技术人员的产品思维
简介
小盖:”如果把需求当成一个点,那所有的商业都应该发生在需求的延长线上。因为我们没有办法为自己的产品创造出来一个刚性的需求。这是我三年来的创业总结。做一件事之前,先看需求,以及你用什么样的方式满足需求。至于其他的,情怀、想象空间、执行力,都是次次要的。
app
我是喜马拉雅app的忠实粉丝,有一次跟产品的鹏哥闲聊:我看到很多产品经常加班很辛苦,但感觉我们的app 一年了没什么变化啊。后来我琢磨了下:为什么很多特性我不知道,发现我对app的使用路径是:打开 ==> 肚脐眼(记录了上一次播放) ==> 郭德纲相声下一首 ==> 设置播放完自动关闭 ==> 锁屏睡觉。
这有两个方面的问题
- 我对我们的app 不够熟悉,不能够理解功能演化背后的产品逻辑,以致于不知道或者知道了也不认可某个新特性的用处
- 我或许是一个少数群体
- 我对app的使用场景是明确的,就是睡前。很多新功能特性是基于用户会“闲逛”的假设,可能效果会有限。举个例子,如果某个产品主打青年男性群体,那么应该在各类游戏、社交、社交app上投广告,而在大街上投广告的作用会很有限,因为他们很少逛街。为解决这个问题,我们有两个发力方向:一 为用户提供更多价值,使得用户别光在睡前才用我们;二 发力好睡前场景,睡前进入app时界面做的更精简,甚至给用户生成一个睡眠报告。
- 我对app的使用目的是非常明确的,就是助眠。此时,只有助眠类的声音才会中断我常规的使用路径,助眠或许可以提成一个专门的声音分类,晚上的时候个性化推荐可以增加助眠类声音的权重,类似的还有开车等。
我们的产品还停留在 各路大V 赶紧来我们的平台做节目,给用户提供更多更好地内容。那么反过来, 我们是否可以通过用户的收听行为感知到用户的需要,进而可以影响声音的“供给”。比如我们通过搜索敏感词、某一类音频的收听指数提高 来感知比如 机器学习的 热度上升,就可以给相关的节目提供商更高的报价/降低该门类的付费门槛吸引更多主播。阿里新零售的一个重要概念之一就是,阿里可以知道一个便利店方圆1000米大部分人群的收入构成、职业及消费习惯,然后就可以估算出来该门店明天应该进货多少个5块的包子、3块的包子。说了这么多,鹏哥的一个词儿就概括了:按需生产。
平台系统
如果你做了一个框架,接入很麻烦,那么基本是没什么人用的。使用文档1页最好,超过2页基本没人细看,很少有人看到第3页,所以你写那么多“注意事项”都只是给自己加戏。
如果原先有一个老系统,你做了一个新系统,这个时候技术先进性什么的都没有价值,迁移新系统是需要成本的,新系统hold 不住迁移成本,再多的宣传都作用不大。
尽量润物细无声,搭顺风车,将自己的功能挂在一个已有的系统、流程里面。
我一直在组内推研发协作工具,每周五(有时会忘)下午会去小组群里发:大家同步下teambition,发下周报。但还是搞不起来,因为有事大家还是习惯IM直接说,我老拿忘发周报说事也不好。teambition 是比IM 更好的协作方式,好但不是足够好
- 需要一个组织文化+开发流程的加持。
- 很多时候人和人的沟通是不可避免的,甚至文字沟通都是不够的,面对面的表情、语气也很重要。面对面/IM沟通必不可免 ==> 面对面/IM沟通时顺带手沟通了 其实不需要 IM 沟通的事项。这个时候,用teambition再排一遍就显得多余。你不能假设开发、测试都在“闲庭信步”,大部分时候他们都是“焦头烂额”,根本不想理会哪怕一点多余的事情。
所以我的一个想法是,如果teambition 能够支持根据feature完成情况自动生成周报的功能。一个是大家不用再写周报了,另一个是大家自然就会多用teambition(用的越多,周报越充实)。
共振
我没事琢磨过,为什么拼多多每年可以有翻几倍的增长,而我们增长的慢一些。一个重要原因是
- 网购的市场已经很大,拼多多只做一件事就行了,就是从网购的市场中吃到尽可能大的蛋糕。
- 而我们其实在做两件事:先把听声音变成大家习惯的一件事,然后再争取这个群体中绝大部分用户。自然就慢一些。
关于这个词儿,鹏哥一个词总结:转化效率。
交流很重要,关于这个鹏哥又说了一个词儿:共振。因为想法很重要又不重要,想法落地是需要真金白银的,在资源有限的时候,甚至需要你牺牲其它方向的投入来保障想法落地,想法不坚定、不清晰就会迟疑反复,更多的共识有助于增强信心,减少推进阻力。
如何判断想法是否靠谱
引用乔布斯的一段话,“一个问题看上去很简单,是因为你并没有理其复杂性;当你把问题搞清楚之后,又会发现其实很复杂,然后拿出了一套复杂的方案来,实际上你只实现了一半,大多数人也都会到此为止;但真正伟大的人会继续前进,找到问题的关键和内在的深层次原因,再拿出优雅的、堪称完美的解决方案”
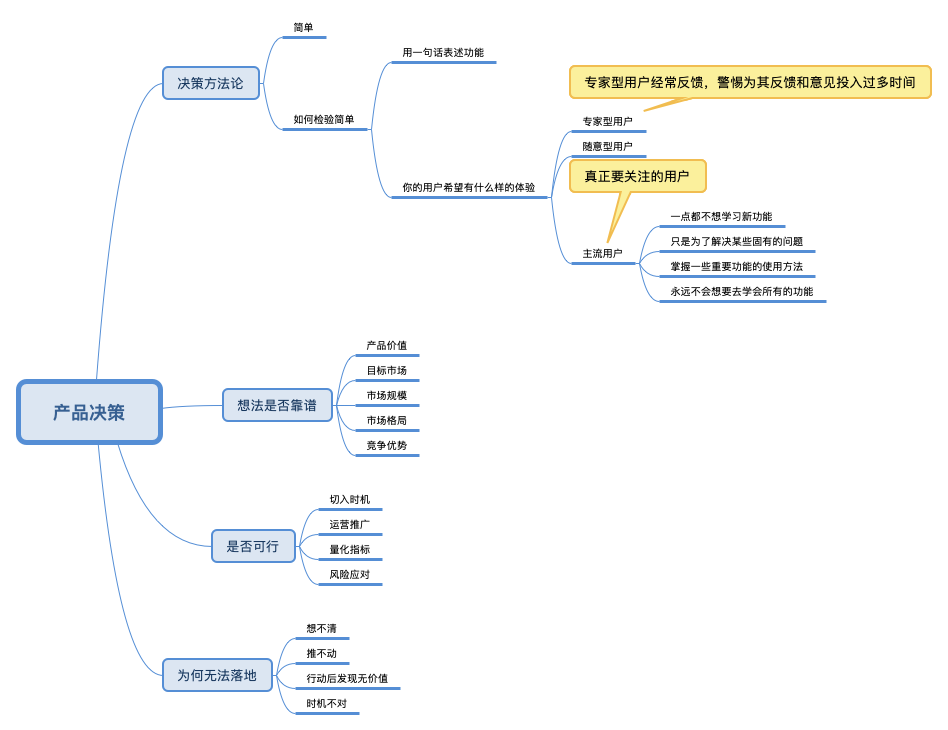
汤力嘉:如何判断想法是否靠谱呢,可以从五个方面出发:
- 产品价值,产品的核心价值是什么?它解决了什么问题?这个问题在此产品没有出现之前是怎么解决的?此产品出现后,是否能更有效的解决问题? PS:《软件架构设计》功能和系统不是需求,只是解决问题的一种答案。
- 目标市场,比如市场的用户存量、用户群体、用户画像、用户消费能力,等等。
- 市场规模,包括存量的市场和增量的市场,增量市场即发展前景
- 市场格局,比如市场中的同款或同类型产品有几种形态,每种产品的布局是怎么样的?大公司有没有进来?产业链是怎样的?
- 竞争优势,这是最重要的一方面,很多时候我们去做一个产品并不是因为产品本身能带来什么,而是先看我们能做什么,有何竞争优势。
确定想法靠谱之后,就该判断该想法是否可行,我们可以从四方面来判断。
- 切入时机,包括自身的硬件条件、技术能力是否已具备实现想法的能力,对用户感知、用户习惯的洞察是否已经有所培养等。
- 运营推广,酒香也怕巷子深,所以,我们可能要先想一想,有什么办法能走出这条“巷子”。
- 量化指标,包括产品进度、人员成本、运营计划等,每一环、每一步都需要制定明确的指标,不断跟进、落实,以降低风险。
- 风险应对,风险可能会来自各个方面,比如财务方面、法律方面、商标、政府部门等等,所以,需要尽可能的想到应对各方面风险的措施
最后,确定了产品策略靠谱,又可执行,但为什么还是无法落地呢?
- 想不清,想法落地的过程中可能会发生改变,这是最伤筋动骨的。
- 推不动,包括人员、招聘、推广等等,都有可能推不动。
- 行动后发现,全量的客户有限,根本没有增量空间,这就是没有价值
- 时机不对,比如手机处理视频特效的功能,提出这个想法的时候,当时的手机配置还不足以支撑这个功能。
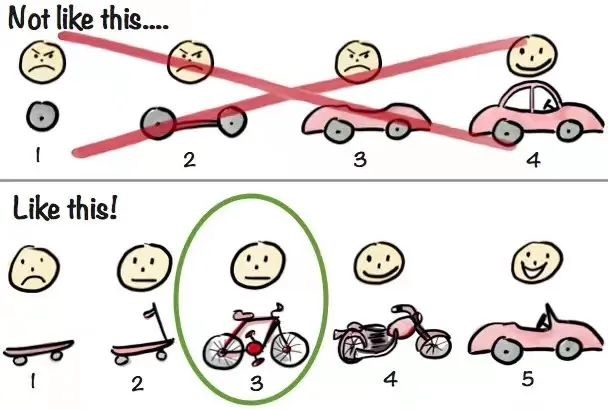
《邱岳的产品实践》在设计最小可用产品(MVP)之前,一定要想清楚自己想验证的问题,要收集哪些数据项,还有这些数据项可能出现的结果,以及不同结果代表的结论。这个事情有点像软件工程中的 TDD(测试驱动开发),先把想要得到的结果列出来,再反推设计,以免设计逻辑不清楚,或者漏掉数据打点,反倒浪费了资源。比如我前面举的那个数据分析功能,我也是在推演的时候才发现需要多做一些数据功能,否则如果功能本身太简陋导致使用率高留存低的情况,就会难以辨别哪里出了问题。
产品哲学
阿里巴巴资深技术专家无相:我们能从 InteliJ IDEA 中学到什么? Every aspect of IntelliJ IDEA is designed with ergonomics in mind. IntelliJ IDEA is built around the idea that every minute a developer spends in the flow is a good minute, and things that break developers out of flow are bad things. Every design and implementation decision considers the possibility of interrupting developer’s flow and seeks to eliminate or minimize it. “Creative Flow” or just “Flow” is a state of mind where you feel evenly attuned, and focused on the task at hand. 当用户使用你的产品时,尽量减少中断用户使用的东西,使其沉浸其中。比如我比较喜欢idea的一点是,idea 直接集成了命令行
鹏哥:做产品一定要去触发用户的情感。 比如我们做一个产品展示用户的收听历史,这个时候单纯的信息可视化 对用户的触动有限,更有价值的比如说:用户最早使用时间、最晚使用时间等等,再辅助一些情感的话术。
取舍
一个大神说过,判断一个featrue的价值就是:没有它和有它有什么区别。其实我觉得还可以补上一句:有了它之后再失去它会不会感觉很难受
产品要做的几个事儿
- 发现需求
- 拒绝需求。
- 功能只要做就比不做有用,但要看覆盖面够不够,切勿仅凭觉得有用就去做系统;
- 做出来是一回事,推的动是另一回事(是否掌握了上下游资源进行协同),要根据推不推得动去反推做不做;
用户至上:
技术人员的一点产品思维思考抽象能力相信大家做技术的都或多或少有一些、平时写代码中也经常用到。但是根据已有的内容去抽象、和面向未来去抽象是2种完全不一样的能力。当技术人员具备产品视角之后,会更容易发现抽象的角度、也更容易表达出来抽象的概念
- 产品思维很重要的一点是,不能从需求层面,而是应该从实现层面来思考,思考怎么把它做出来,怎么把它设计出来。
- “用什么方法,解决谁的,什么问题”里谁的问题是更重要的。只要找到了这个问题,再想用什么方法解决它,不同的产品经理有不同的实践方法。但如果你拿到一个伪需求,一个非高频非刚需的需求,你使了很多蛮力,做出一个更好的解决方案,但最终你却可能是一无所获。基于这个背景,我们去思考为什么要有产品经理?为什么开发不直接跟业务部门对接?一个很重要的原因就是产品经理会在中间发现各种各样伪装成需求的解决方案、伪装成需求的提案、伪装成需求的要求。而不是说我有一把锤子,满世界找钉子。用方法来驱动自己解决问题。我觉得一个产品经理最重要的是需求的识别能力。你识别到一个需求,这个需求它是伪需求还是刚需?再进一步,它是不是高频的刚需?这个需求在市场里的定位是怎样的?是不是真的有这样的定位?找提出的“需求”背后的真实动机,再去看这个动机是少部分人还是很多人的?以及满足这个需求的话,会不会又伤害到别人?想清楚了这些,我们再找解决方案。我认为产品经理的第一职业素养或者第一职业尊严,就是不能把业务部门发来的需求直接转发给开发。
- 需求来源有很多,我之前跟同行聊天,还开玩笑说根本不用问产品经理需求从哪来,你坐在那,10 万个人会给你提 10 万个需求,你要做的是把从这十万个需求里面去挑出两三个做一做,都不大需要自己的创意。张小龙说需求不来自产品经理,需求不来自用户,需求不来自用户调研。那需求来自哪呢?他说需求来自你的感知。对底层逻辑的透析。如果你做一个工具,你最好是它的重度使用者。那你在解决自己需求的同时,也解决了其他人的需求。因为人的共情、同理心使得很多底层的东西是相通的。
- 比如说现在池老师让我晚上来上直播,我不会干巴巴地问他:你为什么要做直播?他说这是一个跟微信的合作;我说你为什么要跟微信合作?他说建立影响力;我说你为什么要建立影响力?基本上问到这儿,朋友就很难做了。你是有各种各样的方法,让这个天儿聊得不那么具有攻击性的。我会通过变换自己说话的方式,对他说,直播是好事儿,别人想直播还直播不了,但是我很想请教一下在这个时候做这个主题的直播,除了用户的需求外,是不是还有些什么其他的考虑?池老师一听这就来劲了,开始倒茶,说你坐好,我给你慢慢道来。很多事情,通过引导的方式真正地好奇去问,和你只是程序化地不断问为什么感觉是不一样的。如果你真的是带着尊重的好奇,一定会让那个人打开话匣子的。
- 很多时候你跟业务方的交流、包括跟开发的交往,取决于你跟他的私下的关系是怎么样。很多的时候在公司里头如果完全公事公办,你做不成任何事情。如果你跟他已经建立了足够的信任,那么你们的交流效率就会很高,你们交流底线也会比较低。所以产品经理的工作里,跟业务团队、运营团队、开发团队,建立良好的信任关系是非常重要的。
池建强:产品经理圈,有条梳理需求的思考方法:“用什么方法,解决谁的,什么问题”,这三点里,“谁的问题”是更重要的。只要找到了这个问题,再想用什么方法解决它,不同的产品经理有不同的实践方法。但如果你拿到一个伪需求,一个非高频非刚需的需求,你使了很多蛮力,做出一个更好的解决方案,但最终你却可能是一无所获。
马丁:在国内,当用户的需求是一根火腿的时候,他想要的往往是一个自动化屠宰场。
留下评论