Kubernetes源码分析——apiserver
简介
apiserver 核心职责
- 提供Kubernetes API
- 代理集群组件,比如Kubernetes dashboard、流式日志、
kubectl exec会话 - 缓存etcd 数据
声明式API
- 命令式命令行操作,比如直接
kubectl run - 命令式配置文件操作,比如先
kubectl create -f xx.yaml再kubectl replace -f xx.yaml - 声明式API 操作,比如
kubectl apply -f xx.yaml。命令式api 描述和执行 是一体的,声明式api 则需要额外的 执行器(下文叫Controller) sync desired state 和 real state。PS:它不需要创建变量用来存储数据,使用方不需要写控制流逻辑 if/else/for
声明式API 有以下优势
- 实现层的逻辑不同。kube-apiserver 在响应命令式请求(比如,kubectl replace)的时候,一次只能处理一个写请求,否则会有产生冲突的可能。而对于声明式请求(比如,kubectl apply),一次能处理多个写操作,并且具备 Merge 能力。
- 如果xx.yaml 不变,可以任意多次、同一时间并发 执行apply 操作。
- “声明式 API”允许有多个 API 写端,以 PATCH 的方式对 API 对象进行修改,而无需关心本地原始 YAML文件的内容。例如lstio 会自动向每一个pod 写入 envoy 容器配置(用户无感知),如果xx.yaml 是一个 xx.sh 则该效果很难实现。
火得一塌糊涂的kubernetes有哪些值得初学者学习的?在分布式系统中,任何组件都可能随时出现故障。当组件恢复时,需要弄清楚要做什么,使用命令式 API 时,处理起来就很棘手。但是使用声明式 API ,组件只需查看 API 服务器的当前状态,即可确定它需要执行的操作。《阿里巴巴云原生实践15讲》 称之为:面向终态自动化。PS:必须能容错、自愈,面向终态 ==> 声明式 ==> 得由控制器辅助干活儿。
不是技术也能看懂云原生Kubernetes还有一个亮点,是他是基于声明式API的,这和传统的运维模式有所区别。传统的运维模式是面向动作的,比如说需求是启动三个应用,那面向动作的运维就是找三个地方,把三个应用启动起来,检查启动没有问题,然后完事儿。稍微自动化一点的,就是写个脚本做这个事情。这种模式的问题是一旦三个应用因为某种原因挂了一个,除非人工检查一遍,要不就没人知道这件事情。而声明式API是面向期望状态的,客户提交的期望状态,kubernetes会保存这种期望状态,并且会自动检查当前状态是否和期望状态一致,如果不一致,则自动进行修复。这在大规模微服务运维的时候更加友好,因为几万个程序,无论靠人还是靠脚本,都很难维护,必须有这么一个Kubernetes平台,才能解放运维,让运维只需要关心期望状态。
分层架构
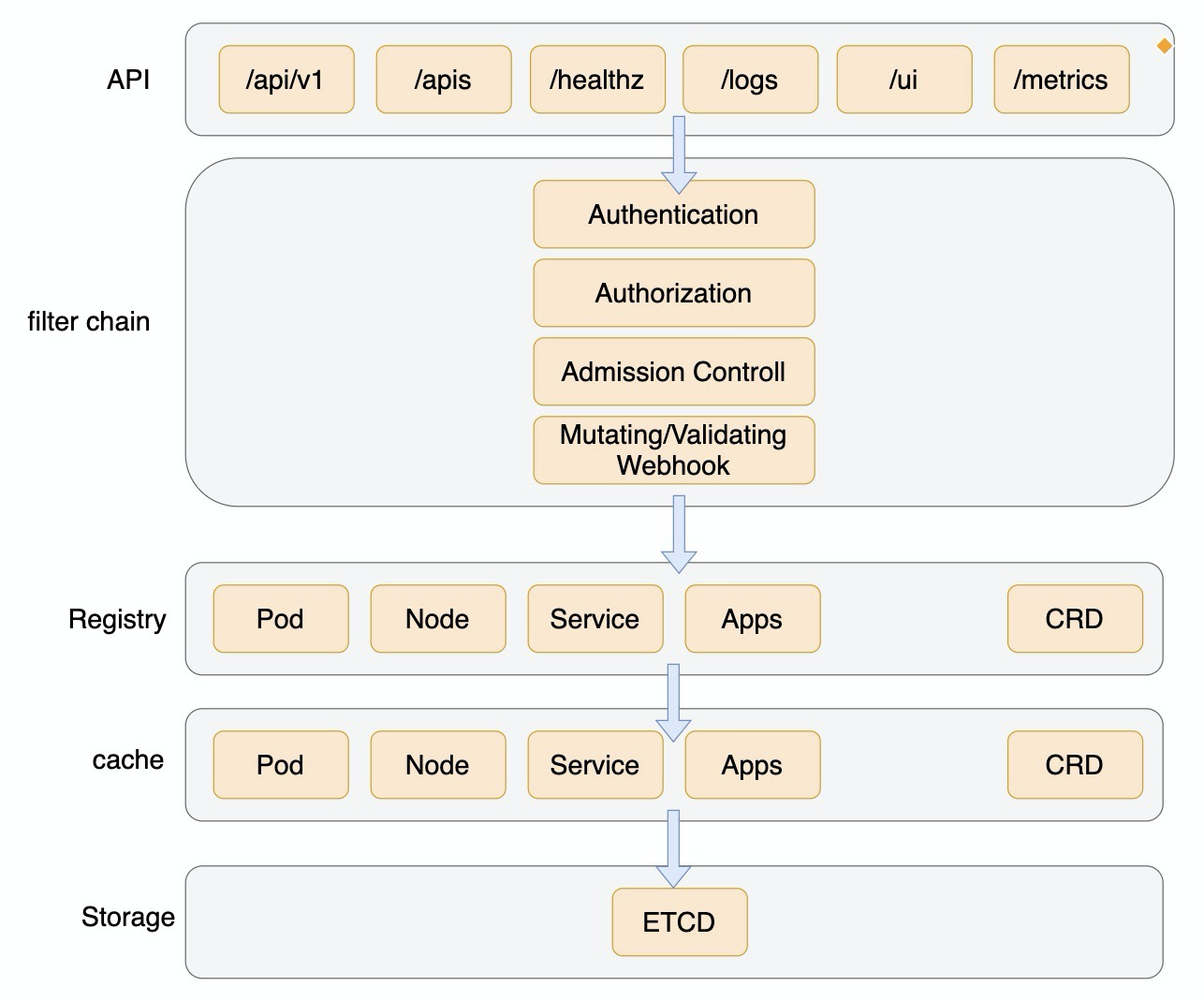
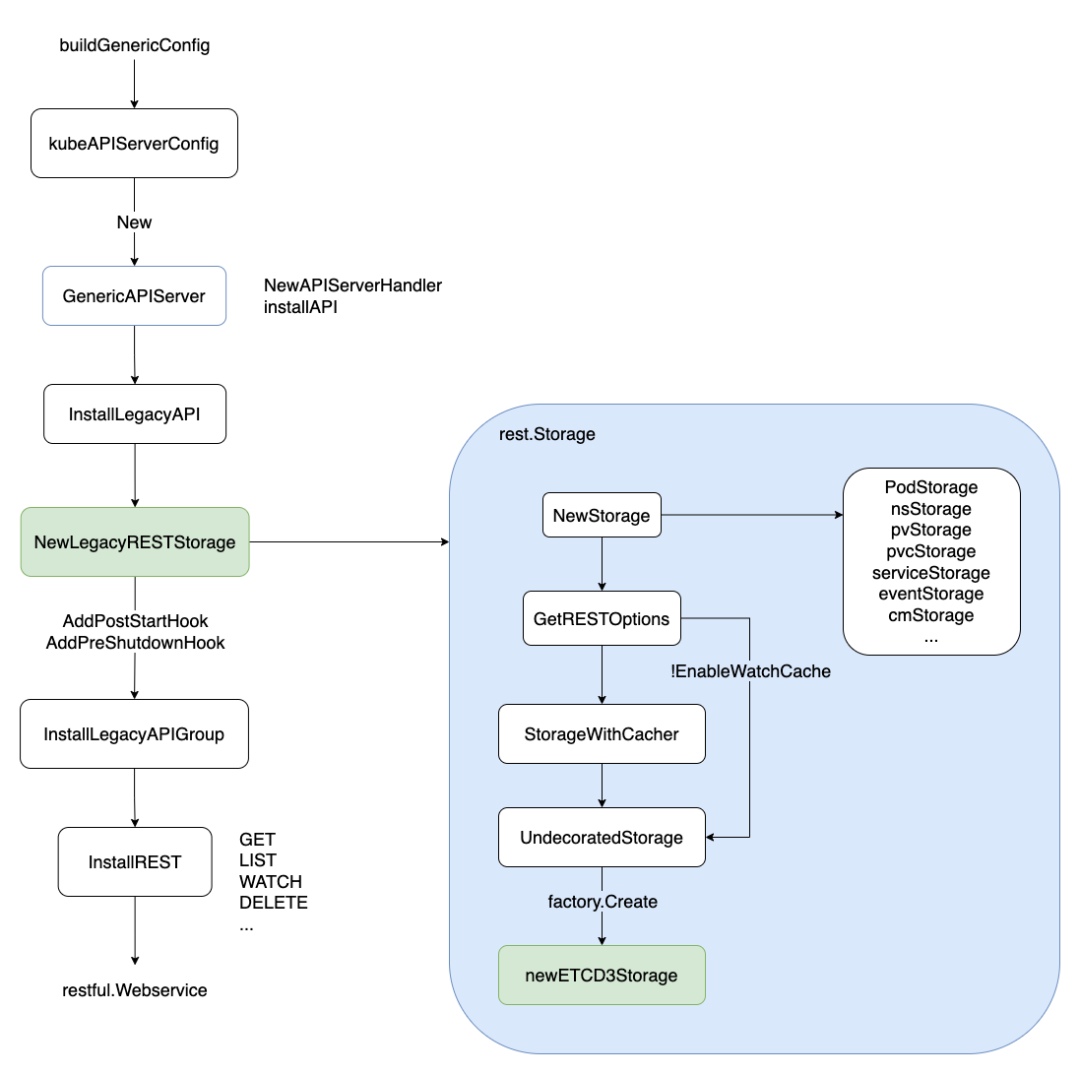
适合从下到上看。不考虑鉴权等,先解决一个Kind 的crudw,多个Kind (比如/api/v1/pods, /api/v1/services)汇聚成一个APIGroupVersion,多个APIGroupVersion(比如/api/v1, /apis/batch/v1, /apis/extensions/v1) 汇聚为 一个GenericAPIServer 即api server。
APIServer 启动
K8s 如何提供更高效稳定的编排能力?K8s Watch 实现机制浅析APIServer 启动采用 Cobra 命令行,解析相关 flags 参数,经过 Complete(填充默认值)->Validate(校验) 逻辑后,通过 Run 启动服务。在 Run 函数中,按序分别初始化 APIServer 链(APIExtensionsServer、KubeAPIServer、AggregatorServer),分别服务于 CRD(用户自定义资源)、K8s API(内置资源)、API Service(API 扩展资源) 对应的资源请求。
// kubernetes/cmd/kube-apiserver/app/server.go
// 创建 APIServer 链(APIExtensionsServer、KubeAPIServer、AggregatorServer),分别服务 CRD、K8s API、API Service
func CreateServerChain(completedOptions completedServerRunOptions, stopCh <-chan struct{}) (*aggregatorapiserver.APIAggregator, error) {
// 创建 APIServer 通用配置
kubeAPIServerConfig, serviceResolver, pluginInitializer, err := CreateKubeAPIServerConfig(completedOptions)
if err != nil {
return nil, err
}
...
// 第一:创建 APIExtensionsServer
apiExtensionsServer, err := createAPIExtensionsServer(apiExtensionsConfig, genericapiserver.NewEmptyDelegateWithCustomHandler(notFoundHandler))
if err != nil {
return nil, err
}
// 第二:创建 KubeAPIServer
kubeAPIServer, err := CreateKubeAPIServer(kubeAPIServerConfig, apiExtensionsServer.GenericAPIServer)
if err != nil {
return nil, err
}
...
// 第三:创建 AggregatorServer
aggregatorServer, err := createAggregatorServer(aggregatorConfig, kubeAPIServer.GenericAPIServer, apiExtensionsServer.Informers)
if err != nil {
// we don't need special handling for innerStopCh because the aggregator server doesn't create any go routines
return nil, err
}
return aggregatorServer, nil
}
之后,经过非阻塞(NonBlockingRun) 方式启动 SecureServingInfo.Serve,并配置 HTTP2(默认开启) 相关传输选项,最后启动 Serve 监听客户端请求。
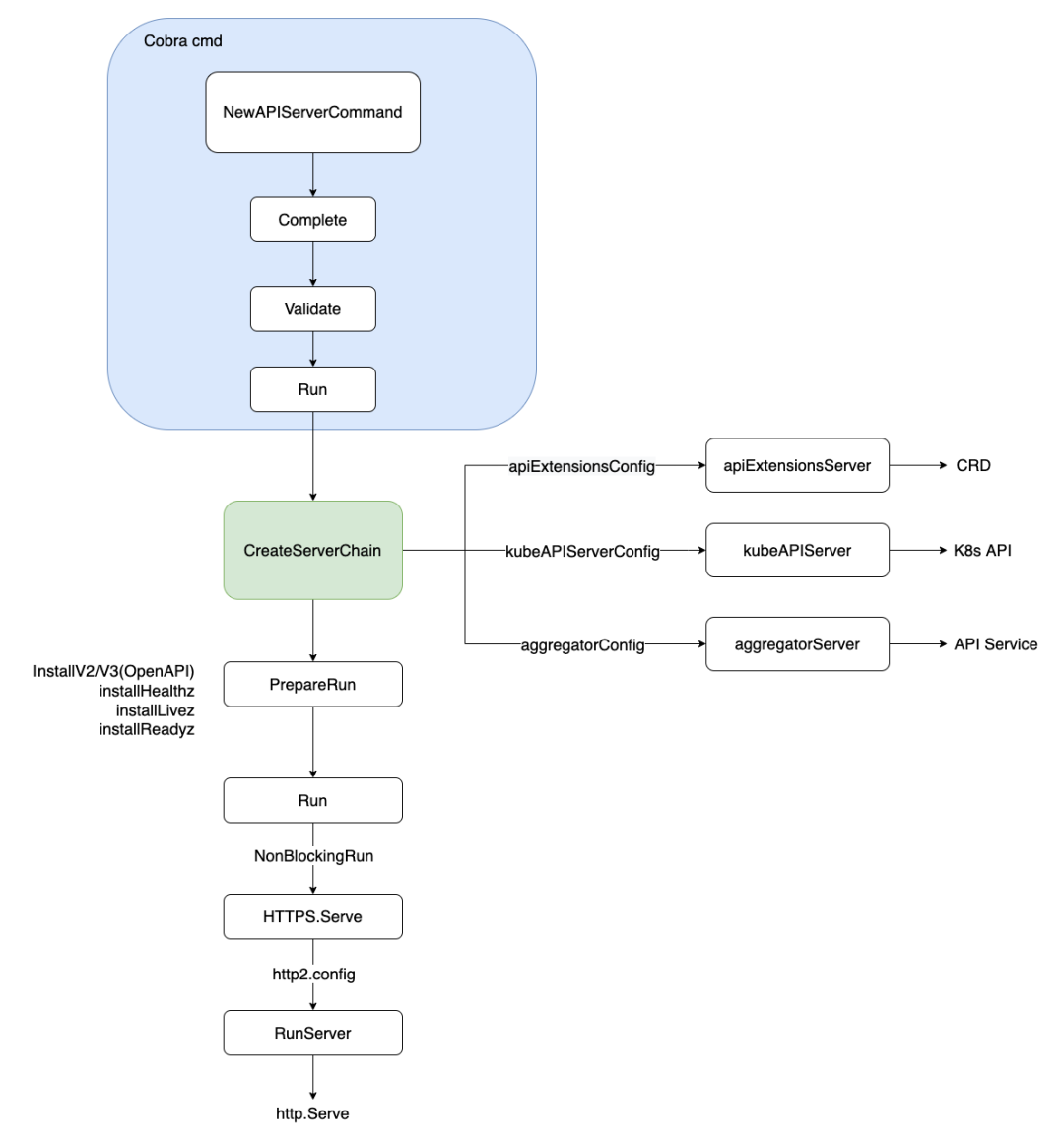
启动的一些重要步骤:
- 创建 server chain。Server aggregation(聚合)是一种支持多 apiserver 的方式,其中包括了一个 generic apiserver,作为默认实现。
- 生成 OpenAPI schema,保存到 apiserver 的 Config.OpenAPIConfig 字段。
- 遍历 schema 中的所有 API group,为每个 API group 配置一个 storage provider,这是一个通用 backend 存储抽象层。
- 遍历每个 group 版本,为每个 HTTP route 配置 REST mappings。稍后处理请求时,就能将 requests 匹配到合适的 handler。
Kubernetes API Server handler 注册过程分析 未读。以内置资源的 handler 注册过程为线索介绍了 APiServer 的启动过程和 handler 注册过程。对APIServer的访问会先经过 filter,再路由给具体的 handler。filter 在 DefaultBuildHandlerChain 中定义,主要对请求做超时处理,认证,鉴权等操作。handler 的注册则是初始化 APIGoupInfo 并设置其 VersionedResourcesStorageMap 后作为入参,调用 GenericAPIServer.InstallAPIGroups即可完成 handler 的注册。k8s.io/apiserver/pkg/endpoints/handlers包中的代码则是对用户请求做编解码,对象版本转换,协议处理等操作,最后在交给rest.Storage 具体实现的接口进行处理。
请求处理流程
资深专家深度剖析Kubernetes API Server第1章
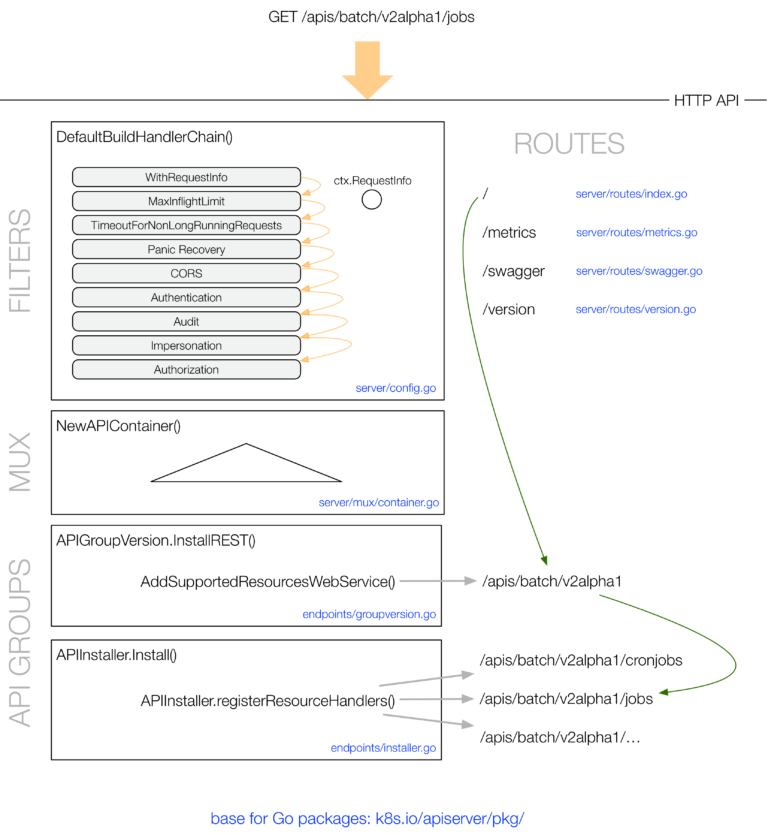
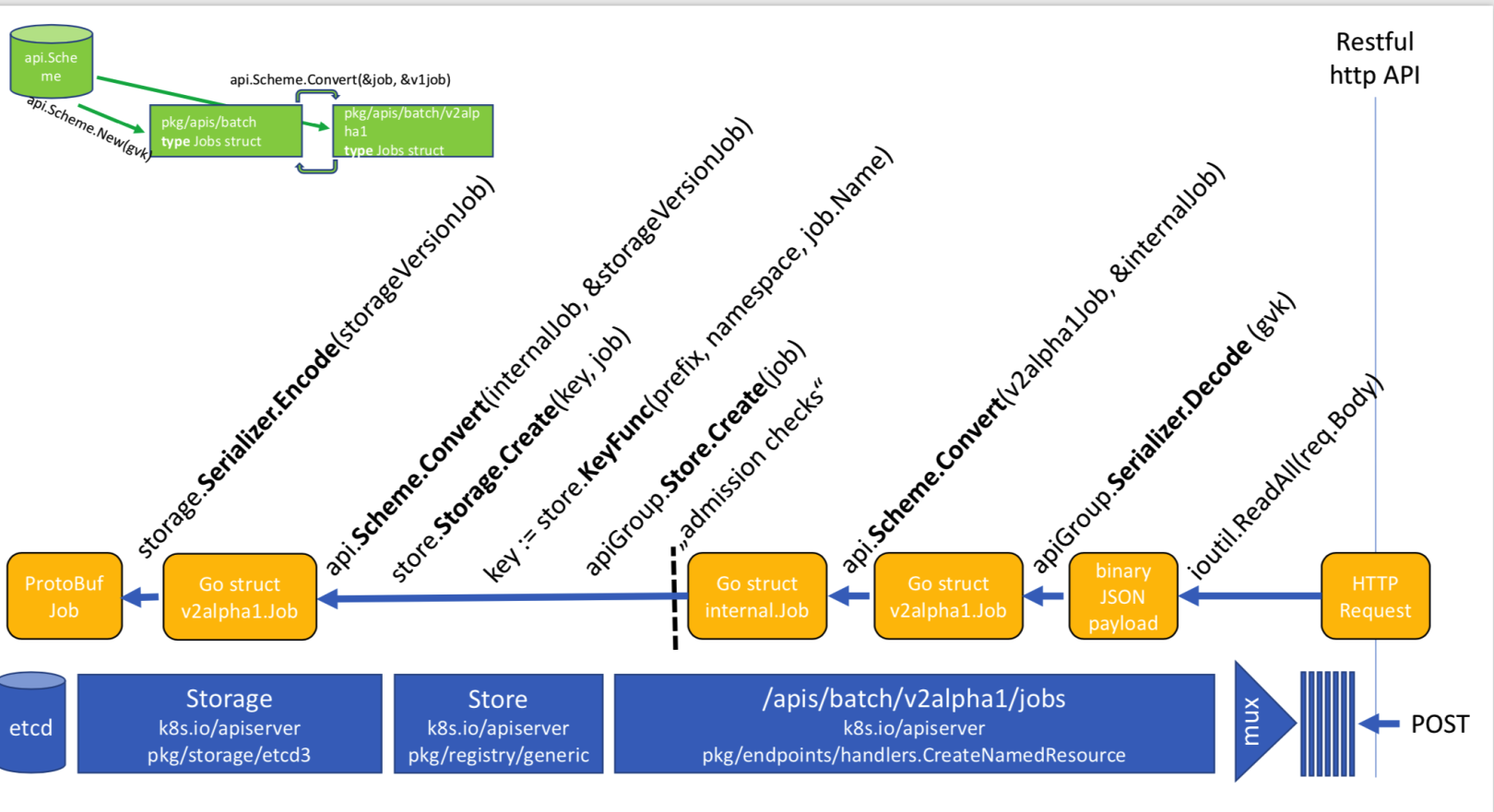
go-restful框架
宏观上来看,APIServer就是一个实现了REST API的WebServer,最终是使用golang的net/http库中的Server运行起来的,按照go-restful的原理,包含以下的组件
- Container: 一个Container包含多个WebService
- WebService: 一个WebService包含多条route
- Route: 一条route包含一个method(GET、POST、DELETE,WATCHLIST等),一条具体的path以及一个响应的handler
ws := new(restful.WebService)
ws.Path("/users").
Consumes(restful.MIME_XML, restful.MIME_JSON).
Produces(restful.MIME_JSON, restful.MIME_XML)
ws.Route(ws.GET("/{user-id}").To(u.findUser).
Doc("get a user").
Param(ws.PathParameter("user-id", "identifier of the user").DataType("string")).
Writes(User{}))
...
func (u UserResource) findUser(request *restful.Request, response *restful.Response) {
id := request.PathParameter("user-id")
...
}
存储层
位于 k8s.io/apiserver/pkg/storage 下
// k8s.io/apiserver/pkg/storage/interface.go
type Interface interface {
Versioner() Versioner
Create(ctx context.Context, key string, obj, out runtime.Object, ttl uint64) error
Delete(ctx context.Context, key string, out runtime.Object, preconditions *Preconditions) error
Watch(ctx context.Context, key string, resourceVersion string, p SelectionPredicate) (watch.Interface, error)
Get(ctx context.Context, key string, resourceVersion string, objPtr runtime.Object, ignoreNotFound bool) error
List(ctx context.Context, key string, resourceVersion string, p SelectionPredicate, listObj runtime.Object) error
...
}
封装了对etcd 的操作,还提供了一个cache 以减少对etcd 的访问压力。在Storage这一层,并不能感知到k8s资源对象之类的内容,纯粹的存储逻辑。
K8s 如何提供更高效稳定的编排能力?K8s Watch 实现机制浅析
K8s apiserver watch 机制浅析为了减轻etcd的压力,kube-apiserver本身对etcd实现了list-watch机制,将所有对象的最新状态和最近的事件存放到cacher里,所有外部组件对资源的访问都经过cacher。
type Cacher struct {
incoming chan watchCacheEvent // incoming 事件管道, 会被分发给所有的watchers
storage storage.Interface //storage 的底层实现
objectType reflect.Type // 对象类型
watchCache *watchCache // watchCache 滑动窗口,维护了当前kind的所有的资源,和一个基于滑动窗口的最近的事件数组
reflector *cache.Reflector // reflector list并watch etcd 并将事件和资源存到watchCache中
watchersBuffer []*cacheWatcher // watchersBuffer 代表着所有client-go客户端跟apiserver的连接
....
}
registry 层
实现各种资源对象的存储逻辑
kubernetes/pkg/registry负责k8s内置的资源对象存储逻辑实现k8s.io/apiextensions-apiserver/pkg/registry负责crd和cr资源对象存储逻辑实现
k8s.io/apiserver/pkg/registry
/generic
/regisry
/store.go // 对storage 层封装,定义 Store struct
k8s.io/kubernetes/pkg/registry/core
/pod
/storage
/storage.go // 定义了 PodStorage struct,使用了Store struct
/service
/node
/rest
/storage_core.go
registry这一层比较分散,k8s在不同的目录下按照k8s的api组的管理方式完成各自资源对象存储逻辑的编写,主要就是定义各自的结构体,然后和Store结构体进行一次组合。
type PodStorage struct {
Pod *REST
Log *podrest.LogREST
Exec *podrest.ExecREST
...
}
type REST struct {
*genericregistry.Store
proxyTransport http.RoundTripper
}
func (c LegacyRESTStorageProvider) NewLegacyRESTStorage(restOptionsGetter generic.RESTOptionsGetter) (LegacyRESTStorage, genericapiserver.APIGroupInfo, error) {
...
// 关联路径 与各资源对象的关系
restStorageMap := map[string]rest.Storage{
"pods": podStorage.Pod,
"pods/attach": podStorage.Attach,
"pods/status": podStorage.Status,
"pods/log": podStorage.Log,
"pods/exec": podStorage.Exec,
"pods/portforward": podStorage.PortForward,
"pods/proxy": podStorage.Proxy,
"pods/binding": podStorage.Binding,
"bindings": podStorage.LegacyBinding,
}
}
endpoint 层
位于 k8s.io/apiserver/pkg/endpoints 包下。根据Registry层返回的路径与存储逻辑的关联关系,完成服务器上路由的注册 <path,handler> ==> route ==> webservice。
// k8s.io/apiserver/pkg/endpoints/installer.go
type APIInstaller struct {
group *APIGroupVersion
prefix string // Path prefix where API resources are to be registered.
minRequestTimeout time.Duration
}
// 一个Resource 下的 所有处理函数 都注册到 restful.WebService 中了
func (a *APIInstaller) registerResourceHandlers(path string, storage rest.Storage, ws *restful.WebService) (*metav1.APIResource, error) {
// 遍历所有操作,完成路由注册
for _, action := range actions {
...
switch action.Verb {
case "GET": // Get a resource.
handler = restfulGetResource(getter, exporter, reqScope)
...
route := ws.GET(action.Path).To(handler).
Doc(doc).
Param(ws.QueryParameter("pretty", "If 'true', then the output is pretty printed.")).
Returns(http.StatusOK, "OK", producedObject).
Writes(producedObject)
...
routes = append(routes, route)
case ...
}
...
for _, route := range routes {
...
ws.Route(route)
}
}
}
func restfulGetResource(r rest.Getter, e rest.Exporter, scope handlers.RequestScope) restful.RouteFunction {
return func(req *restful.Request, res *restful.Response) {
handlers.GetResource(r, e, &scope)(res.ResponseWriter, req.Request)
}
}
func (a *APIInstaller) Install() ([]metav1.APIResource, *restful.WebService, []error) {
ws := a.newWebService()
...
for _, path := range paths {
apiResource, err := a.registerResourceHandlers(path, a.group.Storage[path], ws)
apiResources = append(apiResources, *apiResource)
}
return apiResources, ws, errors
}
type APIGroupVersion struct {
Storage map[string]rest.Storage // 对应上文的restStorageMap
Root string
}
// 一个APIGroupVersion 下的所有Resource处理函数 都注册到 restful.Container 中了
func (g *APIGroupVersion) InstallREST(container *restful.Container) error {
prefix := path.Join(g.Root, g.GroupVersion.Group, g.GroupVersion.Version)
installer := &APIInstaller{
group: g,
prefix: prefix,
minRequestTimeout: g.MinRequestTimeout,
}
apiResources, ws, registrationErrors := installer.Install()
...
container.Add(ws)
return utilerrors.NewAggregate(registrationErrors)
}
同时在Endpoints还应该负责路径级别的操作:比如:到指定类型的认证授权,路径的调用统计,路径上的操作审计等。这部分内容通常在endpoints模块下的fileters内实现,这就是一层在http.Handler外做了一层装饰器,便于对请求进行拦截处理。
server 层
Server模块对外提供服务器能力。主要包括调用调用Endpoints中APIInstaller完成路由注册,同时为apiserver的扩展做好服务器层面的支撑(主要是APIService这种形式扩展)
// 注册所有 apiGroupVersion 的处理函数 到restful.Container 中
func (s *GenericAPIServer) installAPIResources(apiPrefix string, apiGroupInfo *APIGroupInfo, openAPIModels openapiproto.Models) error {
for _, groupVersion := range apiGroupInfo.PrioritizedVersions {
apiGroupVersion := s.getAPIGroupVersion(apiGroupInfo, groupVersion, apiPrefix)
if err := apiGroupVersion.InstallREST(s.Handler.GoRestfulContainer); err != nil {
...
}
}
return nil
}
除了路由注册到服务器的核心内容外,server模块还提供了如下内容:
- 路由层级的日志记录(在httplog模块)
- 健康检查的路由(healthz模块)
- 服务器级别的过滤器(filters模块),如,cors,请求数,压缩,超时等过滤器,
- server级别的路由(routes模块),如监控,swagger,openapi,监控等。
Kubernetes APIServer 机制概述apiserver通过Chain的方式,或者叫Delegation的方式,实现了APIServer的扩展机制,KubeAPIServer是主APIServer,这里面包含了Kubernetes的所有内置的核心API对象,APIExtensions其实就是我们常说的CRD扩展,这里面包含了所有自定义的CRD,而Aggretgator则是另外一种高级扩展机制,可以扩展外部的APIServer,三者通过 Aggregator –> KubeAPIServer –> APIExtensions 这样的方式顺序串联起来,当API对象在Aggregator中找不到时,会去KubeAPIServer中找,再找不到则会去APIExtensions中找,这就是所谓的delegation,通过这样的方式,实现了APIServer的扩展功能。
拦截api请求
- Admission Controller
- Initializers
- webhooks, If you’re not planning to modify the object and intercepting just to read the object, webhooks might be a faster and leaner alternative to get notified about the objects. Make sure to check out this example of a webhook-based admission controller.
Initializers
How Kubernetes Initializers work
Initializers are not part of Kubernetes source tree, or compiled into it; you need to write a controller yourself.
When you intercept Kubernetes objects before they are created, the possibilities are endless: You can mutate the objects in any way you like, or prevent the objects from being created.Here are some ideas for initializers, each enforce a particular policy in your cluster:
- Inject a proxy sidecar container to the pod if it has port 80, or has a particular annotation.
- Inject a volume with test certificates to all pods in the test namespace automatically.
- If a Secret is shorter than 20 characters (probably a password), prevent its creation.
Anatomy of Initialization
- Configure which resource types need initialization
- API server will assign initializers to the new resources
- You will write a controller to watch for the resources
- Wait for your turn to modify the resource
- Finish modifying, yield to the next initializer
- No more initializers, resource ready to be realized. When Kubernetes API server sees that the object has no more pending initializers, it considers the object “initialized”. Now the Kubernetes scheduler and other controllers can see the fully initialized object and make use of them.
从中可以看到,为啥Admission Controller 干活要改源码,Initializers 不用呢? 因为干活要改源码,Initializer 只是给待处理资源加上了标记metadata.initalizers.pending=InitializerName,需要相应的Controller 打辅助。
etcd: Kubernetes’ brain
Every component in Kubernetes (the API server, the scheduler, the kubelet, the controller manager, whatever) is stateless. All of the state is stored in a key-value store called etcd, and communication between components often happens via etcd.
For example! Let’s say you want to run a container on Machine X. You do not ask the kubelet on that Machine X to run a container. That is not the Kubernetes way! Instead, this happens:
- you write into etcd, “This pod should run on Machine X”. (technically you never write to etcd directly, you do that through the API server, but we’ll get there later)
- the kublet on Machine X looks at etcd and thinks, “omg!! it says that pod should be running and I’m not running it! I will start right now!!”
When I understood that basically everything in Kubernetes works by watching etcd for stuff it has to do, doing it, and then writing the new state back into etcd, Kubernetes made a lot more sense to me.
Reasons Kubernetes is coolBecause all the components don’t keep any state in memory(stateless), you can just restart them at any time and that can help mitigate a variety of bugs.The only stateful thing you have to operate is etcd
k8s 在 etcd中的存在
/registry/minions
/registry/minions/192.168.56.102 # 列出该节点的信息,包括其cpu和memory能力
/registry/minions/192.168.56.103
/registry/controllers
/registry/controllers/default
/registry/controllers/default/apache2-controller # 跟创建该controller时信息大致相同,分为desireState和currentState
/registry/controllers/default/heapster-controller
/registry/pods
/registry/pods/default
/registry/pods/default/128e1719-c726-11e4-91cd-08002782f91d # 跟创建该pod时信息大致相同,分为desireState和currentState
/registry/pods/default/128e7391-c726-11e4-91cd-08002782f91d
/registry/pods/default/f111c8f7-c726-11e4-91cd-08002782f91d
/registry/nodes
/registry/nodes/192.168.56.102
/registry/nodes/192.168.56.102/boundpods # 列出在该主机上运行pod的信息,镜像名,可以使用的环境变量之类,这个可能随着pod的迁移而改变
/registry/nodes/192.168.56.103
/registry/nodes/192.168.56.103/boundpods
/registry/events
/registry/events/default
/registry/events/default/704d54bf-c707-11e4-91cd-08002782f91d.13ca18d9af8857a8 # 记录操作,比如将某个pod部署到了某个node上
/registry/events/default/f1ff6226-c6db-11e4-91cd-08002782f91d.13ca07dc57711845
/registry/services
/registry/services/specs
/registry/services/specs/default
/registry/services/specs/default/monitoring-grafana # 基本跟创建信息大致一致,但包含serviceip
/registry/services/specs/default/kubernetes
/registry/services/specs/default/kubernetes-ro
/registry/services/specs/default/monitoring-influxdb
/registry/services/endpoints
/registry/services/endpoints/default
/registry/services/endpoints/default/monitoring-grafana # 终端(traffic在这里被处理),和某一个serviceId相同,包含了service对应的几个pod的ip,这个可能经常变。
/registry/services/endpoints/default/kubernetes
/registry/services/endpoints/default/kubernetes-ro
/registry/services/endpoints/default/monitoring-influxdb
扩展apiserver
The aggregation layer runs in-process with the kube-apiserver. Until an extension resource is registered, the aggregation layer will do nothing. To register an API, you add an APIService object, which “claims” the URL path in the Kubernetes API. At that point, the aggregation layer will proxy anything sent to that API path (e.g. /apis/myextension.mycompany.io/v1/…) to the registered APIService. 聚合层在 kube-apiserver 进程内运行。在扩展资源注册之前,聚合层不做任何事情。 要注册 API,用户必须添加一个 APIService 对象,用它来“申领” Kubernetes API 中的 URL 路径。 自此以后,聚合层将会把发给该 API 路径的所有内容转发到已注册的 APIService。 Aggregated APIServer 构建云原生应用最佳实践
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:
name: v1alpha1.wardle.k8s.io
spec:
insecureSkipTLSVerify: true
group: wardle.k8s.io
groupPriorityMinimum: 1000
versionPriority: 15
service:
name: api
namespace: wardle
version: v1alpha1
上述配置 会让 apiserver 收到 v1alpha1.wardle.k8s.io 请求时 转给 namespace=wardle 下名为 api 的服务。PS:估计是
http://apiserver/apis/v1alpha1.wardle.k8s.io/v1alpha1/abc 转给 http://serviceIp:servicePort/abc
性能优化
大规模部署时潜在的问题,对于 ` podList, err := Client().CoreV1().Pods(“”).List(ctx(), ListOptions{FieldSelector: “spec.nodeName=node1”})`,以一个 4000 node,10w pod 的集群为例,全量 pod 数据量:
- etcd 中:紧凑的非结构化 KV 存储,在 1GB 量级;
- apiserver 缓存中:已经是结构化的 golang objects,在 2GB 量级( TODO:需进一步确认);
- apiserver 返回:client 一般选择默认的 json 格式接收, 也已经是结构化数据。全量 pod 的 json 也在 2GB 量级。 可以看到,某些请求看起来很简单,只是客户端一行代码的事情,但背后的数据量是惊人的。指定按 nodeName 过滤 pod 可能只返回了 500KB 数据,但 apiserver 却需要过滤 2GB 数据 —— 最坏的情况,etcd 也要跟着处理 1GB 数据。
字节跳动 kube-apiserver 高可用方案 KubeGateway 很好玩的一个项目。
字节跳动高性能 Kubernetes 元信息存储方案探索与实践
K8s 集群稳定性:LIST 请求源码分析、性能评估与大规模基础服务部署调优
- 对于 Ceph 对象存储来说,每个 LIST bucket 请求都需要去多个磁盘中捞出这个 bucket 的全部数据;不仅自身很慢,还影响了同一时间段内的其他普通读写请求,因为 IO 是共享的,导致响应延迟上升乃至超时。如果 bucket 内的对象非常多(例如用作 harbor/docker-registry 的存储后端),LIST 操作甚至都无法在常规时间内完成( 因而依赖 LIST bucket 操作的 registry GC 也就跑不起来)。
- 相比于 Ceph,一个实际 etcd 集群存储的数据量可能很小(几个 ~ 几十个 GB),甚至足够缓存到内存中。但与 Ceph 不同的是,它的并发请求数量可能会高 几个量级,比如它是一个 ~4000 nodes 的 k8s 集群的 etcd。单个 LIST 请求可能只需要 返回几十 MB 到上 GB 的流量,但并发请求一多,etcd 显然也扛不住,所以最好在前面有 一层缓存,这就是 apiserver 的功能(之一)。K8s 的 LIST 请求大部分都应该被 apiserver 挡住,从它的本地缓存提供服务,但如果使用不当,就会跳过缓存直接到达 etcd,有很大的稳定性风险。
留下评论