实时训练
简介(未完成)
推荐/广告系统是在线学习的理想应用之一。推荐系统有很自然的标签——如果一位用户点击一个推荐,那么这个预测就是正确的。
- 并非所有推荐系统都需要在线预测。用户对房子、汽车、航班和酒店的偏好不太可能过一分钟就变了,因此对于这样的系统,持续学习并不太合理。
- 在线学习对系统适应罕见事件至关重要。以黑色星期五在线购物为例,由于黑色星期五一年仅发生一次,因此亚马逊和其它电商网站不可能有足够多的历史数据来学习用户在那天的行为,因此它们的系统需要持续学习那天的状况以应对变化(名人事件类似)。
- 在线学习还可以帮助解决冷启动(cold start)问题。冷启动是指新用户加入你的应用时,你还没有他们的信息。如果没有任何形式的在线学习,你就只能向新用户推荐一般性内容,直到你下一次以离线方式训练好模型。
在线学习并不意味着「无批量学习」。在在线学习方面最成功的公司也会同时以离线方式训练其模型,然后再将在线版本与离线版本组合起来。
理论挑战
- 离线训练即 使用足够多 epoch 训练你的模型直到收敛,而在线学习没有 epoch——你的模型只会看见每个数据一次。
- 在线学习也不存在收敛这个说法,基础数据分布会不断变化,没有什么可以收敛到的静态分布。
- 在线学习的另一大理论挑战是模型评估。在传统的批训练中,你会在静态的留出测试集上评估模型。如果新模型在同一个测试集上优于现有模型,那我们就说新模型更好。但是,在线学习的目标是让模型适应不断变化的数据。如果更新后的模型是在现在的数据上训练的,而且我们知道现在的数据不同于过去的数据,那么再在旧有数据集上测试更新后的模型是不合理的。那么,我们该怎么知道在前 10 分钟的数据上训练的模型优于使用前 20 分钟的数据训练的模型呢?答案是必须在当前数据上比较两个模型。在线学习需要在线评估,但是向用户提供还未测试的模型听起来简直是灾难。不过,很多公司都这么做。新模型首先要进行离线测试,以确保它们不会造成灾难性后果,然后再通过复杂的 A/B 测试系统,与现有模型并行地进行在线评估。只有当新模型在该公司关心的某个指标上的表现优于现有模型时,它才能得到更广泛的部署。
实践挑战
- 在线训练目前还没有标准的基础设施。
- 如何与已有的训练、推理流程整合起来。
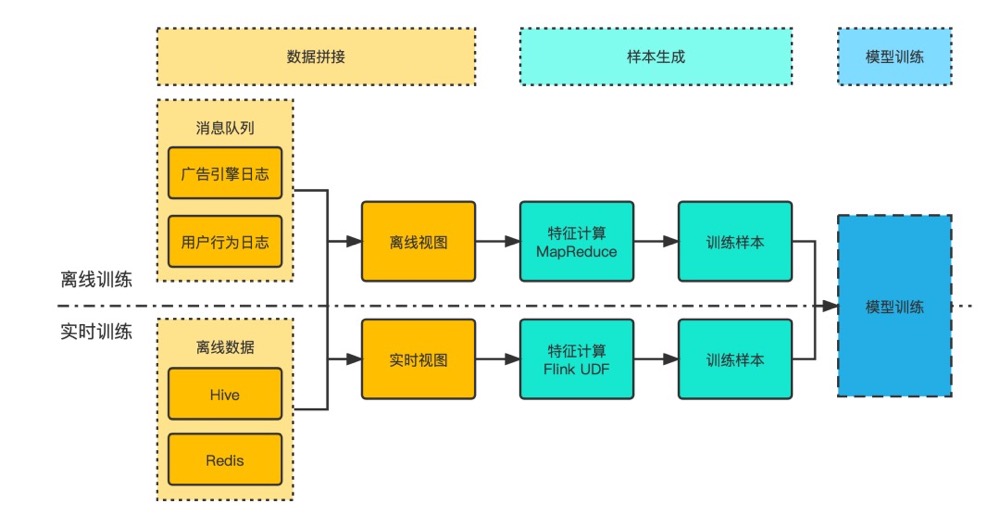
在线/实时训练其实输出的是一个模型的更新数据流,这里其实是最近上一批次产生的对模型造成变化被实时的发布到在线。离线其实会做批量天级别的训练,会发布一个全量的迁移参数模型,同时更回到线上。
- 离线和实时训练
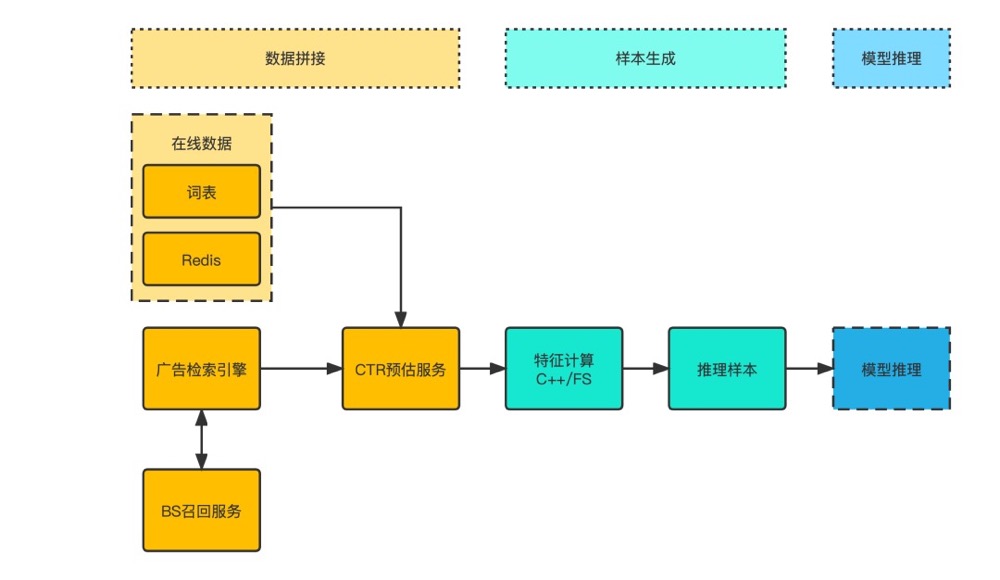
- 推理
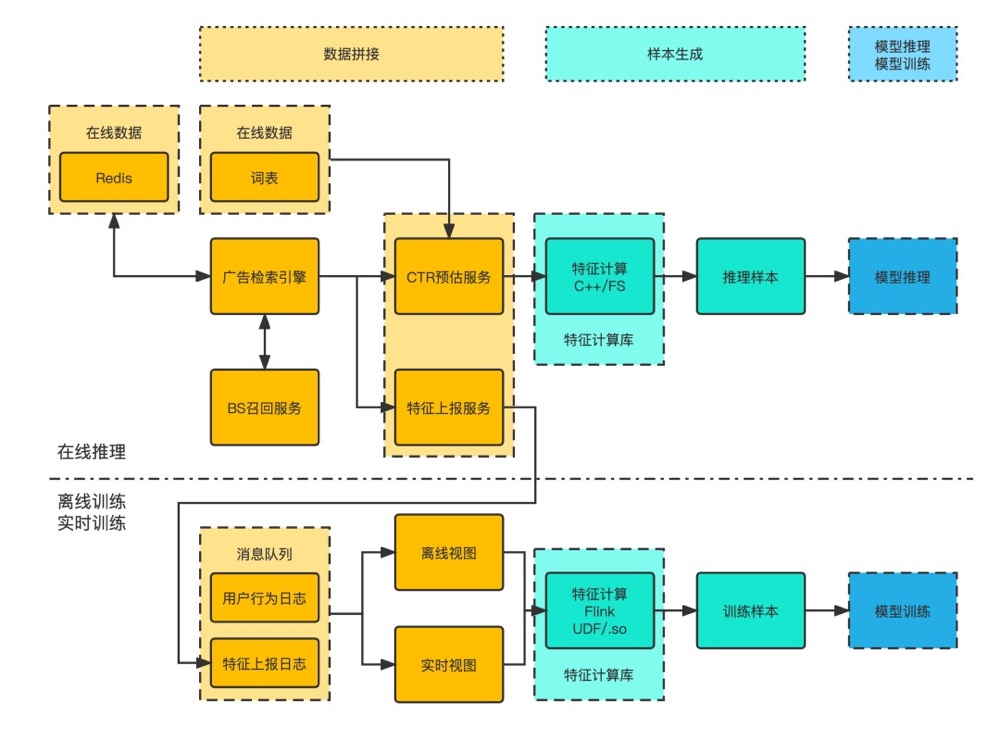
- 离线实时+推理一起
留下评论