学习mesh
前言
服务网格在百度核心业务大规模落地实践 具体细节倒还好,比较有价值的就是提出了落地图景和理想化状态。
云原生时代的DevOps平台设计之道大胆设想一下,开发人员只需要在两个服务组件之间拖动一条表征微服务调用关系的线,就可以生成对应的微服务配置。这样的操作体验完全可以使注册中心、控制平面这种微服务领域中复杂的概念对开发人员屏蔽。本质上讲,维护注册中心或者控制平面也是运维人员需要关心的工作。PS:配置文件 + 业务client sdk ==> 无配置化 + 业务client sdk ==> 无配置 + 通用sdk
缘起
分布式微服务时代的 TCP —— service mesh随着业务的不断发展,微服务的数量越来越多,微服务间的通信网络也变得十分复杂,在这个角度看,服务间通信已经不在是端到端的调用了,而是”多个节点访问多个节点”的关系了。在处理分布式微服务架构中”多个节点”的互相通信上,需要解决很多通用的问题,service mesh 要做微服务时代的 TCP,也就是在解决上述问题的基础上,还要做到通用化、标准化,解耦合业务进程与 mesh。
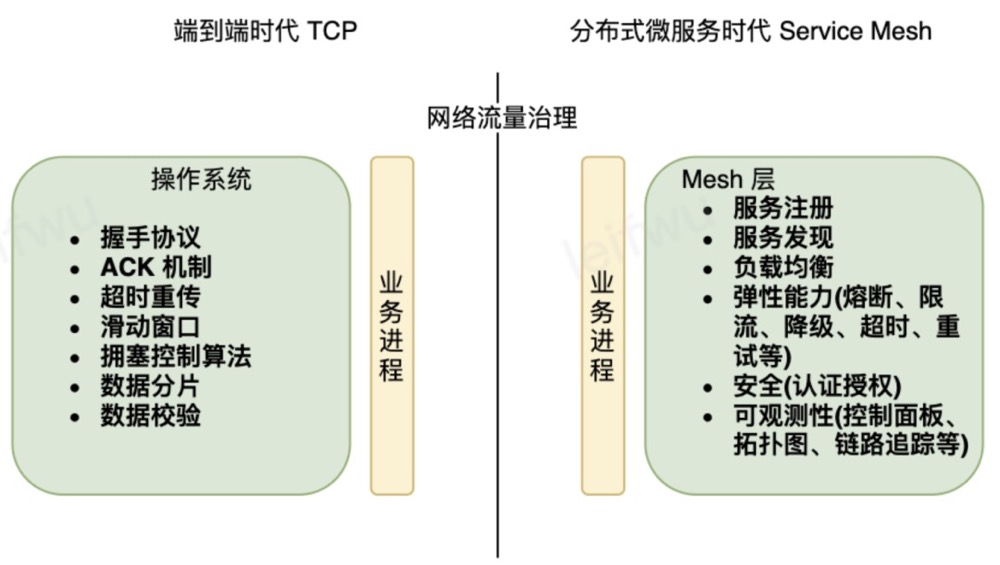
Service Mesh 的未来在于网络 mesh 正在和ebpf 结合起来,尽量在内核实现所有功能。
问题
蚂蚁集团 Service Mesh 进展回顾与展望 提供了演进脉络。
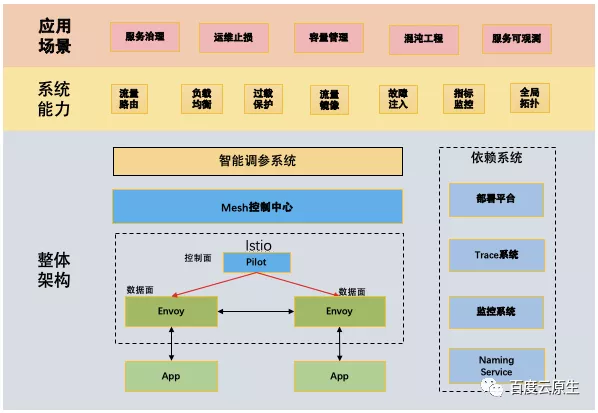
考虑的问题
- 技术选型
- 性能问题和资源问题
- 网络接入:iptables 还是直通
- 性能优化:一跳还是两跳,面向失败设计,Service Mesh 可以 fallback 为直连模式。
- Sidecar自身会消耗资源,增加业务的成本。
- 随着Sidecar规模的增长,开源的控制平面计算开销变大,导致Mesh配置下发时间变长,甚至无法工作。
- 改造成本
- 各种各样的微服务框架网格化改造和适配
- 各种各样的通信协议支持
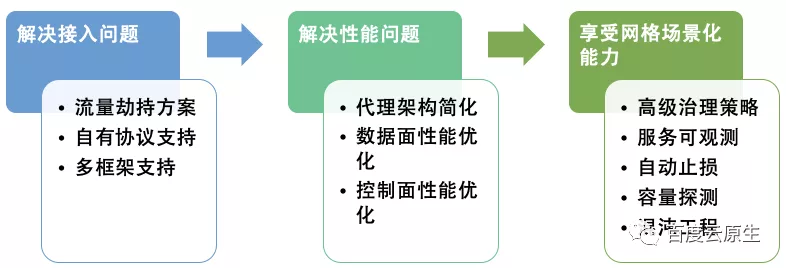
享受网格场景场景化能力
- 服务治理策略
- 延迟感知负载均衡,基于Server 响应时间进行流量调度,尽量多调度给延迟低的Server
- 错误码调权,基于自定义错误码进行Server 调权,加速异常Server 节点的驱逐
- 备份重试,通过定时触发备份重试请求优化长度,提高可用性
- 动态备份重试,按分位值动态设置备份重试请求触发时间,支持备份重试请求熔断,防止重试风暴。
- 流量丢弃/全局流控,在线实施配置流量丢弃比例,摘除下游,提供统一流控预案
- 超时透传,实时透传上游超时给下游,帮助业务实现动态TTL机制
- trace 平台和监控平台
- 自动止损 ==> 稳定性预案平台, 根据监控平台的指标异常实时调参,执行流量降级、切机房、切流等 ==> 反馈到监控平台 ==> 稳定性预案平台继续调参, 实现闭环
- 混沌工程 深度解读:分布式系统韧性架构压舱石OpenChaos
- 系统容量评估(压测)
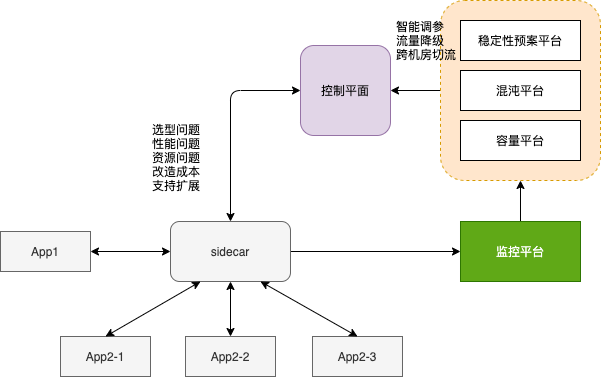
通过接入Mesh服务网格得到的一些启示:
- 服务网格不是微服务治理的银弹
- 完全无入侵的,支持所有协议,所有框架和所有治理策略的 Mesh 方案是不存在的
- 大规模工业化落地的平滑、稳定可控接入方案,涉及到大量对已有服务治理组件的兼容升级和改造
- 服务网格确实实现了业务逻辑和服务治理架构的解耦,解锁了很多新能力
- 服务网格结合可观测、故障止损、混沌工程,容量管理等场景化,才能发挥出最大价值
规范
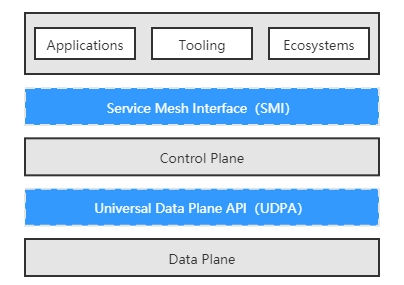
SMI 和 UDPA 的关系与我在容器运行时中介绍到的 CRI 和 OCI 规范之间的关系很相似。
- SMI 规范提供了外部环境(实际上就是 Kubernetes)与控制平面交互的标准,使得 Kubernetes 及在其之上的应用,能够无缝地切换各种服务网格产品;SMI 与 Kubernetes 是彻底绑定的,规范的落地执行完全依靠在 Kubernetes 中部署 SMI 定义的 CRD 来实现。包括四方面的 API
- 流量规范(Traffic Specs),目标是定义流量的表示方式,比如 TCP 流量、HTTP/1 流量、HTTP/2 流量、gRPC 流量、WebSocket 流量等应该如何在配置中抽象和使用。
- 流量拆分(Traffic Split),目标是定义不同版本服务之间的流量比例,提供流量治理的能力,比如限流、降级、容错,等等,以满足灰度发布、A/B 测试等场景。
- 流量度量(Traffic Metrics),目标是为资源提供通用集成点,度量工具可以通过访问这些集成点来抓取指标。这部分完全遵循了 Kubernetes 的Metrics API进行扩充。
- 流量访问控制(Traffic Access Control),目标是根据客户端的身份配置,对特定的流量访问特定的服务提供简单的访问控制。
- UDPA 规范则提供了控制平面与数据平面交互的标准,使得服务网格产品能够灵活地搭配不同的边车代理,针对不同场景的需求,发挥各款边车代理的功能或者性能优势。
技术决策案例
欢乐游戏 Istio 云原生服务网格三年实践思考从笔者个人的观察来讲,istio 网格最具吸引力的,实际上就两点:
- 开放技术栈的想象空间,随着 istio、envoy、gRPC 整个生态越来越丰富,未来可能会有更多能力提供,开箱即用,业务团队不必投入开发;
- 多语言适配,不用为每种语言开发治理 sdk,例如 C++ 编写的 envoy 可以给所有用 gRPC 的 service 使用。 至于熔断、限流、均衡、重试、镜像、注入,以及 tracing 监控之类的能力,严格来讲不能算到网格头上,用 sdk 也是一样可以实现的。在团队语言统一的时候,只用维护一种语言版本的 sdk,此时采用治理 sdk 方案也是可行的,也就是所谓的微服务框架方案。采用 sdk 方式下的版本维护问题,以及后期进一步演进网格的问题,这些都不难解决。对于我们自己来讲,因为恰好有引进 golang 以及 gRPC,所以现在再看,选择 istio 作为网格方案也算合适。
接入网格,要考虑天时地利人和。即,需要满足一些基本条件:
- 需要项目阶段允许,如果团队本身一直在做快版本内容迭代,业务需求都忙不过来,恐怕也很难有人力保障。
- 要有基础设施环境支持(我们使用了腾讯云的 tke mesh 服务),这样不至于所有东西都从零开始。
此外,对于这类大的技术优化,还有必要先统一思想:
- 自上而下,获得各级管理干系人的认可,这样才好做较大人力的投入。
- 自下而上,发动同学们深度介入探讨,使得整体的方向、方案得到大家的认可,这样大家才有干劲。
谈谈我对服务网格的理解 有几个配图很有感觉
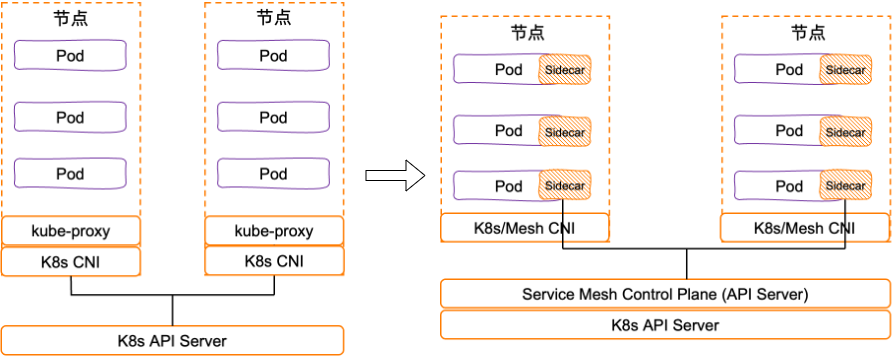
去哪儿网 Service Mesh 落地实践:100%容器化打底,业务友好是接入关键
- 中小企业首先考虑的更多是业务。业务越来越多、越来越复杂后,才可能会出现多语言、多框架的问题。只有确实出现这个问题时,才应该开始考虑是否引入 Service Mesh。此外还需要考虑自身的基础设施、团队技术储备等是否支持落地。Service Mesh 是利用低复杂的技术去解决高复杂度的问题,如果本身复杂度不高,引入 Service Mesh 这样的技术只会增加复杂度,得不偿失。
- 还有一个值得关注的方面就是性价比。引入 Service Mesh 的新增成本包括 sidecar 所占有的资源,比如每个 sidecar 占用的 CPU、内存、磁盘以及其他如 trace 存储、日志存储等存储资源。另外,像请求耗时增加、系统开发维护等会产生相应成本,因此去哪儿网目前对于各类日志是按需开启,只打印耗时高的 trace 信息。
留下评论