Go并发机制及语言层工具
一 前言
我们谈go的优点时,并发编程是最重要的一块。因为go基于新的并发编程模型:不用共享内存的方式来通信,作为替代,以通信作为手段来共享内存。(goroutine共享channel,名为管道,实为内存)。为解释这个优势,本文提出了四个概念:交互方式、手段、类型、目的(不一定对,只是为了便于描述)。并在不同的并发粒度上(进程、线程、goroutine)对这几个概念进行了梳理。
Go 语言的并发模型是 fork-join 型的。使用 go 关键字启动子协程工作,使用 sync.Wait 和 channel 来收集结果。
data race
- 原因:多个goroutine 同时接触一个变量,行为不可预知
- 认定条件:两个及以上 goroutine 同时接触一个变量,其中至少一个goroutine 为写操作
- 检测方案:
go run -race或者go test -race - 解决方案:使用atomic 库或者sync.Mutex 等工具限制访问顺序
- 单个变量一写多读 -> atomic
- 单个变量多写多读 -> sync.Mutex
- 多个变量多写多读 -> sync.Mutex
PS:在 golang 中的并发工具(例如锁 mutex、通道 channel 等)均契合 gmp 作了适配改造,保证在执行阻塞操作时,会将阻塞粒度限制在 g(goroutine)而非 m(thread)的粒度,使得阻塞与唤醒操作都属于用户态行为,无需内核的介入,同时一个 g 的阻塞也完全不会影响 m 下其他 g 的运行。
原子操作
原子操作(atomic operations)是相对于普通指令操作而言的,原子操作由底层硬件直接提供支持,是一种硬件实现的指令级的“事务”,Go语言通过内置包sync/atomic提供了对原子操作的支持,封装了 CPU 实现的部分原子操作指令,为用户层提供体验良好的原子操作函数
- 增减,操作的方法名方式为AddXXXType,保证对操作数进行原子的增减,支持的类型为int32、int64、uint32、uint64、uintptr,使用时以实际类型替换前面我说的XXXType就是对应的操作方法。
- Load,保证了读取到操作数前没有其他任务对它进行变更,操作方法的命名方式为LoadXXXType,支持的类型除了基础类型外还支持Pointer,也就是支持载入任何类型的指针。
- 存储,有载入了就必然有存储操作,这类操作的方法名以Store开头,支持的类型跟载入操作支持的那些一样。如果你想要并发安全的设置一个结构体的多个字段,atomic.Value保证任意值的读写安全
- 比较并交换,也就是CAS (Compare And Swap),像Go的很多并发原语实现就是依赖的CAS操作,同样是支持上面列的那些类型。
- 交换,这个简单粗暴一些,不比较直接交换,这个操作很少会用。
互斥锁是用来保护一段逻辑,原子操作用于对一个变量的更新保护。原子操作由底层硬件支持,这些指令在执行的过程中是不允许中断的,而锁则由操作系统的调度器实现,G1 操作变量时,其它操作变量的G 不允许被调度执行(跟允许被中断一个味道)。Mutex的底层实现也用到了原子操作中的CAS实现的。
同步原语
Go 并没有彻底放弃基于共享内存的并发模型,而是在提供 CSP 并发模型原语的同时,还通过标准库的 sync 包,提供了针对传统的、基于共享内存并发模型的低级同步原语,包括:互斥锁(sync.Mutex)、读写锁(sync.RWMutex)、条件变量(sync.Cond)等,并通过 atomic 包提供了原子操作原语等等。显然,基于共享内存的并发模型在 Go 语言中依然有它的“用武之地”。sync 包低级同步原语可以用在哪?
- 在 Go 中,channel 并发原语也可以用于对数据对象访问的同步,我们可以把 channel 看成是一种高级的同步原语,它自身的实现也是建构在低级同步原语之上的。也正因为如此,channel 自身的性能与低级同步原语相比要略微逊色,开销要更大。
- 在不想转移结构体对象所有权,但又要保证结构体内部状态数据的同步访问的场景。
Go 语言设计与实现-同步原语与锁Go 语言在 sync 包中提供了用于同步的一些基本原语,包括常见的 sync.Mutex、sync.RWMutex、sync.WaitGroup、sync.Once 和 sync.Cond。这些基本原语提高了较为基础的同步功能,但是它们是一种相对原始的同步机制,在多数情况下,我们都应该使用抽象层级的更高的 Channel 实现同步。 觉得WaitGroup不好用?试试ErrorGroup吧!
首次使用 Mutex 等 sync 包中定义的结构类型后,我们不应该再对它们进行复制操作。我们推荐通过闭包方式,或者是传递类型实例(或包裹该类型的类型实例)的地址(指针)的方式进行。
互斥锁(Mutex)和读写锁(RWMutex)。它们都是零值可用的数据类型,sync.Mutex 的零值是一个未锁定的 Mutex。Golang: 让你的零值更有用
Mutex
深入理解 golang 的互斥锁 未细读。Golang 的 Mutex 实现一直在改进,到目前为止,主要经历了 4 个版本:
- V1: 简单实现的版本
- V2: 新的 goroutine 参加锁的竞争
- V3: 新的 goroutines 更多参与竞争的机会
- V4: 解决老 goroutine 饥饿的问题
v1版本
func cas(val *int32, old, new int32) bool
func semacquire(*int32)
func semrelease(*int32)
// The structure of the mutex, containing two fields
// 函数传递只能传锁的指针
type Mutex struct {
key int32 // Indication of whether the lock is held. 表示有几个 gorutines 正在使用或准备使用该锁
sema int32 // Semaphore dedicated to block/wake up goroutine
}
// 基于 cas 的加减法函数, Guaranteed to successfully increment the value of delta on val
func xadd(val *int32, delta int32) (new int32) {
for {
v := *val
if cas(val, v, v+delta) {
return v + delta
}
}
panic("unreached")
}
// request lock
func (m *Mutex) Lock() {
if xadd(&m.key, 1) == 1 { // Add 1 to the ID, if it is equal to 1, the lock is successfully acquired
return
}
semacquire(&m.sema) // Otherwise block waiting
}
func (m *Mutex) Unlock() {
if xadd(&m.key, -1) == 0 { // Subtract 1 from the flag, if equal to 0, there are no other waiters
return
}
semrelease(&m.sema) // Wake up other blocked goroutines
}
v4版本
type Mutex struct {
state int32 // 表示当前互斥锁的状态,最低三位分别表示 mutexLocked、mutexWoken 和 mutexStarving,剩下的位置用来表示当前有多少个 Goroutine 等待互斥锁的释放
sema uint32
}
// 先快速 检测下mutex 此时是否空闲,是,则cas对其加锁
func (m *Mutex) Lock() {
// Fast path
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
return
}
// Slow path
m.lockSlow()
}
// src/runtime/sema.go
func semacquire1(addr *uint32, lifo bool, profile semaProfileFlags, skipframes int) {
gp := getg()
s := acquireSudog()
...
for {
// Add ourselves to nwait to disable "easy case" in semrelease.
atomic.Xadd(&root.nwait, 1)
...
root.queue(addr, s, lifo) // 加入等待队列
goparkunlock(&root.lock, waitReasonSemacquire, traceEvGoBlockSync, 4+skipframes)
if s.ticket != 0 || cansemacquire(addr) {
break
}
}
...
releaseSudog(s)
}
// src/runtime/proc.go
func park_m(gp *g) {
_g_ := getg()
casgstatus(gp, _Grunning, _Gwaiting)
dropg()
if fn := _g_.m.waitunlockf; fn != nil {
ok := fn(gp, _g_.m.waitlock)
...
if !ok {
casgstatus(gp, _Gwaiting, _Grunnable) // 改变goroutine 状态
execute(gp, true)
}
}
schedule() // 触发调度器 调度
}
| state bits | 31~3 | 2 | 1 | 0 |
|---|---|---|---|---|
| 用途 | 等待队列长度 | 0=正常 1=饥饿 |
0=无唤醒 1=有唤醒 |
0=解锁 1=上锁 |
Goroutine修改自己的行为/状态
- 锁空闲则加锁;
- 锁占用 + 普通模式则执行
sync.runtime_doSpin进入自旋,执行30次PAUSE 指令消耗CPU时间; - 如果当前 Goroutine 等待锁的时间超过了 1ms,当前 Goroutine 会将互斥锁切换到饥饿模式
- 锁占用 + 饥饿模式则执行
sync.runtime_SemacquireMutex进入休眠状态 - 如果当前 Goroutine 是互斥锁上的最后一个等待的协程或者等待的时间小于 1ms,当前 Goroutine 会将互斥锁切换回正常模式;
Mutex.Lock 有一个类似jvm 锁膨胀的过程(go 调度器运行在 用户态,因此实现比java synchronized 关键字更简单),Goroutine 会先自旋、实在不行休眠自己,修改 mutex 的state(int32 是一个bit field,有点类似 jvm object的 mark word)。也有普通/饥饿模式对应aqs 的公平锁和非公平锁机制。PS:go mutex 没有引入 os 内核锁
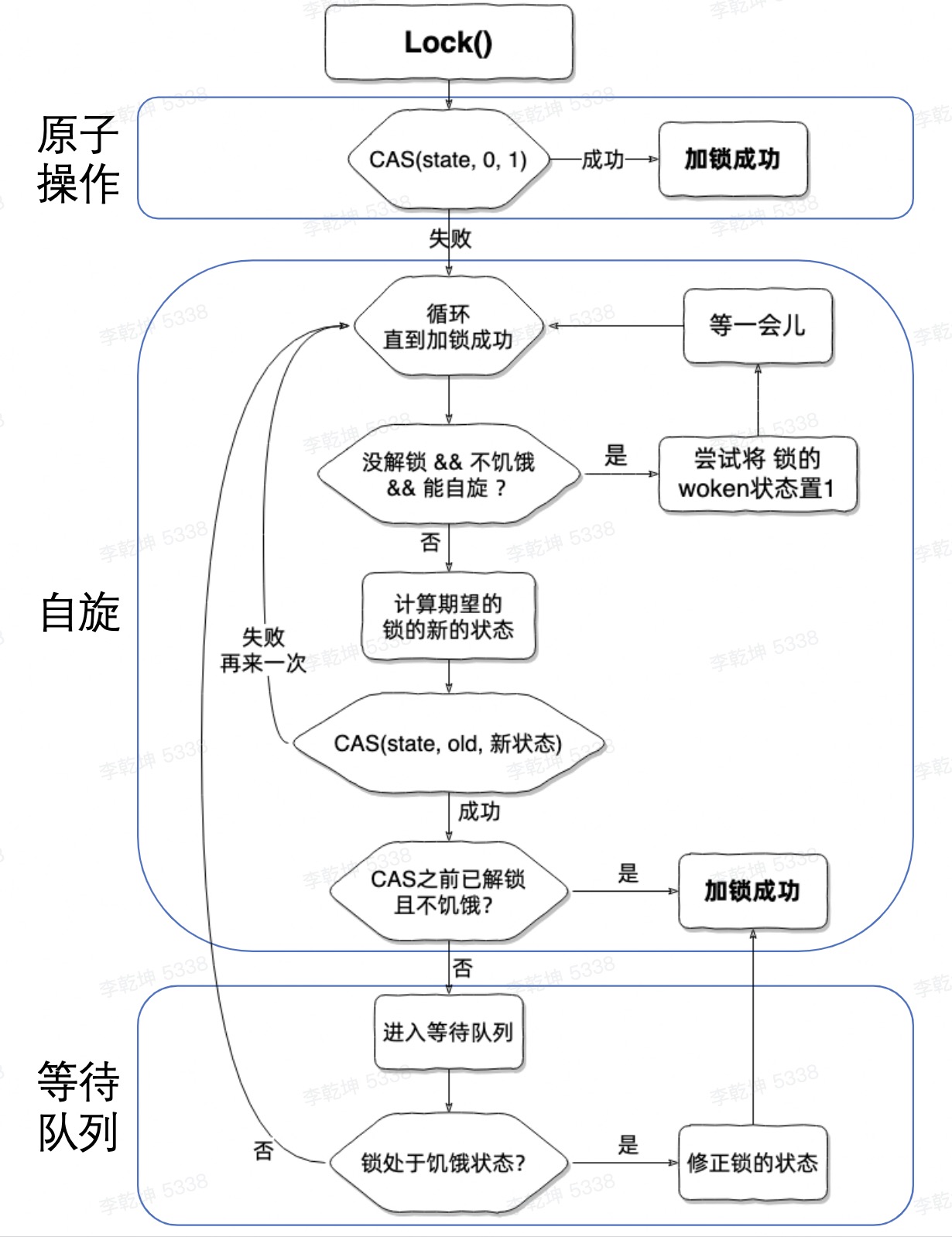
semaphore 实现
semaphore 的原理与实现 Go 语言中暴露的 semaphore 实现,不要认为这些是信号量,把这里的东西看作 sleep 和 wakeup 实现的一种方式。
// /go/1.19.3/libexec/src/sync/runtime.go
func runtime_Semacquire(s *uint32)
func runtime_SemacquireMutex(s *uint32, lifo bool, skipframes int)
func runtime_Semrelease(s *uint32, handoff bool, skipframes int)
// go/1.19.3/libexec/src/runtime/sema.go
//go:linkname sync_runtime_Semacquire sync.runtime_Semacquire
func sync_runtime_Semacquire(addr *uint32) {
semacquire1(addr, false, semaBlockProfile, 0)
}
//go:linkname sync_runtime_Semrelease sync.runtime_Semrelease
func sync_runtime_Semrelease(addr *uint32, handoff bool, skipframes int) {
semrelease1(addr, handoff, skipframes)
}
//go:linkname sync_runtime_SemacquireMutex sync.runtime_SemacquireMutex
func sync_runtime_SemacquireMutex(addr *uint32, lifo bool, skipframes int) {
semacquire1(addr, lifo, semaBlockProfile|semaMutexProfile, skipframes)
}
var semtable semTable
type semTable [semTabSize]struct {
root semaRoot
pad [cpu.CacheLinePadSize - unsafe.Sizeof(semaRoot{})]byte
}
type semaRoot struct {
lock mutex
treap *sudog // root of balanced tree of unique waiters.
nwait uint32 // Number of waiters. Read w/o the lock.
}
- 有一个全局的 semtable(runtime层级的变量),持有一个数组,元素是 semaRoot,每一个sema/addr 哈希计算一个 数组位置, 一个位置一个。 PS:数组加链表
- 对同一个 mutex 上锁的 g,会阻塞在同一个sema/addr上,这些阻塞在同一个地址上的 goroutine 会被打包成 sudog,组成一个链表。用 sudog 的 waitlink 相连。从 semaRoot 的视角(其实就是 lock 的 addr)来看,sudo 链表 是个二叉搜索树。
- 类似于 linux 的 socket 和 golang的channel,都会自己持有一个等待队列,存储访问自己时 因“没有数据” 而阻塞的 执行体。golang 中一般将阻塞的 执行体封装为 sudog,进而拼成链表。 sema 看着像一个孤零零的 int32,实际上 等待队列是挂在 全局semtable 上了。
- 将goroutine 加入等待队列之后,semacquire1 ==> goparkunlock ==> gopark,变更groutine的状态,让出M
读写锁
var (
pcodes = make(map[string]string)
mutex sync.RWMutex
ErrKeyNotFound = errors.New("Key not found in cache")
)
func Add(address, postcode string) {
// 写入的时候要完全上锁
mutex.Lock()
pcodes[address] = postcode
mutex.Unlock()
}
func Value(address string) (string, error) {
// 读取的时候,只用读锁就可以
mutex.RLock()
pcode, ok := pcodes[address]
mutex.RUnlock()
if !ok {
return "", ErrKeyNotFound
}
return pcode, nil
}
func main() {
Add("henan", "453600")
v, err := Value("henan")
if err == nil {
fmt.Println(v)
}
}
超时
java 的future.get(timeout) 体现在channel 上是
select {
case ret:= <- ch:
xx
case <- time.After(time.Second*1):
fmt.Println("time out")
}
java的Combine Future 体现在channel 上是
select {
case ret:= <- ch1:
xx
case ret:= <- ch2:
xx
default:
fmt.Println("no one returned")
}
waitGroup/errGroup
WaitGroup可以等待多个Goroutine执行结束。很多时候并发执行多个任务,如果其中一个任务出错那么整体失败,需要直接返回,这种情况下我们可以使用ErrGroup。
// 启动多个goroutine
for i:=0;i<10;i++{
go func(){
...
}()
}
// 使用waitGroup
wg := sync.WaitGroup{}
for i:=0;i<10;i++{
wg.Add(1)
go func(){
defer wg.wg.Done()
...
}()
}
wg.Wait()
// 当我们想要知道某个goroutine报什么错误的时候发现很难,因为我们是直接go func(){}出去的,并没有返回值,因此对需要接受返回值做进一步处理的需求就无法满足了
eg, _ := errgroup.WithContext(context.Background())
eg.Go(func() error {
defer func() {
//recover
}()
//TODO:真正逻辑
})
if err := group.Wait(); err != nil {
return nil, err
}
waitGroup 使用的时候太麻烦,可以参考Go语言实现的可读性更好的「高并发神库」
取消/中断goroutine 执行的工具——context
深度解密Go语言之contextGo 1.7 标准库引入 context,中文译作“上下文”(其实这名字叫的不好)
在 Go 的 server 里,通常每来一个请求都会启动若干个 goroutine 同时工作:有些去数据库拿数据,有些调用下游接口获取相关数据……这些 goroutine 需要共享这个请求的基本数据,例如登陆的 token,处理请求的最大超时时间(如果超过此值再返回数据,请求方因为超时接收不到)等等。当请求被取消或超时,所有正在为这个请求工作的 goroutine 需要快速退出,因为它们的“工作成果”不再被需要了。context 包就是为了解决上面所说的这些问题而开发的:在 一组 goroutine 之间传递共享的值、取消信号、deadline……
Go 语言设计与实现——上下文 Context主要作用还是在多个 Goroutine 组成的树中同步取消信号以减少对资源的消耗和占用,虽然它也有传值的功能,但是这个功能我们还是很少用到。在真正使用传值的功能时我们也应该非常谨慎,使用 context.Context 进行传递参数请求的所有参数一种非常差的设计,比较常见的使用场景是传递请求对应用户的认证令牌以及用于进行分布式追踪的请求 ID。
为什么有 context?
Go组件:context学习笔记!一个goroutine启动后是无法控制它的,大部分情况是等待它自己结束,如何主动通知它结束呢?go的协程不支持直接从外部退出,不像C++和Java有个线程ID可以操作。所以只能通过协程自己退出的方式。一般来说通过channel来控制是最方便的。
func main() {
stop := make(chan bool)
go func() {
for {
select {
case <-stop: // 有点类似Thread.interrupt() 的感觉
fmt.Println("监控退出,停止了...")
return
default:
fmt.Println("goroutine监控中...")
time.Sleep(2 * time.Second)
}
}
}()
time.Sleep(10 * time.Second)
fmt.Println("可以了,通知监控停止")
stop<- true
}
上面的代码已经够简单了,但是还是显得有些复杂。比如每次都要在协程内部增加对channel的判断,也要在外部设置关闭条件。channel+select是比较优雅的结束goroutine的方式,不过这种方式也有局限性,如果有很多goroutine都需要控制结束?如果这些goroutine又衍生了其他更多的goroutine怎么办呢?goroutine的关系链导致了这些场景非常复杂。
func main() {
ctx, cancel := context.WithCancel(context.Background())
go func(ctx context.Context) {
for {
select {
// 大部分工具库内置了对ctx的判断,下面的部分几乎可以省略
case <-ctx.Done():
fmt.Println("监控退出,停止了...")
return
default:
fmt.Println("goroutine监控中...")
time.Sleep(2 * time.Second)
}
}
}(ctx)
time.Sleep(10 * time.Second)
fmt.Println("可以了,通知监控停止")
cancel() // context.WithCancel 返回的cancel 方法
}
Context顾名思义是协程的上下文,主要用于跟踪协程的状态,可以做一些简单的协程控制,也能记录一些协程信息。且更为友好的是,大多数go库,如http、各种db driver、grpc等都内置了对ctx.Done()的判断,我们只需要将ctx传入即可。PS:感觉这才是关键,大家都接受了拿context 作为任务取消的信号,统一了任务取消的规范。反过来说,这导致很多方法不管用到用不到 都弄了一个ctx 参数,因为保不齐 下游函数用到了。
父 goroutine 创建context
- 根Context,通过
context.Background()/context.TODO()创建 - 子Context
func WithCancel(parent Context) (ctx Context, cancel CancelFunc) // 和WithCancel差不多,会多传递一个截止时间参数,即到了这个时间点会自动取消Context,也可以通过cancel函数提前取消。 func WithDeadline(parent Context, deadline time.Time) (Context, CancelFunc) // 和WithDeadline基本上一样,多少时间后自动取消Context func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc) // 和取消Context无关,绑定了一个kv数据的Context,kv可以通过Context.Value方法访问到 func WithValue(parent Context, key interface{}, val interface{}) Context - 当前Context 被取消时,基于他的子context 都会被取消
Goroutine的创建和调用关系总是像层层调用进行的,就像人的辈分一样,而更靠顶部的Goroutine应有办法主动关闭其下属的Goroutine的执行但不会影响 其上层Goroutine的执行(不然程序可能就失控了)。为了实现这种关系,Context结构也应该像一棵树,叶子节点须总是由根节点衍生出来的。
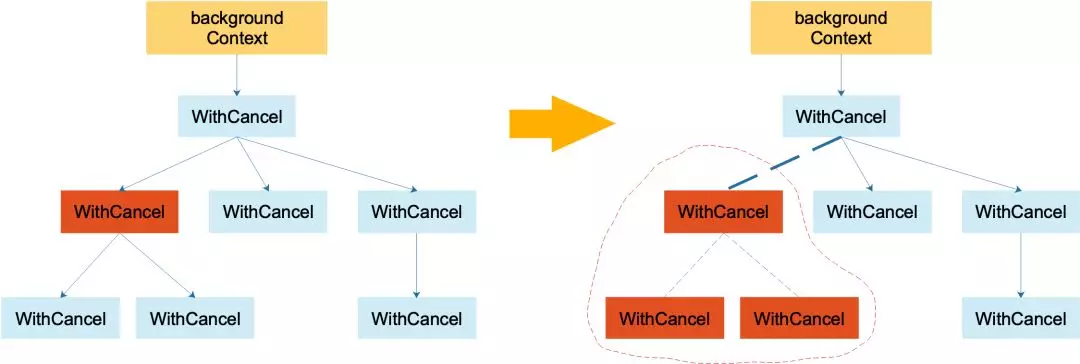
如上左图,代表一棵 context 树。当调用左图中标红 context 的 cancel 方法后,该 context 从它的父 context 中去除掉了:实线箭头变成了虚线。且虚线圈框出来的 context 都被取消了,圈内的 context 间的父子关系都荡然无存了。
子 goroutine 使用context
type Context interface {
Deadline() (deadline time.Time, ok bool) // 获取设置的截止时间
Done() <-chan struct{} // 如果该方法返回的chan可以读取,则意味着parent context已经发起了取消请求
Err() error // 返回取消的原因,在 Done 返回的 Channel 被关闭时返回非空的值;如果 context.Context 被取消,会返回 Canceled 错误;如果 context.Context 超时,会返回 DeadlineExceeded 错误;
Value(key interface{}) interface{}
}
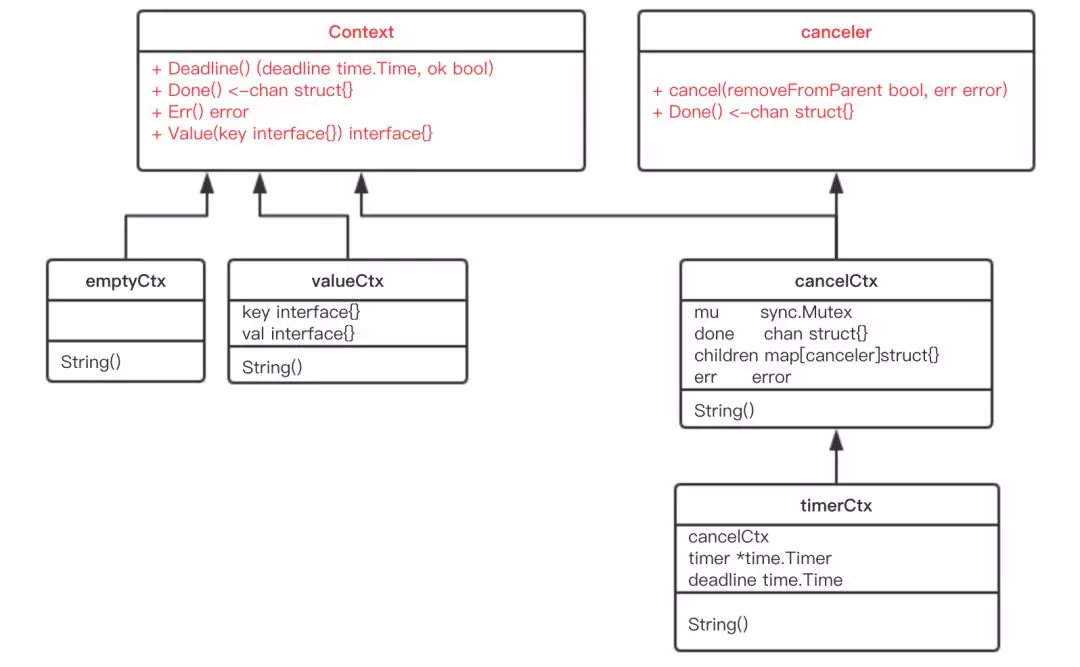
// golang.org/x/net/context/pre_go17.go
type cancelCtx struct {
Context
done chan struct{} // closed by the first cancel call.
mu sync.Mutex
children map[canceler]bool // child 会被加入 parent 的 children 列表中,等待 parent 释放取消信号;
err error
}
func (c *cancelCtx) cancel(removeFromParent bool, err error) {
c.mu.Lock()
if c.err != nil {c.mu.Unlock() return}
c.err = err
if c.done == nil {
c.done = closedchan
} else {
close(c.done)
}
for child := range c.children {
child.cancel(false, err)
}
c.children = nil
c.mu.Unlock()
if removeFromParent {
removeChild(c.Context, c)
}
}
使用建议
官方对于使用 context 提出了几点建议:
- 不要将 Context 塞到结构体里。直接将 Context 类型作为函数的第一参数,而且一般都命名为 ctx。
- 不要向函数传入一个 nil 的 context,如果你实在不知道传什么,标准库给你准备好了一个 context:todo。
- 不要把本应该作为函数参数的类型塞到 context 中,context 存储的应该是一些共同的数据。例如:登陆的 session、cookie 等。
- 同一个 context 可能会被传递到多个 goroutine,别担心,context 是并发安全的。
context 取消和传值示例
func main() {
// cancel 是一个方法
ctx, cancel := context.WithCancel(context.Background())
valueCtx := context.WithValue(ctx, key, "add value")
go watch(valueCtx)
time.Sleep(10 * time.Second)
cancel()
time.Sleep(5 * time.Second)
}
func watch(ctx context.Context) {
for {
select {
case <-ctx.Done():
//get value
fmt.Println(ctx.Value(key), "is cancel")
return
default:
//get value
fmt.Println(ctx.Value(key), "in goroutine")
time.Sleep(2 * time.Second)
}
}
}
留下评论