从chatbot到clawbot
简介
AI的发展正在经历从“信息检索”到“任务执行”的范式转移。由Manus启蒙、OpenClaw破圈,AI以智能体的方式,开始能够自主规划执行路径、自主调用工具,代替人类完成自动化任务。OpenClaw是一个 Local-First (本地优先, vs manus 这种Cloud-native产品) 的 AI Agent 运行时环境,旨在将大模型(LLM)的能力与用户的本地系统、工具链和通讯软件深度结合。最擅长处理那些跨平台、需要系统级权限且带有自动化性质的任务。
- IM 入口带来的体验质变
- 拟人,主动。会主动问你今天怎么样,会在完成任务后开个小玩笑,会记得你上次抱怨过什么。
- Memory做的好。Memory 会是 ChatBot 产品的最大壁垒。
OpenClaw第一次把”个人 AI 助理”这件事完整地具象化了。
架构
OpenClaw 用 4 个设计回答了 4 个重要问题
- 多协议可插拔契约(Channel 25+ Adapter)
- LLM 上下文资源预算(可插拔 Context Engine + 多级 Compaction)
- 记忆自动沉淀不退化(Dreaming 三阶段加权晋升)
- 凭证失败与业务失败分治
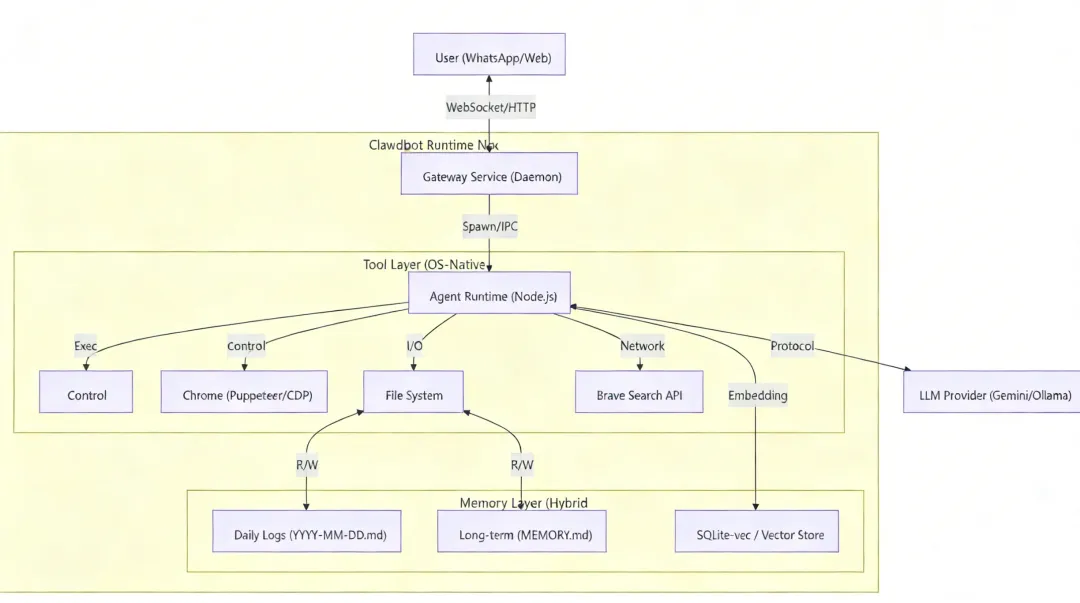
编排流程
- 感知 (Observe):接收用户消息 + 读取最近的 MEMORY 上下文 + 系统状态。
- 规划 (Plan/Reasoning):LLM 进行思考(Chain-of-Thought),决定是否需要调用工具。
- 行动 (Act):LLM 输出结构化 JSON (Tool Call)。Runtime 拦截并执行对应的 JavaScript 函数(如 read, exec)。
- 关键点:如果任务复杂,Agent 会自行决定生成并运行一段代码,或者 Spawn 一个 Sub-Agent(子智能体)。
- 反馈 (Reflect):工具的输出(stdout/stderr/file)回传给 LLM,LLM 判断任务是否完成,未完成则继续循环。
多智能体 (Sub-Agents):通过 sessions_spawn 工具,主 Agent 可以分裂出子 Session 处理耗时任务(如:“帮我爬取这10个网站并总结”)。子 Agent 在独立上下文中运行,完成后回调主 Agent。
OpenClaw 的核心是什么?在于 3 个文件。
- SOUL.md(Agent如何思考与交流),SOUL.md 承担的工作比系统中任何其他组件都重,代理在每次对话开始时都会读取它,并将其作为沟通的基础,包括语气、回复的优先级、行为边界等。如果你的代理回复让你感觉哪里不对劲,但又说不出个所以然,答案通常就在这个文件里。
- USER.md(代理在为谁工作)要提供足够的背景信息,让 OpenClaw 感觉它已经认识你几十年了。
- MEMORY.md(代理长期记忆的内容)
关键设计
- Local-First:数据不出门, 所有会话数据、配置、媒体文件都存储在
~/.openclaw/目录下 - 万物皆插件(Everything is a Plugin):核心代码只负责编排——消息路由、会话管理、安全网关。所有具体能力(Discord 通道、Anthropic 模型、浏览器工具)都以插件形式实现,统一通过 Plugin SDK 注册。
- 记忆驱动(Memory-Driven):Agent 不仅有静态的工作区文件(SOUL.md, USER.md, MEMORY.md)定义人格与记忆,还有向量记忆引擎实现混合搜索、Dreaming 后台整合和 Active Recall 主动召回。
- 配置驱动(Config-Driven):一个 JSON 文件(~/.openclaw/openclaw.json)定义所有行为——Agent 配置、Channel 凭证、模型选择、安全策略、定时任务。支持运行时热重载,改配置不需要重启。
记忆的分层结构和记忆的按需加载(file system 式的)
Steinberger 提到OpenClaw 的哲学是:记忆属于用户。所有的交互历史和上下文都以 Markdown 文件形式存储在本地(把记忆当成工作区里的普通文件/ file‑first),这种透明且可迁移的“本地优先”模式,是保护个人隐私的最终防线。分层的、可搜索的、持久化的知识管理架构。
OpenClaw 把记忆分成“文件层”和“索引层”两部分
- 文件层用 Markdown 组织知识与经验
- 索引层用 SQLite + FTS5 + 向量扩展做检索
本地架构、记忆管理、Agent 编排与上下文组装原理 self-evolving, 没有 memory,Agent 基本上就没有进化的能力。比如反馈都做成 memory,写记忆就是写文件,记忆就是agent workspace 里的md文件。
- Session Context(会话上下文,
sessions/*.jsonl), 仅存在于系统内部的会话状态流。用户无法直接访问或编辑, 完全由系统自动管理,包含 Compaction 逻辑。会话会持久化存储在一个基础的 .jsonl 文件中,每一行都是一个包含用户消息、工具调用、执行结果及模型响应的 JSON 对象。 - Daily Logs(每日日志/流水,
memory/YYYY-MM-DD.md),当用户执行 /new 命令重置会话时,系统会触发 session-memory Hook,自动将上一个会话的关键内容转换为 Markdown 文件。- 混合模式 (Hybrid): 既包含原始交互日志,也包含 Memory Flush 产生的自动摘要(在context 溢出时,会对历史会话进行压缩,压缩前会调用一次memoryFlush,从而提取重要事件)。
- Append-only(只追加)。用户可读可写,系统自动加载“今天+昨天”。
- Curated Memory(精选记忆),MEMORY.md。长期维护的、经过提炼的事实、偏好和决策。仅在主会话 (Main Session) 中加载,用户可手动编辑优化。
~/openclaw
/{agentId}/sessions
├── main.jsonl # 主会话
├── telegram-123456.jsonl # telegram群组会话
/workspace/
├── MEMORY.md - 第二层:经整理的长期知识库(跨越时间),会更新、删除、合并
└── memory/
├── 2026-01-26-{slug}.md - 第一层:日志记忆(按日期)
├── 2026-01-25-{slug}.md
├── 2026-01-24-{slug}.md
└── ...
AGENTS.md存着智能体的指令和记忆使用规则,示例如下:
每次会话的必做步骤
开始任何操作前,需完成以下步骤:
1. 读取SOUL.md文件——定义智能体的自身定位
2. 读取USER.md文件——明确服务的用户信息
3. 读取memory目录下今日和昨日的日志文件——获取近期上下文
4. 若为「主会话」(与用户的直接聊天),额外读取MEMORY.md——获取长期记忆
无需向用户申请权限,直接执行即可。
具体到记忆部分
## Memory Recall
Before answering anything about prior work, decisions, dates, people, preferences, or todos: run memory_search on MEMORY.md + memory/*.md; then use memory_get to pull only the needed lines. If low confidence after search, say you checked.
Recall (召回), Agent 则是通过两个接口实现与整个记忆系统的交互(写入则是标准的文件io): memory_search/memory_get
- memory_search, 给定自然语言查询,在 MEMORY.md、
memory/*.md(以及可选的 sessions)里检索相关片段,并把结果作为一个结构化对象返回。system prompt会明确告诉模型:凡是涉及历史决策、长期偏好或之前提到过的信息,回答前应先调用这个工具。 - memory_get:按路径和行号精确读取某段 Markdown 内容,帮模型做“按需展开”,避免一次性把整篇长文塞进上下文。
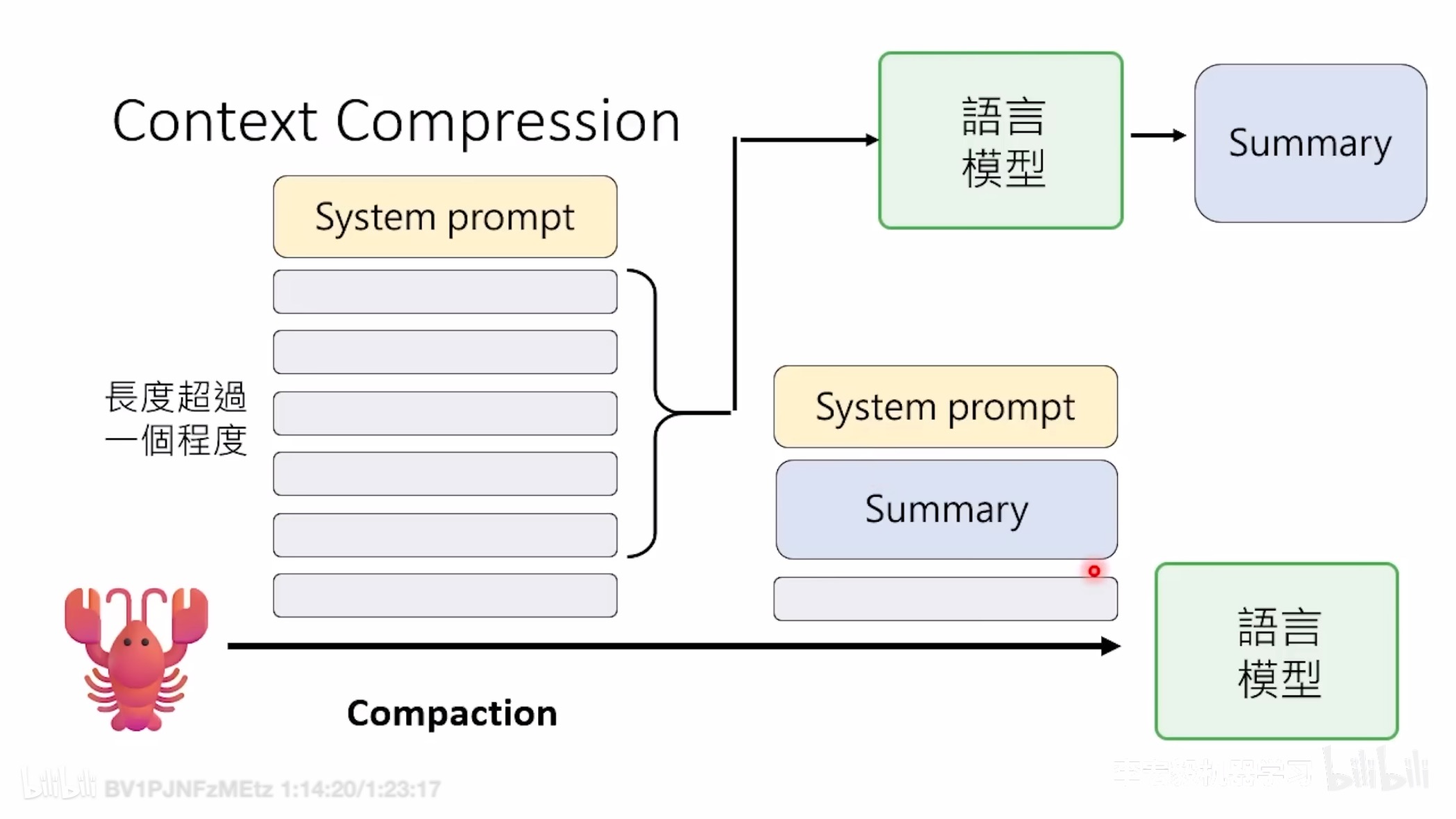
- Compaction :当会话上下文接近模型的 context 上限时,会静默触发一个内部 turn,请模型把当下对话中真正重要、值得长期保留的事实写入当天的 memory/YYYY-MM-DD.md,以降低后续上下文被裁剪时的信息损失(Memory Flush)。
OpenClaw为记忆后端预留了插件 Slot,支持把记忆完全外置。
越用越懂你
有一层对用户的理解,有人设 (SOUL.md),对用户的理解(USER.md)。
没有设计专属的 memory_write 工具,而是直接用智能体自带的、用于文件操作的标准write和edit工具完成记忆写入。agent的写入行为由 AGENTS.md 中的提示词规则驱动,不同的记忆内容会被写入不同的文件,形成了清晰的写入规则,不同触发场景对应不同的写入文件:
- 日常笔记、临时需要记录的内容,会写入memory/YYYY-MM-DD.md按日归档;
- 长期有效的事实、个人偏好、关键决策,会写入MEMORY.md作为核心知识库;
- 经验总结、工具的实操技巧,会写入AGENTS.md或TOOLS.md,让记忆和智能体的能力配置结合更紧密。
- 系统还会在两个关键节点自动执行记忆写入:
- 一是对话历史压缩前的记忆刷写阶段,
- 二是会话正式结束时,这两个节点的自动写入,能有效避免关键信息因对话结束或压缩而丢失。
Clawdbot 设计了自动索引构建功能,只要你保存了任意一个记忆文件(不管是智能体自动写入还是手动编辑),系统都会在后台自动触发索引构建流程,确保新内容能被快速检索。系统会用Chokidar工具监控文件变化,为了避免频繁写入触发重复操作,还设置了1.5秒的防抖延迟;然后,系统会把文件内容分成约400个token的文本块,相邻文本块会保留80个token的重叠区域,这样既能保证语义连贯,又能提高检索精度;接着每个文本块会被传入embedding模型,转换成1536维的embedding数据,最后存储在数据库里。过程中,会结合语义检索(向量检索)和关键词检索(BM25)两种方式,按 7:3 的权重计算最终检索得分,公式如下最终得分 = 0.7 × 向量检索得分 + 0.3 × 关键词检索得分
OpenClaw 的所有数据,包括对话历史、会话状态、工作文件、记忆钩子,全部持久化在本地文件系统中。每一次交互都在积累上下文,Agent 越用越懂你。这不是”聊天记录存档”那么简单,而是一个持续生长的个人数据中心。
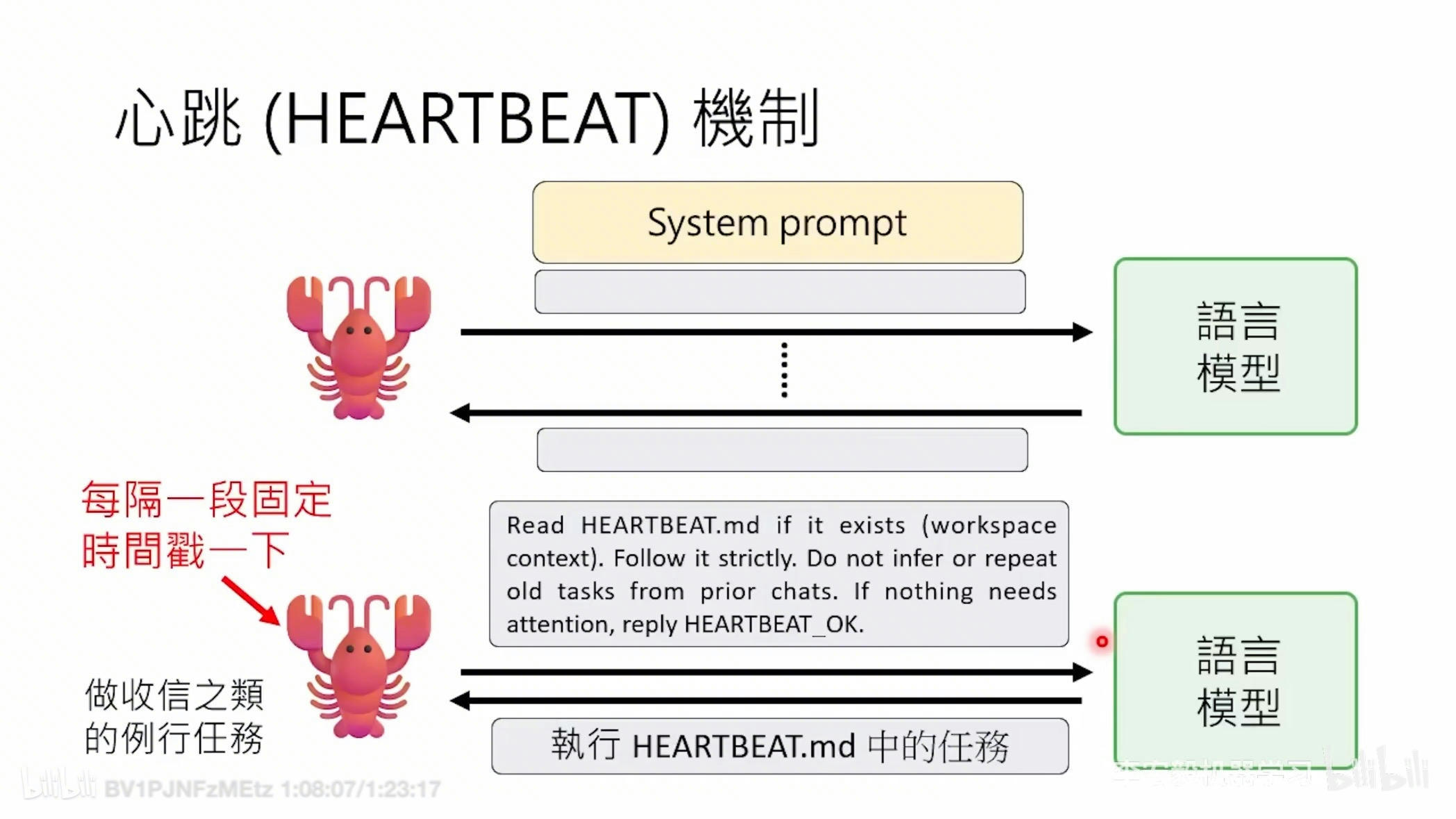
更主动——Heartbeat(心跳)与 Cron(定时)系统
这些系统让它从一个被动工具变成了一个后台协作伙伴。
-
心跳是一个预设的间隔时间,代理会自主醒来,检查你要求它监控的任务列表,并决定发现的内容是否值得通过消息平台联系你。
-
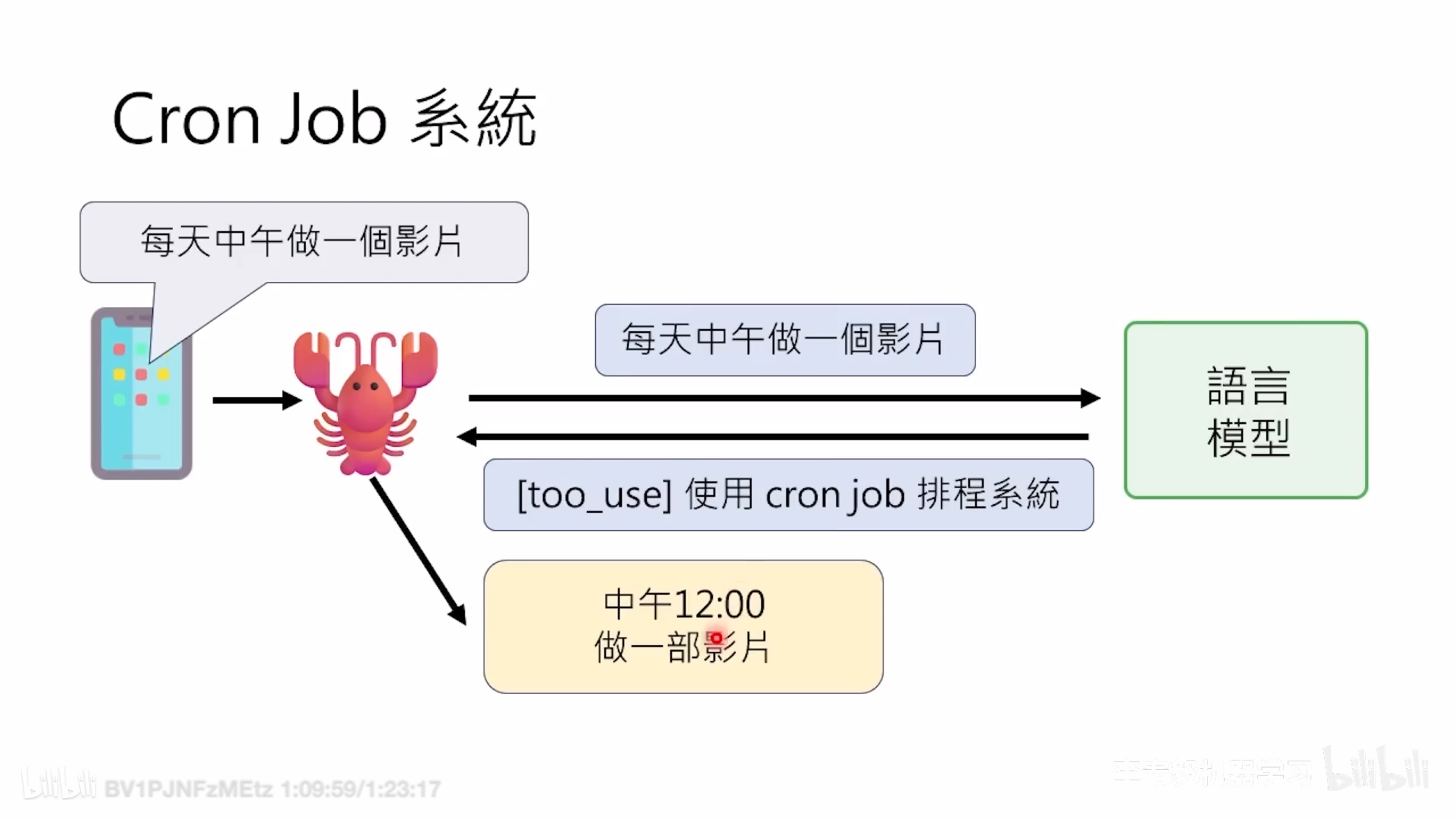
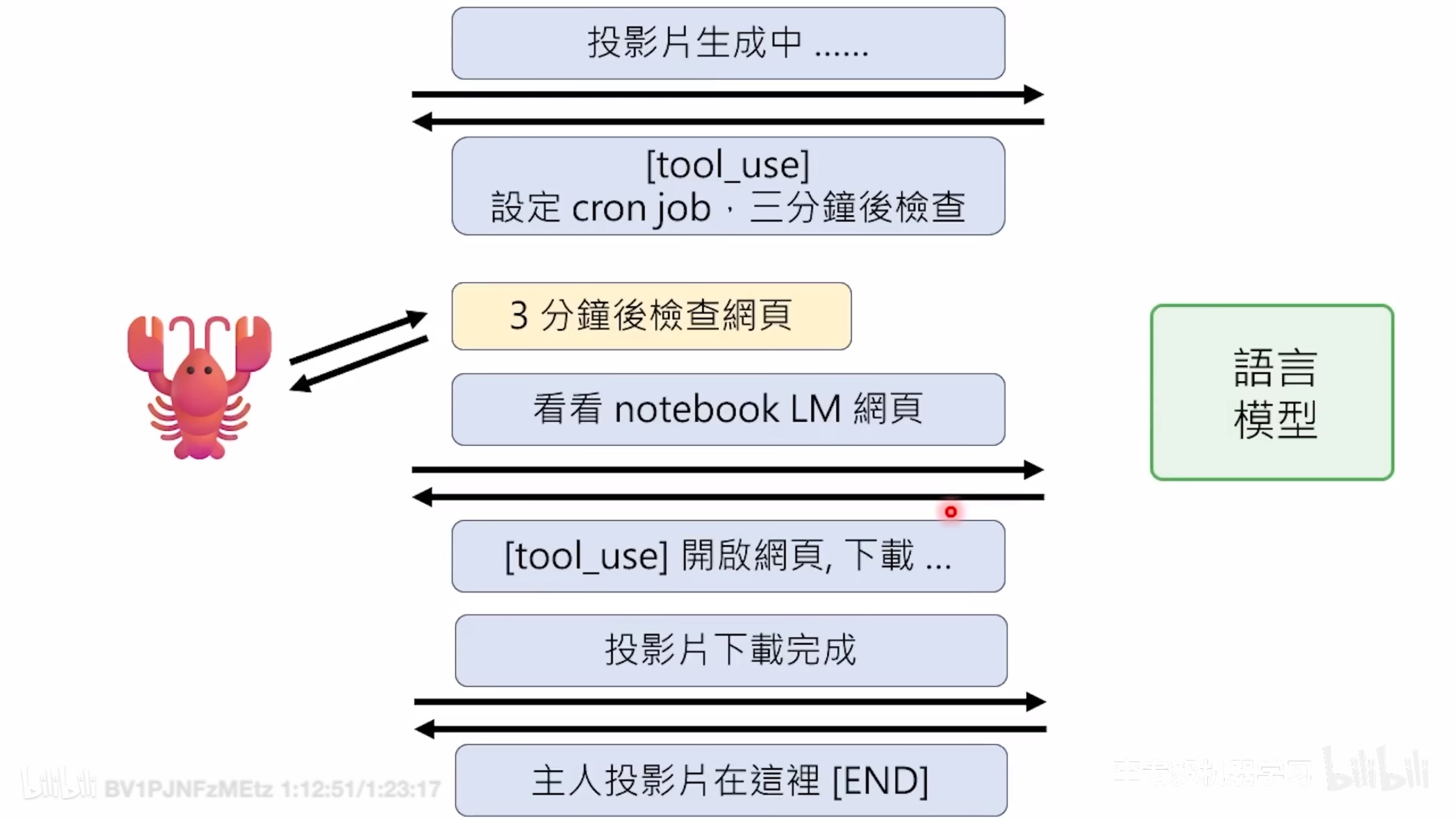
Cron 系统处理需要精确时间的任务,而不是周期性扫描。这就像让 ChatGPT 定时推送新闻一样。心跳和 Cron 的区别在于:一个是特定时间点(日/周),另一个是主动的意识检查。不要在应该用心跳的时候用 Cron,反之亦然。
大多数人的 OpenClaw 配置不尽如人意,并不是因为缺少某个文件,而是文件之间不匹配。如果你的代理有详细的 SOUL.md 但记忆是空的,你可能会得到回复语气很漂亮但完全不记得昨天聊了什么的代理。同理,一个有激进心跳监控但 USER.md 极其单薄的代理,发出的通知虽然技术上准确,但完全不符合你的关注点。这两种情况都要避免。与其只花一小时试用一下就决定它是否值得,我建议额外花几个小时按你的期望设置好所有系统。记住:Soul 文件中的性格定义应与 User 文件中的背景对齐,两者应与 Memory 中的信息对齐,最后与 Heartbeat 中的监控优先级对齐。
插件和Skills系统设计
Agent实践的一个关键瓶颈:大多数智能体的“能力”仍嵌在提示词或硬编码逻辑中——难以复用、适配与系统化推理。PS:经验的标准化与售卖。
OpenClaw核心系统只做最基础的事情——消息路由、模型调用、上下文管理、安全沙箱,其他所有功能都通过插件和Skills(自然语言定义的软体接口)来实现,这种”核心精简、外围开放”的架构模式,才是做平台型产品的正确姿势。而且它的Skills系统设计得特别工程化。每个Skill就是一个标准格式的配置文件加一个执行脚本,有manifest描述元信息,有input/output schema定义接口,有sandbox配置指定权限边界。
skill分为三个层级,优先级从高到低:
- Bundled Skills:项目自带的内置技能。OpenClaw 官方提供,覆盖了编码、写作、研究等常见任务。
- Managed Skills:位于
~/.openclaw/skills/,对该用户的所有项目生效。用户可以通过简单的命令从 ClawHub(OpenClaw 官方维护的一个skill registry) 安装和更新这些技能,就像使用一个应用商店一样。Agent 甚至可被授权自行搜索并安装新技能,以完成超出其当前能力范围的任务。 - Workspace Skills:位于当前项目目录
~/.openclaw/workspace/skills/,仅对该项目生效。每个 skill 一个子目录
将“做什么”(自然语言描述)和“怎么做”(代码实现)分离,极大地降低了扩展难度。非程序员甚至可在 AI 协助下,通过修改 .md 文件微调 Agent 的行为。
工具系统/安全沙箱机制/扩展 or限制 AI 的能力边界
OpenClaw 的几大核心工具:
- 文件系统工具:支持读取、写入和编辑。
- 进程管理 (Process tool):用于处理后台长期运行的命令、终止进程等。
- 浏览器工具:基于 Playwright 开发,并使用“语义快照”(vs 截图/cdp)。这是一种基于文本的页面可访问性树(Accessibility Tree / ARIA) 的表示形式(浏览网页的行为本质上并不一定是一项视觉任务,一张截图的大小可能有 5 MB,而语义快照通常不到 50 KB)。智能体(Agent)看到的页面结构如下:
```
- button “Sign In” [ref=1]
- textbox “Email” [ref=2]
- textbox “Password” [ref=3]
- link “Forgot password?” [ref=4]
- heading “Welcome back”
- list
- listitem “Dashboard”
- listitem “Settings” ```
- Canvas。Agent 可以通过 canvas 工具,在一个可视化的界面上动态地创建、更新和展示内容。它基于一个名为 A2UI 的框架,允许 AI 以一种超越文本的方式来呈现信息和与用户交互,例如实时绘制图表、展示流程图、标注图片等。
- 节点 (Nodes)节点工具是 OpenClaw 连接物理设备能力的体现。通过在 macOS、iOS 或 Android 设备上运行的节点应用,OpenClaw 的主服务(Gateway)可以远程调用这些设备的原生功能,例如:
- camera.snap: 控制手机摄像头拍照。
- screen.record: 录制设备屏幕。
- location.get: 获取设备的地理位置。
- system.notify: 在设备上发送系统通知。
- Cron 工具为 OpenClaw 带来了“记忆”和“计划”的能力。
- Webhooks。Webhooks 允许 OpenClaw 接收来自其他第三方应用或服务的主动推送。这意味着 OpenClaw 可以被动地响应外部事件,例如,当 GitHub 仓库有新的代码提交时,自动触发一次代码审查流程。
强大的能力也伴随着安全风险。OpenClaw 对此有周全的考虑。工具的执行受到严格的权限控制。在沙箱(Sandbox)模式下,可以限制某些会话(例如,来自群聊的请求)只能使用安全的、经过授权的工具,从而防止潜在的恶意操作。
AI Agent和普通chatbot最大的区别是什么?是它能执行真实操作——跑命令、改文件、发请求、调API。这个能力是双刃剑,问题是怎么降低风险、怎么控制爆炸半径。
- 默认情况下Agent执行任何敏感操作都需要用户确认,文件操作只能在指定目录里搞,网络请求有白名单限制,系统命令要过审批。
- Docker部署的话更狠——非root用户运行、文件系统可以设成只读、capabilities全部drop掉。
- 还有个openclaw security audit –deep命令,能扫描当前配置有没有安全隐患,扫完给你出报告告诉你哪里有风险、怎么修。 OpenClaw的安全策略明确写了”prompt injection attacks are out of scope”——就是说它不试图防prompt注入,因为以现在的技术这玩意防不住。它的思路是:既然prompt注入防不住,那就假设Agent会被”骗”,然后在执行层面做限制,让Agent就算被骗了也干不了太出格的事。
用户交互
在传统软件工程中,构建一个全功能应用通常需要前端(React/Vue)、后端(Node/Python/Rust)和数据库的紧密配合,形成复杂的 MVC 或 MVVM 架构。而 OpenClaw 采取了激进的“无界面”(Headless)设计策略,将即时通讯软件(IM)提升为唯一的交互界面(UI)。
IM 即任务入口
- 基本上你能想到的平台OpenClaw都支持。每个平台的消息格式不一样、富文本能力不一样、附件限制不一样、webhook机制不一样、rate limit不一样。Clawdbot的做法是搞了一个WebSocket Gateway作为中心枢纽,所有平台的消息都先转成统一的内部格式进Gateway,处理完再转成各平台的格式出去,中间的AI Agent只处理标准格式的输入输出。每个平台对应一个Channel Adapter,Adapter只负责格式转换这一件事,业务逻辑一行都没有。
- CLI系统。OpenClaw有100多个CLI子命令,能干的事情包括但不限于:管理Skills、配置插件、调试Agent、查看日志、管理记忆、做安全审计、导入导出数据。为什么这很重要?因为CLI是最被低估的用户体验。
默认情况下,系统采用配对模式(Pairing Mode)。当一个陌生的用户首次向您的 AI 助手发送消息时,系统并不会处理该消息,而是会自动回复一个一次性的“配对码”。只有您(作为管理员)在 OpenClaw 的命令行中执行 openclaw pairing approve <配对码> 命令,确认授权该用户访问后,这位用户才能正式与您的 AI 助手进行对话。这就像是为您的数字家庭设置了一个可靠的门禁系统。
源码
从技术上讲 是一个 TypeScript CLI 应用程序,一个 Node.js 应用。核心配置文件位于 ~/.clawdbot/clawdbot.json,在此调整模型参数、渠道设置、安全策略等。
- 运行在你机器上的进程,并暴露一个 网关服务器(Gateway Server) 来处理所有频道连接(Telegram, WhatsApp, Slack 等)。
- 调用 LLM API(Anthropic, OpenAI, 本地模型等)。
- 在本地执行工具。
- 根据你的指令操控电脑。
Channel Adapter ==> Gateway Server ==> Agent Runner ( loop[build context ==> llm call] ==> save response ) ==> Gateway Server ==> Channel (outbound)Adapter。
Agent Runner 内模型在处理每个请求时到底看到了什么:
[0] 系统提示词 (System Prompt) (静态+条件指令)
[1] 项目上下文 (引导文件: AGENTS.md, SOUL.md 等)
[2] 对话历史 (消息, 工具调用, 压缩摘要)
[3] 当前消息
内核 Pi
OpenClaw把 Pi 以 SDK 方式嵌入到 Gateway 架构里,Gateway 是整个服务端运行时和唯一控制平面。消息渠道的生命周期管理、Agent 事件分发、定时任务调度、插件加载、浏览器自动化、设备节点注册、会话和状态存储——全部都绑在这个长期运行的 WebSocket 进程上(127.0.0.1:18789)。其架构可以概括为一个以Gateway(网关)为核心的控制平面的分布式系统。
- Pi 提供的是“通用引擎”——模型抽象、流式推理、agent loop、工具执行这些底层机制;
- Pi 整套系统提示词加工具定义加起来不到 1000 tokens。核心只有 read、write、edit、bash 四个工具。
- 在 Pi 的设计中,也明确了几个主动选择「不做」的功能:
- 不支持 MCP。 给出的替代方案是,写 CLI 工具配 README 文件。agent 需要某个工具时才读对应的 README,按需付出 token 成本,然后用 bash 调用。
- 不内置 plan mode。直接告诉 agent “我们先一起想清楚这个问题,不要改文件也不要执行命令”就够了。
- 不内置 to-do 系统。Mario 的经验是,to-do 列表通常让模型更困惑而不是更高效,增加了模型需要追踪和更新的状态,会引入更多出错的机会。
- 不做后台 bash。后台进程管理会引入大量复杂性,进程追踪、输出缓冲、退出清理、向运行中的进程发送输入。
- 不内置 SubAgent。在这一点上,Mario 的态度最坚决。Claude Code 执行复杂任务时经常在背后生成 SubAgent,完全看不到子 agent 的对话过程,属于「黑箱里的黑箱」。
- OpenClaw 则负责“车身和交通规则”——会话怎么建、怎么存、怎么分支,实例怎么发现,怎么连到 WhatsApp / Telegram / Discord 这类 IM 通道,以及怎么接沙盒与各种外部系统。
代码里导入 Pi 的包,通过 createAgentSession() 实例化 AgentSession,让 Pi 在进程内承担推理与工具循环。
主循环架构 (runEmbeddedPiAgent in run.ts)
runEmbeddedPiAgent()
└── while (true) { // 行538 - 主重试循环
├── 检查重试次数限制 (MAX_RUN_LOOP_ITERATIONS)
├── 调用 runEmbeddedAttempt() // 单次推理尝试
├── 处理 context overflow → 自动压缩
├── 处理 auth failure → profile轮换
├── 处理 timeout → 重试或报错
└── 成功则返回 payloads
}
单次推理尝试 (runEmbeddedAttempt in run/attempt.ts)
runEmbeddedAttempt()
├── 1. 准备阶段
│ ├── 创建 workspace 和 session
│ ├── 解析 tools (createOpenClawCodingTools)
│ ├── 构建 system prompt
│ └── 创建 session manager
│
├── 2. 会话初始化
│ ├── createAgentSession() // 行688
│ ├── 设置 streamFn (LLM调用函数)
│ └── 安装事件订阅器 subscribeEmbeddedPiSession() // 行921
│
├── 3. 执行推理
│ ├── await activeSession.prompt(effectivePrompt) // 行1180-1182
│ │ └── 调用 LLM API(streamSimple/streamFn)
│ │
│ └── 事件流处理:
│ ├── message_start/message_update/message_end → handleMessageStart/Update/End
│ ├── tool_execution_start/update/end → handleToolExecutionStart/Update/End
│ └── agent_start/agent_end → handleAgentStart/End
│
└── 4. 返回结果
├── assistantTexts(生成的文本)
├── toolMetas(工具调用元数据)
└── usage(token使用统计)
Context(上下文) = OpenClaw 在一次运行中发送给模型的所有内容
Context 窗口
系统提示词(OpenClaw 构建)
工具列表 + 描述
Skills 列表(仅元数据)
工作区位置 + 时间 + 运行时元数据
注入的工作区文件(AGENTS.md, SOUL.md, TOOLS.md...)
对话历史(用户消息 + 助手消息)
工具调用 / 结果 + 附件(图片 / 音频 / 文件)
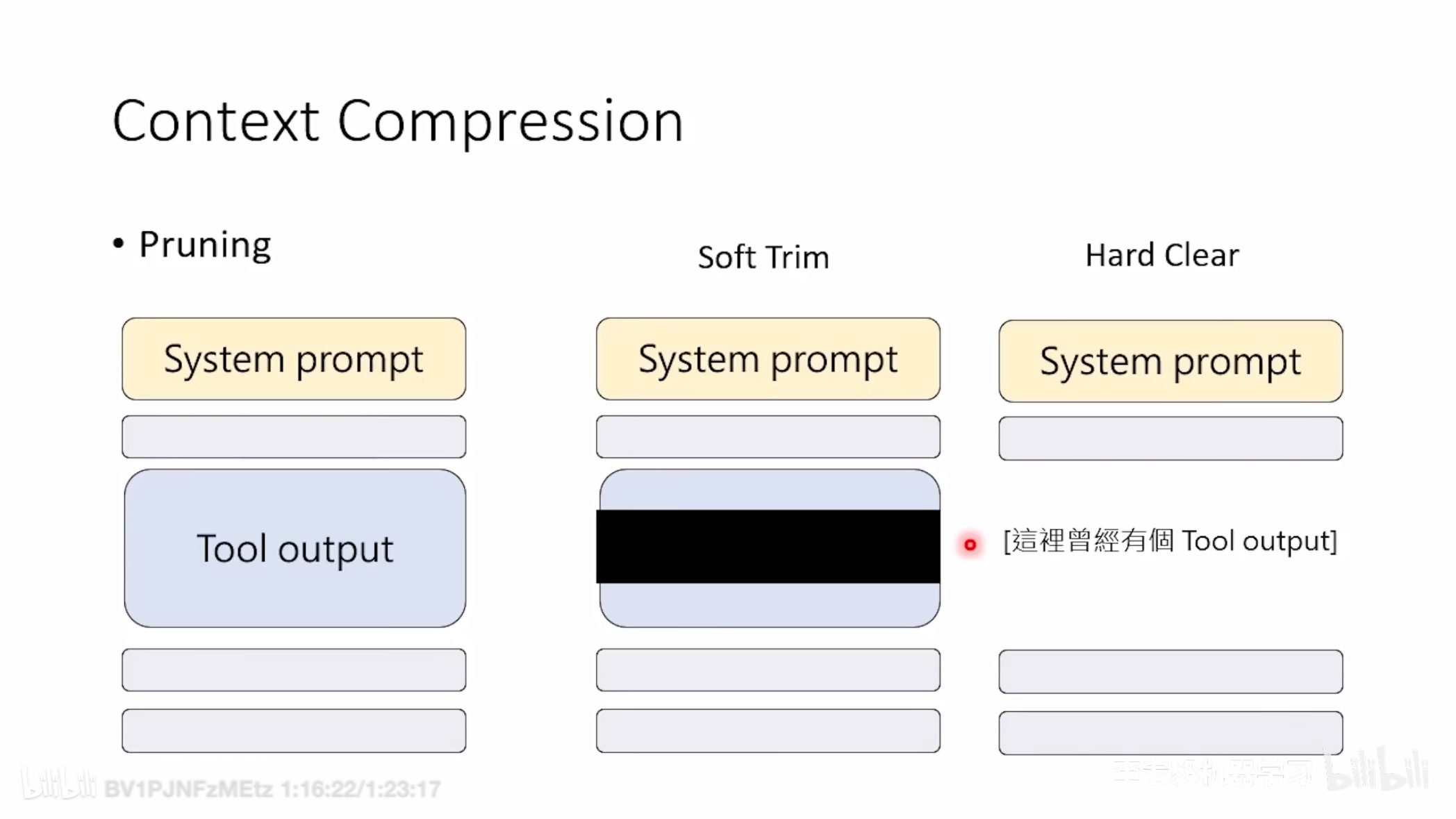
Compaction 摘要 + Pruning 产物
当会话接近或超过上下文窗口时,OpenClaw 自动触发压缩:旧消息 ──→ LLM 总结 ──→ 紧凑摘要条目 ──→ 持久化到 JSONL
agent loop
发起query触发 session.prompt(“List files…”)。这是 coding-agent 层的外壳,负责命令解析、skill 展开、扩展 hook 这些前处理,处理完把消息递给核心层的 agent.prompt(text)。agent.prompt 干两件事:
- 把字符串包成一条 user message
- 起一个 AbortController、把 state.isStreaming = true,然后调 runAgentLoop(messages, ctx, cfg, emit), runAgentLoop 是热身阶段,先把开场 4 个事件喊出去:
- emit agent_start
- emit turn_start ← 第 1 个 turn_start(runAgentLoop 自己发的)
- emit message_start (user)
- emit message_end (user)
热身完了,控制权交给 runLoop ,真正的循环开始。
let firstTurn = true; // runAgentLoop 已经发过一次 turn_start 了
let pendingMessages = (await config.getSteeringMessages?.()) || [];
// 待注入的用户消息(一般是空的)
while (true) { // 外层:follow-up loop
let hasMoreToolCalls = true;
while (hasMoreToolCalls || pendingMessages.length > 0) {
// 内层:turn loop
}
}
turn loop/Tool-Use Loop。经典 ReAct 范式把「推理」当成循环一等公民:模型先 think,再 act,再 observe,推理文本本身就是控制流。Tool-Use Loop 反过来,把「工具调用」当成流程控制器,推理文本更多只是附带产物。是否继续循环、是否并发执行、是否截断,都由 Harness 根据 tool_call 列表判定,不再依赖模型自由发挥的措辞模式。
// 模型每次响应都带 stopReason。toolUse 表示模型还要继续用工具
while (stopReason === "toolUse") {
runTools();
callModel();
}
一个 turn 由模型一次响应和它触发的工具结果构成(Session ==> turn ==> model-call + tool-call)。pi 把这段打包成一个边界,外面的代码就有地方挂钩子:
- 每个 turn 跑完,可以决定要不要压缩历史、要不要中断、tool budget 还剩多少。
- 想做断点续跑,turn_end 是天然的 checkpoint 点
- UI 可以利用 turn 边界把”模型响应 + 工具结果”组织成一组,用户看到的就不是一长串裸事件 没有 turn 边界? 没法做 per-turn 的钩子——自动压缩历史、tool budget、abort、UI 折叠全都没地方挂;持久化也没有天然的快照点,崩了不知道从哪接。
长期运行
很多 agent 失败,不是因为不会做,而是因为做着做着就忘:上下文一压缩,关键背景就被挤出去,最后变成反复重讲、反复试错。OpenClaw 的解法:能分支、能回放、能压缩。
- 两层持久化:
sessions.json:小而可变的 session store,像索引表,记录元信息(当前 session、上次活动、计数器、toggle、压缩周期状态等)。*.jsonltranscript:追加写的事件日志,才是真正的“会话历史”。它不只是聊天记录,还会包含工具调用、压缩摘要、分支摘要等条目。
- 树状 transcript:
- transcript 的条目用 id/parentId 形成树结构,于是你可以开“支线”(基于 forkSessionFromParent())处理脏活(比如修一个坏掉的工具、尝试两套方案),做完再回到主线;支线发生的事可以被总结成 branch_summary 带回主线。这极大降低了长期任务最常见的成本:“修工具把主对话上下文污染掉”。
- 压缩前落盘(最硬的一步):
- 在自动 compaction 触发前,OpenClaw 会先跑一轮静默的 memory flush:当上下文使用接近阈值时,先强制 agent 把关键持久状态写进工作区文件(例如当天的记忆/状态文件),并用 NO_REPLY 让用户无感。
- 你可以把它理解成:先把命根子写进硬盘记忆,再允许短期上下文被压缩。长任务因此不靠“模型记性好”,而靠“系统先把该留的留住”。
为了让“长期运行”更可控,OpenClaw 还会加载自定义扩展做护栏:
- Compaction Safeguard:给压缩加保护(例如更稳的 token 预算、工具失败/文件操作的必要摘要),避免压缩把执行语义压坏。
- Context Pruning:更可控的上下文修剪策略(比如基于缓存 TTL),防止上下文无限膨胀,同时避免粗暴裁剪剪断关键线索。
sub-agent
表面上看,SubAgent 解决的是「并行执行」问题——多个任务同时推进,提升效率。。然而事实上,拆分 Agent 不只是为了”分工”,更是为了”上下文压缩”或者说”上下文隔离”。
- System Prompt 完全不同。Subagent 的提示是”聚焦式”的,强调专注任务、不发起对话;
- 工具集(ToolRegistry)完全不同且受限
- 消息历史完全隔离,Subagent 没有对话历史,每次都是”全新”的开始;
- 最大迭代次数不同,Subagent 执行的任务应该是相对独立的和快速的,避免子代理运行过久占用资源。
- 结果处理方式不同,Subagent 的结果通过 MessageBus 通知 Main Agent,Main Agent 再转发给用户
可观测性
畅想汇总
- 每个人有一个bot,bot 与bot 可以交流
- 我们可以预见,未来的个人计算设备,可能不再是一个个独立的 App 图标的集合,而是一个由类似 Clawd 这样的 AI Agent 作为核心交互界面的“个人 AI 操作系统”。用户通过自然语言下达任务,AI Agent 则负责调度设备上的所有硬件、软件和服务资源来完成它。
几个变化
- 从“提示词工程”转向“系统级适配”。OpenClaw核心设计理念在于将智能体定义为磁盘上的文件集合,而非单纯的代码或需反复注入的提示词。记忆以 Markdown 文件的形式持久化存在于工作区中。这一转变使智能体从一次性脚本升维为可版本控制的基础设施,进而倒逼模型厂商在构建 LLM 时,必须确保模型具备处理模块化、动态组装指令堆栈的能力。模型不仅需理解单一 Prompt,更要在包含 session 历史、技能定义及内存检索结果的复杂系统提示词中,保持推理的稳定性,避免因结构复杂化而“迷失”。
- 内化“上下文管理”能力以应对长程任务。传统的 Agent 通常将上下文管理看作是一个外部的动作:由开发者预设死规则,硬性截断,或或调用另一个更便宜的模型把旧对话总结成一段话,再喂给主模型。随着交互轮次增加,模型看到的是一个被开发者阉割过的上下文,这会导致模型产生幻觉或逻辑不连贯。而将“上下文管理”从外部逻辑转化为 Agent 的内在行为,已经成为当前的集中实践。例如 Letta/MemGPT 能通过一套分页 (Paging) 算法,让 Agent 通过函数调用,自主地将旧记忆从上下文移动到外部存储,或者根据当前需求从外部提取特定历史。Mem0 则用 LLM 提取出结构化的事实并与现有记忆进行冲突检测,并将其转化为结构化的记忆条目存入向量数据库。
- 自进化。目前的智能体往往依赖人工写好的专用工具和固定流程:在熟悉任务里表现不错,但一旦进入开放世界,遇到信息噪声、目标变化、环境随机性或工具缺失,就很容易“卡住”。我们认为,通往 AGI 的关键不只是“能在很多领域用”,更重要的是在面对从未见过的新环境、新规则、新任务时,仍能自主进化学习——边做边吸收经验、沉淀通用能力,并在与环境的交互中持续提升,而不是靠人工补齐工具、改流程或额外训练来“续命”。在新环境里真正决定“能不能动起来”的往往是 tools——没有合适工具,再强的规划与记忆也会被功能边界锁死。基于此,我们首先以“工具自进化”为核心路径(Context、Tools、Workflow各自如何进化),让智能体在任务中自动生成、优化并复用新工具,并将有效能力沉淀为可迁移的通用工具库。
我们在编写提示词时,往往很容易陷入“啰嗦”导致Prompt越来越“冗长”,试图用大量的解释性语言去覆盖各种边界情况,导致token消耗巨大且重点模糊,模型也未必遵循的很好。而OpenClaw的原始Prompt展现了极高的简洁主义风格。比如,当AGENT.md里要求在群聊的时候不要每条都回复,Prompt通过一句Quality > quantity就非常清晰的传达了“注重核心信息、拒绝废话、保证高价值输出”的复杂指令。再比如,当OpenClaw在不确定的、模糊的时候需要去询问用户,Prompt里用了一句Ask anything you're uncertain about。
留下评论