Spark 泛谈
前言
在 2012 年,UC 伯克利 AMP 实验室(Algorithms、Machine 和 People 的缩写)开发的 Spark 开始崭露头角。当时 AMP 实验室的马铁博士发现使用 MapReduce 进行机器学习计算的时候性能非常差,因为机器学习算法通常需要进行很多次的迭代计算,而 MapReduce 每执行一次 Map 和 Reduce 计算都需要重新启动一次作业,带来大量的无谓消耗。还有一点就是 MapReduce 主要使用磁盘作为存储介质,而 2012 年的时候,内存已经突破容量和成本限制,成为数据运行过程中主要的存储介质。PS:再后来,网络已经不比磁盘慢了,就存算分离了。
从操作上直观感受 spark
单机模式
- 官网下载spark-2.3.0-bin-hadoop2.7.tgz包,解压
- 启动master,
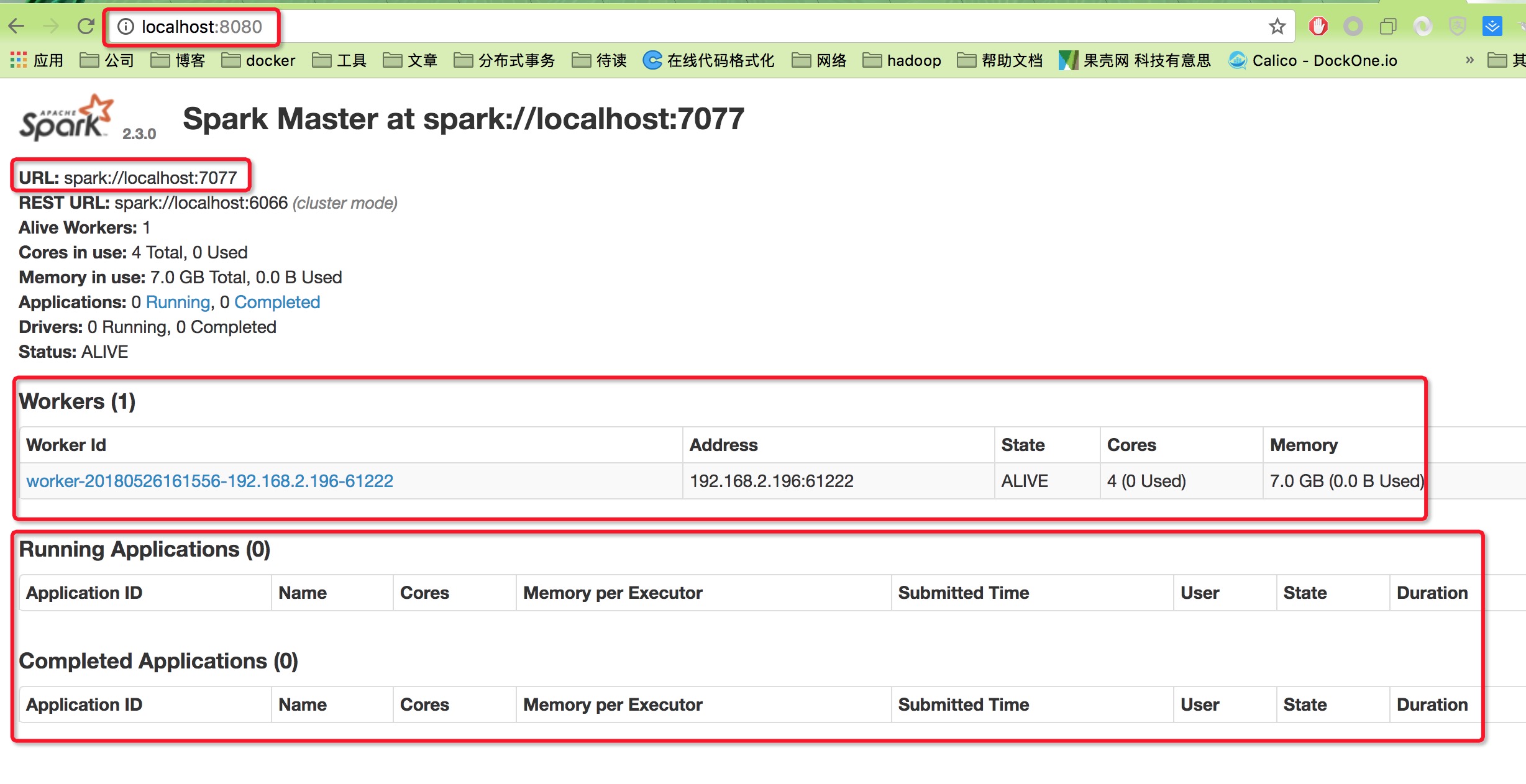
spark-2.3.0-bin-hadoop2.7/sbin/start-master.sh - 可以在
http://localhost:8080下查看 webui - 启动一个slave,
spark-2.3.0-bin-hadoop2.7/sbin/start-slave.sh spark://localhost:7077
交互式查询
传统的 通过提交代码与 spark 或 mapreduce 交互
一个mapreduce 任务执行的流程
- 编写代码
- 打成jar 包
- hadoop master 机器上
hadoop jar wordcount.jar input_arg output_arg
对应到 spark 则是
- 编写代码
bin/spark-submit --class xx.xx.wordcount target_jar input_arg out_arg
《Spark快速大数据分析》讲到spark shell时提到:使用其它shell工具,你只能用单机的硬盘和内存来操作数据,而Spark Shell可用来与分布式存储在许多机器的内存或者硬盘上的数据进行交互,并且处理过程的分发由spark自动控制完成(spark 速度快,速度快就意味着我们可以进行 交互式的数据操作)。
scala> val input = sc.textFile("/tmp/inputFile")
spark info...
scala> val words = input.flatMap(line => line.split(" "))
spark info...
scala> val counts = words.map(word => (word,1)).reduceByKey{case (x,y) => x+y}
spark info...
scala> counts.saveAsTextFile("/tmp/output")
spark info...
此处,运行完毕后,/tmp/output 是一个目录,其结构 跟 hdfs 是一样一样的,这跟选用saveAsTextFile方法有关系。
对比MapReduce
其它:在任务(task)级别上,Spark 的并行机制是多线程模型,而 MapReduce 是多进程模型。多进程模型便于细粒度控制每个任务占用的资源,但会消耗较多的启动时间。而 Spark 同一节点上的任务以多线程的方式运行在一个 JVM 进程中,可以带来更快的启动速度、更高的 CPU 利用率,以及更好的内存共享。
计算模型的差异
MapReduce 一个应用一次只运行一个 map 和一个 reduce,一个典型的批处理作业往往需要多次 Map、Reduce 迭代计算来实现业务逻辑,因此上图中的计算流程会被重复多次,直到最后一个 Reduce 任务输出预期的计算结果(想象一下,完成这样的批处理作业,在整个计算过程中需要多少次落盘、读盘、发包、收包的操作,每一步的 MapReduce 都有可能出错)。Spark 可以根据应用的复杂程度,分割成更多的计算阶段(stage),这些计算阶段组成一个有向无环图 DAG,Spark 任务调度器可以根据 DAG 的依赖关系执行计算阶段。你可以看到 Spark 作业调度执行的核心是 DAG,有了 DAG,整个应用就被切分成哪些阶段,每个阶段的依赖关系也就清楚了。之后再根据每个阶段要处理的数据量生成相应的任务集合(TaskSet),每个任务都分配一个任务进程去处理,Spark 就实现了大数据的分布式计算。
其实从本质上看,Spark 可以算作是一种 MapReduce 计算模型的不同实现。Hadoop MapReduce 简单粗暴地根据 shuffle 将大数据计算分成 Map 和 Reduce 两个阶段,然后就算完事了。而 Spark 更细腻一点,将前一个的 Reduce 和后一个的 Map 连接起来,当作一个阶段持续计算(如果一个应用的计算阶段变得很多的话,MapReduce需要启动多个应用进行计算),形成一个更加优雅、高效的计算模型,虽然其本质依然是 Map 和 Reduce。但是这种多个计算阶段依赖执行的方案可以有效减少对 HDFS 的访问,减少作业的调度执行次数,因此执行速度也更快。
并且和 Hadoop MapReduce 主要使用磁盘存储 shuffle 过程中的数据不同,Spark 优先使用内存进行数据存储,包括 RDD 数据。除非是内存不够用了,否则是尽可能使用内存, 这也是 Spark 性能比 Hadoop 高的另一个原因。
《大数据经典论文解读》对应论文 《《Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing》》。Spark 的计算模型,其实可以看作一个是支持多轮迭代的 MapReduce 模型。不过它在实现层面,又和稍显笨拙的 MapReduce 完全不同。通过引入 RDD 这样一个函数式对象的数据集的概念,Spark 在多轮的数据迭代里,不需要像 MapReduce 一样反反复复地读写硬盘,大大提升了处理数据的性能。MapReduce 的过程并不复杂,Map 函数的输出结果会输出到所在节点的本地硬盘上。Reduce 函数会从 Map 函数所在的节点里拉取它所需要的数据,然后再写入本地。接着通过一个外部排序的过程,把数据进行分组。最后将排序分完组的数据,通过 Reduce 函数进行处理。在这个过程里,任何一个中间环节,我们都需要去读写硬盘。Map 函数的处理结果,并不会直接通过网络发送给 Reduce 所在的 Worker 节点,Reduce 也不会直接在内存中做数据排序。
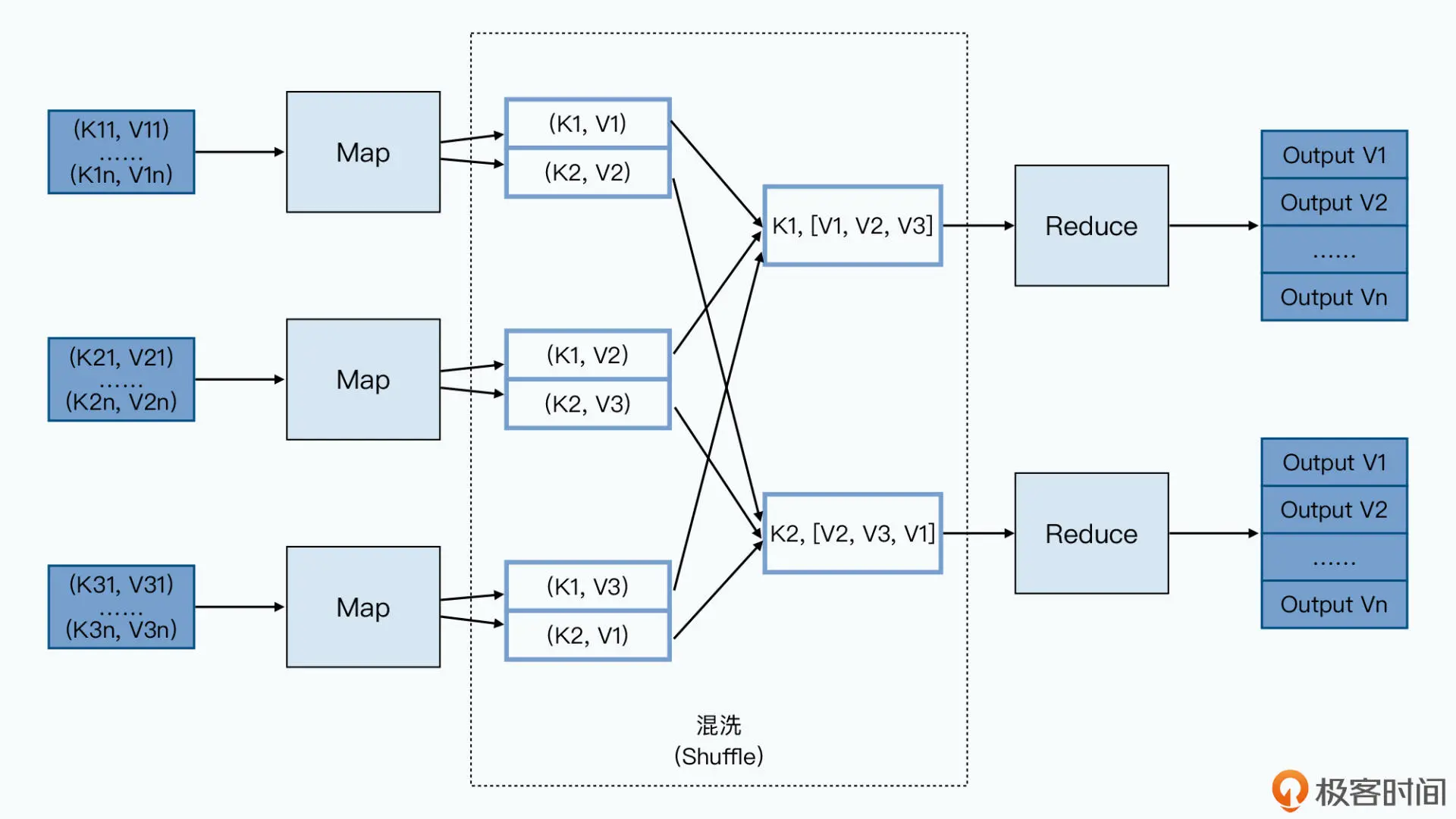
之所以 MapReduce 把所有数据都往硬盘里一写,是因为它追求的是设计上的“简单”,以及在大规模集群下的“容错”能力。把 Map 节点的输出数据,直接通过网络发送给 Reduce 的确是一个很直观的想法,让 Reduce 节点在内存里就直接处理数据,也的确可以提升性能。但是,如果在这个过程中,Map 或者 Reduce 的节点出现故障了怎么办?因为 Reduce 对于前面的 Map 函数有依赖关系,所以任何一个 Map 节点故障,意味着 Reduce 只收到了部分数据,而且它还不知道是哪一部分。那么 Reduce 任务只能失败掉,然后等 Map 节点重新来过。而且,Reduce 的失败,还会导致其他的 Map 节点计算的数据也要重来一遍,引起连锁反应,最终等于是整个任务重来一遍。这只是我们尝试让数据不需要落地到硬盘处理中,会遇到的一种情况,我们还可能遇到网络拥塞、内存不足以处理传输的数据等种种情况。事实上,你可以认为传统的 MPI 分布式计算系统就是这样,让一个节点直接往另外一个节点发送消息来传递数据的,但是这样的系统,容错能力很差,所以集群的规模往往也上不去。而 MapReduce 针对这个问题的解决方案非常简单粗暴,那就是把整个数据处理的环节完全拆分开来,然后把一个个阶段的中间数据都落地到硬盘上。这样,针对单个节点的故障,我们只需要重新运行对应节点分配的任务就好了,其他已经完成的工作不会“半途而废”。所以,很自然地,我们需要有一个更有效率的容错方式。一个很直观的想法自然也就冒出来了,那就是我们是否可以做这三件事情:
- 把数据缓存在内存里
- 如果节点故障怎么办?记录我们运算数据生成的“拓扑图”。也就是记录数据计算的依赖关系,一旦某个节点故障,导致这个依赖关系中的一部分节点出现故障,我们根据拓扑图重新计算这一部分数据就好了。通过这样的方式来解决容错问题,而不是每一次都把数据写入到硬盘。
- 当我们的拓扑图层数很深,或者数据要反复进行很多次的迭代计算。前面通过“拓扑图”进行重新计算的容错方式会变得非常低效。我们可以在一部分中间环节,把数据写入到硬盘上。这样一种折衷的方式,既避免了每次都去从硬盘读写数据,也避免了一旦某一个环节出现故障,“容错”方案只能完全从头再来的尴尬出现。 本质上,Spark 就是根据人的经验,在性能和容错之间做好了平衡。
数据接口的不同
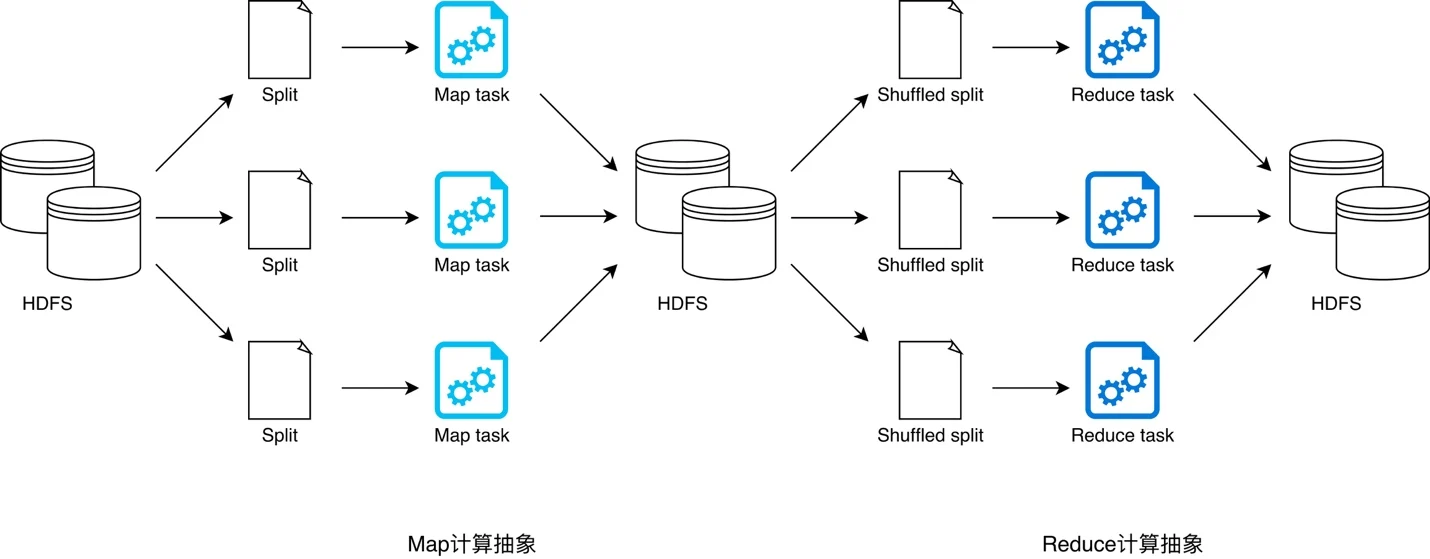
大数据计算就是在大规模的数据集上进行一系列的数据计算处理。MapReduce 针对输入数据,将计算过程分为两个阶段,一个 Map 阶段(定义数据处理逻辑),一个 Reduce 阶段(封装数据聚合逻辑),可以理解成是面向过程的大数据计算。我们在用 MapReduce 编程的时候,思考的是,如何将计算逻辑用 Map 和 Reduce 两个阶段实现,map 和 reduce 函数的输入和输出是什么,这也是我们在学习 MapReduce 编程的时候一再强调的。MapReduce 计算模型采用 HDFS 作为算子(Map 或 Reduce)之间的数据接口,所有算子的临时计算结果都以文件的形式存储到 HDFS 以供下游算子消费。下游算子从 HDFS 读取文件并将其转化为键值对(江湖人称 KV),用 Map 或 Reduce 封装的计算逻辑处理后,再次以文件的形式存储到 HDFS。PS:MapReduce 计算模型最大的问题在于,所有操作之间的数据交换都以磁盘为媒介。且MapReduce 模型的抽象层次低,大量的底层逻辑都需要开发者手工完成,举个例子,两个数据集的 Join 是很基本而且常用的功能,但是在 MapReduce 的世界中,需要对这两个数据集做一次 Map 和 Reduce 才能得到结果。
不难发现,问题就出在数据接口上。HDFS 引发的计算效率问题我们不再赘述,那么,有没有比 HDFS 更好的数据接口呢?如果能够将所有中间环节的数据文件以某种统一的方式归纳、抽象出来,那么所有 map 与 reduce 算子是不是就可以更流畅地衔接在一起,从而不再需要 HDFS 了呢?—— Spark 提出的 RDD 数据模型,恰好能够实现如上设想。
Spark 直接针对数据进行编程,将大规模数据集合抽象成一个 RDD 对象,然后在这个 RDD 上进行各种计算处理,得到一个新的 RDD,继续计算处理,直到得到最后的结果数据。所以 Spark 可以理解成是面向对象的大数据计算。我们在进行 Spark 编程的时候,思考的是一个 RDD 对象需要经过什么样的操作,转换成另一个 RDD 对象,思考的重心和落脚点都在 RDD 上。PS: spark无论处理什么数据先整成一个rdd 再说。
《大数据经典论文解读》RDD 的设计思路也是来自于函数式编程。相对于过程式地把每一个数据转换(Transformation)的结果存储下来,RDD 相当于记录了输入数据,以及对应的计算输入数据的函数。这个方式,和把一步步的计算结果存储下来的效果一样,都可以解决容错问题。当某一个 RDD 的某一个分区因为故障丢失的时候,我们可以通过输入数据和对应的函数,快速计算出当前 RDD 的实际内容。而这个输入数据 + 对应函数的组合,就是 RDD 中的 Lineage 图。PS: RDD 的idea 来源之一就是容错方式,记录处理链路以便重算来容错。
RDD 和其他分布式系统最大的差异,就在代表弹性的 R 这个关键字上。这个弹性体现在两个方面。
- 数据存储上。数据不再是存放在硬盘上的,而是可以缓存在内存中。只有当内存不足的时候,才会把它们换出到硬盘上。同时,数据的持久化,也支持硬盘、序列化后的内存存储,以及反序列化后 Java 对象的内存存储三种形式。每一种都比另一种需要占用更多的内存,但是计算速度会更快。
- 选择把什么数据输出到硬盘上。Spark 会根据数据计算的 Lineage,来判断某一个 RDD 对于前置数据是宽依赖,还是窄依赖的。如果是宽依赖的,意味着一个节点的故障,可能会导致大量的数据要进行重新计算,乃至数据网络传输的需求。那么,它就会把数据计算的中间结果存储到硬盘上。同时,Spark 也支持你自己定义检查点,你可以把一些关键节点的数据通过检查点的方式,持久化到硬盘上,避免出现特定节点的故障,导致大量数据需要重新计算的问题。
其实在 Spark 出现之前,已经有很多人意识到 MapReduce 这个计算框架在性能上的不足了。也有各种各样的论文和系统,尝试去解决需要反复多轮迭代算法的效率问题。在 RDD 的论文中也有提到两篇,分别是来自于 Google 的 Pregel,它的出发点是用来解决 PageRank 的多轮迭代。以及改造自 Hadoop 的 Haloop,它的出发点是解决大规模数据集上迭代式的机器学习问题。
rdd
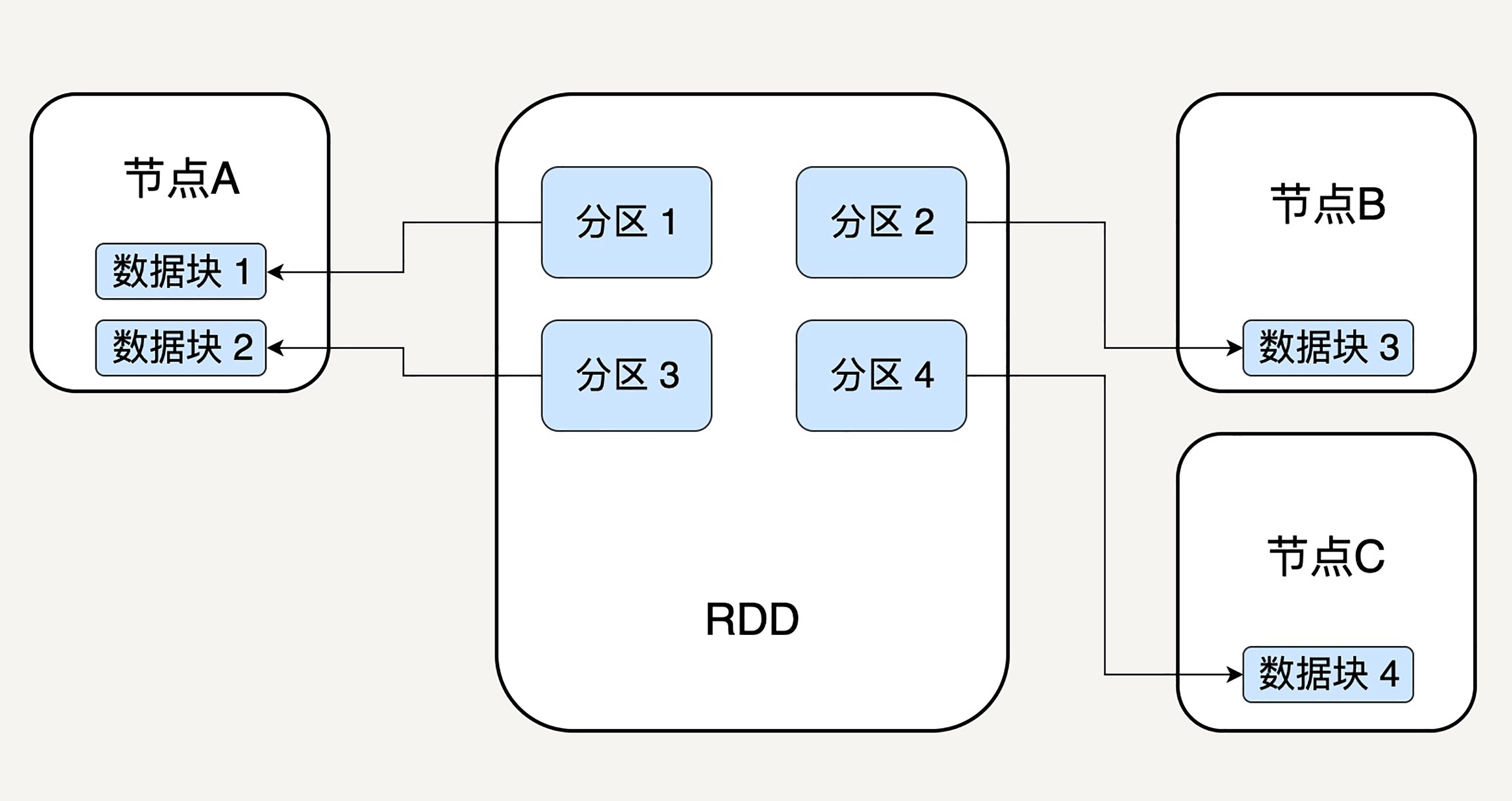
RDD,全称 Resilient Distributed Datasets,翻译过来就是弹性分布式数据集。RDD 表示已被分区、不可变的,并能够被并行操作的数据集合。本质上,它是对于数据模型的抽象,用于囊括所有内存中和磁盘中的分布式数据实体。
分区的(天然就是能并行操作的)
不可变的:《大规模数据处理实战》在普通编程语言中,大部分数据结构都是可变的。但是 PCollection 不提供任何修改它所承载数据的方式。修改一个 PCollection 的唯一方式就是去转化 (Transform) 它,Beam 的 PCollection 都是延迟执行(deferred execution)的模式。也就是说,PCollection p2 = doSomeWork(p1);什么也不会发生,仅仅是生成了一个有向无环图(DAG),也就是执行计划(execution plan)。为什么这么设计呢?这样的有向无环图是框架能够自动优化执行计划的核心。另外,由于 Beam 的分布式本质,即使你想要去修改一个 PCollection 的底层表达数据,也需要在多个机器上查找。
rdd 编程
val rdd1 = textFile.flatMap(line => line.split(" "))
val rdd2 = rdd1.map(word => (word, 1))
val rdd3 = rdd2.reduceByKey(_ + _)
RDD非常类似于 tensorflow 中的dataset 与 tensor 的结合体,tf算子施加于tensor上,从内部或外部数据源获取RDD,算子也都Apply 在RDD 之上。分布式计算的精髓,在于如何把抽象的计算流图,转化为实实在在的分布式计算任务,然后以并行计算的方式交付执行。具体的说,RDD 的计算以数据分区为粒度,依照算子的逻辑,Executors 以相互独立的方式,完成不同数据分区的计算与转换。
与 MapReduce 以算子(Map 和 Reduce)为第一视角、以HDFS文件为衔接的设计方式不同,Spark Core 中 RDD 的设计以数据作为第一视角,不再强调算子的重要性,算子仅仅是 RDD 数据转换的一种计算规则,map 算子和 reduce 算子纷纷被弱化、稀释在 Spark 提供的茫茫算子集合之中。
- rdd 支持两种操作: Transformations 操作和 Actions操作。RDD 上的转换操作又分成两种
- 转换操作产生的 RDD 不会出现新的分片,比如 map、filter 等,也就是说一个 RDD 数据分片,经过 map 或者 filter 转换操作后,结果还在当前分片。就像你用 map 函数对每个数据加 1,得到的还是这样一组数据,只是值不同。
- 转换操作产生的 RDD 则会产生新的分片,比如reduceByKey,来自不同分片的相同 Key 必须聚合在一起进行操作,这样就会产生新的 RDD 分片。
- 惰性求值,在 Actions操作开始之前,spark 不会开始 Transformations操作。
- 转化操作 会返回一个新的rdd,老的rdd 数据不会被改变
- rdd 根据转换操作 形成lineage graph,每当调用一个行动操作,lineage graph 都会从头开始计算。 Spark 的转换(transform)API 可以将 RDD 封装为一系列具有血缘关系(DAG)的 RDD。Spark 的动作(action)API 会将 RDD 及其 DAG(Spark 使用 DAG 来反映各 RDD 之间的依赖或血缘关系) 提交到 DAGScheduler。转换 API 和动作 API 总归都是在处理数据,因此 RDD 的祖先一定是一个跟数据源相关的 RDD,负责从数据源迭代读取数据。
Spark 内核的设计原理执行一个动作 API 产生一个 Job。Spark 会在 DAGscheduler 阶段来划分不同的 Stage, Stage 分为 ShuffleMapStage 和 ResultStage 两种。每个 Stage 中都会按照 RDD 的 Partition 数量创建多个 Task。ShuffleMapStage 中的 Task 为 ShuffleMapTask。ResultStage 中的 Task 为 ResultTask,类似于 Hadoop 中的 Map 任务和 Reduce 任务。Task 调度(TaskScheduler)负责按照 FIFO 或者 FAIR 等调度算法对批量 Task 进行调度;将 Task 发送到集群管理器,分配给当前应用的 executor,由 executor 负责执行工作。
RDD 实现
5 大核心属性
- dependencies, 变量, 生成该RDD所依赖的父RDD
- compute, 方法, 生成该RDD的计算接口。
- partitions, 变量, 该RDD的所有数据分片实体,每个 Partition 会映射到某个节点内存或硬盘的一个数据块。
- partitioner, 方法, 划分数据分片的规则,,目前有两种主流的分区方式:Hash partitioner 和 Range partitioner。此外我们还可以创建自定义的 Partitioner。
- preferredLocations, 变量, 数据分片的物理位置偏好
dependencies 与 compute 两个核心属性实际上抽象出了“从哪个数据源经过怎样的计算规则和转换,从而得到当前的数据集”。所有 RDD 根据 dependencies 中指定的依赖关系和 compute 定义的计算逻辑构成了一条从起点到终点的数据转换路径。
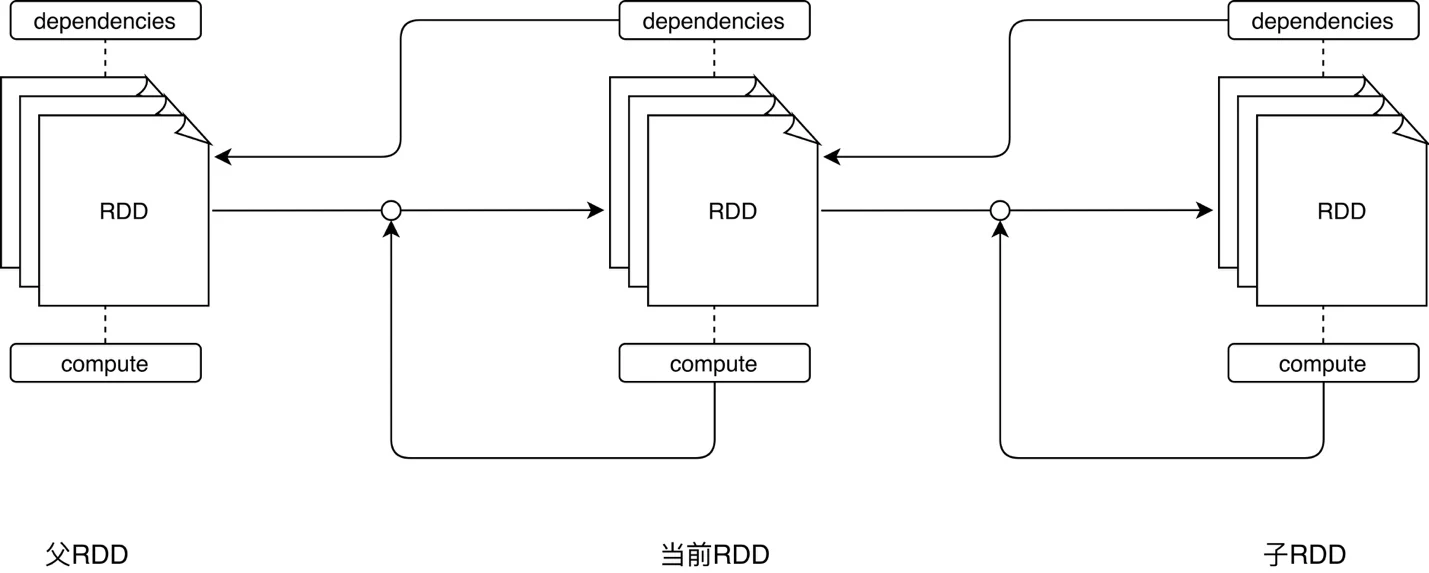
直观地感受一下 RDD 的转换过程

Spark 不需要将每个中间计算结果进行数据复制以防数据丢失,因为每一步产生的 RDD 里都会存储它的依赖关系,即它是通过哪个 RDD 经过哪个转换操作得到的。父 RDD 的分区和子 RDD 的分区之间是否是一对一的对应关系呢?Spark 支持两种依赖关系:窄依赖(Narrow Dependency)和宽依赖(Wide Dependency)。窄依赖就是父 RDD 的分区可以一一对应到子 RDD 的分区,宽依赖就是父 RDD 的每个分区可以被多个子 RDD 的分区使用。显然,窄依赖允许子 RDD 的每个分区可以被并行处理产生,而宽依赖则必须等父 RDD 的所有分区都被计算好之后才能开始处理。一些转换操作如 map、filter 会产生窄依赖关系,而 Join、groupBy 则会生成宽依赖关系。
在这样的编程模型下,Spark 在运行时的计算被划分为两个环节。PS: 与flink/tf的dag 很像,采用Lazy evaluation(对应Eager evaluation)
- 基于不同数据形态之间的转换,构建计算流图(DAG,Directed Acyclic Graph);比如rdd.map(func) 不是立即执行 func,而只是将map + func “挂在”了rdd.compute 上。
- 通过 Actions 类算子,以回溯的方式去触发执行这个计算流图。Actions 算子触发 SparkContext.runJob ==> DAGScheduler.runJob,从而开启一段分布式调度之旅。
整体架构
Spark 应用程序代码中的 RDD 和 Spark 执行过程中生成的物理 RDD 不是一一对应的。PS: 这点与tf 更像,Spark Core引人RDD的概念更多的是把数据处理步骤组成的有向无环图(DAG)抽象成类似函数式编程中的集合的概念,而把分布式数据处理的过程隐藏在这个抽象后面,比如划分stage,划分task,shuffle,调度这些task,保证data locality等等。
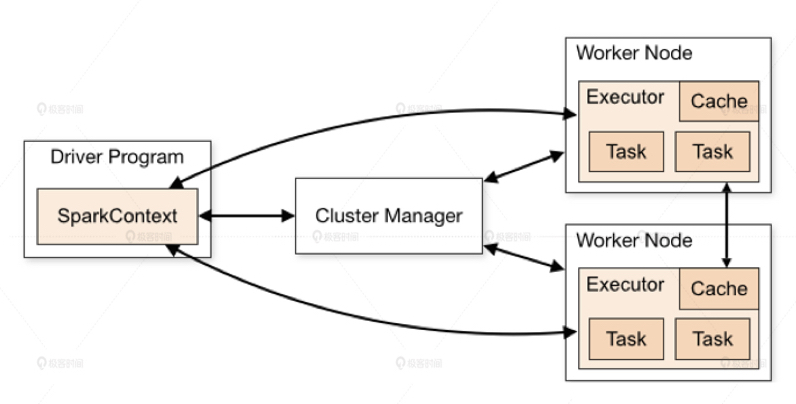
Spark 程序由 Manager Node(管理节点)进行调度组织,由 Worker Node(工作节点)进行具体的计算任务执行,最终将结果返回给 Drive Program(驱动程序)。在物理的 Worker Node 上,数据还会分为不同的 partition(数据分片),可以说 partition 是 Spark 的基础数据单元。
我们用一个任务来解释一下 Spark 的工作过程:我们需要先从本地硬盘读取文件 textFile,再从分布式文件系统 HDFS 读取文件 hadoopFile,然后分别对它们进行处理,再把两个文件按照 ID 都 join 起来得到最终的结果。
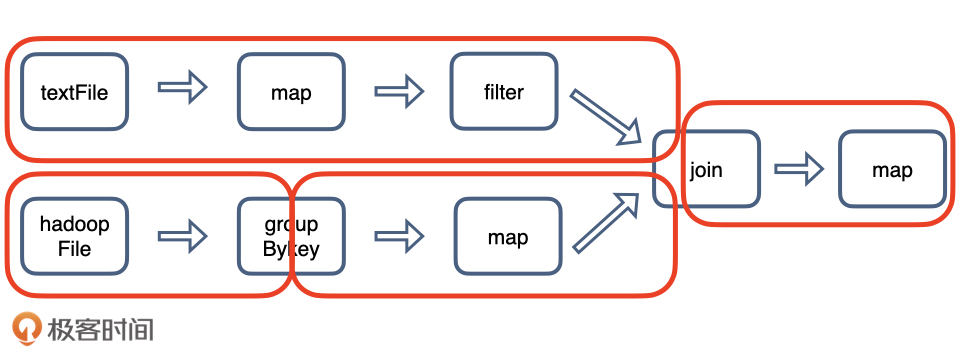
DAGScheduler 核心职责,根据程序代码生成 DAG,把计算图 DAG 拆分为执行阶段 Stages,Stages 指的是不同的运行阶段,同时还要负责把 Stages 转化为任务集合 TaskSets。
- 用一句话来概括从 DAG 到 Stages 的拆分过程:以 Shuffle 为边界,从后向前以递归的方式,把逻辑上的计算图 DAG,转化成一个又一个 Stages。PS: 计算阶段划分的依据是 shuffle,不是转换函数的类型
- 从后向前,以递归的方式,依次提请执行所有的 Stages。在 Word Count 的例子中,DAGScheduler 最先提请执行的是 Stage1。在提交的时候,DAGScheduler 发现 Stage1 依赖的父 Stage,也就是 Stage0,还没有执行过,那么这个时候它会把 Stage1 的提交动作压栈,转而去提请执行 Stage0。当 Stage0 执行完毕的时候,DAGScheduler 通过出栈的动作,再次提请执行 Stage 1。
- 对于提请执行的每一个 Stage,DAGScheduler 根据 Stage 内 RDD 的 partitions 属性创建分布式任务集合 TaskSet(RDD 最终落地为 Task)。TaskSet 包含一个又一个分布式任务 Task,RDD 有多少数据分区,TaskSet 就包含多少个 Task。换句话说,Task 与 RDD 的分区,是一一对应的。
- Task 代表的是分布式任务,包含以下属性。
- stageId, task 所在stage
- stageAttemptId, 失败重试编号
- taskBinary, 任务代码。broadcasted version of the serialized RDD and the function to apply on each partition of the given RDD, once deserialized, the type should be
(RDD[T],(TaskContext,Iterator[T])=>U)。PS: 对象序列化之后发给executor,executor 发序列化后执行。 - partition, task 对应的RDD 分区
- locs, 以字符串的形式记录了该任务倾向的计算节点或是 Executor ID taskBinary、partition 和 locs 这三个属性,一起描述了这样一件事情:Task 应该在哪里(locs)为谁(partition)执行什么任务(taskBinary)。
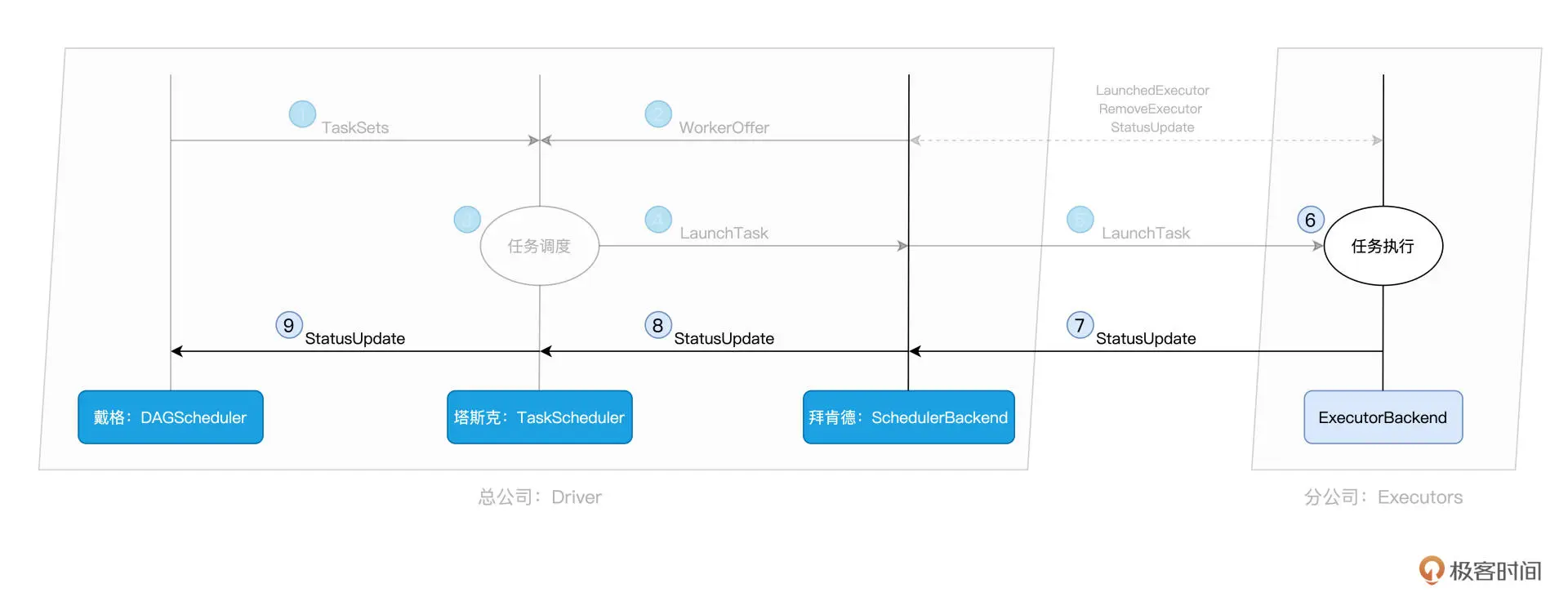
SchedulerBackend 用一个叫做 ExecutorDataMap 的数据结构 <标记 Executor 的字符串,ExecutorData>,ExecutorData 用于封装 Executor 的资源状态,如 RPC 地址、主机地址、可用 CPU 核数和满配 CPU 核数等等。SchedulerBackend 与集群内所有 Executors 中的 ExecutorBackend 保持周期性通信,双方通过 LaunchedExecutor、RemoveExecutor、StatusUpdate 等消息来互通有无、变更可用计算资源。
对于给定的 WorkerOffer,TaskScheduler 是按照任务的本地倾向性,来遴选出 TaskSet 中适合调度的 Tasks。TaskScheduler 就把这些 Tasks 通过 LaunchTask 消息发送给 SchedulerBackend。 SchedulerBackend 拿到这些活儿之后,同样使用 LaunchTask 消息,把活儿进一步下发给ExecutorBackend。PS: SchedulerBackend 知道哪些节点有多少资源(对外提供WorkerOffer),DAGScheduler 产出TaskSet,TaskScheduler 做适配
ExecutorBackend 拿到“活儿”之后,随即把活儿派发给Executor,Executor 先检查自己是否有 Driver 的执行代码,如果没有,从 Driver 下载执行代码,通过 Java 反射加载后开始执行。每个线程负责处理一个 Task,每当 Task 处理完毕,这些线程便会通过 ExecutorBackend,向 Driver 端的 SchedulerBackend 发送 StatusUpdate 事件,告知 Task 执行状态。
代码的运行
总结来说,Spark 有三个主要特性:RDD 的编程模型更简单,DAG 切分的多阶段计算过程更快速,使用内存存储中间计算结果更高效。
上层应用
spark 可以使用自己的 master/slave,也可以使用mesos 或 hadoop yarn
spark/mapreduce 作为 yarn/mesos 的上层,有自己的spark “Scheduler”和 spark “Executor”,对于一段spark 代码
object WordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("wordCount");
val sc = new SparkContext(conf)
val input = sc.textFile("/Users/nali/tmp/hello")
val words = input.flatMap(line => line.split(" "))
val counts = words.map(word => (word,1)).reduceByKey{case (x,y) => x+y}
counts.saveAsTextFile("/Users/nali/tmp/output")
}
}
它实际 是一个 独立运行的进程么?它和spark master如何交互呢?
Spark 学习: spark 原理简述与 shuffle 过程介绍
要点如下:
- wordcount 会对应一个driver 进程,executor 由 spark 框架提供。driver 和 Executor 就是 wordcount 应用的 “scheduler” 和 “executor”
- Driver进程会将我们编写的Spark作业代码分拆为多个stage,每个stage执行一部分代码片段,并为每个stage创建一批Task,然后将这些Task分配到各个Executor进程中执行。
- Task是最小的计算单元(以线程方式执行)。前文提到资源管理器 就是帮你启动Scheduler、Executor,并提供通信服务,Executor 就是启动和监控task。于是,上层是抽象的rdd接口,下层是一个个task, 中间这种抽象层次的弥合 便通过driver (也就是Scheduler )实现。
shuffle
DAGScheduler 以 Shuffle 为边界,把计算图 DAG 切割为多个执行阶段 Stages。显然,Shuffle 是这个环节的关键。Shuffle 的本意是扑克的“洗牌”,在分布式计算场景中,它被引申为集群范围内跨节点、跨进程的数据分发,会引入大量的磁盘 I/O 与网络 I/O。以 Shuffle 为边界,reduceByKey 的计算被切割为两个执行阶段。约定俗成地,我们把 Shuffle 之前的 Stage 叫作 Map 阶段,而把 Shuffle 之后的 Stage 称作 Reduce 阶段。
- 在 Map 阶段,每个 Executors 先把自己负责的数据分区做初步聚合(又叫 Map 端聚合、局部聚合);
- 在 Shuffle 环节,不同的单词被分发到不同节点的 Executors 中;
- 在 Reduce 阶段,Executors 以单词为 Key 做第二次聚合(又叫全局聚合),从而完成统计计数的任务。
与其说 Shuffle 是跨节点、跨进程的数据分发,不如说 Shuffle 是 Map 阶段与 Reduce 阶段之间的数据交换。如何实现数据交换的呢?Map 阶段与 Reduce 阶段,通过生产与消费 Shuffle 中间文件的方式,来完成集群范围内的数据交换。换句话说,Map 阶段生产 Shuffle 中间文件,Reduce 阶段消费 Shuffle 中间文件,二者以中间文件为媒介,完成数据交换。
- Shuffle 文件的生成,是以 Map Task 为粒度的,Map 阶段有多少个 Map Task,就会生成多少份 Shuffle 中间文件。
- 在生成中间文件的过程中,Spark 会借助一种类似于 Map 的数据结构,来计算、缓存并排序数据分区中的数据记录。这种 Map 结构的 Key 是(Reduce Task Partition ID,Record Key),而 Value 是原数据记录中的数据值。当 Map 结构被灌满之后,Spark 根据主键对 Map 中的数据记录做排序,然后把所有内容溢出到磁盘中的临时文件,如此往复,直到数据分区中所有的数据记录都被处理完毕。到此为止,磁盘上存有若干个溢出的临时文件,而内存的 Map 结构中留有部分数据,Spark 使用归并排序算法对所有临时文件和 Map 结构剩余数据做合并,分别生成 data 文件、和与之对应的 index 文件(用来标记目标分区所属数据记录的起始索引)。Shuffle 阶段生成中间文件的过程,又叫 Shuffle Write。
- 不同的 Reduce Task 正是根据 index 文件中的起始索引来确定哪些数据内容是“属于自己的”。
rdd 和block
Spark 存储系统负责维护所有暂存在内存与磁盘中的数据,这些数据包括 Shuffle 中间文件、RDD Cache 以及广播变量(即存储系统的服务对象)。Spark存储系统原理与源码解析
在集群范围内, Spark的各个组件 想要拉取属于自己的数据,就必须要知道这些数据都存储在哪些节点,以及什么位置。而这些关键的元信息,正是由 Spark 存储系统保存并维护的。Spark 存储系统是一个囊括了众多组件的复合系统,如 BlockManager、BlockManagerMaster、MemoryStore、DiskStore 和 DiskBlockManager 等等。不过,家有千口、主事一人,BlockManager 是其中最为重要的组件,它在 Executors 端负责统一管理和协调数据的本地存取与跨节点传输。这怎么理解呢?我们可以从 2 方面来看。
- 对外,BlockManager 与 Driver 端的 BlockManagerMaster 通信,不仅定期向 BlockManagerMaster 汇报本地数据元信息,还会不定时按需拉取全局数据存储状态。另外,不同 Executors 的 BlockManager 之间也会以 Server/Client 模式跨节点推送和拉取数据块。PS: spark 内部组件
- 对内,BlockManager 通过组合存储系统内部组件的功能来实现数据的存与取、收与发。
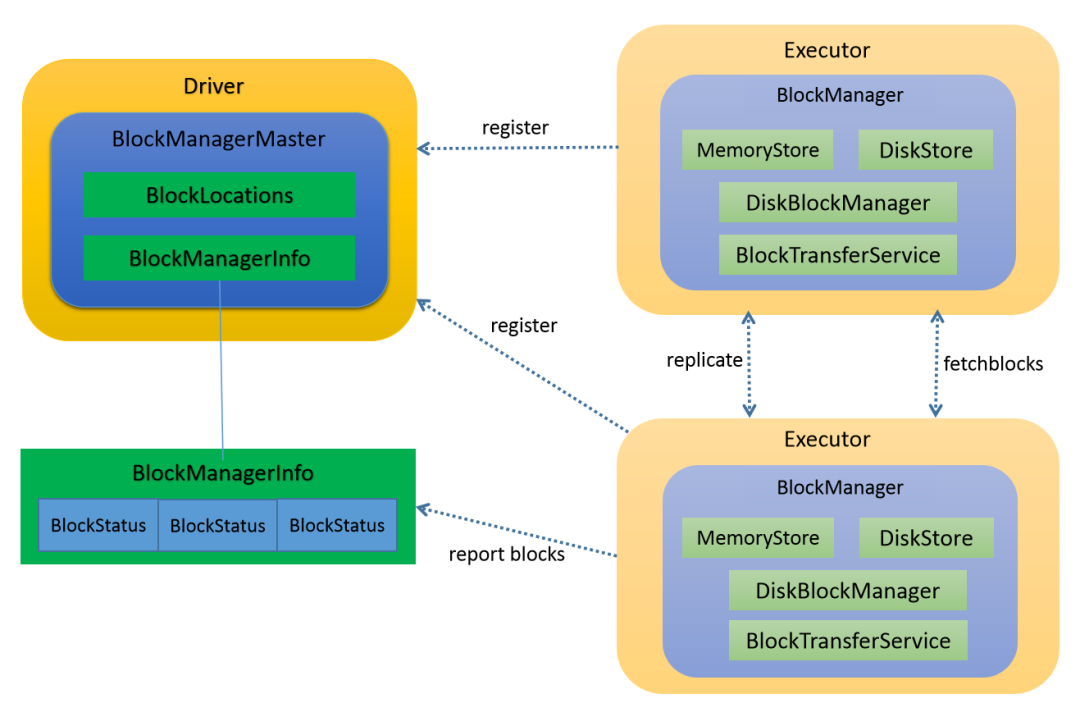
Spark自己的分布式存储系统BlockManager全解析BlockManager 是一个嵌入在 spark 中的 key-value型分布式存储系统,BlockManager 在一个 spark 应用中作为一个本地缓存运行在所有的节点上,BlockManager 对本地和远程提供一致的 get 和set 数据块接口,BlockManager 本身使用不同的存储方式来存储这些数据, 包括 memory, disk, off-heap。BlockManager内部会创建出MemoryStore和DiskStore对象用以存取block,如果内存中拥有足够的内存, 就 使用 MemoryStore存储, 如果 不够, 就 spill 到 磁盘中, 通过 DiskStore进行存储。
def putBlockData(blockId: BlockId,data: ManagedBuffer,level: StorageLevel,classTag: ClassTag[_]): Boolean = {...}
def get[T: ClassTag](blockId: BlockId): Option[BlockResult] = {...}
- 在RDD层面上,RDD是由不同的partition组成的,所进行的transformation和action是在partition上面进行的;
- 在存储系统的语境下,我们经常会用数据块(Blocks)来表示数据存储的基本单元。在逻辑关系上,RDD 的数据分片与存储系统的 Block 一一对应,也就是说一个 RDD 数据分片会被物化成一个内存或磁盘上的 Block。
本质上partition和block是等价的,只是看待的角度不同。在Spark storage模块中中存取数据的最小单位是block,所有的操作都是以block为单位进行的。RDD 的运算是基于 partition, 每个 task 代表一个 分区上一个 stage 内的运算闭包, task 被分别调度到 多个 executor上去运行, 那么是在哪里变成了 Block 呢, 我们以 spark 2.11 源码为准, 看看这个转变过程,一个 RDD 调度到 executor 上会运行调用 getOrCompute方法。
SparkEnv.get.blockManager.getOrElseUpdate(blockId, storageLevel, elementClassTag, () => {
readCachedBlock = false
computeOrReadCheckpoint(partition, context)
})
如果当前RDD的storage level不是NONE的话,表示该RDD在BlockManager中有存储,那么调用CacheManager中的getOrCompute()函数计算RDD,在这个函数中partition和block发生了关系:首先根据RDD id和partition index构造出block id (rdd_xx_xx),接着从BlockManager中取出相应的block。
内存计算
在 Spark 中,内存计算有两层含义:第一层含义就是众所周知的分布式数据缓存,第二层含义是Stage 内的流水线式计算模式。
- 在 Spark 的 DAG 中,顶点是一个个 RDD,边则是 RDD 之间通过 dependencies 属性构成的父子关系。
- 在 Spark 的开发模型下,应用开发实际上就是灵活运用算子实现业务逻辑的过程。开发者在分布式数据集如 RDD、 DataFrame 或 Dataset 之上调用算子、封装计算逻辑,这个过程会衍生新的子 RDD。与此同时,子 RDD 会把 dependencies 属性赋值到父 RDD,把 compute 属性赋值到算子封装的计算逻辑。以此类推,在子 RDD 之上,开发者还会继续调用其他算子,衍生出新的 RDD,如此往复便有了 DAG。从开发者的视角出发,DAG 的构建是通过在分布式数据集上不停地调用算子来完成的。
- DAG 毕竟只是一张流程图,Spark 需要把这张流程图转化成分布式任务,才能充分利用分布式集群并行计算的优势。DAG 转化的分布式任务在分布式环境中执行,其间会经历如下 4 个阶段(以 Actions 算子为起点,从后向前回溯 DAG,以 Shuffle 操作为边界去划分 Stages):
- 回溯 DAG 并划分 Stages;/DAGScheduler
- 在 Stages 中创建分布式任务Tasks 和任务组 TaskSet(囊括了用户通过组合不同算子实现的数据转换逻辑);/DAGScheduler
- 获取集群内可用的硬件资源情况;/SchedulerBackend
- 按照调度规则决定优先调度哪些任务 / 组;/TaskScheduler
- 分布式任务的分发;/SchedulerBackend
- 分布式任务的执行;/Executors
MapReduce 计算模型最大的问题在于,所有操作之间的数据交换都以磁盘为媒介。跟 MapReduce 相比,内存计算就是把数据和计算都挪到内存里去了吗?事情可能并没有你想象的那么简单。在 Spark 中,流水线计算模式指的是:在同一 Stage 内部,所有算子融合为一个函数,Stage 的输出结果由这个函数一次性作用在输入数据集而产生。所谓内存计算,不仅仅是指数据可以缓存在内存中,更重要的是通过计算的融合来大幅提升数据在内存中的转换效率,进而从整体上提升应用的执行性能。也因此,Shuffle 是切割 Stages 的边界,一旦发生 Shuffle,内存计算的代码融合就会中断,处理好Shuffle 是提升Spark 性能的关键。
任务调度
如果从供需的角度看待任务调度,DAGScheduler 就是需求端,SchedulerBackend 就是供给端(提供WorkerOffer)。TaskScheduler 基于既定的规则与策略达成供需双方的匹配与撮合。
SchedulerBackend 是对于资源调度器的封装与抽象,为了支持多样的资源调度模式如 Standalone、YARN 和 Mesos,SchedulerBackend 提供了对应的实现类。
- 对内,SchedulerBackend 用 ExecutorData 对 Executor 进行资源画像。对于集群中可用的计算资源,SchedulerBackend 会用一个叫做 ExecutorDataMap 的数据结构,来记录每一个计算节点中 Executors 的资源状态。
<标记 Executor 的字符串,ExecutorData>ExecutorData 用于封装 Executor 的资源状态,如 RPC 地址、主机地址、可用 CPU 核数和满配 CPU 核数等等,它相当于是对 Executor 做的“资源画像”。 - 对外,SchedulerBackend 以 WorkerOffer 为粒度提供计算资源,WorkerOffer 封装了 Executor ID、主机地址和 CPU 核数,用来表示一份可用于调度任务的空闲资源。
TaskScheduler 的调度策略分为两个层次,一个是不同 Stages 之间的调度优先级,一个是 Stages 内不同任务之间的调度优先级。
- 对于两个或多个 Stages,如果它们彼此之间不存在依赖关系、互相独立,在面对同一份可用计算资源的时候,它们之间就会存在竞争关系。TaskScheduler 提供了 2 种调度模式,分别是 FIFO(先到先得)和 FAIR(公平调度)
- 同一个 Stages 内部不同任务之间的调度优先级,相对来说简单得多,TaskScheduler 会优先挑选那些满足本地性级别要求的任务进行分发。众所周知,本地性级别有 4 种:Process local < Node local < Rack local < Any。
留下评论