多类型负载协调员Koordinator
简介
问题:是不是可以认为,用户设置的request 和limit ,除了最开始作为一个参考值之外,其它时候是没啥用的,全靠pod 真实的资源使用和 node 真实负载 根据priority 和 qos 进行调度了。 若不是为了最开始 有个参考作用,是不是 连request和limit 都不用设置,仅需设置下priority 和 qos 即可。
大佬解答:资源规格智能托管是调度技术里面非常重要的一个课题。
大体思路:先分级,再给低优原本高优的资源,尽量确保高优QoS,保证不了了把低优任务重调度,重调度用资源预留确保迁移成功。
使用
假如创建一个pod
apiVersion: v1
kind: Pod
metadata:
labels:
koordinator.sh/enable-colocation: "true"
name: test-pod
spec:
containers:
- name: app
image: nginx:1.15.1
resources:
limits:
cpu: "1"
memory: "3456Mi"
requests:
cpu: "1"
memory: "3456Mi"
Koordinator 提供了一个 ClusterColocationProfile CRD 和 对应的 Webhook ,修改和验证新创建的 Pod,注入 ClusterColocationProfile 中描述的字段。
apiVersion: config.koordinator.sh/v1alpha1
kind: ClusterColocationProfile
metadata:
name: colocation-profile-example
spec:
namespaceSelector:
matchLabels:
koordinator.sh/enable-colocation: "true"
selector:
matchLabels:
koordinator.sh/enable-colocation: "true"
qosClass: BE
priorityClassName: koord-batch
koordinatorPriority: 1000
schedulerName: koord-scheduler
labels:
koordinator.sh/mutated: "true"
annotations:
koordinator.sh/intercepted: "true"
patch:
spec:
terminationGracePeriodSeconds: 30
上面的 profile.yaml 文件描述了对所有含有标签 koordinator.sh/enable-colocation=true 的 Namespace 下的所有含有标签 koordinator.sh/enable-colocation=true 的 Pod 进行修改,注入 Koordinator QoSClass、Koordinator Priority 等。
pod 创建完成后 真实的样子
apiVersion: v1
kind: Pod
metadata:
annotations:
koordinator.sh/intercepted: true
labels:
koordinator.sh/qosClass: BE
koordinator.sh/priority: 1000
koordinator.sh/mutated: true
...
spec:
terminationGracePeriodSeconds: 30
priority: 5000
priorityClassName: koord-batch
schedulerName: koord-scheduler # schedulerName 换成了 koord-scheduler
containers:
- name: app
image: nginx:1.15.1
resources:
limits:
kubernetes.io/batch-cpu: "1000"
kubernetes.io/batch-memory: 3456Mi
requests:
kubernetes.io/batch-cpu: "1000"
kubernetes.io/batch-memory: 3456Mi
设计思路
打造现代化的云原生调度系统,Koordinator 坚持了如下的设计思路:
- 拥抱 Kubernetes 上游标准,基于 Scheduler-Framework 来构建调度能力,而不是实现一个全新的调度器。构建标准形成共识是困难的,但破坏是容易的,Koordinator 社区与 Kubernetes sig-scheduling 社区相向而行。
- QoS 是系统的一等公民,与业界大多数调度器更多的关注编排结果(静态)不同,Koordinator 更关注 Pod 运行时质量(QoS),因为对于调度系统的用户而言,运行时稳定性是其业务成功的关键。
- 状态自闭环,Koordinator 认为调度必须是一个完整的闭环系统,才能满足企业级应用要求。因此,我们在第一个版本就引入了状态反馈回路,节点会根据运行时状态调优容器资源,中心会根据节点运行时状态反馈做调度决策。
- 中心调度 + 单机调度联合决策,中心调度看到全局视角,其决策可以找到集群中最适合应用需求的节点,而单机调度可以在节点侧做一定的灵活度,以应对应用突发的流量颠簸。
- 调度 + 重调度密切配合,调度解决 Pod 一次性放置的问题,而重调度才是驱动集群资源编排长期保持最优化的关键。Koordinator 将建设面向 SLO 的重调度能力,持续的驱动应用的编排符合预定义的 SLO。
- 智能化、简单化,Koordinator 并不是就所有的选择暴露把问题留给客户,而是根据应用特征智能的为用户提供优化配置建议,简化用户使用 Kubernetes 的成本。
- 调度系统不止于解决调度、重调度、弹性伸缩等领域问题,一个完整的调度系统,需要具备基于历史数据驱动的自我迭代演进的能力。为工作负载的运行历史状态建立数据仓库,基于这些运行历史的大数据分析,持续的改进应用间在各个维度的的亲和、互斥关系,才能在用户运行时体验、集群资源利用效率同时达到最佳状态。
优先级和QoS
资源优先级策略的激进与保守,决定了集群资源的超卖容量,与资源稳定性的高低成反相关,以k8s PriorityClass声明,分为Product、Mid、Batch、Free四个等级,表现为 超卖资源从PriorityClass 高的Pod来,用到低的地方去。
QoS主要表现为使用的隔离参数不同,以Pod Label 的形式声明。
Koordinator 针对智能化调度的设计思路如下:
- 优先级:智能资源超卖,超卖的基本思想是去利用那些已分配但未使用的资源来运行低优先级的任务(一种新资源的上报和调度)。Koordinator 首先解决的是节点资源充分利用的问题,通过分析节点容器的运行状态计算可超卖的资源量,并结合 QoS 的差异化诉求将超卖的资源分配给不同类型的任务,大幅提高集群的资源利用率。 PS:已分配但未使用的资源,对应下图灰色和深蓝色之间的部分。
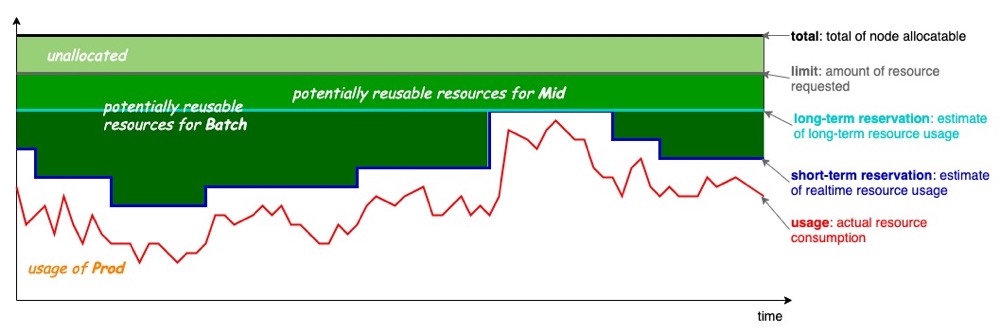
- Priority 和 QoS 是两个正交的维度,可以排列组合使用,部分排列组合不合法。
- QoS 感知的重调度,当节点中 Pod 的运行时 QoS 不符合预期时(干扰检测),Koordinator 将智能决策抑制更低优先级的任务亦或是迁移当前受到干扰的容器,从而解决应用 QoS 不满足导致的问题。问题:重调度的细节问题很多,Pod驱逐后 集群是否有资源保证可以运行,涉及到资源预留。
如何保证QoS
Koordinator v0.7: 为任务调度领域注入新活力
QoS 表示应用在节点上运行时得到的物理资源质量,以 CPU 为主维度,包含了System、LS、BE三类,LS又细分为LSE(Latency-Sensitive Excluded)、LSR(Latency-Sensitive Reserved)、LS(Latency-Sensitive)和 LS(Best Effort),保障策略
- CPU 方面,通过内核自研的 Group Identity 机制,针对不同 QoS 等级设置内核调度的优先级,优先保障 LSR/LS 的 cpu 调度,允许抢占 BE 的 CPU 使用,以达到最小化在线应用调度延迟的效果;对于 LS 应用的突发流量,提供了 CPU Burst 策略以规避非预期的 CPU 限流。
- 内存方面,由于容器 cgroup 级别的直接内存回收会带来一定延时,LS 应用普遍开启了容器内存异步回收能力,规避同步回收带来的响应延迟抖动。除此之外,针对末级缓存(Last-Level Cache,LLC)这种共享资源,为了避免大数据等 BE 应用大量刷 Cache 导致 LS/LSR 应用的 Cache Miss Rate 异常增大,降低流水线执行效率,引入了 RDT 技术来限制 BE 应用可分配的 Cache 比例,缩小其争抢范围。
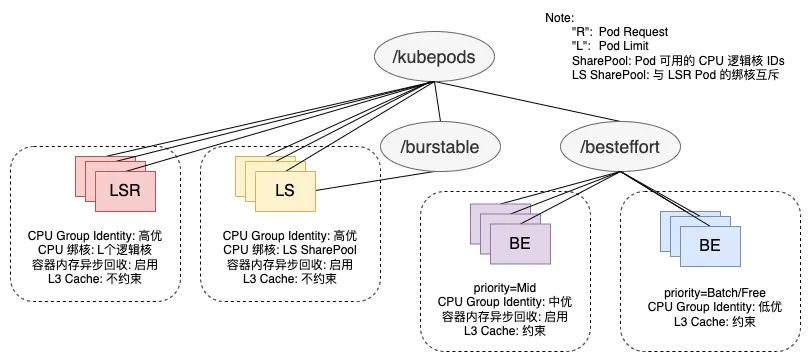
- CPU 资源质量。PS:CPU延时是指从任务变为可运行状态(即它已准备好运行,不再受阻塞),到它真正被操作系统调度器选中并执行的时间间隔。长时间的CPU延时可能会对业务造成影响,如网络数据包到达后,业务进程没有被及时调度运行进行收包从而导致网络延时等。
- 添加 K8S CPU limit 会降低服务性能? 可以查看container_cpu_cfs_throttled_periods_total 指标
- CPU Burst,例如对于 CPU Limit = 2 的容器,操作系统内核会限制容器在每 100 ms 周期内最多使用 200 ms 的 CPU 时间片,进而导致请求的响应时延(RT)变大。当容器真实 CPU 资源使用小于 cfs_quota 时,内核会将多余的 CPU 时间“存入”到 cfs_burst 中;当容器有突发的 CPU 资源需求,需要使用超出 cfs_quota 的资源时,内核的 CFS 带宽控制器(CFS Bandwidth Controller,简称 BWC) 会允许其消费其之前存到 cfs_burst 的时间片。最终达到的效果是将容器更长时间的平均 CPU 消耗限制在 quota 范围内,允许短时间内的 CPU 使用超过其 quota。
- CPU 拓扑感知调度。在多核节点下,进程在运行过程中经常会被迁移到其不同的核心,考虑到有些应用的性能对 CPU 上下文切换比较敏感,kubelet 提供了 static 策略,允许 Guarantee 类型 Pod 独占 CPU 核心。CPU 绑核并不是“银弹”,若同一节点内大量 Burstable 类型 Pod 同时开启了拓扑感知调度,CPU 绑核可能会产生重叠,在个别场景下反而会加剧应用间的干扰。因此,拓扑感知调度更适合针对性的开启。
- 针对低优先级离线容器的 CPU 资源压制能力:内核Group Identity,Group Identity 功能可以对每一个容器设置身份标识,以区分容器中的任务优先级,系统内核在调度包含具有身份标识的任务时,会根据不同的优先级做相应处理。比如高优先级任务 有更多资源抢占机会。
- 在 CPU 被持续压制的情况下,BE 任务自身的性能也会受到影响,将其驱逐重调度到其他空闲节点反而可以使任务更快完成。
- 内存资源质量
- 时延敏感型业务(LS)和资源消耗型(BE)任务共同部署时,资源消耗型任务时常会瞬间申请大量的内存,使得系统的空闲内存触及全局最低水位线(global wmark_min),引发系统所有任务进入直接内存回收的慢速路径(内存申请延时,ack-sysom-monitor Exporter 对内核延迟进行可视化分析与定位),进而导致延敏感型业务的性能抖动。
- 后台异步回收,当容器内存使用超过 memory.wmark_ratio 时,内核将自动启用异步内存回收机制,提前于直接内存回收,改善服务的运行质量。
干扰检测
干扰检测和优化的过程可以分为以下几个过程:
- 干扰指标的采集和分析:选取干扰检测使用的指标需要考虑通用性和相关性,并尽量避免引入过多额外的资源开销。
- 干扰识别模型及算法:分为横向和纵向两个维度,横向是指分析同一应用中不同容器副本的指标表现,纵向是指分析在时间跨度上的数据表现,识别异常并确定“受害者”和“干扰源”。
- 干扰优化策略:充分评估策略成本,通过精准的压制或驱逐策略,控制“干扰源”引入的资源竞争,或将“受害者”进行迁移。同时建设相关模型,用于指导应用后续的调度,提前规避应用干扰的发生。
Koordinator v1.1发布:负载感知与干扰检测采集当前 Koordinator 已经实现了一系列 Performance Collector,在单机侧采集与应用运行状态高相关性的底层指标,并通过 Prometheus 暴露出来,为干扰检测能力和集群应用调度提供支持。目前提供以下几个指标采集器:
- CPICollector:用于控制 CPI 指标采集器。CPI:Cycles Per Instruction。指令在计算机中执行所需要的平均时钟周期数。CPI 采集器基于 Cycles 和 Instructions 这两个 Kernel PMU(Performance Monitoring Unit)事件以及 perf_event_open(2) 系统调用实现。
- PSICollector:用于控制 PSI 指标采集器。PSI:Pressure Stall Information。表示容器在采集时间间隔内,因为等待 cpu、内存、IO 资源分配而阻塞的任务数。使用 PSI 采集器前,需要在 Anolis OS 中开启 PSI 功能,您可以参考文档获取开启方法。
腾讯云:存量 Pod 在节点上也有可能发生高负载,这时我们在节点上部署 Pod-Problem-Detecor、NodeProblem-Detecor,检测出哪个 Pod 会导致节点高负载,哪些 Pod 属于敏感 Pod,通过事件上报告诉API Server,让调度器将异常 Pod、敏感 Pod 重新调度到空闲节点。
云原生场景下,如何缓减容器隔离漏洞,监控内核关键路径?OpenCloudOS 社区中的容器级别的性能跟踪机制——SLI,从容器的角度对 CPU、内存资源的竞争情况进行跟踪、观测,从而为容器性能问题的定位、分析提供可靠的指标。
- 用户态周期性监测:SLI 通过cgroup 接口提供容器的性能数据,用户态可以通过这些数据对容器性能进行监控。
- 容器内负载情况监控。容器内处于 R/D 态的进程平均数量(分别是 1min、5min、15min 的容器平均负载),R 进程数量指标:评估容器内进程数量是否 overload。D进程数量指标:D状态进程的数量可以反馈IO等待以及锁竞争等的情况
- 进程在内核态执行时间。内核态时间可能是因为系统调用、中断或者缺页异常等原因引起的。内核态的执行时间过长,会导致用户业务有较大延迟,从而引起性能抖动问题。
- 调度延迟, 监控容器进程的调度延迟信息(容器进程在调度队列上的等待时间),反馈容器的 CPU 竞争情况,过大的调度延迟会导致业务出现性能抖动。
- iowait 延迟,进程 IO 完成而引起的延迟时间。反馈容器进程的 IO 性能问题,过大的 IO 延迟会让业务文件访问产生性能问题
- 内存延迟,监控容器进程的内存申请延迟信息,反馈容器的内存申请性能情况,过大的内存申请延迟会导致业务出现性能抖动。
- 容器场景下,各个容器是相互独立的应用程序。由于不同容器在运行过程中,各自的资源使用情况、运行情况都不同,需要有一个独立的地方记录不同容器内核层面的异常日志信息,上层应用可以根据日志信息,直接定位到对应容器,从而进行合理的调度等操作;mbuf 就应运而生。
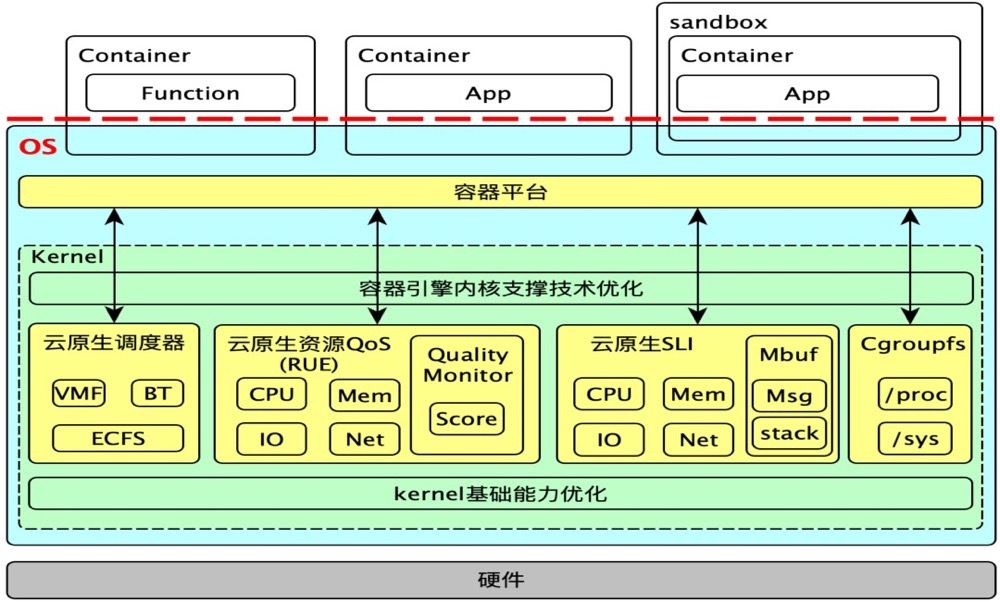
借助mbuf 如何实现混部时的干扰检测呢? 比如在线容器A延迟增加,主要原因是离线计算容器B导致(如何定位到)?在线容器A延迟增加,触发阈值打印的是prev进程的信息以及堆栈,这样就可以知道是被谁干扰的。PS:从cpu 执行的视角,cpu 时间被分摊给容器ABC等等,比例一段时间内是固定的,现在容器A延迟增加,cpu时间分摊比例相对了之前,多了很多容器B的,就知道是被B干扰的?
容器干扰检测与治理(上篇) 未细读。
源码分析
koordinator
/cmd
/koord-descheduler
/koord-manager # 中心管控
/koord-runtime-proxy # 充当 Kubelet 和 Containerd 之间的代理,它用于拦截 CRI 请求,并应用一些资源管理策略, 如混合工作负载编排场景下按实例优先级设置不同的 cgroup 参数,针对最新的 Linux 内核、CPU 架构应用新的隔离策略等。
/koord-scheduler
/koordlet
/pkg
调度器
koordinator
/cmd
/koord-scheduler
/pkg
/scheduler
/apis
/eventhandlers
/frameworkext
/plugins
/batchresource
/elasticquota
/loadaware
/nodenumaresource
/reservation
- k8s scheduler本身代码抽象比较好,对外提供
"k8s.io/kubernetes/cmd/kube-scheduler/app"包,一两行就可以启动一个调度器,koord-scheduler 主要提供了 plugin 实现,注册到 plugin regisry 中即可。cmd := app.NewSchedulerCommand( ... // 添加plugin ); cmd.Execute() - 各个plugin 代码按需求分开看即可,后续的有 看到感兴趣的技术点持续补充
Koordinator 将各优先级资源以标准的extend-resource 形式更新到Node信息中。
apiVersion: v1
kind: Node
metadata:
name: node-1
status:
allocatable:
cpu: 64
memory: 256Gi
kubernetes.io/batch-cpu: "500" # 节点可以超卖的资源总量
kubernetes.io/batch-memory: 50Gi
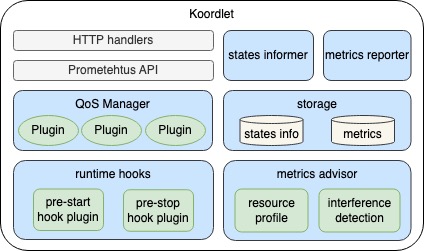
koordlet
- 细粒度的容器指标采集,包括资源消耗、容器进程性能等
- 面向不同QoS等级Pod的干扰检测和调节策略能力
- 提供一系列的Runtime Proxy 插件,支持精细化的QoS 参数注入
koordinator
/cmd
/koordlet
/pkg
/koordlet
/executor
/metrics
/pleg
/qosmanager
/resmanager
/cpu_burst.go
/cpu_evict.go
/memory_evict.go
/koordlet.go
koordlet 依次启动各个组件,各个组件又由多个功能模块/plugin 组成,每个功能模块运行一个小型control loop。比如 resManager 包含 cpu burst 模块,大致实现是check 所在node 上的所有pod,有需要 cpu burst的pod,就向pod 及container 对应cgroup 目录写入一个文件/配置。
// koordlet 依次启动各个组件
daemon, err := agent.NewDaemon(cfg)
daemon.Run(stopCtx.Done())
go func() {
metricCache.Run
}()
go func() {
resManager.Run
}()
go func() {
qosManager.Run
}()
...
以resManager 组件为例
// resManager 启动各个功能模块
func (r *resmanager) Run(stopCh <-chan struct{}) error {
defer utilruntime.HandleCrash()
klog.Info("Starting resmanager")
r.podsEvicted.Run(stopCh)
go configextensions.RunQOSGreyCtrlPlugins(r.kubeClient, stopCh)
util.RunFeature(r.reconcileBECgroup, ...)
cgroupResourceReconcile := NewCgroupResourcesReconcile(r)
util.RunFeatureWithInit(..., cgroupResourceReconcile.reconcile,...)
cpuSuppress := NewCPUSuppress(r)
util.RunFeature(cpuSuppress.suppressBECPU, ...)
cpuBurst := NewCPUBurst(r)
util.RunFeatureWithInit(..., cpuBurst.start,...)
cpuEvictor := NewCPUEvictor(r)
util.RunFeature(cpuEvictor.cpuEvict, ...)
memoryEvictor := NewMemoryEvictor(r)
util.RunFeature(memoryEvictor.memoryEvict, ...)
rdtResCtrl := NewResctrlReconcile(r)
util.RunFeatureWithInit(...,rdtResCtrl.reconcile,...)
klog.Infof("start resmanager extensions")
plugins.SetupPlugins(r.kubeClient, r.metricCache, r.statesInformer)
utilruntime.Must(plugins.StartPlugins(r.config.QOSExtensionCfg, stopCh))
klog.Info("Starting resmanager successfully")
<-stopCh
return nil
}
以cpu burst 为例,找到 需要 burst 的pod,更新其cgroup 配置。
func (b *CPUBurst) start() {
// sync config from node slo
nodeSLO := b.resmanager.getNodeSLOCopy()
b.nodeCPUBurstStrategy = nodeSLO.Spec.CPUBurstStrategy
podsMeta := b.resmanager.statesInformer.GetAllPods()
// get node state by node share pool usage
nodeState := b.getNodeStateForBurst(*b.nodeCPUBurstStrategy.SharePoolThresholdPercent, podsMeta)
for _, podMeta := range podsMeta {
// ignore non-burstable pod, e.g. LSR, BE pods
// merge burst config from pod and node
cpuBurstCfg := genPodBurstConfig(podMeta.Pod, &b.nodeCPUBurstStrategy.CPUBurstConfig)
b.applyCPUBurst(cpuBurstCfg, podMeta) // set cpu.cfs_burst_us for containers
b.applyCFSQuotaBurst(cpuBurstCfg, podMeta, nodeState) // scale cpu.cfs_quota_us for pod and containers
}
b.Recycle()
}
// set cpu.cfs_burst_us for containers
func (b *CPUBurst) applyCPUBurst(burstCfg *slov1alpha1.CPUBurstConfig, podMeta *statesinformer.PodMeta) {
pod := podMeta.Pod
containerMap := make(map[string]*corev1.Container)
for i := range pod.Spec.Containers {
container := &pod.Spec.Containers[i]
containerMap[container.Name] = container
}
podCFSBurstVal := int64(0)
for i := range pod.Status.ContainerStatuses {
containerStat := &pod.Status.ContainerStatuses[i]
container, exist := containerMap[containerStat.Name]
containerCFSBurstVal := calcStaticCPUBurstVal(container, burstCfg)
containerDir, burstPathErr := koordletutil.GetContainerCgroupPathWithKube(podMeta.CgroupDir, containerStat)
if system.ValidateResourceValue(&containerCFSBurstVal, containerDir, system.CPUBurst) {
podCFSBurstVal += containerCFSBurstVal
ownerRef := executor.ContainerOwnerRef(pod.Namespace, pod.Name, container.Name)
containerCFSBurstValStr := strconv.FormatInt(containerCFSBurstVal, 10)
updater := executor.NewCommonCgroupResourceUpdater(ownerRef, containerDir, system.CPUBurst, containerCFSBurstValStr)
updated, err := b.executor.UpdateByCache(updater)
}
} // end for containers
f
podDir := koordletutil.GetPodCgroupDirWithKube(podMeta.CgroupDir)
if system.ValidateResourceValue(&podCFSBurstVal, podDir, system.CPUBurst) {
ownerRef := executor.PodOwnerRef(pod.Namespace, pod.Name)
podCFSBurstValStr := strconv.FormatInt(podCFSBurstVal, 10)
updater := executor.NewCommonCgroupResourceUpdater(ownerRef, podDir, system.CPUBurst, podCFSBurstValStr)
updated, err := b.executor.UpdateByCache(updater)
}
}
executor.UpdateByCache 实质是 特定cgroup 目录写入一个文件。
留下评论