
前言(未完成)
大语言模型仅仅赋予了模型接受语言输入的能力,多模态则想给大模型安装上眼睛和耳朵。
语言模型的发展历程与视觉模型有许多相似之处。
- 它们都考虑了生物行为的特点,找到了适合自身的神经网络结构——循环神经网络(RNN)和卷积神经网络(CNN)。
- 它们在模型规模不断扩大的过程中,也都遇到了梯度爆炸和梯度消失的问题,并基于各自模型结构的特点找到了应对方法,分别是 LSTM 和 ResNet。
- 都逐步走出了自己的预训练之路。CV的分层结构(底层网络正在构建基础的“边缘检测能力”、中层的网络则利用这些边缘信息,来组成更高层次目标的局部特征(比如五官信息)、最上层则会出现和我们的目标分类任务最相关的一些实体),非常适合用来做模型的领域微调,只需要使用较少的数据,更新最上层也就是负责分类功能部分的模型参数,就能够获得良好的效果。Transformer的出现让NLP走出自己的预训练模型之路。
Transformer与多模态
- 其实不是“Transformer适合做多模态任务”,而是Transformer中的Attention适合做多模态任务,准确的说,应该是“Transformer中的Dot-product Attention适合做多模态任务”。PS: Transformer提出了深度学习领域既MLP、CNN、RNN后的第4大特征提取器。
- 之前的多模态任务是怎么做的? 在Transformer,特别是Vision Transformer出来打破CV和NLP的模型壁垒之前,CV的主要模型是CNN,NLP的主要模型是RNN,那个时代的多模态任务,主要就是通过CNN拿到图像的特征,RNN拿到文本的特征,然后做各种各样的Attention与concat过分类器。
- 为什么Transformer可以做图像也可以做文本,为什么它适合做一个跨模态的任务?说的直白一点,因为Transformer中的Self-Attetion机制很强大,使得Transformer是一个天然强力的一维长序列特征提取器,而所有模态的信息都可以合在一起变成一维长序列被Transformer处理。当你输入纯句子时,模型能学到这个it主要指animal,那么比如当你输入图片猫+这个句子的时候,模型可能就能学到你前面那张猫指的就是这个animal。
- attention本身就是很强大的,已经热了很多年了,而self-attention更是使得Transformer的大规模pretrain成为可能的重要原因self-attention的序列特征提取功能其实是非常强大的,如果你用CNN,那么一次提取的特征只有一个限定大小的矩阵,如果在句子里做TextCNN,那就是提取一小段文字的特征,最后汇聚到一起;如果做RNN,那么会产生长程依赖问题,当句子 太长最后RNN会把前面的东西都忘掉。self-attention的本质就是对每个token,计算这个token相对于这个句子其他所有token的特征再concat到一起,无视长度,输入有多长,特征就提多远。Transformer也可以认为是一个全连接图, 缓解了序列数据普遍存在的长距离依赖和梯度消失等缺陷 。
- 那么如果传入的不是句子,而是普通一维序列(也就是一个数组)呢?那就是对序列的每个点(数组的每个值),计算这个点与序列里其他点的所有特征,这也是Vision Transformer成功的原因,既然是对序列建模,我就把一张图片做成序列不就完了?一整张图片的像素矩阵直接平铺变成序列复杂度太大,那就切大块一点呗(反正CNN也是这种思想,卷积核获得的是局部特征,换个角度来说也是特定patch的特征),ViT就把一张图片做成了16个patch然后加上对应的position embedding(就是割成小方块变成token向量塞进去加上patch对应图片原始位置的标号)
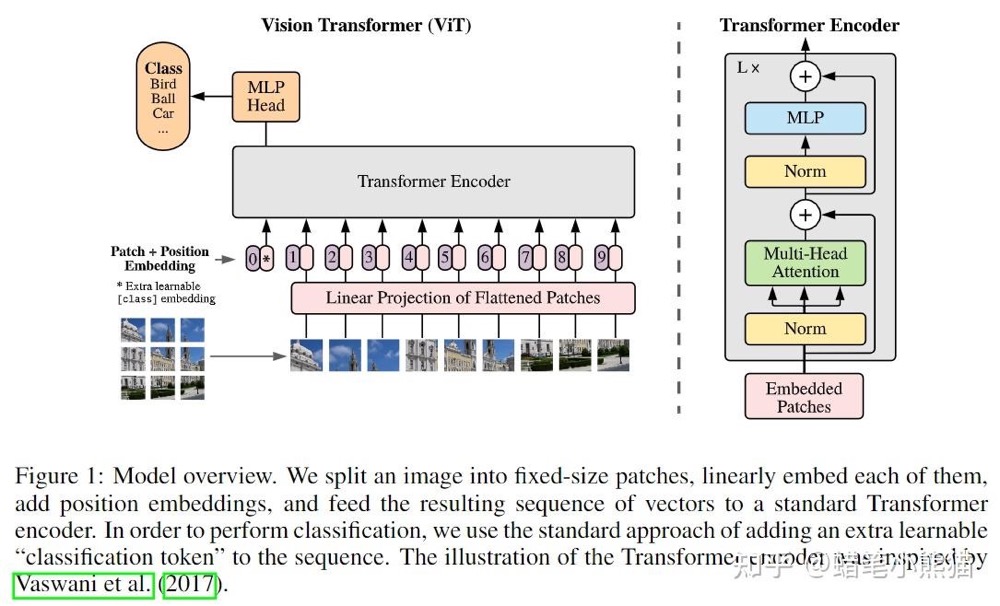
- 所以如果你用Transformer来当backbone的时候,你需要做的就只是把图片,文本,甚至表格信息等其他的所有模态信息全部flatten再concat或者相加成一维数组送进Transformer,然后期待强大的Self-Attention开始work就可以了。
面向统一的AI神经网络架构和预训练方法近几年,自然语言处理(NLP)和图形图像领域(CV)在神经网络架构和预训练上正在经历一个趋向统一的融合趋势。Transformer 的神经网络架构率先在自然语言处理(NLP)领域取得了很好的效果,并成为该领域的主流神经架构。从 2020 年下半年开始,计算机视觉领域也开始将 Transformer 应用到各种视觉问题中,并取代此前的卷积神经网络,成为新的主流神经架构。关于统一的好处,这里列举三点:
- 技术和知识共享:技术和知识共享能让不同领域都有更快的进步,对于 NLP 和 CV 领域来说,深度学习革命的早期主要是 CV 技术在影响 NLP 领域,而最近两年 NLP 领域进展迅速,很多很好的技术被 CV 领域所借鉴。
- 促进多模态应用:技术的统一也在催生全新的多模态研究和应用,例如实现零样本物体识别能力的 CLIP 模型、能给定任意文本生成图片的 DALL-E 模型等等。
- 实现降本增效:我们举芯片的例子,以前设计芯片时需要优化不同的算子,例如卷积、Transformer 等,而现在芯片设计只需要优化 Transformer 就可以解决 90% 以上问题。Nvidia 最新的 H100 GPU 的一个主要宣传点,就是可以将 Transformer 的训练性能提升 6 倍。
谷歌的 ViT 模型就是把图像切块切成不重叠的块,将每个块当作一个 token,于是就可以将 NLP 里的 Transformer 直接应用于图像分类。这种建模相比 CNN 有两个明显的好处:
- 相比 CNN 这种基于静态模板的网络,Transformer 的滤波模板是随位置动态的,可以更高效地建模关系。
- 可以建模长程关系(Long-term relationship),可以建模远距离的 token 之间的关联。
多模态的三条路:
- 用多模态数据端到端预训练的模型:Fuyu-8B,Gemini,LVM
- 使用“胶水层”粘接已经训练好的文本模型和各模态编码/解码器,使用多模态数据训练胶水层(projection layer) GPT-4V, MiniGPT-4/v2, LLaVA
- 使用文本粘接文本模型和多模态识别/生成模型,无需训练,例如语音:whisper语音识别+LLM文本模型+VITS语音合成
文生图
文生图模型发展简史与原理:DALL·E, Imagen, Stable Diffusion 未读。
文生图模型发展简史与原理:DALL·E, Imagen, Stable Diffusion 未读