go channel
前言
Go 对并发的原生支持可不是仅仅停留在口号上的,Go 在语法层面将并发原语 channel 作为一等公民对待。这意味着我们可以像使用普通变量那样使用 channel,比如,定义 channel 类型变量、给 channel 变量赋值、将 channel 作为参数传递给函数 / 方法、将 channel 作为返回值从函数 / 方法中返回,甚至将 channel 发送到其他 channel 中。这就大大简化了 channel 原语的使用,提升了我们开发者在做并发设计和实现时的体验。
通信原语Go 语言中 Channel 与 Select 语句受到 1978 年 CSP 原始理论的启发。 语言设计中,Goroutine 就是 CSP 理论中的并发实体, 而 Channel 则对应 CSP 中输入输出指令的消息信道,Select 语句则是 CSP 中守卫和选择指令的组合。Channel 与 Select 是 Go 语言中提供的语言级的、基于消息传递的同步原语。
channel
channel是一个单向的、大小有限的管道,在goroutine之间传输类型化的信息。Go还提供了一个多路选择原语select,可以根据某channel上的通信是否可进行来控制执行。Go有提供互斥、条件变量、信号量和原子操作的库,供低级别互斥或同步使用,但channel往往是更好的选择。根据我们的经验,人们对消息传递–利用通信在goroutine之间转移所有权–的理解比对互斥和条件变量的理解更容易、更正确。早期流行的一句Go箴言是:”不要通过共享内存来通信,而是通过通信来共享内存”。
和切片、结构体、map 等一样,channel 也是一种复合数据类型。也就是说,我们在声明一个 channel 类型变量时,必须给出其具体的元素类型,比如var ch chan int。 使用操作符<-,我们还可以声明只发送 channel 类型(send-only)和只接收 channel 类型(recv-only)
使用操作符<-,我们还可以声明只发送 channel 类型(send-only)和只接收 channel 类型(recv-only)
ch1 := make(chan<- int, 1) // 只发送channel类型
ch2 := make(<-chan int, 1) // 只接收channel类型
<-ch1 // invalid operation: <-ch1 (receive from send-only type chan<- int)
ch2 <- 13 // invalid operation: ch2 <- 13 (send to receive-only type <-chan int)
数据结构
Go 语言设计与实现-ChannelChannel 在运行时的内部表示是 runtime.hchan,本质上就是一个 mutex 锁加上一个环状缓存、 一个发送方队列和一个接收方队列。社区有一些无锁Channel 的提案,但还在不停的优化中。PS:本质上是有锁队列,还是共享内存
// src/runtime/chan.go
type hchan struct {
qcount uint // Channel 中的元素个数;
dataqsiz uint // Channel 中的循环队列的长度;
buf unsafe.Pointer // Channel 的缓冲区数据指针;指向大小为 dataqsiz 的数组
elemsize uint16 // 当前 Channel 能够收发的元素大小
closed uint32
elemtype *_type // 当前 Channel 能够收发的元素类型
sendx uint // Channel 的发送操作处理到的位置;
recvx uint // Channel 的接收操作处理到的位置;
// 就像linux socket的 等待队列一样,方便根据channel找到goroutine
recvq waitq // recv 等待列表,即( <-ch )
sendq waitq // send 等待列表,即( ch<- )
lock mutex
}
type waitq struct { // 等待队列 sudog 双向队列
first *sudog
last *sudog
}
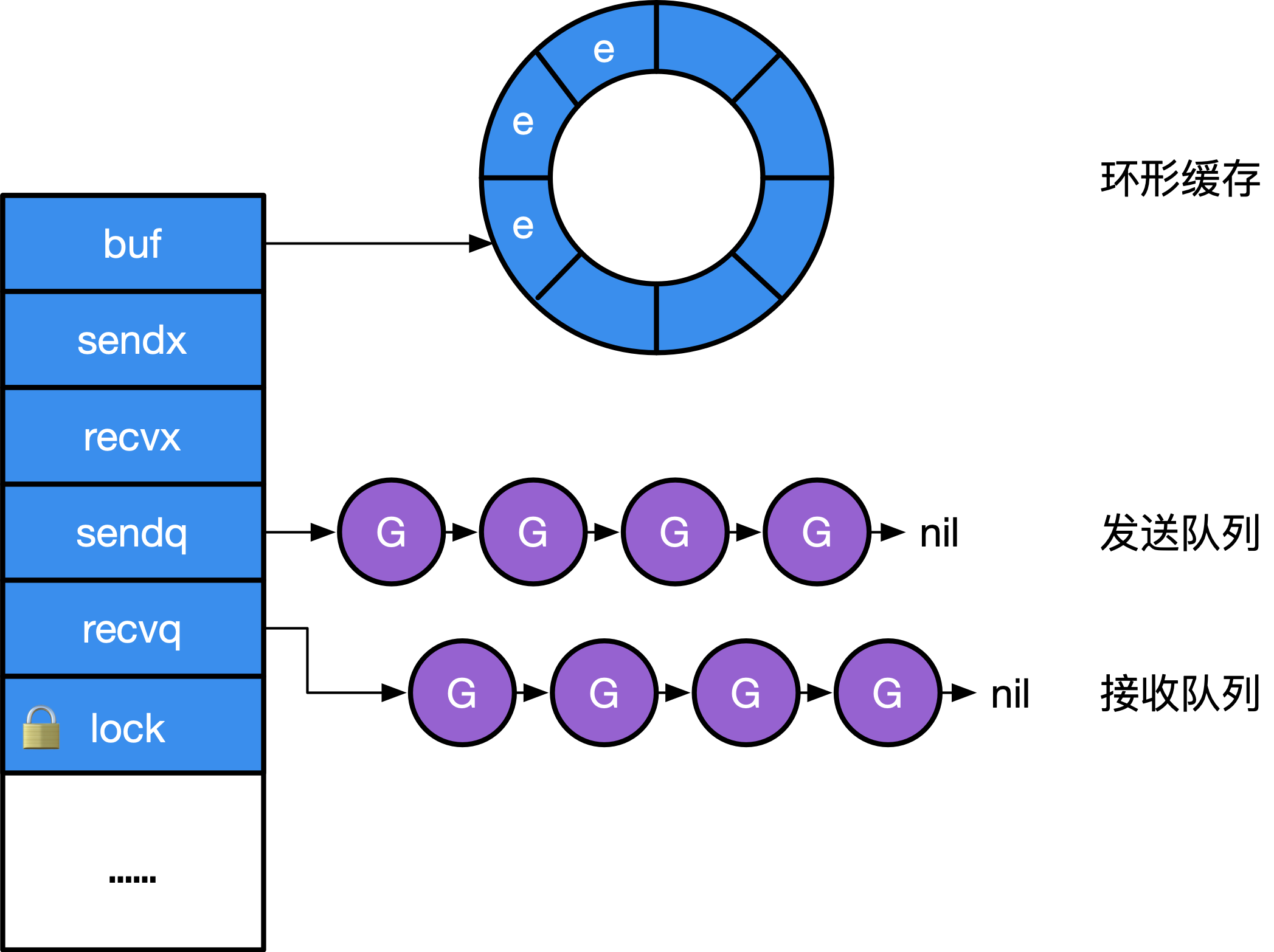
make(chan type, n) => makechan(type, n),makechan 实现的本质是根据需要创建的元素大小, 对 mallocgc 进行封装,因此,Channel 总是在堆上进行分配,它们会被垃圾回收器进行回收, 这也是为什么 Channel 不一定总是需要调用 close(ch) 进行显式地关闭。
发送数据
当我们想要向 Channel 发送数据时,就需要使用 ch <- i 语句,编译器会经过一系列处理后调用runtime.chansend,这个函数负责了发送数据的全部逻辑,如果我们在调用时将 block 参数设置成 true,那么就表示当前发送操作是一个阻塞操作
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
// 异常检查,如GC检查等
...
lock(&c.lock) // 为当前 Channel 加锁,保证线程安全
// 如果 Channel 已经关闭,那么向该 Channel 发送数据时会抛出panic
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("send on closed channel"))
}
// 如果目标 Channel 没有被关闭并且已经有处于读等待的 Goroutine,那么 runtime.chansend 函数会从接收队列 recvq 中取出最先陷入等待的 Goroutine 并直接向它发送数据
if sg := c.recvq.dequeue(); sg != nil {
send(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true
}
// 如果创建的 Channel 包含缓冲区并且 Channel 中的数据没有装满,将发送的数据写入 Channel 的缓冲区;
if c.qcount < c.dataqsiz {
qp := chanbuf(c, c.sendx)
typedmemmove(c.elemtype, qp, ep)
c.sendx++
if c.sendx == c.dataqsiz {
c.sendx = 0
}
c.qcount++
unlock(&c.lock)
return true
}
// 当 Channel 没有接收者能够处理数据时,向 Channel 发送数据就会被下游阻塞
if !block {
unlock(&c.lock)
return false
}
// 阻塞在 channel 上,等待接收方接收数据
gp := getg()
mysg := acquireSudog()
mysg.elem = ep
mysg.g = gp
mysg.c = c
gp.waiting = mysg
c.sendq.enqueue(mysg)
goparkunlock(&c.lock, waitReasonChanSend, traceEvGoBlockSend, 3) // 触发 Goroutine 让出处理器的使用权
// 因为调度器在停止当前 g 的时候会记录运行现场,当恢复阻塞的发送操作时候,会从此处继续开始执行
gp.waiting = nil
gp.param = nil
mysg.c = nil
releaseSudog(mysg)
return true
}
发送数据时会调用 runtime.send,该函数的执行可以分成两个部分:
- 调用
runtime.sendDirect函数将发送的数据直接拷贝到x = <-c表达式中变量 x 所在的内存地址上;其实是一种优化,原因在于,已经处于等待状态的 Goroutine 是没有被执行的, 因此用户态代码不会与当前所发生数据发生任何竞争。我们也更没有必要冗余的将数据写入到缓存, 再让接收方从缓存中进行读取。因此我们可以看到, sendDirect 的调用, 本质上是将数据直接写入接收方的执行栈。 - 调用
runtime.goready将等待接收数据的 Goroutine 标记成可运行状态 Grunnable 并把该 Goroutine 放到发送方所在的处理器的 runnext 上等待执行,该处理器在下一次调度时就会立刻唤醒数据的接收方;
接收数据
i <- ch // 当ch被关闭后,n将被赋值为ch元素类型的零值, 无法判定从 ch 返回的元素类型零值,究竟是不是因为 channel 被关闭后才返回的。
i, ok <- ch // 当ch被关闭后,m将被赋值为ch元素类型的零值, ok值为false
for v := range ch { ... ...} // 当ch被关闭后,for range循环结束
不同的接收方式会被转换成 runtime.chanrecv1 和 runtime.chanrecv2 两种不同函数的调用,但是这两个函数最终还是会调用 runtime.chanrecv。
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
// 当我们从一个空 Channel 接收数据时会直接调用 runtime.gopark 直接让出处理器的使用权
if c == nil {
if !block {
return
}
gopark(nil, nil, waitReasonChanReceiveNilChan, traceEvGoStop, 2)
throw("unreachable")
}
lock(&c.lock)
// 如果当前 Channel 已经被关闭并且缓冲区中不存在任何的数据,那么就会清除 ep 指针中的数据并立刻返回。
if c.closed != 0 && c.qcount == 0 {
unlock(&c.lock)
if ep != nil {
typedmemclr(c.elemtype, ep)
}
return true, false
}
// 当存在等待的发送者时,通过 runtime.recv 直接从阻塞的发送者或者缓冲区中获取数据;
if sg := c.sendq.dequeue(); sg != nil {
recv(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true, true
}
// 当Channel 的缓冲区中已经包含数据时,从 Channel 中接收数据会直接从缓冲区中 recvx 的索引位置中取出数据进行处理
if c.qcount > 0 {
qp := chanbuf(c, c.recvx)
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
typedmemclr(c.elemtype, qp)
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
c.qcount--
return true, true
}
// 当 Channel 的发送队列中不存在等待的 Goroutine 并且缓冲区中也不存在任何数据时,从管道中接收数据的操作会变成阻塞操作,然而不是所有的接收操作都是阻塞的,与 select 语句结合使用时就可能会使用到非阻塞的接收操作
if !block {
unlock(&c.lock)
return false, false
}
// 没有数据可以接收,阻塞当前 Goroutine
gp := getg()
mysg := acquireSudog()
mysg.elem = ep
gp.waiting = mysg
mysg.g = gp
mysg.c = c
c.recvq.enqueue(mysg)
goparkunlock(&c.lock, waitReasonChanReceive, traceEvGoBlockRecv, 3)
// 被唤醒
gp.waiting = nil
closed := gp.param == nil
gp.param = nil
releaseSudog(mysg)
return true, !closed
}
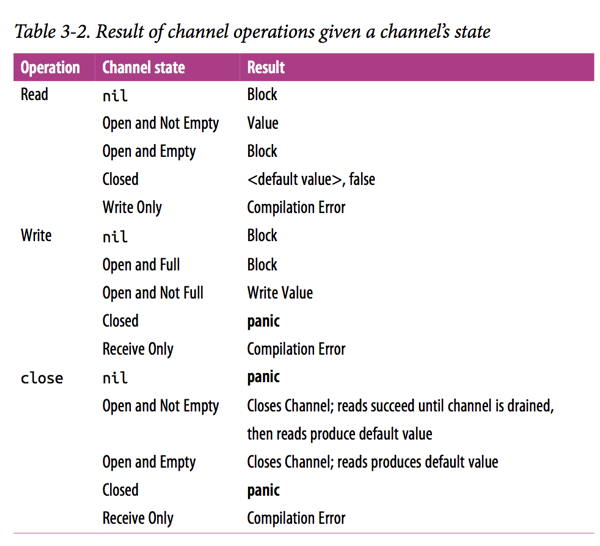
关闭
- 关闭未初始化的channel(nil channel)会panic
- 重复关闭同一channel会panic
- 向已关闭channel发送消息会panic
- 从已关闭channel读取数据,不会panic
- 若还存在数据,会读出未被读取的消息
- 若无数据,会读出对应数据类型的零值
- 关闭channel时,所有阻塞在此channel上的接收者,都会立刻从阻塞等待中返回,可以利用此特性,实现广播机制。
- channel也可以使用for-range取值,并且会一直从channel中读取数据,因此不主动break/goto/return的情况下,for循环结束的唯一条件是channel被关闭
编译器会将用于关闭管道的 close 关键字转换成 OCLOSE 节点以及 runtime.closechan 的函数调用。该函数在最后会为所有被阻塞的 Goroutine 调用 runtime.goready 触发调度。PS:所以close 也成了一种 通知的方式。
select
当涉及同时对多个 channel 进行发送 / 接收操作时, Go 为 CSP 并发模型提供的另外一个原语 select一起使用。
func fibonacci(c, quit chan int) {
x, y := 0, 1
for {
select {
case c <- x:
x, y = y, x+y
case <-quit:
fmt.Println("quit")
return
default:
println("default")
break // select 中的break 只对select 有效,实际上根本无用,无法跳出for 循环
}
}
}
- select 是一种与 switch 相似的控制结构,与 switch 不同的是,select 中虽然也有多个 case,但是这些 case 中的表达式必须都是 Channel 的收发操作。
- 上述控制结构会等待
c <- x或者<-quit两个表达式中任意一个的返回。无论哪一个表达式返回都会立刻执行 case 中的代码,当 select 中的两个 case 同时被触发时,就会随机选择一个 case 执行。 - 非阻塞的 Channel :比如,我们只是想看看 Channel 的可读或者可写状态,不希望Channel收发阻塞当前 Goroutine。此时可以为select 添加default 分支,当某次循环 不存在可以收发的 Channel 时,会直接执行 default 中的代码并返回
- 实现超时机制
func worker() { select { case <-c: // ... do some stuff case <-time.After(30 *time.Second): return } } - 实现心跳
func worker() { heartbeat := time.NewTicker(30 * time.Second) defer heartbeat.Stop() for { select { case <-c: // ... do some stuff case <- heartbeat.C: //... do heartbeat stuff } } }
数据结构
type scase struct {
c *hchan // 正在操作的channel
elem unsafe.Pointer // data element
kind uint16
// ...
}
const (
caseNil = iota
caseRecv
caseSend
caseDefault
)
实现过程
面向信仰编程-selectC 语言中的 select 关键字可以同时监听多个文件描述符的可读或者可写的状态,Go 语言中的 select 关键字也能够让 Goroutine 同时等待多个 Channel 的可读或者可写,在多个文件或者 Channel 发生状态改变之前,select 会一直阻塞当前线程或者 Goroutine。
runtime 通过遍历+等待的方式实现 select 语义,遍历时判断如果 有可执行的 case 或者 select 中带有 default,那么就执行之。如果没有,就通过 gopark 将调用者转换为等待状态,使用 sudog 链表表示它在多个通道上等待。其中任意一个通道对应的 sudog 都可以唤醒调用者。
与 Channel 同步出现的 Select 更像是一个语法糖, 其本质仍然是一个 chansend 和 chanrecv 的两个通用实现。 但为了支持 Select 在不同分支上的非阻塞操作,selectgo 完成了这一需求。func selectgo(cas0 *scase, order0 *uint16, ncases int) (int, bool) 它的第一个返回值表示需要执行哪个 case, 第 2 个返回值表示如果要执行的 case 是 caseRecv,那么接收数据是否成功。
Select 本身会被编译为 selectgo 调用。这与普通的多个 if 分支不同。 selectgo 则用于随机化每条分支的执行顺序,普通多个 if 分支的执行顺序始终是一致的。编译器会特殊处理 当 Select 语句只有一个分支的情况,即 select 关键字在只有一个分支时,没有被翻译成 selectgo。 只有一个分支的情况下,select 与 if 是没有区别的,这种优化消除了只有一个分支情况下调用 selectgo 的性能开销。
func selectgo(cas0 *scase, order0 *uint16, ncases int) (int, bool){
...
// 先遍历一次所有的 case 和 default 语句,看一下是否有可执行的分支,如果有,那么就转移到对应的段去处理。否则就阻塞并且等待被唤醒。
loop:
for i := 0; i < ncases; i++ {
casi = int(pollorder[i]) // pollorder 是伪随机数
cas = &scases[casi]
switch cas.kind {
case caseNil:
case caseRecv:
case caseSend:
case caseDefault:
}
}
recv:
bufrecv:
rclose:
sclose:
send:
bufsend:
...
// 上面的流程都执行完了,并且没有default语句,还没有 goto 出去,说明没有任何 case 当前可以执行。那么就挂起并等待被唤醒。
// 按照锁顺序一次遍历每个 case,然后将其放到 g.waitlink 这个 sudog 链表中,表明是在等待多个 case , 并将当前g 挂到channel的 recvq/sendq中
gp = getg()
nextp = &gp.waiting
for _, casei := range lockorder {
cas = &scases[casi]
sg := acquireSudog()
sg.g = gp
switch cas.kind {
case caseRecv:
c.recvq.enqueue(sg)
case caseSend:
c.sendq.enqueue(sg)
}
}
gp.param = nil
gopark(selparkcommit, nil, waitReasonSelect, traceEvGoBlockSelect, 1)
...
// 说明被某个 channel 唤醒了
}
背景知识——sudog
在 g 对象中,有一个名字为 waiting 的 sudog* 指针,它表示这个 goroutine 正在等待什么东西或者正在等待哪些东西。sudog 是一个链表形式的类型,waitlink 表示它的下一个节点。
type g struct {
// ...
atomicstatus uint32 // 表示 goroutine 的状态
param unsafe.Pointer // 唤醒时参数
waiting *sudog // 等待队列,goroutine ready之前,会waiting做一些检查,waiting不为空是不能运行的。
// ...
}
// sudog is necessary because the g ↔ synchronization object relation is many-to-many.
type sudog struct {
// ....
isSelect bool
elem unsafe.Pointer // data element (may point to stack)
waitlink *sudog // g.waiting list or semaRoot
c *hchan // channel
g *g
}
// sudogs are allocated from a special pool. Use acquireSudog and releaseSudog to allocate and free them.
func acquireSudog() *sudog {}
func releaseSudog(s *sudog) {}
- gopark 将当前的 goroutine 修改成等待状态,然后等待被唤醒。
- goready 函数用来唤醒一个 goroutine,它将 goroutine 的状态修改为可运行状态,随后会被调度器运行。
- 当被调度时,对应的 gopark 函数返回。
应用
- channel 事先创建好
- 先启动 N 个 goroutine 消费者,读某个 channel,之后,生产者再在某个时候向 channel 中发送元素
- 传递信号,比如用 channel 充当一个 “ready” 的信号,用来指示某个“过程”准备好了,可以接收结果了
- 临时创建,就像java 中的future 一样Go channel 的妙用
空结构体类型变量的内存占用为 0。基于空结构体类型内存零开销这样的特性,我们在日常 Go 开发中会经常使用空结构体类型元素,作为一种“事件”信息进行 Goroutine 之间的通信
var c = make(chan struct{}) // 声明一个元素类型为Empty的channel
c<-struct{} // 向channel写入一个“事件”
带缓冲 channel 的惯用法
- 用作消息队列
- 用作计数信号量
使用无缓冲 channel 替代锁
这种并发设计逻辑更符合 Go 语言所倡导的“不要通过共享内存来通信,而是通过通信来共享内存”的原则。PS: 好像没有使用锁好懂
type counter struct {
c chan int
i int
}
func NewCounter() *counter {
cter := &counter{
c: make(chan int),
}
go func() { // 计数生产者
for {
cter.i++
cter.c <- cter.i
}
}()
return cter
}
func (cter *counter) Increase() int {
return <-cter.c
}
func main() {
cter := NewCounter()
var wg sync.WaitGroup
for i := 0; i < 10; i++ {
wg.Add(1)
go func(i int) {
v := cter.Increase()
fmt.Printf("goroutine-%d: current counter value is %d\n", i, v)
wg.Done()
}(i)
}
wg.Wait()
}
广播channel
channels在多个writer,一个reader的模型下面工作的很好,但是却不能很容易的处理多个reader等待获取一个writer发送的数据的情况。处理这样的情况,可能的一个go api原型如下:
type Broadcaster interface{
func NewBroadcaster() Broadcaster
func (b Broadcaster) Write(v interface{})
func (b Broadcaster) Listen() chan interface{}
}
broadcast channel通过NewBroadcaster创建,通过Write函数进行数据广播。为了监听这个channel的信息,我们使用Listen,该函数返回一个新的channel去接受Write发送的数据。这套解决方案需要一个中间process用来处理所有reader的注册。当调用Listen创建新的channel之后,该channel就被注册,通常该中间process的主循环如下:
for {
select {
case v := <-inc:
for _, c := range(listeners) {
c <- v
}
case c := <- registeryc:
listeners.push(c)
}
}
这是一个通常的做法,但是该process在处理数据广播的时候会阻塞,直到所有的readers读取到值。一个可选的解决方式就是reader的channel是有buffer缓冲的,缓冲大小我们可以按需调节。或者当buffer满的时候我们将数据丢弃。
SierraSoftworks/multicast 解决了这个问题,The multicast module provides single-writer, multiple-reader semantics around Go channels. It attempts to maintain semantics similar to those offered by standard Go channels while guaranteeing parallel delivery (slow consumers won’t hold up delivery to other listeners) and guaranteeing delivery to all registered listeners when a message is published.
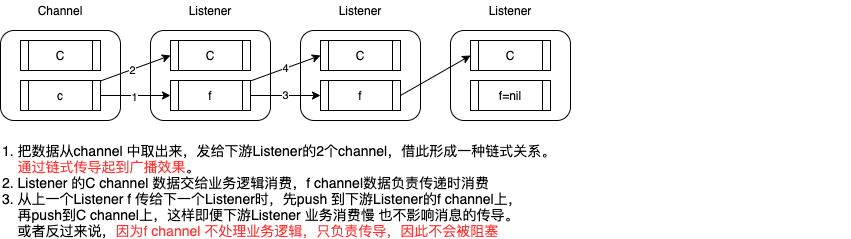
示例代码
import (
"fmt"
"github.com/SierraSoftworks/multicast"
)
func main() {
c := multicast.New()
go func() {
l := c.Listen()
for msg := range l.C {
fmt.Printf("Listener 1: %s\n", msg)
}
fmt.Println("Listener 1 Closed")
}()
go func() {
l := c.Listen()
for msg := range l.C {
fmt.Printf("Listener 2: %s\n", msg)
}
fmt.Println("Listener 2 Closed")
}()
// 据笔者实践,此处最好加上 time.Sleep(1000)
c.C <- "Hello World!"
c.Close()
}
留下评论