《深度学习推荐系统实战》笔记
简介
商业社会中亘古不变的关系是供求关系,供求关系的背后是交换。无论是实体经济还是虚拟经济,都是基于这个原理。供求关系动态变化,当供给小于需求时,就产生了稀缺,有了稀缺,就有了商业。推荐系统处理的是信息,它的主要作用是在信息生产方和信息消费方搭建起桥梁。所以推荐系统是信息经济中的一个装置。那么在信息经济中供求到底又是什么呢?信息经济中,看上去供求方是信息生产者,需求方是注意力提供者。注意力有个特点:总量有限。在移动互联网普及之后,信息已经泛滥到很大程度,智能手机变成身体的一个器官,丰富的注意力被信息源以推荐的方式逐渐侵蚀,注意力从丰富变成稀缺。信息源在打着灯笼到处寻找注意力。
商业社会永远是逐利的,逐利的手段就是制造信息不对称,并且在制造过程中不断提高效率和降低成本。信息泛滥,信息过载,用户错过的信息量越来越多,注意力耗散很多,无法将耗散的注意力变现成了平台最大的痛。
整体架构
当你开始学习一个全新领域的时候,你想做的第一件事情是什么?我最想搞明白的是两个问题,一个是,这个领域到底要解决什么问题?第二个是,这个领域有没有一个非常高角度的思维导图,让我能够了解这个领域有哪些主要的技术,做到心中有数?
推荐系统要处理的问题就可以被形式化地定义为:对于某个用户U(User),在特定场景C(Context)下,针对海量的“物品”信息构建一个函数 ,预测用户对特定候选物品I(Item)的喜好程度,再根据喜好程度对所有候选物品进行排序,生成推荐列表的问题。
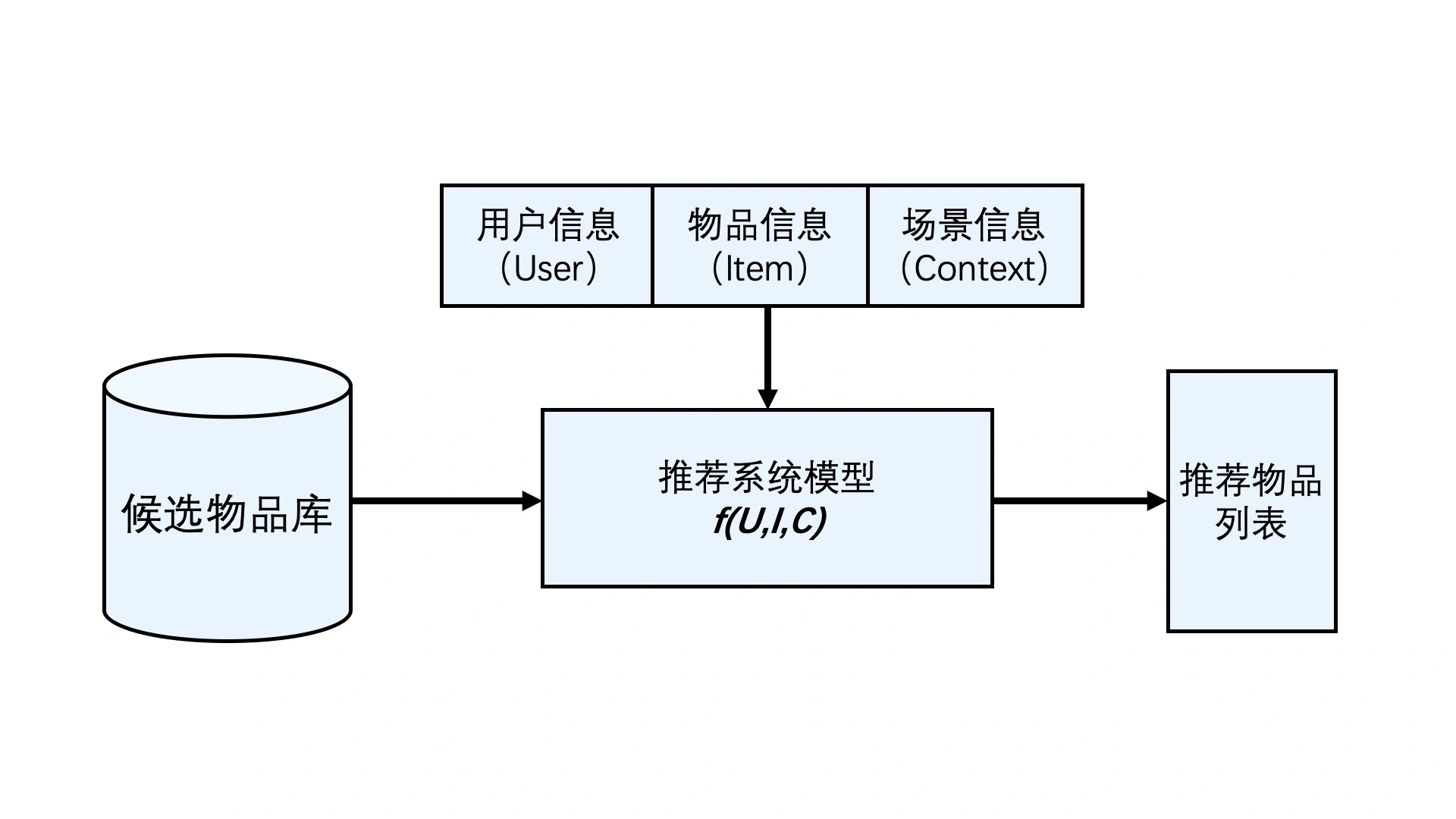
居于中心位置的是一个抽象函数f(U,I,C),它负责“猜测”用户的心,为用户可能感兴趣的物品打分,从而得出最终的推荐物品列表。在推荐系统中,这个函数一般被称为“推荐系统模型”。因为深度学习复杂的模型结构,让深度学习模型具备了理论上拟合任何函数的能力。如果说f(U,I,C) 这个推荐函数具有一个最优的表达形式,那传统的机器学习模型只能够拟合出f(U,I,C) 这个推荐函数的近似形式,而深度学习模型则可以最大程度地接近这个最优形式。近几年,由于深度学习模型的结构复杂度大大提高,使通过训练使模型收敛所需的数据量大大增加,这也反向推动了推荐系统大数据平台的发展,让推荐系统相关的大数据存储、处理、更新模块也一同迈入了“深度学习时代”。
在实际的推荐系统中,工程师需要着重解决的问题有两类。
- 一类问题与数据和信息相关,即“用户信息”“物品信息”“场景信息”分别是什么?如何存储、更新和处理数据?
- 另一类问题与推荐系统算法和模型相关,即推荐系统模型如何训练、预测,以及如何达成更好的推荐效果?
数据部分
大数据平台加工后的数据出口主要有 3 个:
- 生成推荐系统模型所需的样本数据,用于算法模型的训练和评估。
- 生成推荐系统模型服务(Model Serving)所需的“用户特征”,“物品特征”和一部分“场景特征”,用于推荐系统的线上推断。
- 生成系统监控、商业智能(Business Intelligence,BI)系统所需的统计型数据。
特征数据库和模型服务是推荐系统中连接线上环境和线下环境的纽带。
特征工程
特征工程就是利用工程手段从“用户信息”“物品信息”“场景信息”中提取特征的过程。
从具体行为信息转化成抽象特征的过程,往往会造成信息的损失.
- 具体的推荐行为和场景中包含大量原始的场景、图片和状态信息,保存所有信息的存储空间过大,我们根本无法实现。
- 具体的推荐场景中包含大量冗余的、无用的信息,把它们都考虑进来甚至会损害模型的泛化能力。
尽可能地让特征工程抽取出的一组特征,能够保留推荐环境及用户行为过程中的所有“有用“信息,并且尽量摒弃冗余信息。
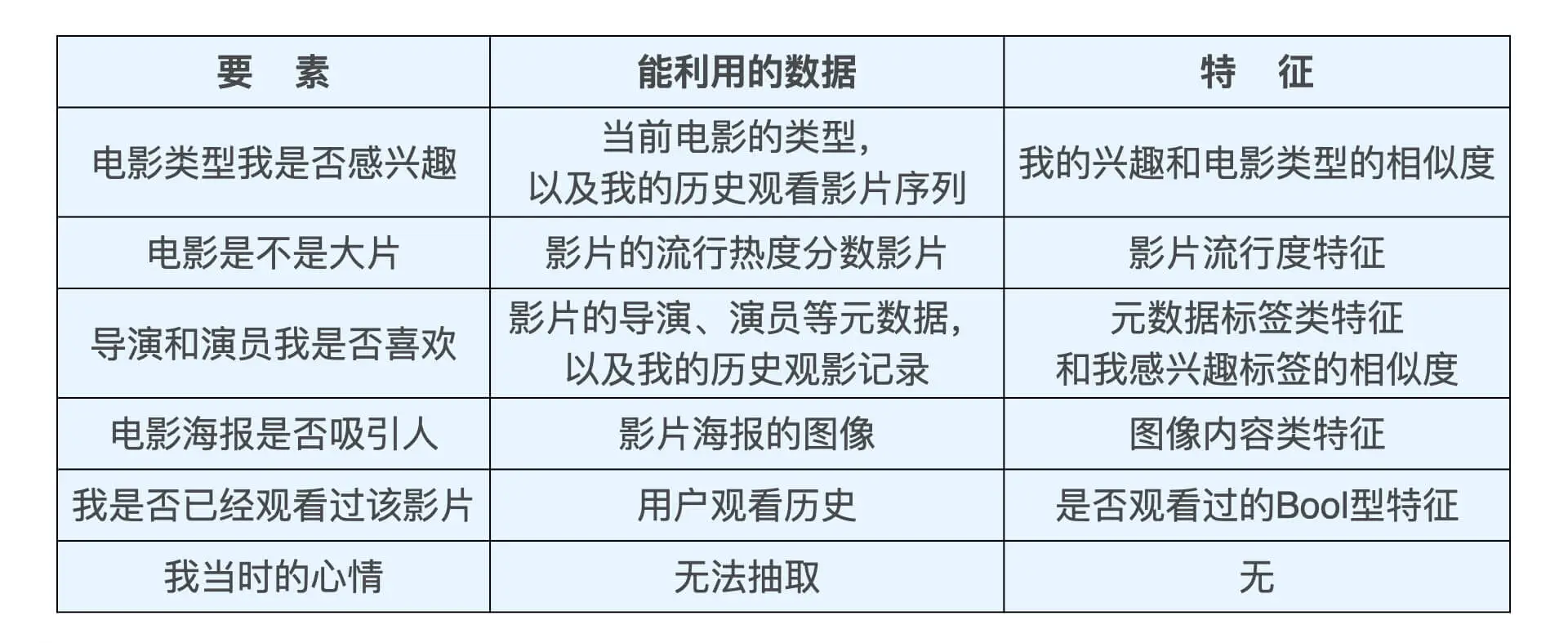
推荐系统中的常用特征
- 用户行为数据
- 显性反馈行为: 评分、 点赞等
- 隐性反馈行为:点击、加入购物车、购买、播放、 播放时长、评论、收藏等
- 用户关系数据
- 显性:关注、好友等
- 隐性:点赞、同处一个社区、 同看一部电影等
- 属性、标签类数据
- 内容类数据:大段的描述型文字、图片,视频等。一般来说,内容类数据无法直接转换成推荐系统可以“消化”的特征,需要通过自然语言处理、计算机视觉等技术手段提取关键内容特征,再输入推荐系统。
- 场景信息(上下文信息):时间、地点、季节、 是否节假日、天气、空气质量、社会大事件等
所有的特征都可以分为两大类。
- 第一类是类别、ID 型特征(以下简称类别型特征),拿电影推荐来说,电影的风格、ID、标签、导演演员等信息,用户看过的电影 ID、用户的性别、地理位置信息、当前的季节、时间(上午,下午,晚上)、天气等等,这些无法用数字表示的信息全都可以被看作是类别、ID 类特征。
- 第二类是数值型特征,能用数字直接表示的特征就是数值型特征,典型的包括用户的年龄、收入、电影的播放时长、点击量、点击率等。
我们进行特征处理的目的,是把所有的特征全部转换成一个数值型的特征向量
- 对于类别、ID 类特征,我们应该怎么处理它们呢?One-hot 编码(也被称为独热编码)它通过把所有其他维度置为 0,单独将当前类别或者 ID 对应的维度置为 1 的方式生成特征向量。
- 比如星期二 用
[0,1,0,0,0,0,0]表示 - ID 型特征也经常使用 One-hot 编码,假设我们的电影库中一共有 1000 部电影,电影 M 的 ID 是 310(编号从 0 开始),那这个行为就可以用一个 1000 维的向量来表示,让第 310 维的元素为 1,其他元素都为 0。
- 对于历史行为序列类、标签特征等数据来说,用户往往会与多个物品产生交互行为,或者一个物品被打上多个标签,这时最常用的特征向量生成方式就是把其转换成 Multi-hot 编码。
- 比如星期二 用
- 对于数值型特征
- 对特征的尺度归一化,对于电影来说, 评价次数的范围一般在[0,无穷大]之间,评分的取值范围在[0,5]之间,如果我们把特征的原始数值直接输入推荐模型,就会导致这两个特征对于模型的影响程度有显著的区别。
- 用分桶的方式解决特征分布不均匀的问题,由于人们打分有“中庸偏上”的倾向,因此评分大量集中在 3.5 的附近,这对于模型学习来说也不是一个好的现象,因为特征的区分度并不高。所谓“分桶(Bucketing)”,就是将样本按照某特征的值从高到低排序,然后按照桶的数量找到分位数,将样本分到各自的桶中,再用桶 ID 作为特征值。改变特征分布 还有取开方、平方等,如果无法通过人工的经验判断哪种特征处理方式更好,可以把它们都输入模型,让模型来做选择。
特征处理这块,spark MLlib 和 机器学习库 都提供了处理函数。
整体设计
模型的结构一般由“召回层”、“排序层”以及“补充策略与算法层”组成。
- “召回层”一般由高效的召回规则、算法或简单的模型组成,这让推荐系统能快速从海量的候选集中召回用户可能感兴趣的物品。
- “排序层”则是利用排序模型对初筛的候选集进行精排序。深度粗排在天猫新品中的实践
- “补充策略与算法层”,也被称为“再排序层”,是在返回给用户推荐列表之前,为兼顾结果的“多样性”“流行度”“新鲜度”等指标,结合一些补充的策略和算法对推荐列表进行一定的调整,最终形成用户可见的推荐列表。
深度学习对于推荐系统的革命集中在模型部分,那具体都有什么呢?
- 深度学习中 Embedding 技术在召回层的应用。
- 不同结构的深度学习模型在排序层的应用。
- 增强学习在模型更新、工程模型一体化方向上的应用。让推荐系统可以在实时性层面更上一层楼。
召回层/recall/matching
我们设计召回层时,计算速度和召回率其实是两个矛盾的指标。怎么理解呢?比如说,为了提高计算速度,我们需要使召回策略尽量简单,而为了提高召回率或者说召回精度,让召回策略尽量把用户感兴趣的物品囊括在内,这又要求召回策略不能过于简单,否则召回物品就无法满足排序模型的要求。在实现的过程中,为了进一步优化召回效率,我们还可以通过多线程并行、建立标签 / 特征索引、建立常用召回集缓存等方法来进一步完善它。
包括单策略召回、多路召回和基于 Embedding 的召回等策略。
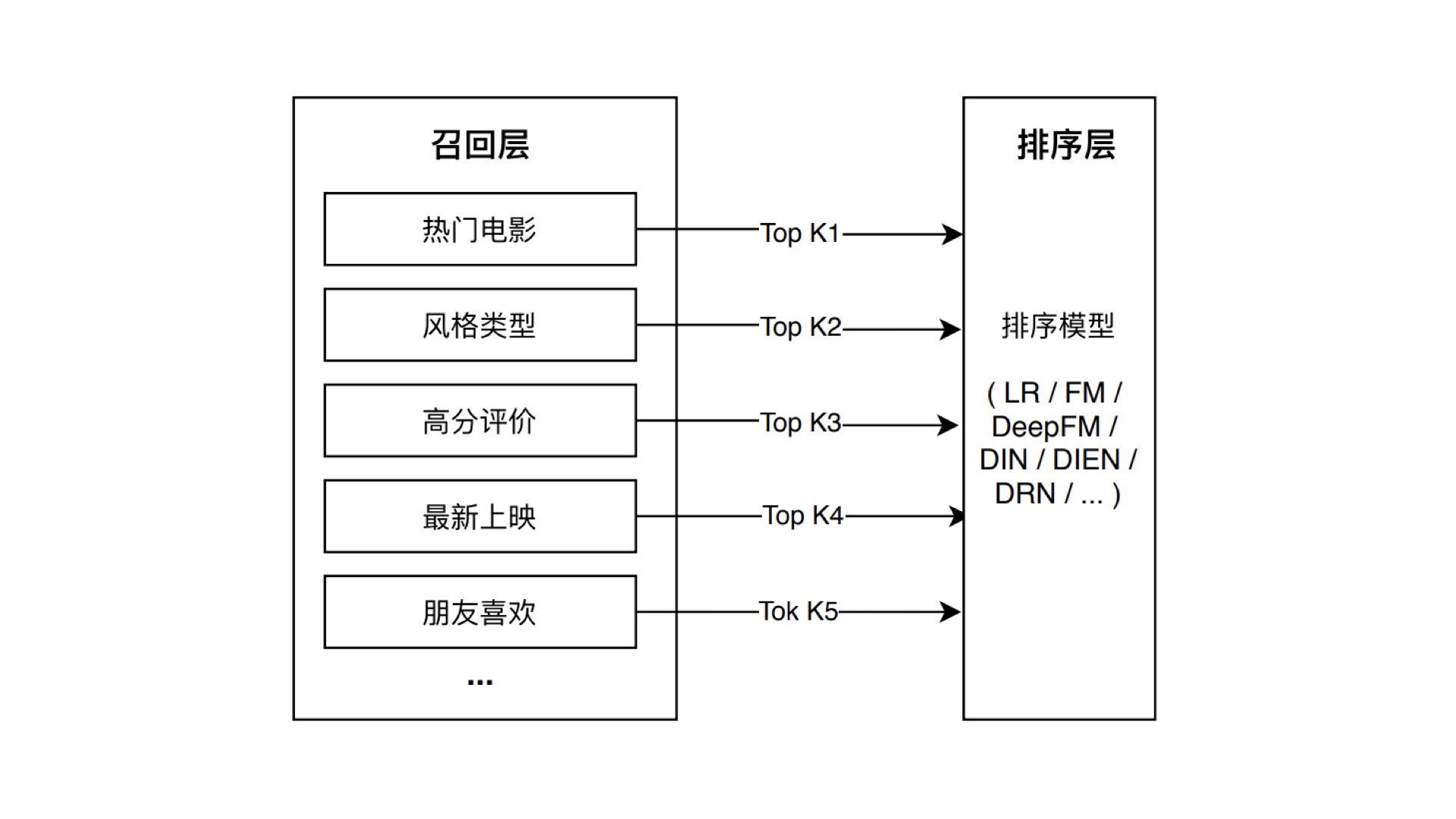
多路召回策略虽然能够比较全面地照顾到不同的召回方法,但也存在一些缺点。比如,在确定每一路的召回物品数量时,往往需要大量的人工参与和调整,具体的数值需要经过大量线上 AB 测试来决定。此外,因为策略之间的信息和数据是割裂的,所以我们很难综合考虑不同策略对一个物品的影响。是否存在一个综合性强且计算速度也能满足需求的召回方法呢?基于 Embedding 的召回方法
- 获取用户的 Embedding
- 获取所有物品的候选集,并且逐一获取物品的 Embedding,计算物品 Embedding 和用户 Embedding 的相似度。Embedding 相似性的计算也相对简单和直接。通过简单的点积或余弦相似度的运算就能够得到相似度得分
- 根据相似度排序,返回规定大小的候选集。
假设,用户和物品的 Embeding 都在一个 k 维的 Embedding 空间中,物品总数为 n,那么遍历计算一个用户和所有物品向量相似度的时间复杂度是多少呢?不难算出是 O(k×n)。虽然这一复杂度是线性的,但物品总数 n 达到百万甚至千万量级时,线性的时间复杂度也是线上服务不能承受的。换一个角度思考这个问题,由于用户和物品的 Embedding 同处一个向量空间内,因此召回与用户向量最相似的物品 Embedding 向量这一问题,其实就是在向量空间内搜索最近邻的过程。近邻搜索的问题一般有两种方案:聚类和索引,但都效果不佳,多使用局部敏感哈希。
模型训练
以电影推荐为例
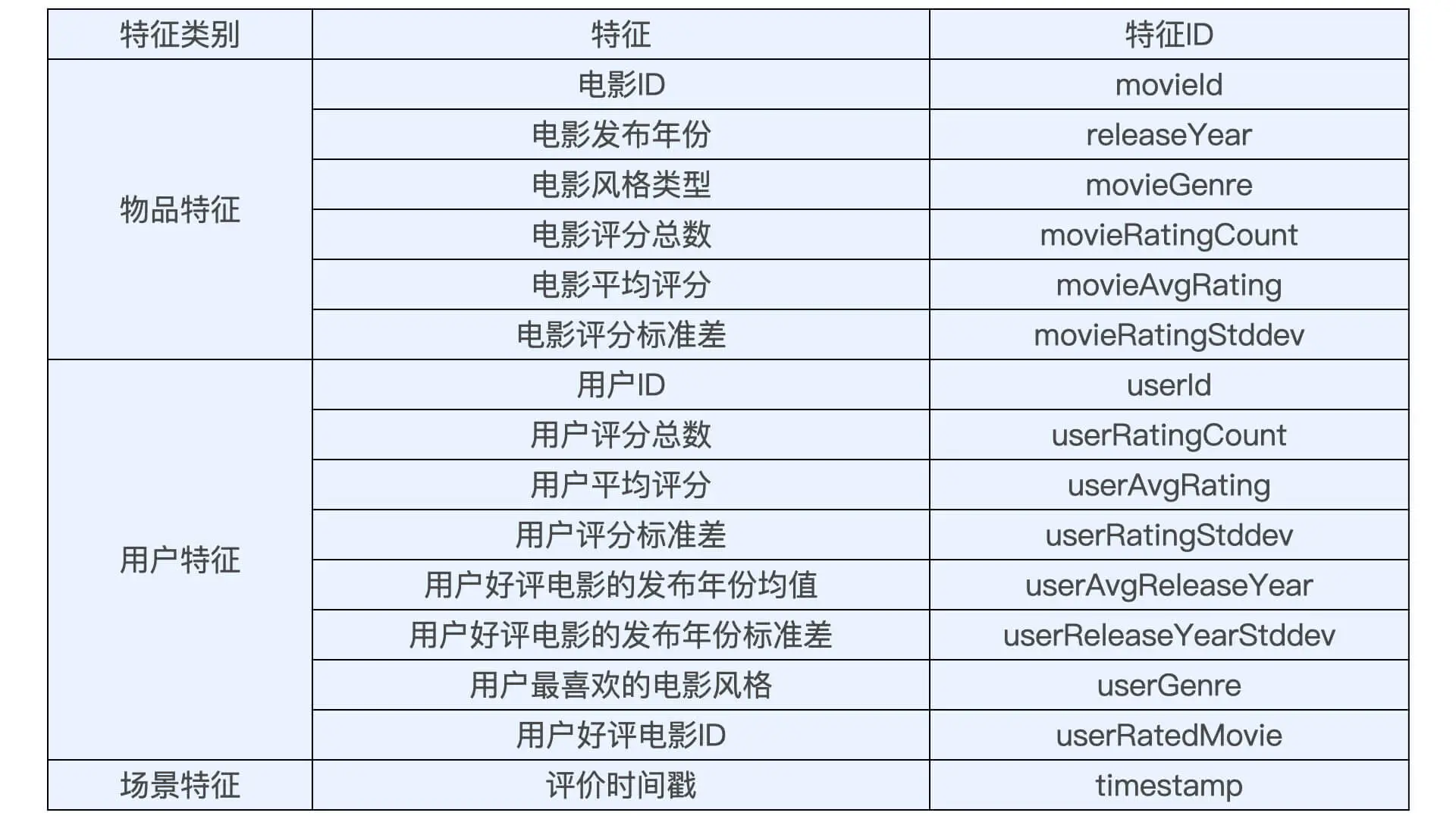
训练样本是什么样的?对于一个推荐模型来说,它的根本任务是预测一个用户 U 对一个物品 I 在场景 C 下的喜好分数。所以在训练时,我们要为模型生成一组包含 U、I、C 的特征,以及最终真实得分的样本。
//读取原始ratings数据
val ratingSamples = spark.read.format("csv").option("header", "true").load(ratingsResourcesPath.getPath)
//添加样本标签
val ratingSamplesWithLabel = addSampleLabel(ratingSamples)
//添加物品(电影)特征
val samplesWithMovieFeatures = addMovieFeatures(movieSamples, ratingSamplesWithLabel)
//添加用户特征
val samplesWithUserFeatures = addUserFeatures(samplesWithMovieFeatures)
样本的标签是什么?对于 MovieLens 数据集来说,用户对电影的评分是最直接的标签数据,因为它就是我们想要预测的用户对电影的评价,所以 ratings 表中的 0-5 的评分数据自然可以作为样本的标签。但对于很多应用来说,我们基本上不可能拿到它们的评分数据,更多的是点击、观看、购买这些隐性的反馈数据,所以业界更多使用 CTR 预估这类解决二分类问题的模型去解决推荐问题。比如把评分大于等于 3.5 分的样本标签标识为 1,意为“喜欢”,评分小于 3.5 分的样本标签标识为 0,意为“不喜欢”。
特征的线上存储问题。我们把用户特征和物品特征分别存入 Redis,线上推断的时候,再把所需的用户特征和物品特征分别取出,拼接成模型所需的特征向量就可以了。
模型
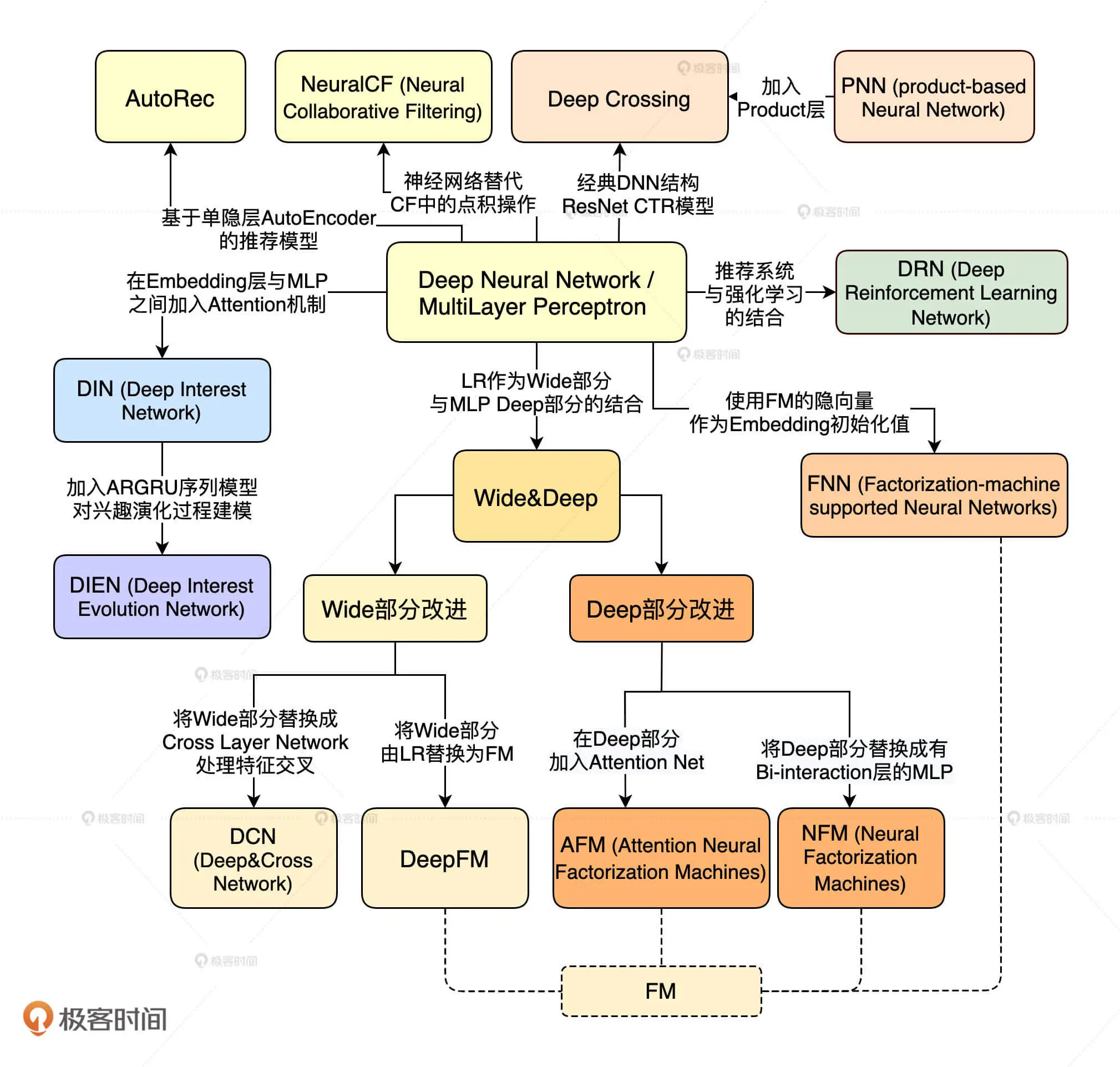
推荐场景下融合多模态信息的内容召回模型 未读 深度学习推荐模型的演化关系图
以Embedding+MLP 模型为例
Embedding+MLP 模型:对于类别特征,先利用 Embedding 层进行特征稠密化,再利用 Stacking 层连接其他特征,输入 MLP 的多层结构,最后用 Scoring 层预估结果。embedding部分通过训练学习到特征的表示,而MLP/DNN部分基于输入embedding来预估分数。
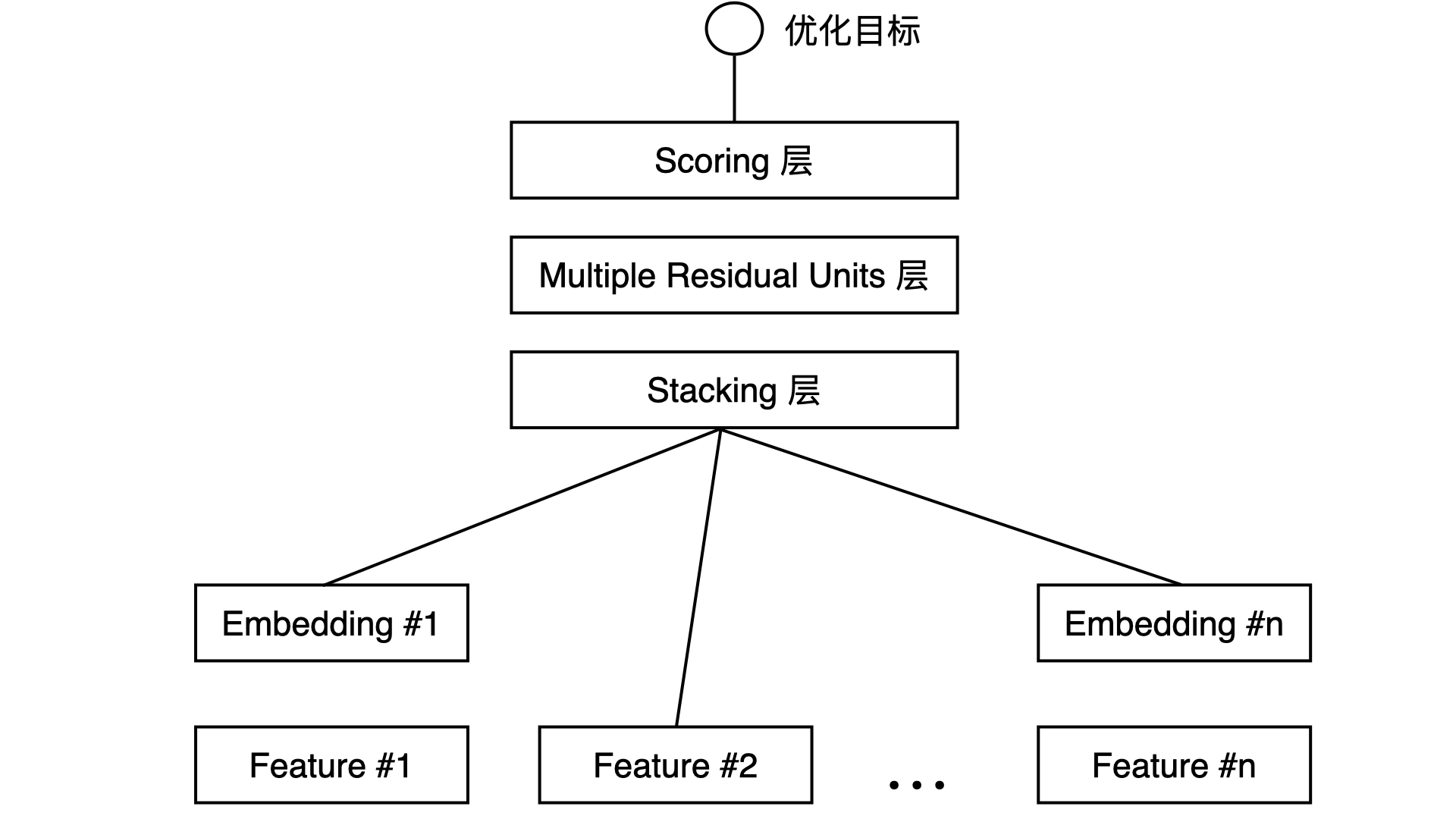
Feature#1 代表的是类别型特征经过 One-hot 编码后生成的特征向量,而 Feature#2 代表的是数值型特征。我们知道,One-hot 特征太稀疏了,不适合直接输入到后续的神经网络中进行训练,所以我们需要通过连接到 Embedding 层的方式,把这个稀疏的 One-hot 向量转换成比较稠密的 Embedding 向量。
Stacking 层中文名是堆叠层,我们也经常叫它连接(Concatenate)层。它的作用比较简单,就是把不同的 Embedding 特征和数值型特征拼接在一起,形成新的包含全部特征的特征向量。
MLP 层的特点是全连接,就是不同层的神经元两两之间都有连接(其基本形式就是矩阵乘法Matmul、矩阵加法BiasAdd及激活函数LeakyRelu)。作用是让特征向量不同维度之间做充分的交叉,让模型能够抓取到更多的非线性特征和组合特征的信息。
samples_file_path = tf.keras.utils.get_file("modelSamples.csv", TRAIN_DATA_URL)
# 载入训练数据
def get_dataset(file_path):
dataset = tf.data.experimental.make_csv_dataset( file_path, batch_size=12, label_name='label', na_value="?", num_epochs=1, ignore_errors=True)
return dataset
raw_samples_data = get_dataset(samples_file_path)
test_dataset = raw_samples_data.take(1000)
train_dataset = raw_samples_data.skip(1000)
# 载入类别型特征,分别是 genre、userId 和 movieId
genre_vocab = ['Film-Noir', 'Action', 'Adventure', 'Horror', 'Romance', 'War', 'Comedy', 'Western', 'Documentary',
'Sci-Fi', 'Drama', 'Thriller',
'Crime', 'Fantasy', 'Animation', 'IMAX', 'Mystery', 'Children', 'Musical']
GENRE_FEATURES = {
'userGenre1': genre_vocab,
'userGenre2': genre_vocab,
'userGenre3': genre_vocab,
'userGenre4': genre_vocab,
'userGenre5': genre_vocab,
'movieGenre1': genre_vocab,
'movieGenre2': genre_vocab,
'movieGenre3': genre_vocab
}
categorical_columns = []
for feature, vocab in GENRE_FEATURES.items():
cat_col = tf.feature_column.categorical_column_with_vocabulary_list(
key=feature, vocabulary_list=vocab)
emb_col = tf.feature_column.embedding_column(cat_col, 10)
categorical_columns.append(emb_col)
movie_col = tf.feature_column.categorical_column_with_identity(key='movieId', num_buckets=1001)
movie_emb_col = tf.feature_column.embedding_column(movie_col, 10)
categorical_columns.append(movie_emb_col)
user_col = tf.feature_column.categorical_column_with_identity(key='userId', num_buckets=30001)
user_emb_col = tf.feature_column.embedding_column(user_col, 10)
categorical_columns.append(user_emb_c)
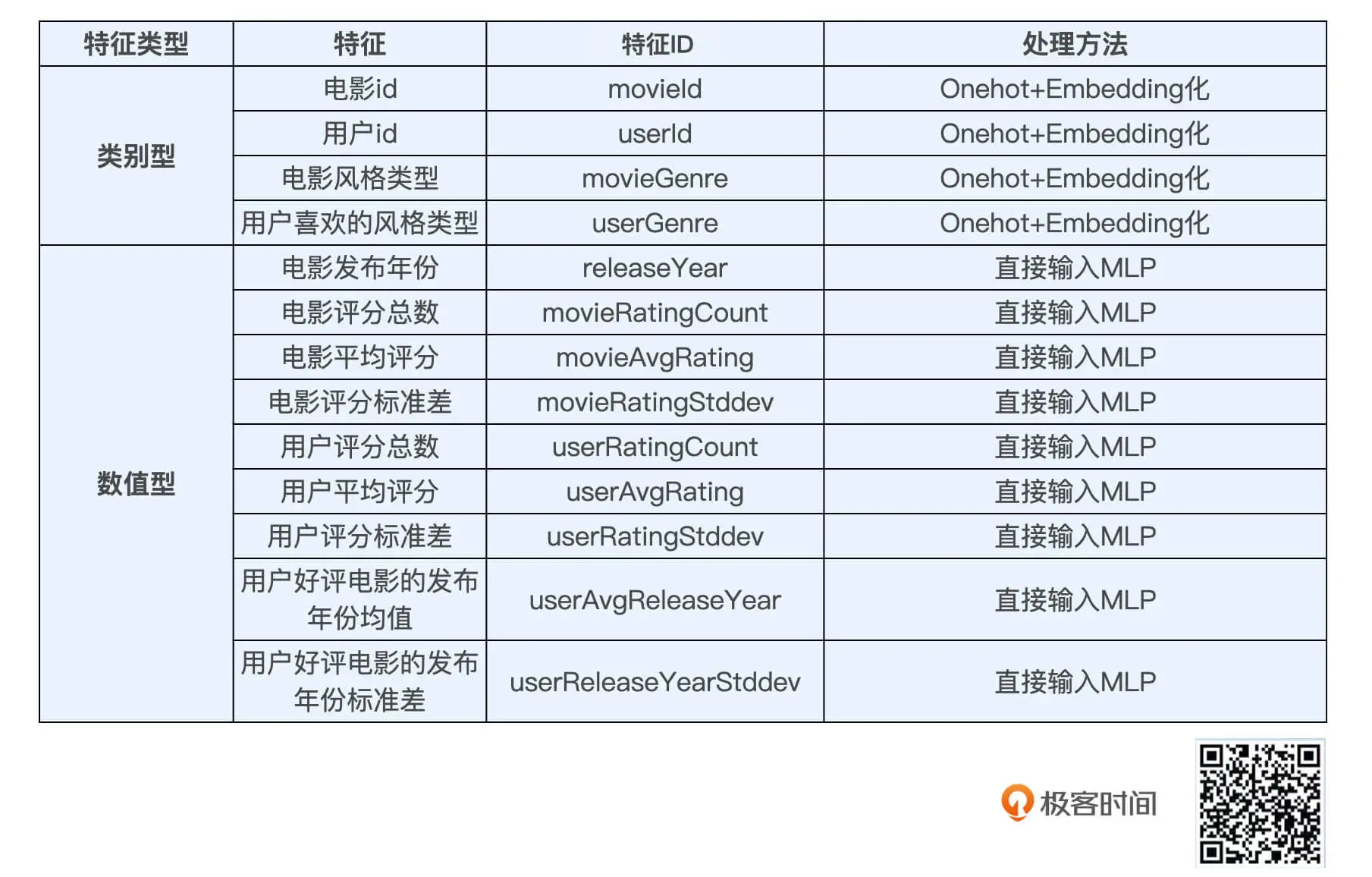
# 数值型特征的处理
numerical_columns = [tf.feature_column.numeric_column('releaseYear'),
tf.feature_column.numeric_column('movieRatingCount'),
tf.feature_column.numeric_column('movieAvgRating'),
tf.feature_column.numeric_column('movieRatingStddev'),
tf.feature_column.numeric_column('userRatingCount'),
tf.feature_column.numeric_column('userAvgRating'),
tf.feature_column.numeric_column('userRatingStddev')]
# 定义模型结构
preprocessing_layer = tf.keras.layers.DenseFeatures(numerical_columns + categorical_columns)
model = tf.keras.Sequential([
preprocessing_layer,
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid'),
])
# 定义模型训练相关的参数
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])
# 模型的训练和评估
model.fit(train_dataset, epochs=10)
test_loss, test_accuracy = model.evaluate(test_dataset)
print('\n\nTest Loss {}, Test Accuracy {}'.format(test_loss, test_accuracy)
技术架构
以猜你喜欢为例
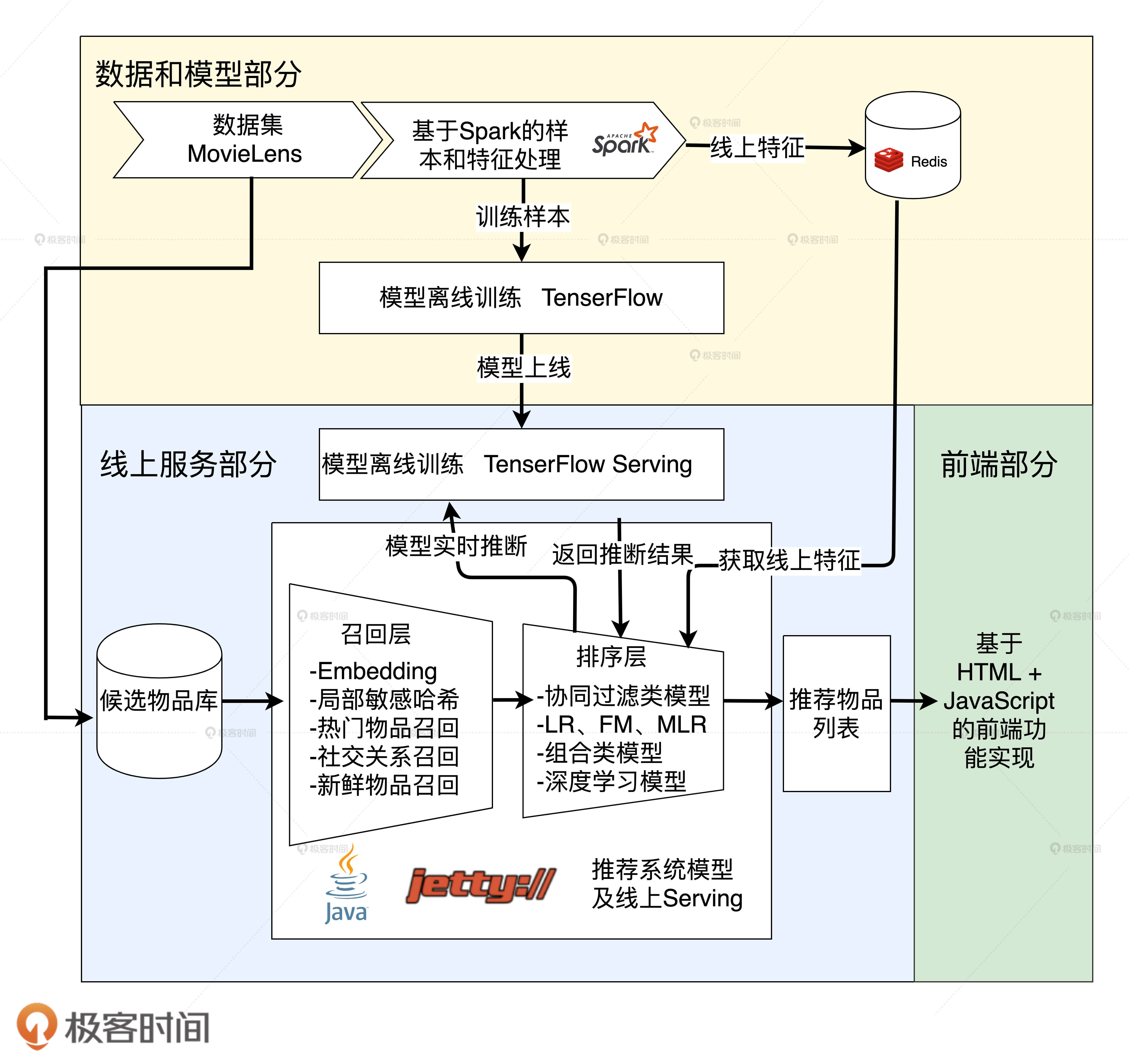
- 数据集 MovieLens经过 Spark 的处理之后,会生成两部分数据,分别从两个出口出去,特征部分会存入 Redis 供线上推断时推荐服务器使用,样本部分则提供给 TensorFlow 训练模型。
- TensorFlow 完成模型训练之后,会导出模型文件,然后模型文件会载入到 TensorFlow Serving 中,接着 TensorFlow Serving 会对外开放模型服务 API,供推荐服务器调用。
- 基于 MovieLens 数据集生成的候选电影集合会依次经过候选物品获取、召回层、排序层这三步,最终生成“猜你喜欢”的电影推荐列表,然后返回给前端,前端利用 HTML 和 JavaScript 把它们展示给用户。
排序层排序过程可以分为三个部分:
- 准备线上推断所需的特征,拼接成 JSON 格式的特征样本;
public static void callNeuralCFTFServing(User user, List<Movie> candidates, HashMap<Movie, Double> candidateScoreMap){ if (null == user || null == candidates || candidates.size() == 0){ return; } //保存所有样本的JSON数组 JSONArray instances = new JSONArray(); for (Movie m : candidates){ JSONObject instance = new JSONObject(); //为每个样本添加特征,userId和movieId instance.put("userId", user.getUserId()); instance.put("movieId", m.getMovieId()); instances.put(instance); } JSONObject instancesRoot = new JSONObject(); instancesRoot.put("instances", instances); //请求TensorFlow Serving API String predictionScores = asyncSinglePostRequest("http://localhost:8501/v1/models/recmodel:predict", instancesRoot.toString()); //获取返回预估值 JSONObject predictionsObject = new JSONObject(predictionScores); JSONArray scores = predictionsObject.getJSONArray("predictions"); //将预估值加入返回的map for (int i = 0 ; i < candidates.size(); i++){ candidateScoreMap.put(candidates.get(i), scores.getJSONArray(i).getDouble(0)); } } - 把所有候选物品的特征样本批量发送给 TensorFlow Serving API;
- 根据 TensorFlow Serving API 返回的推断得分进行排序,生成推荐列表。
我们应该怎么把用户最近的高分电影评价历史,实时反映到推荐结果上呢?其实很简单,我们的用户 Embedding 是通过平均用户的高分电影 Embedding 得到的,我们只需要在得到新的高分电影后,实时地更新用户 Embedding 就可以了,然后在推荐过程中,用户的推荐列表自然会发生实时的变化。PS: 实时计算更新 用户特征(也就是同一个用户,因为最新的数据灌入,模型输入不同了,而不是去改模型参数)
冷启动
冷启动是推荐系统一定要考虑的问题。它是指推荐系统在没有可用信息,或者可用信息很少的情形下怎么做推荐的问题,冷启动可以分为用户冷启动和物品冷启动两类。
用户冷启动是指用户没有可用的行为历史情况下的推荐问题。一般来说,我们需要清楚在没有推荐历史的情况下,还有什么用户特征可以使用,比如注册时的信息,访问 APP 时可以获得的地点、时间信息等等,根据这些有限的信息,我们可以为用户做一个聚类,为每类冷启动用户返回合适的推荐列表。当然,我们也可以利用可用的冷启动特征,来构建一个较简单的冷启动推荐模型,去解决冷启动问题。
对于物品冷启动来说,主要处理的是新加入系统的物品,它们没有跟用户的交互信息。所以,针对物品冷启动,我们除了用类似用户冷启动的方式解决它以外,还可以通过物品分类等信息找到一些相似物品,如果这些相似物品已经具有了预训练的 Embedding,我们也可以采用相似物品 Embedding 平均的方式,来快速确定冷启动物品的 Embedding,让它们通过 Embedding 的方式参与推荐过程。
评估体系
假设,现在有 30 个待筛选的模型,如果所有模型都直接进入线上 A/B 测试的阶段进行测试,所需的测试样本是海量的,由于线上流量有限,测试的时间会非常长。但如果我们把测试分成两个阶段,第一个阶段先进行初筛,把 30 个模型筛选出可能胜出的 5 个,再只对这 5 个模型做线上 A/B 测试,所需的测试流量规模和测试时间长度都会大大减少。这里的初筛方法,就是我们在评估体系中提到的离线评估、离线 Replay 和在线 Interleaving 等方法。
推荐
LLM在电商推荐系统的探索与实践 值得细读
华为:大语言模型在推荐系统的实践应用聚焦在两块,一是如何用语言模型来丰富用户特征的表征,二是如何用语言模型来丰富物品特征的表征。
推荐系统
- 采用两阶段方式融入大模型大模型负责生产知识,这些知识以结构化形式或以文本形式存储;第二阶段,推荐模型消费这些由大模型生产出的知识图谱,实现推荐。
- 通过蒸馏技术,将大模型如 ChatGPT 的推理能力逐步转移到更轻量级的模型,如 LLAMA 及序列模型,最终部署这些轻量级的模型到线上,实现效果和计算开销的平衡。
- 核心还是让大模型来提供推理知识,但并不需要为每个用户生成推理知识,而是只需要一个核心的种子用户群,为其生成推理知识,其他用户只需要检索种子用户池,生成所有用户的 embedding,线上模型只要 serving 这种 embedding 即可。
其它
推荐工程系统架构演进 偏中工程问题的梳理和解决

留下评论