
简介
几个主要点
- Kubernetes 调度本身的演化 从 Kubernetes 资源控制到开放应用模型,控制器的进化之旅
- 调度器的原理, How Kubernetes Initializers work the scheduler is yet another controller, watching for Pods to show up in the API server and assigns each of them to a Node How does the Kubernetes scheduler work?. PS:确实有直接基于controller-runtime 写调度器的
while True:
pods = queue.getPod()
assignNode(pod)
scheduler is not responsible for actually running the pod – that’s the kubelet’s job. So it basically just needs to make sure every pod has a node assigned to it.
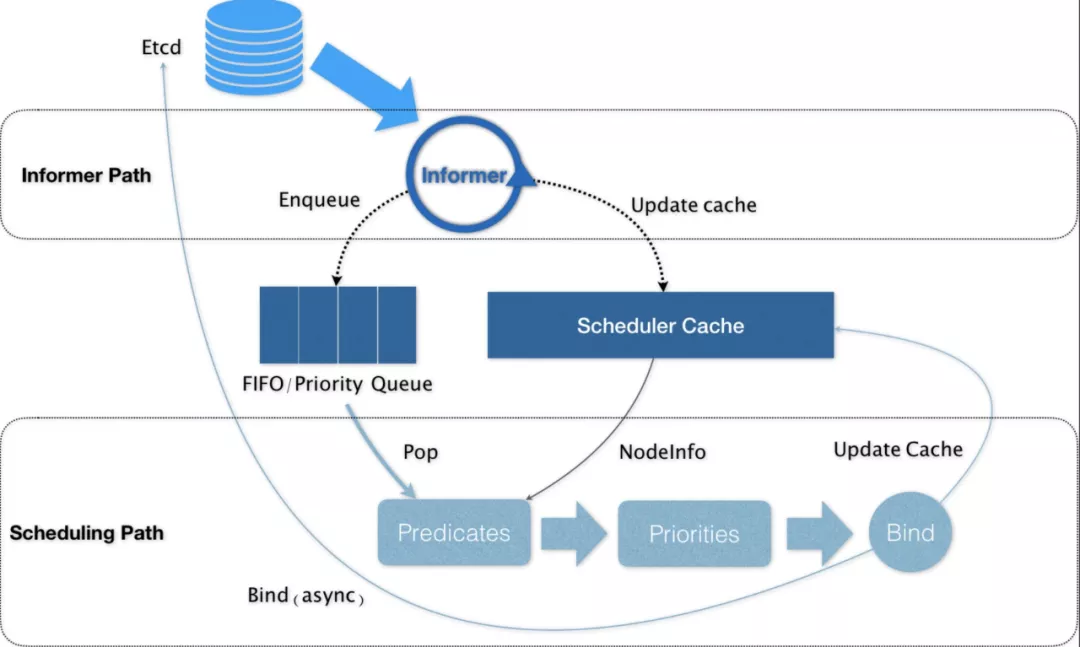
工作流程
Create a custom Kubernetes scheduler
- The default scheduler starts up according to the parameters given.
- It watches on apiserver, and puts pods where its
spec.nodeNameis empty into its internal scheduling queue. It pops out a pod from the scheduling queue and starts a standard scheduling cycle. - It retrieves “hard requirements” (like cpu/memory requests, nodeSelector/nodeAffinity) from the pod’s API spec. Then the predicates phase occurs where it calculates to give a node candidates list which satisfies those requirements.
- It retrieves “soft requirements” from the pod’s API spec and also applies some default soft “policies” (like the pods prefer to be more packed or scattered across the nodes). It finally gives a score for each candidate node, and picks up the final winner with the highest score.
- It talks to the apiserver (by issuing a bind call) and sets
上述设计在批调度器上就不是一定的,批调度器因为要支持gang scheduler,即比如一个job包含5个pod,至少3个pod启动才可以正常工作,此时就不能一个pod一个pod判断,批调度器会采用session的方式,一个session 对当前的 pod node状态 的”定格“,一次性为当前 session内所有未调度的pod 确定node。
Kubernetes 资源模型与资源管理
从编排系统的角度来看,Node 是资源的提供者,Pod 是资源的使用者,而调度是将两者进行恰当的撮合。在 Kubernetes 里,Pod 是最小的原子调度单位。这也就意味着,所有跟调度和资源管理相关的属性都应该是属于 Pod 对象的字段。而这其中最重要的部分,就是 Pod 的CPU 和内存配置。在 Kubernetes 中,像 CPU 这样的资源被称作“可压缩资源”(compressible resources)。它的典型特点是,当可压缩资源不足时,Pod 只会“饥饿”,但不会退出。而像内存这样的资源,则被称作“不可压缩资源(incompressible resources)。当不可压缩资源不足时,Pod 就会因为 OOM(Out-Of-Memory)被内核杀掉。
request and limit
Kubernetes 里 Pod 的 CPU 和内存资源,实际上还要分为 limits 和 requests 两种情况:在调度的时候,kube-scheduler 只会按照 requests 的值进行计算。而在真正设置 Cgroups 限制的时候,kubelet 则会按照 limits 的值来进行设置。这个理念基于一种假设:容器化作业在提交时所设置的资源边界,并不一定是调度系统所必须严格遵守的,这是因为在实际场景中,大多数作业使用到的资源其实远小于它所请求的资源限额。
request limit 关系 ==> QoS ==> 驱逐策略
QoS 划分的主要应用场景,是当宿主机资源(主要是不可压缩资源)紧张的时候,kubelet 对 Pod 进行 Eviction(即资源回收)时需要用到的。“紧张”程度可以作为kubelet 启动参数配置,默认为
memory.available<100Mi
nodefs.available<10%
nodefs.inodesFree<5%
imagefs.available<15%
Kubernetes 计算 Eviction 阈值的数据来源,主要依赖于从 Cgroups 读取到的值,以及使用 cAdvisor 监控到的数据。当宿主机的 Eviction 阈值达到后,就会进入 MemoryPressure 或者 DiskPressure 状态,从而避免新的 Pod 被调度到这台宿主机上。
limit 不设定,默认值由 LimitRange object确定
| limits | requests | Qos模型 | |
|---|---|---|---|
| 有 | 有 | 两者相等 | Guaranteed |
| 有 | 无 | 默认两者相等 | Guaranteed |
| x | 有 | 两者不相等 | Burstable |
| 无 | 无 | BestEffort |
而当 Eviction 发生的时候,kubelet 具体会挑选哪些 Pod 进行删除操作,就需要参考这些 Pod 的 QoS 类别了。PS:怎么有一种 缓存 evit 的感觉。limit 越“模糊”,物理机MemoryPressure/DiskPressure 时,越容易优先被干掉。
DaemonSet 的 Pod 都设置为 Guaranteed 的 QoS 类型。否则,一旦 DaemonSet 的 Pod 被回收,它又会立即在原宿主机上被重建出来,这就使得前面资源回收的动作,完全没有意义了。
Kubernetes 基于资源的调度
在 Kubernetes 项目中,默认调度器的主要职责,就是为一个新创建出来的 Pod,寻找一个最合适的节点(Node)而这里“最合适”的含义,包括两层:
- 预选:从集群所有的节点中,根据调度算法挑选出所有可以运行该 Pod 的节点;
- 优选:从第一步的结果中,再根据调度算法挑选一个最符合条件的节点作为最终结果。
所以在具体的调度流程中,默认调度器会首先调用一组叫作 Predicate 的调度算法,来检查每个 Node。然后,再调用一组叫作 Priority 的调度算法,来给上一步得到的结果里的每个 Node 打分。最终的调度结果,就是得分最高的那个Node。
除了Pod,Scheduler 需要调度其它对象么?不需要。因为Kubernetes 对象虽多,但只有Pod 是调度对象,其它对象包括数据对象(比如PVC等)、编排对象(Deployment)、Pod辅助对象(NetworkPolicy等) 都只是影响Pod的调度,本身不直接消耗计算和内存资源。
Scheduler对一个 Pod 调度成功,是通过设置Pod的.Spec.NodeName为节点的名称,将一个Pod绑定到一个节点。然而,Scheduler是间接地设置.Spec.NodeName而不是直接设置。Kubernetes Scheduler不被允许更新Pod的Spec。因此,KubernetesScheduler创建了一个Kubernetes绑定对象, 而不是更新Pod。在创建绑定对象后,Kubernetes API将负责更新Pod的.Spec.NodeName。
调度主要包括两个部分
- 组件交互,包括如何与api server交互感知pod 变化,如何感知node 节点的cpu、内存等参数。PS:任何调度系统都有这个问题。
- 调度算法,上文的Predicate和Priority 算法
调度这个事情,在不同的公司和团队里的实际需求一定是大相径庭的。上游社区不可能提供一个大而全的方案出来。所以,将默认调度器插件化是 kube-scheduler 的演进方向。
谓词和优先级算法
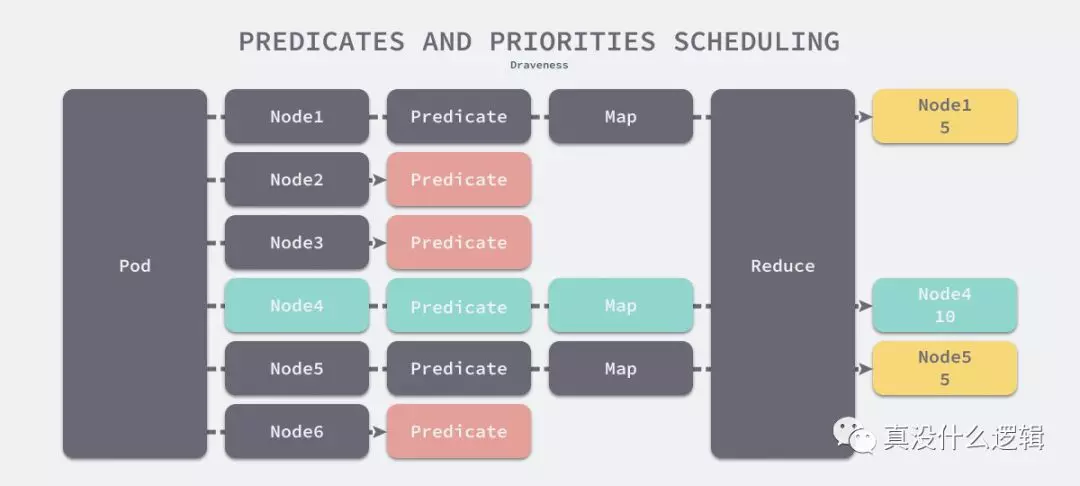
我们假设调度器中存在一个谓词算法和一个 Map-Reduce 优先级算法,当我们为一个 Pod 在 6 个节点中选择最合适的一个时,6 个节点会先经过谓词的筛选,图中的谓词算法会过滤掉一半的节点,剩余的 3 个节点经过 Map 和 Reduce 两个过程分别得到了 5、10 和 5 分,最终调度器就会选择分数最高的 4 号节点。
Predicate
从Pod 属性中检索“硬性要求”(比如 CPU/内存请求值,nodeSelector/nodeAffinity),然后过滤阶段发生,在该阶段计算出满足要求的节点候选列表。
- GeneralPredicates
- PodFitsResources,检查的只是 Pod 的 requests 字段
- PodFitsHost,宿主机的名字是否跟 Pod 的 spec.nodeName 一致。
- PodFitsHostPorts,Pod 申请的宿主机端口(spec.nodePort)是不是跟已经被使用的端口有冲突。
- PodMatchNodeSelector,Pod 的 nodeSelector 或者 nodeAffinity 指定的节点,是否与待考察节点匹配
- 与 Volume 相关的过滤规则
- 是宿主机相关的过滤规则
- Pod 相关的过滤规则。比较特殊的,是 PodAffinityPredicate。这个规则的作用,是检查待调度 Pod 与 Node 上的已有 Pod 之间的亲密(affinity)和反亲密(anti-affinity)关系
在具体执行的时候, 当开始调度一个 Pod 时,Kubernetes 调度器会同时启动 16 个 Goroutine,来并发地为集群里的所有 Node 计算 Predicates,最后返回可以运行这个 Pod 的宿主机列表。
Priorities
从 Pod 属性中检索“软需求”,并应用一些默认的“软策略”(比如 Pod 倾向于在节点上更加聚拢或分散),最后,它为每个候选节点给出一个分数,这里打分的范围是 0-10 分,得分最高的节点就是最后被 Pod 绑定的最佳节点。
-
LeastRequestedPriority + BalancedResourceAllocation
- LeastRequestedPriority计算方法
score = (cpu((capacity-sum(requested))10/capacity) + memory((capacity-sum(requested))10/capacity))/2实际上就是在选择空闲资源(CPU 和 Memory)最多的物理机 - BalancedResourceAllocation,计算方法
score = 10 - variance(cpuFraction,memoryFraction,volumeFraction)*10每种资源的 Fraction 的定义是 :Pod 请求的资源/ 节点上的可用资源。而 variance 算法的作用,则是资源 Fraction 差距最小的节点。BalancedResourceAllocation 选择的,其实是调度完成后,所有节点里各种资源分配最均衡的那个节点,从而避免一个节点上 CPU 被大量分配、而 Memory 大量剩余的情况。
- LeastRequestedPriority计算方法
- NodeAffinityPriority
- TaintTolerationPriority
- InterPodAffinityPriority
- ImageLocalityPriority
优先级和抢占
优先级和抢占机制,解决的是 (高优先级的)Pod 调度失败时该怎么办的问题
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
priorityClassName: high-priority
Pod 通过 priorityClassName 字段,声明了要使用名叫 high-priority 的 PriorityClass。当这个 Pod 被提交给 Kubernetes 之后,Kubernetes 的 PriorityAdmissionController 就会自动将这个 Pod 的 spec.priority 字段设置为 PriorityClass 对应的value 值。
如果确定抢占可以发生,那么调度器就会把自己缓存的所有节点信息复制一份,然后使用这个副本来模拟抢占过程。
- 找到牺牲者,判断抢占者是否可以部署在牺牲者所在的Node上
-
真正开始抢占
- 调度器会检查牺牲者列表,清理这些 Pod 所携带的 nominatedNodeName 字段。
- 调度器会把抢占者的 nominatedNodeName,设置为被抢占的 Node 的名字。
- 调度器会开启一个 Goroutine,同步地删除牺牲者。
- 调度器就会通过正常的调度流程把抢占者调度成功
基于Scheduling Framework
为什么引入?最初对于 Kube-scheduler 进行扩展的方式主要有两种,一种是Scheduler Extender(http外挂), 另外一种是多调度器,部署多个调度器(一个公司两个老板,可能命令冲突)。Scheduler Extender 的性能较差可是维护成本较小,Custom Scheduler 的研发和维护的成本特别高但是性能较好,这种情况是开发者面临这种两难处境。这时候 Kubernetes Scheduling Framework V2 横空出世,在scheduler core基础上进行了改造和提取,在scheduler几乎所有关键路径上设置了plugins扩展点。Scheduler Framework 属于 Kubernetes 内部的扩展机制(通过 Golang 的 Plugin 机制来实现的,需静态编译),用户可以在不修改scheduler core代码的前提下开发plugins,最后与core一起编译打包成二进制包实现扩展/重新编译kube-schduler。
明确了 Kubernetes 中的各个调度阶段,提供了设计良好的基于插件的接口。调度框架认为 Kubernetes 中目前存在调度(Scheduling)和绑定(Binding)两个循环:
- 调度循环在多个 Node 中为 Pod 选择最合适的 Node;
- 绑定循环将调度决策应用到集群中,包括绑定 Pod 和 Node、绑定持久存储等工作;
除了两个大循环之外,调度框架中还包含 QueueSort、PreFilter、Filter、PostFilter、Score、Reserve、Permit、PreBind、Bind、PostBind 和 Unreserve 11 个扩展点(Extension Point),这些扩展点会在调度的过程中触发,它们的运行顺序如下:
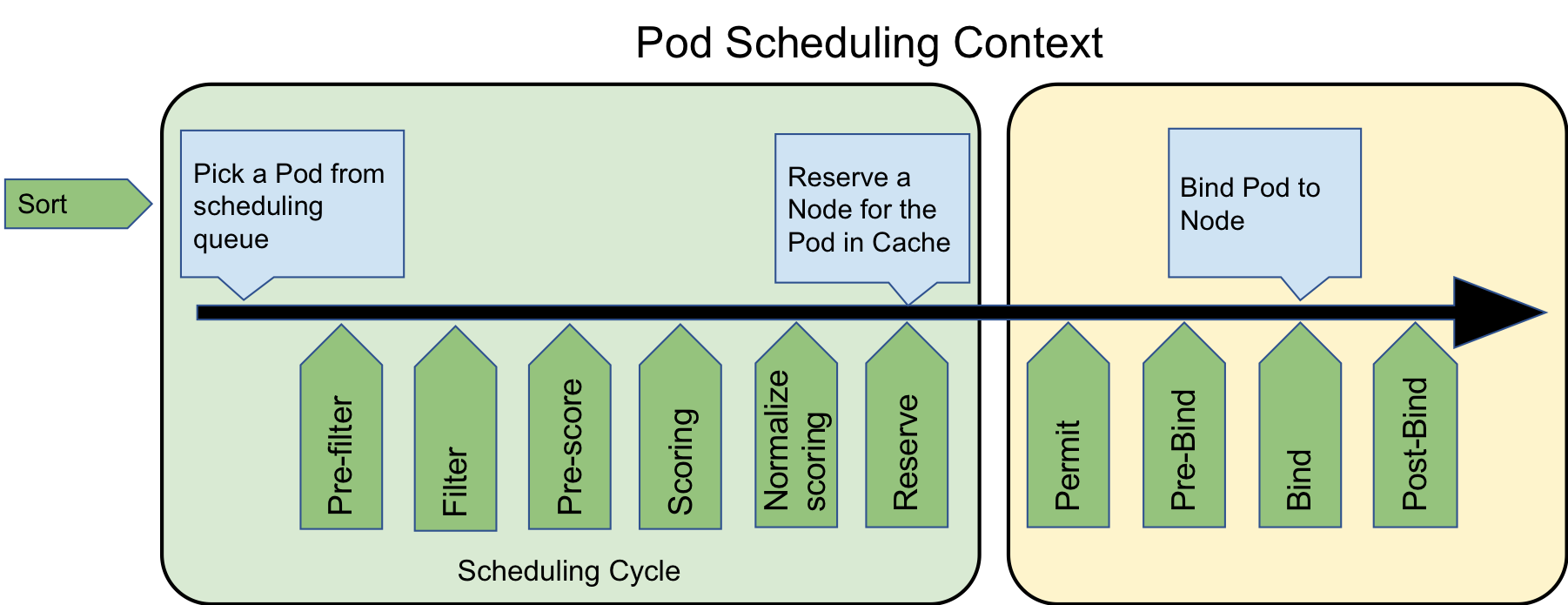
Scheduling Frameworkscheduling cycle
- QueueSort, These plugins are used to sort pods in the scheduling queue. A queue sort plugin essentially will provide a “less(pod1, pod2)” function. Only one queue sort plugin may be enabled at a time.
- PreFilter, PreFilter 类似于调度流程启动之前的预处理,可以对 Pod 的信息进行加工。同时 PreFilter 也可以进行一些预置条件的检查,去检查一些集群维度的条件,判断否满足 pod 的要求。
- Filter, 是 scheduler v1 版本中的 Predicate 的逻辑,用来过滤掉不满足 Pod 调度要求的节点
- PostFilter, 主要是用于处理当 Pod 在 Filter 阶段失败后的操作,例如抢占,Autoscale 触发等行为。
- PreScore, 主要用于在 Score 之前进行一些信息生成。此处会获取到通过 Filter 阶段的节点列表,我们也可以在此处进行一些信息预处理或者生成一些日志或者监控信息。
-
Scoring, 是 scheduler v1 版本中 Priority 的逻辑,目的是为了基于 Filter 过滤后的剩余节点,根据 Scoring 扩展点定义的策略挑选出最优的节点。分为两个阶段:
- 打分:打分阶段会对 Filter 后的节点进行打分,scheduler 会调用所配置的打分策略
- 归一化: 对打分之后的结构在 0-100 之间进行归一化处理
- Reserve, 是 scheduler v1 版本的 assume 的操作,此处会对调度结果进行缓存,如果在后边的阶段发生了错误或者失败的情况,会直接进入 Unreserve 阶段,进行数据回滚。
- Permit, ,当 Pod 在 Reserve 阶段完成资源预留之后,Bind 操作之前,开发者可以定义自己的策略在 Permit 节点进行拦截,根据条件对经过此阶段的 Pod 进行 allow、reject 和 wait 的 3 种操作。
binding cycle, 需要调用 apiserver 的接口,耗时较长,为了提高调度的效率,需要异步执行,所以此阶段线程不安全。
- Bind, 是 scheduler v1 版本中的 Bind 操作,会调用 apiserver 提供的接口,将 pod 绑定到对应的节点上。
- PreBind 和 PostBind, 在 PreBind 和 PostBind 分别在 Bind 操作前后执行,这两个阶段可以进行一些数据信息的获取和更新。
- UnReserve, 用于清理到 Reserve 阶段的的缓存,回滚到初始的状态。当前版本 UnReserve 与 Reserve 是分开定义的,未来会将 UnReserve 与 Reserve 统一到一起,即要求开发者在实现 Reserve 同时需要定义 UnReserve,保证数据能够有效的清理,避免留下脏数据。
插件规范定义在 $GOPATH/src/k8s.io/kubernetes/pkg/scheduler/framework/v1alpha1/interface.go 中,各类插件继承 Plugin
type Plugin interface {
Name() string
}
type PreFilterPlugin interface {
Plugin
// PreFilter is called at the beginning of the scheduling cycle. All PreFilter plugins must return success or the pod will be rejected.
PreFilter(ctx context.Context, state *CycleState, p *v1.Pod) *Status
// PreFilterExtensions returns a PreFilterExtensions interface if the plugin implements one,or nil if it does not. A Pre-filter plugin can provide extensions to incrementally modify its pre-processed info. The framework guarantees that the extensions
// AddPod/RemovePod will only be called after PreFilter, possibly on a cloned CycleState, and may call those functions more than once before calling Filter again on a specific node.
PreFilterExtensions() PreFilterExtensions
}
Kubernetes scheduling frameworkKubernetes 负责 Kube-scheduler 的小组 sig-scheduling 为了更好的管理调度相关的 Plugin,新建了项目 scheduler-plugins 来方便用户管理不同的插件。
github.com/kubernetes-sigs/scheduler-plugins
/pkg
/qos
/queue_sort.go // 插件实现
k8s.io/kubernetes
/cmd
/kube-scheduler
/scheduler.go // 插件注册
以其中的 Qos 的插件来为例,Qos 的插件主要基于 Pod 的 QoS(Quality of Service) class 来实现的,目的是为了实现调度过程中如果 Pod 的优先级相同时,根据 Pod 的 Qos 来决定调度顺序。 注册逻辑如下
// scheduler.go
func main() {
rand.Seed(time.Now().UnixNano())
command := app.NewSchedulerCommand(
app.WithPlugin(qos.Name, qos.New), // 这一行为新增的注册代码
)
pflag.CommandLine.SetNormalizeFunc(cliflag.WordSepNormalizeFunc)
logs.InitLogs()
defer logs.FlushLogs()
if err := command.Execute(); err != nil {
os.Exit(1)
}
}
代码分析
How does the Kubernetes scheduler work?
sched, err := scheduler.New(cc.Client,
cc.InformerFactory,
cc.PodInformer,
recorderFactory,
ctx.Done(),
scheduler.WithProfiles(cc.ComponentConfig.Profiles...),
scheduler.WithAlgorithmSource(cc.ComponentConfig.AlgorithmSource),
scheduler.WithPreemptionDisabled(cc.ComponentConfig.DisablePreemption),
scheduler.WithPercentageOfNodesToScore(cc.ComponentConfig.PercentageOfNodesToScore),
scheduler.WithBindTimeoutSeconds(cc.ComponentConfig.BindTimeoutSeconds),
scheduler.WithFrameworkOutOfTreeRegistry(outOfTreeRegistry),
scheduler.WithPodMaxBackoffSeconds(cc.ComponentConfig.PodMaxBackoffSeconds),
scheduler.WithPodInitialBackoffSeconds(cc.ComponentConfig.PodInitialBackoffSeconds),
scheduler.WithExtenders(cc.ComponentConfig.Extenders...),
)
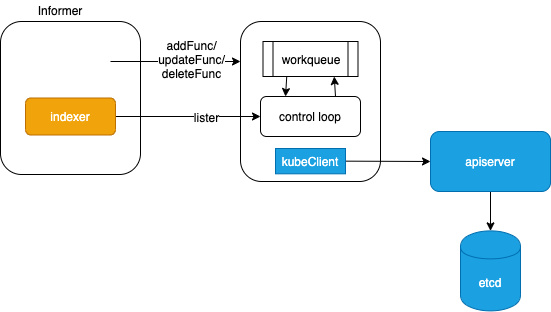
在创建Scheduler的New函数里面,做了以下几件事情:
- 创建SchedulerCache,这里面有podStates保存Pod的状态,有nodes保存节点的状态,整个调度任务是完成两者的匹配。
- 创建volumeBinder,因为调度很大程度上和Volume是相关的,有可能因为要求某个Pod需要满足一定大小或者条件的Volume,而这些Volume只能在某些节点上才能被挂载。
- 创建调度队列,将来尚未调度的Pod都会放在这个队列里面
- 创建调度算法,将来这个对象的Schedule函数会被调用进行调度
- 创建调度器,组合上面所有的对象
- addAllEventHandlers,添加事件处理器。如果Pod已经调度过,发生变化则更新Cache,如果Node发生变化更新Cache,如果Pod没有调度过,则放入队列中等待调度,PV和PVC发生变化也会做相应的处理。
创建了Scheduler之后,接下来是调用Scheduler的Run函数,运行scheduleOne进行调度。
- 从队列中获取下一个要调度的Pod
- 根据调度算法,选择出合适的Node,放在scheduleResult中
- 在本地缓存中,先绑定Volume,真正的绑定要调用API Server将绑定信息放在ETCD里面,但是因为调度器不能等写入ETCD后再调度下一个,这样太慢了,因而在本地缓存中绑定后,同一个Volume,其他的Pod调度的时候就不会使用了。
- 在本地缓存中,绑定Node,原因类似
- 通过API Server的客户端做真正的绑定,是异步操作
runCommand(cmd, opts, registryOptions...)
Setup
Run
sched.Run(ctx)
wait.UntilWithContext(ctx, sched.scheduleOne, 0)
podInfo := sched.NextPod()
fwk, err := sched.frameworkForPod(pod)
scheduleResult, err := sched.Algorithm.Schedule(schedulingCycleCtx, fwk, state, pod)
feasibleNodes, diagnosis, err := g.findNodesThatFitPod(ctx, fwk, state, pod)
fwk.RunPreFilterPlugins(ctx, state, pod)
...
priorityList, err := g.prioritizeNodes(ctx, fwk, state, pod, feasibleNodes)
host, err := g.selectHost(priorityList)
fwk.RunReservePluginsReserve
fwk.RunPermitPlugins
go func() {
fwk.RunPreBindPlugins
sched.bind
fwk.RunPostBindPlugins
}()
接下来我们来看调度算法的Schedule函数,Schedule算法做了以下的事情:
- findNodesThatFitPod:根据所有预选算法过滤符合的node列表
- prioritizeNodes: 对符合的节点进行优选评分,一个排序的列表
- selectHost:对优选的 node 列表选择一个最优的节点
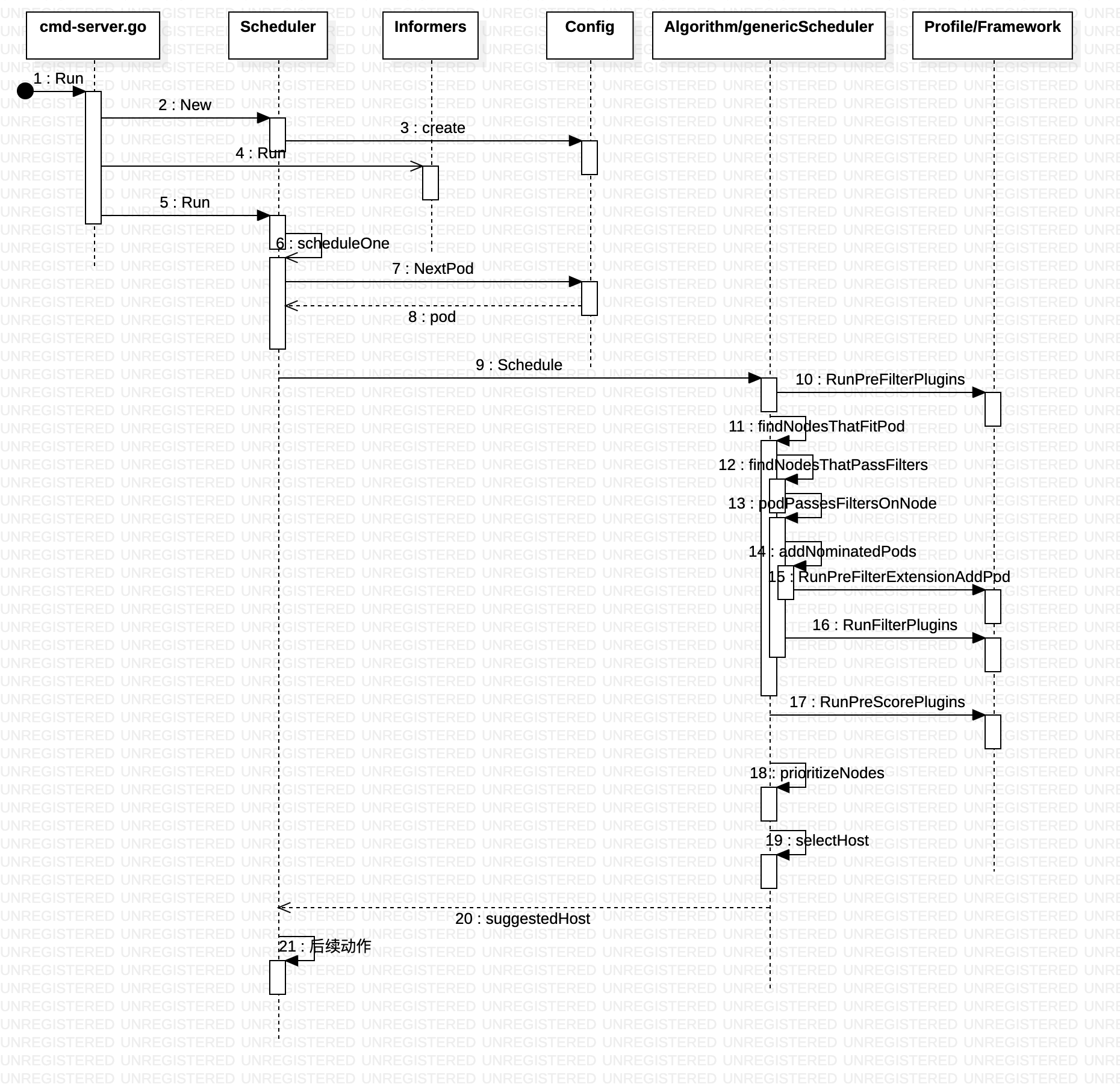
各种插件在哪呢?如何发挥作用呢?
// kubernetes/pkg/scheduler/framework/runtime/framework.go
type frameworkImpl struct {
registry Registry
pluginNameToWeightMap map[string]int
queueSortPlugins []framework.QueueSortPlugin
preFilterPlugins []framework.PreFilterPlugin
filterPlugins []framework.FilterPlugin
postFilterPlugins []framework.PostFilterPlugin
preScorePlugins []framework.PreScorePlugin
scorePlugins []framework.ScorePlugin
reservePlugins []framework.ReservePlugin
preBindPlugins []framework.PreBindPlugin
bindPlugins []framework.BindPlugin
postBindPlugins []framework.PostBindPlugin
permitPlugins []framework.PermitPlugin
extenders []framework.Extender
...
}
// CycleState ,表示调度的上下文,其实是一个 map 的封装,结构体内部通过读写锁实现了并发安全,开发者可以通过 CycleState 来实现多个调度插件直接的数据传递,也就是多个插件可以共享状态或通过此机制进行通信。
func (f *frameworkImpl) RunPreFilterPlugins(ctx context.Context, state *framework.CycleState, pod *v1.Pod) (status *framework.Status) {
startTime := time.Now()
for _, pl := range f.preFilterPlugins {
status = f.runPreFilterPlugin(ctx, pl, state, pod)
if !status.IsSuccess() {
...
}
}
return nil
}