源码分析体会
前言
我们去阅读别人的代码,通常会带有一定的目的性。为什么要把我们的目标搞清楚?因为读懂源代码真的很难,它其实是架构的反向过程。完整把一个系统的代码 “读懂” 需要极大的精力。
有文档,一定要先看文档。如果原本就已经有写过架构设计的文档,我们还要坚持自己通过代码一步步去反向进行理解,那就太傻了。但是,一定要记住文档和代码很容易发生脱节。如果你能够找到之前做过这块业务的人,不要犹豫,尽可能找到他们并且争取一个小时左右的交流机会。
为什么要读源码
如果你看到一个新东西,却没有理清它的逻辑,直到打通你已熟悉的东西(学名叫已有的知识体系),那肯定是没有真正理解它。
直接目标——学习框架
- 浅层知识细节太多,极其容易遗忘。如果一想起某个框架,你只记得一些琐碎的使用细节,那么连“如何使用这个框架”这个技能本身,也终究是会失去的。
- 如果框架对你都是黑盒,那么你就不敢用
- 熟悉源码,是对一些“微言大义”的佐证。每个框架 在其官网都有一句/段的概括,若是不熟悉整个上下文,这段精炼的概括是很难读出感觉的。此外,直接附着在源码上的注释,通常也很精炼,文档上很难看到。
- 世界很奇怪,打败微信的不会是另一个微信;光靠写代码,也不会提高写代码的水平。只有输出没有输入是不行的,要不断的学习优秀源码的实现。
- 涉猎广泛,涉猎广泛就可以理论联系实际。比如我们说事务有四大特性,从一个程序员的角度说,概念背的再溜不如show me your code。比如事务的原子性,在mysql中体现为redo和undo log,在spring-tx 体现为try catch中的rollback。在compensable-transaction 中除了commit、rollback之外,还有系统重启之后的重试,此时transaction就是redo/undo log。
写代码为什么需要注释?一个重要的原因是母语的力量。我们天然所经历的环境与我们每天所接触到的事物,让我们对中文与英文有完全不一样的感受。我们代码的编写本质上是一个将我们沟通中的“中文问题”,翻译成“英文代码”来实现的过程。而阅读代码的人在做得,是一件将“英文代码”翻译成“中文表述”的事情。而这之中经过的环节越多,意思变味越严重。
深层知识/感觉才是有价值的
只有深层知识才可以通用,通用很重要。学习一个源码可以加快理解另一个源码的速度。
- 通用是必要的,对于java来说,如果只会spring + mybatis等入门框架,那么留给你的就是一些简单的后台系统(业务级的系统),你永远无法去做部门级、公司级、apache级的项目。
-
通用是有很大好处的,你学习一个新的东西会越来越快。如果你曾经精研过netty的io 原理,那么当你碰到kafka 的io 部分时,可以一笔跳过。
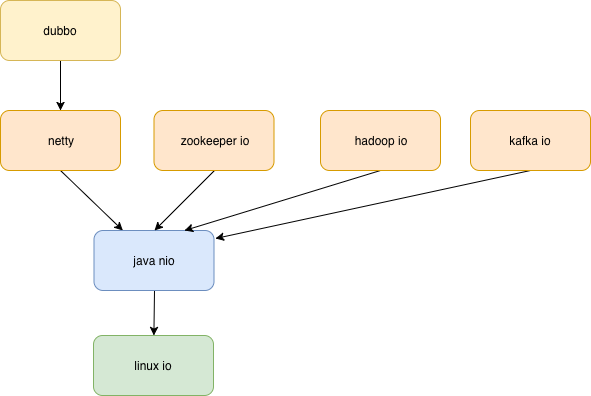
东西都是共通的,认知的几点规律 欧几里得的《几何原本》,从五条公设和五个公理出发,经过层层演绎推理,竟能推出整整一本书的内容。 当你把分层、异步、反应式这些基础的东西 理解透彻后,分析一个框架的源码就是一两天的事情。虽然短时间内增大了学习负担,但一旦理解透彻,疑惑不在脑中徘徊,长期来说省去了纠结、疑虑和google的时间。源码的学习 可以反哺源码学习的能力,从程序员的职业生涯来讲,成长来自解决足够复杂的事情,这需要你有足够高的学习和工作效率,决不能将工作产出绑死在工作时间上,学习源码是提高专业工作效率的重要部分。
如果不深挖一下,一个java开发很少有机会认识到学习linux 有多么必要。
常识比信息重要
信息越多越心累,常识越多越通透。可以为任何学习行为 找到一个通用目标:提炼常识。进而通过常识,碰到一个新技术时可以place it in context
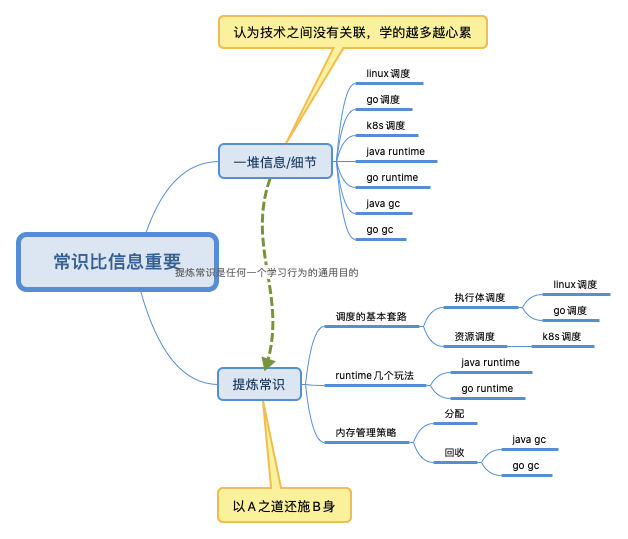
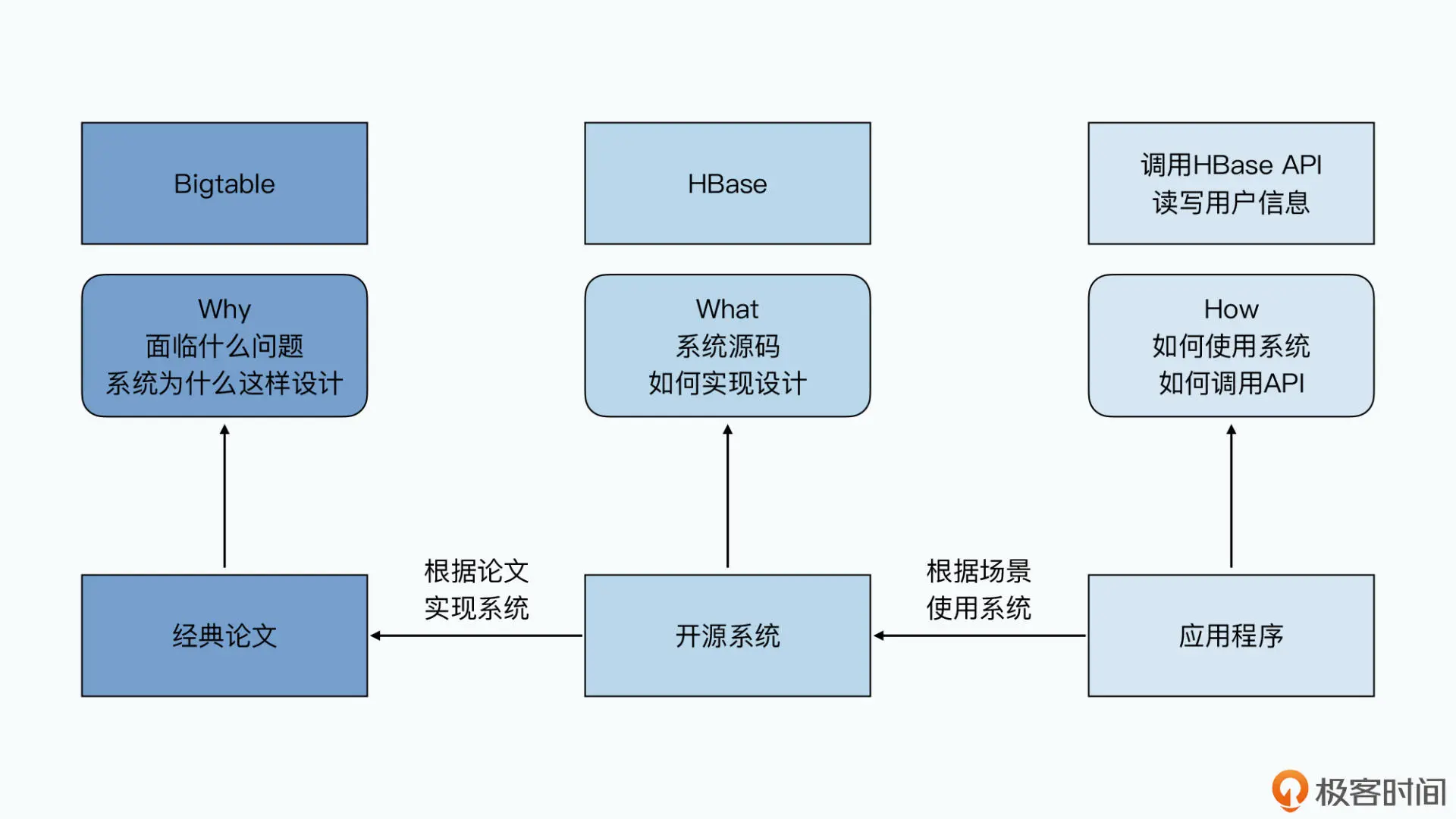
why 比what 和how 重要,看源码之后 还有一个看论文。找回技术发展的脉络。
AngelList 的创始人纳瓦尔·拉威康(Naval Ravikant)说过这样一段话:知识是一座摩天大楼。你可以在记忆的脆弱基础上走捷径,或者在理解的钢架上慢慢建立。
分析方法
前期准备
- demo例子
- 如果条件允许的话,最好能熟练使用框架。使用的过程中最好积累一些疑问,以作为分析源码时的切入点,在分析过程中想办法解决这几个问题。
- 阅读官方文档,搜索一些博客,对其主要设计、理念心中有数
- 了解下框架涉及的一些底层技术,比如NIO等
- 程序=数据结构+算法,识别其数据部分(也就是输入输出是什么),猜测其核心逻辑(算法)。数据结构是容易梳理的,类的成员变量、数据库的表结构。理清楚数据结构,事情就解决了大半。剩下来就是理各个 UserStory 的业务流程,并给这些业务流程画出它的 UML 时序图。
分析过程
- 多画图,相对文字而言,图的信息密度更高
-
类图,所有用面向对象思想实现的框架都可以画类图,类图反映了代码的组织。一个框架如果代码量很大的话,一定要解决一个事情,即代码和数据是如何分散在各个小单元的,类图通常反应了作者对框架所解决问题的逻辑抽象。画类图有几个注意点
- 抓大放小
- 因为Java 各种设计模式,表象跟意图经常错位。比如A 有一个B成员,有时不能画为 A和B 是聚合关系
- 同一个意图的几个类,建议标上一致的背景色,突出功能域
- 序列图。包括初始化流程,和主干流程。 对源码分析进行整理浓缩,跟踪主要路径,直到打通到你已经熟悉的知识。以java为例,一个序列图的尾部,通常是类似java/io 等已熟知的类。
- 重要的不是画这些图,而是以这些图为抓手,串一个下整个过程,分析的过程才是最重要的,切忌把画图手段当成目的。找到感觉,积累成功的心理体验。
类图和序列图系统分析 一个框架示例 Jedis源码分析
最重要的——后期跟进
不管多么高的技巧,初次学习一个新东西,对事情的认识都是有限/片面的。一方面需要一段时间连续投入其中,从细节、琐碎之中憋出一些“体悟”出来。另一个是,经常反刍,碰到类似的东西时尽量举一反三,再反过来加深理解。
一些技巧
-
先弄清楚一个组件的input/output(一些项目会有些自定义协议) ,再看下核心数据结构,所谓业务逻辑,都是对数据结构数据的更新。不同类型的项目, 核心是不同的
- 你看一个web 项目 直接看 数据库表 就算是抓住了核心。大部分业务系统代码是过程式的(从接收数据到发出去都在一个线程内),数据流转是清晰的(请求 ==> 缓存 ==> db),复杂的是业务。
- 你看一个中间件 它的核心 是功能的拆解和组装,有哪些组件,组件之间是如何交互的?数据是如何流转的?
- 只分析主要功能的主要流程,忽略异常处理、特殊逻辑处理等。没错,80%的代码都没干“正经”事。有兴趣可以找源码0.0.1 版本的代码看下。
- 能有一段较长的、可以集中注意力的时间
- 世界很复杂,但基础的逻辑真的很有限。源码很复杂,但基础的原理真的很有限。
- 在你学习一定数量的框架之前,你收到的全是负反馈(因为有那么多不会的),但一旦越过瓶颈点,尤其是你学过一些很难的框架之后,再去看一些简单框架的源码,你就会有一种“藐视敌人的英雄气概”。无论做什么事情,成功过一次很重要。
- 不断去做,以至于成为本能。源码分析的多了,会形成一种直觉,从繁杂的表象下提取关键、有效信息的直觉
- 每个人的背景知识是不一样的,写一篇文档,以自己的视角重新串一下整个框架。
- 任何一个系统的设计都有功能和性能(泛化一下就是功能性和非功能性) 两个部分,识别系统模块属于哪个部分,有助于简化对系统的认识。通常,一个系统的最早版本只专注于功能,后续除非大的变动,后来的演化大部分都是为了性能上的追求
- 作者的代码不是一下子写出来的,你也不要试图一下子勘破所有门道。用分层、主次要矛盾的方法论去认知。
- 不要硬看代码,通过打印日志、打断点的方式来 查看代码的执行链条
你要有一个武器库,而不是三板斧。
即便看了源码,也很难说将系统吃透,但“消除陌生感” 也是很有意义的。
留下评论