golang 系统调用与阻塞处理
前言
Please remember that at the end of the day, all programs that work on UNIX machines end up using C system calls to communicate with the UNIX kernel and perform most of their tasks. 所有在 UNIX 系统上运行的程序最终都会通过 C 系统调用来和内核打交道。用其他语言编写程序进行系统调用,方法不外乎两个:一是自己封装,二是依赖 glibc、或者其他的运行库。Go 语言选择了前者,把系统调用都封装到了 syscall 包。封装时也同样得通过汇编实现。
当M一旦进入系统调用后,会脱离go runtime的控制。试想万一系统调用阻塞了呢,此时又无法进行抢占,是不是整个M也就罢工了。所以为了维持整个调度体系的高效运转,必然要在进入系统调用之前要做点什么以防患未然。
- 异步系统调用 G 会和MP分离(G挂到netpoller)
- 同步系统调用 MG 会和P分离(P另寻M)。在执行期间会导致整个 m 暂时不可用,将发起 syscall 的 g 和 m 绑定,但是解除 p 与 m 的绑定关系,使得此期间 p 存在和其他 m 结合的机会。
生动的说明了GPM相对GM的精妙之处。
阻塞
在 Go 里面阻塞主要分为以下 4 种场景:
- 由于原子、互斥量或通道操作调用导致 Goroutine 阻塞,调度器将把当前阻塞的 Goroutine 切换出去,重新调度 LRQ 上的其他 Goroutine;
- 由于网络请求和 IO 操作导致 Goroutine 阻塞。Go 程序提供了网络轮询器(NetPoller)来处理网络请求和 IO 操作的问题,其后台通过 kqueue(MacOS),epoll(Linux)或 iocp(Windows)来实现 IO 多路复用。通过使用 NetPoller 进行网络系统调用,调度器可以防止 Goroutine 在进行这些系统调用时阻塞 M。这可以让 M 执行 P 的 LRQ 中其他的 Goroutines,而不需要创建新的 M。执行网络系统调用不需要额外的 M,网络轮询器使用系统线程,它时刻处理一个有效的事件循环,有助于减少操作系统上的调度负载。用户层眼中看到的 Goroutine 中的“block socket”,实现了 goroutine-per-connection 简单的网络编程模式。实际上是通过 Go runtime 中的 netpoller 通过 Non-block socket + I/O 多路复用机制“模拟”出来的。
- 当调用一些系统方法的时候(如文件 I/O),如果系统方法调用的时候发生阻塞,这种情况下,网络轮询器(NetPoller)无法使用,而进行系统调用的 G1 将阻塞当前 M1。调度器引入 其它M 来服务 M1 的P。
- 如果在 Goroutine 去执行一个 sleep 操作,导致 M 被阻塞了。Go 程序后台有一个监控线程 sysmon,它监控那些长时间运行的 G 任务然后设置可以强占的标识符,别的 Goroutine 就可以抢先进来执行。
Go 适合 IO 密集型?并不准确!Go 适合 IO 密集型的场景。但其实这里并不准确。更准确的是 Go 适合的是网络 IO 密集型的场景,而非磁盘 IO 密集型。甚至可以说,Go 对于磁盘 IO 密集型并不友好。根本原因:在于网络 socket 句柄和文件句柄的不同。网络 IO 能够用异步化的事件驱动的方式来管理,磁盘 IO 则不行。
- socket 句柄可读可写事件都有意义,socket buffer 里有数据,说明对端网络发数据过来了,即满足可读事件。有 buffer 可以写,那么说明还能发送数据,满足可写事件。所以 socket 的句柄实现了 .poll 方法,可以用 epoll 池来管理。socket 句柄可以设置为 noblocking (非阻塞的方式),这样当网络 IO 还未就绪的时候(比如read 一下没有数据)就可以在 Go 代码里把调度权切走,去执行其他协程,这样就实现了网络 IO 的并发。
- 文件句柄可读可写事件则没有意义,因为文件句柄理论上是永远都是可读可写的,文件 IO 的 read/write 都是同步的 IO(比如read 一下,没数据直接就卡住了) ,没有实现 .poll 所以也用不了 epoll 池来监控读写事件。所以磁盘 IO 的完成只能同步等待。然而磁盘 IO 的等待则会带来 Go 最不能容忍的事情:卡线程。
Go 的代码执行者是系统线程,也就是 G-M-P 模型的 M ,M 不断的从队列 P 中取 G(协程任务)出来执行。当 G 出现等待事件的时候(比如网络 IO),那么立马切走,取下一个执行。这样让 M 一直不停的满载,就能保证 Go 协程任务的高吞吐。那么问题来了,如果某个 G 卡线程了,就相当于这个 M 被废了,吞吐能力就下降。如果 M 全卡住了那相当于整个程序卡死了。然而对于类似系统调用这种卡线程却是无法人为控制的。Go runtime 为了解决这个问题,就只能创建更多的线程来保证一直有可运行的 M 。所以,你经常会发现,当系统调用很慢的时候,M 的数量会变多,甚至会暴涨。下面来看一下 Go 怎么处理这种系统调用的?
系统调用
Go 语言通过 Syscall 和 Rawsyscall 等使用汇编语言编写的方法封装了操作系统提供的所有系统调用,其中 Syscall 在 Linux 386 上的实现如下:
TEXT ·Syscall(SB),NOSPLIT,$0-28
CALL runtime·entersyscall(SB)
MOVL trap+0(FP), AX // syscall entry
MOVL a1+4(FP), BX
MOVL a2+8(FP), CX
MOVL a3+12(FP), DX
MOVL $0, SI
MOVL $0, DI
INVOKE_SYSCALL
CMPL AX, $0xfffff001
JLS ok
MOVL $-1, r1+16(FP)
MOVL $0, r2+20(FP)
NEGL AX
MOVL AX, err+24(FP)
CALL runtime·exitsyscall(SB)
RET
ok:
MOVL AX, r1+16(FP)
MOVL DX, r2+20(FP)
MOVL $0, err+24(FP)
CALL runtime·exitsyscall(SB)
RET
Go: Goroutine, OS Thread and CPU Management Go optimizes the system calls — whatever it is blocking or not — by wrapping them up in the runtime. This wrapper will automatically dissociate the P from the thread M and allow another thread to run on it.
系统调用的逻辑是属于 Go 程序外部代码,Go 用 entersyscall 和 exitsyscall 来包装一下,主要是和调度交互。
- entersyscall 的作用:把当前 M 的 P 设置为 _Psyscall 状态,打上标识 解绑 P -> M 的绑定,但 M 还保留 P 的指针。
- existsyscall 的作用:由于 M 到 P 的指向还在,那么优先还是用原来的 P。 如果原来的 P 被处理掉了,那么就去用一个新的 P ,如果还没有,那就只能把G 挂到全局队列了。 Go 的 sysmon(内部监控线程)发现有这种卡了超过 10 ms 的 M ,那么就会把 P 剥离出来,给到其他的 M 去处理执行,M 数量不够就会新创建。
异步系统调用
通过使用网络轮询器进行网络系统调用,调度器可以防止 Goroutine 在进行这些系统调用时阻塞M。这可以让M执行P的 LRQ 中其他的 Goroutines,而不需要创建新的M。有助于减少操作系统上的调度负载。
G1正在M上执行,还有 3 个 Goroutine 在 LRQ 上等待执行
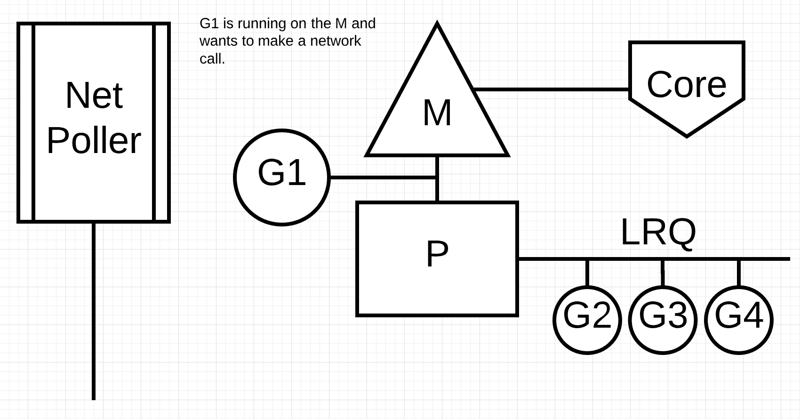
接下来,G1想要进行网络系统调用,因此它被移动到网络轮询器并且处理异步网络系统调用。然后,M可以从 LRQ 执行另外的 Goroutine。
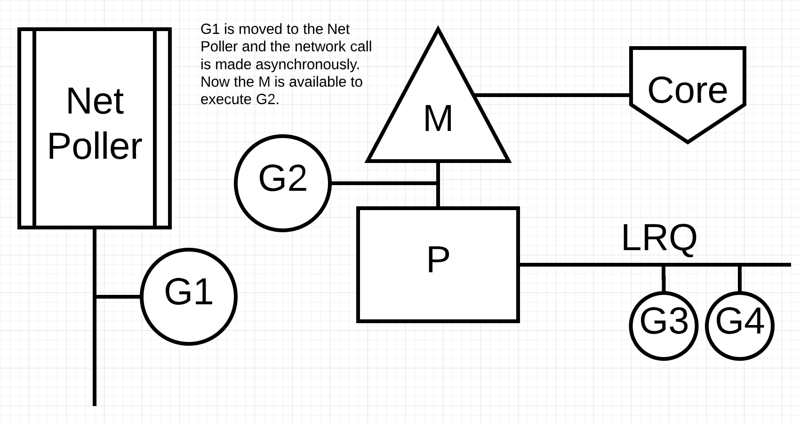
最后:异步网络系统调用由网络轮询器完成,G1被移回到P的 LRQ 中。一旦G1可以在M上进行上下文切换,它负责的 Go 相关代码就可以再次执行。
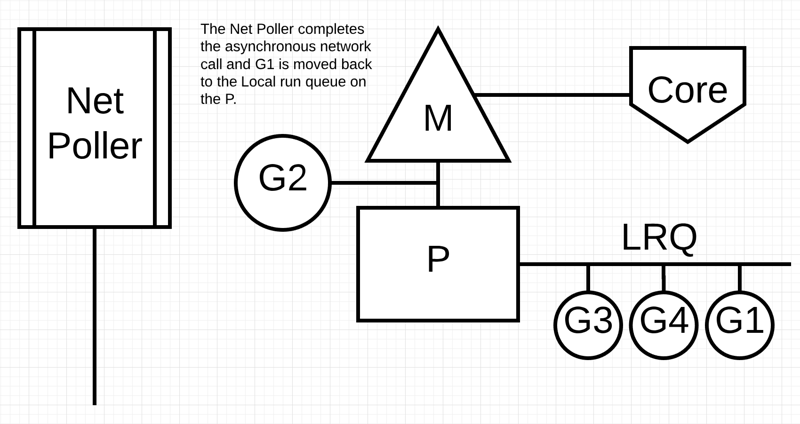
梳理:如果 G 被阻塞在某个 channel 操作或网络 I/O 操作上时,G 会被放置到某个等待(wait)队列中,而 M 会尝试运行 P 的下一个可运行的 G。如果这个时候 P 没有可运行的 G 供 M 运行,那么 M 将解绑 P,并进入挂起状态。当 I/O 操作完成或 channel 操作完成,在等待队列中的 G 会被唤醒,标记为可运行(runnable),并被放入到某 P 的队列中,绑定一个 M 后继续执行。
同步系统调用
G1将进行同步系统调用以阻塞M1
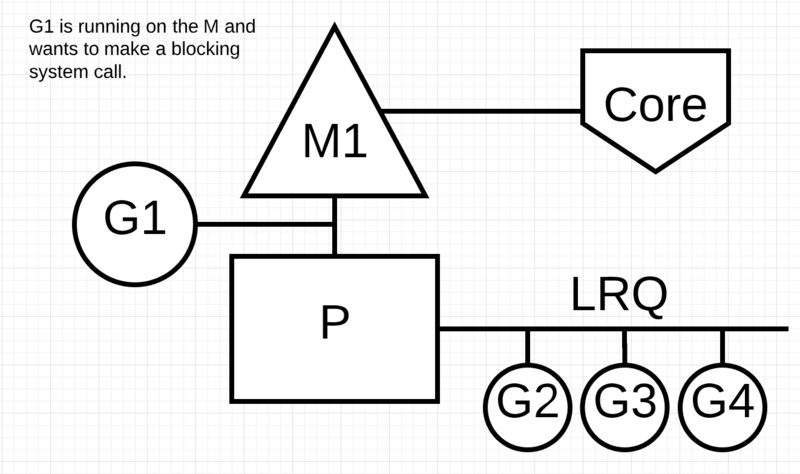
调度器介入后:识别出G1已导致M1阻塞,此时,调度器将M1与P分离(正因为M 和P 可能分离,所以mcache 挂在P上),同时也将G1带走。然后调度器引入新的M2来服务P。PS:将 p 设置为 m.oldp,保留 p 与 m 之间的弱联系(使得 m syscall 结束后,还有一次尝试复用 p 的机会)
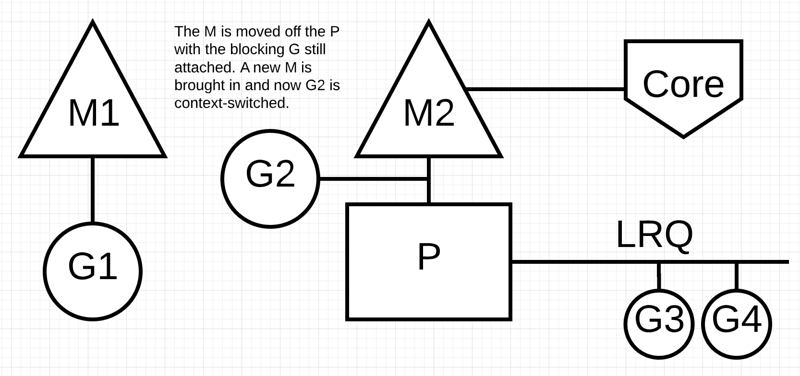
阻塞的系统调用完成后:G1可以移回 LRQ 并再次由P执行。如果这种情况需要再次发生,M1将被放在旁边以备将来使用。
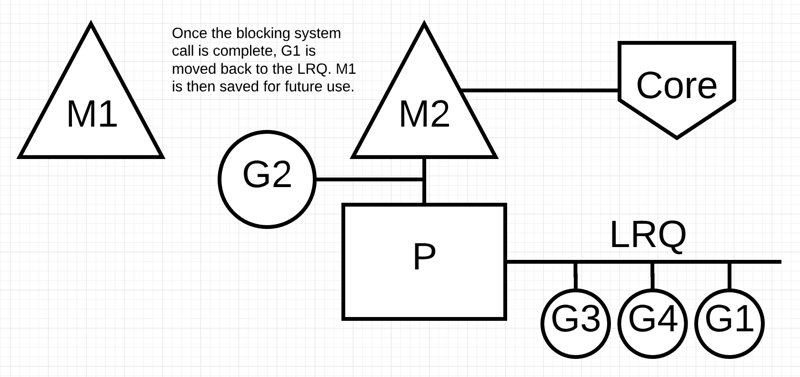
梳理:如果 G 被阻塞在某个系统调用(system call)上,那么不光 G 会阻塞,执行这个 G 的 M 也会解绑 P,与 G 一起进入挂起状态。如果此时有空闲的 M,那么 P 就会和它绑定,并继续执行其他 G;如果没有空闲的 M,但仍然有其他 G 要去执行,那么 Go 运行时就会创建一个新 M(线程)。当系统调用返回后,阻塞在这个系统调用上的 G 会尝试获取一个可用的 P,如果没有可用的 P,那么 G 会被标记为 runnable(添加到 grq ),之前的那个挂起的 M 将再次进入挂起状态。
sysmon 协程
Go 程序启动时,运行时会去启动一个名为 sysmon 的 M(一般称为监控线程),这个 M 的特殊之处在于它不需要绑定 P 就可以运行(以 g0 这个 G 的形式)。
// $GOROOT/src/runtime/proc.go
// The main goroutine.
func main() {
... ...
systemstack(func() {
newm(sysmon, nil)
})
.... ...
}
// Always runs without a P, so write barriers are not allowed.
// go:nowritebarrierrec
func sysmon() {
// If a heap span goes unused for 5 minutes after a garbage collection,
// we hand it back to the operating system.
scavengelimit := int64(5 * 60 * 1e9)
... ...
if .... {
... ...
// retake P's blocked in syscalls and preempt long running G's
if retake(now) != 0 {
idle = 0
} else {
idle++
}
... ...
}
}
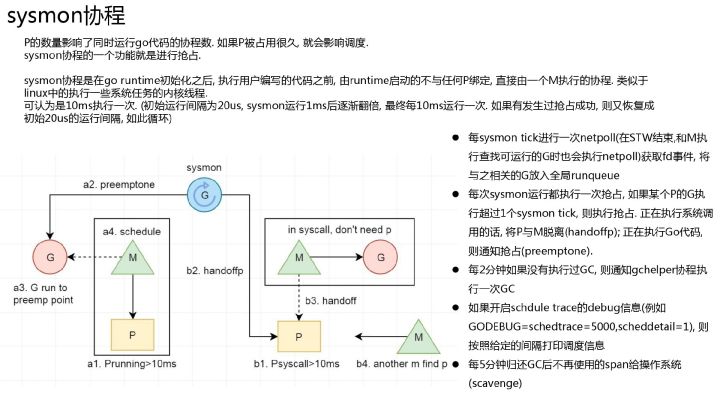
在 linux 内核中有一些执行定时任务的线程, 比如定时写回脏页的 pdflush, 定期回收内存的 kswapd0, 以及每个 cpu 上都有一个负责负载均衡的 migration 线程等.在 go 运行时中也有类似的协程 sysmon. sysmon 运行在 M,且不需要 P。它会每隔一段时间检查 Go 语言runtime,确保程序没有进入异常状态。
sysmon 每 20us~10ms 启动一次,功能比较多:
- 检查死锁runtime.checkdead
- 运行计时器 — 获取下一个需要被触发的计时器;
- 将长时间未处理的 netpoll 结果添加到任务队列;
- 向长时间运行的 G 任务发出抢占调度(retake 方法);
- 打印调度信息,归还内存等定时任务.
- 释放闲置超过 5 分钟的 span 内存;如果超过 2 分钟没有垃圾回收,强制执行;
- 收回因 syscall 长时间阻塞的 P;
留下评论