Kubernetes源码分析——kubelet
简介
go 程序中大量使用channel
- 一个是消灭了观察者模式
- 很多功能组件得以独立。以前对外提供接口,等着上游组件函数调用。现在改成了消息传递,主流程/入口直接go start启动组件,然后在for 循环里 等着channel 来消息就行。channel 作为独立组件的输入,输出则为io操作 或向另一个channel 发出事件。
反应在源码分析上
- 之前,功能分解由接口/类体现,类图有很多接口、实现类(因为要用接口界定组件间的关系)。序列图有较深的 函数调用(从左到右很长)。
- 现在,功能分解由协程体现,一个组件一个协程,大家都是main函数/入口对象的“亲儿子”,各干各的活儿,通过channel 协同
kubelet 源码虽然庞大,但并不复杂,基本适用于上述规律(以并发的事件驱动替代串联的消息驱动),在1.13 版本中,kubelet 大约有13个mannager 保证pod 正常运行。
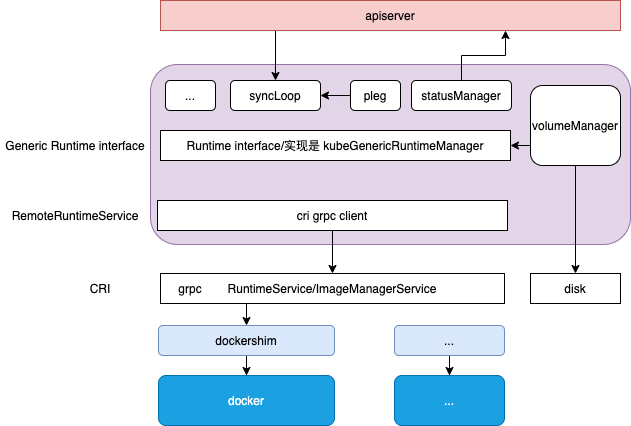
整体结构
Kubelet 作为 Kubernetes 集群中的 node agent,一方面,kubelet 扮演的是集群控制器的角色,它定期从 API Server 获取 Pod 等相关资源的信息,并依照这些信息,控制运行在节点上 Pod 的执行;另外一方面, kubelet 作为节点状况的监视器,它获取节点信息,并以集群客户端的角色,把这些 状况同步到 API Server。
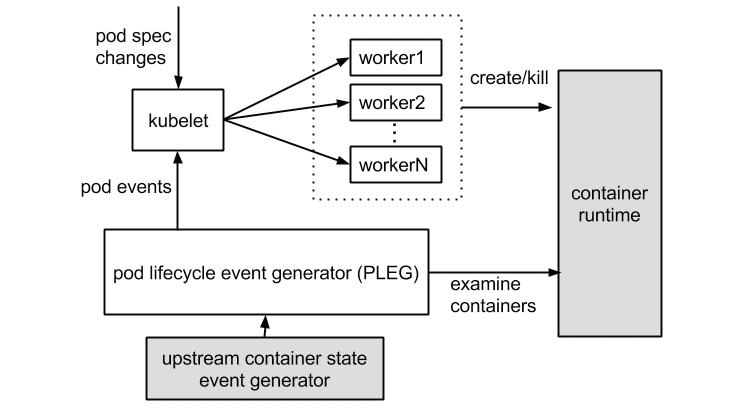
生命周期事件生成器PLEG
对于 Pod来说,Kubelet 会从多个数据来源(api、file以及http) watch Pod spec 中的变化。对于容器来说,Kubelet 会定期轮询容器运行时,以获取所有容器的最新状态。随着 Pod 和容器数量的增加,轮询会产生较大开销,带来的周期性大量并发请求会导致较高的 CPU 使用率峰值,降低节点性能,从而降低节点的可靠性。为了降低 Pod 的管理开销,提升 Kubelet 的性能和可扩展性,引入了 PLEG(Pod Lifecycle Event Generator)。改进了之前的工作方式:
- 减少空闲期间的不必要工作(例如 Pod 的定义和容器的状态没有发生更改)。
- 减少获取容器状态的并发请求数量。
为了进一步降低损耗,社区推出了基于event实现的PLEG,当然也需要CRI运行时支持。
它定期检查节点上 Pod 运行情况,如果发现感兴趣的变化,PLEG 就会把这种变化包 装成 Event 发送给 Kubelet 的主同步机制 syncLoop 去处理。
集群控制器
kubectl 创建 Pod 背后到底发生了什么?从kubectl 命令开始,kubectl ==> apiserver ==> controller ==> scheduler 所有的状态变化仅仅只是针对保存在 etcd 中的资源记录。到Kubelet 才开始来真的。如果换一种思维模式,可以把 Kubelet 当成一种特殊的 Controller,它每隔 20 秒(可以自定义)向 kube-apiserver 通过 NodeName 获取自身 Node 上所要运行的 Pod 清单。一旦获取到了这个清单,它就会通过与自己的内部缓存进行比较来检测新增加的 Pod,如果有差异,就开始同步 Pod 列表。
源码包结构
k8s.io/kubernetes
/cmd/kubelet
/app
/kubelet.go
/pkg/kubelet
/cadvisor
/configmap
/prober
/status
/kubelet.go // 定义了kubelet struct,kubelet 相关功能按作用散落在kubelet_xx.go 中
/kubelet_network.go
/kubelet_pods.go
/...
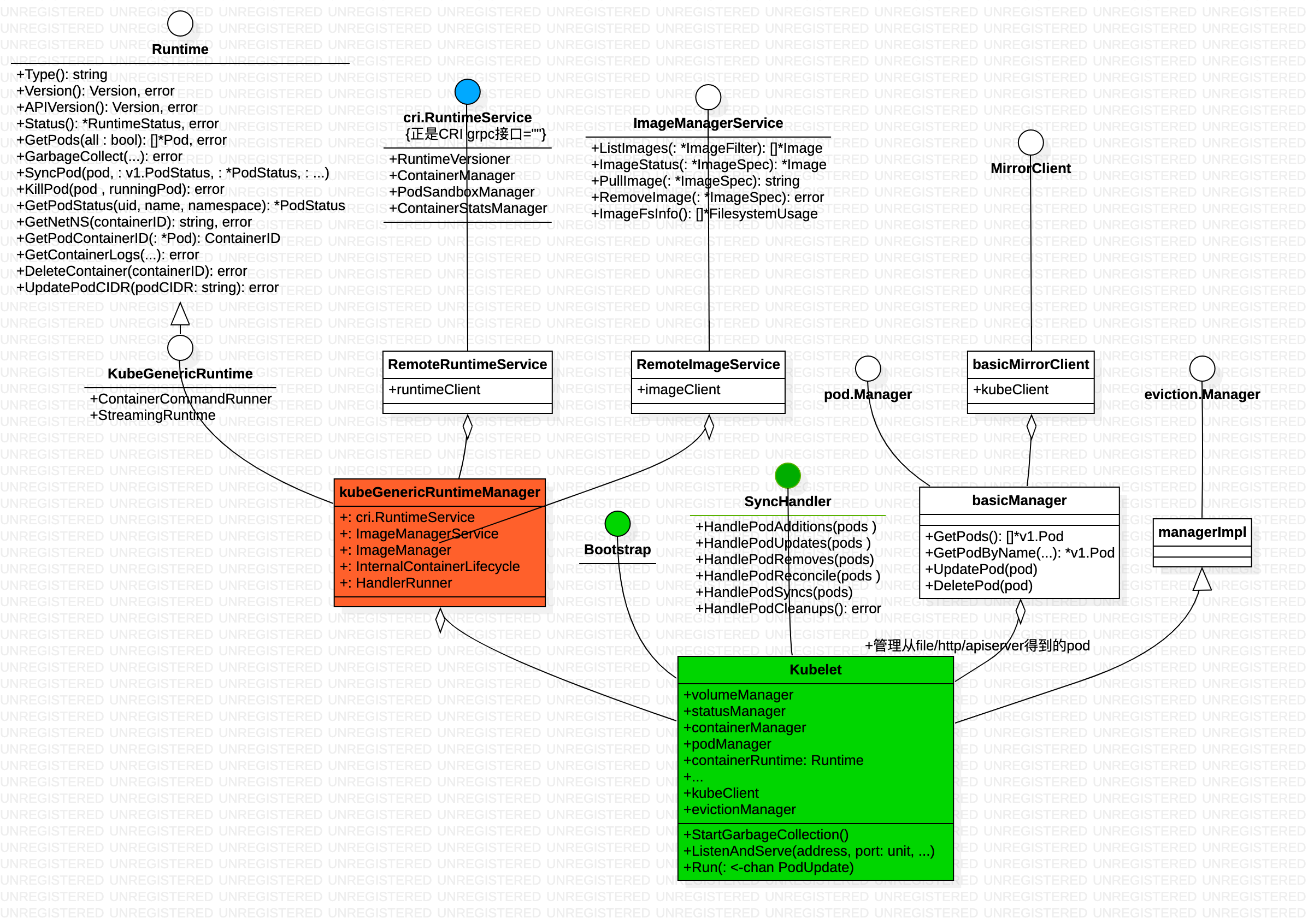
/container // 定义了 Runtime interface,包括了Pod/PodStatus/Container/ContainerStatus/Image 等概念
/kuberuntime // 定义了 kubeGenericRuntimeManager struct,实现了Runtime interface
/kuberuntime_manager.go // kuberuntime_manager 相关功能按作用散落在kuberuntime_xx.go 中
/kuberuntime_sandbox.go
/kuberuntime_container.go
/kuberuntime_image.go
/remote // 定义了 RemoteRuntimeService 封装了cri grpc client
/dockershim // cri grpc server的docker 实现
k8s.io/cri-api
/pkg/apis
/runtime/v1alpha2
/api.pb.go
/service.go // 定义了cri 接口,RuntimeService/ImageManagerService interface,包括了Container/PodSandbox/Image等概念
pkg 下几乎每一个文件夹对应了 kubelet 的一个功能组件,每个功能组件一般对应一个manager 协程,负责具体的功能实现,启动时只需 go manager.start。此外有一个syncLoop 负责kubelet 主功能的实现。
启动流程
比较有意思的是 Bootstap interface 的描述:Bootstrap is a bootstrapping interface for kubelet, targets the initialization protocol. 也就是 cmd/kubelet 和 pkg/kubelet 的边界是 Bootstap interface
// Run starts the kubelet reacting to config updates
func (kl *Kubelet) Run(updates <-chan kubetypes.PodUpdate) {
...
// Start the cloud provider sync manager
go kl.cloudResourceSyncManager.Run(wait.NeverStop)
// Start volume manager
go kl.volumeManager.Run(kl.sourcesReady, wait.NeverStop)
// Start syncing node status immediately, this may set up things the runtime needs to run.
go wait.Until(kl.syncNodeStatus, kl.nodeStatusUpdateFrequency, wait.NeverStop)
go kl.fastStatusUpdateOnce()
// start syncing lease
go kl.nodeLeaseController.Run(wait.NeverStop)
go wait.Until(kl.updateRuntimeUp, 5*time.Second, wait.NeverStop)
// Start loop to sync iptables util rules
go wait.Until(kl.syncNetworkUtil, 1*time.Minute, wait.NeverStop)
// Start a goroutine responsible for killing pods (that are not properly handled by pod workers).
go wait.Until(kl.podKiller, 1*time.Second, wait.NeverStop)
// Start component sync loops.
kl.statusManager.Start()
kl.probeManager.Start()
// Start syncing RuntimeClasses if enabled.
go kl.runtimeClassManager.Run(wait.NeverStop)
// Start the pod lifecycle event generator.
kl.pleg.Start()
kl.syncLoop(updates, kl)
}
syncLoop
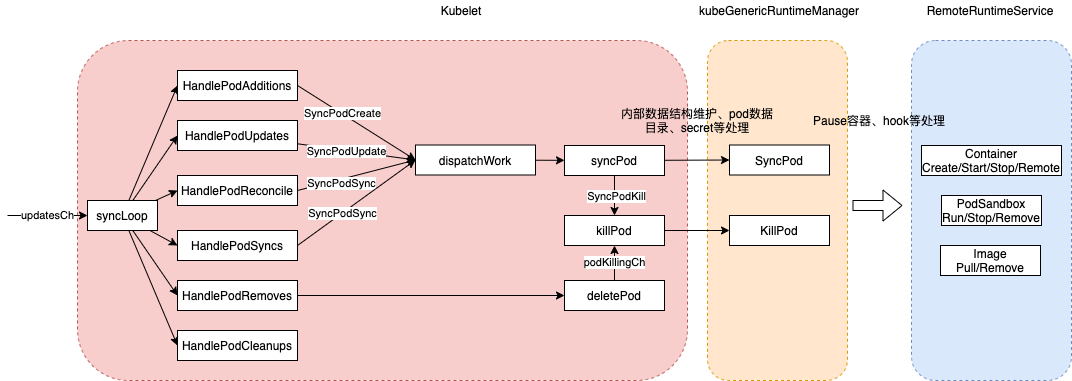
syncLoop is the main loop for processing changes. It watches for changes from three channels (file, apiserver, and http*) and creates a union of them. For any new change seen, will run a sync against desired state and running state. If no changes are seen to the configuration, will synchronize the last known desired state every sync-frequency seconds. Never returns. Kubelet启动后通过syncLoop进入到主循环处理Node上Pod Changes事件,监听来自file,apiserver,http三类的事件并汇聚到kubetypes.PodUpdate Channel(Config Channel)中,由syncLoopIteration不断从kubetypes.PodUpdate Channel中消费。
func (kl *Kubelet) syncLoop(updates <-chan kubetypes.PodUpdate, handler SyncHandler) {
// 准备工作
for{
time.Sleep(duration)
if !kl.syncLoopIteration(...) {
break
}
...
}
}
syncLoopIteration 接收来自多个方向的消息(file, apiserver, and http*),run a sync against desired state and running state
func (kl *Kubelet) syncLoopIteration(configCh <-chan kubetypes.PodUpdate, handler SyncHandler,
syncCh <-chan time.Time, housekeepingCh <-chan time.Time, plegCh <-chan *pleg.PodLifecycleEvent) bool {
select {
case u, open := <-configCh:
switch case...
case e := <-plegCh:
...
case <-syncCh:
...
case update := <-kl.livenessManager.Updates():
...
case <-housekeepingCh:
...
}
return true
}
syncLoopIteration reads from various channels and dispatches pods to the given handler. 以configCh 为例
switch u.Op {
case kubetypes.ADD:
handler.HandlePodAdditions(u.Pods)
case kubetypes.UPDATE:
handler.HandlePodUpdates(u.Pods)
case kubetypes.REMOVE:
handler.HandlePodRemoves(u.Pods)
case kubetypes.RECONCILE:
handler.HandlePodReconcile(u.Pods)
case kubetypes.DELETE:
// DELETE is treated as a UPDATE because of graceful deletion.
handler.HandlePodUpdates(u.Pods)
case kubetypes.RESTORE:
// These are pods restored from the checkpoint. Treat them as new pods.
handler.HandlePodAdditions(u.Pods)
}
最终的立足点还是 syncHandler(还是Kubelet 自己实现的),下面分析下 HandlePodAdditions
sync pod
Kubernetes容器重启原理-Kubelet Hash计算SyncPod保证运行中的 Pod 与我们期望的配置时刻保持一致。通过以下步骤完成
- 根据从 API Server 获得的 Pod Spec 以及当前 Pod 的 Status 计算所需要执行的 Actions
- 在需要情况下 Kill 掉当前 Pod 的 sandbox
- 根据需要(如重启)kill 掉 Pod 内的 containers
- 根据需要创建 Pod 的 sandbox
- 启动下一个 init container
- 启动 Pod 内的 containers
代码中去掉了跟创建 无关的部分,删减了日志、错误校验等
func (kl *Kubelet) HandlePodAdditions(pods []*v1.Pod) {
sort.Sort(sliceutils.PodsByCreationTime(pods))
for _, pod := range pods {
...
// Always add the pod to the pod manager. Kubelet relies on the pod manager as the source of truth for the desired state. If a pod does not exist in the pod manager, it means that it has been deleted in the apiserver and no action (other than cleanup) is required.
kl.podManager.AddPod(pod)
...
mirrorPod, _ := kl.podManager.GetMirrorPodByPod(pod)
kl.dispatchWork(pod, kubetypes.SyncPodCreate, mirrorPod, start)
kl.probeManager.AddPod(pod)
}
}
kubelet.podManager.AddPod 和 kubelet.probeManager.AddPod(pod) 都只是将pod 纳入podManager 和probeManager 的管理结构 ,真正创建pod的是dispatchWork,之后转到 kubelet.syncPod。中间有一个插曲:dispatchWork 交给podWorker.UpdatePod进行Pod的更新处理,每个Pod都会per-pod goroutines进行Pod的管理工作(监听pod updateCh),也就是podWorker.managePodLoop。在managePodLoop中调用Kubelet.syncPod进行Pod的sync处理。
func (kl *Kubelet) syncPod(o syncPodOptions) error {
...
// Generate final API pod status with pod and status manager status
apiPodStatus := kl.generateAPIPodStatus(pod, podStatus)
existingStatus, ok := kl.statusManager.GetPodStatus(pod.UID)
if runnable := kl.canRunPod(pod); !runnable.Admit {...}
// Update status in the status manager
kl.statusManager.SetPodStatus(pod, apiPodStatus)
// Create Cgroups for the pod and apply resource parameters to them if cgroups-per-qos flag is enabled.
pcm := kl.containerManager.NewPodContainerManager()
// Make data directories for the pod
kl.makePodDataDirs(pod);
// Fetch the pull secrets for the pod
pullSecrets := kl.getPullSecretsForPod(pod)
// Call the container runtime's SyncPod callback
result := kl.containerRuntime.SyncPod(pod, apiPodStatus, podStatus, pullSecrets, kl.backOff)
...
}
Kubelet.syncPod中会根据需求进行Pod的Kill、Cgroup的设置、为Static Pod创建Mirror Pod、为Pod创建data directories、等待Volume挂载等工作,最重要的还会调用KubeGenericRuntimeManager.SyncPod进行Pod的状态维护和干预操作。
KubeGenericRuntimeManager.SyncPod确保Running Pod(Kubelet.syncPod 与KubeGenericRuntimeManager.SyncPod sync的粒度不同)处于期望状态,主要执行以下操作。
- Compute sandbox and container changes.
- Kill pod sandbox if necessary.
- Kill any containers that should not be running.
- Create sandbox if necessary.
- Create ephemeral containers.
- Create init containers.
- Create normal containers.
func (m *kubeGenericRuntimeManager) SyncPod(pod *v1.Pod, _ v1.PodStatus, podStatus *kubecontainer.PodStatus, pullSecrets []v1.Secret, backOff *flowcontrol.Backoff) (result kubecontainer.PodSyncResult) {
// Step 1: Compute sandbox and container changes.
podContainerChanges := m.computePodActions(pod, podStatus)
...
// Step 4: Create a sandbox for the pod if necessary.
podSandboxID, msg, err = m.createPodSandbox(pod, podContainerChanges.Attempt)
// Get podSandboxConfig for containers to start.
podSandboxConfig, err := m.generatePodSandboxConfig(pod, podContainerChanges.Attempt)
// Step 5: start the init container.
if container := podContainerChanges.NextInitContainerToStart; container != nil {
// Start the next init container.
msg, err := m.startContainer(podSandboxID, podSandboxConfig, container, pod, podStatus, pullSecrets, podIP, kubecontainer.ContainerTypeInit);
}
// Step 6: start containers in podContainerChanges.ContainersToStart.
for _, idx := range podContainerChanges.ContainersToStart {
container := &pod.Spec.Containers[idx]
msg, err := m.startContainer(podSandboxID, podSandboxConfig, container, pod, podStatus, pullSecrets, podIP, kubecontainer.ContainerTypeRegular);
}
...
}
如何在Kubernetes中实现容器原地升级kubeGenericRuntimeManager.SyncPod 首先调用kubeGenericRuntimeManager.computePodActions检查Pod Spec是否发生变更,并且返回PodActions,记录为了达到期望状态需要执行的变更内容。computePodActions会检查Pod Sandbox是否发生变更、各个Container(包括InitContainer)的状态等因素来决定是否要重建整个Pod。
- 如果容器还没启动,则会根据Container的重启策略决定是否将Container添加到待启动容器列表中(PodActions.ContainersToStart);
- 如果容器的Spec发生变更(比较Hash值),则无论重启策略是什么,都要根据新的Spec重建容器,将Container添加到待启动容器列表中(PodActions.ContainersToStart);
- 如果Container Spec没有变更,liveness probe也是成功的,则该Container将保持不动,否则会将容器将入到待Kill列表中(PodActions.ContainersToKill);
PodActions表示要对Pod进行的操作信息:
// pkg/kubelet/kuberuntime/kuberuntime_manager.go
// podActions keeps information what to do for a pod.
type podActions struct {
KillPod bool
CreateSandbox bool
SandboxID string
Attempt uint32
NextInitContainerToStart *v1.Container
ContainersToStart []int
ContainersToKill map[kubecontainer.ContainerID]containerToKillInfo
}
computePodActions的关键是的计算出了待启动的和待Kill的容器列表。接下来,KubeGenericRuntimeManager.SyncPod就会在分别调用KubeGenericRuntimeManager.killContainer和startContainer去杀死和启动容器。
func (m *kubeGenericRuntimeManager) startContainer(podSandboxID string, podSandboxConfig *runtimeapi.PodSandboxConfig, container *v1.Container, pod *v1.Pod, podStatus *kubecontainer.PodStatus, pullSecrets []v1.Secret, podIP string, containerType kubecontainer.ContainerType) (string, error) {
// Step 1: pull the image.
imageRef, msg, err := m.imagePuller.EnsureImageExists(pod, container, pullSecrets)
// Step 2: create the container.
ref, err := kubecontainer.GenerateContainerRef(pod, container)
containerConfig, cleanupAction, err := m.generateContainerConfig(container, pod, restartCount, podIP, imageRef, containerType)
containerID, err := m.runtimeService.CreateContainer(podSandboxID, containerConfig, podSandboxConfig)
err = m.internalLifecycle.PreStartContainer(pod, container, containerID)
// Step 3: start the container.
err = m.runtimeService.StartContainer(containerID)
// Step 4: execute the post start hook.
msg, handlerErr := m.runner.Run(kubeContainerID, pod, container, container.Lifecycle.PostStart)
}
kubeGenericRuntimeManager.startContainer 相对 runtimeService.startContainer来说,多了拉取镜像、创建容器(包括pause容器和业务容器)、执行hook等工作。 pod 操作在这里 被拆解为容器和镜像操作。

从图中可以看到,蓝色区域 grpc 调用 dockershim等cri shim 完成。
留下评论