codereview
简介
Google对于编程规范的信仰,可能超出很多人的想象:每一个代码提交,类似于 Git 里 diff 的概念,都需要至少两次代码评审(code review),一次针对业务逻辑,一次针对可读性(readability review)。所谓的可读性评审,着重在代码风格规范上。只有通过考核的人,才能够成为可读性评审人(readability reviewer)。有大量的开发自动化工具,确保以上的准则得到强制实施。例如,代码提交前会有 linter 做静态规则检查,不通过是无法提交代码的。
平时,大家抬头看 PRD ,低头写代码,很少有时间静心气闲地交流一下业务流程、业务逻辑、业务未来扩展,在 CR 时,往往可以反复被讨论到。一个人的能力不是体现在解决了问题上,也不是发现了问题,而是利用某种手段预知问题并解决问题。
CR 不是互相看天书,而是产生天天看书的感觉,每一段写得好,写得不好的代码都是一本书,好的代码希望见贤思齐,差的代码希望见不贤而内自省也。总之, CR 是一种修行,也是一种自我积累,苦涩的是看到惨不忍堵的代码,心里说:我去!有意思的是看到优雅的代码,心里也说:我去!
业务跑得这么快,没有时间好好 CR ,总有时间焦头烂额地处理故障和投诉。
如果在同样的效果上,3 行代码能够实现功能的价值,就不应该用 4 行来实现。
良好的日志和异常机制,是不应该出现调试的。打日志和抛异常,一定要把上下文给出来,否则,等于在毁灭命案现场,把后边处理问题的人,往歪路上带。别人传一个参数进来,发现是 null ,立马抛出来一个参数异常提示,然后也不返回哪一个参数是 null ,这在调用参数很多的情况下,简直就是字谜游戏一样。到底是抛异常,还是抛错误码(没有错误码,只有错误内容。如果是人读还好,可是如果是写代码判断,就非常不友好)?我不管抛什么,反正错了什么东西,都应该透明出来。
多个 return 的语句,概率高的一定先进行判定。
感觉空行是廉价的,到处乱扔是一种;另一种是感觉空行是昂贵的,舍不得用,这种情况更多见。50 行代码没有一个空行,就像英语 50 句话,没有任何标点符号一样。既然标点符号起到隔断和语义区分作用,我们的空行不是同一个道理吗?在以下情形:
- 在方法的 return、break、continue、这样断开性语句后必须是空行。
- 在不同语义块之间。
- 循环之前和之后一般有空行。另外,方法和类定义下方就不需要空行了吧。
满天飞的函数式编程好吗?如果一个 stream 后边的调用超过 5 个,我觉得你是为了炫耀。
你的代码为谁而写
统一的编程规范为什么重要?用一句话来概括,统一的编程规范能提高开发效率。而开发效率,关乎三类对象,也就是阅读者、编程者和机器。他们的优先级是阅读者的体验 » 编程者的体验 » 机器的体验。
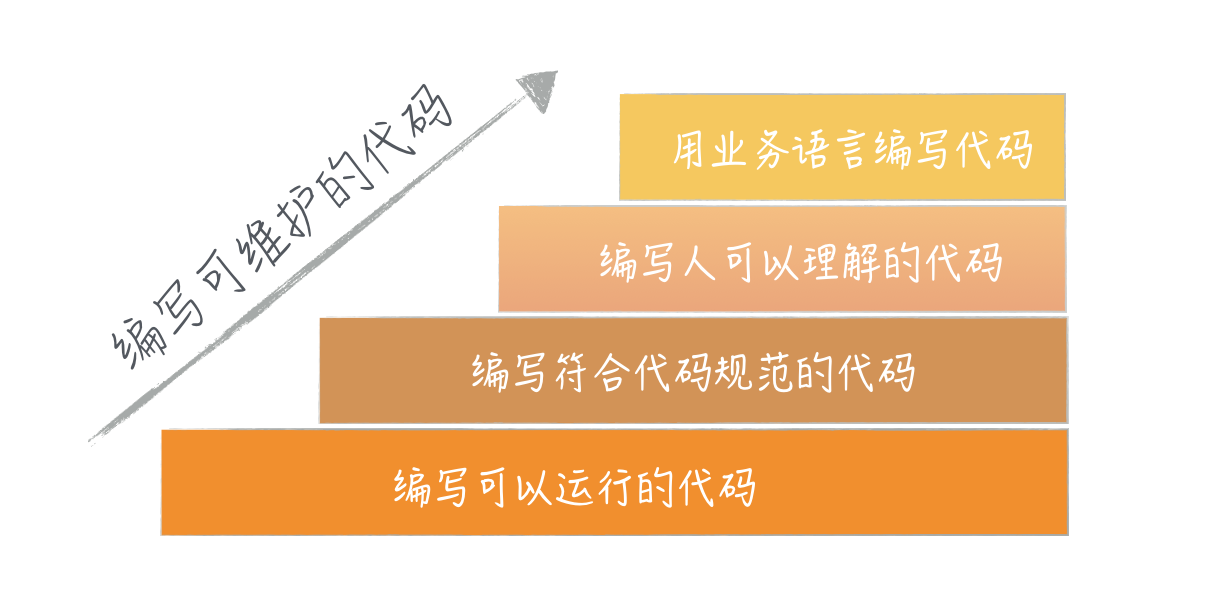
名字起得是否够好,一个简单的评判标准是,拿着代码给人讲,你需要额外解释多少东西。一个好的命名需要你对业务知识有一个深入的理解,虽然只是一个简单的名字修改,但从理解上,这是一步巨大的跨越,缩短了其他人理解这段代码所需填补的鸿沟,工作效率自然会得到提高。
好的设计是日拱一卒的结果,在日常工作中要重视设计和细节的改进。
留下评论