JVM类加载
前言
进入到JVM领域后,其实就跟JAVA没什么关系了,JVM只认得class文件。
字节码结构
字节码的本质是一个虚拟指令集,它里面的每条指令代表一种操作。字节码的设计非常类似于 CPU 指令,它有自己定义的数值计算、位操作、比较操作、跳转操作等。人们把这种专门为某一类编程语言所开发的字节码以及其解释器合并称为编程语言虚拟机。对字节码文件进行加载、分析、执行的逻辑都在 Java 语言虚拟机里封装了。在不同的硬件平台和不同的操作系统上,Java 语言虚拟机的实现各不相同,但是它提供的字节码执行器的功能是完全相同的。
C在开发层面的平台相关性:C语言实现系统兼容性的思路很简单,那就是通过在不同的硬件平台和操作系统上开发各自特定的编译器,从而将相同的C语言源代码翻译为底层平台相关的硬件指令。虽然这种思路很棒,但是仍然有明显的缺点,当涉及系统调用时,开发者仍然要关注具体底层系统的API。在Linux平台上,开发者需要知道Linux平台所提供的创建线程的接口是pthread_create();而在Windows平台上,开发者需要知道Windows平台所提供的创建线程的接口是CreateThread()。另外,在Linux和Windows平台上,C程序需要引用不同的头文件,并且所调用的创建线程的两种API的入参和返回值也不相同。所以在开发层面上屏蔽底层差异的关键就是中间语言,C可以run anywhere,但不能write once。
以类似C struct 的方式来表达java 字节码文件的结构。类的数据结构类似一个数据库,里面多张不同类型的“表”紧凑的挨在一起,最大的节省类占用的空间。多数表都会应用到常量池表里面的字面量。
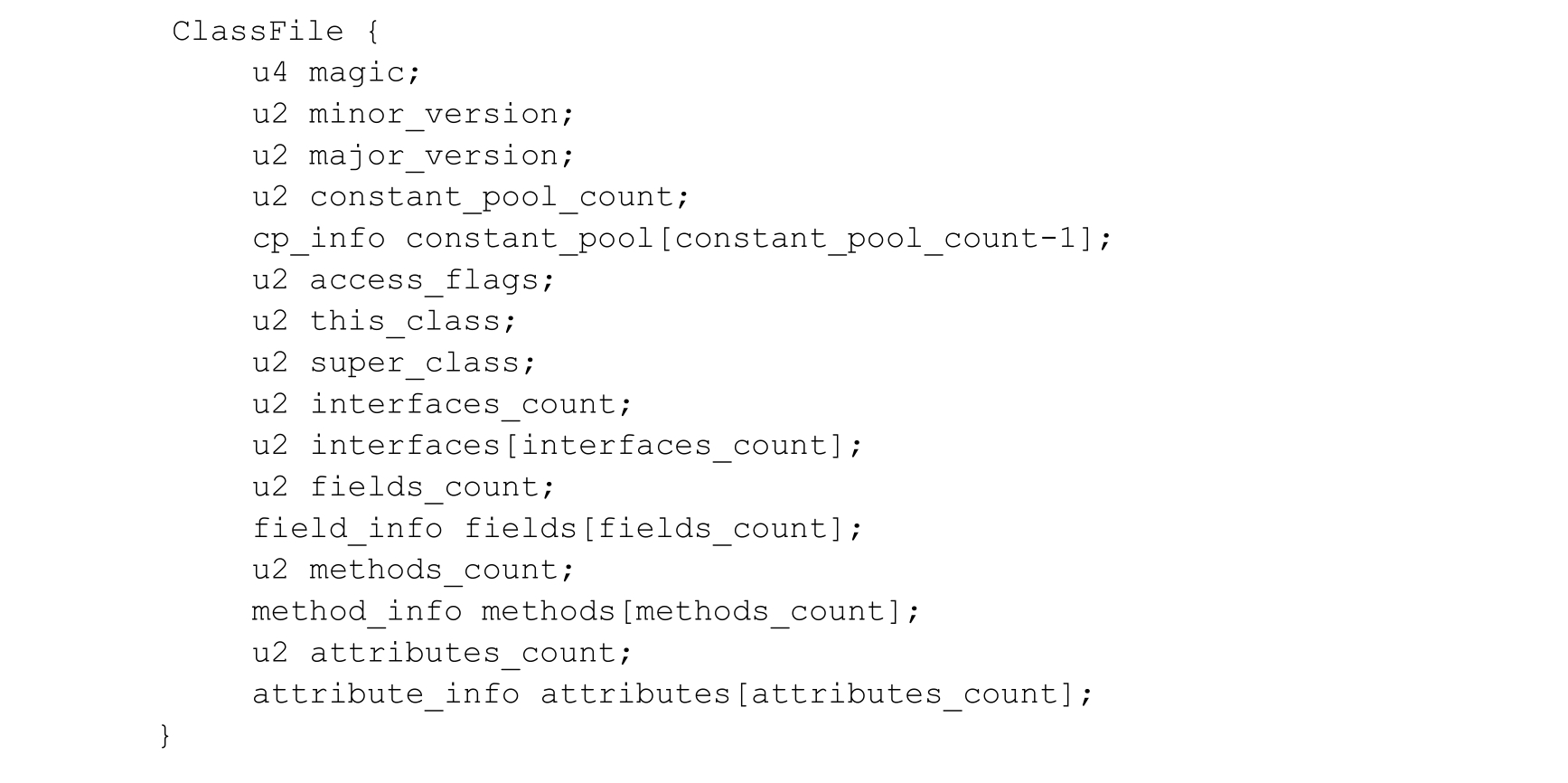
常量池(对应Hotspot C++ constantPoolOop)里放的是字面常量和符号引用
- 字面常量主要包含文本串以及被声明为final的常量。
- 符号引用包含类和接口的全局限定名、字段的名称和描述符、方法的名称和描述符,因为Java语言在编译的时候没有连接这一步,所有的引用都是运行时动态加载的,所以就需要把这些引用的信息保存在class文件里。
字节码生成——ASM
当年学Java时第一章就说Java的特点是「一次编译,到处运行」。但当我们真正在工作中这个特性用处大吗?好像并不大,生产中都使用了同一种服务器,只编译了一次,也都只在这个系统运行。做到一次编译,到处运行的技术底座是JVM,JVM可以加载字节码并运行,这个字节码是平台无关的一种二进制中间码。但似乎这个设定带来了一些其他的好处。在JVM加载字节码时,字节码有一次被修改的机会,但这个字节码的修改比较复杂,好在有现成的库可用,如ASM、Javassist等。
从编译原理的层面看,生成 LLVM 的 IR 时,可以得到 LLVM 的 API 的帮助。字节码就是另一种 IR,而且比 LLVM 的 IR 简单多了,有ASM/Apache BCEL/Javassist 这个工具为我们生成字节码。ASM是一个开源的字节码生成工具/字节码操纵框架。Grovvy 语言就是用它来生成字节码的,它还能解析 Java 编译后生成的字节码,从而进行修改。
ASM 解析字节码的过程,有点像 XML 的解析器解析 XML 的过程:先解析类,再解析类的成员,比如类的成员变量(Field)、类的方法(Mothod)。在方法里,又可以解析出一行行的指令。
- instrument 是 JVM 提供的一个可以修改已加载类文件的类库
- JVM TI(JVM Tool Interface)JVM 工具接口是 JVM 提供的一个非常强大的对 JVM 操作的工具接口。JVM TI 通过事件机制,通过接口注册各种事件勾子,在 JVM 事件触发时同时触发预定义的勾子,以实现对各个 JVM 事件的感知和反应。Agent 是 JVM TI 实现的一种方式。
部分生成的字节码
Spring 采用的代理技术有两个:一个是 Java 的动态代理(dynamic proxy)技术;一个是采用 cglib 自动生成代理,cglib 采用了 asm 来生成字节码。Java 的动态代理技术,只支持某个类所实现的接口中的方法。如果一个类不是某个接口的实现,那么 Spring 就必须用到 cglib,从而用到字节码生成技术来生成代理对象的字节码。
系统的根据编程语言代码AST生成字节码
基于 AST 生成 JVM 的字节码的逻辑还是比较简单的,比生成针对物理机器的目标代码要简单得多,为什么这么说呢?主要有以下几个原因:
- 不用太关心指令选择的问题。针对 AST 中的每个运算,基本上都有唯一的字节码指令对应,直白地翻译就可以了,不需要用到树覆盖这样的算法。
- 不需要关心寄存器的分配,因为 JVM 是使用操作数栈的;
- 指令重排序也不用考虑,因为指令的顺序是确定的,按照逆波兰表达式的顺序就可以了;
- 优化算法,暂时也不用考虑。
类加载——按类名加载
Java类何时会被加载?《深入理解Java虚拟机》给出的答案是:
- 遇到new、getstatic、putstatic 等指令时。
- 反射:对类进行反射调用的时候。
- 继承:初始化某个类的子类的时候。
- 入口:虚拟机启动时会先加载设置的程序主类。包含main方法的类首先被加载
- 使用JDK 1.7 的动态语言支持的时候。 一句话总结就是:当运行过程中需要这个类的时候。
最初的jdk 根本没有类加载的概念,jdk的核心类库直接调用 ClassFileParser::parseClassFile接口完成加载。加载的本质,从磁盘上加载,得到的是一个字节数组,然后按照自己的内存模型,把字节数组中对应的数据放到进程内存对应的地方。并对数据进行校验,转化解析和初始化,最终形成可以被虚拟机直接使用的java类型,这就是虚拟机的类加载机制。
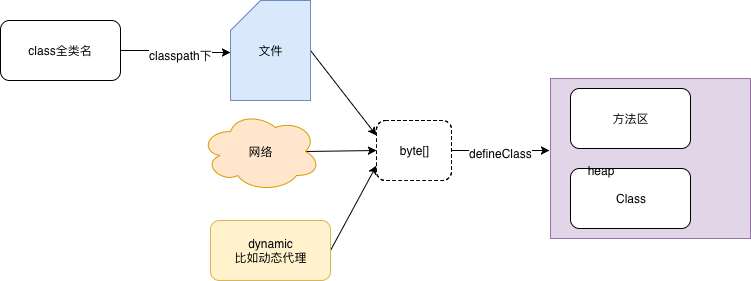
你知道Java类是如何被加载的吗?JVM 默认用于加载用户程序的ClassLoader为AppClassLoader。不过无论是什么ClassLoader,它的根父类都是java.lang.ClassLoader。利用ClassLoader加载类很简单,直接调用ClassLoder的loadClass()方法即可,loadClass()方法最终会调用到ClassLoader.definClass1()中,这是一个 Native 方法。definClass1对应的 JNI 方法为:Java_java_lang_ClassLoader_defineClass1,主要是调用了JVM_DefineClassWithSource()加载类,跟着源码往下走,会发现最终调用的是 jvm.cpp 中的 jvm_define_class_common()方法。
static jclass jvm_define_class_common(JNIEnv *env, const char *name,
jobject loader, const jbyte *buf,
jsize len, jobject pd, const char *source,
TRAPS) {
......
ClassFileStream st((u1*)buf, len, source, ClassFileStream::verify);
Handle class_loader (THREAD, JNIHandles::resolve(loader));
if (UsePerfData) {
is_lock_held_by_thread(class_loader,
ClassLoader::sync_JVMDefineClassLockFreeCounter(),
THREAD);
}
Handle protection_domain (THREAD, JNIHandles::resolve(pd));
//将 Class 文件加载成内存中的 Klass
Klass* k = SystemDictionary::resolve_from_stream(class_name,
class_loader,
protection_domain,
&st,
CHECK_NULL);
......
return (jclass) JNIHandles::make_local(env, k->java_mirror());
}
上面这段逻辑主要就是利用 ClassFileStream 将要加载的class文件转成文件流,然后调用SystemDictionary::resolve_from_stream(),生成 Class 在 JVM 中的代表:Klass。不过Klass只是一个基类,Java Class 真正的数据结构定义在 InstanceKlass 中。
class InstanceKlass: public Klass {
protected:
Annotations* _annotations;
......
ConstantPool* _constants;
......
Array<jushort>* _inner_classes;
......
Array<Method*>* _methods;
Array<Method*>* _default_methods;
......
Array<u2>* _fields;
}
可见 InstanceKlass 中记录了一个 Java 类的所有属性,包括注解、方法、字段、内部类、常量池等信息。这些信息本来被记录在Class文件中,所以说,InstanceKlass就是一个Java Class 文件被加载到内存后的形式。(InstanceKlass 是分配在 ClassLoader的 Metaspace(元空间) 的方法区中。从 JDK8 开始,HotSpot 就没有了永久代,类都分配在 Metaspace 中。Metaspace 和永久代不一样,采用的是 Native Memory。)到这儿,Class文件已经完成了华丽的转身,由冷冰冰的二进制文件,变成了内存中充满生命力的InstanceKlass。PS:二进程程序加载到内存,可以理解为加载到进程地址空间的各个段里,InstanceKlass类似于linux中的task_struct。InstanceKlass 的各个字段类似于task_struct 的各个区域。
类加载器的双亲委派模型
ClassLoader源码注释:The ClassLoader class uses a delegation model to search for classes and resources.

每个ClassLoader都有一个 Dictionary 用来保存它所加载的InstanceKlass信息。并且,每个 ClassLoader 通过锁,保证了对于同一个Class,它只会注册一份 InstanceKlass 到自己的 Dictionary 。正是由于上面这些原因,如果所有的 ClassLoader 都由自己去加载 Class 文件,就会导致对于同一个Class文件,存在多份InstanceKlass,所以即使是同一个Class文件,不同InstanceKlasss 衍生出来的实例类型也是不一样的。双亲委派的好处是尽量保证了同一个Class文件只会生成一个InstanceKlass。
双亲委派模型要求除了顶层的启动类加载器外,其余的类加载器都必须有自己的父类加载器,类加载器间的父子关系不会以继承关系实现,而是以组合的方式来复用父类加载的代码。通过这种层次模型,规定了类加载器优先级,可以避免类的重复加载,也可以避免核心类被不同的类加载器加载到内存中造成冲突和混乱,从而保证了Java核心库的安全。
双亲委派模型的工作过程:当一个类加载器收到类加载请求的时候,它会首先把这个请求委托给父类加载器去执行,因此所有的类加载请求最终都会传送到顶层的启动类加载器中,只有当父类加载器也无法找到时才会交给自己去加载。
Java类加载器 — classloader 的原理及应用使用场景:
- 热部署
- 热加载 spring boot devtools。
- 代码加密。基于java开发编译产生的jar包是由.class字节码组成,由于字节码的文件格式是有明确规范的。因此对于字节码进行反编译,就很容易知道其源码实现了。jar包加密的本质,还是对字节码文件进行加密操作。但是JVM虚拟机加载class的规范是统一的,因此在加载class文件之前通过自定义classloader先进行反向的解密操作,然后再按照标准的class文件标准进行加载
- 依赖冲突。阿里 pandora(潘多拉)通过自定义类加载器,为每个中间件自定义一个加载器来 解决依赖冲突 通过自定义类加载器可以干出很多黑科技,但是有个基本的雷区就是,不能随便替代JAVA的核心基础类,或者说即是你写了一个跟核心类一模一样的类,JVM也不会使用。JVM实例由类加载器+类的全限定包名和类名组成类的唯一标志。加载类的时候,JVM 判断类是否来自相同的加载器,如果相同而且全限定名则直接返回内存已有的类。PS: 要先父后子
- 只要自定义个ClassLoader,重写loadClass方法(不依照往上开始寻找类加载器),那就算是打破双亲委派机制了。
- 把war包放到tomcat的webapp下,这意味着一个tomcat可以运行多个Web应用程序,那假设我现在有两个Web应用程序,它们都有一个类,叫做User,并且它们的类全限定名都一样,比如都是com.yyy.User。但是他们的具体实现是不一样的,那么Tomcat是如何保证它们是不会冲突的呢?Tomcat给每个 Web 应用创建一个类加载器实例(WebAppClassLoader),该加载器重写了loadClass方法,优先加载当前应用目录下的类,如果当前找不到了,才一层一层往上找。
延迟加载
class X{
static{ System.out.println("init class X..."); }
int foo(){ return 1; }
Y bar(){ return new Y(); }
}
The most basic API is ClassLoader.loadClass(String name, boolean resolve)
Class classX = classLoader.loadClass("X", resolve);
If resolve is true, it will also try to load all classes referenced by X. In this case, Y will also be loaded. If resolve is false, Y will not be loaded at this point.
ClassNotFoundException和NoClassDefFoundError
Why am I getting a NoClassDefFoundError in Java?
- ClassNotFoundException This exception indicates that the class was not found on the classpath.
- NoClassDefFoundError, This is caused when there is a class file that your code depends on and it is present at compile time but not found at runtime. Look for differences in your build time and runtime classpaths. 引起的原因比较少见,还未掌握到精髓。
ClassLoader 隔离
在 Java 虚拟机中,类的唯一性是由类加载器实例以及类的全名一同确定的(即便是同一串字节流,经由不同的类加载器加载,也会得到两个不同的类)。猜测一下,如果是一致的,ClassLoader 该如何实现呢?
- ClassLoader
Class<?> defineClass(String name, byte[] b, int off, int len)时,如果发现name 相同, 可以直接返回。但ClassLoader 是可以自定义实现的,很难约束开发必须遵守这个规则。 - defineClass 时直接覆盖,那问题就更严重了,开发就有机会恶意覆盖 一些已有的java 库中的类的实现。
在大型应用中,往往借助这一特性,来运行同一个类的不同版本。tomcat 在类加载方面就有很好的实践 Tomcat源码分析
字节增强
任何合法的源码编译成class后被类加载器加载进JVM的方法区,也就是以字节码的形态存活在JVM的内存空间。
可能很多同学都已经习惯在IDE上对某句代码打上断点,然后逐步往下追踪代码执行的步骤。我们进一步想想,这个是怎么实现的,是一股什么样的力量能把已经跑起来的线程踩下刹车,一步一步往前挪?我们知道线程运行其实就是在JVM的栈空间上不断的把代码对应的JVM指令集不断的送到CPU执行。那能阻止这个流程的力量也肯定是发生在JVM范围内,所以我们可以很轻松的预测到这肯定是JVM提供的机制,而不是IDE真的有这样的能力,只不过是JVM把这种能力封装成接口暴露出去,然后提供给IDE调用,而IDE只不过是通过界面交互来调用这些接口而已。JVM提供的一个工具箱JVMTI(JVM TOOL Interface)提供的接口,而这个工具箱是一套叫做JPDA的架构定义的。 JVM核心知识体系
Java对象在内存中的表示
抛开细节从操作系统层面观察,那么就是JVM实例在运行过程中通过IO从硬盘或者网络读取CLASS二进制文件,然后在JVM管辖的内存区域存放对应的文件。从功能上判断无非就是读取文件到内存。但是乱糟糟的把一堆毫无秩序的类文件往内存里面扔,没有良好的管理也没法用,所以需要我们需要设计一套规则来管理存放内存里面的CLASS文件。
jvm中类和对象定义存储基础知识 未细读。
在 HotSpot 虚拟机中,对象分为如下3块区域:
- 对象头(Header)运行时数据:哈希码、GC分代年龄、锁状态标志、偏向线程ID、偏向时间戳等。类型指针:对象的类型元数据的指针,如果对象是数据,还会记录数组长度。PS:这也是为何堆外内存到堆内内存要有copy过程。
- 对象实例数据(Instance Data)包含对象真正的内容,即其包括父类所有字段的值。
- 对齐填充(Padding)对象大小必须是是8字节的整数倍,所以对象大小不满足这个条件时,需要用对齐填充来补齐。
磁盘表示 :java 源码文件 ==> 磁盘表示: 字节码文件 ==> 内存的c++表示: oop-kclass struct ==> 内存的二进制表示:数据结构和方法对应的机器指令。
面向对象语言将对象(数据)和方法(对象上的操作)绑定到了一起,来提供更强的封装性和多态。这些特性都依赖对象头中的类型信息来实现,Java、Python语言都是如此。Java对象在内存中的layout=mark + kclass* + fields。
+-------------+
| mark |
+-------------+
| Klass* |
+-------------+
| fields |
| |
+-------------+
mark表示了对象的状态,包括是否被加锁、GC年龄等等。而Klass*指向了描述对象类型的数据结构 InstanceKlass 。
// InstanceKlass layout:
// [C++ vtbl pointer ] Klass
// [java mirror ] Klass
// [super ] Klass
// [access_flags ] Klass
// [name ] Klass
// [methods ]
// [fields ]
...
java 对象的C++ 类表示——oop-klass model
当C、C++和Delphi等程序被编译成二进制程序后,原来所定义的高级数据结构都不复存在了,当Windows/Linux等操作系统(宿主机)加载这些二进制程序时,是不会加载这些语言中所定义的高级数据结构的,宿主机压根儿就不知道原来定义了哪些数据结构、哪些类,所有的数据结构都被转换为对特定内存段的偏移地址。例如C中的Struct结构体,被编译后不复存在,汇编和机器语言中没有与之对应的数据结构的概念,CPU更不知道何为结构体。C++和Delphi中的类概念被编译后也不复存在,所谓的类最终变成内存首地址。而JVM虚拟机在加载字节码程序时,会记录字节码中所定义的所有类型的原始信息(元数据),JVM知道程序中包含了哪些类,以及每个类中所关联的字段、方法、父类等信息(类型结构信息被带到了运行期)。这是JVM虚拟机与操作系统最大的区别所在。
在编译期生成的字节码文件中,Java 类结构的信息其实是被抹掉的,谁也无法一眼从二进制格式的字节码文件中看出一个Java 类的结构,但字节码文件通过其本身的格式规范,确保JVM 可以据此还原出原始的Java 类结构。字节码文件的解析包含3个主要的过程:常量池解析;字段解析;方法解析。通过字段解析,jvm 能够分析出java 类所封装的数据结构,通过方法解析 可以分析出java 类所封装的算法逻辑,而前两者很多与字符串 等相关的信息都封装于常量池中,因此要最先解析常量池。当常量池、字段、方法被解析完,则字节码文件的“精华”便被完全消化吸收。
struct iphone6s {
int length;
int width;
int height;
int weight;
int ram;
int rom;
int pixel;
}
int main(){
struct iphone6s iphone; // 定义变量
iphone.length = 138;
iphone.weight = 64;
...
return 0
}
// 编译为汇编
main:
pushl %ebp
movel%esp, %ebp
subl$32, %esp
movel$138, -28(%ebp)
movel$67, -24(%ebp)
...
movel$0,%eax
leave
ret
正因为JVM 需要保存字节码中的类元信息,所以JVM自然而然就演化出了OOP-KLASS二分模型。KLASS 用来保存类元信息,保存在PERM 永久区,OOP 用来表示JVM所创建的类实例对象,分配在堆区。同时JVM 为了支持反射等技术,必须在OOP 中保存一个只恨,用来指向KLASS,这样就可以在运行期获取类的类型、父类、字段、方法等信息。这些有助于开发具有运行时动态特性的程序,例如根据类型来设计更为抽象和优雅的工厂模式,运行时动态生成字节码并执行其方法(ASM字节码编程),进而使得java 成为各种中间件、框架的首选。
深入理解多线程(二)—— Java的对象模型HotSpot是基于c++实现,而c++是一门面向对象的语言,本身具备面向对象基本特征,所以Java中的对象表示,最简单的做法是为每个Java类生成一个c++类与之对应。但HotSpot JVM并没有这么做,而是设计了一个OOP-Klass Model。
- OOP(Ordinary Object Pointer)用来描述对象实例信息
- Klass 用来描述java类,是虚拟机内部Java类型结构的对等体 为什么HotSpot要设计一套oop-klass model呢?答案是:HotSopt JVM的设计者不想让每个对象中都含有一个vtable(虚函数表)。oop的职能主要在于表示对象的实例数据,所以其中不含有任何虚函数。而klass为了实现虚函数多态,所以提供了虚函数表。
字节码文件是分段的,加载过程中,也会分段解析 字节码文件来创建和填充 instanceKlass 和methodOop 等, 在Java程序运行过程中,每创建一个新的对象,在JVM内部就会相应地创建一个对应类型的OOP对象。JVM内部定义了各种oop-klass,在JVM看来,不仅Java类是对象,Java方法也是对象,字节码常量池也是对象,一切皆是对象。JVM使用不同的oop-klass模型来表示各种不同的对象。
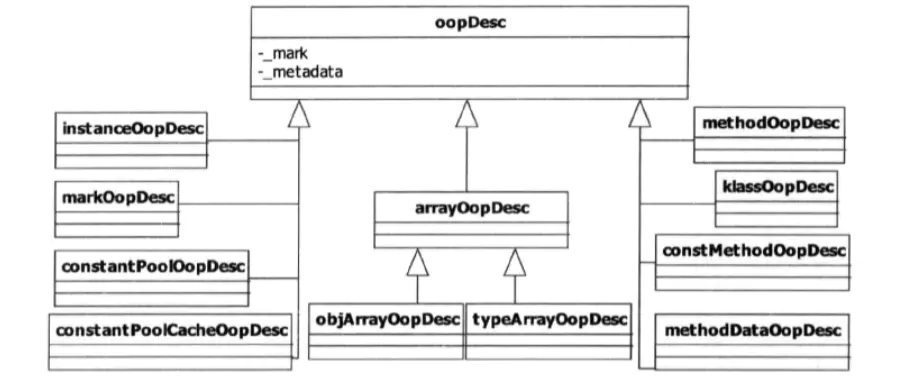
无论是oop还是klass,基本都被划分来描述instance/method/constantMethod/methodData/array/objArray/typeArray/constantPool/constantPoolCache 等,用来勾画一个java code 的全部:数据、方法、类型、数组和实例。
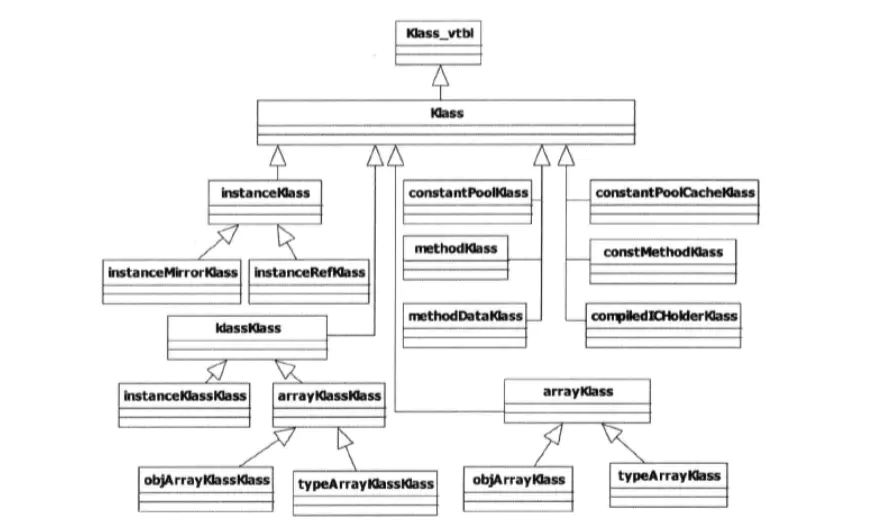
一个Java对象,它的存储是怎样的?
- 一般很多人会回答:对象存储在堆上。
- 稍微好一点的人会回答:对象存储在堆上,对象的引用存储在栈上。
- 一个更加显得牛逼的回答:对象的实例(instanceOopDesc)保存在堆上,对象的元数据(instanceKlass)保存在方法区,对象的引用保存在栈上。
内存布局
// Klass_vtbl 描述了虚函数表
class Klass : public Klass_vtbl{
protected:
jint _layout_helper; // 对象布局综合描述
junit _super_check_offset;
Symbol* _name; // 类名
public: ...
protected:
klassOop _secondary_super_cache;
objArrayOop _secondary_supers;
klassOop _primary_supers[_primary_super_limit];
oop _java_mirror; // 镜像类 Class
klassOop _super; // 父类
klassOop _subklass; // 指向第一个子类
klassOop _next_sibling; // 指向第一个兄弟节点
jint _modifier_flags; // 修饰符标识 例如static
AccessFlags _access_flags; // 访问权限标识,例如public
objectArrayOop _methods // 方法信息
typeArrayOop _fields // 字段信息
oop _class_loader // 类加载器
typeArrayOop _inner_classes // 内部类
int _nonstatic_field_size // 非静态字段大小
int _static_field_size // 静态字段大小
int vtable_len // 虚方法表长度
}
instanceKlass 是java 类加载的最终产物,jvm 根据这个数据结构,可以获取java 类所定义的一切元素。jvm 在创建完instanceKlass 之后,又创建了一个与之对等的镜像类java.lang.Class。Class 是为了被java 程序调用,instanceKlass 是为了被jvm 内部访问。
class oopDesc {
private:
volatile markWord _mark;
union _metadata {
Klass* _klass;
narrowKlass _compressed_klass;
} _metadata;
}
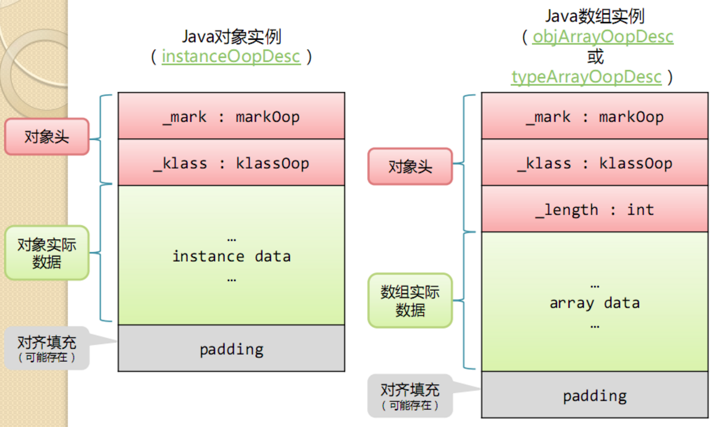
每个 Java 对象都有一个对象头 (object header) ,由标记字段和类型指针构成。java对象头信息是跟对象自身定义的数据结构无关的,这些信息所记录的状态是用于JVM对对象的管理的(比如并发访问与gc)。
- 标记字段用来存储对象的哈希码, GC 信息, 持有的锁信息。比如 hotspots的markword中,用了4个bit去表示分代年龄,那么能表示的最大范围就是0-15。所以这也就是为什么设置新生代的年龄不能超过15。
- 类型指针指向该对象的类 Class。
在 64 位操作系统中,标记字段占有 64 位,而类型指针也占 64 位,也就是说一个 Java 对象在什么属性都没有的情况下要占有 16 字节的空间,当前 JVM 中默认开启了压缩指针,这样类型指针可以只占 32 位,所以对象头占 12 字节, 压缩指针可以作用于对象头,以及引用类型的字段。以 Integer 类为例,它仅有一个 int 类型的私有字段,占 4 个字节。因此,每一个 Integer 对象的额外内存开销至少是 400%。这也是为什么 Java 要引入基本类型的原因之一。
默认情况下,Java 虚拟机堆中对象的起始地址需要对齐至 8的倍数。如果一个对象用不到 8N 个字节,那么剩下的就会被填充。这些浪费掉的空间我们称之为对象间的填充(padding)。
- 对象内存对齐, 这样对象的地址 就可以压缩一下,比如address * 8 得到对象的实际地址。
- 对象字段内存对齐(有六七个对齐规则),让字段只出现在同一 CPU 的缓存行中。如果字段不是对齐的,那么就有可能出现跨缓存行的字段。也就是说,该字段的读取可能需要替换两个缓存行,而该字段的存储也会同时污染两个缓存行。
- Java 虚拟机重新分配字段的先后顺序,以达到内存对齐的目的
CDS
InstanceKlass结构比较复杂,包含了类的所有方法、field等等,方法又包含了字节码等信息。这个数据结构是通过运行时解析class文件获得的,为了保证安全性,解析class时还需要校验字节码的合法性(非通过javac产生的方法字节码很容易引起jvm crash)。CDS可以将这个解析、校验产生的数据结构存储(dump)到文件,在下一次运行时重复使用。这个dump产物叫做Shared Archive,以jsa后缀(java shared archive)。为了减少CDS读取jsa dump的开销,避免将数据反序列化到InstanceKlass的开销,jsa文件中的存储layout和InstanceKlass对象完全一样,这样在使用jsa数据时,只需要将jsa文件映射到内存,并且让对象头中的类型指针指向这块内存地址即可,十分高效。 Alibaba Dragonwell对AppCDS的优化
其它
通常情况下类加载器会持有该加载器加载过的所有类的引用,所有如果类是经过系统默认类加载器加载的话,那就很难被垃圾收集器回收,除非符合根节点不可达原则才会被回收。
探究 Java 应用的启动速度优化InstanceKlass结构比较复杂,包含了类的所有方法、field等等,方法又包含了字节码等信息。这个数据结构是通过运行时解析class文件获得的,为了保证安全性,解析class时还需要校验字节码的合法性。CDS 可以将这个解析、校验产生的数据结构存储(dump)到文件,在下一次运行时重复使用。这个dump产物叫做Shared Archive,以jsa后缀(Java shared archive)。为了减少 CDS 读取 jsa dump 的开销,避免将数据反序列化到InstanceKlass的开销,jsa 文件中的存储layout和InstanceKlass对象完全一样,这样在使用 jsa 数据时,只需要将 jsa 文件映射到内存,并且让对象头中的类型指针指向这块内存地址即可,十分高效。
《揭秘Java虚拟机:JVM设计原理与实现》Java选择具备运行时类型识别的特性本身便从一个十分隐晦的层面制约了Java必须选择成为一门面向对象的编程语言,为何?类型本身就是一种“闭包”的技术手段,只有先从语法层面实现了“闭包”,才能实现“对象”的概念,否则,何来的属性、成员变量、类方法一说?类型是实现将若干属性和动作打包成为一个整体对象进行统一识别的策略。如果Java像C++那样,类型不作为属性和方法封装的唯一手段,开发者可以随心所欲地在类的外面定义变量和函数,那么对于这部分数据的“运行时识别”必然是一个难题,可能需要通过类似namespace或者filename这样的机制去实现动态反射了,但是这种反射想想都让人头大,不容易啊!
当一门编程语言实现了完全的闭包语法策略(使用类型包装可以认为是闭包的一种),便自然而然具备了自动内存管理的技术基础,或者说实现自动内存管理更加容易。所以闭包便成为很多具备自动内存回收特性的编程语言的语法基础,例如GO语言、Phthon、JavaScript等,虽然大家具体实现闭包的手段不同,但是殊途同归,都是为了能够让虚拟机在自动回收内存时尽量简单。
import 语句仅仅是个语法糖,且为了不写那一长串的全限定名,并没有任何关联的运行时行为,更不会导致类的加载,纯粹是为了方便写代码。
留下评论