
前言
orm 的几个基本功能
- 生成SQL。 难点:同样功能不同数据库 语句不同,如何支持偏门一点的SQL 语句。
db.Where("age > ?",35).Limit(100).Order("age desc").Find(&user)。 前面的方法称为 Chain method,最后一个Find方式称为 Finisher Method,决定了sql 的类型(crud) 并真正执行。- 数据库连接池
- 插件/扩展机制,比如执行每个sql 时自动加一个 过滤条件,比如支持多数据库、读写分离(根据操作类型 选择db连接)。
What is MyBatis?
MyBatis is a first class persistence framework with support for custom SQL, stored procedures and advanced mappings. MyBatis eliminates almost all of the JDBC code and manual setting of parameters and retrieval of results. MyBatis can use simple XML or Annotations for configuration and map primitives, Map interfaces and Java POJOs (Plain Old Java Objects) to database records.
- Mybatis It is characterized by the use of Xml files to configure SQL statements. Programmers write their own SQL statements. When the requirements change, we only need to modify the configuration files, which is more flexible. 在这一类orm 框架出现之前,sql是写死在代码中的。有了mybatis 之后,sql 可以与 代码分离。
- In addition, Mybatis transfer to the SQL statement can be passed directly into the Java object without the need for a parameter to correspond with the placeholder; the query result set is mapped to a Java object. sql 的输入输出 都可以是对象,而不是java.sql 默认支持的ResultSet 等。 PS: mybatis 之于java.sql 有点类似于 netty 之于java.nio
使用手感
原生mybatis 代码
String resource = "mybatis/mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
try (SqlSession session = sqlSessionFactory.openSession()) {
List<User> users = session.selectList("mybatis.mapper.UserMapper.getAll");
System.out.println(String.format("result:%s", users));
}
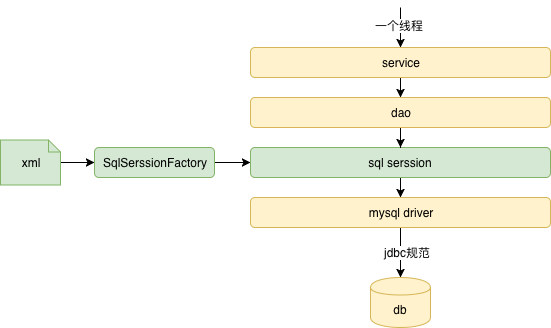
Mapper.xml 文件可以看做是 MyBatis 的 JDBC SQL 模板,Mapper.java 文件是 Mapper.xml 对应的 Java 对象。UserMapper.java 中的方法和 UserMapper.xml 的 CRUD 语句元素( <insert>、<delete>、<update>、<select>)存在一一对应关系。使用时,SqlSession 可以直接执行sql,也可以通过动态代理生成UserMapper 实例UserMapper userMapper = sqlSession.getMapper(UserMapper.class);,底层仍是 SqlSession.xx。PS:核心就是如何构造SQLsession,如何使用SQLsession
MyBatis框架要做的事情,就是在运行session.selectList("mybatis.mapper.UserMapper.getAll")的时候,将 mybatis.mapper.UserMapper.getAll进行替换,使SQL语句变成SELECT id,name FROM user。
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/test"/>
<property name="username" value="root"/>
<property name="password" value="root"/>
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="mybatis/mapper/UserMapper.xml"/>
</mappers>
</configuration>
// UserMapper.xml
<mapper namespace="io.github.dunwu.spring.orm.mapper.UserMapper">
...
<delete id="deleteByPrimaryKey" parameterType="java.lang.Long">
delete from user
where id = #{id,jdbcType=BIGINT}
</delete>
</mapper>
public interface UserMapper {
int deleteByPrimaryKey(Long id);
int insert(User record);
User selectByPrimaryKey(Long id);
List<User> selectAll();
int updateByPrimaryKey(User record);
}
整体架构
MyBatis版本升级引发的线上告警回顾及原理分析MyBatis要将SQL语句完整替换成带参数值的版本,需要经历框架初始化以及实际运行时动态替换这两个部分。
在框架初始化阶段,有一些组件会被构建:
- SqlSession:作为MyBatis工作的主要顶层API,表示和数据库交互的会话(包括对事务的控制),完成必要的数据库增删改查功能。
- SqlSource:负责根据用户传递的parameterObject,动态地生成SQL语句,将信息封装到BoundSql对象中,并返回。
- Configuration:MyBatis所有的配置信息都维持在Configuration对象之中。在构建Configuration的过程中,会涉及到构建对应每一条SQL语句对应的MappedStatement
在具体执行阶段
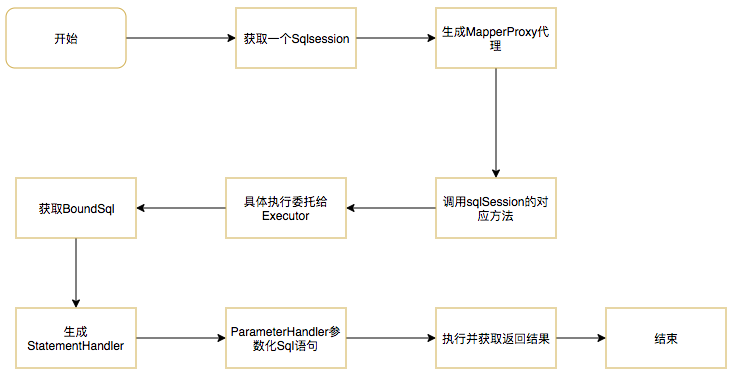
- SqlSession:作为MyBatis工作的主要顶层API,表示和数据库交互的会话,完成必要数据库增删改查功能。
- Executor:MyBatis执行器,这是MyBatis调度的核心,负责SQL语句的生成和查询缓存的维护。
- BoundSql:表示动态生成的SQL语句以及相应的参数信息。
- StatementHandler:封装了JDBC Statement操作,负责对JDBC statement的操作,如设置参数、将Statement结果集转换成List集合等等。
- ParameterHandler:负责对用户传递的参数转换成JDBC Statement 所需要的参数。
- TypeHandler:负责Java数据类型和JDBC数据类型之间的映射和转换。
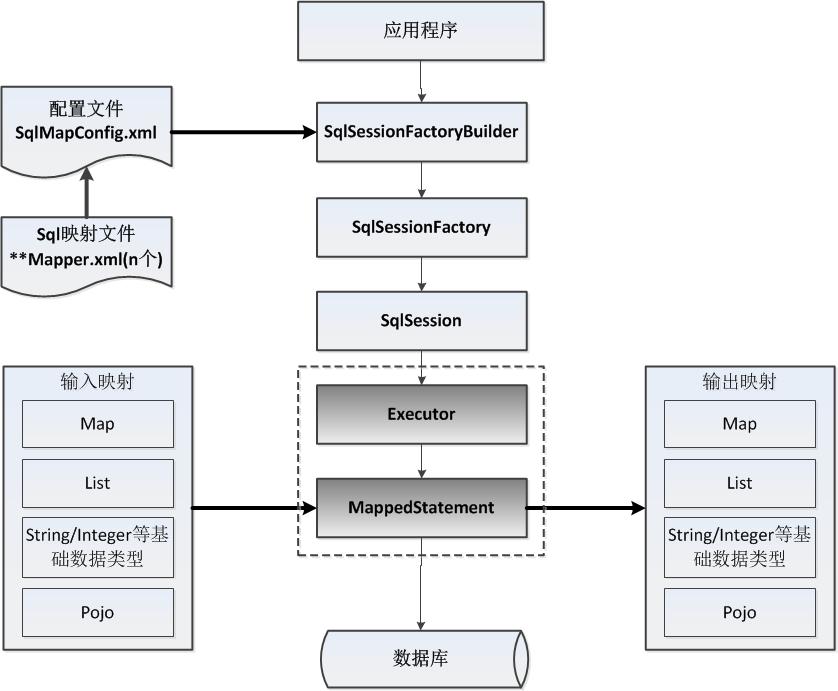
- The global configuration file SqlMapConfig.xml configuring the running environment of Mybatis. The Mapper.xml file is the SQL map file, and the SQL statement in the file is configured in the file. This file needs to be in SqlMLoad in apConfig.xml.
- SqlSessionFactory is constructed through configuration information such as Mybatis environment, that is, a conversation factory. 这个图的走势很形象,尤其是从配置文件 建builder的感觉。
- SqlSession is created by a conversational factory, and the operation database needs to be done through SqlSession.
- Mybatis The bottom layer customize the Executor actuator interface to operate the database, and the Executor executor calls the specific MappedStatement object to perform the database operation.
- MappedStatement Mybatis is also a low-level encapsulation object, which encapsulates Mybatis configuration information and SQL mapping information. A SQL in the Mapper.xml file corresponds to a Mapped Statement object, SQL.ID is the ID of the Mapped statement.
- Executor The input Java object is mapped to SQL by MappedStatement before the SQL is held, and the meaning of the input parameter mapping is to set the parameters for PreparedStatement in JDBC programming. Executor maps the output results to the Java object after executing SQL through the MappedStatement, and the output result mapping process is equivalent to the resolution process for the results in JDBC programming.
源码分析

mybatis 最重要的接口是 SqlSession,它是应用程序与持久层之间执行交互操作的一个单线程对象,SqlSessionTemplate 只是mybatis-spring 对它的封装
- SqlSession对象完全包含以数据库为背景的所有执行SQL操作的方法,它的底层封装了JDBC连接,可以用SqlSession实例来直接执行被映射的SQL语句.
- SqlSession是线程不安全的,每个线程都应该有它自己的SqlSession实例.
- 使用完SqlSeesion之后关闭Session很重要,应该确保使用finally块来关闭它.
自上而下,逐渐分解
| 抽象 | 参数 ==> 结果 | 方法 | 备注 |
|---|---|---|---|
| SqlSession | mapper xml 文件中的statement id ==> (List) obj | 增删改查 | |
| Executor | MappedStatement ==> (List) obj, 根据parameterObject 可以得到真正待执行的BoundSql | query/update | 额外处理缓存、批量等逻辑 |
| StatementHandler | java.sql.Statement ==> (List) obj | query/update | |
| java.sql.Statement | sql ==> ResultSet | query/update |

// DefaultSqlSession
public void select(String statement, Object parameter, RowBounds rowBounds, ResultHandler handler) {
try {
MappedStatement ms = configuration.getMappedStatement(statement);
executor.query(ms, wrapCollection(parameter), rowBounds, handler);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
// SimpleExecutor
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
stmt = prepareStatement(handler, ms.getStatementLog());
return handler.query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
}
// SimpleStatementHandler
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
// BoundSql boundSql = ms.getBoundSql(parameter); 来自BaseExecutor.query
String sql = boundSql.getSql();
statement.execute(sql);
return resultSetHandler.handleResultSets(statement);
}
学到的技巧
StatementHandler 包含多个子类,分别对应不同的场景。一般情况下 会使用工厂模式,mybatis 实现了一个RoutingStatementHandler(上层代码无需关心具体实现),根据参数 创建一个delegate 实现 并将请求转发给它。 是一个用对象 替换if else 的典型实现。
public class RoutingStatementHandler implements StatementHandler {
private final StatementHandler delegate;
public RoutingStatementHandler(Executor executor, MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
switch (ms.getStatementType()) {
case STATEMENT:
delegate = new SimpleStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
case PREPARED:
delegate = new PreparedStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
case CALLABLE:
delegate = new CallableStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
default:
throw new ExecutorException("Unknown statement type: " + ms.getStatementType());
}
}
}
再进一步
作者在做hibernate 与mybatis 的对比时提到:
- Hibernate The degree of automation is high, it only needs to configure OR mapping relations, and does not need to write Sql statements. hibernate完全可以通过对象关系模型实现对数据库的操作,拥有完整的JavaBean对象与数据库的映射结构来自动生成sql。而mybatis仅有基本的字段映射,对象数据以及对象实际关系仍然需要通过手写sql来实现和管理。
- Mybatis Although mapping relations between Sql and Java objects, programmers need to write Sql themselves.
github baomidou/mybatis-plus重点:
- 只做增强不做改变,这一点对理解 mybatis的使用很重要
- 启动即会自动注入基本 CURD,Mapper 对应的 XML 支持热加载,对于简单的 CRUD 操作,甚至可以无 XML 启动
- 内置代码生成器:采用代码或者 Maven 插件可快速生成 Mapper(替换原来的dao) 、 Model 、 Service 、 Controller 层代码
- 支持 Lambda 形式调用