tensornet源码分析
- 简介
- Wide&Deep模型Demo
- 源码结构
- PsStrategy 相对 MultiWorkerMirroredStrategy 做了什么
- tn.feature_column.category_column相比tensorflow自带的 有何不同(未完成)
- tn.layers.EmbeddingFeatures的核心实现逻辑
- tn.optimizer.Optimizer是如何实现梯度参数更新和自身参数存储的
- tn.model.Model都做了哪些工作
- 一些设计
简介
tensorflow ML框架外接ps方案 可以看到一些扩展tf的思路
tensornet框架初探-(一)从Wide&Deep模型Demo出发看框架实现
TensorNet——基于TensorFlow的大规模稀疏特征模型分布式训练框架
通过对 tensornet 的分析可以看到,机器学习框架中,python 调用c 有两种方式
- 一种方式是直接通过 pybind11 调用c++ 对应函数,调用时即立即执行
- 一种调用 自定义算子,由session.run 真正触发执行。
定制tf时要不要新增python层接口:
- 新增python层接口。那么就要自定义一个python库,在这个库里应用自定义或原生OP,或者只是单纯调用下 c++函数做一些初始化工作
- 使用原有的tf python层接口。那么就要从 tensorboard 看计算图,看看tf python 函数用到了哪些原生op,这些op有哪些作用,哪些op需要自己自定义实现,进而替换掉这些原生op。
Wide&Deep模型Demo
import tensornet as tn
import tensorflow as tf
def columns_builder():
columns = {}
for slot in set(C.WIDE_SLOTS + C.DEEP_SLOTS):
columns[slot] = tn.feature_column.category_column(key=slot)
wide_columns = []
for slot in C.WIDE_SLOTS:
feature_column = tf.feature_column.embedding_column(columns[slot], dimension=1)
wide_columns.append(feature_column)
deep_columns = []
for slot in C.DEEP_SLOTS:
feature_column = tf.feature_column.embedding_column(columns[slot], dimension=8)
deep_columns.append(feature_column)
return wide_columns, deep_columns
def create_model(wide_columns, deep_columns):
wide, deep = None, None
inputs = {}
for slot in set(C.WIDE_SLOTS + C.DEEP_SLOTS):
inputs[slot] = tf.keras.layers.Input(name=slot, shape=(None,), dtype="int64", sparse=True)
sparse_opt = tn.core.AdaGrad(learning_rate=0.01, initial_g2sum=0.1, initial_scale=0.1)
if wide_columns:
wide = tn.layers.EmbeddingFeatures(wide_columns, sparse_opt, name='wide_inputs', is_concat=True)(inputs)
if deep_columns:
deep = tn.layers.EmbeddingFeatures(deep_columns, sparse_opt, name='deep_inputs', is_concat=True)(inputs)
for i, unit in enumerate(C.DEEP_HIDDEN_UNITS):
deep = tf.keras.layers.Dense(unit, activation='relu', name='dnn_{}'.format(i))(deep)
if wide_columns and not deep_columns:
output = tf.keras.layers.Dense(1, activation='sigmoid', name='pred')(wide)
elif deep_columns and not wide_columns:
output = tf.keras.layers.Dense(1, activation='sigmoid', name='pred')(deep)
else:
both = tf.keras.layers.concatenate([deep, wide], name='both')
output = tf.keras.layers.Dense(1, activation='sigmoid', name='pred')(both)
model = tn.model.Model(inputs, output)
dense_opt = tn.core.Adam(learning_rate=0.001, beta1=0.9, beta2=0.999, epsilon=1e-8)
model.compile(optimizer=tn.optimizer.Optimizer(dense_opt),
loss='binary_crossentropy',
metrics=['accuracy', tf.keras.metrics.AUC(),])
return model
def create_model():
if C.MODEL_TYPE == "DeepFM":
return DeepFM(C.LINEAR_SLOTS, C.DEEP_SLOTS, C.DEEP_HIDDEN_UNITS)
elif C.MODEL_TYPE == "WideDeep":
return WideDeep(C.LINEAR_SLOTS, C.DEEP_SLOTS, C.DEEP_HIDDEN_UNITS)
elif C.MODEL_TYPE == "DCN":
return DCN(C.DEEP_SLOTS, C.DEEP_HIDDEN_UNITS)
else:
sys.exit("unsupported model type: " + C.MODEL_TYPE)
# tensornet/examples/main.py
def main():
strategy = tn.distribute.PsStrategy()
model, sub_model = create_model()
dense_opt = tn.core.Adam(learning_rate=0.001, beta1=0.9, beta2=0.999, epsilon=1e-8)
model.compile(optimizer=tn.optimizer.Optimizer(dense_opt),loss='binary_crossentropy',metrics=['acc', "mse", "mae", 'mape', tf.keras.metrics.AUC(),tn.metric.CTR(), tn.metric.PCTR(), tn.metric.COPC()])
train_dataset = read_dataset(...)
model.fit(train_dataset, epochs=1, verbose=1, callbacks=[cp_cb, tb_cb])
if __name__ == "__main__":
main()
TensorNet版的wide-deep相较于TensorFlow原生版的主要由如下5个改动:
- 分布式训练strategy改为了tn.distribute.PsStrategy()。
- 将sparse特征的feature column统一使用tn.feature_column.category_column适配。
- 将模型的第一层统一使用tn.layers.EmbeddingFeatures替换。
- 将tf.keras.Model切换为tn.model.Model。
- 将optimizer切换为tn.optimizer.Optimizer。 PS:这五点也说明了我们可以如何扩展tf
源码结构
tensornet
/core // c++ 部分
/main
/py_wrapper.cc // 使用 PYBIND11_MODULE 建立 python 与 c 函数的映射关系
/kernels // op kernel 实现
/xx.cc
/ops // 为每个op kernel REGISTER_OP
/ps // 从中可以观察一个ps 的构成
/optimizer // 因为ps 是存储tf.Variable的,所以进行参数更新的优化器 自然也是 ps的一部分
/table // 因为ps 是存储tf.Variable的,table 就是参数的存储结构,基于ml 特性优化的kv 存储
/ps_cluster.cc/ps_cluster.h
/ps_local_server.cc/ps_local_server.h
/ps_remote_server.cc/ps_remote_server.h
/ps_server_interface.h
/ps_service_impl.cc/ps_service_impl.h
/BUILD // 为每个op 生成so 及python wrapper
tensornet // python 部分
/core // op 对应的python wrapper,由 Bazel 生成
examples
PsStrategy 相对 MultiWorkerMirroredStrategy 做了什么
- 从部署上看,传统的ps 模型是ps 和worker 分开部署,ps 是独立进程。tensornet 中 ps 和worker 在一个进程中,ps 是一个独立的服务,多个ps 服务组成PsCluster
- 从代码上看,PsCluster 持有一个 local_server 和 多个 remote_servers_,均实现了PsServerInterface,opKernel 通过持有PsCluster 实例来进行参数 访问和更新。
tn.distribute.PsStrategy() # 执行 __init__
super(OneDeviceStrategy, self).__init__(PsExtend(self))
tn.core.init() # PsExtend() 执行
# py_wrapper.cc 中由 PYBIND11_MODULE 注册,对应一个匿名函数
[]() {
PsCluster* cluster = PsCluster::Instance(); // 获取ps集群的实例
if (cluster->IsInitialized()) { // 判断集群是否初始化
return true;
}
if (cluster->Init() < 0) { // 对ps集群进行初始化操作
throw py::value_error("Init tensornet fail");
}
tensorflow::BalanceInputDataInfo* data_info = tensorflow::BalanceInputDataInfo::Instance();
if (data_info->Init(cluster->RankNum(), cluster->Rank()) < 0) {
throw py::value_error("Init BalanceInputDataInfo fail");
}
return true;
}
PsCluster 定义如下
// tensornet/core/ps/ps_cluster.h
class PsCluster {
public:
static PsCluster* Instance();
int Init();
int Rank() const; // 当期节点编号
size_t RankNum() const; // 集群节点数量
const PsServerInterface* GetServer(int shard_id) const; // 获取PsServer
public:
PsLocalServer local_server; // 当前节点对应的PsServer
private:
bool is_initialized_ = false;
std::unique_ptr<brpc::Server> server_;
PsServiceImpl ps_service_impl_;
std::vector<std::unique_ptr<PsRemoteServer>> remote_servers_; // 远端PsServer 引用
std::vector<std::string> workers_;
PsServer 接口定义如下,就是sparse 和 Dense 参数的pull 和push
// tensornet/core/ps/ps_server_interface.h
class PsServerInterface {
public:
virtual void SparsePullAsync(brpc::Controller *cntl,const SparsePullRequest *request,SparsePullResponse *response,Callback done) const = 0;
virtual void SparsePushAsync(brpc::Controller *cntl,const SparsePushRequest *request,SparsePushResponse *response,Callback done) const = 0;
virtual void DensePushPullAsync(brpc::Controller *cntl,const DensePushPullRequest *request,DensePushPullResponse *response,Callback done) const = 0;
virtual void DatasetPullAsync(brpc::Controller *cntl,const DatasetPullRequest *request,DatasetPullResponse *response,Callback done) const = 0;
tn.feature_column.category_column相比tensorflow自带的 有何不同(未完成)
tn.layers.EmbeddingFeatures的核心实现逻辑
python 调用c++函数 和 opKernel
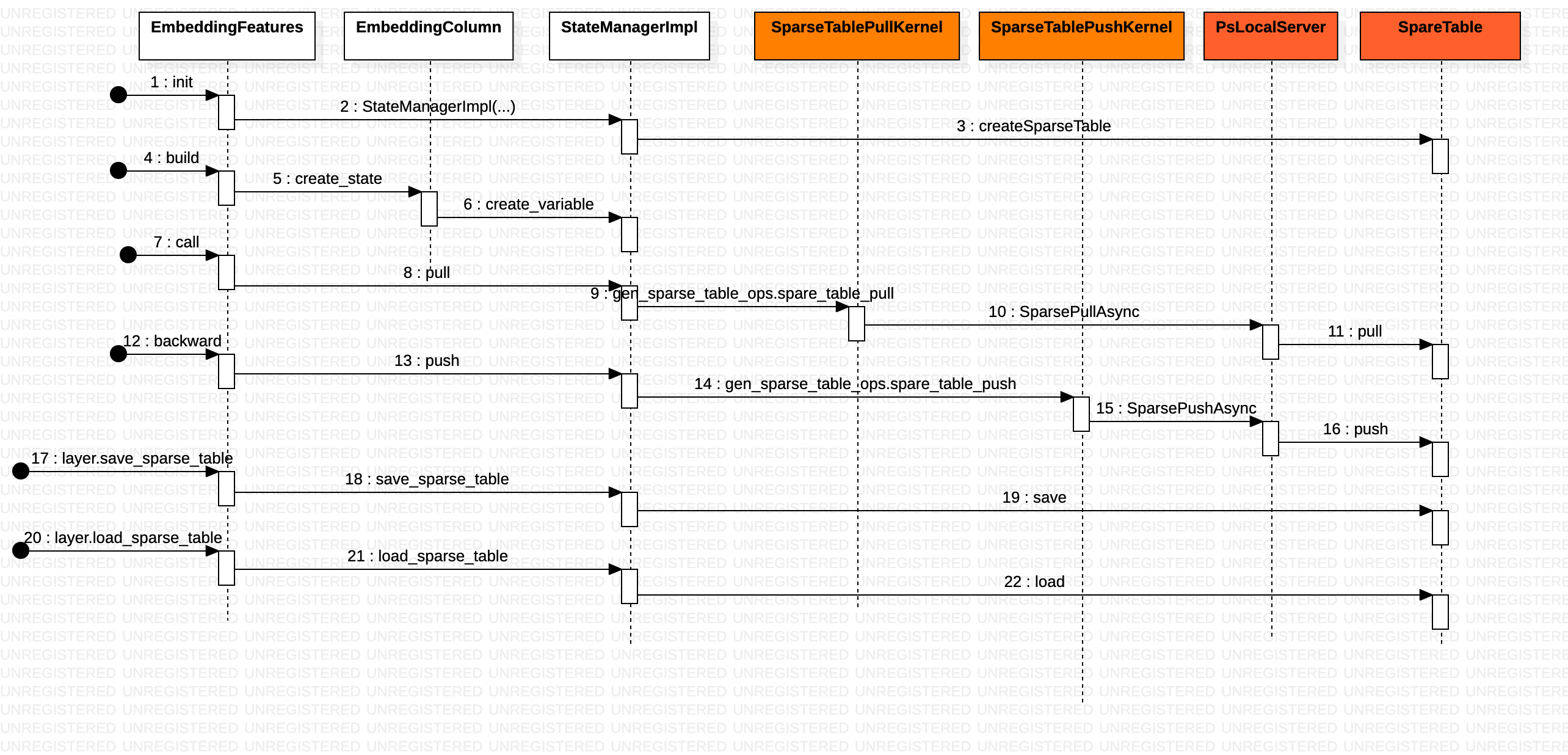
sparse 参数的活儿都让 SparseTable 干了。EmbeddingFeatures 是一个 Layer 实现。根据传入的 feature_column 名字 _state_manager.pull 返回一个 tensor。
# when this layer is been called, all the embedding data of `feature_columns` will be pulled from ps server and return as a tensor list.
# tensornet/tensornet/layers/embedding_features.py
class EmbeddingFeatures(Layer):
def __init__(self,feature_columns,...):
self._feature_columns = feature_columns
self._state_manager = StateManagerImpl(self, name, sparse_opt, dim, self.trainable
def call(self, features, cols_to_output_tensors=None):
using_features = self.filter_not_used_features(features)
transformation_cache = fc.FeatureTransformationCache(using_features)
self.sparse_pulling_features = self.get_sparse_pulling_feature(using_features)
pulled_mapping_values = self._state_manager.pull(self.sparse_pulling_features)
output_tensors = []
for column in self._feature_columns:
mapping_value = pulled_mapping_values[column.categorical_column.name]
with ops.control_dependencies([mapping_value]):
tensor = column.get_dense_tensor(transformation_cache,self._state_manager)
processed_tensors = self._process_dense_tensor(column, tensor)
output_tensors.append(processed_tensors)
return output_tensors
def backwards(self, grads_and_vars):
return self._state_manager.push(grads_and_vars, self.sparse_pulling_features)
_state_manager.pull 也就是 StateManagerImpl.pull ==> gen_sparse_table_ops.sparse_table_pull
class StateManagerImpl(fc.StateManager):
def __init__(self, layer, name, ...):
self.sparse_table_handle = tn.core.create_sparse_table(sparse_opt, name if name else "", dimension)
# py_wrapper.cc 中由 PYBIND11_MODULE 注册,对应一个匿名函数
[](py::object obj, std::string name, int dimension) {
OptimizerBase* opt = static_cast<OptimizerBase*>(PyCapsule_GetPointer(obj.ptr(), nullptr));
PsCluster* cluster = PsCluster::Instance();
SparseTable* table = CreateSparseTable(opt, name, dimension, cluster->RankNum(), cluster->Rank());
return table->GetHandle();
}
self.pulled_mapping_values = {}
self._cols_to_var_map = collections.defaultdict(lambda: None)
self._var_to_cols_map = collections.defaultdict(lambda: None)
def create_variable(self,feature_column,name,shape,...)
def get_variable(self, feature_column, name)
def pull(self, features):
...
pulled_mapping_values = gen_sparse_table_ops.sparse_table_pull(
[var.handle for var in vars],
[f.values for f in feature_values],
table_handle=self.sparse_table_handle)
...
def push(self, grads_and_vars, features):
...
return gen_sparse_table_ops.sparse_table_push(feature_values, grads,table_handle=self.sparse_table_handle)
def get_feature_mapping_values(self, column_name)
def save_sparse_table(self, filepath, mode):
return tn.core.save_sparse_table(self.sparse_table_handle, filepath, mode)
def load_sparse_table(self, filepath, mode):
return tn.core.load_sparse_table(self.sparse_table_handle, filepath, mode)
def show_decay(self):
return tn.core.show_decay(self.sparse_table_handle)
StateManagerImpl 初始化时 返回了一个table Handle,传给op 时会携带table Handle(uint32_t)
// tensornet/core/ps/table/sparse_table.cc
SparseTable* CreateSparseTable(const OptimizerBase* opt, const std::string& name,int dimension, int shard_num, int self_shard_id) {
SparseTable* table = new SparseTable(opt, name, dimension, shard_num, self_shard_id);
table->SetHandle(SparseTableRegistry::Instance()->Register(table));
return table;
}
SparseTable::SparseTable(const OptimizerBase* opt, const std::string& name,int dimension, int shard_num, int self_shard_id)
: shard_num_(shard_num)
, self_shard_id_(self_shard_id)
, opt_(opt)
, dim_(dimension)
, name_(name) {
CHECK(opt_ != nullptr);
op_kernel_ = opt_->CreateSparseOptKernel(dim_);
}
// tensornet/core/ps/table/sparse_table.h
class SparseTable {
public:
SparseTable(const OptimizerBase* opt, const std::string& name,int dimension, int shard_num, int self_shard_id);
~SparseTable() = default;
void Pull(const SparsePullRequest* req, butil::IOBuf& out_emb_buf, SparsePullResponse* resp);
void Push(const SparsePushRequest* req, butil::IOBuf& grad_buf, SparsePushResponse* resp);
void SetHandle(uint32_t handle);
uint32_t GetHandle() const {return handle_;}
void Save(const std::string& filepath, const std::string& mode);
void Load(const std::string& filepath, const std::string& mode);
void ShowDecay() const;
spare_table_pull 逻辑
gen_sparse_table_ops.spare_table_pull ==> SparseTablePullKernel.ComputeAsync ==> SparsePullCall.Start ==> PsLocalServer/PsRemoteServer.SparsePullAsync ==> SparseTable.Pull
// tensornet/core/kernels/sparse_table_ops.cc
class SparseTablePullKernel : public AsyncOpKernel {
void ComputeAsync(OpKernelContext* c, DoneCallback done) override {
...
PsCluster* cluster = PsCluster::Instance();
for (size_t shard_id = 0; shard_id < cluster->RankNum(); shard_id++) {
calls.emplace_back(new SparsePullCall(table_handle_, shard_id, dim));
}
...
Semaphore semaphore(calls.size());
for (auto& call : calls) {
call->Start([this, call, &var_infos, &semaphore]() {
PopulatePulledVariable_(var_infos, call->call_sign_infos,call->resp, call->cntl.response_attachment());
semaphore.Notify();
delete call;
});
}
semaphore.WaitForSemaphore();
}
}
class SparsePullCall {
public:
SparsePullCall(int table_handle, int shard_id, int dim)
: shard_id_(shard_id) {
req.set_table_handle(table_handle);
req.set_dim(dim);
}
void Start(const tensornet::Callback& done) {
if (call_sign_infos.empty()) {
done();
} else {
const PsServerInterface* si = PsCluster::Instance()->GetServer(shard_id_);
si->SparsePullAsync(&cntl, &req, &resp, done);
}
}
}
public:
brpc::Controller cntl;
SparsePullRequest req;
SparsePullResponse resp;
private:
int shard_id_ = -1;
如果是本机,则PsServer = local_server,否则PsServer = remote_server
// tensornet/core/ps/ps_cluster.cc
const PsServerInterface* PsCluster::GetServer(int shard_id) const {
if (Rank() == shard_id) {
return &local_server;
} else {
CHECK_LT(shard_id, (int)remote_servers_.size());
return remote_servers_[shard_id].get();
}
}
底层存储
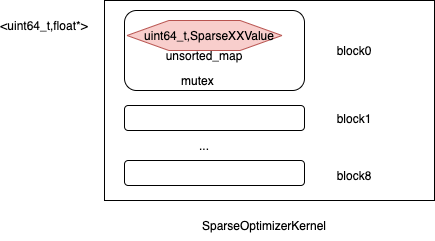
SparseTable 对外提供的是 kv式(<uint64_t,float*>)的带有 ml意义的操作接口(Pull和Push 方法,Push grad 会更新W),底层 使用8个SparseKernelBlock,每个SparseKernelBlock 使用unordered_map 存储kv(ps就是一个kv嘛),key是uint64_t id,value是一个封装float*的SparseXXValue class。对于同一个key,复杂点的Optimizer 除了存储W 之外,还有其它数据,因此用一个class(这里的xxValue) 来封装它们,且Optimizer 策略与xxValue 有一一对应关系。SparseKernelBlock 操作有mutex 保护,所以 SparseTable 弄8个SparseKernelBlock 的原因估计是 降低锁竞争。
- PsLocalServer.pull ==> SparseTable.Pull ==> SparseOptimizerKernel.GetWeight ==> SparseKernelBlock.GetWeight ==> SparseAdaGradValue.Weight
- PsLocalServer.push ==> SparseTable.Push ==> SparseOptimizerKernel.Apply ==> SparseKernelBlock.Apply ==> SparseAdaGradValue.Apply
// tensornet/core/ps/optimizer/optimizer_kernel.h
static constexpr size_t SPARSE_KERNEL_BLOCK_NUM = 8;
template <typename KernelBlockType>
class SparseOptimizerKernel : public SparseOptimizerKernelBase {
public:
SparseOptimizerKernel(const OptimizerBase* opt, int dimension) {
// 创建八个块进行存储,每个块是一个SparseKernelBlock对象
for (size_t i = 0; i < SPARSE_KERNEL_BLOCK_NUM; ++i) {
blocks_.emplace_back(opt, dimension);
}
}
float* GetWeight(uint64_t sign) {
int block_num = GetBlockId_(sign);
return blocks_[block_num].GetWeight(sign);
}
private:
std::vector<KernelBlockType> blocks_;
}
template <typename OptType, typename ValueType>
class SparseKernelBlock {
public:
float* GetWeight(uint64_t sign) {
const std::lock_guard<std::mutex> lock(*mutex_);
// 返回一个 pair<iterator, bool> ,当 insert 将 val 成功添加到容器中时,返回的迭代器指向新添加的键值对,bool 值为 True,头插法
auto inserted = values_.insert({sign, nullptr});
if (inserted.second) {
// inserted.first = iterator 也可以视为 iterator 第一个pair,inserted.first->first 第一个pair的key,inserted.first->second 第一个pair的value
inserted.first->second = alloc_.allocate(dim_, opt_);
}
return inserted.first->second->Weight();
}
}
private:
const OptType* opt_ = nullptr;
// unordered_map 是标准库中一个无排序的map,key,value,哈希函数
std::unordered_map<uint64_t, ValueType*, decltype(sparse_key_hasher)> values_;
Allocator<ValueType> alloc_;
SparseXXValue存储了当前embedding的维度,以及优化器的参数。
// tensornet/core/ps/optimizer/ada_grad_kernel.h
class alignas(4) SparseAdaGradValue: public SparseOptValue {
public:
float* Weight() {
return data_;
}
private:
float g2sum_;
float data_[0];
// tensornet/core/ps/optimizer/ada_grad_kernel.cc
void SparseAdaGradValue::Apply(const AdaGrad* opt, SparseGradInfo& grad_info, int dim) {
delta_show_ += grad_info.batch_show;
float* w = Weight();
double add_g2sum = 0;
for (int i = 0; i < dim; ++i) {
add_g2sum += grad_info.grad[i] * grad_info.grad[i];
}
g2sum_ += add_g2sum / dim;
for (int i = 0; i < dim; ++i) {
w[i] -= opt->learning_rate * grad_info.grad[i] / (opt->epsilon + sqrt(g2sum_));
}
}
从大的方面来说,DenseTable与SparseTable 类似,也有DenseOptimizerKernel、DenseKernelBlock 等概念,实际差异 DenseXXValue 和 SparseXXValue 上体现出来。以Adam为例(未完成)
- TensorNet将模型的所有dense参数合并后使用分布式数组切分到不同的机器上,每次pull和push参数的时候只有一次网络请求。相较于TensorFlow对每个tensor都有一次网络请求的方法极大的减少了网络请求的次数从而提升了模型训练的速度。
- TensorNet对sparse参数使用分布式hashmap按照哈希值均匀分布不同的节点上。这相较于TensorFlow需要让开发者根据自身情况将tensor分布在不同的ps节点上的方法更加灵活,这不仅减小了节点通信热点的概率,还减轻了开发者的工作量。
// tensornet/core/ps/optimizer/adam_kernel.h
class DenseAdamValue {
public:
void SetWeight(butil::IOBuf& w_buf);
const Eigen::ArrayXf& GetWeight() const {
return w_;
}
// tensornet/core/ps/optimizer/adam_kernel.cc
void Apply(const Adam* opt, const Eigen::ArrayXf& g) {
beta1_power_ *= opt->beta1;
beta2_power_ *= opt->beta2;
const float alpha = opt->learning_rate * Eigen::numext::sqrt(1.0 - beta2_power_) / (1.0 - beta1_power_);
m_ += (g - m_) * (1.0 - opt->beta1);
v_ += (g.square() - v_) * (1.0 - opt->beta2);
w_ -= (m_ * alpha) / (v_.sqrt() + opt->epsilon);
}
private:
float beta1_power_ = 0;
float beta2_power_ = 0;
// ArrayXf 即 Array<float,Dynamic,1> 对应 Array<typename Scalar, int RowsAtCompileTime, int ColsAtCompileTime>
// Array类提供了更方便的元素级的操作,可以通过matrix() 转为Matrix,这种转换并不耗费运行时间(编译器优化了)
Eigen::ArrayXf w_;
Eigen::ArrayXf m_;
Eigen::ArrayXf v_;
}
class alignas(4) SparseAdamValue
: public SparseOptValue {
public:
float* Weight() {
return data_;
}
const float* Weight() const {
return data_;
}
// tensornet/core/ps/optimizer/adam_kernel.cc
void Apply(const Adam* opt, SparseGradInfo& grad_info, int dim) {
delta_show_ += grad_info.batch_show;
float* w = Weight();
float* m = M(dim);
float* v = V(dim);
for (int i = 0; i < dim; ++i) {
m[i] = opt->beta1 * m[i] + (1 - opt->beta1) * grad_info.grad[i];
v[i] = opt->beta2 * v[i] + (1 - opt->beta2) * grad_info.grad[i] * grad_info.grad[i];
w[i] -= opt->learning_rate * m[i] / (opt->epsilon + sqrt(v[i]));
}
}
protected:
float* M(int dim) {
return data_ + dim * 1;
}
float* V(int dim) {
return data_ + dim * 2;
}
private:
float data_[0];
};
// tensornet/core/ps/optimizer/data_struct.h
struct SparseGradInfo {
float* grad;
int batch_show;
};
tn.optimizer.Optimizer是如何实现梯度参数更新和自身参数存储的
原生的tf 根据 grad 的类型 来决定更新weight/ variable 的方法。Optimizer 实现了 梯度计算、更新的整体流程, 根据不同的梯度计算策略 对应不同的 Optimizer 子类,子类实现Optimizer 暴露的抽象方法即可。
# tensorflow/tensorflow/python/training/optimizer.py
class Optimizer(object):
def minimize(self, loss, global_step=None, var_list=None,...):
grads_and_vars = self.compute_gradients(loss, var_list=var_list, ...)
vars_with_grad = [v for g, v in grads_and_vars if g is not None]
return self.apply_gradients(grads_and_vars, global_step=gl
def compute_gradients(self, loss, var_list=None,...):
...
def apply_gradients(self, grads_and_vars, global_step=None, name=None):
# 调用update_op
def _apply_dense(self, grad, var):
raise NotImplementedError()
def _apply_sparse_duplicate_indices(self, grad, var):
...
return self._apply_sparse(gradient_no_duplicate_indices, var)
def _apply_sparse(self, grad, var):
raise NotImplementedError()
class _RefVariableProcessor(_OptimizableVariable):
# g ==> 梯度, self._v ==> 待更新的variable
def update_op(self, optimizer, g):
if isinstance(g, ops.Tensor):
update_op = optimizer._apply_dense(g, self._v)
return update_op
else:
assert isinstance(g, ops.IndexedSlices), ("Gradient ", g, " is neither a tensor nor IndexedSlices.")
return optimizer._apply_sparse_duplicate_indices(g, self._v)
# tensorflow/python/training/gradient_descent.py
class GradientDescentOptimizer(optimizer.Optimizer):
def __init__(self, learning_rate, use_locking=False, name="GradientDescent"):
super(GradientDescentOptimizer, self).__init__(use_locking, name)
self._learning_rate = learning_rate
def _apply_dense(self, grad, var):
return training_ops.apply_gradient_descent(var,math_ops.cast(self._learning_rate_tensor, var.dtype.base_dtype),grad,use_locking=self._use_locking).op
def _apply_sparse_duplicate_indices(self, grad, var):
delta = ops.IndexedSlices(grad.values * math_ops.cast(self._learning_rate_tensor, var.dtype.base_dtype),grad.indices, grad.dense_shape)
return var.scatter_sub(delta, use_locking=self._use_locking)
tensornet 对Optimizer 的使用,可以看到 optimizer 主要是为了更新dense参数(全连接网络的参数)
# tensornet/examples/main.py
dense_opt = tn.core.Adam(learning_rate=0.001, beta1=0.9, beta2=0.999, epsilon=1e-8)
model.compile(optimizer=tn.optimizer.Optimizer(dense_opt),loss='binary_crossentropy',metrics=['acc', "mse", "mae", 'mape', tf.keras.metrics.AUC(),tn.metric.CTR(), tn.metric.PCTR(), tn.metric.COPC()])
原版 Optimizer 使用 opt.minimize(loss, var_list=[var1, var2]) 更新var1, var2。 计算梯度_compute_gradients 更新梯度 apply_gradients,分布式场景下 apply_gradients 会用到_distributed_apply,_distributed_apply 会用到 _resource_apply_sparse 和_resource_apply_dense(由Optimizer 子类实现)。PS: 由此可见,tf层面sparse 和 dense 就支持分开处理了,并留了接口来扩展。
# tensorflow/python/keras/optimizer_v2/optimizer_v2.py
# 实际使用的是其子类 tf.keras.optimizers.SGD`, `tf.keras.optimizers.Adam`
class OptimizerV2(trackable.Trackable):
def minimize(self, loss, var_list, grad_loss=None, name=None, tape=None):
grads_and_vars = self._compute_gradients(loss, var_list=var_list, grad_loss=grad_loss, tape=tape)
return self.apply_gradients(grads_and_vars, name=name)
# Add ops to apply sparse gradients to the variable `handle`
def _resource_apply_sparse(self, grad, handle, indices, apply_state):
raise NotImplementedError("Must be implemented in subclasses.")
# Add ops to apply dense gradients to the variable `handle`
def _resource_apply_dense(self, grad, handle, apply_state):
raise NotImplementedError("Must be implemented in subclasses.")
Optimizer 最重要的改动是_distributed_apply,使用了自定义OP DenseTablePushPullKernel, 一个op 把 apply gradients 和 pull 都干了,_resource_apply_sparse 和 _resource_apply_dense 也就啥都不用干了。
# tensornet/optimizer/optimizer.py
class Optimizer(optimizer_v2.OptimizerV2):
def __init__(self,dense_opt,name='TensornetOptimizer',**kwargs):
self.dense_table_handle = tn.core.create_dense_table(dense_opt)
...
def save_dense_table(self, filepath):
return tn.core.save_dense_table(self.dense_table_handle, filepath)
def load_dense_table(self, filepath):
return tn.core.load_dense_table(self.dense_table_handle, filepath)
def _distributed_apply(self, distribution, grads_and_vars, name, apply_state):
...
# 对应 DenseTablePushPullKernel
gen_dense_table_ops.dense_table_push_pull(vars, grads, table_handle=self.dense_table_handle)
super(Optimizer, self)._distributed_apply(distribution, grads_and_vars, name, apply_state)
def _resource_apply_sparse(self, grad, var, indices, apply_state=None):
return control_flow_ops.no_op()
def _resource_apply_dense(self, grad, var, apply_state=None):
return control_flow_ops.no_op()
gen_dense_table_ops.dense_table_push_pull ==> DenseTablePushPullKernel.ComputeAsync ==> DensePushPullCall.Start ==> PsServer.DensePushPullAsync ==> SparseOptimizerKernel->Apply + SparseOptimizerKernel->GetWeight
tn.model.Model都做了哪些工作
Model.fit ==> Model.train_step 原版Model.train_step 实现
# tensorflow/python/keras/engine/training.py
class Model(base_layer.Layer, version_utils.ModelVersionSelector):
def train_step(self, data):
...
data = data_adapter.expand_1d(data)
x, y, sample_weight = data_adapter.unpack_x_y_sample_weight(data)
# Run forward pass.
with backprop.GradientTape() as tape:
y_pred = self(x, training=True)
loss = self.compiled_loss(y, y_pred, sample_weight, regularization_losses=self.losses)
# Run backwards pass.
self.optimizer.minimize(loss, self.trainable_variables, tape=tape)
...
train_step 只会调用优化器更新dense参数,然后调用backwards方法更新id特征的参数。
# tensornet/tensornet/model/Model.py
class Model(tf.keras.Model):
# This method should contain the mathematical logic for one step of training. This typically includes the forward pass,loss calculation, backpropagation,and metric updates.
def train_step(self, data):
data = data_adapter.expand_1d(data)
x, y, sample_weight = data_adapter.unpack_x_y_sample_weight(data)
with backprop.GradientTape() as tape:
y_pred = self(x, training=True) # 计算预测值
loss = self.compiled_loss(y, y_pred, sample_weight, regularization_losses=self.losses) # 计算损失
gradients = tape.gradient(loss, self.trainable_variables) # 计算梯度
self.optimizer.apply_gradients(zip(gradients, self.trainable_variables)) # 更新dense参数
self.backwards(list(zip(gradients, self.trainable_variables))) # 更新id特征的参数,更新方法在EmbeddingFeatures中
...
def backwards(self, grads_and_vars):
backward_ops = []
for layer in self.layers:
if not hasattr(layer, 'backwards'):
continue
op = layer.backwards(grads_and_vars)
if op:
backward_ops.append(op)
...
Model.backwards ==> layer/EmbeddingFeatures.backwards ==> StateManagerImpl.push ==> gen_sparse_table_ops.spare_table_push就到了OP 的逻辑了。
一些设计
临时embedding 矩阵
TensorNet——基于TensorFlow的大规模稀疏特征模型分布式训练框架对于最简单的wide&deep模型,如果在一个广告系统中有3亿用户,那么就需要定义一个维度为3亿的embedding矩阵,在训练模型时需要在这个3亿维的矩阵上做embedding_lookup得到当前batch内的用户的embedding信息,近而在embedding之上做更加复杂的操作。
训练的batch_size=1024,在进行前向计算之前,TensorNet将每个batch的特征ID从0开始重新编排作为输入,这样输入特征的index分布在[0,1024)之间;同时根据原始的特征ID从server拉取对应的embedding向量,填充到tensorflow的embedding矩阵中,这样每个特征field/slot的embedding矩阵大小就只有1024 x 4(以下图中embedding_size=4为例)。对于tensorflow来说,每次迭代只需要在1024 x 4这样非常小的embedding矩阵中做查找。dense网络地计算则完全依赖tensorflow实现,可以基于tensorflow构造各种复杂的网络结构,例如Transformer/Attention/CNN/RNN等,保留了tensorflow设计网络结构的灵活性。PS: 相当于sparse 参数检索 不仅是只访问slot 了,根据当前 batch 构造的临时的 embedding 矩阵还降低了检索空间
下图以wide&deep模型为例,结合下图做进一步说明,我们从最下层往上看。最下面的sparse feature,输入的是原始的特征ID,从sparse feature到virtual sparse feature,将原始特征ID映射为新的index,范围在[0, 1024)。倒数第二层的parameter server节点,保存全部特征的embedding,TensorNet根据原始特征ID从server拉取对应的embedding,填充至倒数第四层的embedding矩阵中。通过这种方式,将图中从sparse feature到parameter server的查找,转换为从virtual sparse feature到embedding lookup这部分的查找,对tensorflow来说,相当于在一个1024 x 4的embedding矩阵上做查找。之后,从virtual sparse feature一直到最顶层的ctr预估,都由tensorflow来完成。
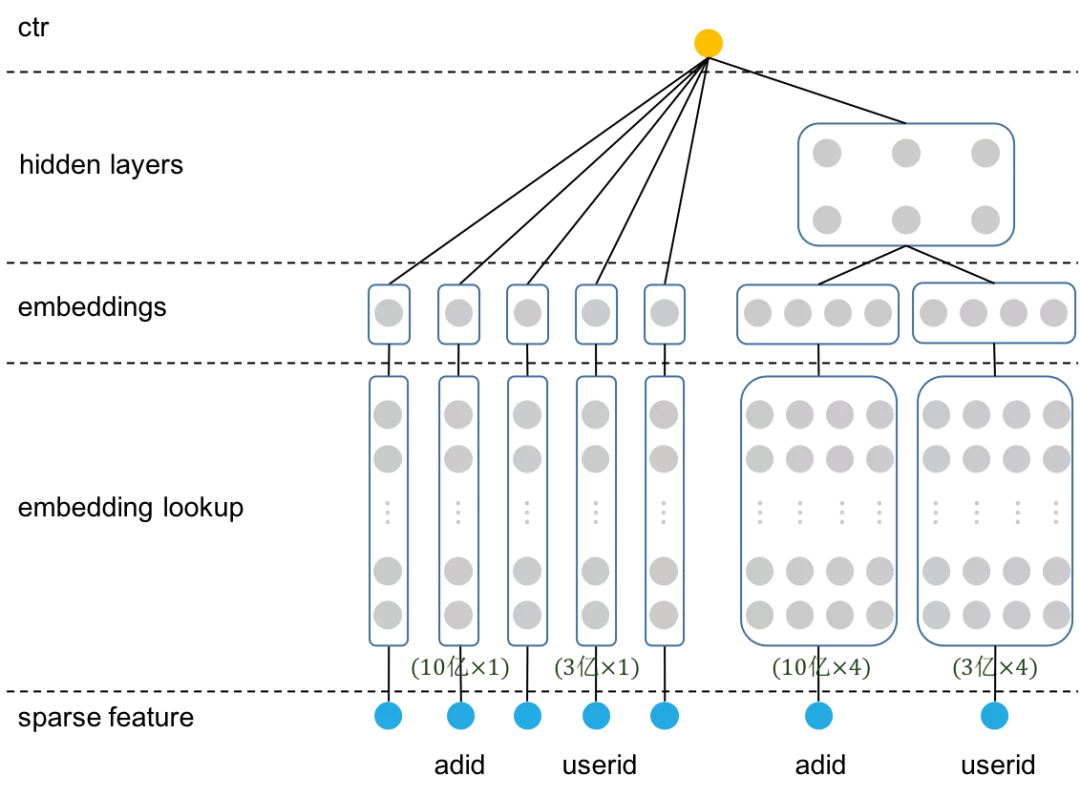
训练
TensorNet使用一个较小的,可以容纳特征在一个batch内所有数据的embedding矩阵代替TensorFlow默认实现中需要定义的较大的embedding矩阵。
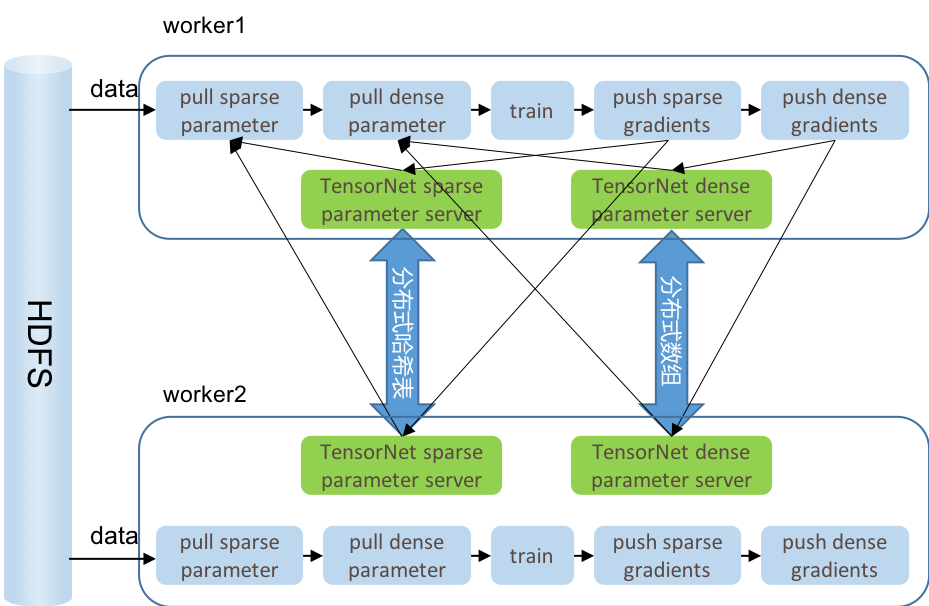
TensorNet异步训练架构
- TensorNet将sparse参数和与dense参数分别使用不同的parameter server管理。
- TensorNet不设单独的parameter server节点。在每个worker中都会维护一个sparse paramter server和dense parameter server。这省去了开发人员管理ps节点和worker节点的不少麻烦。
- TensorNet将模型的所有dense参数合并后使用分布式数组切分到不同的机器上,每次pull和push参数的时候只有一次网络请求。相较于TensorFlow对每个tensor都有一次网络请求的方法极大的减少了网络请求的次数从而提升了模型训练的速度。
TensorNet同步训练架构
- TensorNet使用单独的sparse parameter server节点保存所有sparse参数。通过parameter server可以解决TensorFlow支持的sparse特征维度不能太大的问题。
- TensorNet对sparse参数做了特殊的定制化的同步。TensorNet在训练时只同步当前训练的batch所关注的稀疏特征,相较于TensorFlow会将所有参数都同步的模式通信数据减少到了原来的万分之一,乃至十万分之一。sparse参数的梯度汇总是在worker上完成的,而不是在server上,TensorNet采用定制化的all-reduce在worker上对sparse参数的梯度进行合并,之后再push到server上去。PS: 因为有临时embedding 矩阵,所以在梯度通信处理上跟 dense 参数差不多了
- dense参数存储在worker中,每个worker都有一份dense参数的完整副本,所以不需要dense ps server。每一次迭代,所有worker先计算dense参数的梯度,然后做all-reduce操作,worker之间相互交换数据,然后各自对梯度做汇总,再对权重或参数做更新。
留下评论