可观察性和监控系统
简介
最早的可观测概念来源于:控制论书,里面强调:要控制一个系统的前提是对其具有可观测性。必须以应用为中心,向上关联业务成败与用户体验,向下覆盖基础设施与云服务监控。
聊聊云原生转型之前实现可观察性的必要性程序员的世界非常魔幻,有时不明白老板们在想什么,突发奇想说公司想做云原生转型,碰到什么困难,老板们开始怀疑技术上存在问题,试图通过技术解决一切问题,而不考虑公司组织架构是否需要变革。要做云原生转型仅仅靠技术就够了么?有时仅仅只是创造了一堆工作要做,可能不会带来任何收益,反而会增加工作量。无论做云原生转型,还是做组织架构调整,还是做技术迭代升级,只要你还准备继续迭代和升级,首先你需要了解你的系统到底发生了什么;要想了解公司的业务发展就要从监控和可观察性开始。为什么这样说呢?从某种意义上来说,云原生是一种提效手段,所以找到组织效率低下的原因,然后再进行转型和升级。如果找不到现在效率低下的原因,贸然进行云原生转型可能会徒增工作量。
数据支柱
观测体系的三大数据支柱。
- Metrics:IT 系统是否有问题;
- Traces:哪里出了问题;
- Logs:问题是由什么原因导致的。
Trace回答的是“为什么这次请求变慢/失败了?”,它提供的是诊断性的、富含上下文的个体故事。而Metric回答的是“系统现在的整体状态如何?”,它提供的是概览性的、统计性的宏观画像。技术选型并非孤立存在,它与业务场景紧密相连,并形成一种“相互强化”的循环。
- 电商、本地生活、在线旅游等业务的核心是交易闭环,其流程天然决定了 Trace 的不可替代性。每一笔失败的交易都可能是一个需要跟进的客诉。研发需要工具来复现“那一个”用户的失败全过程。Trace 提供的请求级上下文,是满足这种精细化排查需求的唯一途径。
- 视频流、内容分发等业务的核心是保障海量用户的内容消费体验,一次视频播放请求的核心链路通常很短,且大量交互通过 CDN 和异步消息队列完成,服务间的依赖关系松散。平台更关注的是“整体播放成功率是否低于 99.99%”这样的宏观指标。单次的用户播放失败对整体影响微乎其微,花费巨大成本去追溯每一个失败的个体请求,投入产出比很低。对于日活数亿、每秒处理数百万请求的应用,采集 Trace 的数据存储和计算成本是天文数字。相比之下,Metric 以其极低的数据量,成为唯一现实可行的大规模监控方案。
未来是关联
一文读懂可观测性与Opentelemetry传统的系统相对简单,(我们会不辞劳苦地在各种指标数据中寻找可能的关联性,得到关键线索后,我们会在大脑中构造出一堆复杂的日志查询条件来验证自己的猜想。就这样比对、猜想、验证,同时还要在各种工具中切换)行之有效。现代IT系统的关键词是分布式、池化、大数据、零信任、弹性、容错、云原生等,越来越庞大,越来越精细,越来越动态,同时也越来越复杂。通过人去寻找各种信息的关联性,再根据经验判断和优化,显然是不可行的,耗时耗力还无法找到问题根因。传统的工具是垂直向的,引入一个新的组件的同时也会引入一个与之对应的观测工具,这样是保证了数据的全面性,但丢失了数据的关联性和分析排查的连贯性(换句话说,我们方方面面都监控到了,但遇到问题,还是不能很好地发现和定位)。此时我们很自然的想到做一个统一的数据平台,想象中把所有数据放在一个平台就能解决关联性的问题,但往往实际情况是我们只是把数据堆在一个地方,用的时候还是按传统的方式各看各的。我们只是把无数根柱子(工具),融合成了三根柱子:一个观测指标、日志、链路的统一平台,数据统一了,但关联性还得靠人的知识和经验。这里边最关键的其实是解决数据关联的问题,把之前需要人去比对、过滤的事交给程序去处理,程序最擅长此类事同时也最可靠,人的时间更多的用在判断和决策上。这在复杂系统中,节省的时间会被放大很多倍,就这点小事就是可观测性看得见的未来。
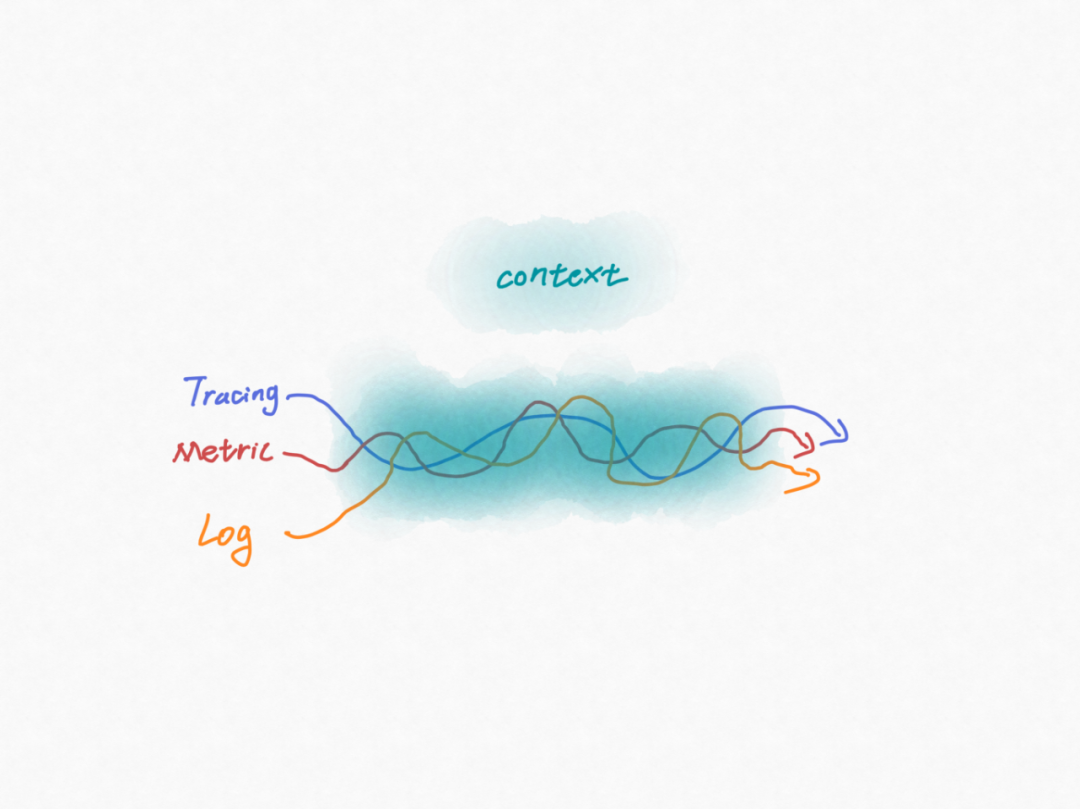
那么,如何做数据关联呢?说起来很容易,那就是做时间+空间的关联。在我们的统一数据平台上,由于数据是来自于各种观测工具的,虽然我们在数据格式上统一成了metric、log、trace,但不同工具的metric、log、trace的元数据截然不同,而如果我们在这个统一数据平台上去梳理和映射这些元数据的话,这将是庞杂、难维护、不可持续的。那该如何做呢?答案就是标准化。只有将标准化、结构化的数据喂给观测平台,观测平台才能从中发现巨大价值。统一数据平台只是在数据格式上进行了标准化,而要想将trace、metric、log关联还必须建立context的标准化,context就是数据的空间信息,再叠加上时间信息的关联就可以发挥真正的观测价值。
MetaFlow:开源的高度自动化可观测性平台非常酷的AutoMetrics,AutoTracing、AutoTagging、SmartEncoding等创新能力
- AutoMetrics,MetaFlow完整的使用了eBPF的kprobe、uprobe、tracepoints能力,也完整的使用了eBPF的前身——已经有三十年历史的BPF的能力,与AF_PACKET、Winpcap等机制结合,实现面向任何操作系统、任意内核版本的全自动的数据采集。也就是说,不管一个调用是发生在Application这一侧的客户端或服务端,不管是一个加密之后的HTTPS调用、编码之后的HTTP2调用,还是普通明文的HTTP、Dubbo、MySQL、Redis调用,都能自动的获取到它的每一个调用的事件详情及RED(Request、Error、Delay)性能指标。不管这个调用流经的是Pod的虚拟网卡、VM的虚拟网卡、宿主机的物理网卡,还是中间的NFV虚拟网关,或者七层API网关,只要有MetaFlow Agent部署到的地方,都可以通过eBPF/BPF技术从内核中获取到调用数据,并生成应用层面的RED指标、网络层面的吞吐、时延、异常、重传等指标。这样的指标采集是完全自动化的,它不需要我们的开发者手动做任何的埋点或插码,所有这些能力,通过部署MetaFlow Agent即可自动获取到。
- AutoTracing,eBPF追踪的是每个Request相关的TCP/UDP通信函数,通过挂载到这些系统调用函数中实现自动追踪,高度完整的展示出微服务调用链。PS:异步调用的追踪还有欠缺
- AutoTagging,MetaFlow Agent通过同步K8s、服务注册中心的大量的资源、服务、API属性信息,然后由Server进程汇总并统一插入到所有的可观测性数据上,使得我们能够无缝的、在所有数据之间关联切换,呈现应用调用的全栈性能。基于AutoTagging构建统一的可观测性数据平台的实践 DeepFlow AutoTagging 之 Prometheus 标签标准化 未读。
- SmartEncoding,MetaFlow会为所有观测数据自动注入大量的Tag,比如在容器环境中,从客户端去访问服务端这样的双端数据,可能要注入上百个维度的标签,这些标签有可能是非常长的字符串,给我们的后端存储造成了非常大的压力。MetaFlow创新的使用SmartEncoding机制,在Agent上独立采集标签和观测数据,同步到Server端后对标签进行独立的整形编码,并将整形编码注入到观测数据中存储下来,使得整个标签的注入开销降低10倍。由于存储的标签都是Int编码之后的,有助于降低查询过程中的数据检索量,也能显著提升查询性能。而对于一些衍生的Tag则完全没必要存储在数据库中,MetaFlow Server通过SQL接口抽象出来底层的一个大宽表。比如在底层我们存储了40个标签,通过Server的抽象,把它延展成100个标签的虚拟大宽表。上层应用在虚拟大宽表之上进行查询,完全感受不到标签是否存储在数据中、是以Int还是String的形式存储。
其它
做出让人爱不释手的基础软件:可观测性和可交互性 个人理解: 尽可能多的监控,之后就是尽量串起来
- 我觉得更重要的是,找问题过程中我们使用的工具、老司机的思考过程。作为一个观察者,我看到年轻的同事看着老司机熟练地操作 perf 和在各种各样工具和界面中切换那种仰慕的眼神,我隐约觉得事情有点不对:这意味着这门手艺不能复制。
- 如果打开 TiDB 的内部 Grafana 就会看到大量这样的指标,得到对系统运行状态的大致图景。更进一步的关键是,这些系统的指标一定要和业务上下文联系在一起才能好用,举例说明,对于一个支持事务的数据库来说,假设我们看到 CPU 线程和 call stack,发现大量的 CPU 时间花在了 wait / sleep / idle 之类的事情上,同时也没有其他 I/O 资源瓶颈,此时,如果只看这些的数字可能会一脸懵,但是结合事务的冲突率来看可能柳岸花明,甚至能直接给出这些 lock 的等待时间都花在了哪些事务,甚至哪些行的冲突上,这对观测者是更有用的信息。
- 如果我们讨论可观测性脱离了周期,就毫无意义。周期越贴近终端用户的使用场景越实用。譬如,在数据库中,选择单条 SQL 的执行作为周期不如选择事务的周期,事务周期不如应用程序一个请求全链路的周期。其实 TiDB 在很早就引入了 OpenTracing 来追踪一个 SQL 的执行周期内到底调用了哪些函数,花费多少时间,但最早只应用在了 TiDB 的 SQL 层内部(熟悉我们的朋友应该知道我们的 SQL 和存储是分离的),没有在存储层 TiKV 实现,所以就会出现一条 SQL 语句的执行过程往下追到 TiKV 就到了一个断头路;后来我们实现了把 TraceID 和 SpanID 传到了 TiKV 内部这个功能才算初步可用,至少把一个周期的图景变得更加完整了,本来我们打算就止步于此,但是后来发生了一个小事情,某天一个客户说:为什么我的应用访问 TiDB 那么慢?然后我一看 TiDB 的监控,没有啊,SQL 到数据库这边基本都是毫秒就返回了,但是客户说:你看我这个请求也没干别的呀,两边怎么对不上?后来我们把 Tracer 加进来以后才知道客户这边的网络出了点问题。这个案例提醒了我,如果能做到全链路的 Tracing,这里的全链路应该是从业务端请求开始计算,去看待生命周期才有意义。所以在此之后我们在 TiDB 里面通过拓展 Session Variable,能够支持用户将 OpenTracing 协议的 Tracer 信息通过 Session Varible 传入到 TiDB 的体系中,打通业务层和数据库层,能够真正实现的一个全生命周期的跟踪,这个功能也会在很近的未来的版本中和大家见面。
- 根据我们的经验,结合上面内容,有了完善的 Tracing 系统,大部分的 Debug 过程在 Tracing + Log 就能找到问题的根因。
- 我在观察老师傅处理问题的时候发现一个特别有意思的现象:有经验的开发者总是能够很快通过观测,决定自己接下来该做什么,不需要查阅资料什么或者等着别人指导,完全处于一个心流的状态(例如在 TiDB 里面看到数据在集群内部分布不均或者有热点,就知道去修改调度策略或者手工 split region),但是新人在这一步总是会卡着,要么去 Google 要么去翻文档,内心 OS:「我看到问题了,然后怎么办?」,如果这个时候,系统能够给一些接下来应该观测哪些指标,或者行动建议,会更加友好,目前能做到这一点的系统不多,如果能做到这一点,相信你的系统已经在可观测性上做得很棒了。把这个点放在可观测性的最后其实是想借着这个话题引出可交互性。
- 一个优秀的基础软件,在输出负向反馈的时候,最好的做法就是建议开发者接下来该干嘛。遇到真的 Unknown Error 要输出各种帮助 Debug 的上下文信息,最后在错误日志里提示用户到哪个链接提 Github Issue,然后最好在 URL Link 里帮用户把 Issue Title 填好(让用户自己决定是不是发 Issue)。
高效定位代码问题为了提高排查效率,目前常见的解决方案是:链路跟踪+日志分析工具相结合。即通过链路跟踪产品(如阿里云的Tracing Analysis)可视化还原业务执行过程的系统调用链路的拓扑、接口请求量与耗时等数据,再配合日志分析工具(如阿里云的SLS)进一步分析链路中某个系统的详细日志从而锁定出问题的大致坐标。分析具体日志详情以及一键跳转日志关联的源码仓库,定位到问题代码行。PS: 定位问题项目 ==> 代码
日志在可观测场景下的应用以故障发现和故障定位为目的使用日志场景可大致分为日志搜索和日志分析两类:
- 日志搜索:通过日志关键字搜索日志;通过线程名、类名搜索日志;结合 Trace 上下文信息,衍生出根据 TraceID、根据 spanName、parentSpanName、serviceName、parentServiceName 搜索日志。
- 日志分析:查看、分析指定日志数量的趋势;根据日志内容生成指标(比如每次交易成功打印一条日志,可以生成关于交易额的一个指标);自动识别日志模式(比如查看不同模式的日志数量的变化,占比)。
- 闲鱼异常日志问题自动追踪-定位-分发机制之前,我们处理扫描出来的异常问题,需要测试先过滤一遍异常,然后指派给一个指定的开发owner(一个应用对应一个开发owner),然后由开发owner 自己去看代码识别 判断指派的问题是不是自己写的,如果不是,需要转发给其他开发,这里面会涉及到测试+开发两方面的精力投入,针对这种情况,我们研发了一套异常日志问题自动追踪-定位-分发机制,,自动分发缺陷给到对应开发,同时我们指派的BUG可以精确到行级别(哪一行日志报错,自动指派给那一行的提交人),做到又准又快又省力。
Continuous Profiling 实践解析 对cpu 利用率高、频繁gc 等进行更细致的分析。
留下评论