也就意味着你可以用kill -9来结束Nimbus 和 Supervisor 进程,然后再重启它们,就好像什么都没有发生过。
Topology 的定义是一个Thrift结构,并且Nimbus 就是一个Thrift 服务。
你可以动态增加或减少执行Topology的进程和线程数量
代码实例
可以 参见 https://github.com/alibaba/jstorm/tree/master/example/sequence-split-merge/src/main/java/com/alipay/dw/jstorm/example/batch,包括三个类:
- SimpleBatchTopology.java,包含main 方法
- SimpleBolt.java
- SimpleSpout.java
与mapreduce 极其相像,实现一个mapper类、reudce类,再提供一个聚合类,包括main函数。
public interface ISpout extends Serializable {
void open(Map conf, TopologyContext context, SpoutOutputCollector collector); //当task起来后执行的初始化动作
void close(); //当task被shutdown后执行的动作
void activate(); // 当task被激活时,触发的动作
void deactivate(); // 是task被deactive时,触发的动作
void nextTuple(); // 是spout实现核心, nextuple完成自己的逻辑,即每一次取消息后,用collector 将消息emit出去。
void ack(Object msgId); // 当spout收到一条ack消息时,触发的动作
void fail(Object msgId); // 当spout收到一条fail消息时,触发的动作
}
public interface IBolt extends Serializable {
void prepare(Map stormConf, TopologyContext context, OutputCollector collector); // task起来后执行的初始化动作
void execute(Tuple input); // execute是bolt实现核心, 完成自己的逻辑,即接受每一次取消息后,处理完,有可能用collector 将产生的新消息emit出去。 在executor中,当程序处理一条消息时,需要执行collector.ack. 当程序无法处理一条消息时或出错时,需要执行collector.fail ,详情可以参考 ack机制
void cleanup(); // 当task被shutdown后执行的动作
}
消息的处理
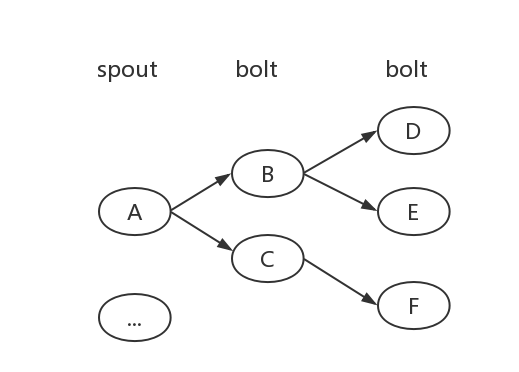
以一个wordcount 的中间 Bolt 为例,如果输入是“hello world”,则输出为”hello”,”world”,对应上图的B 节点
public class SplitSentence extends BaseRichBolt{
OutputCollector _collector;
public void prepare(Map conf,TopologyContext context,OutputCollector collector){
_collector = collector;
}
public void execute(Tuple tuple){
String sentence = tuple.getString(0);
for(String word : sentence.split(" ")){
_collector.emit(tuple,new Values(word));
}
_collector.ack(tuple);
}
public void declareOutputFields(OutputFieldsDeclarer declarer){
declarer.declare(new Fields("word"));
}
}
首先new Values(word) 和 declarer.declare(new Fields("word")); 表示 该bolt 发往下一个 bolt 的 格式:只有一个字段,字段名word。
_collector.emit(tuple,new Values(word)); 两个参数,原来的消息tuple,新的消息。storm将将它们做了关联,即可形成一个tuple tree
storm 中有一个专职的acker,_collector.emit(tuple,new Values(word))/_collector.ack(tuple) 向acker 发送消息,acker 保存了一个<消息id,spout id,ack val>,以上图为例
| 所在节点 | <消息id,spout id,ack val> |
|
|---|---|---|
| emit B | A 所在 spout | a_msg_id,spout_id, a_msg_id xor b_msg_id |
| emit D | B bolt | a_msg_id,spout_id, last_id xor d_msg_id |
| emit E | B bolt | a_msg_id,spout_id, last_id xor e_msg_id |
| ack B | B bolt | a_msg_id,spout_id, last_id xor b_msg_id |
| emit C | A spout | a_msg_id,spout_id, last_id xor c_msg_id |
| emit F | C bolt | a_msg_id,spout_id, last_id xor f_msg_id |
| ack C | C bolt | a_msg_id,spout_id, last_id xor c_msg_id |
| ack F | F bolt | a_msg_id,spout_id, last_id xor f_msg_id |
| ack D | F bolt | a_msg_id,spout_id, last_id xor d_msg_id |
| ack E | F bolt | a_msg_id,spout_id, last_id xor e_msg_id |
a_msg_id 对应的 <消息id,spout id,ack val>,若全部顺利处理(都发了ack),其ack val 最终会是0. 即通过是否为0 ,acker 向spout 告知该消息 需要重发
Storm的设计模式
就像基于spark core 衍生了spark sql、spark stream 等一样,颠覆大数据分析之Storm的设计模式 文中将DRPC 与 Trident 成为基于 storm 的设计模式(在给定上下文环境中,针对设计问题的可重用的通常解决方案)
Distributed RPC
DRPC提供了一个在Storm之上的分布式RPC实现。storm集群通过一个DRPC服务器协调DRPC请求,具体的说:
- DRPC服务器接收来自客户端的RPC请求,并把它们分到Storm集群,由集群节点并行的执行程序;
- DRPC服务器接收来自Storm集群的结果,并用它们响应客户端。
假设一次rpc 涉及到千万次的数据库调用。通常也只能先用spark 跑一下,将数据写入到hdfs,然后在代码中读取hdfs数据,再进行业务处理。DRPC 使得 业务系统 能够较为顺滑的接入 storm 以获取 集群维度的处理能力。
Trident
TridentTopology topology = new TridentTopology();
TridentState wordCounts = topology.newStream("input1",spout)
.each(new Fields("sentence"), new Split(), new Fields("word"))
.groupBy(new Fields("word"))
.persistentAggregate(MemcachedState.transactional(serverLocations),
new Count(), new Fields("count"));
MemcachedState.transactional();
是不是找到了spark rdd 的感觉。Trident 是基于 storm 进行实时流处理的高级抽象,提供了对实时流的聚集、投影、过滤等操作。省得写那么多琐碎的bolt
留下评论