学习Linux
简介
张彦飞:在对内核缺乏认识的时候,大家的优化方式一般都是“盲人摸象”式的,手段非常有限,做法很片面。当你理解了网络整体收发包过程以后,将会对网络在cpu、内存等方面的开销理解的深深刻,这会对你分析项目的性能瓶颈提供极大的帮助,为你的项目做性能优化提供充足的弹药。在看应用层各种新技术时,就犹如带了透视镜一般,直接看到骨骼。不深入底层看一看,永远都在隔靴搔痒,理解不了问题的本质。但不建议你一开始就陷入到源码里,大部分人都已经工作,没有大把的时间去啃,即使啃完了也无法跟手头的工作联系起来,我曾啃完了《深入理解linux网络技术内幕》,但连网络包如何从网卡到达应用程序都没搞明白。所以在阅读源码的时候,要时刻牢记要消灭的问题是什么,如果某段逻辑和你要解决的问题无关,那就直接绕过去,不要恋战。
艺术性
- 指令是稳定的,但指令序列是变化的,只有这样计算机才能够实现 “解决一切可以用 ‘计算’ 来解决的问题” 这个目标。计算是稳定的,但数据交换是多变的,只有这样才能够让计算机不必修改基础架构却可以适应不断发展变化的交互技术革命。
- 通过引入缺页中断,CPU 将自身与多变的外置存储设备,以及多变的文件系统格式进行了解耦。
- 中断机制,我们可以简单把它理解为 CPU 引入的回调函数。通过中断,CPU 把对计算机外设的演进能力交给了操作系统。
中断
内核是这样提供服务的:通过停止应用程序代码运行,进入内核地址空间运行内核代码,然后返回结果。
单机操作系统的系统调用需要「陷入」内核,所谓的陷入(trap)也叫做中断(interrupt),无论内核是什么类型,单机操作系统都需要在启动时将系统调用注册到内存中的一个区域里,这个区域叫做中断向量(Interrupt Vector)或中断描述符表(IDT,Interrupt Descriptor Table)。当然,现代操作系统的中断处理非常复杂,系统调用也很多,因此除了IDT之外,还需要一张系统调用表(SCV,System Call Vector),系统调用通过一个统一的中断入口(如 INT 80)调用某个中断处理程序,由这个中断处理程序通过 SCV 把系统调用分发给内核中不同的函数代码。因此 SCV 在操作系统中的位置和在星际争霸中的位置同样重要。对微内核架构来说,除了 SCV 中的系统调用之外,用户态服务提供什么样的系统能力,同样需要注册到某个区域。
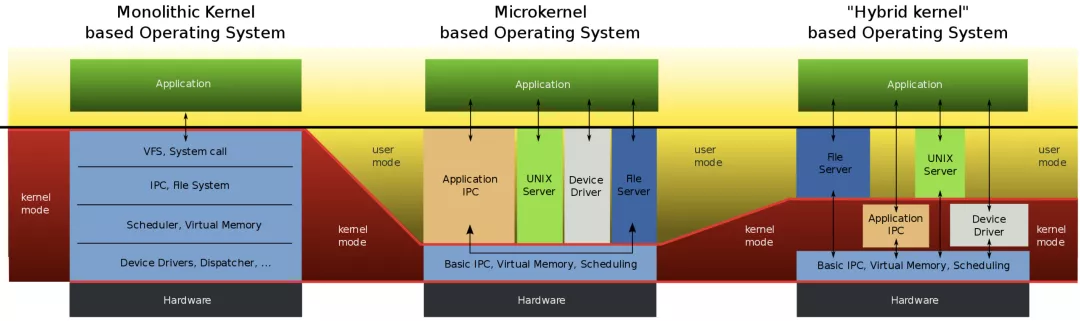
微内核 vs 宏内核
什么是微内核架构设计?微内核是这样一种内核:它只完成内核不得不完成的功能,包括时钟中断、进程创建与销毁、进程调度、进程间通信,而其他的诸如文件系统、内存管理、设备驱动等都被作为系统进程放到了用户态空间,一般是单独的用户态 daemon 进程。用户态应用程序通过 IPC 访问这些服务,从而访问操作系统的全部功能,如此一来,需要陷入内核的系统调用数量将大大减少,系统的模块化更加清晰。同时系统更加健壮,只有内核中的少量系统调用才有权限访问硬件的全部能力。说白了,微内核是相对于宏内核而言的,像Linux就是典型的宏内核,它除了时钟中断、进程创建与销毁、进程调度、进程间通信外,其他的文件系统、内存管理、输入输出、设备驱动管理都需要内核完成。
Kubernetes: 微内核的分布式操作系统微内核的概念虽然美好,但现实非常残酷:在 Linux 中,系统调用(比如 open)只要陷入内核一次,如果在一个微内核操作系统中,用户调用 open 就需要先拼装一条 IPC 请求消息,发送给对应的文件系统服务进程,随后从文件系统服务进程获取IPC响应消息并解包,拿到调用结果,这样一来,消息带来的数据拷贝和进程上下文切换都会带来很多开销。消息需要拷贝是因为用户态进程间不能相互访问内存地址,而内核的代码可以访问任何用户态进程的任何内存地址。在电脑性能不佳的情况下,因为乔布斯无法说服销售团队换一根更强的内存条,因此初代 Mac 的性能较差,未能获得应得的蓝海成功。
但是这里还有一个问题,那就是进程间通讯。你可能会问,这个有什么好疑问的,就是两个进程之间相互发消息呗。但是这里有一个最大的疑问,那就是进程间通讯是否有第三者介入?如下图:
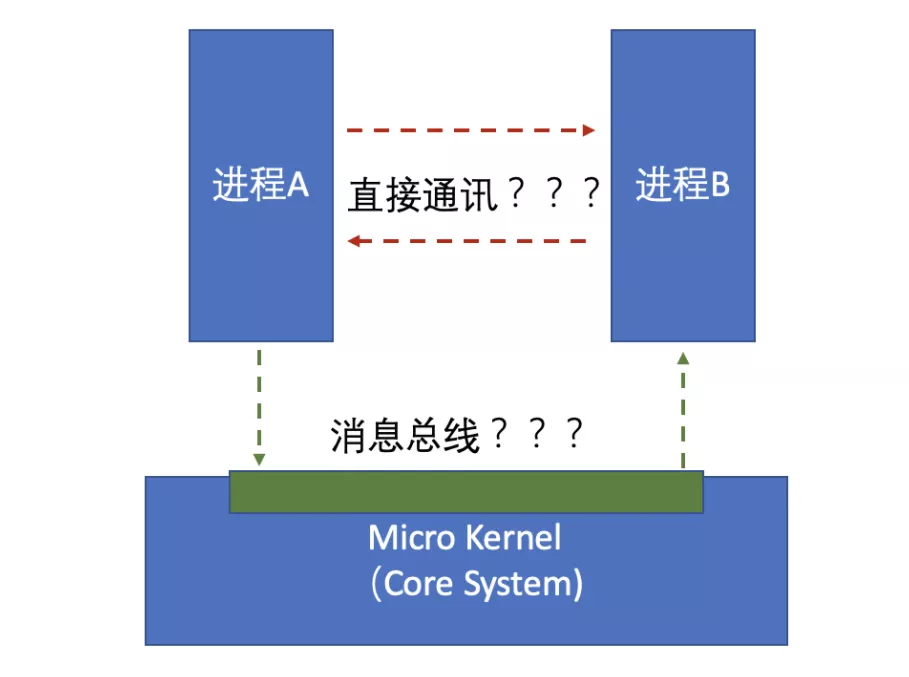
当然在操作系统的内核设计中,一定是通过内核进行转发的,就是我们理解的总线架构,内核负责协调各个进程间的通讯。这个大家也能理解,如果进程A直接发给另外一个进程B,必然要了解对应的内存地址,微内核中的服务是可以被随时替换的,如果服务不可用或者被替换,这个时候要通知和其通讯的其他进程,是不是太复杂?刚才已经提到,只有send和receive接口,没有其他通知下线、服务不可用的接口。在微内核的设计中,一定是通过总线结构,进程向Kernel发送消息,然后kernel再发送给对应的进程,这样的一个总线设计。实际上很多应用内部在做Plug-in组件解耦时,都会使用EventBus的结构,其实就是总线的设计机制。
bios ==> grub ==> linux
CPU 被设计成只能运行内存中的程序,没有办法直接运行储存在硬盘或者 U 盘中的操作系统程序。如果想要运行硬盘或者 U 盘中的程序,就必须要先加载到内存(RAM)中才能运行。这是因为硬盘、U 盘(外部储存器)并不和 CPU 直接相连,它们的访问机制和寻址方式与内存截然不同。内存在断电后就没法保存数据了,那 BIOS 又是如何启动的呢?硬件工程师设计 CPU 时,硬性地规定在加电的瞬间,强制将 CS 寄存器的值设置为 0XF000,IP 寄存器的值设置为 0XFFF0。这样一来,CS:IP 就指向了 0XFFFF0 这个物理地址。在这个物理地址上连接了主板上的一块小的 ROM 芯片。ROM芯片的访问机制和寻址方式和内存一样,只是它在断电时不会丢失数据,在常规下也不能往这里写入数据,它是一种只读内存,BIOS 程序就被固化在该 ROM 芯片里。现在,CS:IP 指向了 0XFFFF0 这个位置,正是 BIOS 程序的入口地址。这意味着 BIOS 正式开始启动。
BIOS 一开始会初始化 CPU,接着检查并初始化内存,然后将自己的一部分复制到内存,最后跳转到内存中运行。BIOS 的下一步就是枚举本地设备进行初始化,并进行相关的检查,检查硬件是否损坏,这期间 BIOS 会调用其它设备上的固件程序,如显卡、网卡等设备上的固件程序。当设备初始化和检查步骤完成之后,BIOS 会在内存中建立中断表和中断服务程序,这是启动 Linux 至关重要的工作,因为 Linux 会用到它们。为了启动外部储存器中的程序,BIOS 会搜索可引导的设备,搜索的顺序是由 CMOS 中的设置信息决定的(这也是我们平时讲的,所谓的在 BIOS 中设置的启动设备顺序)。一个是软驱,一个是光驱,一个是硬盘上,还可以是网络上的设备甚至是一个 usb 接口的 U 盘,都可以作为一个启动设备。当然,Linux 通常是从硬盘中启动的。硬盘上的第 1 个扇区(每个扇区 512 字节空间),被称为 MBR(主启动记录),其中包含有基本的 GRUB 启动程序和分区表,安装 GRUB 时会自动写入到这个扇区,当 MBR 被 BIOS 装载到 0x7c00 地址开始的内存空间中后,BIOS 就会将控制权转交给了 MBR。在当前的情况下,其实是交给了 GRUB。
BIOS 只会加载硬盘上的第 1 个扇区。不过这个扇区仅有 512 字节,这 512 字节中还有 64 字节的分区表加 2 字节的启动标志,很显然,剩下 446 字节的空间,是装不下 GRUB 这种大型通用引导器的。于是,GRUB 的加载分成了多个步骤,同时 GRUB 也分成了多个文件,其中有两个重要的文件 boot.img 和 core.img。其中,boot.img 被 GRUB 的安装程序写入到硬盘的 MBR 中,同时在 boot.img 文件中的一个位置写入 core.img 文件占用的第一个扇区的扇区号。如果是从硬盘启动的话,core.img 中的第一个扇区的内容就是 diskboot.img 文件。diskboot.img 文件的作用是,读取 core.img 中剩余的部分到内存中。core.img 文件中嵌入了足够多的功能模块,所以可以保证 GRUB 识别出硬盘分区上文件系统(访问磁盘不需要再依靠BIOS的中断以扇区为单位读取了),能够访问 /boot/grub 目录,并且可以加载相关的配置文件和功能模块,来实现相关的功能,例如加载启动菜单、加载目标操作系统等。Linux内核的相关文件位于/boot 目录下,文件名均带有前缀 vmlinuz。
引导协议:引导程序加载内核,前提是确定好数据交换方式,叫做引导协议,内核中引导协议相关部分的代码在arch/x86/boot/header.S中,内核会在这个文件中标明自己的对齐要求、是否可以重定位以及希望的加载地址等信息。同时也会预留空位,由引导加载程序在加载内核时填充,比如initramfs的加载位置和大小等信息。引导加载程序和内核均为此定义了一个结构体linux_kernel_params,称为引导参数,用于参数设定。Grub会在把控制权移交给内核之前,填充好linux_kernel_params结构体。
用户选择对应的菜单后,Grub会开始执行对应命令,定位、加载、初始化内核,并移交到内核继续执行。
- GRUB 加载 vmlinuz 文件之后,会把控制权交给 vmlinuz 文件的 setup.bin 的部分中 _start,它会设置好栈,清空 bss,设置好 setup_header 结构,调用 16 位 main 切换到保护模式,最后跳转到 1MB 处的 vmlinux.bin 文件中。
- 从 vmlinux.bin 文件中 startup32、startup64 函数开始建立新的全局段描述符表和 MMU 页表,切换到长模式下解压 vmlinux.bin.gz。释放出 vmlinux 文件之后,由解析 elf 格式的函数进行解析,释放 vmlinux 中的代码段和数据段到指定的内存。然后调用其中的 startup_64 函数,在这个函数的最后调用 Linux 内核的第一个 C 函数x86_64_start_kernel。
- Linux 内核第一个 C 函数重新设置 MMU 页表,随后便调用了最有名的 start_kernel 函数, start_kernel 函数中调用了大多数 Linux 内核功能性初始化函数(硬件层、内核层、接口层),在最后调用 rest_init 函数建立了两个内核线程,在其中的 kernel_init 线程建立了第一个用户态进程。
void start_kernel(void){
char *command_line;
char *after_dashes;
//CPU组早期初始化
cgroup_init_early();
//关中断
local_irq_disable();
//ARCH层初始化
setup_arch(&command_line);
//日志初始化
setup_log_buf(0);
sort_main_extable();
//陷阱门初始化
trap_init();
//内存初始化
mm_init();
ftrace_init();
//调度器初始化
sched_init();
//工作队列初始化
workqueue_init_early();
//RCU锁初始化
rcu_init();
//IRQ 中断请求初始化
early_irq_init();
init_IRQ();
tick_init();
rcu_init_nohz();
//定时器初始化
init_timers();
hrtimers_init();
//软中断初始化
softirq_init();
timekeeping_init();
mem_encrypt_init();
//每个cpu页面集初始化
setup_per_cpu_pageset();
//fork初始化建立进程的
fork_init();
proc_caches_init();
uts_ns_init();
//内核缓冲区初始化
buffer_init();
key_init();
//安全相关的初始化
security_init();
//VFS数据结构内存池初始化
vfs_caches_init();
//页缓存初始化
pagecache_init();
//进程信号初始化
signals_init();
//运行第一个进程
arch_call_rest_init();
}
要实现一个功能模块,首先要设计出相应的数据结构(以及这些数据结构的管理数据结构,比如链表等),基于数据结构设计初始化函数以及该功能模块对应的业务函数。
任何软件工程,第一个函数总是简单的,因为它是总调用者,像是一个管理者,坐在那里发号施令,自己却是啥活也不干。
留下评论