从长期回报、Credit Assignment 到 PPO
简介
- 简介
- 什么是强化学习
- 一张 RL 家谱图
- 第一问:怎么定义长期回报,而不是只看眼前这一步
- 第二问:怎么把“整段轨迹最后才知道好不好”这件事,分摊到中间每一个 action 上
- 第三问:怎么让训练既朝高回报方向更新,又不至于一下子把策略训歪
这篇文章不追求把强化学习的所有公式一口气讲完,而是先回答一个更重要的问题:
强化学习这棵树是怎么长出来的?
很多人第一次学 RL,会觉得内容特别碎:
- 一会儿是 MDP、Bellman 方程
- 一会儿是 MC、TD
- 一会儿又跳到 Q-learning、Policy Gradient
- 再往后又是 Actor-Critic、GAE、PPO
看起来像是一堆并列算法,但其实它们不是“平铺罗列”的关系,而是一条很明确的演化主线:
\[\text{Bellman} \rightarrow \text{MC / TD} \rightarrow \text{Q-learning / Policy Gradient} \rightarrow \text{Actor-Critic} \rightarrow \text{GAE} \rightarrow \text{PPO}\]如果先把这条主线串起来,后面的细节会好懂很多。
这篇主线梳理也参考了强化学习从入门到掌握的学习笔记(四)里对 RL 主干结构的总结。
如果把这条演化主线再压缩一下,也可以理解成 RL 在逐步解决三个连续问题:
- 怎么定义“长期回报”,而不是只看眼前这一步。
- 怎么把“整段轨迹最后才知道好不好”这件事,分摊到中间每一个 action 上。
- 怎么让训练既朝高回报方向更新,又不至于一下子把策略训歪。
放到 LLM 语境里,这三个问题分别对应:怎么看整段回答值不值得鼓励、怎么给中间 token 分配 credit、以及怎么避免模型在 post-train 时偏离原有分布太远。
什么是强化学习
从系统视角看,强化学习至少包含下面几个基本元素:
- 智能体(Agent):负责学习和决策,也就是“谁在做动作”
- 环境(Environment):智能体之外一切与其交互的对象,也就是“动作作用在谁身上”
- 状态(State):环境在某一时刻的快照
- 动作(Action):智能体在当前状态下可以采取的操作
- 奖励(Reward):环境对动作的反馈
强化学习最核心的不是单个元素,而是它们之间形成了一个闭环:
\[\text{状态} \rightarrow \text{动作} \rightarrow \text{反馈} \rightarrow \text{更新策略}\]也正因为这是一个闭环,强化学习和普通监督学习相比,训练数据不是静态给定的,而是会随着策略变化而变化。当前策略选什么动作,会直接影响之后能看到什么状态、拿到什么奖励。
这也是 RL 和监督学习的本质区别之一。
监督学习更像是在学:
\[x \rightarrow y\]而强化学习更像是在学:
\[state \rightarrow action\]但 RL 里没有一个现成标签直接告诉你“这个动作对不对”,只有环境在一段时间后给你反馈。所以 RL 关注的不是单步是否正确,而是这一连串动作最终能不能带来更高的长期收益。放到 LLM 上,对应的是:我们不该只看某个 token 当下像不像好词,而要看“这个 token 接下去会不会把整段回答带向更好的结果”。
如果用一个更直观的比喻,微调有点像是对一只已经会基本动作的机器狗做定向训练。比如它已经会走路、会听简单指令,现在你希望它在公园里专门学会捡某一种球,这时你可以用一组更具体的数据继续调它的行为。强化学习则更像是让这只机器狗在环境里自己试错学新技能:你不给它标准答案,只给它目标和激励,比如“尽可能快地找到并捡起球”。它每次尝试后拿到奖励,再逐渐调整自己的行为。比如它发现跑直线更快找到球,之后就会更倾向于这样做。
这也导致 RL 有三个天然难点:
- 奖励经常是延迟的
- 奖励通常比较稀疏
- 当前动作会改变未来拿到的数据分布
从思想史上看,强化学习本身就是一种 trial-and-error learning。更早的时候,“reinforcement” 这个词最初被用来描述巴甫洛夫实验里行为被增强的现象;到了 20 世纪 80 年代,强化学习才在 MDP 框架下逐步拥有了比较严谨的数学基础。
从更直觉的角度讲,强化学习的魅力也在于它不是试图把每一项任务都手把手教给系统,而是通过激励机制让系统自己去学会解决问题。在这个意义上,强化学习更像“教会它什么值得追求”,而不是“直接告诉它每一步怎么做”。
我很喜欢一个相关表述:o1核心作者MIT演讲:激励AI自我学习,比试图教会AI每一项任务更重要。里面有句话是:“Teach him the taste of fish and make him hungry.” 可以翻成“先让它尝到鱼的味道,再让它饿起来”。意思不是一步步手把手教它钓鱼,而是给它目标和驱动力,让它自己在过程中学会更多通用技能,比如耐心、观察环境、推理规律。对人类来说,直接教往往更快;但对机器来说,只要给足计算,它是有机会通过这种激励式学习长出更通用能力的。
一张 RL 家谱图
先放结论图:
长期回报最大化
|
v
Bellman 递推
|
+-- 动态规划 / 价值迭代
| 前提:环境已知
|
+-- 采样近似(环境未知)
|
+-- MC
+-- TD
|
+-- Value-based
| |
| +-- Q-learning
| +-- DQN
|
+-- Policy-based
| |
| +-- REINFORCE / PG
|
+-- Actor-Critic
|
+-- A2C / A3C
+-- GAE
+-- TRPO
+-- PPO
这张图最重要的不是记住所有算法名,而是记住每一代方法都在解决什么问题:
- Bellman:长期目标怎么递推
- MC / TD:环境未知时,怎么估 value
- Q-learning:怎么通过 value 直接做 control
- Policy Gradient:连续动作或高维空间里,怎么直接学 policy
- Actor-Critic:怎么降低 PG 的方差
- GAE:怎么更稳地估 Advantage
- PPO:怎么限制 policy update 的幅度
学会价值之后,还要进一步解决一个更实际的问题:
在状态 $s$ 下,到底怎么选动作?
于是 RL 开始分成两条经典路线。
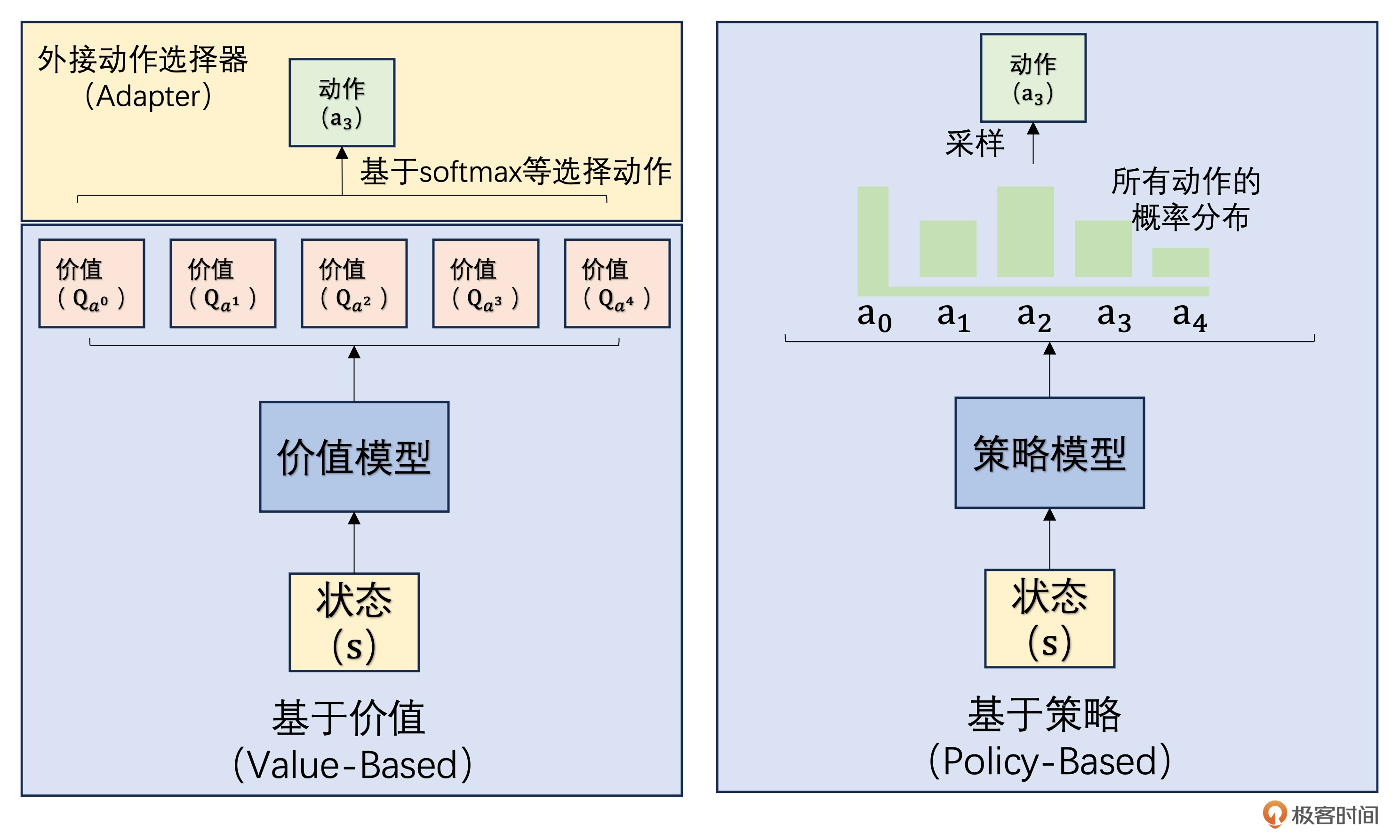
Value-based
Value-based 的想法是:
先把动作价值学出来,再通过贪心选择动作。
更准确地说,这一路方法通常不需要一个显式策略,而是让状态价值函数 $V_{\pi}(s)$ 和动作价值函数 $Q_{\pi}(s,a)$ 隐式承担起制定策略的角色。只要找到了一个足够好的价值函数,最优策略也就跟着出来了。
最典型的方法是 Q-learning:
\[Q(s,a) \leftarrow Q(s,a) + \alpha \left[ r + \gamma \max_{a'} Q(s',a') - Q(s,a) \right]\]如果我们已经学到了 $Q^*(s,a)$,那策略可以直接写成:
\[\pi(s) = \arg\max_a Q^*(s,a)\]这条路线的优点是:
- 离散动作很自然
- 逻辑直接
- 往往收敛更快,训练通常也更稳定
但它的问题也很明显:
- 连续动作空间里很难做 $\arg\max$
- 状态空间和动作空间一大,Q-table 就不现实了
- 高维复杂任务上不够灵活
这也是为什么在 LLM 场景里,value-based 方法通常不是主流:token 级 action space 太大,直接做基于动作值的显式选择并不自然。不过 value 的思想本身依然重要,很多时候它仍然会以 Critic、baseline,甚至训练数据筛选信号的形式出现。
Policy Gradient
另一条对称的主线是 Policy-based。
它的想法不是先把 value 学出来,再由 value 推出动作;而是直接学习策略本身:
\[\pi_{\theta}(a \mid s)\]这条路线的特点是:
- 直接优化策略,更适合连续动作空间
- 更容易表示随机策略
- 在高维复杂问题里通常更灵活
它的代表方法就是 Policy Gradient,后面进一步长出了 Actor-Critic、GAE、PPO 这一支。也就是说,如果说 Value-based 更像是“先学怎么评分,再按分数选动作”,那么 Policy-based 更像是“直接学习在什么状态下该怎么行动”。
再补一个视角:Model-based 和 Model-free
除了按 value-based / policy-based 来看,还可以按“我们对环境知道多少”再切一刀:
- Model-based:环境更像白盒,状态转移和奖励结构已知或可建模,可以直接做规划
- Model-free:环境更像黑盒,只能靠和环境交互获得反馈来学习
Model-based 一族通常包括 Value Iteration、Policy Iteration 这类方法;而日常最常见的 Q-learning、Policy Gradient、Actor-Critic、PPO,则基本都属于 Model-free。
如果把这两个视角叠在一起看,就会更清楚:
- Bellman 是总源头
- MC / TD 是在未知环境下逼近 Bellman 的基础工具
- Value-based 和 Policy-based 是 control 层面的两条主要路线
- Actor-Critic 则是这两条路线的一次创造性融合
第一问:怎么定义长期回报,而不是只看眼前这一步
RL 先做的第一件事,不是想办法直接学动作,而是先把“什么叫好”定义清楚。RL 的目标其实很简单:最大化长期回报,而不是最大化某一步的即时奖励。
也正因为如此,RL 先引入了 return 这个概念。直觉上说,return 就是“从当前这一步开始,往后能拿到的总收益”,而不是只看眼前这一小步的奖励。只有先把优化目标从“即时奖励”切换到“长期回报”,后面的 Bellman 递推、value function、policy optimization 才有意义。
长期回报通常写成:
\[G_t = r_{t+1} + \gamma r_{t+2} + \gamma^2 r_{t+3} + \dots\]也可以写成递推形式:
\[G_t = r_{t+1} + \gamma G_{t+1}\]这里:
- $r_{t+1}$ 是下一步的即时奖励
- $\gamma$ 是折扣因子
- $G_t$ 表示从时刻 $t$ 开始往后的累积折扣奖励
如果从最简单的问题出发,强化学习通常先从 bandit 讲起。
想象你面前有 3 台老虎机:A / B / C 的平均奖励分别不同,但你一开始不知道。你的目标是:用尽量少的试错,找到长期最赚钱的那台机器。这就是 k-armed bandit。
bandit 已经体现了 RL 的核心矛盾:
- 探索(exploration):多试几个选择,了解哪个更好
- 利用(exploitation):多用当前看起来最好的选择
但 bandit 还不是真正完整的 RL,因为它没有状态。现实问题更复杂:动作不仅会带来即时奖励,还会改变后续局面。这也是为什么需要 MDP。
一个强化学习问题通常建模成马尔可夫决策过程(Markov Decision Process, MDP)。它的关键假设是:未来只依赖当前状态,而不依赖更久远的历史。
这句话不是说历史不重要,而是说:当前状态已经把历史中对决策有用的信息压缩进来了。例如围棋棋盘的当前局面,就已经是过去所有落子的压缩结果。
如果再往前追一层,MDP 是从马尔可夫随机过程长出来的。随机过程研究的是“随时间演变的随机现象”,也就是概率论里偏动力学的一部分。某个时刻 $t$ 的状态记作 $S_t$,如果已知完整历史 $(S_1,S_2,\dots,S_t)$ 时,下一时刻状态 $S_{t+1}$ 的概率写作:
\[P(S_{t+1} \mid S_1,S_2,\dots,S_t)\]而当一个随机过程满足:
\[P(S_{t+1} \mid S_t)=P(S_{t+1} \mid S_1,S_2,\dots,S_t)\]就说它具有马尔可夫性质。也就是说,当前状态已经是未来的充分统计量,知道当前状态以后,更早的历史不再额外提供决策所必需的信息。强化学习再往前走一步,把动作也放进来,就得到:
\[P(S_{t+1} \mid S_t, A_t)\]这就是 MDP 里“动作会影响未来状态演化”的来源。
MDP 通常写成五元组 $(S, A, P, R, \gamma)$:
- $S$:状态空间
- $A$:动作空间
- $P(s’ \mid s,a)$:状态转移概率
- $R$:奖励函数
- $\gamma$:折扣因子
折扣因子 $\gamma$ 的作用很重要:
- 从数学上,它让无限长轨迹的累积奖励保持有界
- 从决策上,它刻画了智能体有多“看重未来”
正是在 MDP 框架下,RL 才把“状态如何演化”“动作如何影响未来”“长期奖励如何计算”这些问题放到了一起,这也就是 Bellman 方程得以出现的背景。
为了把长期回报和当前决策连接起来,RL 引入了价值函数。
针对策略 $\pi$:
状态价值函数定义为:
\[V_{\pi}(s) = \mathbb{E}_{\pi}[G_t \mid s_t = s]\]动作价值函数定义为:
\[Q_{\pi}(s,a) = \mathbb{E}_{\pi}[G_t \mid s_t = s, a_t = a]\]它们分别回答两个问题:
- 这个状态总体值多少钱
- 在这个状态下,这个动作值多少钱
Bellman 方程之所以是 RL 的源头,是因为它把“长期回报”拆成了“当前一步 + 未来价值”。
由
\[G_t = r_{t+1} + \gamma G_{t+1}\]再结合
\[V_{\pi}(s) = \mathbb{E}_{\pi}[G_t \mid s_t = s]\]可以得到:
\[V_{\pi}(s) = \mathbb{E}_{\pi}\left[ r_{t+1} + \gamma V_{\pi}(s_{t+1}) \mid s_t = s \right]\]这句话非常关键,因为它给了 RL 一个递推结构:
当前状态值多少钱 = 当前一步奖励 + 折扣后的下一状态价值。
也就是说,Bellman 方程真正提供的不是一个孤立公式,而是一种“把未来折回现在”的方法。正因为有了这个递推结构,学习才可以从“整条轨迹算一次总账”,变成“边交互边更新”。
如果继续往“最优”方向走,就有:
\[V^*(s) = \max_{\pi} V_{\pi}(s)\]以及:
\[Q^*(s,a) = \max_{\pi} Q_{\pi}(s,a)\]常见的 Bellman 最优方程写法是:
\[Q^*(s,a) = r(s,a) + \gamma \sum_{s'} P(s' \mid s,a) V^*(s')\]到了这一步,问题变成了:
既然 Bellman 递推很重要,那现实里怎么学它?
如果环境已知,可以直接做动态规划、价值迭代、策略迭代。但现实里大多数问题都不是白盒,所以真正常见的是:环境未知,只能靠采样近似。
这时最基础的两条路线就是 MC 和 TD。
Monte Carlo
MC 的核心思想是:等整条轨迹结束,再用真实回报更新。
更新形式可以写成:
\[V(s) \leftarrow V(s) + \alpha (G_t - V(s))\]它的特点是:
- 用真实回报 $G_t$
- 不 bootstrap
- 无偏
- 但方差大,而且必须等 episode 结束
Temporal Difference
TD 的核心思想是:不等未来全部发生,而是用当前估计去近似未来,也就是所谓的 bootstrapping。
最简单的一步 TD 更新是:
\[V(s) \leftarrow V(s) + \alpha \left( r + \gamma V(s') - V(s) \right)\]对应的 TD error 是:
\[\delta_t = r_t + \gamma V(s_{t+1}) - V(s_t)\]TD 的特点是:
- 可以在线更新
- 方差更小
- 样本效率更高
- 但因为用了估计值,所以会有偏差
一句话记忆:
- MC:等账单出来再记账
- TD:先按预估入账,再不断修正
第二问:怎么把“整段轨迹最后才知道好不好”这件事,分摊到中间每一个 action 上
这一步是 RL 真正难的地方,也就是 credit assignment。如果最后只给一个总分,那中间每一步到底谁该记功、谁该背锅?放到 LLM 上sequence-level reward 只告诉你“整段回答总体好不好”,但训练时必须把这个总体评价,变成每个 token 的更新权重,否则模型没法知道,究竟是哪个步骤、哪种说法、哪个推理分支更值得强化。
Policy Gradient
在第二问里,我们先看 Policy-based 这条路线中最基础的方法:Policy Gradient。
Policy Gradient 则反过来想:
我不先学 value 再推出动作,而是直接学策略本身。
策略写作:
\[\pi_{\theta}(a \mid s)\]目标是直接最大化期望回报:
\[J(\theta) = \mathbb{E}_{\pi_{\theta}}[G_t]\]策略梯度的核心形式可以写成:
\[\nabla_{\theta} J(\theta) = \mathbb{E}_{\pi_{\theta}} \left[ \nabla_{\theta} \log \pi_{\theta}(a_t \mid s_t) G_t \right]\]最原始的策略梯度方法比较粗糙:“既然这整条轨迹最后得分高,那轨迹里的动作都一起鼓励;得分低,就都一起压制。”这能跑,但很粗糙,不知道中间到底是哪一步真正起了关键作用。后面 Actor-Critic、Advantage、GAE 这些方法,本质上都是在继续改进这件事。
Policy Gradient 非常重要,因为它解决了 value-based 的几个关键限制:
- 连续动作空间更自然
- 可以直接优化策略
- 可以自然表示随机策略,更适合高维问题和复杂分布
但它也带来了一个大问题:
方差太大,训练不稳定。
如果想系统看策略梯度一系的发展脉络,可以直接读综述 The Definitive Guide to Policy Gradients in Deep Reinforcement Learning: Theory, Algorithms and Implementations。
Actor-Critic 可以看成是 value-based 和 policy-based 的融合。
它把职责拆成两部分:
- Actor:负责输出策略 $\pi(a \mid s)$
- Critic:负责估计价值,给 Actor 提供更稳定的学习信号
它的核心思想,是把原来直接用的 $G_t$,换成更稳定的 Advantage:
\[A(s,a) = Q(s,a) - V(s)\]Advantage 表示的是:
这个动作比当前状态下的平均水平好多少。
于是策略更新就不再是问“这个动作最后得了多少分”,而是问“这个动作相对平均水平是不是更好”。这样做的好处是,很多和状态整体难度相关的公共波动会被减掉,训练信号更稳定。
对应的策略梯度可以写成:
\[\nabla_{\theta} J(\theta) = \mathbb{E}_{\pi_{\theta}} \left[ \nabla_{\theta} \log \pi_{\theta}(a_t \mid s_t) A(s_t,a_t) \right]\]Critic 一般通过 TD 目标去学价值函数,例如:
\[V(s_t) \leftarrow V(s_t) + \alpha \left( r_t + \gamma V(s_{t+1}) - V(s_t) \right)\]从家谱上看,Actor-Critic 的意义就在于:
它让 RL 从“只靠原始 return 更新 policy”,进化成“用 value estimation 给 policy 提供低噪声信号”。
有了 Actor-Critic 之后,问题又进一步变成:
Advantage 该怎么估,才既不太抖,又不太偏?
如果完全用 Monte Carlo 风格的 return,方差很大;如果只用一步 TD,又可能太粗糙。于是就有了 GAE(Generalized Advantage Estimation)。
GAE 的核心可以理解成:
- TD:偏差大但方差小
- MC:偏差小但方差大
- GAE:把多步 TD 残差按权重叠起来,在 bias / variance 之间做折中
所以 GAE 不是一个完全独立的新范式,它在家谱里的位置更像是:
Actor-Critic 上进一步优化 Advantage 估计的方法。
尤其在 LLM 这种“末尾才拿到整体 reward”的场景里,GAE 的作用很大,因为它可以更稳定地把最终奖励分摊到中间 token 上。
第三问:怎么让训练既朝高回报方向更新,又不至于一下子把策略训歪
到了 Actor-Critic + GAE,其实已经“能学”了。但工程上还有一个特别现实的问题:policy 更新太猛,模型很容易一下改崩。如果你某一轮采样恰好采到几条高分轨迹,就猛地把这些动作概率抬得很高,模型很容易跑偏。
前两问主要解决的是:长期目标怎么定义、最终结果怎么分摊给中间动作。到了第三问,重点就变成了:即使已经知道该往哪个方向优化,更新的时候也不能一步跨太大,否则模型很容易训练崩掉。PPO 之所以重要,主要就是因为它在这件事上给出了一个工程上非常好用的解法。
- TRPO / PPO:限制每次 policy update 幅度
- KL penalty:别离参考模型太远
PPO 的核心就是:限制更新幅度。
定义新旧策略比值:
\[ratio = \frac{\pi_{new}(a \mid s)}{\pi_{old}(a \mid s)}\]它表示:新策略相对旧策略,把这个动作的概率放大了多少。
如果旧策略给某动作的概率是 0.01,新策略一下拉到 0.5,那么:
\[ratio = 50\]这种更新就太激进了,很容易训练崩掉。
所以 PPO 使用 clip:
\[\mathrm{clip}(r, 1 - \varepsilon, 1 + \varepsilon)\]对应的 PPO loss 写成:
\[L = \min\left( rA,\ \mathrm{clip}(r, 1-\varepsilon, 1+\varepsilon)A \right)\]直觉上可以理解成:
- 你可以改
- 但不能改太多
- 一旦超出安全区间,就不再继续鼓励这个方向的更新
所以 PPO 在家谱里的定位,不是“又一个全新 RL 目标”,而是:
给 Actor-Critic 风格的策略更新加了一个工程上非常好用的限速器。
如果想专门看 PPO 的目标函数、importance sampling 和 clip 的推导,可以继续看 PPO理论推导+代码实战。
用三层框架收一下
如果把 RL 再压缩,我会把它看成三层:
- 目标层:长期回报最大化
- 数学上是最大化 $J(\pi)=\mathbb{E}[G_t]$
- 评估层:当前状态或动作到底好不好
- 对应 $V(s)$、$Q(s,a)$、$A(s,a)$
- 更新层:如何用采样数据修正参数
- 对应 MC、TD、GAE、Policy Gradient、PPO clip
这个三层框架有一个好处:以后你看到任何 RL 算法,都可以先问它三件事:
- 它优化的目标是什么
- 它怎么估 value / advantage
- 它怎么更新 policy
最后一句话总结
所以我现在理解强化学习,不会再把它看成一堆并列算法,而是看成一条很清楚的演化主线:
- 先用 Bellman 方程把长期目标拆成递推结构
- 再用 MC / TD 解决“环境未知时怎么估 value”
- 再分成 value-based 和 policy-based 两条路线
- 再用 Actor-Critic 把价值估计和策略优化结合起来
- 再用 GAE 改善 Advantage 的估计
- 最后用 PPO 把策略更新控制在一个稳定范围内
强化学习最终的核心不是 reward,不是 PPO,甚至也不只是 policy,而是一个闭环:
\[\text{行动} \rightarrow \text{反馈} \rightarrow \text{价值评估} \rightarrow \text{策略更新}\]也就是:在与环境的交互中,通过反馈不断修正对未来的判断,逐渐逼近长期最优决策。
留下评论