《Apache Kafka源码分析》——clients
前言
生产者
The producer connects to any of the alive nodes and requests metadata about the leaders for the partitions of a topic. This allows the producer to put the message directly to the lead broker for the partition.
大纲是什么?
- 线程模型
- 发送流程
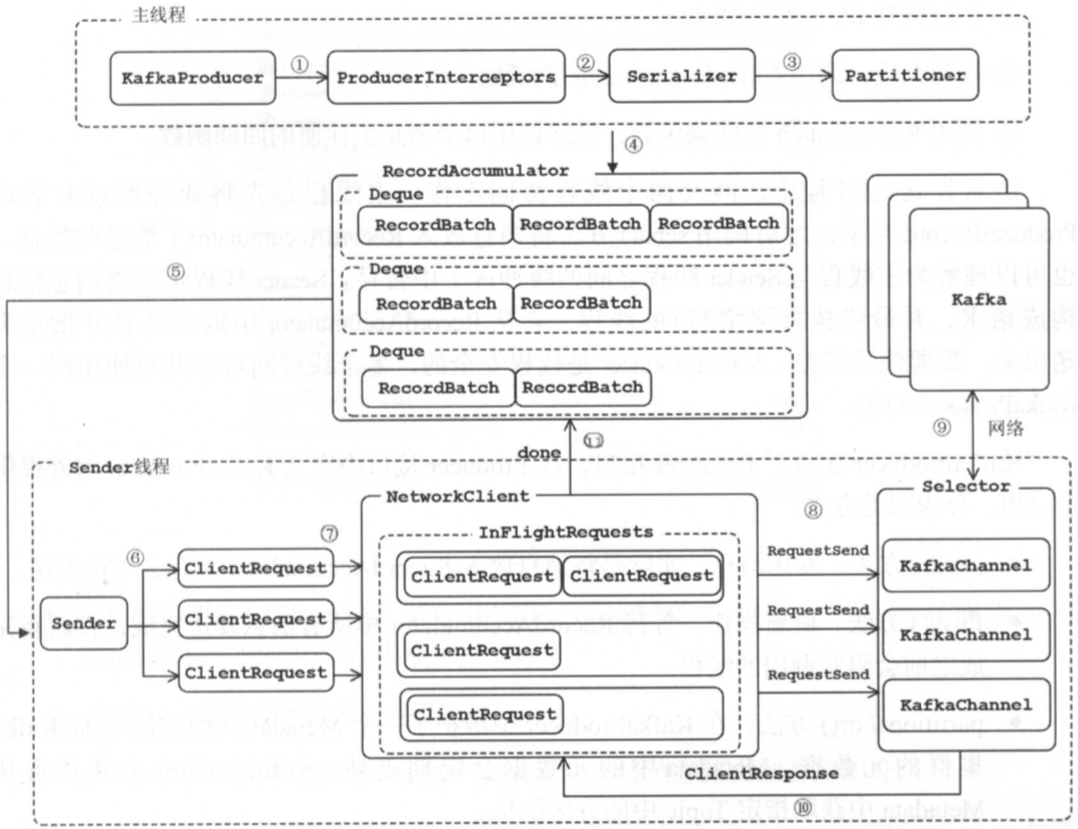

- producer 实现就是 业务线程(可能多个线程操作一个producer对象) 和 io线程(sender,看样子应该是一个producer对象一个)生产消费的过程
- 从producer 角度看,topic 分区数量以及 leader 副本的分布是动态变化的,Metadata 负责屏蔽相关细节,为producer 提供最新数据
- 发送消息时有同步异步的区别,其实底层实现相同,都是异步。业务线程通过
KafkaProducer.send不断向RecordAccumulator 追加消息,当达到一定条件,会唤醒Sender 线程发送RecordAccumulator 中的消息。其实nio发送数据包也是业务线程和io线程分开的。 - ByteBuffer的创建和释放是比较消耗资源的,为了实现内存的高效利用,基本上每个成熟的框架或工具都有一套内存管理机制,对应到kafka 就是 BufferPool
-
业务线程和io线程协作靠队列,为什么不直接用队列?
- RecordAccumulator acts as a queue that accumulates records into MemoryRecords instances to be sent to the server.The accumulator uses a bounded amount of memory and append calls will block when that memory is exhausted, unless this behavior is explicitly disabled.
- 用了队列,才可以batch和压缩。
- If the request fails, the producer can automatically retry, though since we have specified etries as 0 it won’t. Enabling retries also opens up the possibility of duplicates
bootstrap.servers
bootstrap.servers 指定了Producer 启动时要连接的 Broker 地址。通常指定 3~4 台就足以了。因为 Producer 一旦连接到集群中的任一台 Broker,就能拿到整个集群的 Broker 信息
在创建 KafkaProducer 实例时,生产者应用会在后台创建并启动一个名为 Sender 的线程,该 Sender线程开始运行时首先会创建与 Broker 的连接。
业务线程
producer 在KafkaProducer 与 NetworkClient 之间玩了多好花活儿?

sender 线程

值得学习的地方——interceptor
在发送端,record发送和执行record发送结果的callback之前,由interceptor拦截
- 发送比较简单,record发送前由interceptors操作一把。
ProducerRecord<K, V> interceptedRecord = this.interceptors == null ? record : this.interceptors.onSend(record) Callback interceptCallback = this.interceptors == null ? callback : new InterceptorCallback<>(callback, this.interceptors, tp);
对于底层发送来说,doSend(ProducerRecord<K, V> record, Callback callback)interceptors的加入并不影响(实际代码有出入,但大意是这样)。
值得学习的地方——反射的另个一好处
假设你的项目,用到了一个依赖jar中的类,但因为策略问题,这个类对有些用户不需要,自然也不需要这个依赖jar。此时,在代码中,你可以通过反射获取依赖jar中的类,避免了直接写在代码中时,对这个jar的强依赖。
消费者
While subscribing, the consumer connects to any of the live nodes and requests metadata about the leaders for the partitions of a topic. The consumer then issues a fetch request to the lead broker to consume the message partition by specifying the message offset (the beginning position of the message offset). Therefore, the Kafka consumer works in the pull model and always pulls all available messages after its current position in the Kafka log (the Kafka internal data representation).
读Kafka Consumer源码 对consumer 源码的实现评价不高
开发人员不必关心与kafka 服务端之间的网络连接的管理、心跳检测、请求超时重试等底层操作,也不必关心订阅Topic的分区数量、分区leader 副本的网络拓扑以及consumer group的Rebalance 等kafka的具体细节。
KafkaConsumer 依赖SubscriptionState 管理订阅的Topic集合和Partition的消费状态,通过ConsumerCoordinator与服务端的GroupCoordinator交互,完成Rebalance操作并请求最近提交的offset。Fetcher负责从kafka 中拉取消息并进行解析,同时参与position 的重置操作,提供获取指定topic 的集群元数据的操作。上述所有请求都是通过ConsumerNetworkClient 缓存并发送的,在ConsumerNetworkClient 中还维护了定时任务队列,用来完成HeartbeatTask 任务和AutoCommitTask 任务。NetworkClient 在接收到上述请求的响应时会调用相应回调,最终交给其对应的XXHandler 以及RequestFuture 的监听器进行处理。
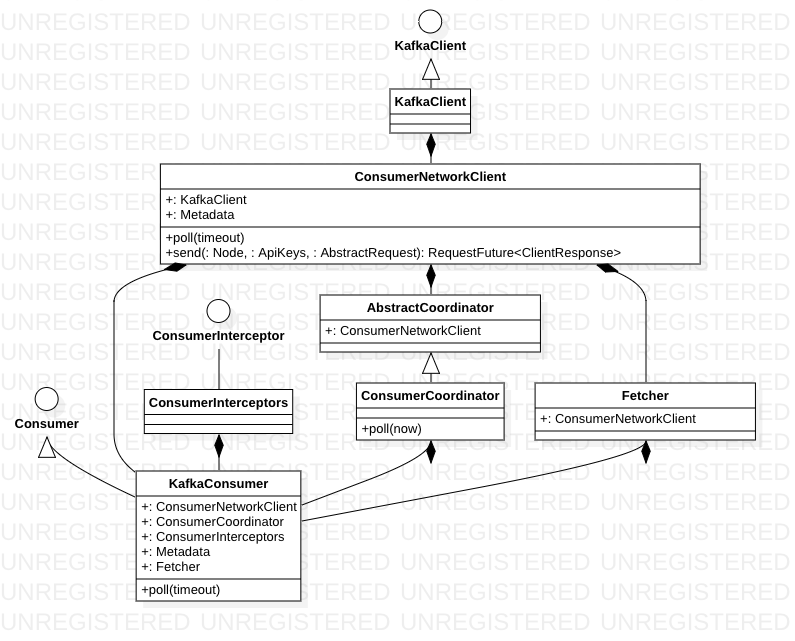
poll 的核心逻辑在pollOnce 中, Do one round of polling. In addition to checking for new data, this does any needed heart-beating, auto-commits, and offset updates.

Kafka对外暴露了一个非常简洁的poll方法,其内部实现了协作、分区重平衡、心跳、数据拉取等功能,但使用时这些细节都被隐藏了
Kafka provides two types of API for Java consumers:
- High-level API, does not allow consumers to control interactions with brokers.
- Low-level API, is stateless and provides fine grained control over the communication between Kafka broker and the consumer.
那么consumer 与broker 交互有哪些细节呢?The high-level consumer API is used when only data is needed and the handling of message offsets is not required. This API hides broker details from the consumer and allows effortless communication with the Kafka cluster by providing an abstraction over the low-level implementation. The high-level consumer stores the last offset (the position within the message partition where the consumer left off consuming the message), read from a specific partition in Zookeeper. This offset is stored based on the consumer group name provided to Kafka at the beginning of the process.
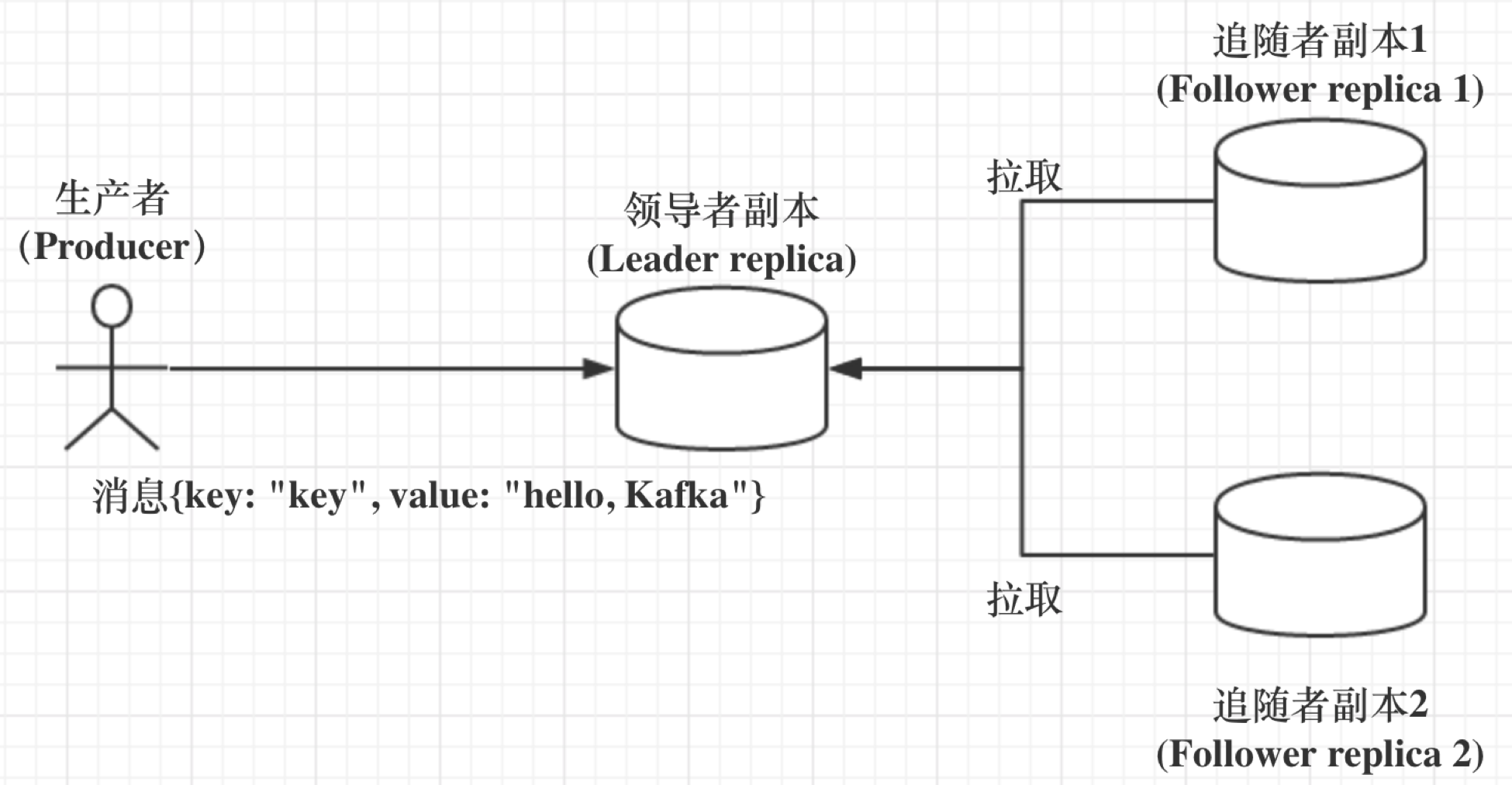
主动拉取 是kafka 的一个重要特征,不仅是consumer 主动拉取broker, broker partition follower 也是主动拉取leader。
KafkaConsumer线程安全
private final AtomicLong currentThread = new AtomicLong(NO_CURRENT_THREAD);
private final AtomicInteger refcount = new AtomicInteger(0);
public ConsumerRecords<K, V> poll(long timeout) {
acquire();
try {
...
} finally {
release();
}
}
currentThread holds the threadId of the current thread accessing KafkaConsumer and is used to prevent multi-threaded access.refcount is used to allow reentrant (re entry)access by the thread who has acquired currentThread
private void acquire() {
ensureNotClosed();
long threadId = Thread.currentThread().getId();
if (threadId != currentThread.get() && !currentThread.compareAndSet(NO_CURRENT_THREAD, threadId))
throw new ConcurrentModificationException("KafkaConsumer is not safe for multi-threaded access");
refcount.incrementAndGet();
}
Acquire the light lock protecting this consumer from multi-threaded access. Instead of blocking when the lock is not available, however, we just throw an exception (since multi-threaded usage is not supported). acquire只是做了简单的线程监测, 如果KafkaConsumer 已被线程占用,则另一个线程调用时会抛出异常
consumer group
为什么要引入consumer group呢?主要是为了提升消费者端的吞吐量。多个consumer实例同时消费,加速整个消费端的吞吐量(TPS)。
| broker | consumer | |
|---|---|---|
| 逻辑 | topic | consumer group |
| 物理 | partition | consumer instance |
| partition | leader-follower | leader-consumer |
| 描述 | producer写到哪了,当前同步到哪了 | 当前各个consumer group消费到哪了 |
如果将consumer group 类比为partition follower,消费数据与同步数据其实也差不多。
消费者的线程数
我们说 KafkaConsumer 是单线程的设计,严格来说这是不准确的。因为,从 Kafka 0.10.1.0 版本开始,KafkaConsumer 就变为了双线程的设计,即用户主线程和心跳线程。
所谓用户主线程,就是你启动 Consumer 应用程序 main 方法的那个线程,而新引入的心跳线程(Heartbeat Thread)只负责定期给对应的 Broker 机器发送心跳请求,以标识消费者应用的存活性(liveness)。引入这个心跳线程还有一个目的,那就是期望它能将心跳频率与主线程调用 KafkaConsumer.poll 方法的频率分开,从而解耦真实的消息处理逻辑与消费者组成员存活性管理。
虽然有心跳线程,但实际的消息获取逻辑依然是在用户主线程中完成的。因此,在消费消息的这个层面上,我们依然可以安全地认为 KafkaConsumer 是单线程的设计。
rebalance
kafka系列之(3)——Coordinator与offset管理和Consumer Rebalance
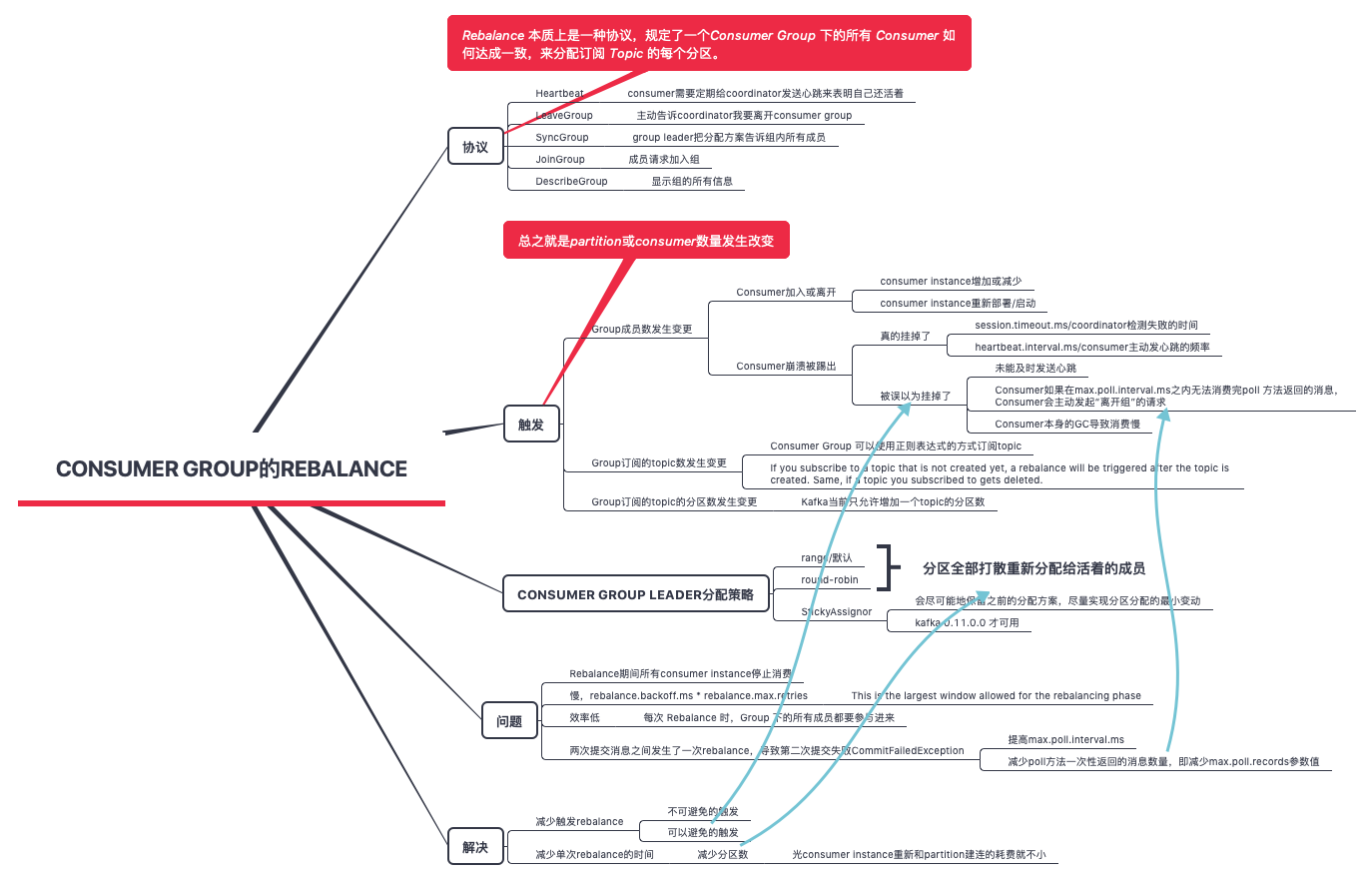
两个角色
- Consumer Group Co-ordinator
- Group Leader
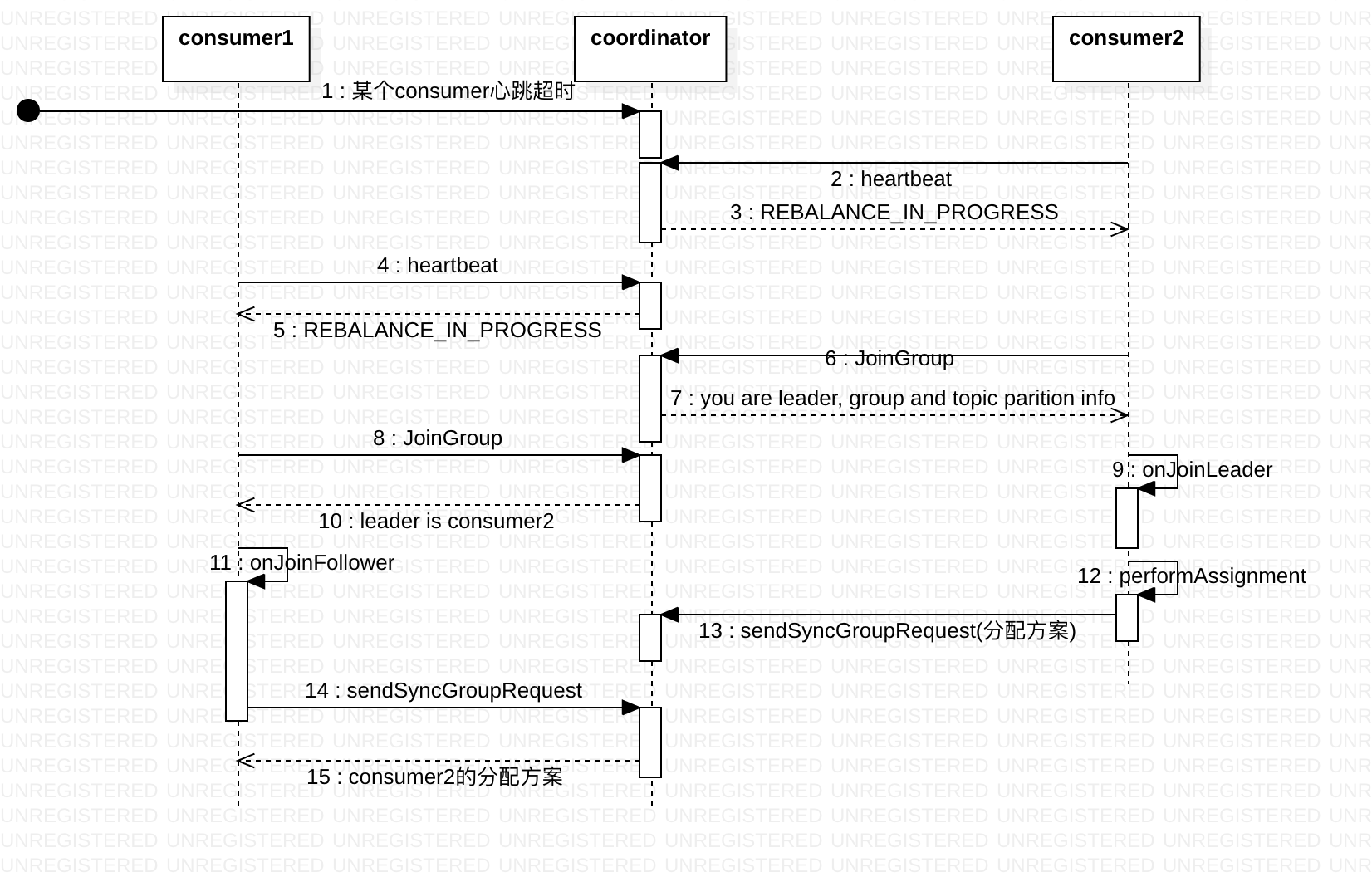
rebalance过程有以下几点
- rebalance本质上是一组协议。group与coordinator共同使用它来完成group的rebalance。
- consumer如何向coordinator证明自己还活着? 通过定时向coordinator发送Heartbeat请求。如果超过了设定的超时时间,那么coordinator就认为这个consumer已经挂了。
- 一旦coordinator认为某个consumer挂了,那么它就会开启新一轮rebalance,并且在当前其他consumer的心跳response中添加“REBALANCE_IN_PROGRESS”,告诉其他consumer:不好意思各位,你们重新申请加入组吧!
- 所有成员都向coordinator发送JoinGroup请求,请求入组。一旦所有成员都发送了JoinGroup请求,coordinator选择第一个发送JoinGroup请求的consumer担任leader的角色,并将consumer group 信息和partition信息告诉group leader。
- leader负责分配消费方案(使用PartitionAssignor),即哪个consumer负责消费哪些topic的哪些partition。一旦完成分配,leader会将这个方案封装进SyncGroup请求中发给coordinator,非leader也会发SyncGroup请求,只是内容为空。coordinator接收到分配方案之后会把方案塞进SyncGroup的response中发给各个consumer。
小结一下就是:coordinator负责决定leader,leader 负责分配方案,consumer group的分区分配方案是在客户端执行的, 分配方案由coordinator 扩散。

位移管理
Apache Kafka Foundation Course - Offset Management
消费者在消费的过程中需要记录自己消费了多少数据,即消费位置信息,以便重启时继续上次中断的位置消费。
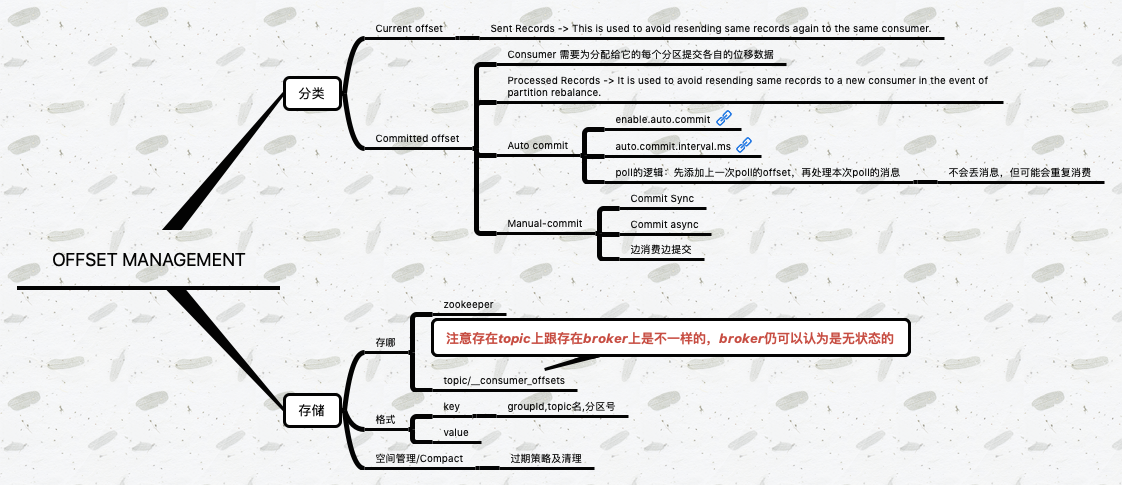
__consumer_offsets。位移topic就是普通的 Kafka topic。你可以手动地创建它、修改它,甚至是删除它。但它的消息格式却是 Kafka 自己定义的,用户不能修改,也就是说你不能随意地向这个topic写消息,因为一旦你写入的消息不满足 Kafka 规定的格式,那么 Kafka 内部无法成功解析,就会造成 Broker 的崩溃。
假设 Consumer 当前消费到了某个topic的最新一条消息,位移是 100,之后该topic没有任何新消息产生,故 Consumer 无消息可消费了,所以位移永远保持在 100。由于是自动提交位移,__consumer_offsets中会不停地写入位移 =100 的消息。Kafka 是怎么删除__consumer_offsets中的过期消息的呢?答案就是Compaction。对于同一个 Key 的两条消息 M1 和 M2,如果 M1 的发送时间早于 M2,那么 M1 就是过期消息。Compact 的过程就是扫描日志的所有消息,剔除那些过期的消息,然后把剩下的消息整理在一起。Kafka 提供了专门的后台线程定期地巡检待Compact 的topic,看看是否存在满足条件的可删除数据。这个后台线程叫 Log Cleaner。很多实际生产环境中都出现过__consumer_offsets无限膨胀占用过多磁盘空间的问题,如果你的环境中也有这个问题,建议你去检查一下 Log Cleaner 线程的状态,通常都是这个线程挂掉了导致的。
如何确定为consumer group服务的coordinator?
-
确定consumer group位移信息写入__consumers_offsets这个topic的哪个分区。具体计算公式:
__consumers_offsets partition# = Math.abs(groupId.hashCode() % groupMetadataTopicPartitionCount)注意:groupMetadataTopicPartitionCount由offsets.topic.num.partitions指定,默认是50个分区。 知晓这个算法的最大意义在于,它能够帮助我们解决定位问题。 当 Consumer Group 出现问题,需要快速排查 Broker 端日志时,我们能够根据这个算法准确定位 Coordinator 对应的 Broker,不必一台 Broker 一台 Broker 地盲查。 -
该分区leader所在的broker,就是被选定Coordinator。每个Broker 在启动时,都会创建和开启相应的Coordinator
留下评论