以应用为中心
简介
解读容器 2019:把“以应用为中心”进行到底云原生的本质是一系列最佳实践的结合;更详细的说,云原生为实践者指定了一条低心智负担的、能够以可扩展、可复制的方式最大化地利用云的能力、发挥云的价值的最佳路径。这种思想,以一言以蔽之,就是“以应用为中心”。正是因为以应用为中心,云原生技术体系才会无限强调让基础设施能更好的配合应用、以更高效方式为应用“输送”基础设施能力,而不是反其道而行之。而相应的, Kubernetes 、Docker、Operator 等在云原生生态中起到了关键作用的开源项目,就是让这种思想落地的技术手段。
脉络:直接操作物理机细节太多,k8s 给了我们机会 将一切操作api化 ==> k8s yaml太多,且不同workload不统一,不同云厂商不一定统一 ==> kustomize/helm(helm values.yaml太随意了) ==> 弄一个paas平台封装一下k8s ==> 可扩展性(封装的标准化、可复用) ==> OAM
k8s 的问题
K8s 的 API 没有“应用”的概念
上 Kubernetes 有什么业务价值?Kubernetes 作为一个面向基础设施工程师的系统级项目,主要负责提供松耦合的基础设施语义。 K8s 不是一个 PaaS 或者应用管理的平台。实际上它是一个标准化的能力接入层。实际上通过 Kubernetes 对用户暴露出来的是一组声明式 API,这些声明式 API 无论是 Pod 还是 Service 都是对底层基础设施的一个抽象。比如 Pod 是对一组容器的抽象,而 Deployment 是对一组 pod 的抽象。而 Service 作为 Pod 的访问入口,实际上是对集群基础设施:网络、网关、iptables 的一个抽象。Node 是对宿主机的抽象。Kubernetes 还提供了我们叫做 CRD(也就是 Custom Resource)的自定义对象。让你自己能够自定义底层基础设施的一个抽象。Kubernetes 他的专注点是“如何标准化的接入来自于底层,无论是容器、虚机、负载均衡各种各样的一个能力,然后通过声明式 API 的方式去暴露给用户”。
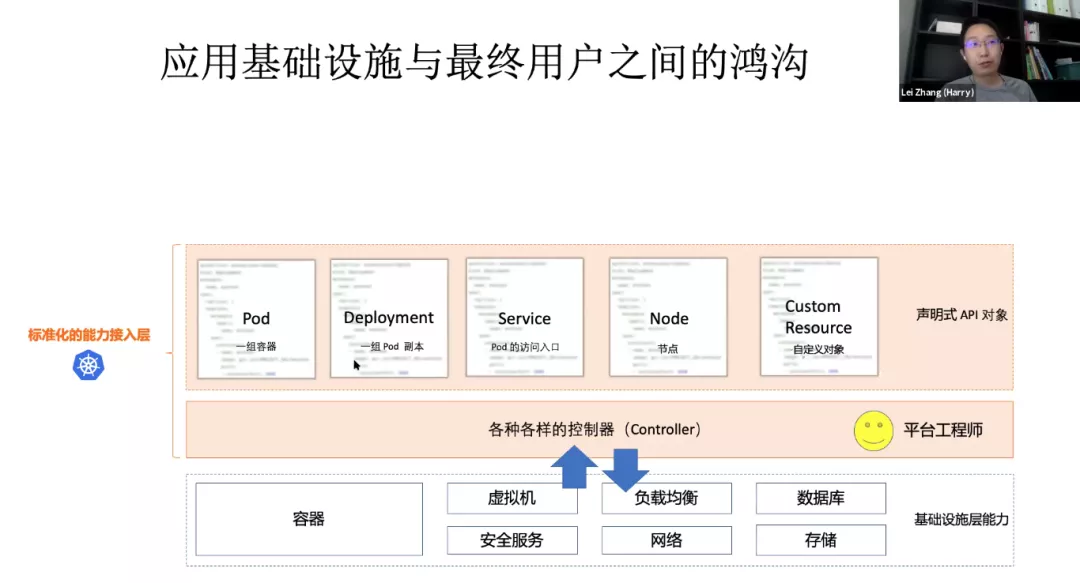
给 K8s API “做减法”:阿里巴巴云原生应用管理的挑战和实践Kubernetes API 的设计把研发、运维还有基础设施关心的事情全都糅杂在一起了。这导致研发觉得 K8s 太复杂,运维觉得 K8s 的能力非常凌乱、零散,不好管理。很多 PaaS 平台只允许开发填 Deployment 的极个别字段。为什么允许填的字段这么少?是平台能力不够强吗?其实不是的,本质原因在于业务开发根本不想理解这众多的字段。归根到底,Kubernetes 是一个 Platform for Platform 项目,它的设计是给基础设施工程师用来构建其他平台用的(比如 PaaS 或者 Serverless),而不是直面研发和运维同学的。从这个角度来看,Kubernetes 的 API,其实可以类比于 Linux Kernel 的 System Call,这跟研发和运维真正要用的东西(Userspace 工具)完全不是一个层次上的。
K8s 实在是太灵活了,插件太多了,各种人员开发的 Controller 和 Operator 也非常多,上k8s带来的成本已经超过带来的业务效率的提升了。
基于k8s 做一个应用管理平台
Kubernetes 实际上是面向平台开发者,而不是面向研发和应用运维的这么一个项目。要基于 Kubernetes 去构建应用管理平台。去更好的服务研发和运维,这也是一个非常自然的选择。不是说必须使用 K8s 去服务你的用户。如果你的用户都是 K8s 专家,这是没问题的(社区正在迫使他们成为 Kubernetes 专家才能使事情正常运行)。如果不是的话,你去做这样一个应用平台是非常自然的事情。
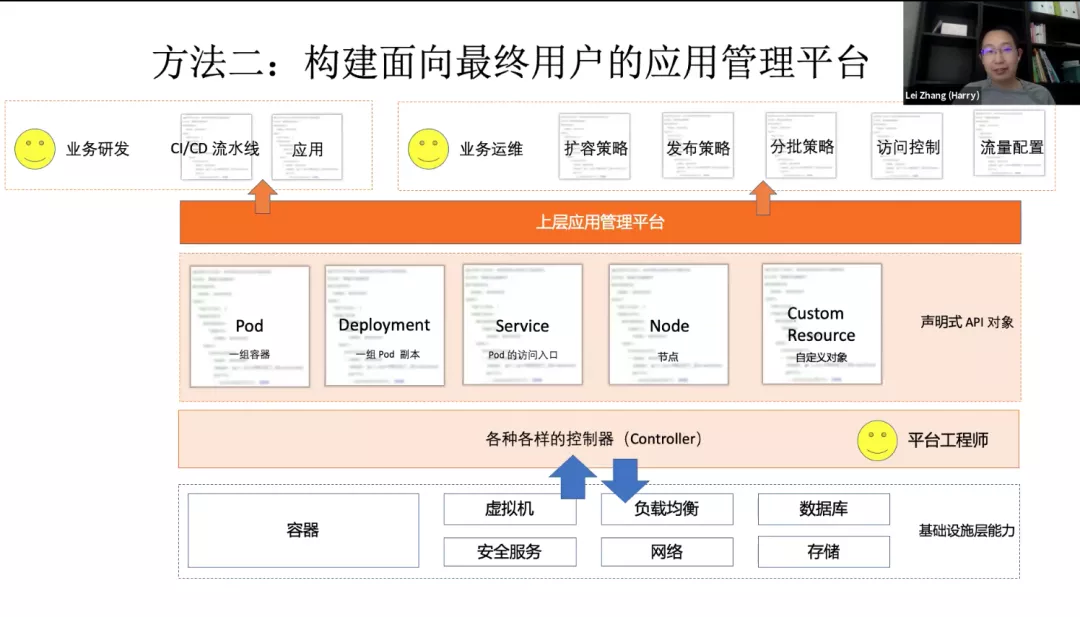
几乎所有的 PaaS 都会存在这么一个问题:它往上暴露的是一个用户友好的API,但是不可扩展的,是个有限集。有自己的一套 API,自己的理念,自己的模型,自己的使用方式。跟 Kubernetes 都是不太一样的,会把 K8s 的能力完全遮住。
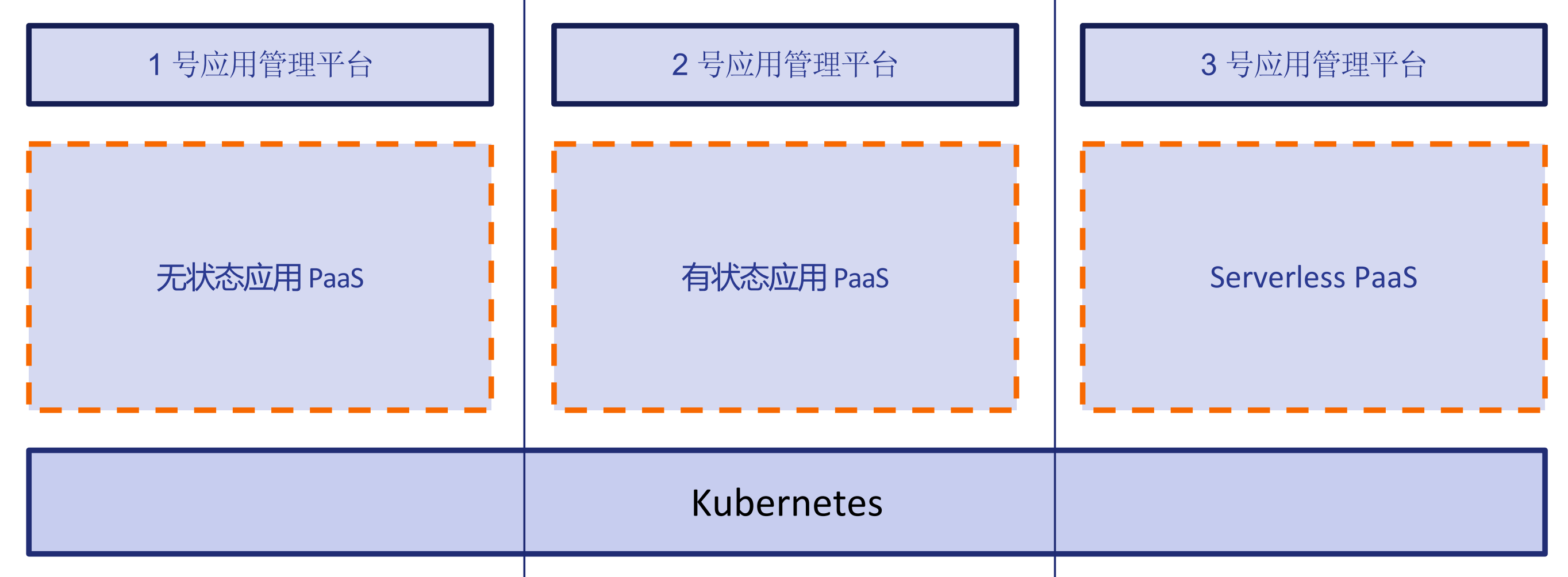
我们能不能抛弃传统 PaaS 的一个做法,基于 K8s 打造高可扩展的应用管理平台。我们想办法能把 K8s 能力无缝的透给用户,同时又能提供传统 PaaS 比较友好的面向研发运维的使用体验呢?我们不是说要在 Kubernetes 上盖一个 PaaS,因为 K8s 本身可以扩展,可以写一组 CRD,把我们要的 API 给装上去。PS:从使用者来看,对平台的使用可以看做写 core.oam.dev/v1beta1 的Application ,仅需指定type+properties 即可使用平台。平台能力提供者提供type 即可将能力发布出去。
Open Application Model (OAM)
由微软和阿里云支持的开放应用程序模型(OAM),其目标是为云原生应用程序应该是什么样子提供一个理论模型。它最初被设计为不与 Kubernetes 绑定,并且倾向于为操作应用程序提供统一的接口。OAM 提出了组件和特性的概念,以对应用程序架构进行抽象。PS:就好像Serverless 是一种理念,FaaS 是实现这个理念的一种落地实践,只是在k8s和oam这里,是先有的k8s,再提取的理念oam。
为什么
给 K8s API “做减法”:阿里巴巴云原生应用管理的挑战和实践
Kubernetes 的核心 API 资源比如 Service、Deployment 等,实际上只是应用中的不同组成部分,并不能代表一个应用的全部。也许我们可以通过像 Helm charts 这样的方式来尝试表达一个可部署的应用,可一旦部署起来,实际运行的应用中却依旧缺乏以应用为中心的约束模型。这些问题都反映出,Kubernetes 以及云原生技术栈需要一种以应用为中心的 API 资源来提供一个专注于应用管理的、标准的、高度一致的模型,这个 API 资源可以代表完整运行的应用本身,而不仅仅是应用模板或者一个应用的几个组成部分,这就是今天阿里云与微软联合宣布推出开放应用模型 Open Application Model (OAM)的原因。
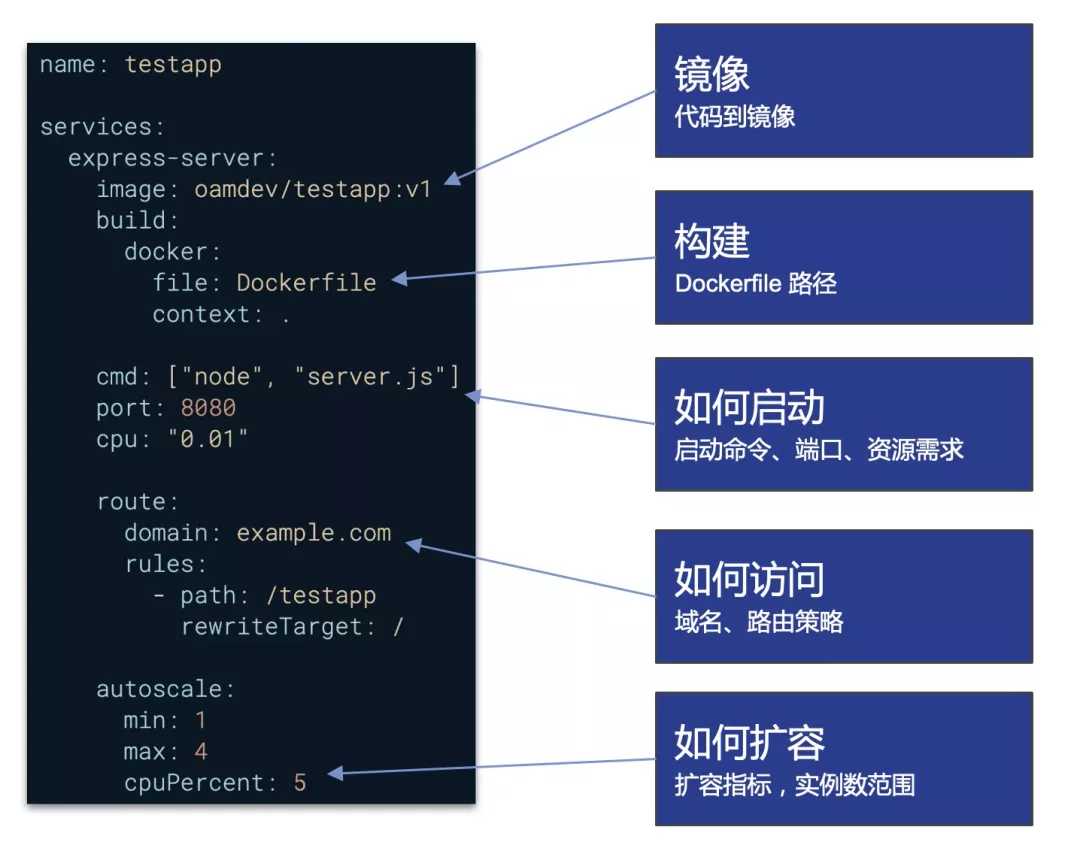
Why Open Application Model? PS: 所有对应用的操作 用一个配置文件描述,命令行 ==> api ==> IaC
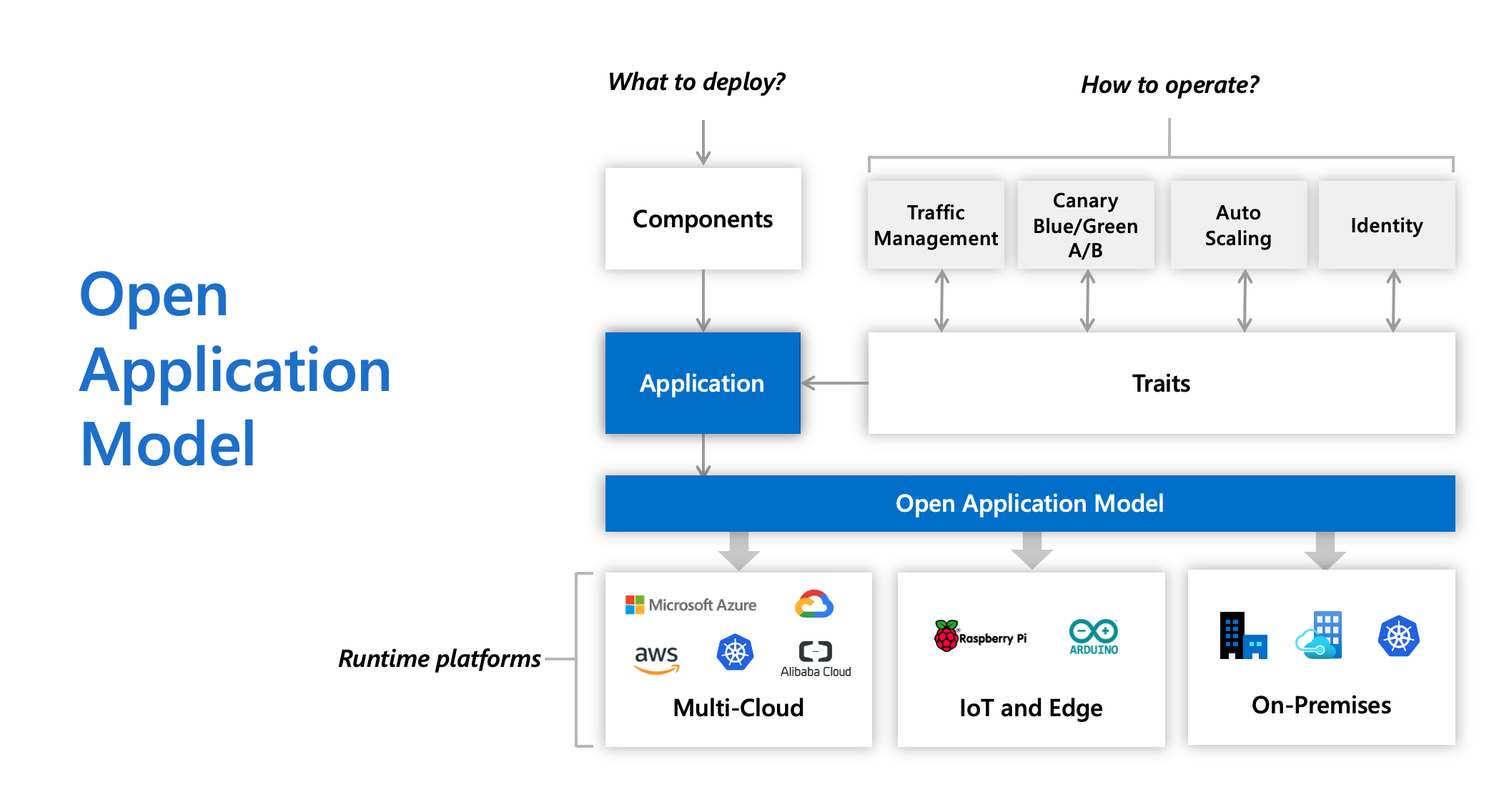
In today’s hybrid deployment environments, delivering applications without application context is hard:
- Developers spend time on infrastructure details instead of apps - clusters, ingresses, labels, DNS, etc, and learning how the infrastructure is implemented in different environments
- Inextensible - upper layer platform may be introduced, but it’s almost certain that the needs of your app will outgrow the capabilities of that platform soon.
- Vendor lock-in - app deployment is tightly coupled with service provider and infrastructure, which heavily impact on how you configure, develop and operate the app across hybrid environments.
In Open Application Model, we propose an app-centric approach instead:
- Application first - define the app deployment with a self-contained model, where operational behaviors as part of app definition, free of infrastructure, simply deploy.
- Clarity and extensibility - an open standard to modularize app delivery into reusable pieces, assemble them into a deployment plan per your own needs, fully self-service.
- Vendor agnostic - a consistent yet higher level abstraction to model app delivery across on-prem clusters, cloud providers or even edge devices. Zero lock-in.
应用定义实际上是应用交付/分发不可或缺的部分,所以我们可以思考下是否可以定义足够开放的、可复用的应用模型呢?
- 一个应用定义需要容易上手,但又不失灵活性,更不能是一个黑盒。应用定义同样需要跟开源生态紧密结合,没有生态的应用定义注定是没有未来的,自然也很难持续的迭代和演进。
- 一个合理的应用模型应该具有区分使用者角色的分层结构,同时将运维能力模块化的封装。让不同的角色使用不同的 API
oam 应用模型
与 PaaS 应用模型相比,OAM 有很多独有的特点,其中最重要一点是:平台无关性。虽然我们目前发布的 OAM 实现是基于 Kubernetes 的,但 Open Application Model 与 Kubernetes 并没有强耦合。PS: 如果marathon 等还在的话,OAM 确实是一个很不错的抽象。
OAM 支持 Kubernetes 内置的工作负载,那什么时候该使用 Deployment、什么时候该使用ContainerizedWorkload 来作为 OAM 的工作负载呢?如果你的用户希望看到一个极简的、没有一些”乱七八糟“字段的 Deployment 的话;或者,你希望对你的用户屏蔽掉 Deployment 里面与用户无关的字段(比如:不想允许研发自行设置 PodSecurityPolicy),那你就应该给用户暴露 ContainerizedWorkload。这时候,这个工作负载需要的运维操作和策略,则是由另一个 OAM 对象 Traits(运维特征) 来定义的,比如 ManualScalerTrait。
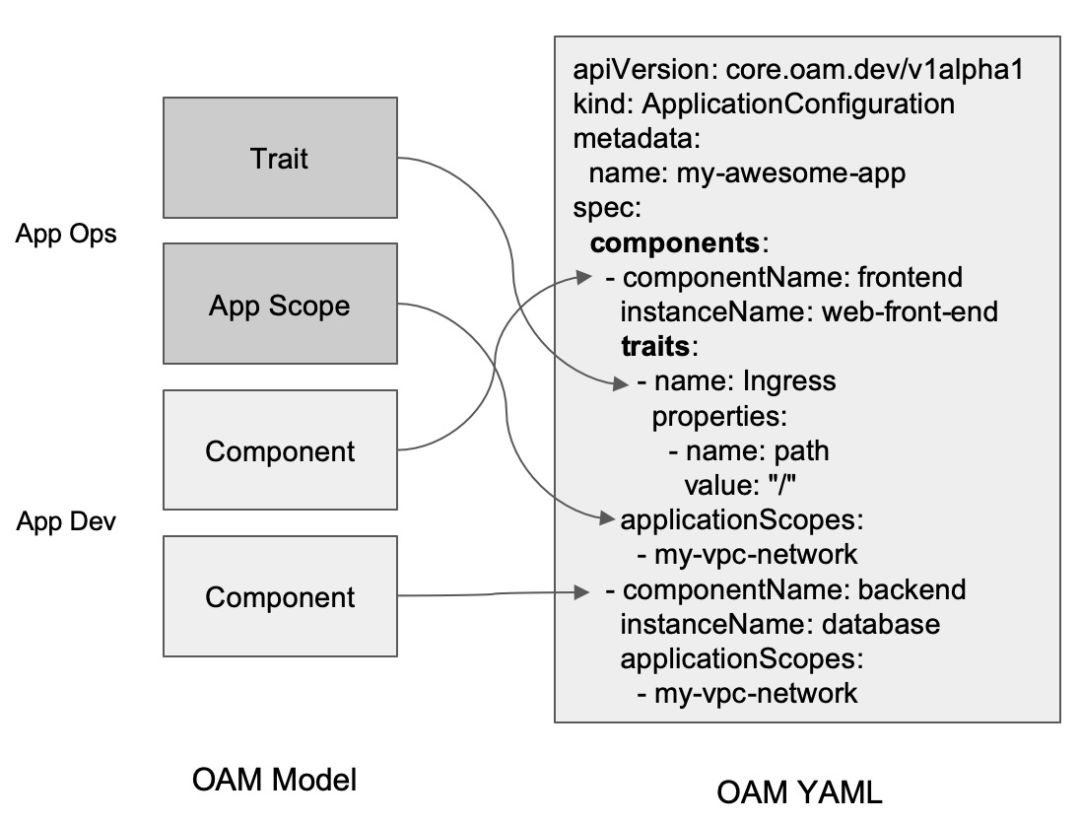
OAM 深入解读:OAM 为云原生应用带来哪些价值?OAM 也将原先 K8s All-in-one 的复杂 API 做了一定层次的解耦,分为应用研发(管理 Component)、应用运维(将 Component 组合并绑定 Trait 变成 AppConfig)、以及基础设施提供方(提供 OAM 的解释能力映射到实际的基础设施)三大角色。当模块化的 Workload 和 Trait 越来越多,就会形成这些组件的市场,用户可以在 CRD Registry 这样的注册中心,快速找到适合自己的应用的架构(Workload,可以是简单的无状态应用 “Server”,表示应用可复制、可访问、并作为守护进程长久运行;也可以是一个数据库类型的应用 “RDS”),以及自己需要使用的运维能力(Trait)。构建应用将越来越简单。
揭秘 OAM Kubernetes 实现核心原理OAM 带来的
- 把“关注点分离”作为这个定义模型的核心思想
- 为 Kubernetes 项目带来了应用定义。站在 Kubernetes 项目的角度来讲,OAM 是一个 Kubernetes 原生的标准的“应用定义”项目,同时也是一个专注于封装、组织和管理 Kubernetes 中各种“运维能力”、以及连接“运维能力”与“应用”的平台层框架。OAM 基于 Kubernetes API 资源模型(Kubernetes Resource Model)来标准化应用定义的规范,它强调一个现代应用是多个组件的集合,而非一个简单的工作负载或者 K8s Operator。所以在 OAM 的语境中,一个 PHP 容器和它所依赖的数据库,以及它所需要使用的各种云服务,都是一个“电商网站”应用的组成部分。更进一步的,OAM 把这个应用所需的“运维策略”也认为是一个应用的一部分,比如这个 PHP 容器所需的 HPA(水平自动扩展策略)
- 基于 OAM 暴露出来的新的 API 之后,上层的UI(也可以认为是应用平台)构建起来会非常简单。 OAM 天然分为工作负载和运维特征两类, UI 这层可以直接去对接了,会减少很多前端的工作。因为 GitOps 也好,持续集成也好,是不想管你的 pod 或者是 Deployment 怎么生成的,这个应用怎么运维,怎么 run 起来,还是要靠 Kubernetes 插件或者内置能力去做的。这些能力都被定义到一个自包含的文件,适用于所有集群。这就会使得你的 GitOps 和持续集成变得简单。这样的系统真正做到了标准,自运维,一个以应用为中心和用户为中心的 Kubernetes 平台。
如何构建以应用为中心的“Kubernetes”?Application Configuration 就像是一个信封,将 Traits 绑定给 Component,这个是显式绑定的。OAM 里面不建议去使用 Label 这样的松耦合的方式去关联你的工作负载。建议通过这种结构化的方式,通过 CRD 去显式的绑定你的特征和工作负载。这样的好处是我的绑定关系是可管理的。可以通过 kubectl get 看到这个绑定关系。作为管理员或者用户,就非常容易的看到某一个组件绑定的所有运维能力有哪些,这是可以直接展示出来的,如果通过 label 是很难做到的。同时 Label 本身有个问题是,本身不是版本化的,不是结构体,很难去升级,很难去扩展。通过这么结构化定义,后面的升级扩展将会变得非常简单。
未来
在下一代“以应用为中心”的基础设施当中,业务研发通过声明式 API 定义的不再是具体的运维配置(比如:副本数是 10 个),而是“我的应用期望的最大延时是 X ms”。接下来的事情,就全部会交给 Kubernetes 这样的应用基础设施来保证实际状态与期望状态的一致,这其中,副本数的设置只是后续所有自动化操作中的一个环节。只有让 Kubernetes 允许研发通过他自己的视角来定义应用,而不是定义 Kubernetes API 对象,才能从根本上的解决 Kubernetes 的使用者“错位”带来的各种问题。
其它
许式伟:桌面的领域特征是强交互,以事件为输入,GDI 为输出。所以,桌面技术的迭代,是交互的迭代,是人机交互的革命。而服务端程序有很强烈的服务特征。它的领域特征是大规模的用户请求,以及 24 小时不间断的服务。这些都不是业务功能上的需要,是客户服务的需要。所以服务端操作系统的演进,并不是因为服务端业务开发的需要,是服务治理的需要。所以,服务端技术的迭代,虽然一开始沿用了桌面操作系统的整套体系框架,但它正逐步和桌面操作系统分道而行,转向数据中心操作系统(DCOS)之路。
- 第一个里程碑的事件是 Docker 的诞生。容器技术诞生已经多年,但是把容器技术的使用界面标准化,始于 Docker。它完成了服务端软件的标准化交付,与底层的服务端本地操作系统实现了解耦。在 Docker 之前,不同服务端本地操作系统的软件交付有这样几个问题。
- 标准不同。MacOS 有 brew,Linux 不同分支差别很大,有的是基于 rpm,有的是 apt,五花八门。
- 不符合服务软件的交付规格需要。这些软件管理工具只实现了一个软件仓库,它虽然标准化了软件安装的过程,但并没有定义服务的运行规范。
- 环境依赖。这些软件管理工具对软件的描述并不是自包含的。它们并没有非常干净的软件运行环境的描述,行为有较大的不确定性,甚至有大量的软件包在实际安装时会因为各种各样的系统环境问题而失败。
- Google 牵头推 Kubernetes,结束了 DCOS 之争。
为什么让一个软件能24小时运行,要说清楚哪些事儿?
云计算的诞生,标志着服务端分工的正式形成。未来,所谓服务端工程师很可能不再存在。要么,你往基础设施走,变成一个云计算基础设施的研发工程师。要么你深入行业,变成某个领域的研发工程师,但是这时,就别抱着自己是服务端工程师的态度不放,好好琢磨清楚业务需求。
我们对 “变更” 需求进行正交分解,分为 “主动性变更” 与 “被动变更”。“主动性变更” 是指有计划的变更行为,例如软硬件升级、数据库表结构的调整等等。“被动变更” 是指由于线上用户请求、业务负载、软硬件环境的故障等非预期的行为导致的变更需求,比如扩容、由于机房下线而导致的 DNS 配置项变更等等。为了应对 “被动变更”,服务治理系统对服务的软硬件环境的依赖进行了系统性的梳理。最终,硬件被池化。业务系统的逻辑描述与硬件环境彻底解耦。然后,我们对 “主动性变更” 进行进一步的正交分解,分为 “软件变更” 与 “软件数据的变更”。“软件变更” 通过版本化来表达。每个 “软件” 版本必须是自包含的,它自身有完整的环境,不会出现跑在 A 机器和 B 机器不一致的情况。
版本化是非常重要的概念。它意味着每个独立版本的数据都是确定性的、只读的、行为上可复现的。大家最熟悉的版本化的管理思想,就是源代码管理系统,比如 Git。在服务治理系统中,“软件变更” 和我们熟悉的源代码管理系统如出一辙。PS:一切基础设施即配置
Borg、Omega、K8s:Google 十年三代容器管理系统的设计与思考
- 容器化使数据中心的观念从原来的面向机器(machine oriented) 转向了面向应用(application oriented),容器封装了应用环境(application environment), 向应用开发者和部署基础设施屏蔽了大量的操作系统和机器细节,每个设计良好的容器和容器镜像都对应的是单个应用,因此 管理容器其实就是在管理应用,而不再是管理机器。Management API 的这种从面向机器到面向应用的转变,显著提升了应用的部署效率和问题排查能力。
- 应用开发者和应用运维团队无需再关心机器和操作系统等底层细节;
- 基础设施团队引入新硬件和升级操作系统更加灵活, 可以最大限度减少对线上应用和应用开发者的影响;
- 将收集到的 telemetry 数据(例如 CPU、memory usage 等 metrics以及Log)关联到应用而非机器, 显著提升了应用监控和可观测性,尤其是在垂直扩容、 机器故障或主动运维等需要迁移应用的场景。
- 内核 cgroup、chroot、namespace 等基础设施的最初目的是保护应用免受 noisy、nosey、messy neighbors 的干扰。而这些技术与容器镜像相结合,创建了一个新的抽象, 将应用与它所运行的(异构)操作系统隔离开来。这层抽象能成功的关键,是有一个hermetic(封闭的,不受外界影响的)容器镜像,这个镜像能封装一个应用的几乎所有依赖(文件、函数库等等);唯一剩下的外部依赖就是 Linux 系统调用接口了,极大提升了镜像的可移植性, 因此容器成为了 Google 基础设施唯一支持的可运行实体。这带来的一个后果就是, Google 内部只有很少几个版本的操作系统,也只需要很少的人来维护这些版本, 以及维护和升级服务器。
- 容器作为基本管理单元
- 通用 API 和自愈能力:容器能提供一些通用的 API 注册机制,使管理系统和应用之间无需知道彼此的实现细节就能交换有用信息。当检测到一个不健康的应用时, 就会自动终止或重启对应的容器。这种自愈能力(self-healing)是构建可靠分布式系统的最重要基石之一。
- 用 annotation 描述应用结构信息:K8s 提供了 key-value annotation, 存储在每个 object metadata 中,可以用来传递应用结构(application structure)信息。这些 annotations 可以由容器自己设置,也可以由管理系统中的其他组件设置(例如发布系统在更新完容器之后更新版本号)。
- 应用维度 metrics 聚合:监控和 auto-scaler 的基础。 容器还能用其他方式提供面向应用的监控,基于这些监控数据就能开发一些通用工具,例如 auto-scaler 和 cAdvisor3, 它们记录和使用这些 metrics,但无需理解每个应用的细节。
- 编排是开始,不是结束。使得我们能在共享的机器上运行不同类型的 workload 来提升资源利用率。
- 避免野蛮生长:K8s 统一 API(Object Metadata、Spec、Status)这种统一 API 提供了几方面好处:
- 学习更加简单,因为所有 object 都遵循同一套规范和模板;
- 编写适用于所有 object 的通用工具也更简单;
- 用户体验更加一致。
- Reconcile 机制:还通过让不同 k8s 组件使用同一套设计模式来实现一致性。由于所有操作都是基于观察(observation)而非状态机, 因此 reconcile 机制非常健壮:每次一个 controller 挂掉之后再起来时, 能够接着之前的状态继续工作。
留下评论