领域驱动理念
简介
一文教会你如何写复杂业务代码一般来说实践 DDD 有两个过程:
- 套概念阶段。了解了一些 DDD 的概念,然后在代码中“使用”Aggregation Root,Bounded Context,Repository 等等这些概念。更进一步,也会使用一定的分层策略。然而这种做法一般对复杂度的治理并没有多大作用。
- 融会贯通阶段。术语已经不再重要,理解 DDD 的本质是统一语言、边界划分和面向对象分析的方法。PS:让代码成为业务概念的忠实映射,
作者认为自己处于1.7阶段。在现实业务中,很多的功能都是用例特有的(Use case specific)的,如果“盲目”的使用 Domain 收拢业务并不见得能带来多大的益处。相反,这种收拢会导致 Domain 层的膨胀过厚,不够纯粹,反而会影响复用性和表达能力。我们承认模型不是一次性设计出来的,而是迭代演化出来的。不强求一次就能设计出 Domain 的能力,也不需要强制要求把所有的业务功能都放到 Domain 层,而是采用实用主义的态度,即只对那些需要在多个场景中需要被复用的能力进行抽象下沉,而不需要复用的,就暂时放在 App 层的 Use Case 里就好了。PS:Use Case 是《架构整洁之道》里面的术语,简单理解就是响应一个 Request 的处理过程。
DDD被高估了吗?提出并识别模式,给它们起个名字,并使用它们来给出系统结构,保证系统统一性。我们可以并且应该发明自己的语言,并将任何 DDD 材料视为起点,而不是最终结果。如果你所做的一切都是按照现有的 DDD 标准术语定义,并试图将任何问题都硬塞到现有的结构中,那么你的生活将非常悲惨。有一种生活超越了 DDD,尽管我认可它应该总是由领域驱动的,只是不一定是 DDD 意义上的。
软件设计的三重境界:守-破-离 很有境界
聊一聊,我对DDD的关键理解 值得细读
- 现状:分层支撑机制。我们选择各种框架、进行各种组织设计,核心是为了提高生产效率。但如果业务逻辑都是case by case地进行实现、缺少复用,那么研发成本是非常高的、投入周期也会非常长。为了增加复用、缩短业务的落地时间,就需要很多通用的能力、产品:基础能力;平台产品;通用产品。这样的层次,看上去很美好:在起步阶段,由于缺少历史包袱,的确可以提升一定的生产效率,这是能力本身的收益。但是,越往后,随着业务接入的增多,业务之间开始互相影响,研发的阻力也越来越大。研发效能降低的重要原因在于:更多的时候,我们还是按照“业务能跑起来,怎么快怎么来“的逻辑去做相关工作,遇水搭桥,遇山开洞,然后直达目的地,进行信息的传达、数据库字段的操作。这样的过程,违背了我们”希望通过业务场景,丰富平台能力,同时保证内核干净“的初衷。能力应该是基于相对多的用例、相对完善的思考进行抽象,是横向统一看,有更深刻的理解,但是垂直的交付,让我们更加纵向地处理问题,往往只是“窥探”了链路,在交付时长和业务节点的限制下,很难想得更加全面、深刻,难以做出更通用的设计。
- 工作中,的确很少看到DDD的最佳实践。在复杂的业务面前,谁也没有勇气说,哪个软件结构是理想的设计:因为这不是一个确定性的问题分解,你的设计会被放在显微镜下研究,总能找到各种反例。而且,我们深知,最佳的实践,一定是做得足够的“软”,对扩展留有设计,能够随着业务发展而迭代,不是一个静态的结果。
- 以领域为中心,其实是一个比较重要的转变:
- 原来以分层架构为主:讲究按层次去看,尽量将能力下沉,进行更多工具复用,积累的是通用组件。
- 现在以领域为中心:讲究按抽象层次去看,尽量将理解融入到领域核心,进行更多“理解”复用,积累的是业务知识。
个人想法:做设计的时候,往往已知的、深入理解的case 不多,不足以为以后的case 留下足够的“缝隙”,设计者和后来者往往不是一个人,后来者没有能力也没有意愿 通过调整整体设计来实现需求,只能部分微调、堆上奇技淫巧,分不清是不是承重墙(以至于一不留神就拆了设计之初约定、默认的重要原则)。所以感觉,核心还是如何 尽量 设计者的“想法”能够尽量无损传递给“后来者”,及时根据最新需求调整整体架构,这延伸两个思路
- 随时根据最新需求对整体架构进行微调
- 设计的架构如何尽可能容纳新需求,以便于后来者“填代码”即可(且知道在哪填)
- 以电商业务为例,有商品、订单表、优惠券等表,有满减规则(这意味着订单里新增商品要重新计算价格,移除商品也要计算价格),关键是满减规则 是一个“软”的概念,没有实体对应,且经常变,很容易逻辑分散在 商品、订单表、优惠券的处理逻辑中。
革新的对象——面向数据库的架构/传统分层架构
领域驱动设计(DDD:Domain-Driven Design)提到服务器后端发展三个阶段
- UI+DataBase的两层架构,这种面向数据库的架构没有灵活性。
- UI+Service+DataBase的多层SOA架构,这种服务+表模型的架构易使服务变得囊肿,难于维护拓展,伸缩性能差
- DDD+SOA的事件驱动的CQRS读写分离架构,应付复杂业务逻辑,以聚合模型替代数据表模型,以并发的事件驱动替代串联的消息驱动。真正实现以业务实体为核心的灵活拓展。
领域驱动设计和开发实战不投入资源去建立和开发领域模型,会导致应用架构出现“肥服务层”和“贫血的领域模型”,在这样的架构中
- 外观类(通常是无状态会话 Bean)开始积聚越 来越多的业务逻辑,而领域对象则成为只有 getter 和 setter 方法的数据载体。
- 这种做法还会导致领域特定业务逻辑和规则散布于多个的外观类中(有些 情况下还会出现重复的逻辑)。
- 在大多数情况下,贫血的领域模型没有成本效益;它们不会给公司带来超越其它公司的竞争优势,因为在这种架构里要实现业务需求变更,开发并部署到生产环境中去要花费太长的时间。
基于数据库设计
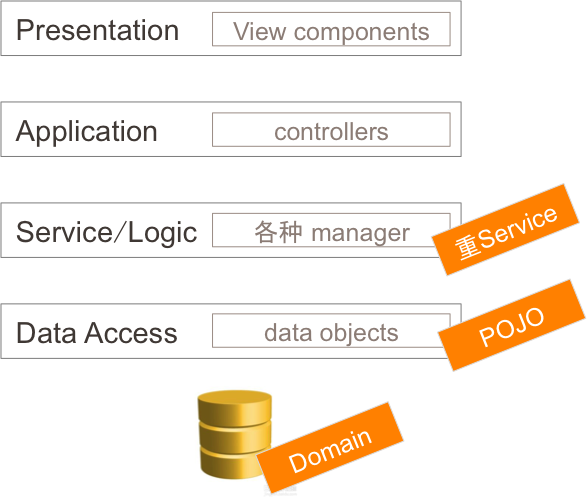
多视角理解领域驱动
从腾讯视频架构重构,看DDD的概念与方法DDD 为复杂度而生,同时也提供了一些应对复杂度的具体方法,比如:通过架构设计来分离业务复杂度和技术复杂度;通过限界上下文将一个大系统切分为若干高内聚低耦合的子领域;通过领域模型对业务领域的知识进行抽象。但是,我们期望也不能太高。总的来说,DDD能解决一些问题,但 DDD 并不是银弹,在最好的情况下,DDD 也只是一个部分可用工程解,而不会是一个完美无缺的理论解。
分解复杂性视角
领域驱动设计在互联网业务开发中的实践 解决复杂和大规模软件的武器可以被粗略地归为三类:抽象、分治和知识。
- 分治 把问题空间分割为规模更小且易于处理的若干子问题。分割后的问题需要足够小,以便一个人单枪匹马就能够解决他们;其次,必须考虑如何将分割后的各个部分装配为整体。分割得越合理越易于理解,在装配成整体时,所需跟踪的细节也就越少。
- 抽象 使用抽象能够精简问题空间,而且问题越小越容易理解。举个例子,从北京到上海出差,可以先理解为使用交通工具前往,但不需要一开始就想清楚到底是高铁还是飞机,以及乘坐他们需要注意什么。PS:《原则》中也有类似的表述,你在思考高层次的事情时,一定不要考虑低层次的细节。《重构》中讲一个方法只要 包含跟该方法同级层次的代码。《程序员的底层思维》讲抽象层次的一致性 谈谈业务开发中的抽象思维 抽象思维的三个阶段
- 经验归纳,只要我们认真做好手头的工作,就事论事地保持积累和总结,把这些经验进行系统化的记录、归纳、整理、分类,对于较复杂的、专业性较强的业务领域,甚至可以著书立说。
- 建模,有一点哲学认识论的味道,涉及到人类知识如何对客观世界进行刻画的问题。类比到物理学领域,物理定律对于客观的物理规律的描绘,实际上也是一种「建模」。经验归纳的思维方法,主要是对信息进行收集,以及简单的加工整理;而建模方法考验的主要是逻辑思维过程,对于信息的了解,所占比重已大幅下降。建模可以看作是对信息的深度加工整理。
- 高层抽象,主要是为了应对问题规模,把握更「大」的东西。首先,并不是所有人都会遇到规模足够大的问题需要解决。只有对于规模庞大的公司、组织、政府机构,这种思维方式才是必不可少的。更进一步,高层抽象需要处理模型和模型之间,甚至是体系和体系之间的关系问题。还是类比到物理学领域,如果把牛顿运动定律、相对论和量子力学看作三个不同的模型,那么高层抽象就相当于要描述清楚这三个理论体系之间的关系。类似这种「大一统」的思维方式,自然是抽象层次最高,也最难的。
- 知识 顾名思义,DDD可以认为是知识的一种。DDD提供了这样的知识手段,让我们知道如何抽象出限界上下文以及如何去分治。
西瓜可以横着切也可以纵着切,分治怎么分也要找到一个切口。
在系统复杂之后,我们都需要用分治来拆解问题。一般有两种方式,技术维度和业务维度。技术维度是类似MVC这样,业务维度则是指按业务领域来划分系统。微服务架构更强调从业务维度去做分治来应对系统复杂度,而DDD也是同样的着重业务视角。DDD的核心诉求就是将业务架构映射到系统架构上,在响应业务变化调整业务架构时,也随之变化系统架构。
领域驱动设计学习输出「DDD」则把大多数的业务逻辑都包含在了「聚合」、「实体」、「值对象」里面,简单理解也就是实现了对象自治,把之前暴露出来的一些业务操作隐藏进了「域」之中。每个不同的区域之间只能通过对外暴露的统一的聚合根来访问,这样就做了收权的操作,这样数据的定义和更改的地方就聚集在了一处,很好的解决了复杂度的问题。
- 代码没有按照业务绑定的”分析模型”去编码,软件变成一个大泥潭
- 软件的可扩展性较差
- 软件变成面向过程
- 分层不合理
- 没有规范
- DDD是如何处理上面提到的软件复杂度的?
- 提供了一个领域划分的方法:让软件系统产生边界。
- 提供一个一系列的战略模式:限界上下文的映射,分层架构等。
- 提供一个一系列的战术模式:如何规划领域层 内部
- DDD的核心思想,大家都清楚,就是分析模型要和代码模型保持一致。 如果技术实现和业务实现不在用一水平线上,那技术模型的行进路线只会考虑劈开技术障碍并且可能会撞在未来的业务障碍的墙上。这样就很容易出现,业务持续演进等技术想实现的时候,却发现当前的实现依赖于“业务不会这样发展”的假设上。这也是为什么会出现现在众多业务需求,技术无法实现或者是需要花大量时间去实现的原因。但是如果技术和业务通过统一语言打破知识的壁垒保持一致,那么如果后面技术遇到问题即是业务碰到的问题,业务人员需求的变更和迭代会自然而然的帮助技术同学越过一些门槛。也就是说业务方与技术方参与到对方的工作中,就在双方之间带来了更好的协同,形成1+1>2的功效。
- 复杂度处理 - 分层不合理:传统的三层架构 ==> 六边形架构 ==> 洋葱架构 ==> DDD 架构 ==> CQRS
软件架构设计视角
Evic Evans在《领域驱动设计》中将软件系统的设计分为2个部分:战略设计和战术设计。
- 战略设计部分指导我们如何拆分一个复杂的系统。 PS: 和微服务的划分不谋而合
- 战术部分指导我们对于拆分出来的单个子系统如何进行落地,在落地过程中应该遵循哪些原则。PS:对应大部分技术开发同学的工作。
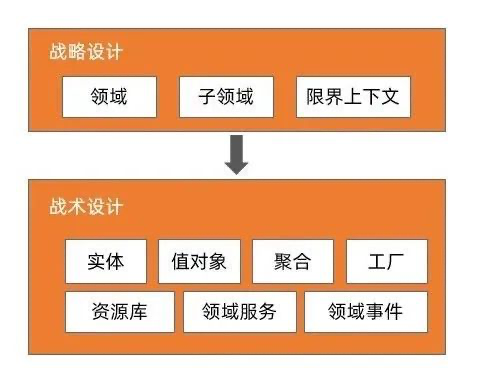
为什么是“领域”驱动,而不是什么别的东西驱动?比如服务驱动?对象驱动?
- 简单的系统数据库CRUD就可以搞定,只有足够复杂且多变(二者缺一不可)的系统才用得上领域驱动
- 开发人员经常把业务流程实现成系统流程,业务流程复杂、多变的时候, 系统流程也必须做出改变,因而需要在“业务流程”和“系统流程”之间提出一层,即领域模型
- 领域就是现实世界的业务,是复杂多变的,我们看到的只是现象。而领域模型就是要找到这些现象背后不变的部分,也就是本质,也就是“变化”背后的“不变性”
- 就像任何一门语言,最基本的是单词。领域驱动设计的一系列概念:实体、值对象、聚合根、领域事件、Specification,就是领域模型这门“建模”语言的“单词”。给了我们一系列分析工具,帮我们分析出“领域”现象背后的“本质”。
所以,换句话说,本质是业务流程和系统流程不一致带来许多问题, 需要抽一个中间层,这个中间靠近业务/领域,所以以“领域”方式描述,但又不能易变,所以必须找到业务中不变的部分(即本质),来减少系统流程的变动。
不拔:在建模的过程中,你会体会到抽象的乐趣,越是深刻、灵活的模型,往往就越抽象,建模考验的是不是能把客观业务事实概念化地呈现出来,所以先观察业务事实有什么,再用概念把它表达出来,这里有一个观点:关系即结构,结构即模型,我们本质是要建一个能体现现实业务运转的模型,这个模型包含动静两方面,静的方面即是模型结构,动的方面是相互之间的依赖关系。模型要体现普通性,并不是你所看到的业务事实,它还可能包含其它的业务事实并没有被观测到,没有观测到并不表示它们不存在。因此,在建模时要想一想,还有没有其它的业务场景,业务的多样性会不会对业务模型带来冲击,所以,全面的调查是设计的基础,要不然是解决了一部分问题(没有调查就没有发言权,实践出真知)。
如何用代码有效描述业务视角
领域驱动设计学习输出DDD 改变了传统软件开发工程师针对数据库进行的建模方法,从而将要解决的业务概念和业务规则转换为软件系统中的类型以及类型的属性与行为,通过合理运用面向对象的封装、继承、多态等设计要素,降低或隐藏整个系统的业务复杂性,并使得系统具有更好的扩展性,应对纷繁多变的现实业务问题。
- 传统项目中,架构师交给开发的一般是一本厚厚的概要设计文档,里面除了密密麻麻的文字就是分好了域的数据库表设计。言下之意:数据库设计是根本,一切开发围绕着这本数据字典展开
- 我经常会做一个假设:假设你的机器内存无限大,永远不宕机,在这个前提下,我们是不需要持久化数据的,也就是我们可以不需要数据库,那么你将会怎么设计你的软件?这就是我们说的 Persistence Ignorance:持久化无关设计。首先一点,领域模型无法通过数据库表来表示了,就要基于程序本身来设计了。
- 按照 object domain 的思路,领域模型存在于内存对象里,意味着得 通过 类图 而不是ER图来描述业务。用类 比用 数据库表 有更丰富的表达方式:通过引用来表达多对多关系、封装、继承和多态等。
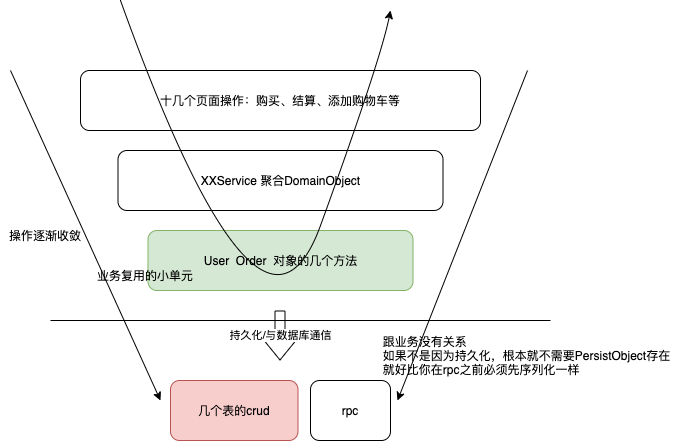
领域驱动设计和开发实战从设计和实现的角度来看,典型的 DDD 框架应该支持以下特征:应该是一个以 POJO(这里说的应该是充血对象)为基础的架构;领域第一,基础设施第二:PersistentObject只是表达了一种存储方式而已, 跟业务毫无关系。
组织架构视角
- 之前,很多团队在自己的领域层上面都有应用层,这些应用层,导致有些事情上下游团队都可以做,很多事情,谁都能做的时候,就可能出现谁都不想做。
- 技术架构整体的调整策略:包含核心领域的团队交出各自的“应用层”,统一交给下游网关团队,组成统一的应用层。领域团队负责的事情变成一个个核心领域,业务收敛到一个团队(“大前台”),这个团队了解下游可提供的能力,能从全局看业务整体开展情况。很多需求,产品只需要对接“大前台”一个团队即可。 以 DDD 得到的业务领域模型为基础,审视与调整组织架构,进行团队的划分,并在业务发生显著变化时保持组织架构的灵活性,反向使康威定律发挥作用。
DDD不只是指导写代码
- 为什么业务建模重要? 以前的开发流程有什么问题?先说结论,开发人员交付的程序对业务方,产品人员,测试人员来说就是一个黑盒子。除了开发人员自己,没人知道盒子里有什么。当新的需求加入来,需求方,产品人员,甚至测试人员都认为可行,开发人员却给出相反结论。
- 业务建模怎么解决这个黑盒子问题?DDD引入了业务专家这个角色(在我看来就是业务方,产品)。假设业务专家听不懂 什么叫类,什么是方法,设计模式,他只知道他的业务,两方人马完全不在同一频道,这个时候就需要“明确上下文”,“统一语言”了。业务建模,用例分析法、事件风暴、四色建模等看看开始整上。最终达到划分领域,识别聚合的目的。业务建模落地。开发人员开发过程中,应遵守已经建立的业务模型来编写代码。至此终于实现了,业务专家可通过业务模型窥探到开发人员的代码实现。统一语言、业务模型在业务专家跟开发人员中间充当了沟通的桥梁。当追加新的需求时,业务专家能合理评估需求的可行性。
- 让非开发人员参与到开发中。统一语言,业务建模,模型充血(OOP)。这一系列手段都是为了实现让非开发人员参与到开发中这一最终目的。与其说DDD是一种架构,不如认为他是指导开发的方法论。
领域驱动设计学习输出面对客户的业务需求,由领域专家与开发团队展开充分的交流,经过需求分析与知识提炼,获得清晰的问题域。通过对问题域进行分析和建模,识别限界上下文,利用它划分相对独立的领域,再通过上下文映射建立它们之间的关系,辅以分层架构与六边形架构划分系统的逻辑边界与物理边界,界定领域与技术之间的界限。之后,进入战术设计阶段,深入到限界上下文内对领域进行建模,并以领域模型指导程序设计与编码实现。若在实现过程中,发现领域模型存在重复、错位或缺失时,再进而对已有模型进行重构,甚至重新划分限界上下文。
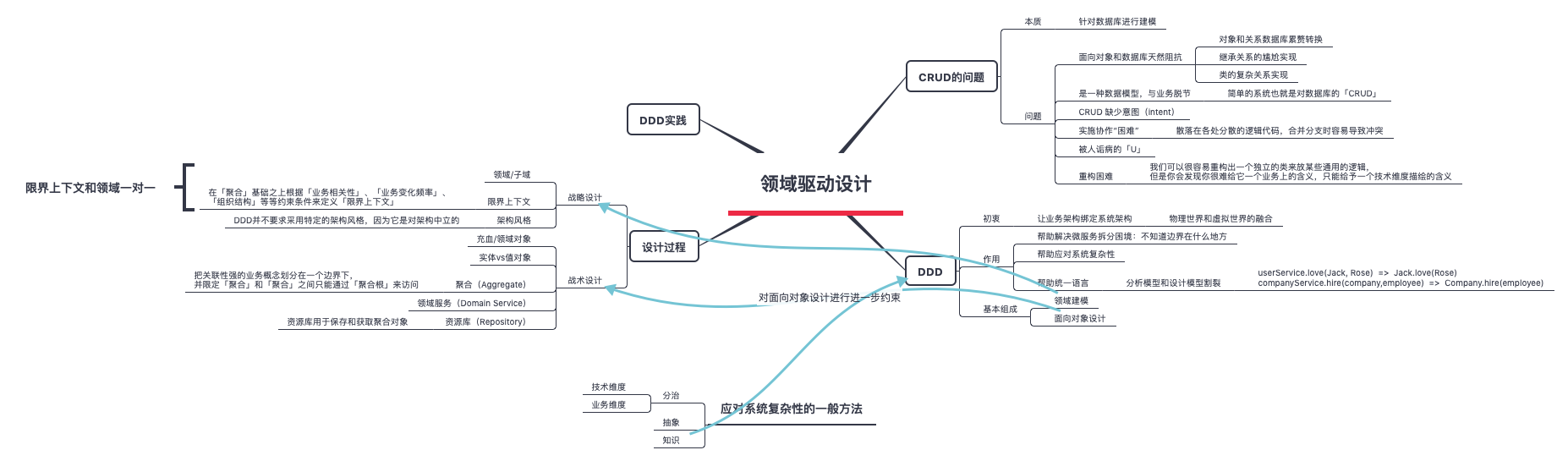
领域模型设计
领域模型是业务概念在程序中的一种表达方式。领域模型可以用来设计和理解整个软件结构。面向对象设计中的类概念是领域模型的一种表达方式。与此类似,UML的建模方法也可以应用在对领域模型的表达上。但是要区分的一点就是,领域模型≠数据模型。
主要来自极客时间《软件设计之美》
- 战术设计(Tactic DDD):Entity, Value Object; Aggregate, Root Entity, Service, Domain Event; Factory, Repository。
- 战略设计(Strategic DDD):Bounded Context, Context Map; Published Language, Shared Kernel, Open Host Service, Customer-Supplier, Conformist, Anti Corruption Layer (context relationship types)。
战略设计:子域、限界上下文和上下文映射图
- 软件开发是解决问题,而解决问题要分而治之。所谓分而治之,就是要把问题分解了,对应到领域驱动设计中,就是要把一个大领域分解成若干的小领域,而这个分解出来的小领域就是子域(Subdomain)
- 对于一个真实项目而言,划分出来的子域可能会有很多,但并非每个子域都一样重要。所以,我们还要把划分出来的子域再做一下区分,分成核心域(Core Domain)、支撑域(Supporting Subdomain)和通用域(Generic Subdomain)。核心域是整个系统最重要的部分,是整个业务得以成功的关键。关于核心域,Eric Evans 曾提出过几个问题,帮我们识别核心域:为什么这个系统值得写?为什么不直接买一个?为什么不外包?
- 有了切分出来的子域,怎样去落实到代码上呢?首先要解决的就是这些子域如何组织的问题,是写一个程序把所有子域都放在里面呢,还是每个子域做一个独立的应用,抑或是有一些在一起,有一些分开。这就引出了领域驱动设计中的一个重要的概念,限界上下文(Bounded Context)。它形成了一个边界,一个限定了通用语言自由使用的边界,一旦出界,含义便无法保证。比如,同样是说“订单”,一旦定义了限界上下文,那交易上下文的“订单”和物流上下文的“订单”肯定是不同的。
- 很自然地,我们就可以把限界上下文看作是一个独立的系统,比如,每个限界上下文都可以成为一个独立的服务。限界上下文的重点在于,它是完全独立的,不会为了完成一个业务需求要跑到其他服务中去做很多事,而这恰恰是很多微服务出问题的点,比如,一个业务功能要调用很多其他系统的功能。
- 有了对限界上下文的理解,我们就可以把整个业务分解到不同的限界上下文中,但是,尽管我们拆分了系统,它们终究还是一个系统,免不了彼此之间要有交互。所以,我们就要有一种描述方式,将不同限界上下文之间交互的方式描述出来,这就是上下文映射图(Context Map),DDD 给我们提供了一些描述这种交互的方式,比如:合作关系(Partnership);共享内核(Shared Kernel);客户 - 供应商(Customer-Supplier);跟随者(Conformist);防腐层(Anticorruption Layer);开放主机服务(Open Host Service);发布语言(Published Language);各行其道(Separate Ways);大泥球(Big Ball of Mud)。
- 当我们知道了不同的限界上下文之间采用哪种交互方式之后,不同的交互方式就可以落地为不同的协议。比如REST API、RPC 或是MQ
战术设计——如何在微观上实现OO?
聚合(Aggregate)/实体(Entity)/值对象(VO):提供了比Class更丰富的战术模式,指导我们构建充血模型。
领域模型/战术设计包含了很多概念,比如,实体、值对象、聚合、领域服务、应用服务等等。有这么多概念,我们该如何区分和理解他们呢?我们同样需要一根主线。
- 首要任务就是设计角色,在战术设计中,我们的角色就是各种名词。识别名词也是很多人对于面向对象的直觉反应。有一些设计方法会先建立数据库表,这种做法本质上也是从识别名词入手的。我们在战术设计中,要识别的名词包括了实体和值对象。什么是实体呢?实体(Entity)指的是能够通过唯一标识符标识出来的对象。在业务处理中,有一类对象会有一定的生命周期。以电商平台上的订单为例,它会在一次交易的过程中存在,而在它的生命周期中,它的一些属性可能会有变化,比如说,订单的状态刚开始是下单完成,然后在支付之后,变成了已支付,在发货之后就变成了已发货。但是这个订单始终都是这个订单,不会因为属性的变化而变化,因为这个订单有唯一的标识符,也就是订单号。
- 由标识定义,而不依赖它的所有属性和职责,并在整个生命周期中有连续性。就是一个标识没变的对象,在其他自身属性发生变化后,它依然是它,那么它就是实体;一个商品的商品id没变,即使它的标题改了,图片改了,优惠信息变了,它发生了翻天覆地的变化,但它依然是它,它有唯一的标识来表明它还是它,只是一些属性发生了变化;通过这种方式来识别实体的目的,是因为领域中的关键对象,通常并不由它们的属性定义,而是由可见的/不可见的标识来定义,且有完整的生命周期,在这个周期内它如何变化,它都依然是它;通过这种方式识别出实体这种领域关键对象,也是领域驱动设计和数据驱动设计最大的差别,数据驱动设计是先识别出我们需要哪些数据表,然后将这些数据表映射为对象模型;而领域驱动设计是先通过业务模型识别出实体,再将实体映射为所需要的数据表。
- 实体的业务形态:实体能够反映业务的真实形态,实体是从用例提取出来的。领域模型中的实体是多个属性、操作或行为的载体。
- 实体的代码形态:我们要保证实体代码形态与业务形态的一致性。那么实体的代码应该也有属性和行为,也就是我们说的充血模型,但实际情况下我们使用的是贫血模型。贫血模型缺点是业务逻辑分散,更像数据库模型,充血模型能够反映业务,但过重依赖数据库操作,而且复杂场景下需要编排领域服务,会导致事务过长,影响性能。所以我们使用充血模型,但行为里面只涉及业务逻辑的内存操作。
- 实体的运行形态:实体有唯一ID,当我们在流程中对实体属性进行修改,但ID不会变,实体还是那个实体。
- 实体的数据库形态:实体在映射数据库模型时,一般是一对一,也有一对多的情况。
- 还有一类对象称为值对象,它就表示一个值。比如,订单地址,它是由省、市、区和具体住址组成。它同实体的差别在于,它没有标识符。实体的属性是可以变的,只要标识符不变,它就还是那个实体。但是,值对象的属性却不能变,一旦变了,它就不再是那个对象,所以,我们会把值对象设置成一个不变的对象。一个商品实体的发货地址Address对象有区域信息、门牌信息、时区信息这几个属性,其中的门牌号从111修改成222后,它就已经不再是修改前的那个它了,因为门牌号222并不等于门牌号111的地址。即它是没有生命周期的。我们为什么要将对象分为实体和值对象?其实主要是为了分出值对象,也就是把变的对象和不变的对象区分开。一方面,我们会把一些值对象当作实体,但其实这种对象并不需要一个标识符;另一方面,也是更重要的,就是很多值对象我们并没有识别出来,比如,很多人会用一个字符串表示电话号码,会用一个 double 类型表示价格,而这些东西其实都应该是一个值对象。之所以说这里缺少了对象,原因就在于,这里用基本类型是没有行为的。在 DDD 的对象设计中,对象应该是有行为的。比如,价格其实要有精度的限制,计算时要有自己的计算规则。如果不用一个类将它封装起来,这种行为就将散落在代码的各处,变得难以维护。只有数据的对象是封装没做好的结果,一个好的封装应该是基于行为的。在 DDD 的相关讨论中,经常有人批评所谓的“贫血模型”,说的其实就是这种没有行为的对象。
- 值对象的业务形态:值对象是描述实体的特征,大多数情况一个实体有很多属性,一般都是平铺,这些数据进行分类和聚合后能够表达一个业务含义,方便沟通而不关注细节。
- 值对象的代码形态:实体的单一属性是值对象,例如:字符串,整型,枚举。多个属性的集合也是值对象,这个时候我们把这个集合设计为一个CLASS,但没有ID。例如商品实体下的航段就是一个值对象。航段是描述商品的特征,航段不需要ID,可以直接整体替换。商品为什么是一个实体,而不是描述订单特征,因为需要表达谁买了什么商品,所以我们需要知道哪一个商品,因此需要ID来标识唯一性。
- 值对象的运行形态:值对象创建后就不允许修改了,只能用另外一个值对象来整体替换。当我们修改地址时,从页面传入一个新的地址对象替换调用person对象的地址即可。如果我们把address设计成实体,必然存在ID,那么我们需要从页面传入的地址对象的ID与person里面的地址对像的ID进行比较,如果相同就更新,如果不同先删除数据库在新增数据。
- 值对象的数据库形态:有两种方式嵌入式和序列化大对象。
- 以属性嵌入的方式形成的人员实体对象,地址值对象直接以属性值嵌入人员实体中。
- 以序列化大对象的方式形成的人员实体对象,地址值对象被序列化成大对象Json串后,嵌入人员实体中。
选定了角色之后,接下来,我们就该考虑它们的关系了。
- 在传统的开发中,我们经常会遇到一个难题。比如,如果有一个订单,它有自己对应的订单项。问题来了,取订单的时候,该不该把订单项一起取出来呢?取吧,怕一次取出来东西太多;不取吧?要是我用到了,再去一条一条地取,太浪费时间了。这就是典型的一对多问题,也是一种用技术解决业务问题的典型思路。我们之所以这么纠结,主要就是因为我们考虑问题的出发点是技术,如果我们把考虑问题的出发点放到业务上呢?战术设计就给了我们这样一个思考的维度:聚合。聚合(Aggregate)就是多个实体或值对象的组合,这些对象是什么关系呢?你可以理解为它们要同生共死。比如,一个订单里有很多个订单项,如果这个订单作废了,这些订单项也就没用了。所以,我们基本上可以把订单和订单项看成一个单元,订单和订单项就是一个聚合。PS: 生命周期一致
- 一个聚合里可以包含很多个对象,每个对象里还可以继续包含其它的对象,就像一棵大树一层层展开。但重点是,这是一棵树,所以,它只能有一个树根,这个根就是聚合根。聚合根(Aggregate Root),就是从外部访问这个聚合的起点。其实,我们可以把所有的对象都看成是一种聚合。只不过,有一些聚合根下还有其他的对象,有一些没有而已。这样一来,你就有了一个统一的视角看待所有的对象了。那如果不同的聚合之间有关系怎么办?比如,我要在订单项里知道到底买了哪个产品,这个时候,我在订单项里保存的不是完整的产品信息,而是产品 ID。还记得吗?实体是有唯一标识符的。有了对于聚合的理解,做设计的时候,我们就要识别出哪些对象可以组成聚合。一对多问题也就不再是问题了:是聚合的,我们可以一次都拿出来;不是聚合的,我们就靠标识符按需提取。
有角色了,也确定关系了。接下来,就要安排互动了
- 事件风暴 识别出了事件和动作,而故事的来龙去脉其实就是这些事件和动作。因为有了各种动作,各种角色才能够生动地活跃起来,整个故事才得以展开。动作的结果会产生出各种事件,也就是领域事件,领域事件相当于记录了业务过程中最重要的事情。那各种动作又是什么呢?在战术设计中,领域服务(Domain Service)就是动词。只不过,它操作的目标是领域对象,更准确地说,它操作的是聚合根。动词,是我们在学习面向对象中最为缺少的一个环节,很多教材都会教你如何识别名词。在实际编码中,我们会大量地使用像 Handler、Service 之类的名字,它们其实就是动词。PS:面向对象单纯描述对象和对象之间的关系, 还是不能说清楚全貌啊
- 领域事件(Domain Event)代表领域中的发生的重要事件,可以用于通知其他领域对象或跨限界上下文进行解耦和协作。领域事件通常具有明确的业务含义,例如“用户已下单”、“商品已支付”等。领域事件可能被特定的领域实体和聚合根相关联。领域事件和我们常听说的MQ中的事件不一样,一般不会在分布式系统之间传递,只会在单个微服务内部传递。它起到最大的好处和MQ一样,就是解耦,通过事件的方式来解除领域之间的耦合,通过发布事件的方式进行一种松耦合的通信,而不用依赖具体的实现细节。
- 动作不应该在实体或值对象上吗?确实是这样的,能放到这些对象上的动作固然可以,但是,总会有一些动作(比如一些对实体/聚合/值对象进行编排操作)不适合放在这些对象上面,比如,要在两个账户之间转账,这个操作牵扯到两个账户,肯定不能放到一个实体类中。这样的动作就可以放到领域服务中。领域服务的操作应该是无状态的。
- 还有一类动作也比较特殊,就是创建对象的动作。显然,这个时候还没有对象,所以,这一类的动作也要放在领域服务上。这种动作对应的就是工厂(Factory)(其实就是设计模式中常提到的工厂)。工厂创建聚合根,聚合根创建聚合里的各种子对象(以便保证二者之间的关联)。
- 领域服务的接口应该清晰的反映其提供的业务能力,参数的返回值应该是领域对象或基本数据类型
- 对于这些领域对象,无论是创建,还是修改,我们都需要有一个地方把变更的结果保存下来,而承担这个职责的就是仓库(Repository)。你可以简单地把它理解成持久化操作(当然,在不同的项目中,具体的处理还是会有些差别的)。
- 当我们把领域服务构建起来之后,核心的业务逻辑基本就成型了。但要做一个系统,肯定还会有一些杂七杂八的东西,比如,用户要修改一个订单,但首先要保证这个订单是他的。在 DDD 中,承载这些内容的就是应用服务。应用服务和领域服务之间最大的区别就在于,领域服务包含业务逻辑,而应用服务不包含。一些与业务逻辑无关的内容都会放到应用服务中完成,比如,监控、身份认证等等。
- 实体从根本上不由其属性来定义,而是由连续性和唯一性来定义。在领域模型中,需要通过一个唯一标识而不是其属性来区分,且在其生命周期中具有连续性的对象,我们将它定义为一个实体。在实际应用的过程中,实体往往是需要持久化到数据库的,因此大部分情况下,我们都以实体的唯一标识作为数据库中的主键(而不是数据库的逐渐作为实体的唯一标识)。
- 一个实体往往会关联另外一个实体,这种关联关系主要包含一对一、一对多、多对多这三种类型。在领域模型里,一对多,多对多的关联,往往会让代码复杂度急剧上升。解决这个问题有几种思路:规定一个遍历的方向;添加限定;消除不必要的关联。实体间的关联,在数据库中经常会通过关系表来表达,但在领域对象中,完全可以通过类的引用关系来表示,不需要将关系抽象为实体(除非这个关系有特殊的业务意义)。
- 当一个实体内的部分属性,我们发现它们具有较强的相关性,这些属性单独抽象成一个对象可以更好的描述事物,且这个对象并不具备唯一性,我们就将它归类为值对象。值对象具备以下特征:不需要唯一标识来代表其唯一性;一些有关系的属性的聚合;不变性(值对象可以复制,并在对象间传递)。
- 实体关联的极简设计能够帮助我们描述现实世界事物之间的关系,并且能在一定程度上限制关系的复杂度增长,但随着业务发展,实体间的关系会越来越复杂,我们依然需要将这种关系表达在模型里,但是如果还是将这种关联表达在实体中,实体就会因各种关系带来的复杂性而膨胀,开发者也无法关注到模型的核心。当多个实体之间在某些场景下需要保持更改的一致性时,除了使用对象关联外,还可以建立一个对象组,将有着紧密关系的实体和值对象封装在一起,这个对象组就是领域模型中的聚合。聚合拥有两个重要特征:
- 边界:定义聚合内有什么,与其他聚合区分。
- 聚合根:聚合由聚合根(Aggregation root)统一管理,聚合根可以被理解成一个聚合中最具有代表性的实体。
- 选择聚合中的一个Entity作为聚合根;
- 通过根来控制对边界内其他对象的访问;
- 只允许外部对象保持对根的访问;
- 对边界内的其他对象通过根来遍历关联来发现;
- 在实际将聚合在代码中落地的过程中,有两种不同的写法:
- 一个对象,即是实体,也是聚合,同时是该聚合中的聚合根。此时,实体和聚合的概念经常容易搅在一起,只需要关注实体本身时,又不得不去考虑这个对象中关联的其他实体。
- 在实体之上单独定义一个聚合对象(xxAggreagte),在其中选择一个实体作为聚合根。
- 软件工程没有“银弹”,模型需要在实践中不断的演进和迭代,从简单到复杂,只要我们时刻关注模型是否能够反映业务实际情况。
- 查询不是领域模型。不要因为对数据的查询需求而改变领域模型,领域模型是为了映射业务活动,以及业务活动的影响,这个影响可能是领域内的数据,也可能是对领域外的改变。在我们的开发过程中,页面的展示,对外提供查询接口往往是高频变更的地方,查询的逻辑也经常是无花八门,很难控制用户想要把哪些数据聚合在一起展示。因此对于这种纯查询的场景,我们不要用领域模型去承载,最简单直接的方式就是直接从数据层去查询、拼装数据。这也是命令查询的责任分离(Command Query Responsibility Segregation,CQRS)这种设计模式一种体现。
- 以上所说的查询,和我们在写链路里需要从数据库中重建领域对象,是两种不同的场景。重建领域对象一般是通过repository来提供查询接口,返回的结果一定是领域对象,重建出来的领域对象也一定是在写入链路使用的。
- 工厂(Factory)。不同于设计模式中的工厂模式,这里的Factory仅仅是为了将领域对象创建的过程通过一种单独的模式独立出来。我们的一个系统,可能会对外提供多种类型、多种模式的入口,比如消息监听、端面、接口、定时任务等,不同的入口我们对外的契约不同,用户能提供的入参也不相同。我们使用领域驱动设计来作为代码设计的基本诉求是所有的核心业务代码都基于领域对象,因此领域对象的创建是一切业务代码的开始。Factory是承载将系统对外提供的请求模型转换为领域模型功能的一系列对象。为了屏蔽持久化方案的细节,我们使用仓库(REPOSITORY)来查询和持久化领域对象;有的时候我们期望直接获取到一个非空的领域对象,而不关心这个对象从哪里来,如何构造,那我们就需要工厂(FACTORY)来帮我们生产这个对象。
- 当创建一个实体对象或聚合的操作很复杂,甚至有很多领域内部的结构需要暴露的时候,就可以用工厂进行封装。一种相对简单粗暴的判断方法是看这个类的构造方法实现是否复杂,并且看着这些逻辑不应该由这个类实现,那么不妨用工厂来构造这个对象吧!
- 工厂可以利用不同的业务参数构建不同的领域模型。 对于简单的业务逻辑实现可以不使用工厂。工厂的实现不一定是类的形式,也可以是具备工厂功能的方法。
深入理解领域驱动设计中的聚合 聚合的本质就是建立了一个比对象粒度更大的边界,聚集那些紧密关联的对象,形成了一个业务上的对象整体。使用聚合根作为对外的交互入口,从而保证了多个互相关联的对象的一致性。通过把对象组织为聚合,在基本的对象层次之上构造了一层新的封装。封装简化了概念,隐藏了细节,在外部需要关心的模型元素数量进一步减少,复杂性下降。但是不是所有相关对象都聚合到一块呢?聚合划分的原则
- 生命周期一致性。生命周期一致性是指聚合边界内的对象,和聚合根之间存在“人身依附”关系。即:如果聚合根消失,聚合内的其他元素都应该同时消失。
- 问题域一致性。个图书网站,用户可以对图书发表评论。如果只是因为文章删除和评论删除之间存在逻辑上的关联,就让文章聚合持有评论对象,那么显然就约束了评论的适用范围。一目了然的事实是,评论这一个概念,在本质上和文章这个概念相去甚远。
- 场景频率一致性
- 聚合内的元素尽可能少
PS: 下图就是战术设计的结果
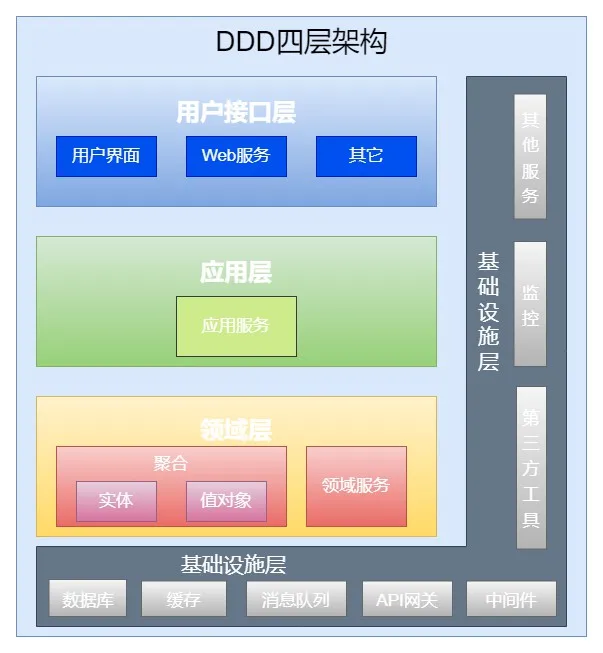
读写分离
DDD读写对待不一样的,写需要严格遵守分层结构。读不一定,看情况。
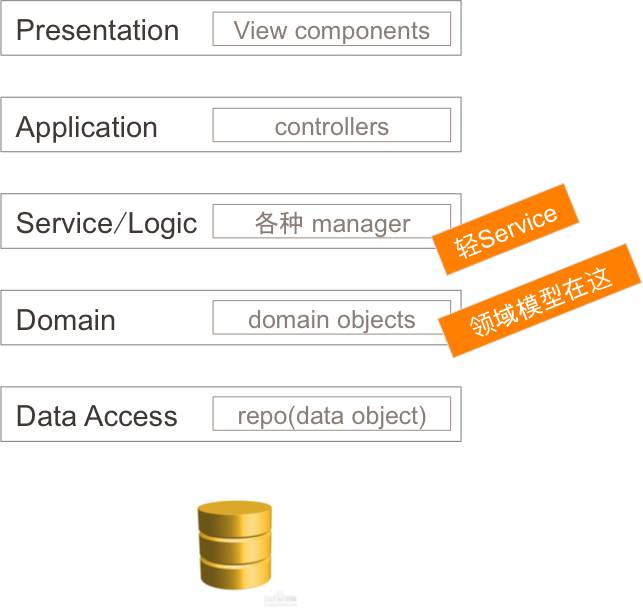
领域模型是用于领域操作的,当然也可以用于查询(read),不过这个查询是有代价的。在这个前提下,一个 aggregate 可能内含了若干数据,这些数据除了类似于 getById 这种方式,不适用多样化查询(query),领域驱动设计也不是为多样化查询设计的。 查询是基于数据库的(比如 获取某数据的列表,这是一个查询需求,不算业务模型之内。业务模型一般侧重于 几个抽象 以及 抽象之间的相互作用),所有的复杂变态查询其实都应该绕过 Domain 层,直接与数据库打交道。
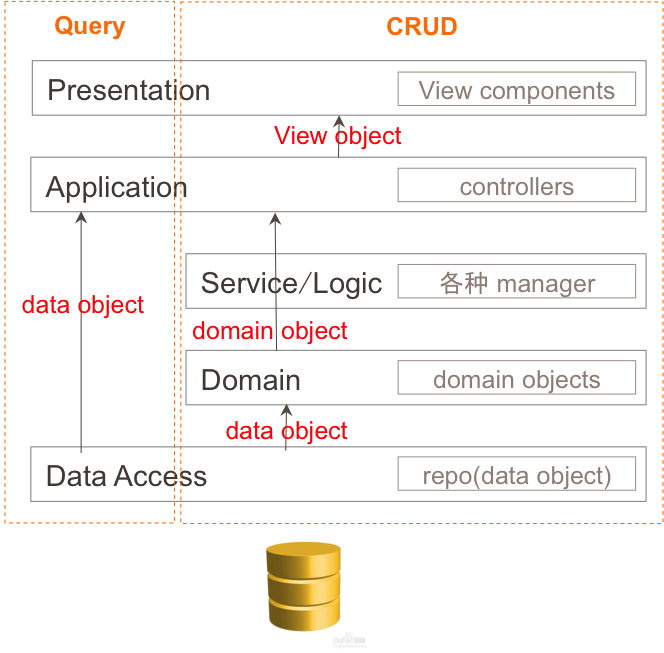
横着看
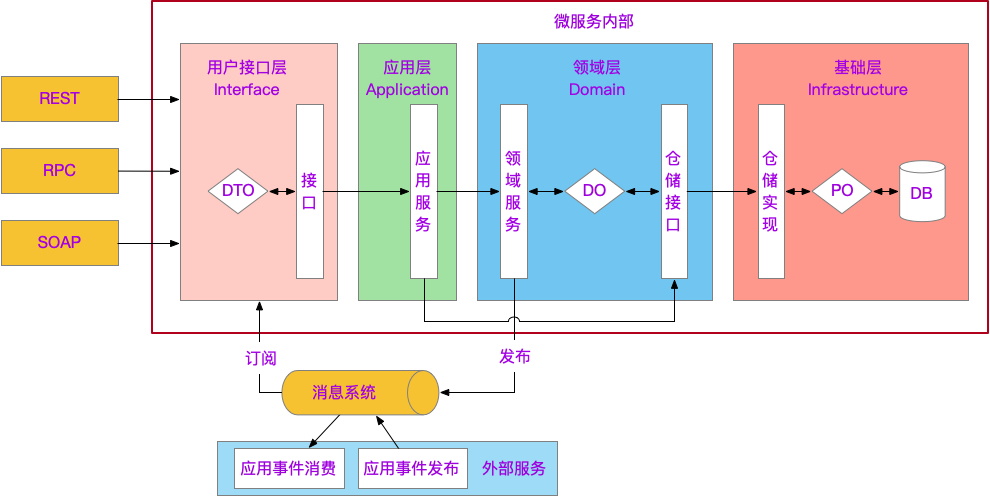
细节:贫血模型和充血模型
我们必须将应用程序的业务逻辑从服务层迁移到领域模型类中,为何呢? 先来看看贫血模型和充血模型的对比。
举个具体的例子,假设一个用户有很多收货地址
class User{
List<Address> addresses;
setter
getter
}
那么在为用户添加收货地址时,不得不有很多判空操作
class UserService{
void addAddress(User user,Address address){
List<Address> addresses = user.getAddresses();
if(null == addresses){
addresses = new ArrayList<Address>();
user.setAddresses(addresses);
}
addresses.add(address);
}
}
想象一下
- 如果有多个位置操作User的Address(这个例子针对这一点不是很适当),
if(null == addresses){...}会大量出现,代码量不大, 但会很丑。如果是电商业务,每一次购物都要做优惠券、红包、满减检查、余额不足检查等,这些逻辑有可能重复在各个Service中。PS: domain 的属性被Get 出去给业务逻辑用,业务逻辑就会散落,不如业务逻辑就写在domain里。信息专家原则:你拥有什么信息就应该承担怎样的职责。当我们在讨论是否是贫血模型时,你可以用这个原则去检验,如果一类中的成员属性操作放在另外一类中,大概率是不符合信息专家原则,举一个简单的例子,比如要计算订单的金额,那么这个计算方法应该是在订单类中,而不是放在另外一个类中,因为订单类中有订单的单价和数量。 - 更复杂的成员变量
List<List>或者List<Map<String,String>> - 更复杂的逻辑,比如设定默认地址,地址判重等。
UserService.addAddress吐血表示,我只想添加个地址而已。 换成充血模型
class User{
List<Address> addresses;
public User(){
addresses = new ArrayList<Address>();
}
void addAddress(Address address){
addresses.addAddress(address)
}
}
class UserService{
void addAddress(User user,Address address){
...
user.addAddress(address);
...
}
}
从中可以看到,addresses的 初始化和 添加都由User 负责,代码简洁很多。
PersistentObject一般由框架自动生成,不适合做改动,只提供setter/getter方法,或者说除了set/get什么都做不了。这样不得不很多逻辑放在XXService中,造成XXService的臃肿。直接暴露set/get很多时候是有不安全的。
如何从容应对复杂性基于贫血模型的传统开发模式,将数据与业务逻辑分离,违反了 OOP 的封装特性,实际上是一种面向过程的编程风格。充血模型是一种有行为的模型,模型中状态的改变只能通过模型上的行为来触发,同时所有的约束及业务逻辑都收敛在模型上。User的行为交由自己去管理, 而不是交给各种Service去管理。面向对象设计主张将数据和行为绑定在一起也就是充血模型,而贫血领域模型则更像是一种面向过程设计,贫血领域模型的根本问题是,它引入了领域模型设计的所有成本,却没有带来任何好处。最主要的成本是将对象映射到数据库中,从而产生了一个O/R(对象关系)映射层。只有当你充分使用了面向对象设计来组织复杂的业务逻辑后,这一成本才能够被抵消。
软件设计的中庸之道初识DDD的同学,最大的困惑不外乎是“我到底要把什么东西放到Domain里面?”并由此引发出一系列的设计模式:
- 失血模型:模型只是数据接口,没有任何的方法(能力)。
- 贫血模型:模型包含了一些原子能力。是一种将数据与行为分离的模型,其中数据由对象持有,而行为则由外部服务提供。
- 充血模型:模型包含了除了持久化之外的所有能力。它本质上是携带业务含义和行为的对象,而不仅仅是数据容器。传统的对象中也可以承载业务知识,在对象中我们可以定义很多属性,所以第一点领域对象和传统对象无异,但是第二点,领域对象相比传统对象反映了更加丰富的业务行为。
- 胀血模型:模型无所不包。
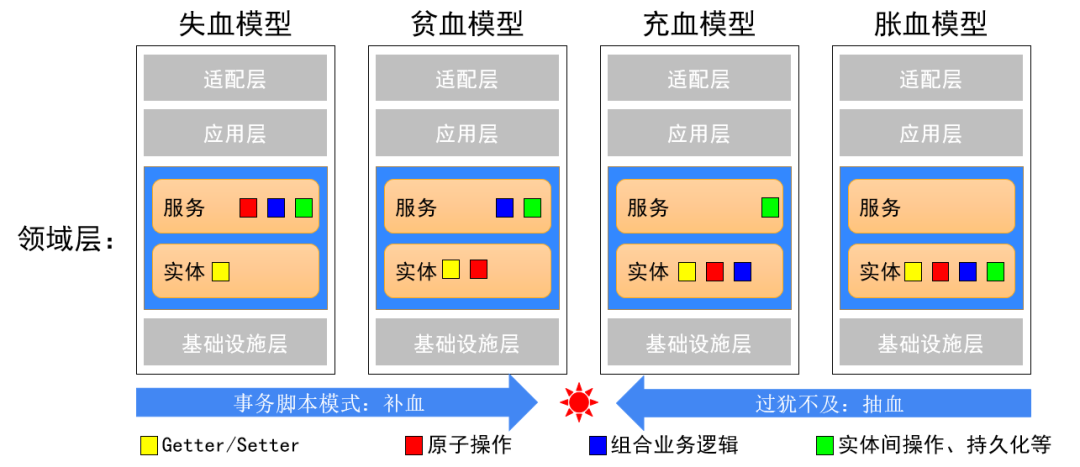
DDD之于业务支撑的意义在刚开始学习DDD的时候,我们可能会强行把一些逻辑放到实体中,进行控制和收敛。但后面随着业务的变化,会发现在实体中承担行为逻辑很难受:
- 影响较大:很难有勇气去频繁地修改一个核心类。
- 过于集中:随着方法和逻辑的增多,实体越来越臃肿。
- 场景较多:很多逻辑并不是正交的,不是 if 这样 else 那样的,充满着交集与叠加。 抛弃 POJO 的get、set,走向实体的丰富行为,让我们编写代码更加困难了么?其实,我们的烦恼来自于,太关注实体行为的收口,忽略了扩展的设计:
- 原来 get set 写法很舒服的本质在于,很多的扩展被放在了业务脚本中,业务脚本虽然千疮百孔,但是是在应用层,远离核心逻辑。底层模型、通用组件等基础逻辑还是比较干净的。
- 应用DDD的时候,把一些行为下沉到领域层之后,也是要考虑扩展的。如果只关注收口,不关注扩展,那的确是“画地为牢”、“捡了芝麻,丢了西瓜”。 但是,要突破这一个困境,能够在实体行为中设计扩展,其实要有这样的认同:要往上看一个层次,就是实体行为的表达,不一定只有一个类完成,可以通过策略模式等方式的路由,由一个模块中的一些类进行完成,只要对外有封装和管控其实就可以了。突破一个类的限制,走向更多的类的协作设计,也是我们进阶的方向。
落地
跨越DDD从理论到工程落地的鸿沟 伴随一个实际例子,值得细读。
- Domain层作为原来三层架构之外新引入的层次,会带来一些额外的成本。与其把Domain层当成负担,不如把它当成是一个机会或者投资,既然是投资,我们就要看ROI(投入产出比)。有没有ROI不成正比的时候呢?有的,比如简单的Query,可能就是读取数据,没有什么业务逻辑,那么我们也完全可以绕过Domain层,让数据模型直接转换成DTO,这也是CQRS所提倡的。一种典型的错误做法是把所有的业务逻辑都放到了Domain层,这样的DDD当然没人喜欢。
- 在domain层中,将各领域内的业务模型定义成entity和vo(value object),并且基于面向对象的思想,将相关的业务逻辑封装到类的成员方法中,以形成所谓的“充血模型”。
- 先把App层做厚,再把App做薄。我们先可以把业务逻辑都写到App里面,在写的过程中,我们会发现有一些业务逻辑,不仅仅是过程式的代码,它也是领域知识(Domain knowledge),应该被更加清晰、更加内聚的表达出来,那么我们就可以把这段代码沉淀为领域能力。
以用户注册为例
public class CustomerServiceImpl {
private CustomerGateway customerGateway;
private HealthCodeService healthCodeService;
public void register(CustomerDTO customerDTO){
Customer customer = Customer.fromDTO(customerDTO);
// 1. 校验年龄
if(customer.getAge() < 18){
BizException.of("对不起,你未满18岁");
}
// 2. 校验国籍
if(!customer.getCountry().equals("china")){
BizException.of("对不起,你不是中国人");
}
// 3. 查看健康码,需要调用另外一个服务。
HealthCodeRequest request = new HealthCodeRequest();
request.idCardNo = customer.getIdCardNo();
HealthCodeResponse response = healthCodeService.check(request);
if(!response.isSuccess()){
BizException.of("无法验证健康码,请稍后再试");
}
if(!response.isGreen()){
BizException.of("对不起,你不是绿码");
}
// 4. 注册用户
customerGateway.save(customer);
}
}
年龄和国籍都是customer的属性,对于这样的业务知识,无能是从可理解性的角度,还是从功能内聚和复用性的角度,把它们沉淀到customer身上都会更合适。
class Consumer{
public void isRequiredAge(){
if(age < 18){
BizException.of("对不起,你未满18岁");
}
}
public void isValidCountry(){
if(!country.equals("china")){
BizException.of("对不起,你不是中国人");
}
}
}
健康码有点特殊,虽然它也是Customer的健康码,但是它并不存在于本应用中,而是存在于另一个服务中,需要通过远程调用的方式来获取。这在我们的分布式系统中,是非常常见的现象,即我们要通过分布式的服务交互来共同完成业务功能。如果直接调用外部系统,基于外系统的DTO,当然也能完成代码功能,但这样做会有三个问题:表达晦涩;复用性差,校验健康码不仅仅客户注册会用到,可能很多客户相关的操作都会用到;没有防腐和隔离,HealthCodeResponse不是我这个注册领域的东西,怎么能让它如此轻易的侵入到我的业务代码中呢?
解决上面的问题,我们就可以充分发挥Domain层的边界上下文(Bounded Context)的作用,使用上下文映射(Context Mapping),把外领域的信息映射到本领域。即我可以认为HealthCode就是属于Customer的,至于这个HealthCode是怎么来的,那是Gateway和infrastructure要帮我处理的问题,它可能来自于自身的数据库,也可能来自于RPC的远程调用,总之那是infrastructure要处理的“技术细节”问题,对于上层的业务代码不需要关心。
public class Customer {
...
// 你虽然是游荡在外面游子,但我带你如同己出
private String healthCode;
public void isHealthCodeGreen(){
if(healthCode != null){
healthCode = healthCodeGateway.getHealthCode(idCardNo);
}
if(!healthCode.equals("green")){
BizException.of("对不起,你不是绿码");
}
}
...
}
经过一系列的“能力下沉”之后,除了代码变得clean之外,代码的可理解性也提高了
public class CustomerServiceImpl {
private CustomerGateway customerGateway;
public void register(CustomerDTO customerDTO){
Customer customer = Customer.fromDTO(customerDTO);
// 1. 校验年龄
customer.isRequiredAge();
// 2. 校验国籍
customer.isValidCountry();
// 3. 查看健康码,需要调用另外一个服务。
customer.isHealthCodeGreen();
// 4. 注册用户
customerGateway.save(customer);
}
}
小结
2018.6.20 补充 大家一直在谈的领域驱动设计(DDD),我们在互联网业务系统是这么实践的 本文字字珠玑,适合细读。
留下评论