Kubernetes存储
简介
- 简介
- Volume 背景介绍
- docker volume——物理机的一个目录
- Kubernetes的存储设计理念
- kubernetes volume——为容器提供外置存储能力
- kubelet 相关代码实现
云原生存储的两个关键领域:
- Docker 存储卷:容器服务在单节点的存储组织形式,关注数据存储、容器运行时的相关技术;
- K8s 存储卷:关注容器集群的存储编排,从应用使用存储的角度关注存储服务。
Volume 背景介绍
Docker容器的文件系统分层机制主要靠联合文件系统(UnionFS)来实现。联合文件系统保证了文件的堆叠特性,即上层通过增加文件来修改依赖层文件,在保证镜像的只读特性时还能实现容器文件的读写特性。
从UnionFS说起
每个容器都需要一个镜像,这个镜像就把容器中程序需要运行的二进制文件,库文件,配置文件,其他的依赖文件等全部都打包成一个镜像文件。如果容器使用普通的 Ext4 或者 XFS 文件系统,那么每次启动一个容器,就需要把一个镜像文件下载并且存储在宿主机上。假设一个镜像文件的大小是 500MB,那么 100 个容器的话,就需要下载 500MB*100= 50GB 的文件,并且占用 50GB 的磁盘空间。在绝大部分的操作系统里,库文件都是差不多的。而且,在容器运行的时候,这类文件也不会被改动,基本上都是只读的。
假如这 100 个容器镜像都是基于”ubuntu:18.04”,你不难推测出理想的情况应该是什么样的?当然是在一个宿主机上只要下载并且存储存一份”ubuntu:18.04”,所有基于”ubuntu:18.04”镜像的容器都可以共享这一份通用的部分,不同容器启动的时候,只需要下载自己独特的程序部分就可以。正是为了有效地减少磁盘上冗余的镜像数据,同时减少冗余的镜像数据在网络上的传输,选择一种针对于容器的文件系统是很有必要的,而这类的文件系统被称为 UnionFS。
UnionFS 这类文件系统实现的主要功能是把多个目录一起挂载(mount)在一个目录下。
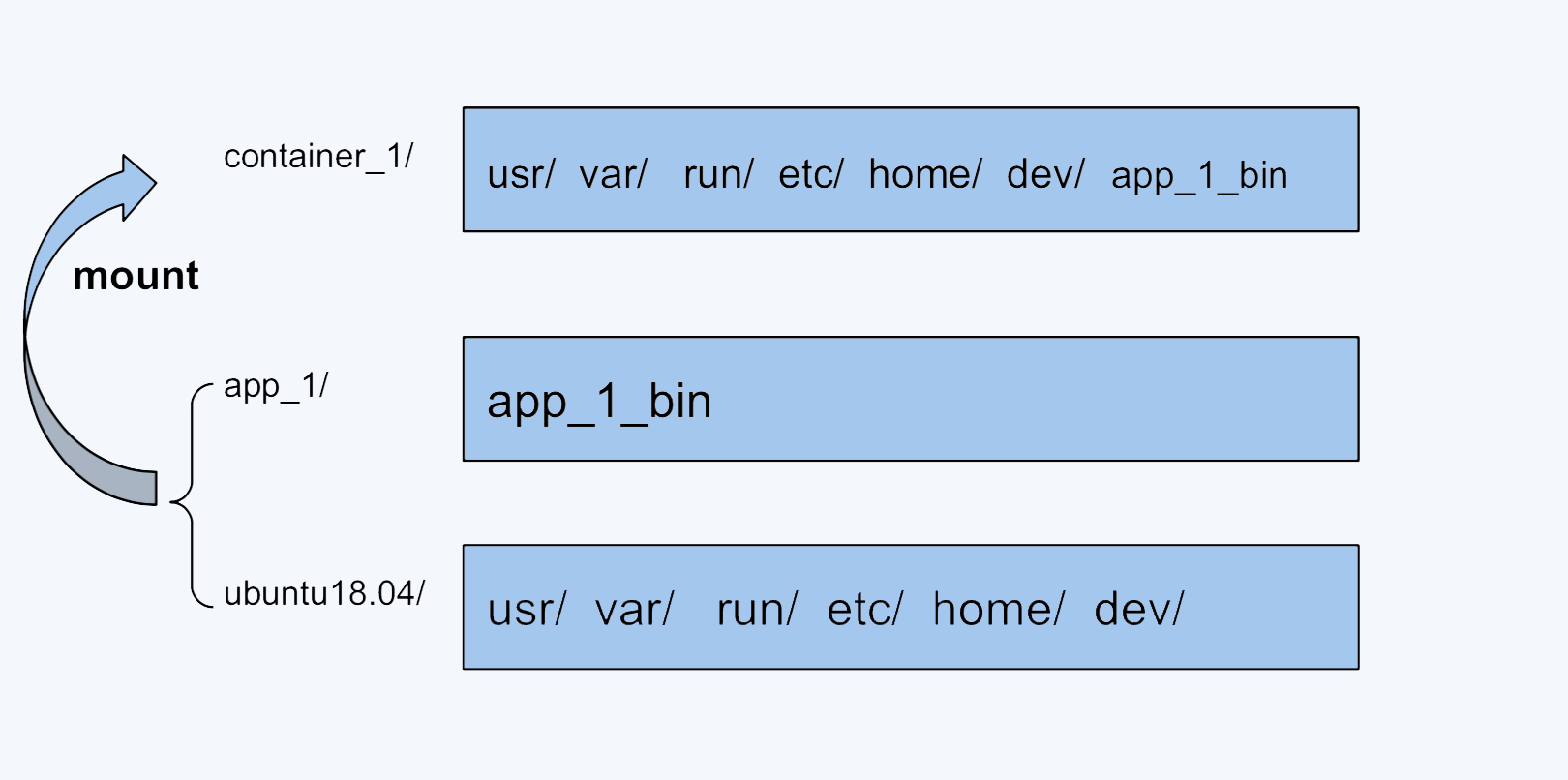
云原生存储详解:容器存储与 K8s 存储卷容器服务之所以如此流行,一大优势即来自于运行容器时容器镜像的组织形式。容器通过复用容器镜像的技术,实现多个容器共享一个镜像资源(更细一点说是共享某一个镜像层),避免了每次启动容器时都拷贝、加载镜像文件,这种方式既节省了主机的存储空间,又提高了容器启动效率。为了实现多个容器间共享镜像数据,容器镜像每一层都是只读的。
以下引用自深入理解Docker Volume(一)先谈下Docker的文件系统是如何工作的。Docker镜像是由多个文件系统(只读层)叠加而成。当我们启动一个容器的时候,Docker会加载只读镜像层并在其上添加一个读写层。写时复制:如果运行中的容器修改了现有的一个已经存在的文件,那该文件将会从读写层下面的只读层复制到读写层,该文件的只读版本仍然存在,只是已经被读写层中该文件的副本所隐藏。一旦容器销毁,这个读写层也随之销毁,之前的更改将会丢失。在Docker中,只读层及在顶部的读写层的组合被称为Union File System(联合文件系统)。

merged/upper/lower 也是linux UnionFS 官方的说法,可以在/proc/mounts 查看所有mount 信息。
为什么要有volume
云原生存储详解:容器存储与 K8s 存储卷容器中的应用读写数据都是发生在容器的读写层,镜像层+读写层映射为容器内部文件系统、负责容器内部存储的底层架构。当我们需要容器内部应用和外部存储进行交互时,需要一个类似于计算机 U 盘一样的外置存储,容器数据卷即提供了这样的功能。 ==> 容器存储组成:只读层(容器镜像) + 读写层 + 外置存储(数据卷)
DockOne技术分享(五十七):Docker容器对存储的定义(Volume 与 Volume Plugin)提到:Docker容器天生设计就是为了应用的运行环境打包,启动,迁移,弹性拓展,所以Docker容器一个最重要的特性就是disposable,是可以被丢弃处理,稍瞬即逝的。而应用访问的重要数据可不是disposable的,这些重要数据需要持久化的存储保持。Docker提出了Volume数据卷的概念就是来应对数据持久化的。
简单来说,Volume就是目录或者文件,它可以绕过默认的UFS,而以正常的文件或者目录的形式存在于宿主机上。换句话说,宿主机和容器建立/a:/b的映射,那么对容器/b的写入即对宿主机/a的写入(反之也可)。
the two main reasons to use Volumes are data persistency and shared resources:
- 将容器以及容器产生的数据分离开来。相比通过存储驱动实现的可写层,数据卷读写是直接对外置存储进行读写,效率更高
- 容器间共享数据
docker volume——物理机的一个目录
Volume 挂载方式语法:-v: src:dst:opts
// 创建一个容器,包含两个数据卷
$ docker run -v /var/volume1 -v /var/volume2 -name Volume_Container ubuntu14.04 linux_command
// 创建App_Container容器,挂载Volume_Container容器中的数据卷
$ docker run -t -i -rm -volumes-from Volume_Container -name App_Container ubuntu14.04 linux_command
// 这样两个容器就可以共用这个数据卷了
// 最后可以专门安排一个容器,在应用结束时,将数据卷中的内容备份到主机上
docker run -rm --volumes-from DATA -v $(pwd):/backup busybox tar cvf /backup/backup.tar /data
在默认方式下,volume就是在/var/lib/docker/volumes目录下创建一个文件夹,并将该文件夹挂载到容器的某个目录下(以UFS文件系统的方式挂载)。当然,我们也可以指定volume为主机的某个特定目录(该目录要显式指定)挂载到容器的目录中。
docker run -v /container/dir imagename command
docker run -v /host/dir:/container/dir imagename command
docker run -v dir:/container/dir imagename command
第三种方式相当于docker run -v /var/lib/docker/volumes/dir:/container/dir imagename command
到目前为止,容器的创建/销毁期间来管理Volume(创建/销毁)是唯一的方式。
- 该容器是用
docker rm -v命令来删除的(-v是必不可少的)。 docker run中使用了--rm参数
即使用以上两种命令,也只能删除没有容器连接的Volume。连接到用户指定主机目录的Volume永远不会被docker删除。bypasses the Union File System, independent of the container’s life cycle.Docker therefore never automatically deletes volumes when you remove a container, nor will it “garbage collect” volumes that are no longer referenced by a container. Docker 有 Volume 的概念,但对它只有少量且松散的管理(没有生命周期的概念),Docker 较新版本才支持对基于本地磁盘的 Volume 的生存期进行管理。
Kubernetes的存储设计理念
周志明
- 容器是镜像的运行时实例,为了保证镜像能够重复地产生出具备一致性的运行时实例,必须要求镜像本身是持久而稳定的,这就决定了在容器中发生的一切数据变动操作,都不能真正写入到镜像当中,否则必然会破坏镜像稳定不变的性质。PS:云原生伴随着存算分离,但终究还是要访问数据的,尤其是针对数据密集型应用。
- Docker 内建支持了三种挂载类型,分别是 Bind(–mount type=bind)、Volume(–mount type=volume)和 tmpfs(–mount type=tmpfs)
- Bind Mount 是 Docker 最早提供的(发布时就支持)挂载类型,作用是把宿主机的某个目录(或文件)挂载到容器的指定目录(或文件)下
- 从 Docker 17.06 版本开始,Bind 就在 Docker Swarm 中借用了–mount参数过来,这个参数默认创建的是 Volume Mount,从 Bind Mount 到 Volume Mount,实质上是容器发展过程中对存储抽象能力提升的外在表现。我们根据“Bind”这个名字,以及 Bind Mount 的实际功能,其实可以合理地推测,Docker 最初认为“Volume”就只是一种“外部宿主机的磁盘存储到内部容器存储的映射关系”,但后来它眉头一皱,发现事情并没有那么简单:存储的位置并不局限只在外部宿主机,存储的介质并不局限只是物理磁盘,存储的管理也并不局限只有映射关系。
- 比如,Bind Mount 只能让容器与本地宿主机之间建立某个目录的映射,那么如果想要在不同宿主机上的容器共享同一份存储,就必须先把共享存储挂载到每一台宿主机操作系统的某个目录下,然后才能逐个挂载到容器内使用,这种跨宿主机共享存储的场景涉及到大量与宿主机环境相关的操作,只能由管理员人工地去完成,不仅繁琐,而且由于每台宿主机环境的差异,还会导致主机很难实现自动化。
- 即使只考虑单台宿主机的情况,Docker 也完全有支持 Volume Mount 的必要。在 Bind Mount 的设计里,Docker 只有容器的控制权,存放容器生产数据的主机目录是完全独立的,与 Docker 没有任何关系,它既不受 Docker 保护,也不受 Docker 管理。所以这就使得数据很容易被其他进程访问到,甚至是被修改和删除。
- 存储并不是只有挂载在宿主机上的物理存储这一种介质。在云计算时代,网络存储逐渐成为了数据中心的主流选择,不同的网络存储都有各自的协议和交互接口。而且,并不是所有的存储系统都适合先挂载到操作系统,然后再挂载到容器的,如果 Docker 想要越过操作系统去支持挂载某种存储系统,首先必须要知道该如何访问它,然后才能把容器中的读写操作自动转移到该位置。Docker 把解决如何访问存储的功能模块叫做存储驱动(Storage Driver)。PS:弹性集群,节点是可能是临时申请和释放的,物理机完全可以具备fuse等能力,将对文件的读写变为网络读写。
- Kubernetes 把 Volume 分为了持久化的 PersistentVolume 和非持久化的普通 Volume 两类,普通 Volume 的设计目标并不是为了持久地保存数据,而是为同一个 Pod 中多个容器提供可共享的存储资源,所以普通 Volume 的生命周期非常明确,也就是与挂载它的 Pod 有着相同的生命周期。这样,就意味着尽管普通 Volume 不具备持久化的存储能力,但至少比 Pod 中运行的任何容器的存活期都更长。
- PersistentVolume 可以独立于 Pod 存在,生命周期与 Pod 无关,所以也就决定了 PersistentVolume 不应该依附于任何一个宿主机节点,否则必然会对 Pod 调度产生干扰限制。那么,在把 PersistentVolume 与 Pod 分离后,就需要专门考虑 PersistentVolume 该如何被 Pod 所引用的问题了。所以,Kubernetes 又额外设计出了 PersistentVolumeClaim 资源。
kubernetes volume——为容器提供外置存储能力
A Volume is a directory, possibly with some data in it, which is accessible to a Container. Kubernetes Volumes are similar to but not the same as Docker Volumes.
A process in a Container sees a filesystem view composed from two sources: a single Docker image and zero or more Volumes(这种表述方式很有意思). A Docker image is at the root of the file hierarchy. Any Volumes are mounted at points on the Docker image; Volumes do not mount on other Volumes and do not have hard links to other Volumes. Each container in the Pod independently specifies where on its image to mount each Volume. This is specified a VolumeMounts property.
The storage media (Disk, SSD, or memory) of a volume is determined by the media of the filesystem holding the kubelet root dir (typically /var/lib/kubelet)(volumn的存储类型(硬盘,固态硬盘等)是由kubelet所在的目录决定的). There is no limit on how much space an EmptyDir or PersistentDir volume can consume(大小也是没有限制的), and no isolation between containers or between pods.
apiVersion: v1
kind: Pod
metadata:
name: test-pod
spec:
containers:
- name: test-container
image: k8s.gcr.io/busybox
volumeMounts: ## 这里的volume 配置可以视为单纯的传递给 container runtime的参数
- name: cache-volume
mountPath: /cache
- name: test-volume
mountPath: /hostpath
- name: config-volume
mountPath: /data/configmap
- name: special-volume
mountPath: /data/secret
volumes: ## 集群范围内的volume配置,在pod 调度到某个机器上时,k8s 要负责将这些volume 在 Node 上准备好
- name: cache-volume
emptyDir: {}
- name: hostpath-volume
hostPath:
path: /data/hostpath
type: Directory
- name: config-volume
configMap:
name: special-config
- name: secret-volume
secret:
secretName: secret-config
Types of Volumes 支持十几种类型的Volume
- Volume 与pod 声明周期相同,不是 Kubernetes 对象,主要用于跨节点或者容器对数据进行同步和共享。 EmptyDir、HostPath、ConfigMap 和 Secret
- PersistentVolume,为集群中资源的一种,它与集群中的节点 Node 有些相似,PV 为 Kubernete 集群提供了一个如何提供并且使用存储的抽象,与它一起被引入的另一个对象就是 PersistentVolumeClaim(PVC),这两个对象之间的关系与Node和 Pod 之间的关系差不多。PVC 消耗了持久卷资源,而 Pod 消耗了节点上的 CPU 和内存等物理资源。PS:当 Kubernetes 创建一个节点时,它其实仅仅创建了一个对象来代表这个节点,并基于 metadata.name 字段执行健康检查,对节点进行验证。如果节点可用,意即所有必要服务都已运行,它就符合了运行一个 pod 的条件;否则它将被所有的集群动作忽略直到变为可用。
云原生存储详解:容器存储与 K8s 存储卷另一种划分方式:
- 本地存储:如 HostPath、emptyDir(临时卷,即 Pod 删除后临时卷也随之删除),这些存储卷的特点是,数据保存在集群的特定节点上,并且不能随着应用漂移,节点宕机时数据即不再可用;
- 网络存储:Ceph、Glusterfs、NFS、Iscsi 等类型,这些存储卷的特点是数据不在集群的某个节点上,而是在远端的存储服务上,使用存储卷时需要将存储服务挂载到本地使用;
- Secret/ConfigMap:这些存储卷类型,其数据是集群的一些对象信息,并不属于某个节点,使用时将对象数据以卷的形式挂载到节点上供应用使用;
- CSI/Flexvolume:这是两种数据卷扩容方式,可以理解为抽象的数据卷类型。每种扩展方式都可再细化成不同的存储类型;其中,FlexVolume 因为其命令式的特点,不易维护和管理,从 Kubernetes v1.23 版本开始已被弃用。
因为 PVC 允许用户消耗抽象的存储资源,所以用户需要不同类型、属性和性能的 PV 就是一个比较常见的需求了,在这时我们可以通过 StorageClass 来提供不同种类的 PV 资源,上层用户就可以直接使用系统管理员提供好的存储类型。
kubelet 相关代码实现
源码包
k8s.io/
/utils
/mount
/mount_linux.go // 定义了Mounter
/kubernetes
/pkg
/kubelet
/kubelet.go
/volumemanager
/populator
/desired_state_of_world_populator.go
/reconciler
/reconciler.go
/volume_manager.go
/volume
/volume.go // 定义了 Mounter
/plugins.go // 定义了 VolumePluginMgr VolumePlugin
/util
/operationexecutor
/operation_generator.go //定义了OperationGenerator
/local
/local.go // 定义了localVolumeMounter
/nfs
/cephfs

kubelet volume 相关代码主要分为两个部分
- 定义了VolumePlugin 插件体系,每个volume 方案相机实现Mounter/Unmounter/Attacher/Detacher 等逻辑。对外提供 operationexecutor 作为统一的volume 操作入口。
- volumePluginManager,根据pod spec 定义的desire state 与 actual state 比对 pod 与volume 的绑定情况,调用operationexecutor 该挂载挂载,该卸载卸载
// Run starts the kubelet reacting to config updates
func (kl *Kubelet) Run(updates <-chan kubetypes.PodUpdate) {
...
// Start volume manager
go kl.volumeManager.Run(kl.sourcesReady, wait.NeverStop)
...
}
func (vm *volumeManager) Run(sourcesReady config.SourcesReady, stopCh <-chan struct{}) {
go vm.desiredStateOfWorldPopulator.Run(sourcesReady, stopCh)
go vm.reconciler.Run(stopCh)
// start informer for CSIDriver
vm.volumePluginMgr.Run(stopCh)
<-stopCh
klog.Infof("Shutting down Kubelet Volume Manager")
}
desiredStateOfWorldPopulator.Run ==> 每隔一段时间执行 populatorLoop ,从PodManager中获取pod spec数据,更新DesiredStateOfWorld
func (dswp *desiredStateOfWorldPopulator) populatorLoop() {
dswp.findAndAddNewPods()
...
dswp.findAndRemoveDeletedPods()
}
func (dswp *desiredStateOfWorldPopulator) findAndAddNewPods() {
// Map unique pod name to outer volume name to MountedVolume.
mountedVolumesForPod := make(map[volumetypes.UniquePodName]map[string]cache.MountedVolume)
...
processedVolumesForFSResize := sets.NewString()
for _, pod := range dswp.podManager.GetPods() {
if dswp.isPodTerminated(pod) {continue}
dswp.processPodVolumes(pod, mountedVolumesForPod, processedVolumesForFSResize)
}
}
// processPodVolumes processes the volumes in the given pod and adds them to the
// desired state of the world.
func (dswp *desiredStateOfWorldPopulator) processPodVolumes(pod *v1.Pod,mountedVolumesForPod ..., ...) {
uniquePodName := util.GetUniquePodName(pod)
mounts, devices := util.GetPodVolumeNames(pod) // 即抓取 container.VolumeMounts 配置
// Process volume spec for each volume defined in pod
for _, podVolume := range pod.Spec.Volumes {
pvc, volumeSpec, volumeGidValue, err :=
dswp.createVolumeSpec(podVolume, pod.Name, pod.Namespace, mounts, devices)
// Add volume to desired state of world
_, err = dswp.desiredStateOfWorld.AddPodToVolume(
uniquePodName, pod, volumeSpec, podVolume.Name, volumeGidValue)
}
}
预期状态和实际状态的协调者,负责调整实际状态至预期状态。reconciler.Run ==> reconciliationLoopFunc ==> 每隔一段时间执行 reconcile,根据desire state 对比actual state,该卸载卸载,该挂载挂载。
func (rc *reconciler) reconcile() {
rc.unmountVolumes() // 对于实际已经挂载的与预期不一样的需要unmount
rc.mountAttachVolumes() // 从desiredStateOfWorld中获取需要mount的volomes
rc.unmountDetachDevices()
}
func (rc *reconciler) mountAttachVolumes() {
// Ensure volumes that should be attached/mounted are attached/mounted.
for _, volumeToMount := range rc.desiredStateOfWorld.GetVolumesToMount() {
volMounted, devicePath, err := rc.actualStateOfWorld.PodExistsInVolume(volumeToMount.PodName, volumeToMount.VolumeName)
volumeToMount.DevicePath = devicePath
if cache.IsVolumeNotAttachedError(err) {
if rc.controllerAttachDetachEnabled || !volumeToMount.PluginIsAttachable {
// Volume is not attached (or doesn't implement attacher), kubelet attach is disabled, wait for controller to finish attaching volume.
} else {
// Volume is not attached to node, kubelet attach is enabled, volume implements an attacher, so attach it
volumeToAttach := operationexecutor.VolumeToAttach{
VolumeName: volumeToMount.VolumeName,
VolumeSpec: volumeToMount.VolumeSpec,
NodeName: rc.nodeName,
}
err := rc.operationExecutor.AttachVolume(volumeToAttach, rc.actualStateOfWorld)
}
} else if !volMounted || cache.IsRemountRequiredError(err) {
// Volume is not mounted, or is already mounted, but requires remounting
err := rc.operationExecutor.MountVolume(
rc.waitForAttachTimeout,
volumeToMount.VolumeToMount,
rc.actualStateOfWorld,
isRemount)
}
}
}
挂载操作主要由 OperationGenerator 负责,MountVolume 时,先根据volumeSpec找到匹配的volumePlugin,每一个volumePlugin 都有一个对应的Mounter/Unmounter。 如果volumePlugin 是AttachableVolumePlugin类型,还有对应的Attacher/Detacher

func (og *operationGenerator) GenerateMountVolumeFunc(
waitForAttachTimeout,volumeToMount,ActualStateOfWorldMounterUpdater,isRemount bool) volumetypes.GeneratedOperations {
volumePluginName := unknownVolumePlugin
// FindPluginBySpec函数遍历所有的plugin判断volumeSpec符合哪种plugin
volumePlugin, err :=
og.volumePluginMgr.FindPluginBySpec(volumeToMount.VolumeSpec)
mountVolumeFunc := func() (error, error) {
// Get mounter plugin
volumePlugin, err := og.volumePluginMgr.FindPluginBySpec(volumeToMount.VolumeSpec)
affinityErr := checkNodeAffinity(og, volumeToMount)
volumeMounter, newMounterErr := volumePlugin.NewMounter(volumeToMount.VolumeSpec,volumeToMount.Pod,volume.VolumeOptions{})
mountCheckError := checkMountOptionSupport(og, volumeToMount, volumePlugin)
// Get attacher, if possible
attachableVolumePlugin, _ :=
og.volumePluginMgr.FindAttachablePluginBySpec(volumeToMount.VolumeSpec)
volumeAttacher, _ = attachableVolumePlugin.NewAttacher()
// get deviceMounter, if possible
deviceMountableVolumePlugin, _ := og.volumePluginMgr.FindDeviceMountablePluginBySpec(volumeToMount.VolumeSpec)
volumeDeviceMounter, _ = deviceMountableVolumePlugin.NewDeviceMounter()
devicePath := volumeToMount.DevicePath
// Wait for attachable volumes to finish attaching
devicePath, err = volumeAttacher.WaitForAttach(
volumeToMount.VolumeSpec, devicePath, volumeToMount.Pod, waitForAttachTimeout)
if volumeDeviceMounter != nil {
deviceMountPath, err :=
volumeDeviceMounter.GetDeviceMountPath(volumeToMount.VolumeSpec)
// Mount device to global mount path
err = volumeDeviceMounter.MountDevice(volumeToMount.VolumeSpec,devicePath,deviceMountPath)
// Update actual state of world to reflect volume is globally mounted
markDeviceMountedErr := actualStateOfWorld.MarkDeviceAsMounted(
volumeToMount.VolumeName, devicePath, deviceMountPath)
}
// Execute mount
mountErr := volumeMounter.SetUp(volume.MounterArgs{
FsGroup: fsGroup,
DesiredSize: volumeToMount.DesiredSizeLimit,
FSGroupChangePolicy: fsGroupChangePolicy,
})
// Update actual state of world
markVolMountedErr := actualStateOfWorld.MarkVolumeAsMounted(markOpts)
return nil, nil
}
return volumetypes.GeneratedOperations{
OperationName: "volume_mount",
OperationFunc: mountVolumeFunc,
EventRecorderFunc: eventRecorderFunc,
CompleteFunc: util.OperationCompleteHook(util.GetFullQualifiedPluginNameForVolume(volumePluginName, volumeToMount.VolumeSpec), "volume_mount"),
}
}
以 localVolumeMounter 的SetUp 为例,其实就是构造mount 命令并执行mount 命令的过程
func (m *localVolumeMounter) SetUp(mounterArgs volume.MounterArgs) error {
return m.SetUpAt(m.GetPath(), mounterArgs)
}
// SetUpAt bind mounts the directory to the volume path and sets up volume ownership
func (m *localVolumeMounter) SetUpAt(dir string, mounterArgs volume.MounterArgs) error {
notMnt, err := mount.IsNotMountPoint(m.mounter, dir)
if err != nil && !os.IsNotExist(err) {...}
if !notMnt {return nil}
refs, err := m.mounter.GetMountRefs(m.globalPath)
if runtime.GOOS != "windows" {...}
// Perform a bind mount to the full path to allow duplicate mounts of the same volume.
options := []string{"bind"}
if m.readOnly {options = append(options, "ro")}
mountOptions := util.JoinMountOptions(options, m.mountOptions)
globalPath := util.MakeAbsolutePath(runtime.GOOS, m.globalPath)
err = m.mounter.Mount(globalPath, dir, "", mountOptions)
return nil
}
// k8s.io/utils/mount/mount_linux.go
func (mounter *Mounter) Mount(source string, target string, fstype string, options []string) error {
return mounter.MountSensitive(source, target, fstype, options, nil)
}
func (mounter *Mounter) MountSensitive(source,target,fstype string, options,sensitiveOptions []string) error {
// Path to mounter binary if containerized mounter is needed. Otherwise, it is set to empty.
// All Linux distros are expected to be shipped with a mount utility that a support bind mounts.
bind, bindOpts, bindRemountOpts, bindRemountOptsSensitive := MakeBindOptsSensitive(options, sensitiveOptions)
if bind {
err := mounter.doMount(mounterPath, defaultMountCommand, source, target, fstype, bindOpts, bindRemountOptsSensitive)
return mounter.doMount(mounterPath, defaultMountCommand, source, target, fstype, bindRemountOpts, bindRemountOptsSensitive)
}
...
return mounter.doMount(mounterPath, defaultMountCommand, source, target, fstype, options, sensitiveOptions)
}
func (mounter *Mounter) doMount(mounterPath, mountCmd, source, target, fstype string, options, sensitiveOptions []string) error {
mountArgs, mountArgsLogStr := MakeMountArgsSensitive(source, target, fstype, options, sensitiveOptions)
command := exec.Command(mountCmd, mountArgs...)
output, err := command.CombinedOutput()
return err
}
整体来说,kubelet volume reconcile 过程和k8s controller 类似,只是“实际状态”的数据来源有些不同。
| 理想状态 | 实际状态 | |
|---|---|---|
| k8s controller | resource yaml 文件 | kubelet 上报的status 数据 |
| kubelet volume manager | resource yaml 文件 | 本地实际的 数据目录等 |
留下评论