
前言
钱,算力,数据哪个会成为大模型继续 scale 的瓶颈?总体来说最有可能成为瓶颈的是数据。在特定数据量下即使是无限的参数量都没法打败拥有更多数据量训练出来的有限参数量的模型。因为 retrieval 模式非常有效,所以大家自然会有想法说是不是不需要那么大的模型来记住各种知识点,而只需要一个拥有推理能力的小模型就可以?小模型可以在手机端,机器人设备上直接部署使用,想象空间还是非常大的。
我们的重点不是从头开始训练LLM,而是适应预训练的LLM用于下游任务。
- LangChain 的链式调用方法或者说编程语言 Python 不适合生产环境,真正工业级的应用需要有离线、近线几套系统配合供给,才能让在线系统效果出众、性能稳定。
- 大模型通过提示词中信息的 Embedding 去检索外部记忆片段这种做法并不高明,充其量只是字面匹配的一个变种而已,存在非常明显的缺点。你无法找到主题最相近的文档,因为在一开始,你就把文档的语义切割了,更何况你所能使用的开源向量检索,根本没办法满足工业级的性能和数据量级要求。
- 各类开源模型,比如 ChatGML 和 Llama 是无法直接拿来满足商业需求的。在大模型商业化的过程中,模型的领域定制是免不了的。
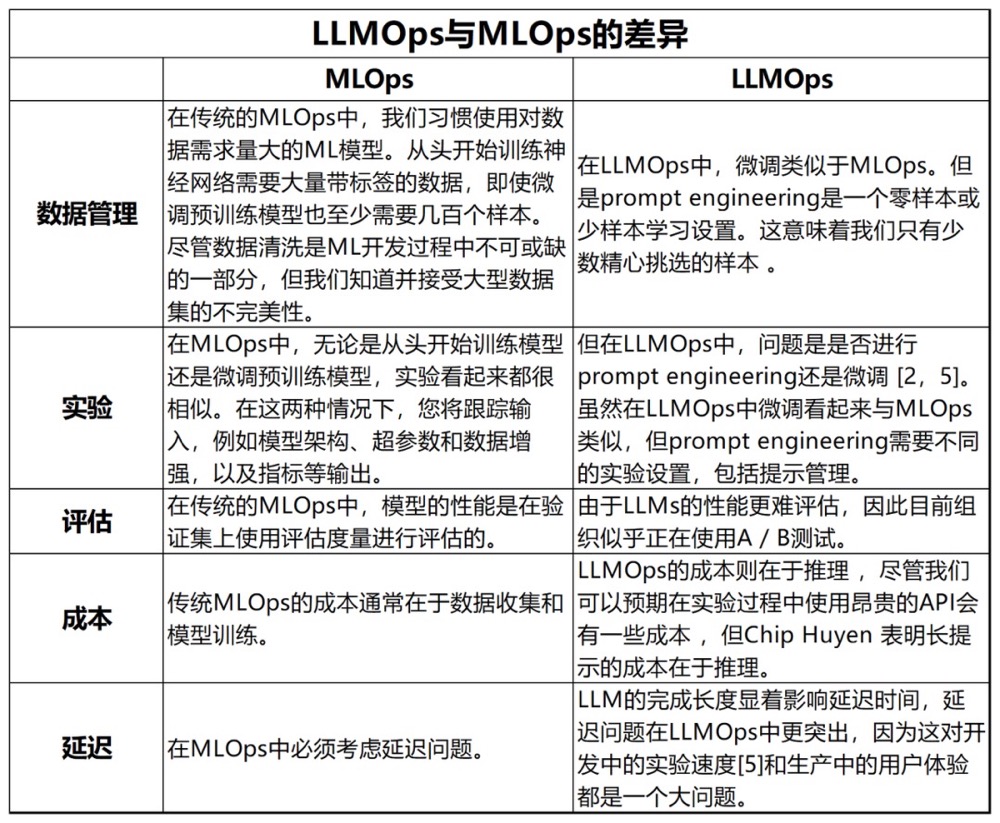
LMOps 工具链与千帆大模型平台 LMOps 是基于 MLOps 框架的一种扩展,它主要针对大语言模型进行优化。与 MLOps 相比,LMOps 更注重无监督学习的方式,并弱化了代码层面的处理。然而,在分布式训练、提示工程、Peft 调优、大模型插件扩展以及大模型评估方法等方面,LMOps 相较于 MLOps 进行了相应的增强。
- LLM 相关的所有操作可以白屏化进行。
挑战
淘天集团大模型应用十大挑战命题发布 值得细读。
从 PyTorch DDP 到 Accelerate 到 Trainer
框架/平台有一个草灰蛇线
- 尽量统一单机、单机多卡、多机多卡代码。其实这一条倒不强求,因为对于一个训练平台太多,统一使用DDP就够了,毕竟不需要算法从0到1写训练代码。
- 将很多优化参数化、配置化,比如是否启用量化、lora(
model = get_peft_model(model, config))等。对于用户来说,只暴露数据集名称/地址、模型名/模型文件等有限几个参数就够了。PS:从训练平台的角度讲,最好是所有需求都是参数化的,参数 + 固定代码 + 数据集 = 训练任务。 - 如果是多机多卡,则到每台机器上依次启动进程(torchrun 及其各种上层封装)有点麻烦,因此出现了类似pdsh工具, pdsh是deepspeed里面可选的一种分布式训练工具,适合你有几台裸机,它的优点是只需要在一台机上运行脚本就可以,pdsh会自动帮你把命令和环境变量推送到其他节点上,然后汇总所有节点的日志到主节点。要用pdsh前,你得自己给所有的机器配一样的环境,配ssh,把所有机器之间都通过ssh的秘钥文件设置成不需要密码登录,然后安装pdsh,准备工作就结束了。
- 很明显,有一个k8s平台更好一些,使用DLRover 等带有容错能力的工具栈,还可以支持分布式训练任务的容错。
class BasicNet(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout(0.25)
self.dropout2 = nn.Dropout(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
self.act = F.relu
def forward(self, x):
x = self.act(self.conv1(x))
x = self.act(self.conv2(x))
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.act(self.fc1(x))
x = self.dropout2(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return output
# 构建一些基本的 PyTorch DataLoaders:
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307), (0.3081))
])
train_dset = datasets.MNIST('data', train=True, download=True, transform=transform)
test_dset = datasets.MNIST('data', train=False, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dset, shuffle=True, batch_size=64)
test_loader = torch.utils.data.DataLoader(test_dset, shuffle=False, batch_size=64)
从零手撸
def train():
# 把模型放入 CUDA 设备
model = BasicNet().to(device)
# 构建优化器
optimizer = optim.AdamW(model.parameters(), lr=1e-3)
model.train()
# 训练和评估循环
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
optimizer.zero_grad()
model.eval()
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
print(f'Accuracy: {100. * correct / len(test_loader.dataset)}')
通常从这里开始,就可以将所有的代码放入 Python 脚本或在 Jupyter Notebook 上运行它。然而,只执行 python myscript.py 只会使用单个 GPU 运行脚本。如果有多个 GPU 资源可用,可以使用 torch.distributed 的 DataParallel/ DistributedDataParallel,问题是:单机、单机多卡、多机多卡的分布式训练代码不一样。
Accelerate
Accelerate 是一个库,旨在不论是单节点还是多节点,无需大幅修改 PyTorch 原生代码的情况下完成并行化。
def train_ddp_accelerate():
accelerator = Accelerator()
# Build model
model = BasicNet()
# Build optimizer
optimizer = optim.AdamW(model.parameters(), lr=1e-3)
# 把我们的模型、数据、优化器等等都放进accelerate里面
train_loader, test_loader, model, optimizer = accelerator.prepare( # 替换掉 model.to(device)
train_loader, test_loader, model, optimizer
)
# Train for a single epoch
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
output = model(data) # 省掉 data.to(device)
loss = F.nll_loss(output, target)
accelerator.backward(loss) # accelerator.backward(loss)替换掉常用的loss.backword()
optimizer.step()
optimizer.zero_grad()
# Evaluate
model.eval()
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
print(f'Accuracy: {100. * correct / len(test_loader.dataset)}')
if __name__ == "__main__":
train_ddp_accelerate()
可以 accelerate launch {script_name.py} --arg1 --arg2 ... 执行以上脚本,或
# 生成config文件
accelerate config
# xx_config.yaml 单机多卡
compute_environment: LOCAL_MACHINE
distributed_type: MULTI_GPU
gpu_ids: all
num_machines: 1
num_processes: 2
rdzv_backend: static
# 基于config文件运行脚本
accelerate launch --config_file default_config.yaml train.py --arg1 --arg2...# xx_config.yaml 多机多卡
compute_environment: LOCAL_MACHINE
distributed_type: MULTI_GPU
gpu_ids: all
machine_rank: 0
num_machines: 2
num_processes: 4
rdzv_backend: static
# 节点1
accelerate launch --config_file default_config.yaml train.py --arg1 --arg2...
# 节点2,config.yaml中的machine_rank改成1即可
accelerate launch --config_file default_config.yaml train.py --arg1 --arg2...trainer
Hugging Face Trainer.
def train_trainer_ddp():
model = BasicNet()
# 定义一些 TrainingArguments 来控制所有常用的超参数
training_args = TrainingArguments(
"basic-trainer",
per_device_train_batch_size=64,
per_device_eval_batch_size=64,
num_train_epochs=1,
evaluation_strategy="epoch",
remove_unused_columns=False
)
# Trainer 需要的训练数据是字典类型的,因此需要制作自定义整理功能
def collate_fn(examples):
pixel_values = torch.stack([example[0] for example in examples])
labels = torch.tensor([example[1] for example in examples])
return {"x":pixel_values, "labels":labels}
# 将训练器子类化并编写我们自己的 compute_loss. The Trainer contains the basic training loop which supports the above features. To inject custom behavior you can subclass them and override the 对应的 methods.
class MyTrainer(Trainer):
def compute_loss(self, model, inputs, return_outputs=False):
outputs = model(inputs["x"])
target = inputs["labels"]
loss = F.nll_loss(outputs, target)
return (loss, outputs) if return_outputs else loss
trainer = MyTrainer(
model,
training_args,
train_dataset=train_dset,
eval_dataset=test_dset,
data_collator=collate_fn,
)
trainer.train()
if __name__ == "__main__":
train_trainer_ddp()
这段代码也可以分布式运行,而无需修改任何训练代码
跑AI大模型的K8s与普通K8s有什么不同?
- 计算,为了成为一个通用的资源调度系统,K8s搞了个插件框架Device-plugin,来辅助自己判断节点有没有“特殊资源”/GPU,辅助K8s按需分配GPU算力。为实现GPU资源的复用(显存+算力隔离),来提升底层GPU整体的利用率,还要增强Device-plugin插件逻辑。异构硬件故障的检测,任务的快速恢复,都需要这个DP的深入参与。
- 存储,Kubernetes集群本身也不管存储,主要管理的是容器“如何接入”存储。通过引入PV和PVC概念,标准的K8s都可以做到将存储挂载至容器中,使得容器里面的程序,像使用本地文件一样的访问远端存储。训练是多轮迭代来逼近目标范围的,因为训练数据量太大,数据无法全部放入内存,在每轮迭代结束后,需要重新从文件系统里读取数据进行下一轮迭代的训。即得重新访问样本进行一轮计算。那么如果每次都重新访问“远程”存储,性能必将大受影响(100T数据,每个epoch重新读一遍OBS桶,你想想那得多慢)。所以如何将大量的样本数据,就近缓存,就是AI+K8s系统需要重点考虑的问题。分布式缓存加速系统,就是其中一条路线。
- 网络,在Kubernetes的标准框架里,容器是只有1个网络平面的。即容器里面,只有1个eth0网卡。所以无论是利用overlay实现容器隧道网络,还是underlay实现容器网络直通,其目的都是解决容器网络“通与不通”的问题。而大规模AI集群中,百亿、千亿级别参数量的大模型通常需要做分布式训练,这时参数梯度等信息要在节点间交换,就需要使用RDMA网络来传递,否则参数信息传的实在太慢了。一般成本考虑咱们都是走RoCE方案,即用IB网卡+以太网交换机(而不是IB专用交换机)实现。RoCE网卡的管理,也属于“异构资源”,也需要开发Device-plugin来告知K8s如何分配这种RoCE网卡。而且GPU和RoCE网卡是需要进行联合分配的,因为硬件连接关系,必须是靠近在一起的配对一起用。PS:还有交换机的一些配置
- 调度,标准K8s集群的容器调度,都是单个容器独立考虑的:即取一个容器,找到其适合的节点,然后取下个容器调度。但是分布式AI训练容器不一样,它们是一组容器。这一组容器,必须同时运行,才可以进行集合通信,即所谓的All_or_Nothing。通常也会叫「Gang Scheduling」,这个是分布式AI场景的强诉求。于是,各家又开始整活了。什么Coscheduling,Yunikorn,Volcano,Koordinator,Katalyst等纷纷上线。以Volcano为例,它除了完成分布式AI训练中「Pod-group」这种容器组的调度,还实现了容器组之间「SSH免密登录」,MPI任务组的「Hostfile文件」这些辅助实现。
Related Issues not found
Please contact @qiankunli to initialize the comment