K8S YAML 资源清单管理方案
简介
Kubernetes 会是容器化崛起之路的终点线吗?它达到了人们对云原生时代技术基础设施的期望了吗?从易用角度来看,坦白说差距还非常大。云原生基础设施的其中一个重要目标,是接管掉业务系统复杂的非功能特性,这会让业务研发与运维工作变得足够简单,不受分布式的牵绊。但如果要用 Kubernetes 部署一套Spring Cloud 版的 Fenix’s Bookstore,你需要分别部署一个到多个的配置中心、注册中心、服务网关、安全认证、用户服务、商品服务、交易服务,然后要对每个微服务都配置好相应的 Kubernetes 工作负载与服务访问,为每一个微服务的 Deployment、ConfigMap、StatefulSet、HPA、Service、ServiceAccount、Ingress 等资源都编写好元数据配置。这个过程最难的地方不仅在于繁琐,还在于要想写出合适的元数据描述文件,你既需要懂开发(网关中服务调用关系、使用容器的镜像版本、运行依赖的环境变量等等这些参数,只有开发最清楚),又需要懂运维(要部署多少个服务、配置何种扩容缩容策略、数据库的密钥文件地址等等,只有运维最清楚),有时候还需要懂平台(需要什么样的调度策略、如何管理集群资源,通常只有平台组、中间件组或者核心系统组的同学才会关心),一般企业根本找不到合适的角色来为它管理、部署和维护应用。
这些困难的实质是源于 Docker 容器镜像封装了单个服务,而 Kubernetes 通过资源封装了服务集群,却没有一个载体真正封装整个应用,封装应用的方法没能将开发、运维、平台等各种角色的关注点恰当地分离。但是,既然在微服务时代,应用的形式已经不再局限于单个进程,那就也该到了重新定义“以应用为中心的封装”这句话的时候了。至于具体怎样的封装才算是正确的,其实到今天也还没有特别权威的结论,不过经过人们的尝试探索,已经能够窥见未来容器应用的一些雏形了。Kustomize 和 Helm是封装“无状态应用”的典型代表,Operator 与 OAM 是支持有状态应用的封装方式。
PodPreset
开发人员习惯的写的,是最简单的pod
apiVersion: v1
kind: Pod
metadata:
name: website
labels:
app: website
role: frontend
spec:
containers:
- name:website
image: nginx
ports:
- containerPort:80
但对运维来说,在实际环境中还需添加大量的配置,此时,运维可以事先定义一个PodPreset.yaml,并创建一个PodPresetkubectl create -f preset.yaml。 之后开发创建的pod(有一个规则匹配) 都会自动加上 preset.yaml 指定的配置。
Kustomize
一旦开始处理多种资源类型,Kubernetes 资源的配置文件就会真正开始泛滥,尤其是当环境之间的差异很小时,例如开发与生产环境。直接通过 kubectl 来管理一个应用,你会发现这十分蛋疼。
思路
应用就是一组具有相同目标的 Kubernetes 资源的集合,如果逐一管理、部署每项资源元数据太麻烦啰嗦的话,那就提供一种便捷的方式,把应用中不变的信息与易变的信息分离开,以此解决管理问题;把应用所有涉及的资源自动生成一个多合一(All-in-One)的整合包,以此解决部署问题。
Kustomize是一种针对 YAML 的模版引擎的变体。Kustomize 使用Kustomization 文件来组织与应用相关的所有资源,Kustomization 本身也是一个以 YAML 格式编写的配置文件,里面定义了构成应用的全部资源,以及资源中需根据情况被覆盖的变量值。Kustomize 的主要价值是根据环境来生成不同的部署配置。只要建立多个 Kustomization 文件,开发人员就能以基于基准进行派生(Base and Overlay)的方式,对不同的模式(比如生产模式、调试模式)、不同的项目(同一个产品对不同客户的客制化)定制出不同的资源整合包。
在配置文件里,无论是开发关心的信息,还是运维关心的信息,只要是在元数据中有描述的内容,最初都是由开发人员来编写的,然后在编译期间由负责 CI/CD 的产品人员针对项目进行定制。最后在部署期间,由运维人员通过 kubectl 的补丁(Patch)机制更改其中需要运维去关注的属性,比如构造一个补丁来增加 Deployment 的副本个数,构造另外一个补丁来设置 Pod 的内存限制,等等。
k8s
├── base
│ ├── deployment.yaml
│ ├── kustomization.yaml
│ └── service.yaml
└── overlays
└── prod
│ ├── load-loadbalancer-service.yaml
│ └── kustomization.yaml
└── debug
└── kustomization.yaml
一个由 kustomize 管理的应用结构,它主要由 base 和 overlays 目录组成,Base下存放的是模版文件(一般是在base下维护全量yaml?),Overlays是不同环境的差异化管理目录,这两个目录下都需要有kustomization.yaml文件,这个文件用于描述如何生成定制的资源。Kustomize 使用 Base、Overlay 和 Patch 生成最终配置文件的思路,与 Docker 中分层镜像的思路有些相似(PS:所以叫overlays,指定 Kubernetes 将使用哪些策略修补资源),这样的方式既规避了以“字符替换”对资源元数据文件的入侵,也不需要用户学习额外的 DSL 语法(比如 Lua)。但是,毕竟 Kustomize 只是一个“小工具”性质的辅助功能,要做的事、要写的配置,最终都没有减少,只是不用反复去写罢了。PS:kubectl apply -k 带有 kustomization.yaml的目录 就可以看做 kubectl apply -f kustomization.yaml 引用的所有resource manifest
Kustomize 提供的两个核心功能 —— 聚合资源和修补字段。
# let's modify the contents of kustomization.yaml thus:
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
namespace: frontend
commonLabels:
app: frontend
resources: # 聚合资源
- service.yaml
- deployment.yaml
patches: # 修补字段
- target:
kind: Deployment
name: frontend
patch: |-
- op: replace
path: /spec/replicas
value: 15
使用
$ cd k8s/
# 从 Kubernetes v1.14 开始,kubectl 就完全支持 Kustomize 和 kustomization 文件。
# 部署基本配置
$ kubectl apply -k k8s/base
# 部署生产配置
$ kubectl apply -k k8s/overlays/prod
# 输出生产配置对应的yaml文件
$ kustomize build k8s/overlays/prod
helm
Helm 一开始的目标就很明确:如果说 Kubernetes 是云原生操作系统的话,那 Helm 就要成为这个操作系统上面的应用商店与包管理工具。如 Debian 系的 apt-get 命令与 dpkg 格式、RHEL 系的 yum 命令与 rpm 格式,Helm 主要用来管理 Chart 包,Helm Chart 包中包含一系列 YAML 格式的 Kubernetes 资源/object定义文件,以及这些资源的配置,可以通过 Helm Chart 包来整体维护这些资源。
Kubernetes应用管理深度剖析完整的应用通常不只是简单的deployment,StatefulSet等负载资源,通常还包括配套的service, PV/PVC, configmap等一系列资源。我们在进行实例下发、升级、更新换代等一系列生命周期操作时,这些资源都需要统筹考虑。Kubernetes只面向Kubernetes资源对象,而Helm则真正意义上定义了Kuberentes App的边界。
详解 Kubernetes 包管理工具 HelmHelm 是一个可执行文件,具有以下特性:
- Kubernetes 管理组件和应用程序的部署生命周期
- 基于模板的定义,支持跨部署环境 (例如,开发、质保、生产) 的可移植性
- 钩子机制可以在部署生命周期的不同阶段注入特定于用例的代码
- 部署测试框架
使用 helmfile 声明式部署 Helm Chart 未理解。
原理
Helm3 架构图如下:
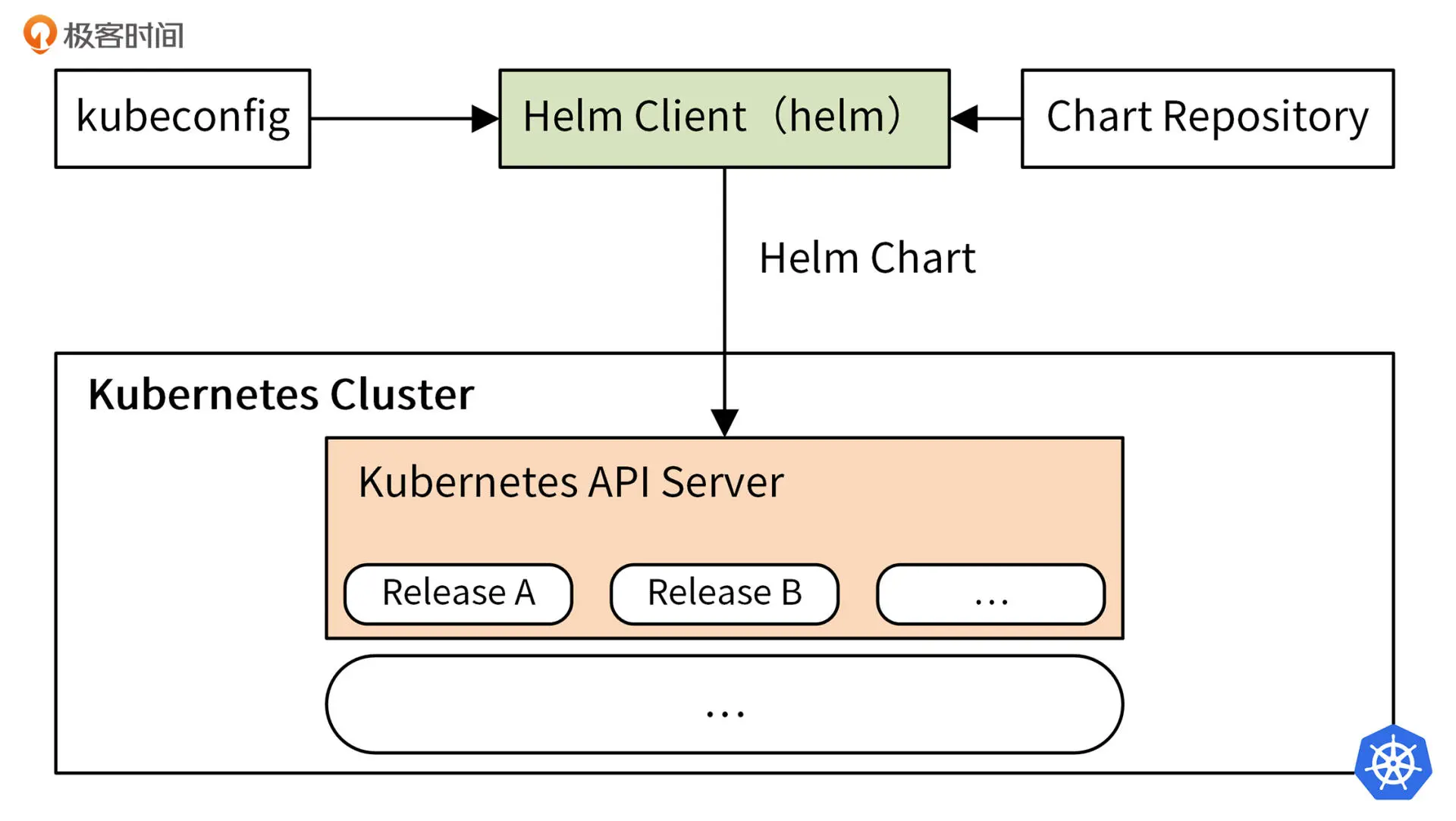
Helm的打包格式叫做chart,helm命令从Chart Repository中下载 Helm Chart 包,读取kubeconfig文件,并构建 kube-apiserver REST API 接口的 HTTP 请求。通过调用 Kubernetes 提供的 REST API 接口,将 Chart 包中包含的所有以 YAML 格式定义的 Kubernetes 资源,在 Kubernetes 集群中创建。这些资源以 Release 的形式存在于 Kubernetes 集群中,每个 Release 又包含多个 Kubernetes 资源,例如 Deployment、Pod、Service 等。
模板文件
开发 Helm Chart 需要使用预定义的目录结构组织文件,比如官方仓库中 WordPress Chart 的目录结构是这样的:
WordPress
|—— charts // 存放依赖的chart
├── templates // 存放应用一系列 k8s 资源的 yaml 模板,通过渲染变量得到部署文件
│ ├── NOTES.txt // 为用户提供一个关于 chart 部署后使用说明的文件
| |—— _helpers.tpl // 存放能够复用的模板
│ ├── deployment.yaml
│ ├── externaldb-secrets.yaml
│ └── 版面原因省略其他资源文件
│ └── ingress.yaml
└── Chart.yaml // chart 的基本信息(名称、版本、许可证、自述、说明、图标,等等)
└── requirements.yaml // 应用的依赖关系,依赖项指向的是另一个应用的坐标(名称、版本、Repository 地址)
└── values.yaml // 存放全局变量, templates 目录中模板文件中用到变量的值
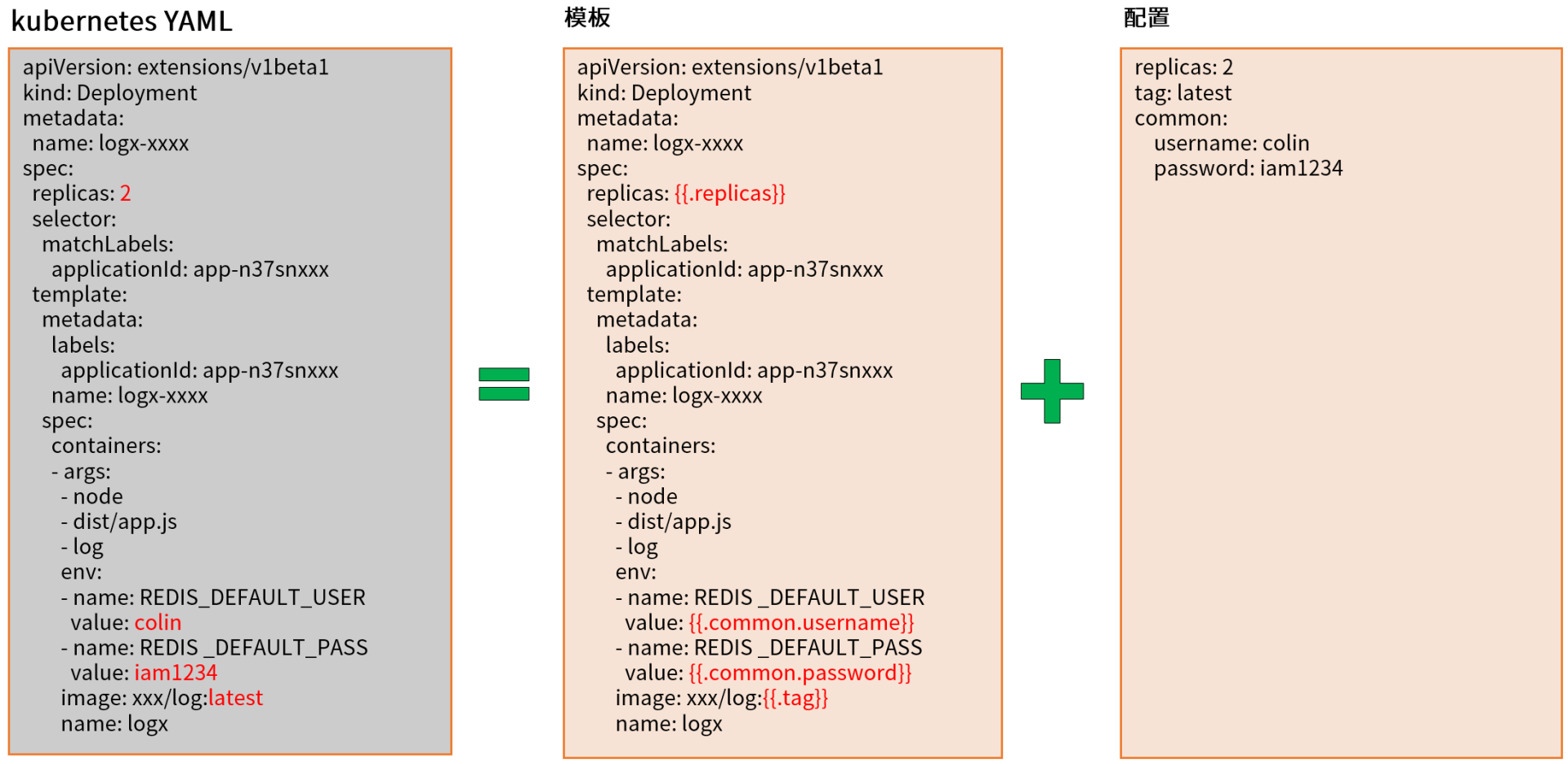
Helm Chart 中的 YAML 文件是使用 Helm 的模板语言开发的,其中的双大括号包扩起来的部分是Go template,其中的Values是在values.yaml文件中定义的。下面是由 helm create 生成的被模板化的 ingress 描述示例,提供了几个变量,用来定义和配置 ingress 资源,包括是否应该创建 ingress 资源。
```yamlapiVersion: apps/v1 kind: Deployment metadata: labels: app.kubernetes.io/component: controller name: namespace: annotations:
抛开 k8s yaml的要求 将自定义配置 集中在一起,这为部分用户不需要懂 k8s yaml 提供了可能性。
```yaml
# values.yaml
rbac:
...
serviceAccount:
...
controller:
name: controller
image:
registry: registry.k8s.io
image: ingress-nginx/controller
annotations: {...}
labels: {...}
通过模板,Helm 提供了对 Kubernetes 资源如何部署的大量控制。规划良好的模板模式可以生成单个部署包,使 Helm Chart 能够成功部署,范围从开发人员工作站上的单节点 Kubernetes 集群到生产 Kubernetes 集群。
values.yaml 文件可以有多个
values-test-env.yaml // 测试环境 Helm values 文件。
values-pre-env.yaml // 预发环境 Helm values 文件。
values-prod-env.yaml // 生产环境 Helm values 文件。
使用
helm 日常操作也是区分namespace 的。
$ helm repo list // 查看仓库列表,有点yum 的感觉
# helm install [NAME] [CHART] [flags]
# [CHART] 是仓库中的名字,如果以 ./ 开头,则为本地目录
$ helm install happy-panda bitnami/wordpress # 类似于yum install
# 把对应的 values 值和生成的最终的资源清单文件打印出来,不会真正的去部署一个release实例
$ helm install —debug —dry-run happy-panda bitnami/wordpress
There are five different ways you can express the chart you want to install:
- By chart reference:
helm install mymaria example/mariadb - By path to a packaged chart:
helm install mynginx ./nginx-1.2.3.tgz - By path to an unpacked chart directory:
helm install mynginx ./nginx - By absolute URL:
helm install mynginx https://example.com/charts/nginx-1.2.3.tgz - By chart reference and repo url:
helm install --repo https://example.com/charts/ mynginx nginx
# 仓库操作
# 添加阿里云的 chart 远程仓库
helm repo add aliyun https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts
"aliyun" has been added to your repositories
# 查看配置的 chart 仓库有哪些
helm repo list
# 删除 chart 仓库地址
helm repo remove aliyun
# 从指定 chart 仓库地址搜索 chart
helm search repo aliyun
# 搜索和下载Chart
# 查看阿里云 chart 仓库中的 memcached
# helm search repo aliyun |grep memcached
# 查看 chart 信息
helm show chart aliyun/memcached
# 下载 chart 包到本地
helm pull aliyun/memcached
留下评论