
为什么需要微调
通俗解读大模型微调(Fine Tuning)Prompt Engineering的方式是一种相对来说容易上手的使用大模型的方式,但是它的缺点也非常明显。
- 因为通常大模型的实现原理,都会对输入序列的长度有限制,Prompt Engineering 的方式会把Prompt搞得很长。越长的Prompt,大模型的推理成本越高,因为推理成本是跟Prompt长度的平方正向相关的。
- Prompt太长会因超过限制而被截断,进而导致大模型的输出质量打折口,这也是一个非常严重的问题。可能会胡乱地给你一些东西,它更适合一些泛化的任务。而fine-tuning则不一样,只要你的微调训练数据是高质量的,它可以很稳定地在你自己的数据集或任务上进行稳定的输出。
- Prompt Engineering的效果达不到要求时,企业又有比较好的自有数据,能够通过自有数据,更好的提升大模型在特定领域的能力。这时候微调就非常适用,微调可以使你为LLM提供比prompt多得多的数据,你的模型可以从该数据中进行学习,而不仅仅是访问该数据。
- 要在个性化的服务中使用大模型的能力,这时候针对每个用户的数据,训练一个轻量级的微调模型,就是一个不错的方案。
- 数据安全的问题。如果数据是不能传递给第三方大模型服务的,那么搭建自己的大模型就非常必要。通常这些开源的大模型都是需要用自有数据进行微调,才能够满足业务的需求,这时候也需要对大模型进行微调。
外挂知识库也不是全能的
- 向量化的匹配能力是有上限的,搜索引擎实现语义搜索已经是好几年的事情了,为什么一直无法上线,自然有他的匹配精确度瓶颈问题,只是很多以前没有接触过AI 的朋友对之不熟悉罢了。
- 在引入外部知识这个事情上,如果是特别专业领域,纯粹依赖向量、NLP、策略/规则在某些场景仍然不奏效。对于某个具体业务而言,不要管是不是90%会被解决,只有需要被解决或不需要被解决。
- 微调的优势在于能够使LLM的行为适应特定的细微差别、语气或术语。如果我们希望模型听起来更像医学专业人士、或者使用特定行业的术语,那么对特定领域的数据进行微调可以让我们实现这些定制。
- 有多少标记的训练数据可用?微调LLM以适应特定任务或领域在很大程度上取决于可用标记数据的质量和数量。丰富的数据集可以帮助模型深入理解特定领域的细微差别、复杂性和独特模式,从而使其能够生成更准确且与上下文相关的响应。然而,如果我们使用有限的数据集,微调带来的改进可能微乎其微。从本质上讲,如果我们拥有大量的标记数据来捕获该领域的复杂性,那么微调可以提供更加定制和完善的模型行为。但在此类数据有限的情况下,RAG 系统提供了一个强大的替代方案,确保应用程序通过其检索功能保持数据知情和上下文感知。
- 抑制幻觉有多重要?
- 数据的静态/动态程度如何?在特定数据集上微调 LLM 意味着模型的知识成为训练时该数据的静态快照。如果数据频繁更新、更改或扩展,模型很快就会过时。相比之下,RAG 系统在动态数据环境中具有固有的优势。他们的检索机制不断查询外部来源,确保他们提取用于生成响应的信息是最新的。
整体思路
在大模型相关原理的指导下,AI 模型的构建也逐渐演化出了不同的阶段和流程:预训练、继续预训练、对齐(SFT、RLHF)。预训练模型(Base 模型)始终是智能的基础,而Alignment的主要目标是实现有效的人机接口。此外,由于RLHF的高成本和相对复杂性,SFT作为其廉价替代品已经获得了广泛的应用。
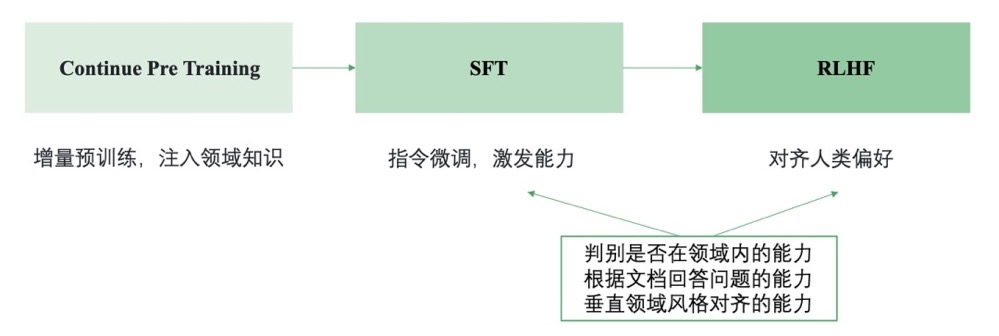
垂直大模型基本套路
- Continue PreTraining: 一般垂直大模型是基于通用大模型进行二次的开发。为了给模型注入领域知识,就需要用领域内的语料进行继续的预训练。
- SFT: 通过SFT可以激发大模型理解领域内各种问题并进行回答的能力(在有召回知识的基础上)
- RLHF: 通过RLHF可以让大模型的回答对齐人们的偏好,比如行文的风格。 需要注意的是一般垂直领域大模型不会直接让模型生成答案,而是跟先检索相关的知识,然后基于召回的知识进行回答,这种方式能减少模型的幻觉,保证答案的时效性,还能快速干预模型对特定问题的答案。
SFT和RLHF阶段(微调也会有RLHF)主要要培养模型的三个能力:
- 领域内问题的判别能力,对领域外的问题需要能拒识
- 基于召回的知识回答问题的能力
- 领域内风格对齐的能力,例如什么问题要简短回答什么问题要翔实回答,以及措辞风格要与领域内的专业人士对齐。
继续预训练
- 混合数据,如果想要领域的模型还具备一定的通用能力,即通用的能力不会退化(或者灾难性遗忘)这就需要在语言模型训练的时候混杂通用的数据。
- 要不要从零训。回顾人对知识的理解:小学中学都在学习通用领域的知识,然后大学阶段继续进一步学习特定领域的知识。所以在通用模型的基础上继续二次预训练注入领域知识是合理的。但是如果想通过二次预训练进行语言层面的迁移就会比较难,没有从零开始训练好。回顾人对语言的学习,如果刚“出生”时候就在学习一门语言,进行听说读写的训练,这就是母语了。会比长大以后再去学习一门外语要容易的多,效果也要好很多。所以基于llama做的中文适配 不如 纯中文训练的baichuan 在中文任务上效果好。
领域微调
领域微调的核心是构建高质量大规模的领域微调数据。让人去收集一个领域内的语料是容易的,但是让人去编写领域内的微调指令和回答是很难的。下面介绍的方法都是来尝试解决这个问题。这些方法的核心都是基于一些已有的数据+GPT4,然后生成领域内的微调数据。
| 数据生成方法 | 已有数据 | 生成数据 |
|---|---|---|
| Self-Instruct | 一些单轮/多轮种子数据 | 单轮/多轮指令微调数据 |
| Self-QA | 文档数据 | 单轮指令微调数据 |
| Self-KG | 知识图谱 | 单轮指令微调数据 |
Self-Instruct是一种微调数据扩充的方法。如果已经一些种子微调数据(大约100条),可以通过Self-Instruct+GPT4进行扩充,生成更多相对符合要求的微调数据。一条微调数据包括三个部分:指令,输入 和 输出。下面具体介绍如何生成这三个部分。
- 首先从种子指令(人工编写的指令/业务侧积累的问题)中随机选择一些指令,然后让GPT4参考这些指令,生成一系列类似的指令。
- 有了指令后,再让GPT4判断这个指令是一个“分类”问题还是一个“生成”问题。后面会采用不同的答案生成策略。
- 如果一个问题是“分类”问题,则采用“output-first”的生成方式,即首先生成输出(具体哪个类别),然后再根据指令和输出,生成输入。例如指令是:”判断下面句子的情感是消极还是积极”,首先生成输出的类别:“积极”,然后再根据指令和类别生成输入的句子:“我今天很开心”。
- 如果一个问题是“生成”问题,则采用“input-first”的生成方式,即首先生成输入,然后再根据指令和输入,生成输出。例如指令是:“将下面的句子翻译成英文”,首先生成输入的句子:“我今天很开心”,然后再根据指令和输入生成输出的答案:“I am happy today”。如果一个指令不需要输入的句子,则输入为空。例如指令:“有哪些减肥的运动?”
- 经过上面的步骤就能初步获得一批微调数据,还需要进行进一步的过滤。例如过滤与已有数据相似度很高的结果,过滤明显低质的结果(指令过长或者过短)。过滤后的微调数据就可以继续加入“种子指令”中,以此循环,源源不断地进行生成。
如果连基础的种子指令数据都没有,那就不适于Self-Instruct的方法了。这时候可以尝试Self—QA的方法,直接从文档中生成指令数据。整体的流程如下:
- 基本的思想是:首先根据无结构的文档通过GPT4生成可能的指令,然后输入指令和对应的文档再让GPT4生成问题的答案。这里的文档可以直接就是文档语料,也可以从结构的表格数据或者图谱数据中生成无结构的文档数据。
- 基于设计的Prompt就可以让GPT4分别进行指令和答案的生成,由此构成指令微调数据。这些数据还需要进一步通过启发式和规则的方法进行过滤,来提高数据的质量。
如果一个领域已经有了高质量的知识图谱,也可以直接基于知识图谱生成指令数据。这种基于知识的指令数据生成方法是HuaTuo提出的,称为Self—KG。
如何对大模型进行微调
- 对全量的参数,进行全量的训练,这条路径叫全量微调FFT(Full Fine Tuning)。但FFT也会带来一些问题,影响比较大的问题,主要有以下两个:一个是训练的成本会比较高,因为微调的参数量跟预训练的是一样的多的;一个是叫灾难性遗忘(Catastrophic Forgetting),用特定训练数据去微调可能会把这个领域的表现变好,但也可能会把原来表现好的别的领域的能力变差。
- 只对部分的参数进行训练,这条路径叫PEFT(Parameter-Efficient Fine Tuning)。有以下几条技术路线:
- 一个是监督式微调SFT(Supervised Fine Tuning) ,这个方案主要是用人工标注的数据,用传统机器学习中监督学习的方法,对大模型进行微调;
- 一个是基于人类反馈的强化学习微调RLHF(Reinforcement Learning with Human Feedback) ,这个方案的主要特点是把人类的反馈,通过强化学习的方式,引入到对大模型的微调中去,让大模型生成的结果,更加符合人类的一些期望;
- 还有一个是基于AI反馈的强化学习微调RLAIF(Reinforcement Learning with AI Feedback) ,这个原理大致跟RLHF类似,但是反馈的来源是AI。这里是想解决反馈系统的效率问题,因为收集人类反馈,相对来说成本会比较高、效率比较低。
一些比较流行的PEFT方案
- Prompt Tuning,Prompt Tuning的出发点,是基座模型(Foundation Model)的参数不变,为每个特定任务,训练一个少量参数的小模型,在具体执行特定任务的时候按需调用。Prompt Tuning的基本原理是在输入序列X之前,增加一些特定长度的特殊Token,以增大生成期望序列的概率。具体来说,就是将$X = [x1, x2, …, xm]变成,X
= [x1, x2, ..., xk; x1, x2, …, xm], Y = WX`$。如果将大模型比做一个函数:Y=f(X),那么Prompt Tuning就是在保证函数本身不变的前提下,在X前面加上了一些特定的内容,而这些内容可以影响X生成期望中Y的概率。 - Prefix Tuning,Prefix Tuning的出发点,跟Prompt Tuning的是类似的,只不过它们的具体实现上有一些差异。Prompt Tuning是在Embedding环节,往输入序列X前面加特定的Token。而Prefix Tuning是在Transformer的Encoder和Decoder的网络中都加了一些特定的前缀。具体来说,就是将Y=WX中的W,变成$W
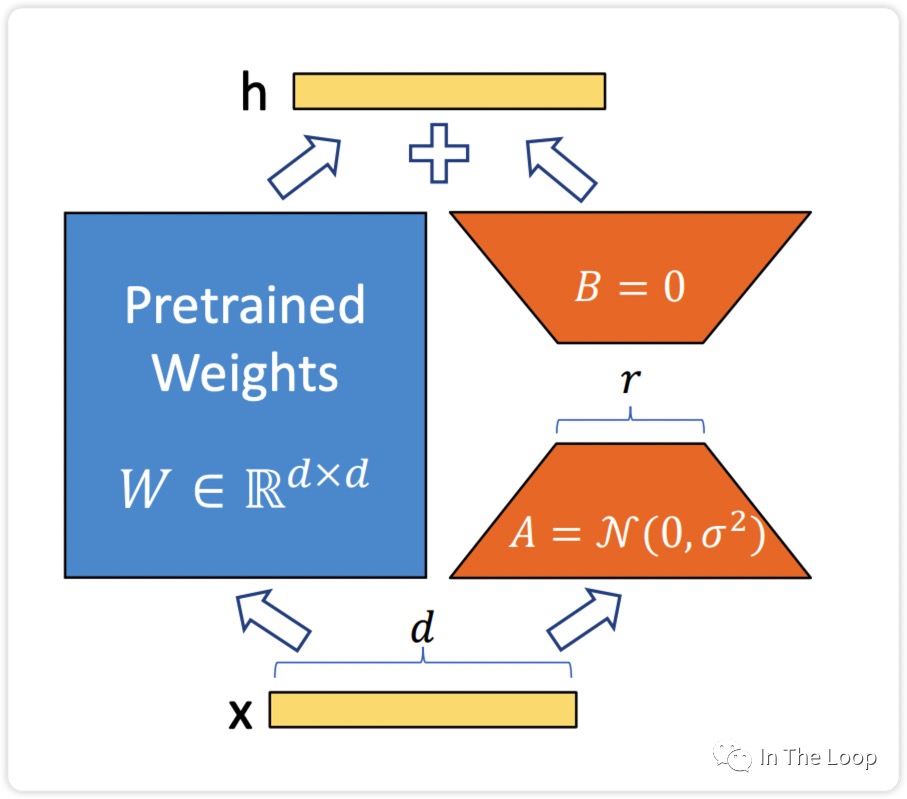
= [Wp; W],Y=WX$。Prefix Tuning也保证了基座模型本身是没有变的,只是在推理的过程中,按需要在W前面拼接一些参数。 - LoRA,LoRA背后有一个假设:我们现在看到的这些大语言模型,它们都是被过度参数化的。而过度参数化的大模型背后,都有一个低维的本质模型。通俗讲人话:大模型参数很多,但并不是所有的参数都是发挥同样作用的;大模型中有其中一部分参数,是非常重要的,是影响大模型生成结果的关键参数,这部分关键参数就是上面提到的低维的本质模型。LoRA的基本思路,在原始预训练模型旁边增加一个旁路,先用一个 Linear 层 A,将数据从 d 维降到 r 维,在用第二个 Linear 层 B,将数据从 r 维变回 d 维。LoRA 训练的时候固定预训练模型的参数,只训练降维矩阵 A 和升维矩阵 B。
- QLoRA,QLoRA就是量化版的LoRA(Quantize+LoRA),量化,是一种在保证模型效果基本不降低的前提下,通过降低参数的精度,来减少模型对于计算资源的需求的方法。量化的核心目标是降成本,降训练成本,特别是降后期的推理成本。
使用 DPO 微调 Llama 2 没看懂。
难点:
- 计算量太大
- 不好评估,因为大模型生成的海量内容暂无标准的答案,所以我们无法全部依赖人工去评判内容的质量。让模型做选择题不能准确的评估性能,一些垂类领域也很难搞到相关测试集,如果用GPT4评估又涉及到数据隐私问题,GPT4更倾向于给句子长的、回答更多样性的答案更高的分数,有时候也是不准的。
- 微调数据量到底要多少?
- LoRA VS 全量参数微调?微调基础模型LoRA还是比全量微调差一些的,微调对话模型差距不大,个人任务有时候全量微调是不如LoRA的,全量微调灾难遗忘现象会更加严重
微调算法
假如LLM的原始权重视为矩阵“X”。对于任何给定的任务,经过优化微调的 LLM 的权重由矩阵“Y”表示。微调的目标是发现一个 delta 矩阵“Z”,使得 X+Z=Y。然而,在 LoRA 的情况下,这个增量矩阵“Z”是通过低秩分解来近似的。因此,对于某些类型的任务来说, 一些数据集可能更容易对齐,而另一些数据集可能会有效果损失。相比之下,全参数微调则没有这个约束, 学习到的权重保留了原始模型的表达能力,可能简化了拟合不同数据的任务。
对于大语音模型来说,其参数量非常多。GPT3有1750亿参数,而且LLAMA系列模型包括 7B,13B,33B,65B,而其中最小的7B都有70亿参数。要让这些模型去适应特定的业务场景,需要对他们进行微调。如果直接对这些模型进行微调,由于参数量巨大,需要的GPU成本就会非常高。LoRA的做法是对这些预训练好的大模型参数进行冻结,也就是在微调训练的时候,这些模型的参数设置为不可训练。然后往模型中加入额外的网络层,并只训练这些新增的网络层参数。这样可训练的参数就会变的非常少,可以以低成本的GPU微调大语言模型。LoRA在Transformer架构的每一层注入可训练的秩分解矩阵,与使用Adam微调的GPT-3 175B相比,LoRA可以将可训练参数数量减少10000倍,GPU内存需求减少3倍,并且在效果上相比于传统微调技术表现的相当或更好。当前已经得到HuggingFace 的 PEFT库 https://github.com/huggingface/peft 的支持。
PEFT/LoRA原理
LoRA,LoRA背后有一个假设:我们现在看到的这些大语言模型,它们都是被过度参数化的。而过度参数化的大模型背后,都有一个低维的本质模型。通俗讲人话:大模型参数很多,但并不是所有的参数都是发挥同样作用的;大模型中有其中一部分参数,是非常重要的,是影响大模型生成结果的关键参数,这部分关键参数就是上面提到的低维的本质模型。LoRA的基本思路,在原始预训练模型旁边增加一个旁路,先用一个 Linear 层 A,将数据从 d 维降到 r 维,在用第二个 Linear 层 B,将数据从 r 维变回 d 维。LoRA 训练的时候固定预训练模型的参数,只训练降维矩阵 A 和升维矩阵 B。包括以下几步:
- 要适配特定的下游任务,要训练一个特定的模型,将Y=WX变成$Y=(W+∆W)X$,这里面$∆W$主是我们要微调得到的结果;
- 将∆W进行低维分解
∆W=AB(∆W为m * n维,A为m * r维,B为r * n维,r就是上述假设中的低维); - 接下来,用特定的训练数据,训练出A和B即可得到∆W,在推理的过程中直接将∆W加到W上去,再没有额外的成本。另外,如果要用LoRA适配不同的场景,切换也非常方便,做简单的矩阵加法即可:$(W + ∆W) - ∆W + ∆W`$。
深入浅出剖析 LoRA 技术原理 未细读。
HuggingFace Peft 实现
许多朋友在使用LoRA的过程中,都会用到HuggingFace Peft,使得预训练语言模型能够高效地适应各种下游应用,无需微调模型的所有参数。与 Accelerate 无缝集成,支持利用 DeepSpeed 和 Big Model Inference 来处理大规模模型。支持的方法:LoRA、Prefix Tuning、P-Tuning、Prompt Tuning、AdaLoRA等。
# 导入必要的库和函数
from transformers import AutoModelForSeq2SeqLM # 用于加载和处理序列到序列的语言模型
from peft import get_peft_config, get_peft_model, LoraConfig, TaskType # 导入PEFT相关的配置和功能
# 指定模型和分词器的路径或名称
model_name_or_path = "bigscience/mt0-large" # 指定预训练模型的名称或路径
tokenizer_name_or_path = "bigscience/mt0-large" # 指定分词器的名称或路径
# 配置PEFT的参数
peft_config = LoraConfig(
task_type=TaskType.SEQ_2_SEQ_LM, # 指定任务类型为序列到序列的语言模型
inference_mode=False, # 设置是否为推理模式
r=8, # 设置LoRA的rank
lora_alpha=32, # LoRA的alpha值,决定参数增加的数量
lora_dropout=0.1 # LoRA层的dropout比例
)
# 加载预训练的序列到序列语言模型
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
# 应用PEFT方法调整模型
model = get_peft_model(model, peft_config)
HuggingFace Peft库封装好的LoRA接口,这个接口是对微软版LoRA代码的改写和封装,目的是减少大家在使用LoRA过程中的手工活(例如徒手更改模型架构,为模型添加LoRA adapter结构等),除此外核心处理逻辑不变。
LoRAAs with other methods supported by PEFT, to fine-tune a model using LoRA, you need to:
- Instantiate a base model.
- Create a configuration (LoraConfig) where you define LoRA-specific parameters.
- Wrap the base model with get_peft_model() to get a trainable PeftModel.
- Train the PeftModel as you normally would train the base model.
from peft import LoraConfig, get_peft_model
# # 创建基础transformer模型
model = xx.from_pretrained(args.model_dir)
config = LoraConfig(r=args.lora_r,lora_alpha=32,...)
model = get_peft_model(model, config) # 初始化Lora模型
model = model.half().cuda()
# 设置DeepSpeed配置参数,并进行DeepSpeed初始化
conf = {"train_micro_batch_size_per_gpu": args.train_batch_size,...)
model_engine, optimizer, _, _ = deepspeed.initialize(config=conf,model=model,model_parameters=model.parameters())
model_engine.train()
train_dataset = Seq2SeqDataSet(args.train_path, tokenizer,...)
train_dataloader = DataLoader(train_dataset,batch_size=...)
# 开始模型训练
for i_epoch in range(args.num_train_epochs):
train_iter = iter(train_dataloader)
for step, batch in enumerate(train_iter):
# 获取训练结果
input_ids = batch["input_ids"].cuda()
labels = batch["labels"].cuda()
outputs = model_engine.forward(input_ids=input_ids, labels=labels)
loss = outputs[0]
# 损失进行回传
model_engine.backward(loss)
model_engine.step() # 进行参数优化
# 每一轮模型训练结束,进行模型保存
save_dir = os.path.join(args.output_dir, f"global_step-{global_step}")
model_engine.save_pretrained(save_dir)
def get_peft_model(model: PreTrainedModel, peft_config: PeftConfig, adapter_name: str = "default") -> PeftModel:
model_config = getattr(model, "config", {"model_type": "custom"})
peft_config.base_model_name_or_path = model.__dict__.get("name_or_path", None)
if peft_config.task_type not in MODEL_TYPE_TO_PEFT_MODEL_MAPPING.keys() and not peft_config.is_prompt_learning:
return PeftModel(model, peft_config, adapter_name=adapter_name)
if peft_config.is_prompt_learning:
peft_config = _prepare_prompt_learning_config(peft_config, model_config)
return MODEL_TYPE_TO_PEFT_MODEL_MAPPING[peft_config.task_type](model, peft_config, adapter_name=adapter_name)
(微软的)LoraModel是LoRA模块的核心类,冻结base model的参数,旁路低秩矩阵的创建,替换,合并等逻辑都在这个类中。
# LoraModel也是继承torch.nn.Module,相当于pytorch的一个网络模块
class LoraModel(torch.nn.Module):
def __init__(self, model, config, adapter_name) -> None:
super().__init__()
self.model = model # # model 被用来微调的基础大模型
self.forward = self.model.forward # LoraModel把自己的前向传播函数forword设置为大模型的forward方法
self.peft_config = config
self.add_adapter(adapter_name,self.peft_config[adapter_name])
def _find_and_replace(self,adapter_name):
# 使用新的LoraLayer替换target_modules中配置的Layer,实现添加旁路低秩矩阵的功能。
...
def mark_only_lora_as_trainable(model: nn.Module, bias:str="none") -> None:
for n,p in model.named_parameters():
if "lora_" not in n:
p.requires_grad = False # 除了新增的LoraLayer的模块外,其他所有参数都被冻结。
...
def forward(self, x:torch.Tensor):
...
result = F.linear(x,...,bias=self.bias) # 使用大模型target_module中线性层进行计算,得出结果result。
result += ( # 使用lora_A与lora_B的低秩矩阵进行计算并把计算结果加到result上。
self.lora_B[self.active_adapter](
self.lora_A[self.active_adapter](self.lora_dropout[self.active_adapter](x))
)
* self.scaling(self.active_adapter)
)
可以看到
- Freeze 预训练模型权重/参数的本质:requires_grad = False ,不接受梯度更新,只微调参数A和B。,此时该步骤模型微调的参数量由$d×k$变成$d×r+r×k$,而$r≪min(d,k)$,因此微调参数量大量减少了。
图解大模型微调系列之:大模型低秩适配器LoRA(源码解读与实操篇) 未读。
P-Tuning 系列/可学习的提示
prompt tuning, prefix tuning 和p-tuning v1 有一定的联系,这几种方法都是基于优化continuous prompt,之前的工作都是手动设计模板或者自动生成模板,统称discrete prompt。discrete prompt有一定的局限性,找出的结果可能不是最优,而且对token的变动十分敏感,所以之后的研究方向也都是连续空间内的prompt。
P-Tuning,简称PT,是一种针对于大模型的soft-prompt方法,包括两个版本;P-Tuning,仅对大模型的Embedding加入新的参数; P-Tuning-V2,将大模型的Embedding和每一层前都加上新的参数,这个也叫深度prompt。
很多任务我们只需要在输入端输入合适的prompt,大语言模型就能给出一个比较合理的结果。但对于人工设计的prompt,prompt的变化对模型最终的性能特别敏感,加一个词、少一个词或者变动位置都会造成比较大的变化。那干脆让大模型学习一个合理的prompt,然后直接输入到模型中,这样是不是就可以直接得到一个比较合理的结果了?放弃之前人工或半自动离散空间的hard prompt设计,采用连续可微空间soft prompt设计,通过端到端优化学习不同任务对应的prompt参数。
Prefix Tuning(面向文本生成领域(NLG)) 方法在输入 token 之前构造一段任务相关的 virtual tokens 作为 Prefix,然后训练的时候只更新 Prefix 部分的参数,而 PLM 中的其他部分参数固定。
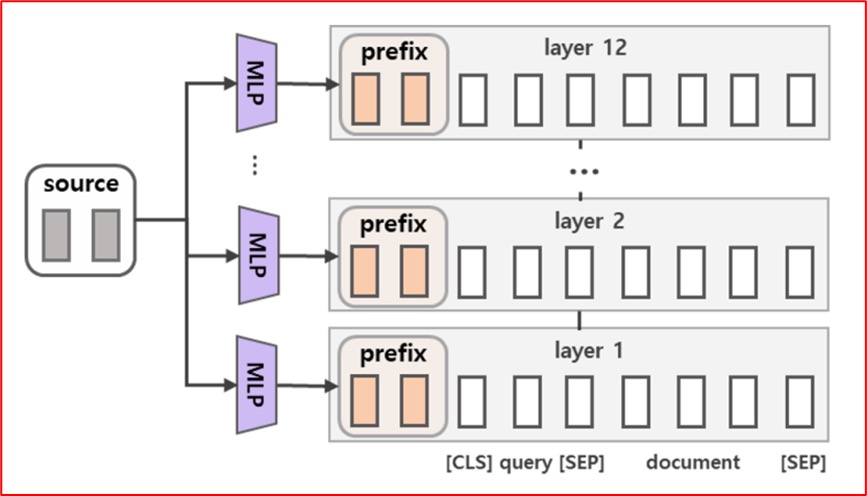
Prompt Tuning 可以看作是 Prefix Tuning 的简化版本,它给每个任务定义了自己的Prompt,然后拼接到数据上作为输入,但只在输入层加入prompt tokens(在输入embedding层加入一段定长的可训练的向量,在微调的时候只更新这一段prompt的参数),另外,virtual token的位置也不一定是前缀,插入的位置是可选的。 但也有一些缺点 PS: Prompt Tuning 和 P Tuning 分不清了。
- 针对模型参数量缺少通用性,之前的试验证明了p-tuning针对参数量大于10B的模型有很好的效果,甚至可以达到全量微调的效果。但是针对中等规模的模型,效果就不是很明显了。
- 针对不同任务的通用性也比较差,之前的实验结果证明了在一些NLU任务上效果比较好,对序列标注类比较难的任务效果较差。
- prompt只加在了embedding层,这样做就让prompt比较难训练,同时也导致了可训练参数比较少。
基于此,作者提出了P-tuning v2
- 在每一层都加入了Prompts tokens作为输入,而不是仅仅加在输入层,可学习的参数更多(从P-tuning和Prompt Tuning的0.01%增加到0.1%-3%),prompts与更深层相连,对模型输出产生更多的直接影响。
除Prefix Tuning用于NLG任务外,Prompt Tuning、P-Tuning、P-Tuning V2 均用于NLU,P-Tuning和Prompt Tuning技术本质等同,Prefix Tuning和P-Tuning V2技术本质等同。
对于领域化的数据定制处理,P-Tune(Parameter Tuning)更加合适。领域化的数据通常包含一些特定的领域术语、词汇、句法结构等,与通用领域数据不同。对于这种情况,微调模型的参数能够更好地适应新的数据分布,从而提高模型的性能。相比之下,LORA(Layer-wise Relevance Propagation)更注重对模型内部的特征权重进行解释和理解,通过分析模型对输入特征的响应来解释模型预测的结果。虽然LORA也可以应用于领域化的数据定制处理,但它更适合于解释模型和特征选择等任务,而不是针对特定领域的模型微调。
未细读
NEFT:新的指令微调技术大幅提升大模型性能(LLaMA系增加NEFT性能提升约10%)
代码
手写
- 加载数据集,pytorch Dataset/DataLoader
- 构建模型,在实际操作中,除了使用预训练模型编码文本外,我们通常还会进行许多自定义操作,因此在大部分情况下我们都需要自己编写模型,不过不用从0写,更为常见的写法是继承 Transformers 库中的预训练模型来创建自己的模型。
class BertForPairwiseCLS(BertPreTrainedModel): # 继承 BERT 模型(BertPreTrainedModel 类) def __init__(self, config): super().__init__(config) self.bert = BertModel(config, add_pooling_layer=False) self.dropout = nn.Dropout(config.hidden_dropout_prob) self.classifier = nn.Linear(768, 2) self.post_init() def forward(self, x): bert_output = self.bert(**x) cls_vectors = bert_output.last_hidden_state[:, 0, :] cls_vectors = self.dropout(cls_vectors) logits = self.classifier(cls_vectors) return logits config = AutoConfig.from_pretrained(checkpoint) # 通过预置的 from_pretrained 函数来加载模型参数 model = BertForPairwiseCLS.from_pretrained(checkpoint, config=config).to(device) # 加载 预置模型 print(model) # Transformers 库同样实现了很多的优化器,相比 Pytorch 固定学习率,Transformers 库的优化器会随着训练过程逐步减小学习率(通常会产生更好的效果) optimizer = AdamW(model.parameters(), lr=learning_rate) def train_loop(dataloader, model, loss_fn, optimizer,...): ... def test_loop(dataloader, model, mode='Test'): ... for t in range(epoch_num): total_loss = train_loop(train_dataloader, model, loss_fn, optimizer, lr_scheduler, t+1, total_loss) valid_acc = test_loop(valid_dataloader, model, mode='Valid') if valid_acc > best_acc: best_acc = valid_acc print('saving new weights...\n') torch.save(model.state_dict(), ...) # # 保存模型
使用huggingface的Trainer API进行模型微调
Fine-tuning a model with the Trainer APITransformers provides a Trainer class to help you fine-tune any of the pretrained models it provides on your dataset. Once you’ve done all the data preprocessing work in the last section, you have just a few steps left to define the Trainer. The hardest part is likely to be preparing the environment to run Trainer.train()
from datasets import load_dataset
from transformers import AutoTokenizer, DataCollatorWithPadding
raw_datasets = load_dataset("glue", "mrpc")
checkpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
def tokenize_function(example):
return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
from transformers import TrainingArguments
training_args = TrainingArguments("test-trainer")
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
from transformers import Trainer
trainer = Trainer(
model,
training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
)
# To fine-tune the model on our dataset, we just have to call the train() method of our Trainer
trainer.train()
A full training 手写train loop。
LLaMA-Factory
/src
/llmtuner
/train
/data
/loader.py # get_dataset
/preprocess.py # preprocess_dataset
/model
/loader.py # load_model_and_tokenizer
/dpo
/trainer.py # 一些trainer 用到的函数
/workflow.py # run_dpo
/ppo
/trainer.py # 一些trainer 用到的函数
/workflow.py # run_ppo
/pt
/trainer.py # 一些trainer 用到的函数
/workflow.py # run_pt
/rm
/trainer.py # 一些trainer 用到的函数
/workflow.py # run_rm
/sft
/trainer.py # 一些trainer 用到的函数
/workflow.py # run_sft
workflow.py 的逻辑言简意赅,就是拼凑运行 Trainer的dataset、model、tokenizer、data_collator等参数
- 对于dataset 有一个load_dataset 和preprocess_dataset 的过程,preprocess_dataset 会根据任务目标不同,处理逻辑不同,也就是将数据转为input_ids 的方式不同。 最终转为trainer 也就是transformer model 可以接受的dataset,包含列 input_ids/attention_task/labels(或其它model.forward 可以支持的参数)。
- Trainer 对训练逻辑已经封的很好了,内部也支持了accelerate 和 deepspeed,只要合适的配置 training_args 即可。
以pt对应的workflow.py 为例
def run_pt(model_args: "ModelArguments",data_args: "DataArguments",training_args: "Seq2SeqTrainingArguments",finetuning_args: "FinetuningArguments",callbacks: Optional[List["TrainerCallback"]] = None):
dataset = get_dataset(model_args, data_args)
model, tokenizer = load_model_and_tokenizer(model_args, finetuning_args, training_args.do_train, stage="pt")
dataset = preprocess_dataset(dataset, tokenizer, data_args, training_args, stage="pt")
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
trainer = Trainer(model,training_args,tokenizer,data_collator,callbacks,**split_dataset(dataset, data_args, training_args)
# Training
if training_args.do_train:
train_result = trainer.train(resume_from_checkpoint=training_args.resume_from_checkpoint)
trainer.log_metrics("train", train_result.metrics)
trainer.save_metrics("train", train_result.metrics)
trainer.save_state()
trainer.save_model()
if trainer.is_world_process_zero() and model_args.plot_loss:
plot_loss(training_args.output_dir, keys=["loss", "eval_loss"])
# Evaluation
if training_args.do_eval:
metrics = trainer.evaluate(metric_key_prefix="eval")
perplexity = math.exp(metrics["eval_loss"])
metrics["perplexity"] = perplexity
trainer.log_metrics("eval", metrics)
trainer.save_metrics("eval", metrics)
不管是PreTraining阶段还是SFT阶段,loss函数都是一样的,只是计算的方式存在差异,PreTraining阶段计算的是整段输入文本的loss,而SFT阶段计算的是response部分的loss。
- preprocess_pretrain_dataset处理PreTraining阶段的数据,数据组成形式:
- 输入input:
<bos> X1 X2 X3 - 标签labels:
X1 X2 X3 </s>典型的Decoder架构的数据训练方式;
- 输入input:
- preprocess_supervised_dataset处理SFT阶段的数据,数据组成形式:
- 输入input:
<bos> prompt response - 标签labels:
-100 ... -100 response </s>对于prompt部分的labels被-100所填充,这样在计算loss的时候模型只计算response部分的loss,-100的部分被忽略了。这个机制得益于torch的CrossEntropyLossignore_index参数,ignore_index参数定义为如果labels中包含了指定了需要忽略的类别号(默认是-100),那么在计算loss的时候就不会计算该部分的loss也就对梯度的更新不起作用。
- 输入input:
PS: 深度学习都得指定features/labels。在llm 场景下,features 和labels 有几个特点
- llm 有base model、sft model 等,不同的model 数据集格式不同,一般分为几个部分,比如sft 的
{"question:":"xx","answer":"xx"},各家模型都不太一样,很多数据集是不公开的。但不管如何,这几部分都会拼为一个sentence(中间可能有一些特殊字符起到连接作用),然后把sentence通过tokenizer转换成input_ids,之后再走embedding 模块等等就是Transformer系列模型内的事儿了,最后得到output_ids. - 模型输入格式,模型输入dict 一般包含3个key: input_ids,attention_mask,labels
- 有些模型内置从input ids 提取attention mask的操作
- 预训练场景 labels 一般由input_ids copy而来,然后做一些处理,比如labels 全部左移一位(预训练)
- 明确指定labels 的话,一般是要微调,比如sft时,sentence部分中question 的位置都置为-100,-100表示在计算loss的时候会被忽略,这个由任务性质决定。
- 预处理(将dataset 转为模型输入)过程由 Dataset.map() + tokennizer 来办。
def tokenize_function(example): # example 表示数据集中的一行数据 return tokenizer(example["sentence1"], example["sentence2"], truncation=True) tokenized_dataset = dataset.map(tokenize_function, batched=True) - 之后就是对output_ids 和 labels 计算loss。