内存管理玩法汇总
简介
Demystifying memory management in modern programming languages是一个系列,建议细读。推荐极客时间教程《编程高手必学的内存知识》
过去25年中硬件发生了很大变化:内存延迟与处理器执行性能之间的冯诺依曼瓶颈增加了100-2000倍(也就是说,如果以CPU算术计算的速度为基准看,读内存的速度没有变快反而更慢了);
- 指针的间接获取对性能的影响变得更大,因为对指针的解引用是昂贵的操作,尤其是当指针或它指向的对象不在处理器的缓存中时(没办法,只能读内存了);
- java Valhalla引入的值类型,纯数据的聚合一类的对象,只有数据,没有标识。没有标识意味着不再有多态性、可变性,不能在对象上加锁,不能为Null,只能基于状态做对象比较,但优势是:不需要object header了,可以省去内存占用和分配的开销;可以在栈上直接分配值类型,而不必在堆上分配它们;
内存分配
内存分配一般有三种方式:静态存储区(根对象、静态变量、常量)、栈(函数中的临时局部变量)、堆(malloc、new等);
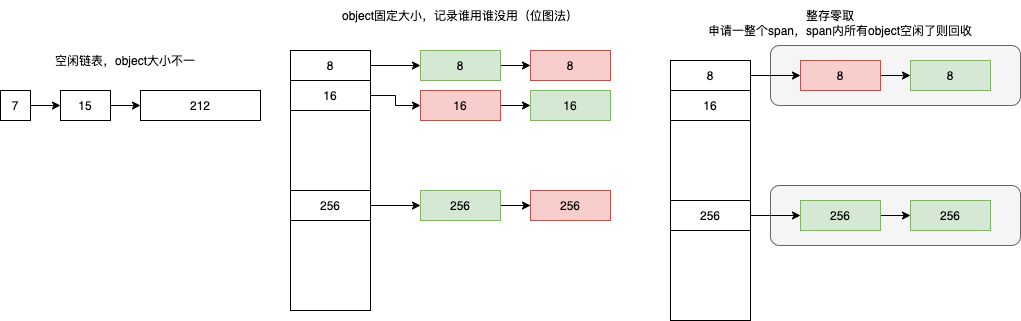
内存的分配和使用其是一个增加系统中熵的过程,内存分配器只包含线性内存分配器(Sequential Allocator)和空闲链表内存分配器(Free-list Allocator)两种,其它内存分配器其实都是上述两种不同分配器的变种。
- 线性内存分配器。“用到哪了标识到哪”,维护一个指向内存特定位置的指针,当用户程序申请内存时,分配器只需要检查剩余的空闲内存、返回分配的内存区域并修改指针在内存中的位置。
- 因为指针只有一个,因此无法把前面回收的部分进行再次分配,它只能继续往后分配。需要与拷贝方式的垃圾回收算法配合使用,比如标记压缩(Mark-Compact)、复制回收(Copying GC)和分代回收(Generational GC)等,所以 C 和 C++ 等需要直接对外暴露指针的语言就无法使用该策略。
- 空闲链表内存分配器。将内存按照块的结构来进行划分,维护一个类似链表的数据结构。当用户程序申请内存时,空闲链表分配器会依次遍历空闲的内存块,找到足够大的内存,然后申请新的资源并修改链表。因为分配内存时需要遍历链表,所以它的时间复杂度就是 O(n),为了提高效率,将内存分割成多个链表,每个链表中的内存块大小相同(不同链表不同),申请内存时先找到满足条件的链表,再从链表中选择合适的内存块,减少了需要遍历的内存块数量。
内存回收/gc
GC 和内存分配方式是强相关的两个技术。
独立成文。
整体描述
内存管理设计精要虽然多数系统都会将内存管理拆分成多个复杂的模块并引入一些中间层提供缓存和转换的功能,但是内存管理系统实际上都可以简化成两个模块,即内存分配器(Allocator)、垃圾收集器(Collector)。在研究内存管理时都会引入第三个模块 — 用户程序(Mutator/App)
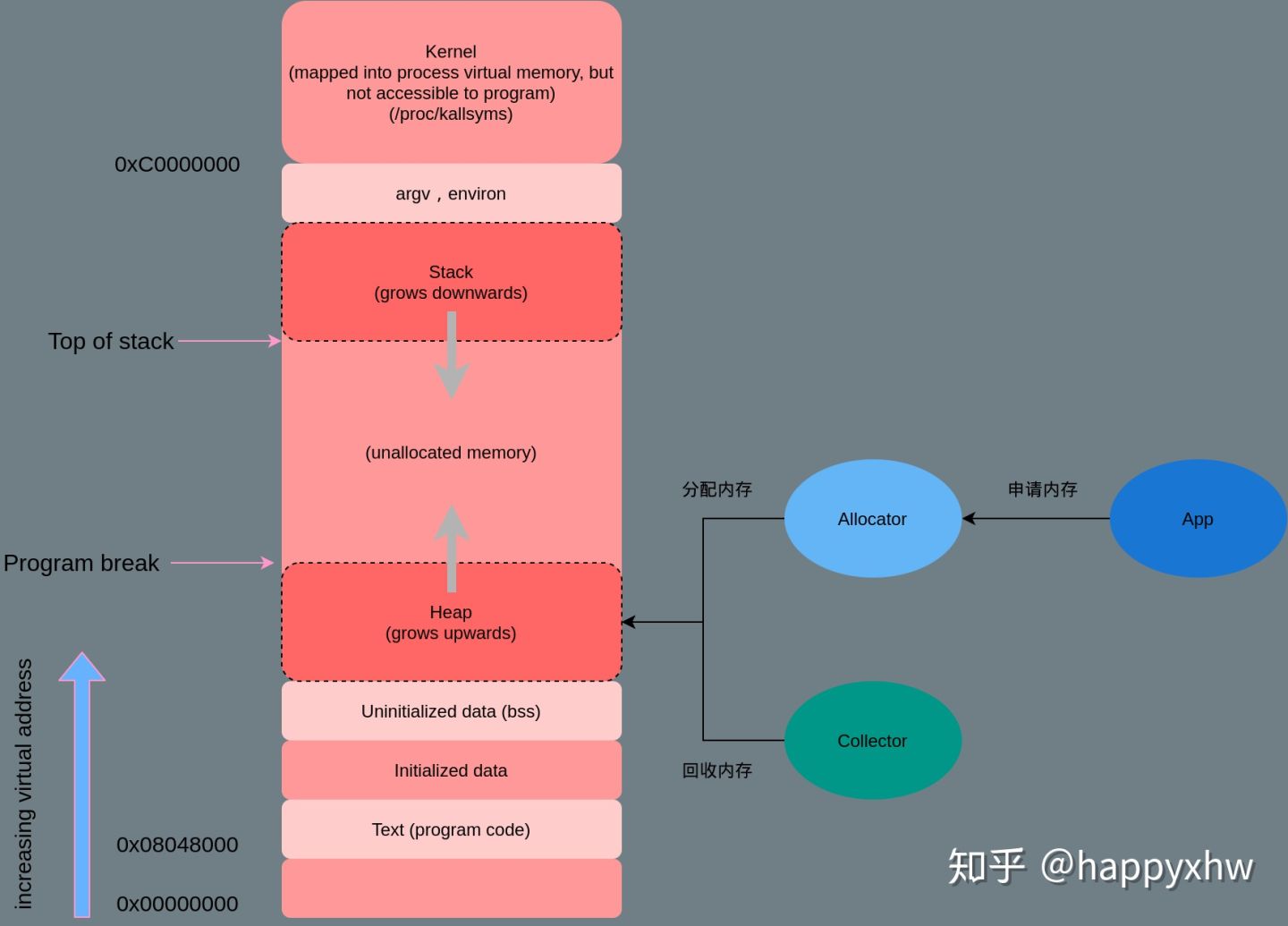
一个优秀的通用内存分配器应具有以下特性:
- 额外的空间损耗尽量少
- 分配速度尽可能快
- 尽量避免内存碎片
- 缓存本地化友好。每个线程有自己的栈,每个线程有自己的堆缓存(减少对全局堆内存管理结构的争用)
- 通用性,兼容性,可移植性,易调试
我们可以将内存管理简单地分成手动管理和自动管理两种方式,手动管理内存一般是指由工程师在需要时通过 malloc 等函数手动申请内存并在不需要时调用 free 等函数释放内存;自动管理内存由编程语言的内存管理系统自动管理,在编程语言的编译期或者运行时中引入,最常见的自动内存管理机制就是垃圾回收,一些编程语言也会使用自动引用计数辅助内存的管理,自动内存管理会带来额外开销并影响语言的运行时性能。
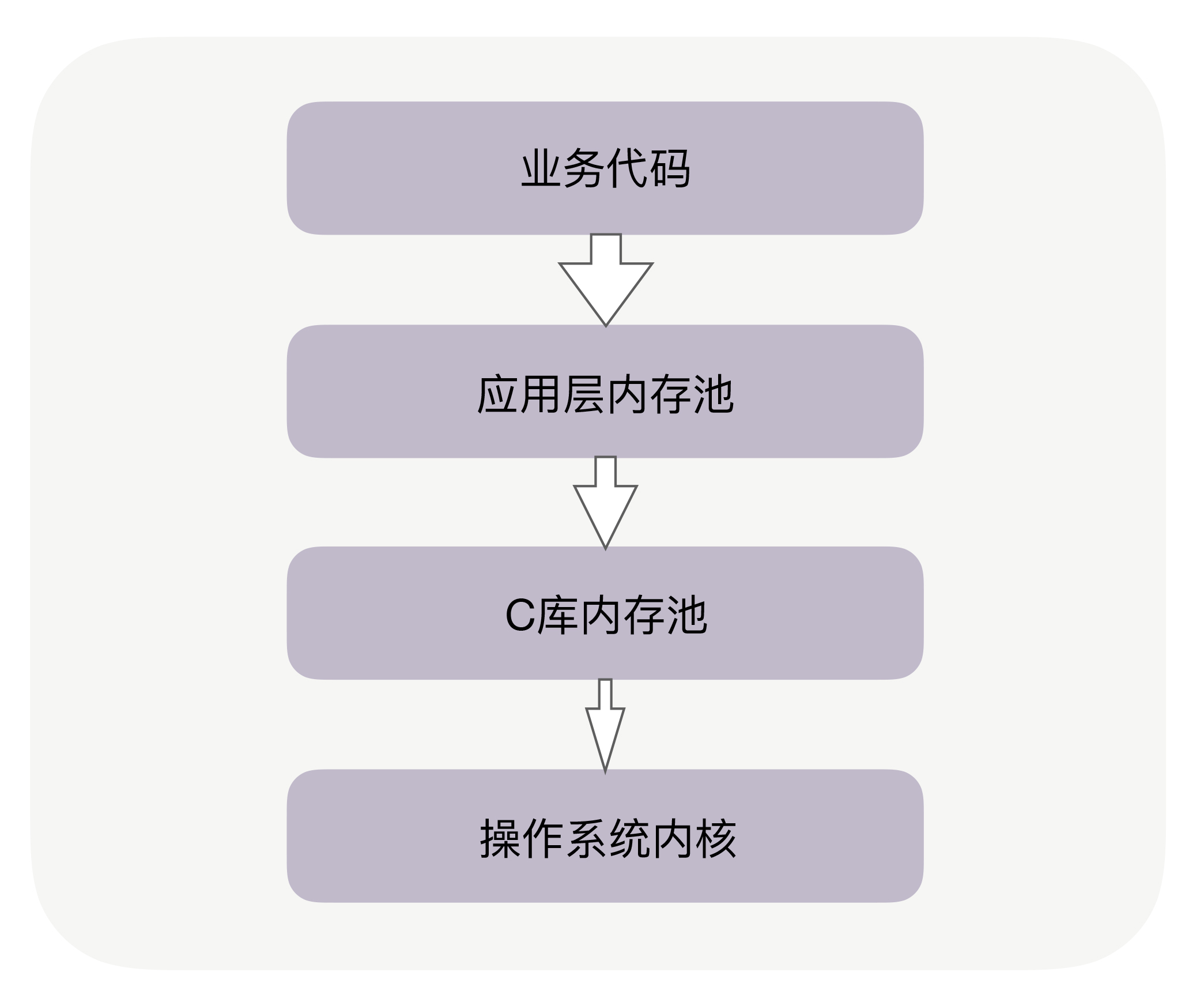
内存管理可以分为三个层次,自底向上分别是:
- 操作系统内核的内存管理
- glibc层使用系统调用维护的内存管理算法。glibc/ptmalloc2,google/tcmalloc,facebook/jemalloc。C 库内存池工作时,会预分配比你申请的字节数更大的空间作为内存池。比如说,当主进程下申请 1 字节的内存时,Ptmalloc2 会预分配 132K 字节的内存(Ptmalloc2 中叫 Main Arena),应用代码再申请内存时,会从这已经申请到的 132KB 中继续分配。当我们释放这 1 字节时,Ptmalloc2 也不会把内存归还给操作系统。
- 应用程序从glibc动态分配内存后,根据应用程序本身的程序特性进行优化, 比如netty的arena
进程/线程与内存:Linux 下的 JVM 编译时默认使用了 Ptmalloc2 内存池,64 位的 Linux 为每个线程的栈分配了 8MB 的内存,还(为每个线程?)预分配了 64MB 的内存作为堆内存池。在多数情况下,这些预分配出来的内存池,可以提升后续内存分配的性能。但也导致创建很多线程时会占用大量内存。
栈空间由编译器 + os管理。如果堆上有足够的空间的满足我们代码的内存申请,内存分配器可以完成内存申请无需内核参与,否则将通过操作系统调用(brk)进行扩展堆,通常是申请一大块内存。(对于 malloc 大默认指的是大于 MMAP_THRESHOLD 个字节 - 128KB)。但是,内存分配器除了更新 brk address 还有其他职责。其中主要的一项就是如何减少 内部(internal)和外部(external)碎片和如何快速分配当前块。我们该如何减少内存碎片化呢 ?答案取决是使用哪种内存分配算法,也就是使用哪个底层库。
操作系统
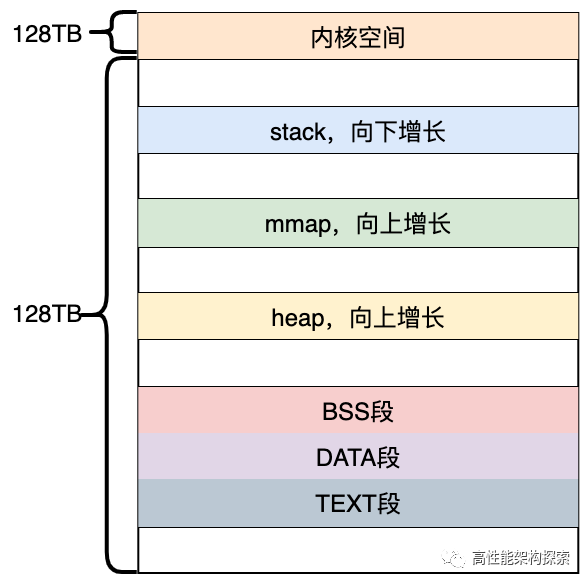
30张图带你领略glibc内存管理精髓Linux 系统在装载 elf 格式的程序文件时,会调用 loader 把可执行文件中的各个段依次载入到从某一地址开始的空间中。用户程序可以直接使用系统调用来管理 heap 和mmap 映射区域,但更多的时候程序都是使用 C 语言提供的 malloc()和 free()函数来动态的分配和释放内存。stack区域是唯一不需要映射,用户却可以访问的内存区域,这也是利用堆栈溢出进行攻击的基础。
- 对于heap的操作,操作系统提供了brk()函数,c运行时库提供了sbrk()函数。
- 对于mmap映射区域的操作,操作系统提供了mmap()和munmap()函数。
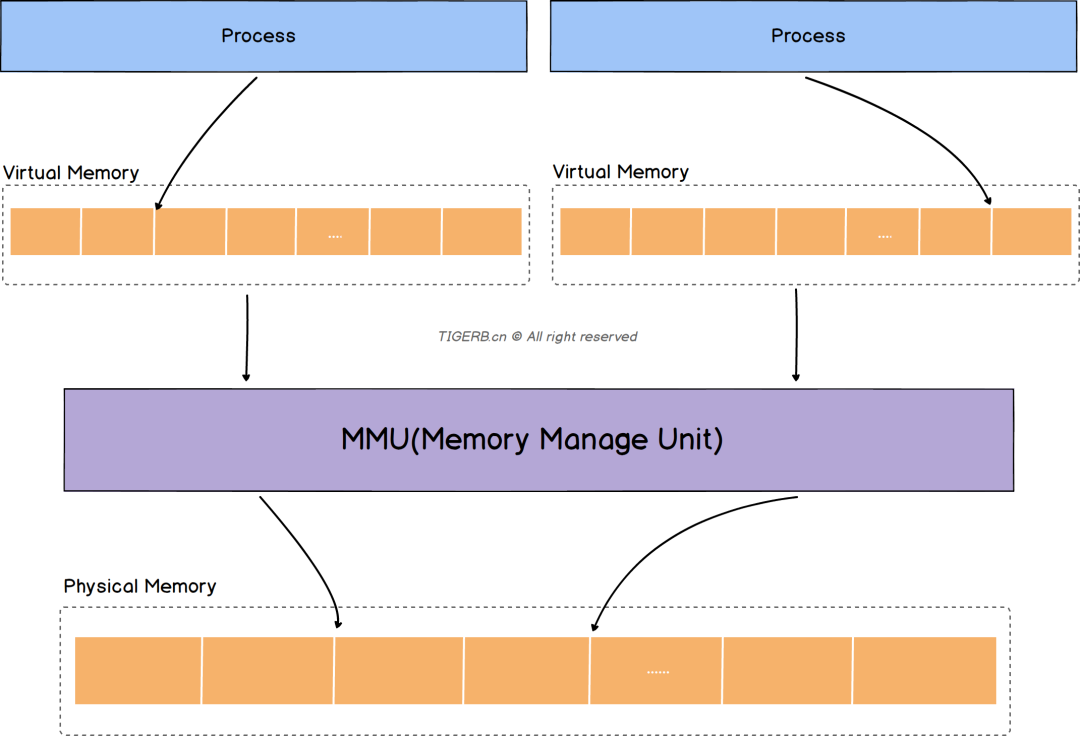
内存的延迟分配,只有在真正访问一个地址的时候才建立这个地址的物理映射,这是 Linux 内存管理的基本思想之一。Linux 内核在用户申请内存的时候,只是给它分配了一个线性区(也就是虚拟内存),并没有分配实际物理内存;只有当用户使用这块内存的时候,内核才会分配具体的物理页面给用户,这时候才占用宝贵的物理内存。内核释放物理页面是通过释放线性区,找到其所对应的物理页面,将其全部释放的过程。
在用户态所需要的内存数据,如代码、全局变量数据以及mmap 内存映射等都是通过mm_struct 进行内存查找和寻址的。mm_struct 中所有成员共同表示一个虚拟地址空间,当虚拟地址空间中的内存区域被访问的时候,会由cpu中的mmu 配合tlb缓存来将虚拟地址转换成物理地址进行访问。对于内核线程来说,由于它只固定工作在地址空间较高的那部分,所以并没有涉及对虚拟内存部分的使用,内核线程的mm_struct都是null。在内核内存区域,可以直接通过计算得出物理内存地址,并不需要复杂的页表计算。而且最重要的是所有内核进程及用户进程的内核态内存都是共享的。
struct mm_struct {
...
unsigned long (*get_unmapped_area) (struct file *filp,
unsigned long addr, unsigned long len,
unsigned long pgoff, unsigned long flags);
...
unsigned long mmap_base; /* base of mmap area */
unsigned long task_size; /* size of task vm space */
...
unsigned long start_code, end_code, start_data, end_data;
unsigned long start_brk, brk, start_stack;
unsigned long arg_start, arg_end, env_start, env_end;
...
// [start_code,end_code)表示代码段的地址空间范围
// [start_data,end_start)表示数据段的地址空间范围
// [start_brk,brk)分别表示heap段的起始空间和当前的heap指针
// [start_stack,end_stack)表示stack段的地址空间范围
// mmap_base表示memory mapping段的起始地址
}
C语言的动态内存分配基本函数是 malloc(),在 Linux 上的实现是通过内核的 brk 系统调用。brk()是一个非常简单的系统调用, 只是简单地改变mm_struct结构的成员变量 brk 的值。PS:系统级分配内存还是很简单的,就是入门的线性分配或链表分配。
语言/运行时
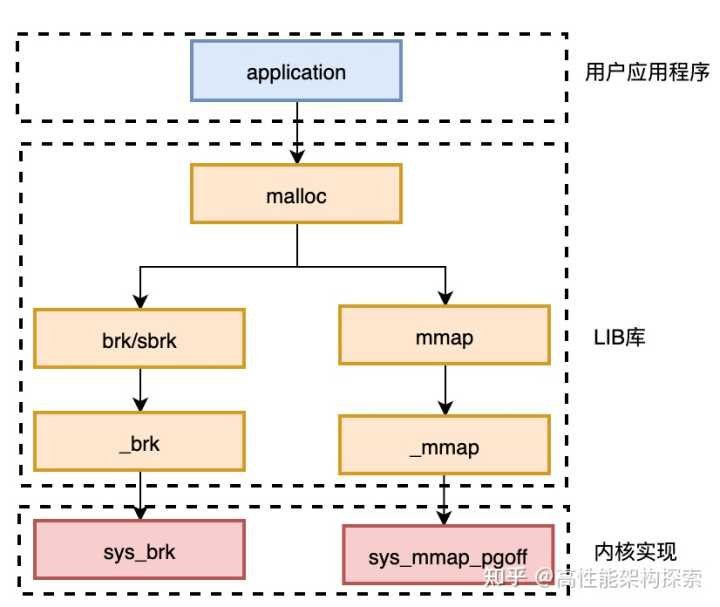
聊聊C语言中的malloc申请内存的内部原理操作系统为应为应用层提供了 mmap、brk 等系统调用来申请内存。但是这些系统调用在很多的时候,我们并不会直接使用。原因有以下两个
- 系统调用管理的内存粒度太大。系统调用申请内存都是整页 4KB 起,但是我们平时编程的时候经常需要申请几十字节的小对象。如果使用 mmap 未免碎片率也太大了。
- 频繁的系统调用的开销比较大。和函数调用比起来,系统的调用的开销非常的大。如果每次申请内存都发起系统调用,那么我们的应用程序将慢如牛。 所以,现代编程语言的做法都是自己在应用层实现了一个内存分配器。其思想都和内核自己用的 SLAB 内存分配器类似。都是内存分配器预先向操作系统申请一些内存,然后自己构造一个内存池。当我们申请内存的时候,直接由分配器从预先申请好的内存池里申请。当我们释放内存的时候,分配器会将这些内存管理起来,并通过一些策略来判断是否将其回收给操作系统。通过这种方式既灵活地管理了各种不同大小的小对象,也避免了用户频率地调用 mmap 系统调用所造成的开销。常见的内存分配器有 glibc 中的 ptmalloc、Google 的 tcmalloc、Facebook 的 jemalloc 等等。我们在学校里学习 C 语言时候使用的 malloc 函数的底层就是 glibc 的 ptmalloc 内存分配器实现的。
ptmalloc
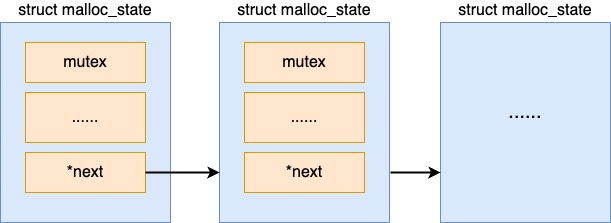
在 ptmalloc 中,使用分配区 arena 管理从操作系统中批量申请来的内存。之所以要有多个分配区,原因是多线程在操作一个分配区的时候需要加锁。在线程比较多的时候,在锁上浪费的开销会比较多。为了降低锁开销,ptmalloc 支持多个分配区。这样在单个分配区上锁的竞争开销就会小很多(但但是有,毕竟不是一个线程一个分配区)。
//file:malloc/malloc.c ptmalloc存在一个全局的主分配区,是用静态变量的方式定义的。
static struct malloc_state main_arena;
//file:malloc/malloc.c
struct malloc_state {
// 锁,用来解决在多线程分配时的竞争问题
mutex_t mutex;
// 分配区下管理内存的各种数据结构
...
/* Linked list 通过这个指针,ptmalloc 把所有的分配区都以一个链表组织了起来,方便后面的遍历。*/
struct malloc_state *next;
}
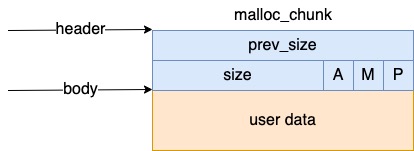
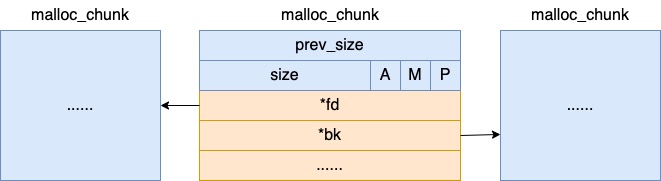
 内存块 chunk,在每个 arena 中,最基本的内存分配的单位是 malloc_chunk,我们简称 chunk。它包含 header 和 body 两部分。
内存块 chunk,在每个 arena 中,最基本的内存分配的单位是 malloc_chunk,我们简称 chunk。它包含 header 和 body 两部分。
// file:malloc/malloc.c
struct malloc_chunk {
INTERNAL_SIZE_T prev_size; /* Size of previous chunk (if free). */
INTERNAL_SIZE_T size; /* Size in bytes, including overhead. */
struct malloc_chunk* fd; /* double links -- used only if free. */
struct malloc_chunk* bk;
/* Only used for large blocks: pointer to next larger size. */
struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */
struct malloc_chunk* bk_nextsize;
};
我们在开发中每次调用 malloc 申请内存的时候,分配器都会给我们分配一个大小合适的 chunk 出来,把 body 部分的 user data 的地址返回给我们。这样我们就可以向该地址写入和读取数据了。如果我们在开发中调用 free 释放内存的话,其对应的 chunk 对象其实并不会归还给内核。而是由 glibc 又组织管理了起来。其 body 部分的 fd、bk 字段分别是指向上一个和下一个空闲的 chunk( chunk 在使用的时候是没有这两个字段的,这块内存在不同场景下的用途不同),用来当双向链表指针来使用。
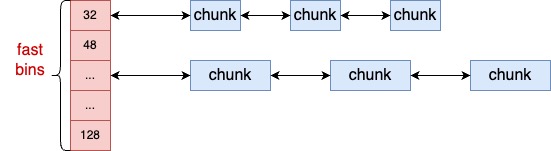
glibc 会将相似大小的空闲内存块 chunk 都串起来。这样等下次用户再来分配的时候,先找到链表,然后就可以从链表中取下一个元素快速分配。这样的一个链表被称为一个 bin。ptmalloc 中根据管理的内存块的大小,总共有 fastbins、smallbins、largebins 和 unsortedbins 四类。
这四类 bins 分别定义在 struct malloc_state 的不同成员里。
//file:malloc/malloc.c
struct malloc_state {
/* Fastbins */
mfastbinptr fastbins[NFASTBINS]; // 管理尺寸最小空闲内存块的链表。其管理的内存块的最大大小是 MAX_FAST_SIZE。
/* Base of the topmost chunk -- not otherwise kept in a bin */
mchunkptr top; // 当所有的空闲链表中都申请不到合适的大小的时候,会来这里申请。
/* The remainder from the most recent split of a small request */
mchunkptr last_remainder;
/* Normal bins packed as described above */
mchunkptr bins[NBINS * 2]; // 管理空闲内存块的主要链表数组。NBINS 的大小是 128,所以这里总共有 256 个空闲链表。smallbins、largebins 和 unsortedbins 都使用的是这个数组。
/* Bitmap of bins */
unsigned int binmap[BINMAPSIZE];
}
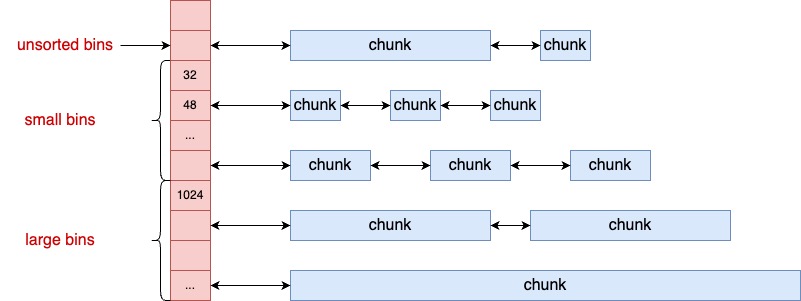
malloc 的工作过程:,当用户要分配内存的时候,malloc 函数就可以根据其大小,从合适的 bins 中查找合适的 chunk。当用户用完需要释放的时候,glibc 再根据其内存块大小,放到合适的 bin 下管理起来。下次再给用户申请时备用。另外还有就是为 ptmalloc 管理的 chunk 可能会发生拆分或者合并。当需要申请小内存块,但是没有大小合适的时候,会将大的 chunk 拆成多个小 chunk。如果申请大内存块的时候,而系统中又存在大量的小 chunk 的时候,又会发生合并,以降低碎片率。
//file:malloc/malloc.c
Void_t* public_mALLOc(size_t bytes){
// 选一个分配区 arena 出来,并为其加锁
arena_lookup(ar_ptr);
arena_lock(ar_ptr, bytes);
// 从分配区申请内存
victim = _int_malloc(ar_ptr, bytes);
// 如果选中的分配区没有申请成功,则换一个分配区申请
......
// 释放锁并返回
mutex_unlock(&ar_ptr->mutex);
return victim;
}
堆栈
进程在推进运行的过程中会调用一些数据,可能中间会产生一些数据保留在堆栈段,栈空间 一般在编译时确定(在编译器和操作系统的配合下,栈里的内存可以实现自动管理), 堆空间 运行时动态管理。对于堆具体的说,由runtime 在启动时 向操作 系统申请 一大块内存,然后根据 自定义策略进行分配与回收(手动、自动,分代不分代等),必要时向操作系统申请内存扩容。
从堆还是栈上分配内存?如果你使用的是静态类型语言,那么,不使用 new 关键字分配的对象大都是在栈中的,通过 new 或者 malloc 关键字分配的对象则是在堆中的。对于动态类型语言,无论是否使用 new 关键字,内存都是从堆中分配的。
为什么从栈中分配内存会更快?由于每个线程都有独立的栈,所以分配内存时不需要加锁保护,而且栈上对象的size在编译阶段就已经写入可执行文件了,执行效率更高!性能至上的 Golang 语言就是按照这个逻辑设计的,即使你用 new 关键字分配了堆内存,但编译器如果认为在栈中分配不影响功能语义时,会自动改为在栈中分配。
当然,在栈中分配内存也有缺点,它有功能上的限制。
- 栈内存生命周期有限,它会随着函数调用结束后自动释放,在堆中分配的内存,并不随着分配时所在函数调用的结束而释放,它的生命周期足够使用。
- 栈的容量有限,如 CentOS 7 中是 8MB 字节,如果你申请的内存超过限制会造成栈溢出错误(比如,递归函数调用很容易造成这种问题),而堆则没有容量限制。
jvm
JVM运行时数据区域
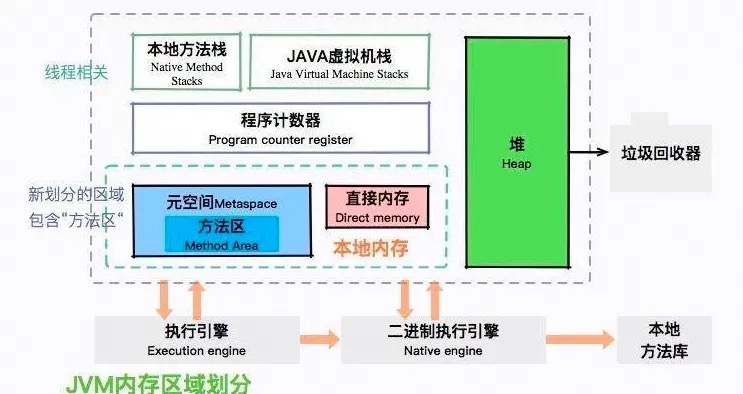
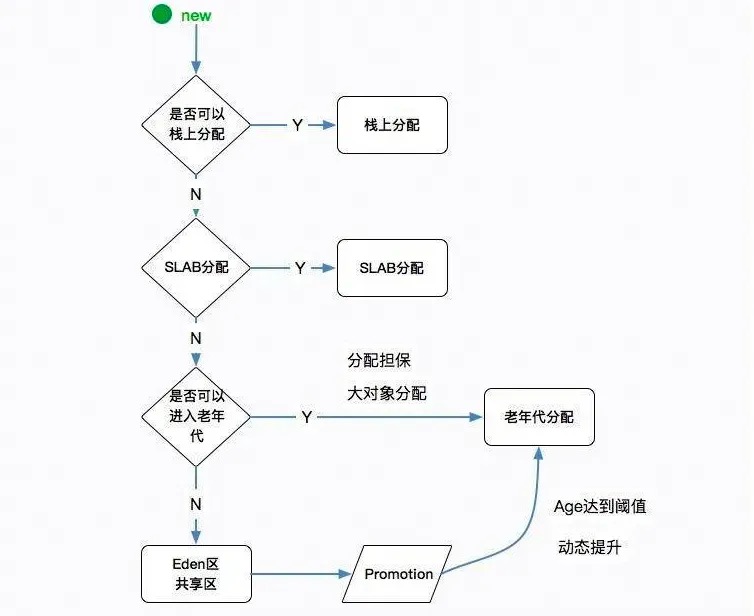
堆内存分配策略
go runtime
Visualizing memory management in Golang 有动图建议细读
各个语言的分配器的实现原理基本上和linux内核使用的slab分配器差不太多。
中间件
os、语言运行时等层面 对内存分配已经做了很多优化,但是很多框架 依然会使用对象池,为什么呢?可能申请内存这个路径 的耗时并没有减少多少,但是因为用完 通过gc 回收的,大量小对象对 gc 压力还是挺大的。因此,基于gc 类语言的做高性能框架,可以把 对象池 可以作为一个通用的优化点。对象池 borrow/returnObject 手动管理内存还是有用武之地的。
- netty arena
- kafka BufferPool
- redis
- go hertz RequestContext 池 cloudwego/hertz 原理浅析
其它
留下评论