jib源码分析之细节
简介
阅读本文前,建议事先了解下 jib源码分析及应用
几个问题
通过docker registry v2 api,是可以上传镜像的
- jib 的最后,是不是也是调用 docker registry v2 api? 比如对于golang语言 就有针对 registry api 的库 github.com/heroku/docker-registry-client
- jib maven plugin 与 jib-core 分工的边界在哪里? 直接的代码调用,使用jib-core 即可
- 如何将不同的数据分layer
- jib源码分析及应用 的分析只涉及到 jib 有限的几个package,还有大量package 分别是什么作用?
- Allocation 看着很复杂,是什么意思?
- TimerEventDispatcher 为什么有这个?
- guava Futures 的深意要好好理解
EventDispatcher
在com.google.cloud.tools.jib.event包下 有几个类
- DefaultEventDispatcher
- EventDispatcher
- EventHandlers
- Handler
- JibEvent
- JibEventType
- events 定义了几个特定的JibEvent,比如LogEvent、ProgressEvent、TimerEvent
详情如下
public interface EventDispatcher {
void dispatch(JibEvent jibEvent);
}
public interface JibEvent {}
class Handler<E extends JibEvent> {
private final Class<E> eventClass;
// java8 java.util.function. Consumer
private final Consumer<E> eventConsumer;
Handler(Class<E> eventClass, Consumer<E> eventConsumer) {
this.eventClass = eventClass;
this.eventConsumer = eventConsumer;
}
void handle(JibEvent jibEvent) {
Preconditions.checkArgument(eventClass.isInstance(jibEvent));
// Class.cast 强转的简便用法
eventConsumer.accept(eventClass.cast(jibEvent));
}
}
// Handler工具类
public class EventHandlers {...}
public class DefaultEventDispatcher implements EventDispatcher {
private final ImmutableMultimap<Class<? extends JibEvent>, Handler<? extends JibEvent>> handlers;
public DefaultEventDispatcher(EventHandlers eventHandlers) {
handlers = eventHandlers.getHandlers();
}
@Override
public void dispatch(JibEvent jibEvent) {
handlers.get(JibEvent.class).forEach(handler -> handler.handle(jibEvent));
handlers.get(jibEvent.getClass()).forEach(handler -> handler.handle(jibEvent));
}
}
设置EventHandler 的方式
containerizer
.getEventHandlers()
.ifPresent(
eventHandlers ->
buildConfigurationBuilder.setEventDispatcher(
new DefaultEventDispatcher(eventHandlers)));
- 定义一套event 生产与消费 的接口约定
- 框架流程持有EventDispatcher 在恰当的时机发布event。所以对于jib来说,只关心EventDispatcher 和 event。EventDispatcher 之所以带 Dispatcher 是因为其会根据event 类型分发
- 传统的观察者模式,Subject 会直接持有 Observer列表,而在jib 中,EventDispatcher ==> Handler ==> Consumer 三角关系。为何呀?一个重要因素是JibEvent 定义了不同的事件类型,如果还是 Subject-Observer 二元关系。则Subject 要么定义不同的方法,用来分发不同的事件;要么一个分发方法中实现if else,Observer 作为事件接收方法类似。
- 真正的 event 源 聚合了EventDispatcher 而不是 实现它。
- 但万变不离其宗,从
new DefaultEventDispatcher(eventHandlers)看, 还是通过 “Observer” 去构造“Subject”
Allocation
在com.google.cloud.tools.jib.event.progress包下
创建
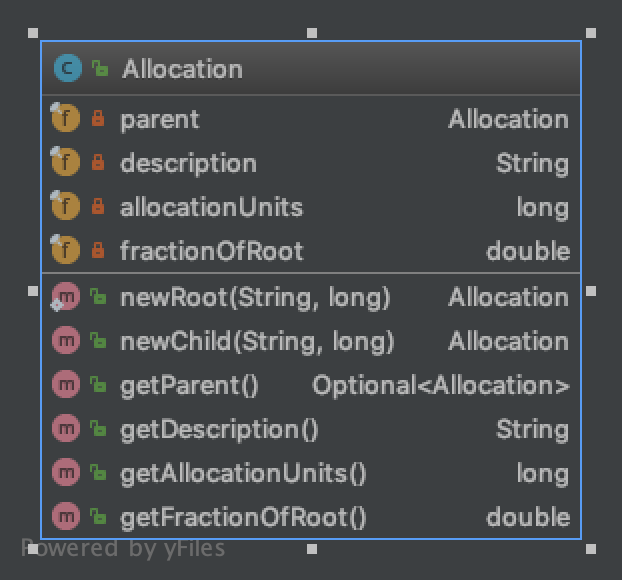
Allocation 有两个创建入口:newRoot 和 newChild。newChild 分散在各个 Step 中被调用。
newRoot 的创建入口在 StepsRunner 中
private void createRootProgressAllocation(String description) {
rootProgressAllocation = Allocation.newRoot(description, stepsCount);
buildConfiguration.getEventDispatcher().dispatch(new ProgressEvent(rootProgressAllocation, 0L));
}
并且createRootProgressAllocation只在 以下三个方法中使用,它们分别是 forBuildToDockerRegistry、forBuildToDockerDaemon、forBuildToTar 的finalStep
- StepsRunner.pushImage
- StepsRunner.loadDocker
- StepsRunner.writeTarFile
在将finalStep 时创建rootProgressAllocation,然后从第一个Step 开始 真正执行 流程。Step真正开始运行时(执行子Step的构造方法)会检查 是否有rootProgressAllocation
基本概念
- Decentralized Allocation Tree (DAT)
- Allocation,A DAT node is immutable and pointers only go in the direction from child to parent. java 里面表示一个tree、链表、队列 都只 表示一个Node 就行了。
- allocation unit,从
StepsRunner.createRootProgressAllocation可以看到,rootProgressAllocation 的allocation unit 为step 的数量。而非finalStep 的allocation 的 allocation unit 都为1(不准确)。 - fractionOfRoot
加上非finalStep代码中 频频出现 progressAllocation ,可以做一个大胆假设:allocation 是用来跟踪进度的。
如果看过jib源码分析及应用 中的Step 依赖关系图,并可以知道,感知一个并行的任务的进度是非常困难的。因为对Decentralized Allocation Tree 了解不多,本文不做过多涉及。
通过学习jib 对 java future 有了一些新的体会,参见future
与docker registry 的交互
com.google.cloud.tools.jib
blob
image
json
registry
RegistryClient
BlobPuller
BlobPusher
ManifestPuller
ManifestPusher
RegistryEndpointCaller
RegistryEndpointProvider
RegistryClient 大体上可以作为 与Registry 交互的入口,然后将请求具体分发给BlobPuller/ManifestPuller 等,blob、image、json 等包则提供 对请求及响应对象的封装。
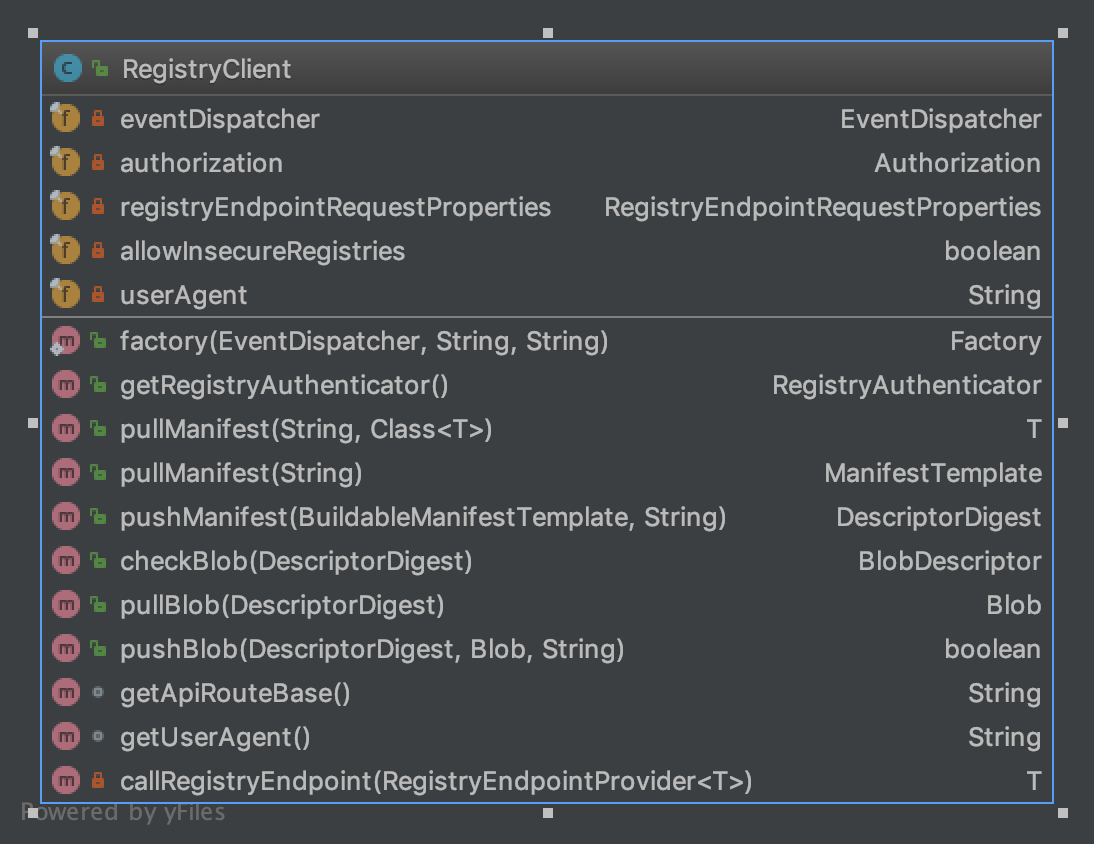
RegistryClient/BlobPuller 提供高层语义抽象,实际干活的是RegistryEndpointCaller 和 RegistryEndpointProvider。RegistryEndpointCaller 控制整体流程,RegistryEndpointProvider 及其子类控制流程中 个性化的部分,类似于模板模式,但采用了聚合的方式。这是封装http 请求的经典方式
class RegistryEndpointCaller<T> {
RegistryEndpointCaller(
...
RegistryEndpointProvider<T> registryEndpointProvider,
Authorization authorization,
RegistryEndpointRequestProperties registryEndpointRequestProperties,
boolean allowInsecureRegistries){
...
}
private T call(URL url, Function<URL, Connection> connectionFactory){
try (Connection connection = connectionFactory.apply(url)) {
Request.Builder requestBuilder = Request.builder().setXX...
if (sendCredentials) {
requestBuilder.setAuthorization(authorization);
}
Response response = connection.send(registryEndpointProvider.getHttpMethod(), requestBuilder.build());
return registryEndpointProvider.handleResponse(response);
}
}
RegistryEndpointProvider 接口定义
interface RegistryEndpointProvider<T> {
String getHttpMethod();
URL getApiRoute(String apiRouteBase) throws MalformedURLException;
BlobHttpContent getContent();
List<String> getAccept();
T handleResponse(Response response) throws IOException, RegistryException;
default T handleHttpResponseException(HttpResponseException httpResponseException)
throws HttpResponseException, RegistryErrorException {
throw httpResponseException;
}
String getActionDescription();
}
其子类包括,基本囊括了与registry 交互的所有过程
- AuthenticationMethodRetriever
- BlobChecker
- BlobPuller
- BlobPusher
- ManifestPuller
- ManifestPusher
jsonTemplate 继承图
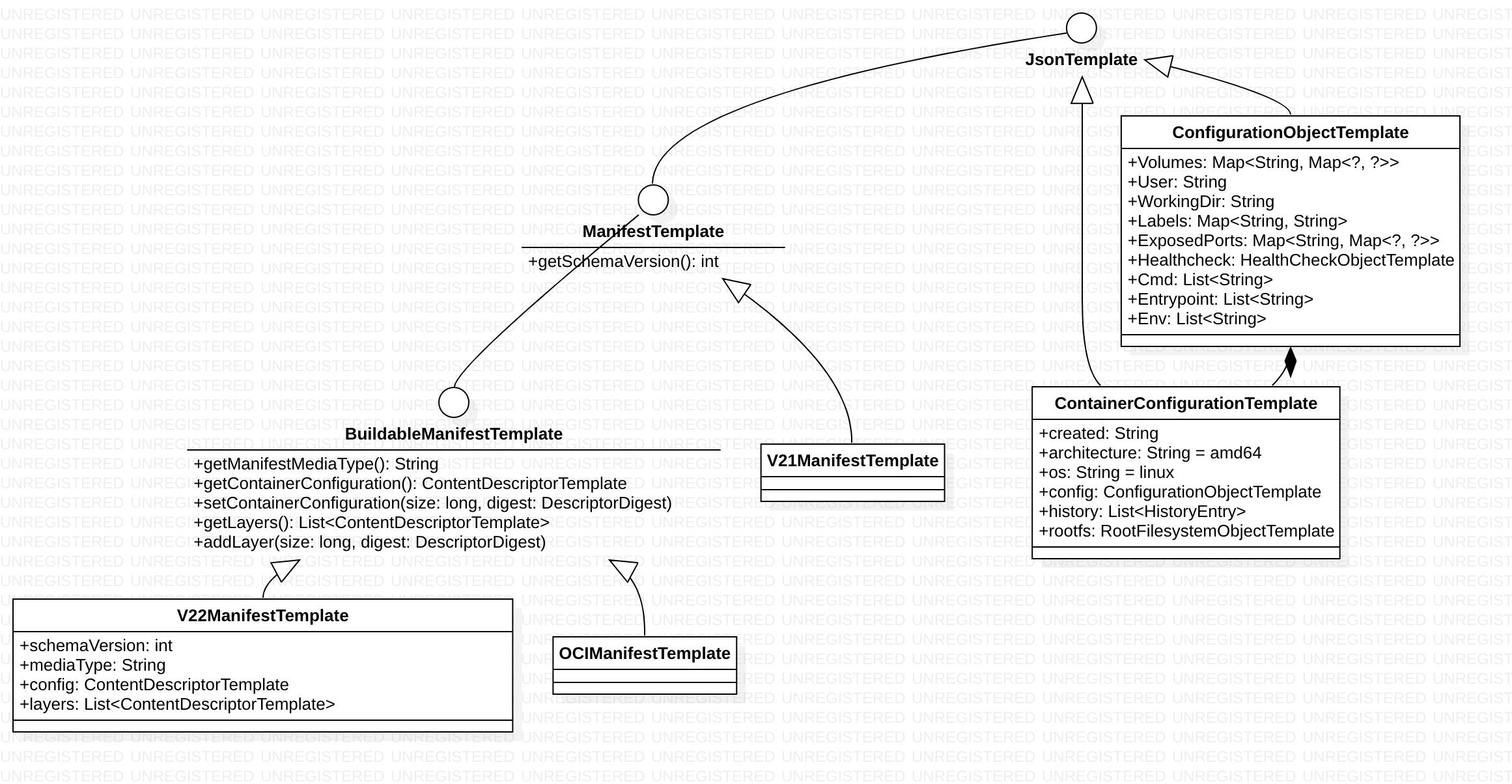
估计是受 json 序列化框架的影响,就像JsonTemplate 的注释:All JSON templates to be used with JsonTemplateMapper must extend this class. 其实就是dokcer distribution http 交互都是 json 字符串,所以弄些对应的对象,在web开发中经常被称为XXDTO,一些通用元素会搞一个BaseDTO 之类的公共类。
Image 数据在客户端的保存
先留一个问题:若是给镜像加Label,会不会影响镜像/layer 的digest?
对象表示
这块内容主要在 com.google.cloud.tools.jib.image中,重点包括以下对象
- Image
- Layer
- Blob
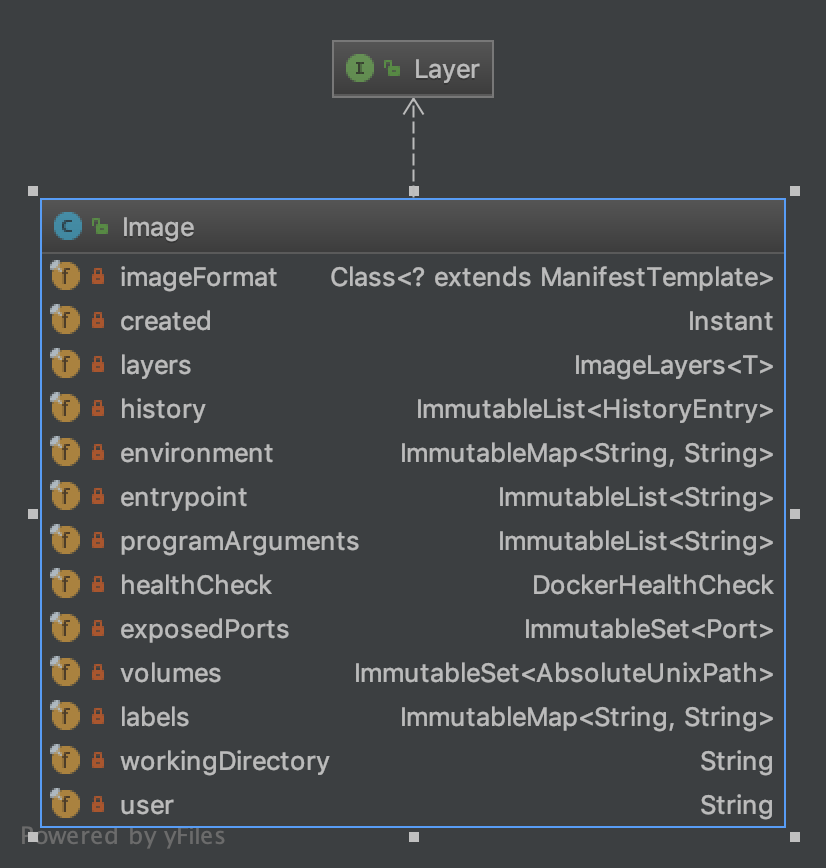
Image是一个数据类,包括字段及对应的Getter方法,setter工作由其内部类Builder 完成。
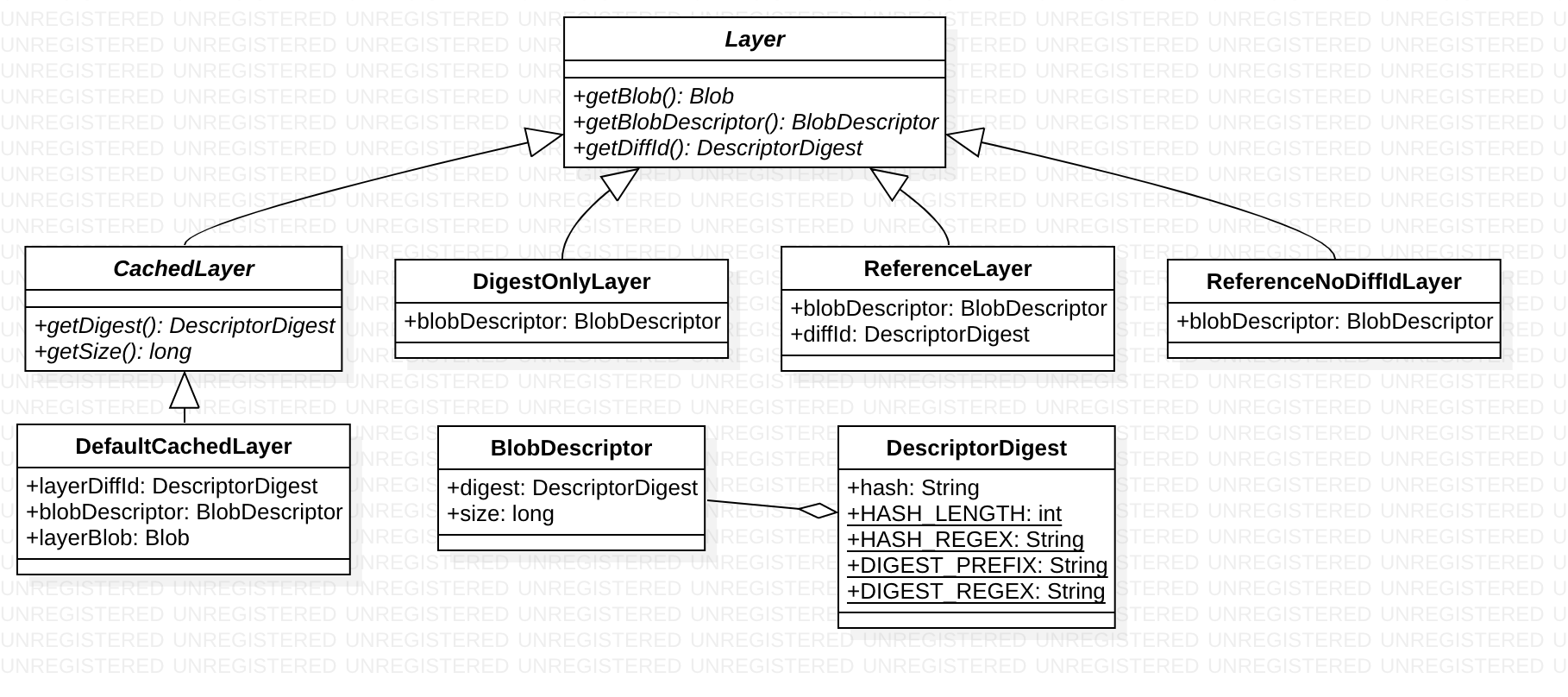
An image layer 主要包括Blob 及其元数据信息
- Content BLOB, The compressed archive (tarball gzip) of the partial filesystem changeset
- Content Digest, The SHA-256 hash of the content BLOB.
- The SHA-256 hash of the uncompressed archive (tarball) of the partial filesystem changeset.
- Content Size, The size (in bytes) of the content BLOB.
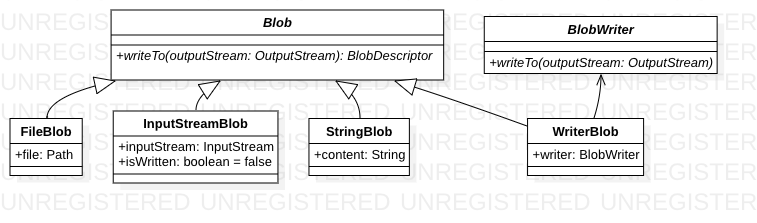
本地镜像缓存
在com.google.cloud.tools.jib.cache 包下

Cache 名为缓存,实际可以看做是 对象存储与检索,将对象数据最终存到磁盘上。
缓存的目录位置参见 com.google.cloud.tools.jib.filesystem.UserCacheHome,不同OS 位置不同。$CACHE_HOME/google-cloud-tools-java/jib 主要内容如下
- layers digest 文件,内容为digest
- tmp
- metadata-v2.json
- 各种xxx.tar.gz

从上图可以看到Blob 状态的演变 Blob ==> WrittenLayer ==> Cachedlayer
Content-Type: application/octet-stream流 ,先写在$CACHE_HOME/google-cloud-tools-java/jib/tmp/.tmp.layer文件中,在接收文件的同时计算文件的Content Digest(SHA-256) 得到DescriptorDigest,配合文件长度totalBytes 得到BlobDescriptor。- 解压文件,对解压后的文件 计算Content Digest(SHA-256) 得到diffId。然后将
$CACHE_HOME/google-cloud-tools-java/jib/tmp/.tmp.layer改名为$CACHE_HOME/google-cloud-tools-java/jib/tmp/$diffId - 将
$CACHE_HOME/google-cloud-tools-java/jib/tmp/$diffId改名为$CACHE_HOME/google-cloud-tools-java/jib/layers/$digest/$diffId - 基于
$CACHE_HOME/google-cloud-tools-java/jib/layers/$digest/$diffId文件构建FileBlob,进而构建Cachedlayer
对于UncompressedLayer 文件,写入完毕后还会再加一个操作 write selector
- 创建一个
$CACHE_HOME/google-cloud-tools-java/jib/selectors/$diffId - 创建一个临时文件,写入内容
$digest - 将临时文件mv 为
$CACHE_HOME/google-cloud-tools-java/jib/selectors/$diffId
临时文件的意图是 atomic move。selector file的意图是 建立$diffId 到 $digest 的关联关系,这样就不用每次将UncompressedLayer 再压缩一遍后计算$digest。
jib本地镜像缓存与docker 本地镜像缓存的对比
- registry storage(也就是registry daemon/container) 磁盘上存储layer 的方式
- registry storage 也 docker local storage的对比
- 可以看到,单就layer存储来说,jib 本地与 registry 采用的方式是一致的
container configuration blob
参见 关于docker image的那点事儿 以及 Image Manifest Version 2, Schema 1
个人微信订阅号

留下评论