简介
拿存储这件事来说,开发人员到底关注什么呢?围绕存储这个概念,我们可以说出一堆名词,块设备、文件系统、对象存储、本地磁盘、磁盘阵列、NFS、Ceph等等。这些名词毋庸置疑都与存储相关,也的确会被各种业务系统所使用,但我相信,绝大多数的开发人员对这些名词并不关心。
- 作为用户,开发人员只关心一件事情,我所负责的业务系统,指定目录中的数据需要被持久化的保存下来。
- 使用复杂存储的场景更多见于业务系统所调用的各种中间件中,比如数据库需要高速稳定的块设备类型存储,再比如大数据领域的“存算分离”场景下对接对象存储等等。然而在大多数场景下,这些复杂中间件的维护并不是开发人员应该关心的事情。它们由专门的运维人员进行维护,开发人员只需要得到访问它们的地址即可。
如何接入 K8s 持久化存储?K8s CSI 实现机制浅析 未读
浅谈如何实现一个 CSI 插件 未读。
Kubernetes存储方案发展过程概述
- 最开始是通过Volume Plugin实现集成外部存储系统,即不同的存储系统对应不同的Volume Plugin。Volume Plugin实现代码全都放在了Kubernetes主干代码中(in-tree),也就是说这些插件与核心Kubernetes二进制文件一起链接、编译、构建和发布。
- 从1.8开始,Kubernetes停止往Kubernetes代码中增加新的存储支持。从1.2开始,推出了一种新的插件形式支持外部存储系统,即FlexVolume。FlexVolume类似于CNI插件,通过外部脚本集成外部存储接口,这些脚本默认放在
/usr/libexec/kubernetes/kubelet-plugins/volume/exec/,需要安装到所有Node节点上。它是只针对 Kubernetes 的私有的存储扩展,目前已经处于冻结状态,可以正常使用但不再发展新功能了。 - 从1.9开始又引入了Container Storage Interface(CSI)容器存储接口,CSI 是公开的技术规范,是目前 Kubernetes 重点发展的扩展机制。
与容器服务 ACK 发行版的深度对话最终弹:如何通过 open-local 玩转容器本地存储
CSI规范
CSI 规范可以分为需要容器系统去实现的组件,以及需要存储提供商去实现的组件两大部分。
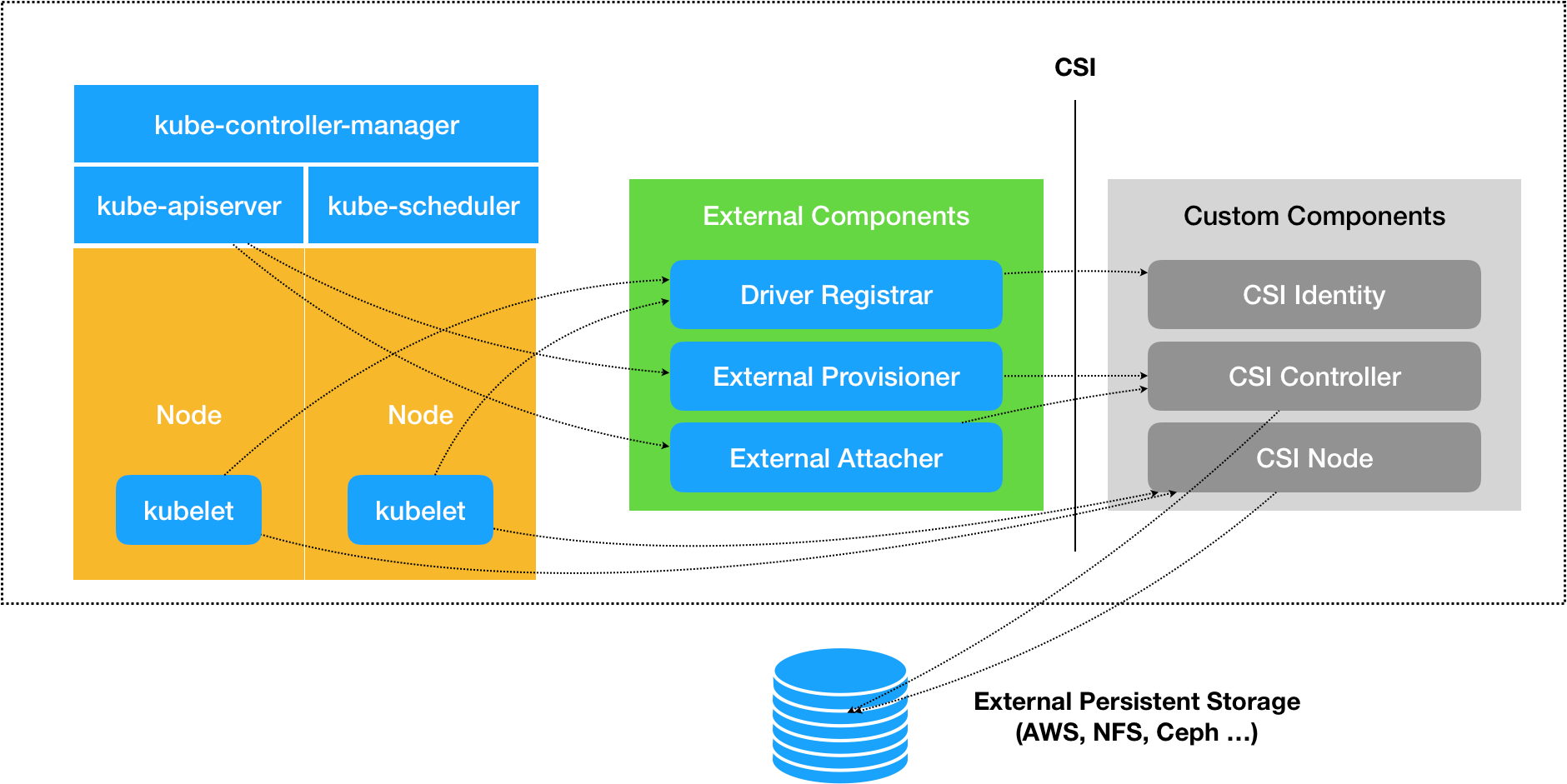
- 前者包括了存储整体架构、Volume 的生命周期模型、驱动注册、Volume 创建、挂载、扩容、快照、度量等内容,这些 Kubernetes 都已经完整地实现了,大体上包括以下几个组件:
- Driver Register:负责注册第三方插件,CSI 0.3 版本之后已经处于 Deprecated 状态,将会被Node Driver Register所取代。
- External Provisioner:调用第三方插件的接口来完成数据卷的创建与删除功能。
- External Attacher:调用第三方插件的接口来完成数据卷的挂载和操作。
- External Resizer:调用第三方插件的接口来完成数据卷的扩容操作。
- External Snapshotter:调用第三方插件的接口来完成快照的创建和删除。
- External Health Monitor:调用第三方插件的接口来提供度量监控数据。
- 后者定义了外部存储挂载到容器过程中所涉及操作的抽象接口和具体的通讯方式,主要包括以下三个 gRPC 接口:
- CSI Identity 接口:用于描述插件的基本信息,比如插件版本号、插件所支持的 CSI 规范版本、插件是否支持存储卷创建、删除功能、是否支持存储卷挂载功能等等。
- CSI Controller 接口:用于从存储系统的角度对存储资源进行管理,比如准备和移除存储(Provision、Delete 操作)、附加与分离存储(Attach、Detach 操作)、对存储进行快照等等。存储插件并不一定要实现这个接口的所有方法,对于存储本身就不支持的功能,可以在 CSI Identity 接口中声明为不提供。
- CSI Node 接口:用于从集群节点的角度对存储资源进行操作,比如存储卷的分区和格式化、将存储卷挂载到指定目录上,或者将存储卷从指定目录上卸载,等等。
| external sidecar container | capacity | |
|---|---|---|
| controller service | external-provisioner | 创建与删除pv功能 |
| controller service | external-attacher | 执行pv的挂载和卸载操作 |
| controller service | external-resizer | 执行pv的扩容操作 |
| controller service | external-snapshotter | 完成快照的创建和删除 |
| controller service | liveness-probe | 检查CSI驱动程序的运行状况 |
| node service | node-driver-registar | 将外部CSI插件注册到kubelet |
| node service | liveness-probe | 检查CSI驱动程序的运行状况 |
CSI 插件本身是由一组标准的 Kubernetes 资源所构成,CSI Controller 接口是一个以 StatefulSet 方式部署的 gRPC 服务,CSI Node 接口则是基于 DaemonSet 方式部署的 gRPC 服务。
整体设计
CSI 包括CSI Controller 和 CSI Node。 PS:传统的master + agent 工作模式,master 掌握所有信息,做出决策, agent 根据决策执行落地
- CSI Controller的主要功能是提供存储服务视角对存储资源和存储卷进行管理和操作。
- CSI Node主要功能是对主机(Node)上的Volume进行管理和操作。PS:可以猜测:pod声明了pvc,scheduler 为pod调度了node后,对应node 上的csi node 组件开始mount nfs目录到某个本地目录,创建pod后,再bind mount 到容器内。
CSI 插件体系的设计思想,就是把Dynamic Provision 阶段以及 Kubernetes 里的一部分存储管理功能(比如“Attach 阶段”和“Mount 阶段”,实际上是通过调用 CSI 插件来完成的),从主干代码里剥离出来,做成了几个单独的组件。这些组件会通过 Watch API 监听 Kubernetes 里与存储相关的事件变化,比如 PVC 的创建,来执行具体的存储管理动作。
浅析 CSI 工作原理CSI 的设计思想,把插件的职责从“两阶段处理”,扩展成了Provision、Attach 和 Mount 三个阶段。不过不是每个存储方案都会经历这三个阶段,比如 NFS 就没有 Attach/Detach 阶段。其中
- Provision 等价于“创建磁盘”。它的逆操作是移除(Delete)存储。
- 当 PVController watch 到集群中有 PVC 创建时,会判断当前是否有 in-tree plugin 与之相符,如果没有则判断其存储类型为 out-of-tree 类型,于是给 PVC 打上注解 volume.beta.kubernetes.io/storage-provisioner={csi driver name};
- 当 extenal-provisioner watch 到 PVC 的注解 csi driver 与自己的 csi driver 一致时,调用 CSI Controller 的 CreateVolume 接口;
- 当 CSI Controller 的 CreateVolume 接口返回成功时,extenal-provisioner 会在集群中创建对应的 PV;
- PVController watch 到集群中有 PV 创建时,将 PV 与 PVC 进行绑定。
- Attach 等价于“挂载磁盘到虚拟机”,此时尽管设备还不能使用,但你已经可以用操作系统的
fdisk -l命令查看到设备。它的逆操作是分离(Detach)存储设备。- ADController 监听到 pod 被调度到某节点,并且使用的是 CSI 类型的 PV,会调用内部的 in-tree CSI 插件的接口,该接口会在集群中创建一个 VolumeAttachment 资源;
- external-attacher 组件 watch 到有 VolumeAttachment 资源创建出来时,会调用 CSI Controller 的 ControllerPublishVolume 接口;
- 当 CSI Controller 的 ControllerPublishVolume 接口调用成功后,external-attacher 将对应的 VolumeAttachment 对象的 Attached 状态设为 true;
- ADController watch 到 VolumeAttachment 对象的 Attached 状态为 true 时,更新 ADController 内部的状态 ActualStateOfWorld。
- Mount 等价于“将该磁盘格式化后,挂载在 Volume 的宿主机目录上”,也就是操作系统中mount命令的作用。它的逆操作是卸载(Unmount)存储设备。
- kubelet 在创建 pod 的过程中,会调用 CSI Node 插件,执行 mount 操作
Kubernetes存储生态系统:几种有代表性的CSI存储插件的实现 未读
nfs示例
k8s-storage-1 作为 NFS 存储服务器
# 安装 NFS 服务端软件包
yum install nfs-utils
# 创建共享数据目录
mkdir -p /data/k8s
chown nfsnobody:nfsnobody /data/k8s
# 编辑服务配置文件
vi /etc/exports
/data/k8s 192.168.9.0/24(rw,sync,all_squash,anonuid=65534,anongid=65534,no_subtree_check)
# 说明
# 192.168.9.0/24:可以访问 NFS 存储的客户端 IP 地址
# rw:读写操作,客户端机器拥有对卷的读写权限。
# sync:内存数据实时写入磁盘,性能会有所限制
# all_squash:NFS 客户端上的所有用户在使用共享目录时都会被转换为一个普通用户的权限
# anonuid:转换后的用户权限 ID,对应的操作系统的 nfsnobody 用户
# anongid:转换后的组权限 ID,对应的操作系统的 nfsnobody 组
# no_subtree_check:不检查客户端请求的子目录是否在共享目录的子树范围内,也就是说即使输出目录是一个子目录,NFS 服务器也不检查其父目录的权限,这样可以提高效率。
# 启动服务并设置开机自启
systemctl enable nfs-server --now
找一台额外的机器作为客户端验证测试
# 创建测试挂载点
mkdir /mnt/nfs
# 安装 NFS 软件包(一定要安装,否则无法识别 nfs 类型的存储)
yum install nfs-utils
# 挂载 NFS 共享目录
mount -t nfs 192.168.9.81:/data/k8s /mnt/nfs/
想要 Kubernetes 支持 NFS 存储,我们需要安装 nfs-subdir-external-provisioner ,它是一个存储资源自动调配器,它可将现有的 NFS 服务器通过持久卷声明来支持 Kubernetes 持久卷的动态分配。
# 所有集群节点安装 NFS Client
yum install nfs-utils
# 添加 Helm 源
helm repo add nfs-subdir-external-provisioner https://kubernetes-sigs.github.io/nfs-subdir-external-provisioner
kubectl create ns nfs-system
helm install nfs-subdir-external-provisioner nfs-subdir-external-provisioner/nfs-subdir-external-provisioner --set storageClass.name=nfs-sc --set nfs.server=192.168.9.81 --set nfs.path=/data/k8s -n nfs-system
# --set storageClass.name=nfs-sc:指定 storageClass 的名字
# --set nfs.server=192.168.9.81:指定 NFS 服务器的地址
# --set nfs.path=/data/k8s:指定 NFS 导出的共享数据目录
# --set storageClass.defaultClass=true:指定为默认的 sc,本示例没使用
# -n nfs-system:指定命名空间
查看创建的资源
[root@k8s-master-1 ~]# kubectl get sc nfs-sc -o wide
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
nfs-sc cluster.local/nfs-subdir-external-provisioner Delete Immediate true 66s
[root@k8s-master-1 ~]# kubectl get deployment -n nfs-system -o wide
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
nfs-subdir-external-provisioner 1/1 1 1 73m nfs-subdir-external-provisioner registry.k8s.io/sig-storage/nfs-subdir-external-provisioner:v4.0.2 app=nfs-subdir-external-provisioner,release=nfs-subdir-external-provisioner
创建测试 PVC
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: nfs-pvc
spec:
storageClassName: nfs-sc
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Gi
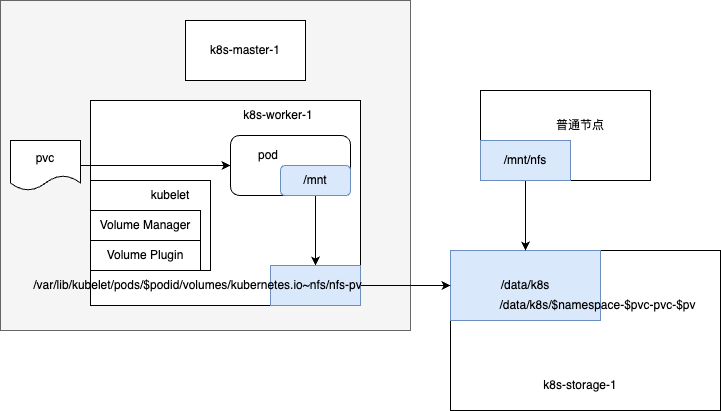
PersistentVolumeController 会不断地循环去查看每一个 PVC,是不是已经处于 Bound(已绑定)状态。如果不是,那它就会遍历所有的、可用的 PV,并尝试将其与未绑定的 PVC 进行绑定,所谓将一个 PV 与 PVC 进行“绑定”,其实就是将这个 PV 对象的名字,填在了 PVC 对象的 spec.volumeName 字段上。PV 和 PVC 绑定上了,那么又是如何将容器里面的数据进行持久化的呢, Docker 的 Volume 挂载,其实就是将一个宿主机上的目录和一个容器里的目录绑定挂载在了一起。
当 Pod 被调度到一个节点上后,节点上的 kubelet 组件就会为这个 Pod 创建它的 Volume 目录,默认情况下 kubelet 为 Volume 创建的目录在 kubelet 工作目录下面:/var/lib/kubelet/pods/<Pod的ID>/volumes/kubernetes.io~<Volume类型>/<Volume名字>然后就需要根据我们的 Volume 类型来决定需要做什么操作了
- 比如我们用的 Ceph RBD,那么 kubelet 就需要先将 Ceph 提供的 RBD 挂载到 Pod 所在的宿主机上面,这个阶段在 Kubernetes 中被称为 Attach 阶段。Attach 阶段完成后,为了能够使用这个块设备,kubelet 还要进行第二个操作,即:格式化这个块设备,然后将它挂载到宿主机指定的挂载点上。这个挂载点,也就是上面我们提到的 Volume 的宿主机的目录。将块设备格式化并挂载到 Volume 宿主机目录的操作,在 Kubernetes 中被称为 Mount 阶段。
- 因为 NFS 存储并没有一个设备需要挂载到宿主机上面,所以 kubelet 就会直接进入第二个 Mount 阶段,相当于直接在宿主机上面执行如下的命令:
mount -t nfs k8s-storage-1:/data/k8s /var/lib/kubelet/pods/<Pod的ID>/volumes/kubernetes.io~nfs/nfs-pv我们可以看到这个 Volume 被挂载到了 NFS(k8s-storage-1:/data/k8s)下面,以后我们在这个目录里写入的所有文件,都会被保存在远程 NFS 服务器上。