机器学习中的python调用c
简介
作为一种解释型的语言,Python的速度并不算慢。如果对速度有很高的要求的话,可以选择用更快的语言实现,比如C或C++,然后用Python调用。Python的一种常见应用场景是实现高级的逻辑。Python的解释器就是用C语言写的,即CPython。解释器将Python转换成一种中间语言,叫做Python字节码,类似于汇编语言,但是包含一些更高级的指令。当一个运行一个Python程序的时候,评估循环不断将Python字节码转换成机器码。解释型语言的好处是方便编程和调试,但是程序的运行速度慢。其中的一种解决办法是,用C语言实现一些第三方的库,然后在Python中使用。另一种方法是使用即时编译器来替换Cpython,例如PyPy,PyPy对代码生成和Python的运行速度做了优化。
python 是解释型语言,性能是瓶颈。实现混合编程的方式
- 使用ctypes 库加载c++编写的动态链接库
- 使用pybind 将c++编译为python库
- 使用pythran库 将python直接转换为C++代码
跨语言调用,有几个问题
- 一些要素 在跨语言间的对应关系,比如c++ 的对象、函数、全局变量。c++ 函数 暴露到 python 成为 一个模块下的函数,c++ 对象则暴露为 一个python 对象。 比如在jna 中,c++ 函数会被暴露为 一个接口的方法,jna 负责提供这个接口的实现。
- 常见的类型(作为参数的时候) 如何跨语言打通,比如string、vector、map以及指针
tf 从swig 切到了pybind11。
双引擎 GPU 容器虚拟化,用户态和内核态的技术解析和实践分享典型的 AI 软硬件生态都分为这样几个层次 ——应用 & 框架层,运行时层,驱动层,硬件层。最上层是用户的应用,这里包含了各种常见的框架 PaddlePaddle、TensorFlow、PyTorch 等等。在应用层之下是硬件提供商封装的 API 接口层:包含各类常用算子库与硬件运行时访问接口。
swig
tf 早期通过swig 实现python 调用c
- 在 pywrap_tensorflow_internal.cc 的实现中,静 态注册了一个函数符号表,实现了 Python 函数名到 C 函数名的二元关系。
- _pywrap_tensorflow_internal.so 包 含了整个 TensorFlow 运行时的所有符号。
- pywrap_tensorflow_internal.py 模块首次被导入时,自动地加载 _pywrap_tensorflow_internal.so 的动态链接库
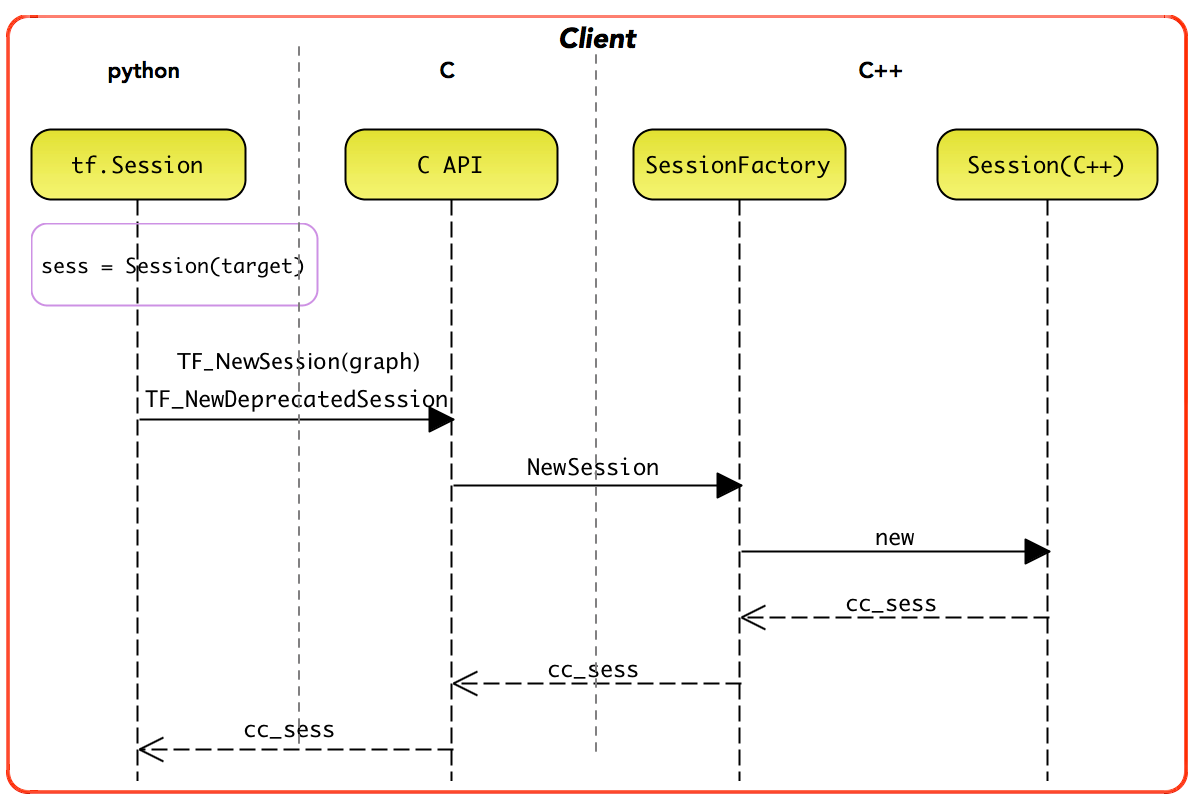
- 在运行时,按 照 Python 的函数名称,匹配找到对应的 C 函数实现,最终实现 Python 到 c_api.c 具体 实现的调用关系。c_api.h 是 TensorFlow 的后端执行系统面向前端开放的公共 API 接口。
Client 存在部分 C++ 实现,即 tensorflow::Session。其中,tf.Session 实例直接持有 tensorflow::Session 实例的句柄。一般地,用户使用的是 tf.Session 实施编程
pybind11
动手学深度学习框架(2)- python 端如何调用 c++ 的代码
pybind11 是一个轻量级的只包含头文件(header-only)的 c++ 库,用于将 c++ 代码暴露给 python 调用,(反之亦可,但主要还是前者)。即能够在 C++ 和 Python 之间自由转换,任意翻译两者的语言要素,比如把 C++ 的 vector 转换为 Python 的列表,把 Python 的元组转换为 C++ 的 tuple,既可以在 C++ 里调用 Python 脚本,也可以在 Python 里调用 C++ 的函数、类。pybind11 名字里的“11”表示它完全基于现代 C++ 开发(C++11 以上),它使用了大量的现代 C++ 特性,不仅代码干净整齐,运行效率也更高。
简单调用c++函数
#include <pybind11/pybind11.h> // pybind11的头文件
double add(double a, double b) { return a + b; }
// PYBIND11_MODULE 是一个宏,实现一个 Python 扩展模块
PYBIND11_MODULE(pydemo, m){ // 定义Python模块pydemo,之后在 Python 脚本里必须用这个名字才能 import。m其实是 pybind11::module 的一个实例对象,它只是个普通的变量,起什么名字都可以,但为了写起来方便,一般都用“m”。
m.doc() = "pybind11 demo doc"; // 模块的说明文档
m.def("add", &add); // def函数,传递一个 Python 函数名和 C++ 的函数、函数对象或者是 lambda 表达式
} // Python模块定义结束
假设这个 C++ 源文件名是“pybind.cpp”,用 g++ 把它编译成在 Python 里调用的模块,生成一个大概这样的文件:pydemo.cpython-35m-x86_64-linux-gnu.so
g++ pybind.cpp \ #编译的源文件
-std=c++11 -shared -fPIC \ #编译成动态库
`python3 -m pybind11 --includes` \ #获得 pybind11 所在的包含路径,让 g++ 能够找得到头文件
-o pydemo`python3-config --extension-suffix` #生成的动态库名字,前面必须是源码里的模块名,而后面那部分则是 Python 要求的后缀名
之后就可以在python 中使用
import pydemo
x = pydemo.add(1,2)
print(x)
c++并发+异步
复杂一点,给一个c++后端异步、并发处理的效果
// 全局任务表
static std::vector<std::future<double>> TASKS;
static std::mutex M;
int add_async(double a, double b) {
std::lock_guard<std::mutex> g(M);
int id = static_cast<int>(TASKS.size());
TASKS.emplace_back(std::async(std::launch::async, [=]{
// 模拟计算耗时
std::this_thread::sleep_for(std::chrono::milliseconds(100));
return a + b;
}));
return id;
}
// 等待所有任务完成并返回结果
std::vector<double> wait_all() {
py::gil_scoped_release release; // 等待期间释放 GIL
std::vector<std::future<double>> local;
{
std::lock_guard<std::mutex> g(M);
local.swap(TASKS);
}
std::vector<double> results;
results.reserve(local.size());
for (auto &f : local) results.push_back(f.get());
return results;
}
PYBIND11_MODULE(myops, m) {
m.doc() = "Async add backend (Python fires sequentially, C++ runs concurrently)";
m.def("add", &add_async, "Submit async add task, return task ID");
m.def("wait_all", &wait_all, "Wait all tasks and return results");
}
python 使用
import time, myops
t0 = time.time()
# Python 单线程顺序触发四次 add()
for i in range(4):
myops.add(i, i * 10) # 每次立即返回,不阻塞
# 等待所有任务完成
results = myops.wait_all()
print(f"results={results}, elapsed={time.time() - t0:.3f}s")
算子+Dispatcher机制
/ 假设所有算子都是 double(double,double)
using Kernel = std::function<double(double,double)>;
// 全局注册表: op_name -> kernel_func
static std::unordered_map<std::string, Kernel> registry;
// 注册一个算子实现,比如 "add"
void register_op(const std::string& name, Kernel fn) {
registry[name] = std::move(fn);
}
// 调用算子(分发)
double run_op(const std::string& name, double a, double b) {
auto it = registry.find(name);
if (it == registry.end()) {
throw std::runtime_error("No op registered: " + name);
}
return it->second(a, b);
}
// 提供一个 add 算子注册入口
void init_ops() {
register_op("add", [](double a, double b) {
std::cout << "[C++] executing add(" << a << "," << b << ")\n";
return a + b;
});
register_op("mul", [](double a, double b) {
std::cout << "[C++] executing mul(" << a << "," << b << ")\n";
return a * b;
});
}
PYBIND11_MODULE(myops_dispatch_cpu, m) {
m.doc() = "Mini dispatcher (single CPU backend)";
init_ops(); // 启动时注册算子
m.def("run_op", &run_op, "Run an op by name, e.g. run_op('add',3,4)");
}
算子若是关联backend(cpu,gpu) 就类似pytorch 多后端机制了。
y = ops.run_op("add", i, i * 10)
y = ops.run_op("mul", i, i * 10)
重载python 运算符
class Scalar {
public:
double v;
explicit Scalar(double x) : v(x) {}
// C++ 加法:Scalar + Scalar
Scalar operator+(const Scalar& other) const {
return Scalar(v + other.v);
}
// C++ 加法:Scalar + double(可选,方便 radd 复用)
Scalar add_scalar(double x) const { return Scalar(v + x); }
};
PYBIND11_MODULE(overload_ops, m) {
py::class_<Scalar>(m, "Scalar")
.def(py::init<double>())
.def_readwrite("v", &Scalar::v)
// Python: a + b (a、b 都是 Scalar)
.def("__add__", [](const Scalar& a, const Scalar& b){
return a + b;
})
// Python: x + a (x 是 float/int,a 是 Scalar)
.def("__radd__", [](const Scalar& a, py::object x){
if (py::isinstance<py::float_>(x) || py::isinstance<py::int_>(x)) {
return a.add_scalar(py::float_(x).cast<double>());
}
throw std::runtime_error("Unsupported type for +");
})
// print时会用上
.def("__repr__", [](const Scalar& s){
return "Scalar(" + std::to_string(s.v) + ")";
});
}
python 使用
import overload_ops as ops
a = ops.Scalar(1.5)
b = ops.Scalar(2.0)
print(a + b) # -> Scalar(3.500000...)
print(3.0 + a) # -> Scalar(4.500000...)
print(a.v) # 1.5 (a 未被修改,非就地)
PyTorch 的 torch.Tensor 在 Python 层其实只是包了一层壳,真正的底层对象是一个 C++ class。
异步 Scalar
class Scalar {
public:
// 构造“立即有值”的 Scalar
explicit Scalar(double x) : state_(std::make_shared<State>()) {
// 立即就绪的 future:用 packaged_task 立即 set
std::promise<double> p;
p.set_value(x);
state_->fut = p.get_future().share();
}
// Python 仍然可以 a.v 读取;读取时若尚未完成,会等待(期间释放 GIL)
double get_value() const {
py::gil_scoped_release rel; // 等待期间不阻塞 Python
return state_->fut.get();
}
// 友好打印:按需取值,必要时等待
std::string repr() const {
double x = get_value();
return "Scalar(" + std::to_string(x) + ")";
}
// Scalar + Scalar :异步提交一个“加法任务”
Scalar operator+(const Scalar& other) const {
auto next = Scalar::from_future(std::async(std::launch::async, [s1=state_, s2=other.state_]() {
// 这里在工作线程里等待两个输入值(不阻塞 Python 主线程)
double a = s1->fut.get();
double b = s2->fut.get();
// 模拟一点耗时,观感更像“后台干活”
std::this_thread::sleep_for(std::chrono::milliseconds(50));
return a + b;
}).share());
return next;
}
// Scalar + double(给 __radd__ 复用)
Scalar add_scalar(double x) const {
auto next = Scalar::from_future(std::async(std::launch::async, [s=state_, x]() {
double a = s->fut.get();
std::this_thread::sleep_for(std::chrono::milliseconds(30));
return a + x;
}).share());
return next;
}
private:
struct State {
std::shared_future<double> fut;
};
std::shared_ptr<State> state_;
// 私有辅助:从 future 构造一个“异步 Scalar”
static Scalar from_future(std::shared_future<double> f) {
Scalar out(0.0); // 先随便建一个
out.state_ = std::make_shared<State>();
out.state_->fut = std::move(f);
return out;
}
public:
// --- pybind11 绑定 ---
static void bind(py::module& m) {
py::class_<Scalar>(m, "Scalar")
.def(py::init<double>(), py::arg("x"))
// 改成只读属性 v(示例里只读不写,保持 Python 侧用法不变)
.def_property_readonly("v", &Scalar::get_value,
"Get the (possibly async-computed) value; waits if needed")
// Python: a + b(两个 Scalar)
.def("__add__", [](const Scalar& a, const Scalar& b) {
return a + b;
})
// Python: x + a(标量在左,Scalar 在右)
.def("__radd__", [](const Scalar& a, py::object x) {
if (py::isinstance<py::float_>(x) || py::isinstance<py::int_>(x)) {
return a.add_scalar(py::float_(x).cast<double>());
}
throw std::runtime_error("Unsupported type for +");
})
.def("__repr__", &Scalar::repr);
}
};
PYBIND11_MODULE(overload_ops, m) {
m.doc() = "Scalar with async + operator (minimal lazy/async demo)";
Scalar::bind(m);
}
a + b 会“立刻返回一个结果对象”,print时才会等那 50ms;
import overload_ops as ops
a = ops.Scalar(1.5)
b = ops.Scalar(2.0)
print(a + b) # -> 会打印 Scalar(3.5),内部在 __repr__ 处等待一次
print(3.0 + a) # -> Scalar(4.5),同理
print(a.v) # -> 1.5(a 本身是立即可用的 Scalar)
加个队列
class TaskQueue {
public:
using Job = std::function<void()>;
TaskQueue() : stop_(false), pending_(0) {
worker_ = std::thread([this]{ // 单工作线程
for (;;) {
Job job;
{
std::unique_lock<std::mutex> lk(mu_);
cv_.wait(lk, [&]{ return stop_ || !q_.empty(); });
if (stop_ && q_.empty()) return;
job = std::move(q_.front());
q_.pop();
}
job(); // 执行任务
pending_.fetch_sub(1);
empty_cv_.notify_all(); // 通知可能的 flush 等待者
}
});
}
~TaskQueue() {
{
std::lock_guard<std::mutex> g(mu_);
stop_ = true;
}
cv_.notify_all();
if (worker_.joinable()) worker_.join();
}
void submit(Job j) {
pending_.fetch_add(1);
{
std::lock_guard<std::mutex> g(mu_);
q_.push(std::move(j));
}
cv_.notify_one();
}
// 等到队列所有任务完成
void flush() {
py::gil_scoped_release rel;
std::unique_lock<std::mutex> lk(mu_);
empty_cv_.wait(lk, [&]{ return q_.empty() && pending_.load()==0; });
}
std::size_t queue_size() const {
std::lock_guard<std::mutex> g(mu_);
return q_.size();
}
std::size_t pending() const { return (std::size_t)pending_.load(); }
private:
mutable std::mutex mu_;
std::condition_variable cv_;
std::condition_variable empty_cv_;
std::queue<Job> q_;
std::thread worker_;
std::atomic<int> pending_;
bool stop_;
};
// 全局单例队列
static TaskQueue& GLOBAL_Q() {
static TaskQueue Q;
return Q;
}
class Scalar {
public:
explicit Scalar(double x) : state_(std::make_shared<State>()) {
std::promise<double> p;
p.set_value(x); // 立即可用的值
state_->fut = p.get_future().share();
}
// 读取数值:如有未完成任务,会等待(释放 GIL)
double get_value() const {
py::gil_scoped_release rel;
return state_->fut.get();
}
std::string repr() const {
return "Scalar(" + std::to_string(get_value()) + ")";
}
// 异步:Scalar + Scalar => 入队一个任务,返回"未来的" Scalar
Scalar operator+(const Scalar& other) const {
std::promise<double> p;
auto fut = p.get_future().share();
Scalar out = Scalar::from_future(fut);
auto a_state = state_;
auto b_state = other.state_;
// 任务内容:等左右值 -> sleep 模拟耗时 -> set_value
GLOBAL_Q().submit([p=std::move(p), a_state, b_state]() mutable {
try {
double a = a_state->fut.get();
double b = b_state->fut.get();
std::this_thread::sleep_for(std::chrono::milliseconds(40)); // 模拟耗时
p.set_value(a + b);
} catch (...) {
// 异常传播到 future
p.set_exception(std::current_exception());
}
});
return out;
}
// 异步:Scalar + double(用于 __radd__)
Scalar add_scalar(double x) const {
std::promise<double> p;
auto fut = p.get_future().share();
Scalar out = Scalar::from_future(fut);
auto a_state = state_;
GLOBAL_Q().submit([p=std::move(p), a_state, x]() mutable {
try {
double a = a_state->fut.get();
std::this_thread::sleep_for(std::chrono::milliseconds(20));
p.set_value(a + x);
} catch (...) {
p.set_exception(std::current_exception());
}
});
return out;
}
private:
struct State {
std::shared_future<double> fut;
};
std::shared_ptr<State> state_;
static Scalar from_future(std::shared_future<double> f) {
Scalar s(0.0);
s.state_ = std::make_shared<State>();
s.state_->fut = std::move(f);
return s;
}
public:
// 绑定到 Python
static void bind(py::module& m) {
py::class_<Scalar>(m, "Scalar")
.def(py::init<double>())
.def_property_readonly("v", &Scalar::get_value,
"Get the (possibly async-computed) value; waits if needed")
.def("__add__", [](const Scalar& a, const Scalar& b){ return a + b; })
.def("__radd__", [](const Scalar& a, py::object x){
if (py::isinstance<py::float_>(x) || py::isinstance<py::int_>(x)) {
return a.add_scalar(py::float_(x).cast<double>());
}
throw std::runtime_error("Unsupported type for +");
})
.def("__repr__", &Scalar::repr);
}
};
// 模块导出:保持Python 侧用法不变,并额外提供队列工具函数
PYBIND11_MODULE(overload_ops, m) {
m.doc() = "Scalar + operator with global task queue (async enqueue + on-demand wait)";
Scalar::bind(m);
m.def("flush", [](){ GLOBAL_Q().flush(); }, "Wait until the global task queue is empty");
m.def("queue_size", [](){ return GLOBAL_Q().queue_size(); }, "Current queued jobs");
m.def("pending", [](){ return GLOBAL_Q().pending(); }, "Current running/queued jobs");
}
- 只有一个全局队列,单工作线程,任务按提交顺序执行
__add__/__radd__入队任务并立即返回一个“带 future 的 Scalar”。- 访问
.v或__repr__时才等待(用 py::gil_scoped_release 避免阻塞 Python) - 提供 flush()/queue_size()/pending() 便于调试与演示
import overload_ops as ops
import time
a = ops.Scalar(1.5)
b = ops.Scalar(2.0)
# 仍然可以像之前一样用 —— 底层会把加法入队,print 时触发取值等待
print(a + b) # -> Scalar(3.5)
print(3.0 + a) # -> Scalar(4.5)
print(a.v) # 1.5
# 也可以先提交很多,再一起等待
xs = [ops.Scalar(i) for i in range(5)]
ys = [ops.Scalar(10+i) for i in range(5)]
zs = [x + y for x, y in zip(xs, ys)] # 全部入队,立即返回“未来的” Scalar
print("queued:", ops.queue_size(), "pending:", ops.pending())
ops.flush() # 等队列清空
print([z.v for z in zs]) # 所有结果都已就绪
想再靠近 PyTorch:
- 把“单队列”升级为“多队列/多工作线程”(→ 类似 Stream 的效果);pytorch真实实现:CPU 用线程池并行,CUDA 用 kernel。
- 让 Scalar 携带“所属队列”,支持跨队列同步;
- 在队列中添加错误传播与取消逻辑。
以上述例子看,pytorch 基本上就是c++ 侧把 tensor、正向传播、反向传播实现了一遍,然后套了个python的壳儿。
固定线程池
// =============== 固定线程池(多工作线程) ===============
class ThreadPool {
public:
using Job = std::function<void()>;
explicit ThreadPool(unsigned num_threads = std::max(1u, std::thread::hardware_concurrency()))
: stop_(false), pending_(0)
{
workers_.reserve(num_threads);
for (unsigned i = 0; i < num_threads; ++i) {
workers_.emplace_back([this]{
for (;;) {
Job job;
{
std::unique_lock<std::mutex> lk(mu_);
cv_.wait(lk, [&]{ return stop_ || !q_.empty(); });
if (stop_ && q_.empty()) return;
job = std::move(q_.front());
q_.pop();
}
job(); // 执行任务
pending_.fetch_sub(1, std::memory_order_relaxed);
empty_cv_.notify_all(); // 通知 flush 等待者
}
});
}
}
~ThreadPool() {
{
std::lock_guard<std::mutex> g(mu_);
stop_ = true;
}
cv_.notify_all();
for (auto &t : workers_) if (t.joinable()) t.join();
}
void submit(Job j) {
pending_.fetch_add(1, std::memory_order_relaxed);
{
std::lock_guard<std::mutex> g(mu_);
q_.push(std::move(j));
}
cv_.notify_one();
}
// 等到队列与正在执行的任务都清空
void flush() {
py::gil_scoped_release rel;
std::unique_lock<std::mutex> lk(mu_);
empty_cv_.wait(lk, [&]{ return q_.empty() && pending_.load(std::memory_order_relaxed) == 0; });
}
std::size_t queue_size() const {
std::lock_guard<std::mutex> g(mu_);
return q_.size();
}
std::size_t pending() const {
return static_cast<std::size_t>(pending_.load(std::memory_order_relaxed));
}
private:
mutable std::mutex mu_;
std::condition_variable cv_;
std::condition_variable empty_cv_;
std::queue<Job> q_;
std::vector<std::thread> workers_;
std::atomic<int> pending_;
bool stop_;
};
// 全局固定线程池
static ThreadPool& GLOBAL_POOL() {
static ThreadPool P; // 默认使用 hardware_concurrency() 个线程(至少 1)
return P;
}
// =============== 与之前一致的 Scalar(异步 +) ===============
class Scalar {
public:
explicit Scalar(double x) : state_(std::make_shared<State>()) {
std::promise<double> p;
p.set_value(x); // 立即可用
state_->fut = p.get_future().share();
}
double get_value() const {
py::gil_scoped_release rel;
return state_->fut.get();
}
std::string repr() const {
return "Scalar(" + std::to_string(get_value()) + ")";
}
// 异步:Scalar + Scalar => 提交到固定线程池
Scalar operator+(const Scalar& other) const {
std::promise<double> p;
auto fut = p.get_future().share();
Scalar out = Scalar::from_future(fut);
auto a_state = state_;
auto b_state = other.state_;
GLOBAL_POOL().submit([p = std::move(p), a_state, b_state]() mutable {
try {
double a = a_state->fut.get();
double b = b_state->fut.get();
std::this_thread::sleep_for(std::chrono::milliseconds(40)); // 模拟耗时
p.set_value(a + b);
} catch (...) {
p.set_exception(std::current_exception());
}
});
return out;
}
// 异步:Scalar + double(用于 __radd__)
Scalar add_scalar(double x) const {
std::promise<double> p;
auto fut = p.get_future().share();
Scalar out = Scalar::from_future(fut);
auto a_state = state_;
GLOBAL_POOL().submit([p = std::move(p), a_state, x]() mutable {
try {
double a = a_state->fut.get();
std::this_thread::sleep_for(std::chrono::milliseconds(20)); // 模拟耗时
p.set_value(a + x);
} catch (...) {
p.set_exception(std::current_exception());
}
});
return out;
}
private:
struct State { std::shared_future<double> fut; };
std::shared_ptr<State> state_;
static Scalar from_future(std::shared_future<double> f) {
Scalar s(0.0);
s.state_ = std::make_shared<State>();
s.state_->fut = std::move(f);
return s;
}
public:
static void bind(py::module& m) {
py::class_<Scalar>(m, "Scalar")
.def(py::init<double>())
.def_property_readonly("v", &Scalar::get_value, "Get the (possibly async) value")
.def("__add__", [](const Scalar& a, const Scalar& b){ return a + b; })
.def("__radd__", [](const Scalar& a, py::object x){
if (py::isinstance<py::float_>(x) || py::isinstance<py::int_>(x))
return a.add_scalar(py::float_(x).cast<double>());
throw std::runtime_error("Unsupported type for +");
})
.def("__repr__", &Scalar::repr);
}
};
// =============== 模块导出(工具函数名保持一致) ===============
PYBIND11_MODULE(overload_ops, m) {
m.doc() = "Scalar + operator with fixed thread pool (async + on-demand wait)";
Scalar::bind(m);
m.def("flush", [](){ GLOBAL_POOL().flush(); }, "Wait until all jobs are finished");
m.def("queue_size", [](){ return GLOBAL_POOL().queue_size(); }, "Jobs waiting in queue");
m.def("pending", [](){ return GLOBAL_POOL().pending(); }, "Running + queued jobs");
}
a = ops.Scalar(1.5)
b = ops.Scalar(2.0)
# 立即返回一个“未来的” Scalar,不阻塞
z = a + b
print("立即返回:", z) # 会触发取值等待(内部 __repr__ 时才真正等待)
print("结果值:", z.v) # 显式取值
计算梯度
class Grad {
public:
double val;
explicit Grad(double v = 0.0) : val(v) {}
};
class Scalar {
public:
double v; // 前向值
double grad = 0.0; // 累积梯度
// 边:指向父节点 + 对应的梯度(乘法时即另一侧的前向值)
struct Edge {
Scalar* parent;
Grad grad;
};
std::vector<Edge> edges; // 每个Scalar持有一组入边(Edges),指向它的“父节点”
explicit Scalar(double value = 0.0) : v(value) {}
// 前向:z = a * b
Scalar operator*(const Scalar& other) const {
Scalar out(v * other.v);
// 局部梯度:dz/da = b, dz/db = a
out.edges.push_back(Edge{ const_cast<Scalar*>(this), Grad(other.v) });
out.edges.push_back(Edge{ const_cast<Scalar*>(&other), Grad(this->v) });
return out;
}
// out = sin(a)
Scalar sin() const {
Scalar out(std::sin(v));
out.edges.push_back(Edge{ const_cast<Scalar*>(this), Grad(std::cos(v)) }); // dout/da = cos(a)
return out;
}
// 反向传播:累积上游梯度 * 本边的 grad
void backward(double grad_out = 1.0) {
grad += grad_out;
for (auto &e : edges) {
e.parent->backward(grad_out * e.grad.val); // 链式触发了上游所有backward
}
}
std::string repr() const {
return "Scalar(v=" + std::to_string(v) + ", grad=" + std::to_string(grad) + ")";
}
static void bind(py::module& m) {
py::class_<Grad>(m, "Grad")
.def(py::init<double>())
.def_readwrite("val", &Grad::val)
.def("__repr__", [](const Grad& g) {
return "Grad(" + std::to_string(g.val) + ")";
});
py::class_<Scalar>(m, "Scalar")
.def(py::init<double>())
.def_readwrite("v", &Scalar::v)
.def_readwrite("grad", &Scalar::grad)
.def("__mul__", [](const Scalar& a, const Scalar& b){ return a * b; })
.def("backward", &Scalar::backward, py::arg("grad_out") = 1.0)
.def("__repr__", &Scalar::repr);
}
};
PYBIND11_MODULE(scalar_mul_grad_class, m) {
m.doc() = "Autograd look-alike with explicit Grad class (only mul op)";
Scalar::bind(m);
}
PyTorch 没有显式维护一个“Graph类”。计算图是分布式、链式存储在每个 Tensor 的 autograd 元信息里的。Tensor(若由运算产生) 拥有指向上游 Function 的指针grad_fn,而 Function 拥有指向输入 Tensor 的 Edge 列表(next_edges,表示它在反向传播时要把梯度传递给哪些输入张量),这两者互相连接,自然构成一张隐式 Dynamic DAG,由成千上万个张量和函数之间的指针关系自然形成的,而不是集中式的数据结构。
a = ops.Scalar(2.0)
b = ops.Scalar(3.0)
c = ops.Scalar(4.0)
y = a * b * c
y.backward()
print("y =", y) # Scalar(v=24..., grad=1)
print("a.grad =", a.grad) # 12
print("b.grad =", b.grad) # 8
print("c.grad =", c.grad) # 6
PyTorch 的运行过程本质上是 Python 与 C++ 的交替协作。Python 负责图的构建、调度与封装接口;而一旦进入实际计算阶段,就会调用 C++/CUDA 实现的算子内核、内存管理器,以及诸如 NCCL、cuBLAS、cuDNN 等底层库完成真正的计算与通信。因此,PyTorch 的高性能来自这种分层设计——Python 负责组织,C/C++ 负责执行,两者在每一次算子或通信调用中高频交替,却又无缝衔接。
- Python 调度阶段,Python 代码层负责组织逻辑、调用接口(如 torch.distributed.init_process_group、torch.matmul 等)。
- 进入 C++ 层执行具体操作
- 调用 C++ backend(ATen / c10 / CUDA 内核) 实际执行算子计算。
- 若涉及 GPU 通信,则调用 NCCL / Gloo / MPI 等通信库。
- 若是张量运算,则调度 CUDA kernel(C++ → CUDA)。
- Python 回到控制权
- C++ 返回执行结果(例如一个新的 TensorImpl 指针)。
- Python 层封装为 torch.Tensor 对象,继续执行下一步逻辑。
- 再次进入 C++
- 例如执行反向传播时,Python 调 loss.backward(),随后自动进入 C++ 的 AutogradEngine,递归触发每个算子的 backward 内核。
算子设计
PS:其实如果使用c++ 来写推理或训练引擎的话,就没有python调用c这个复杂的事儿了。对于一个推理框架,大概可以理解为,
- 先基于onnx/pnnx等模型文件,自己提一套抽象比如RuntimeGraph等将模型权重、参数加载进来,然后按拓扑排序执行,执行到某个节点时,调用其对应的算子(为此有一个全局的算子注册机制),节点(Node或Operator)为算子准备入参、拿到出参。概念上从大到下是Graph ==> node/op ==> cuda 函数。
- 专用的推理框架入口是onnx/pnnx等模型文件,只需要graph、节点/等概念,不需要pytorch 中类似layer概念(那是为了编程上抽象复用的)。
- tensor/显存的申请、释放都是上层组件负责,会有一个DeviceAllocator(分别对应cpu和gpu)组件负责内存和显存的分配和释放、内存和显存之间的copy等接口(比如tensor.to_cuda。再复杂一点先提前申请一个大的,内部再复用一下),对DeviceAllocator封装后提供tensor对象(tensor持有DeviceAllocator 引用,初始化时调用DeviceAllocator.allocate,析构时调用DeviceAllocator.release)。只是给算子函数传入input/weight/output 指针,算子也分为cpu和gpu实现。 在深度学习中,算子通常指的是在神经网络中对数据执行数学运算的函数。这些运算可以是简单的,如加法、乘法,也可以是复杂的,如卷积、池化、归一化等。根据算子内部参数的有无,我们大致可以将算子分为两大类:
- 带参数的,例如卷积算子,全连接算子,rmsnorm算子等。PS: 加载模型的一个重要的活儿就是用模型权重去初始化各类带参数算子。
- 不带参数的,例如sigmoid算子,softmax算子等
算子基类
class BaseOP {
public:
explicit BaseOP(base::DeviceType device_type, OPType op_type,base::DataType data_type, std::string op_name = "");
base::DataType data_type() const;
OPType op_type() const;
...
...
const std::string& get_op_name() const; // 返回算子的名字
void set_op_name(const std::string& op_name); // 设置算子的名称
base::DeviceType device_type() const; // 返回层的设备类型
void set_device_type(base::DeviceType device_type);
virtual base::Status forward() = 0;
protected:
std::string op_name_; // 算子名
OPType OP_type_ = OPType::kOPUnknown; // 算子类型
base::DataType data_type_ = base::DataType::kDataTypeUnknown; // 数据类型 fp32 或fp16 或int8
base::DeviceType device_type_ = base::DeviceType::kDeviceUnknown; // 设备类型 cpu或gpu
};
不带参(权重)算子类的设计
class OP : public BaseOP {
public:
explicit OP(base::DeviceType device_type, OPType op_type,std::string op_name = "");
void set_input(int32_t idx, const tensor::Tensor& input) override; // 传入输入 ,需要指定这是该算子的第几个(idx)输入
void set_output(int32_t idx, const tensor::Tensor& output) override; // 传入输出
const tensor::Tensor& get_input(int32_t idx) const override; // 获取输入
const tensor::Tensor& get_output(int32_t idx) const override; // 获取输出
// 关于算子输入、输出张量的辅助函数
size_t input_size() const override; // 获取输入的个数
size_t output_size() const override; // 获取输出的个数
void reset_input_size(size_t size);
void reset_output_size(size_t size);
virtual void to_cuda();
private:
std::vector<tensor::Tensor> inputs_; // 存放输入的数组
std::vector<tensor::Tensor> outputs_; // 存放输出的数组
};
base::Status VecAddOP::forward() {
auto status = this->check();
if (!status) {
return status;
}
auto input1 = this->get_input(0);
auto input2 = this->get_input(1);
auto output = this->get_output(0);
if (device_type_ == base::DeviceType::kDeviceCUDA) {
CHECK(cuda_config_ != nullptr);
}
kernel::get_add_kernel(device_type_)(input1, input2, output,cuda_config_ ? cuda_config_->stream : nullptr);
return base::error::Success();
}
带参数的算子类,多了一个类内变量用于存储权重张量。
class OPFp32Param : public OP {
public:
explicit OPFp32Param(base::DeviceType device_type, OPType op_type,std::string op_name = "");
size_t weight_size() const;
void reset_weight_size(size_t size);
tensor::Tensor& get_weight(int32_t idx);
const tensor::Tensor& get_weight(int32_t idx) const;
void set_weight(int32_t idx, const tensor::Tensor& weight); // load model时设置权重便是靠set_weight
void set_weight(int32_t idx, const std::vector<int32_t>& dims, const float* weight_ptr,base::DeviceType device_type = base::DeviceType::kDeviceUnknown);
private:
std::vector<tensor::Tensor> weights_; // 用于额外存放权重数据
};
base::Status RmsNormOP::forward() { // 计算的时候
auto status = check();
if (!status) {
return status;
}
auto input = this->get_input(0);
auto weight = this->get_weight(0);
auto output = this->get_output(0);
// 得到一个具体的算子计算实现
kernel::get_rmsnorm_kernel(device_type_)(input, weight, output,cuda_config_ ? cuda_config_->stream : nullptr);
return base::error::Success();
}
所谓的load_model,一般先读取模型配置(或者是一个config.json 或者是model.bin 的前xx个字节,看模型格式?),这样知道模型有几层,hidden_dim 是多少,然后才是读取每层的权重(比如每层的weight 是顺序排在model.bin中,此时顺序读即可),最终将weight数据赋值给OP.weight(一个tensor对象)。
horovod
很多机器学习框架都会采用如下套路:shell脚本(可选),python端 和 C++端。
- Shell脚本是启动运行的入口,负责解析参数,确认并且调用训练程序;
- Python是用户的接口,引入了C++库,封装了API,负责运行时和底层C++交互;
- C++实现底层训练逻辑;
深度学习分布式训练框架 horovod (2) — 从使用者角度切入
引入库的作用是获取到 C++ 的函数,并且用 python 封装一下,这样就可以在 python 世界使用 C++代码了。比如下文,python 的 _allreduce 函数就会把功能转发给 C++,由 MPI_LIB.horovod_allreduce 完成。
def _allreduce(tensor, name=None, op=Sum, prescale_factor=1.0, postscale_factor=1.0,
ignore_name_scope=False):
if name is None and not _executing_eagerly():
name = 'HorovodAllreduce_%s' % _normalize_name(tensor.name)
return MPI_LIB.horovod_allreduce(tensor, name=name, reduce_op=op,
prescale_factor=prescale_factor,
postscale_factor=postscale_factor,
ignore_name_scope=ignore_name_scope)
## 初始化时执行
def _load_library(name):
"""Loads a .so file containing the specified operators.
"""
filename = resource_loader.get_path_to_datafile(name)
library = load_library.load_op_library(filename)
return library
# Check possible symbol not found error from tensorflow version mismatch
try:
MPI_LIB = _load_library('mpi_lib' + get_ext_suffix())
except Exception as e:
check_installed_version('tensorflow', tf.__version__, e)
raise e
else:
check_installed_version('tensorflow', tf.__version__)
留下评论