
简介(未完成)
Reasoning LLM(二):过程监督与结果监督 奖励模型的作用
- 训练数据增强。即通过奖励模型评分结合拒绝抽样来采用数据选择过程, 其本质是通过这种方式产生更高质量的数据。这种方法当前已被广泛用在 SFT 数据构造上
- 强化学习训练。这种方式是最广泛最经典的奖励模型的用法,即在强化学习训练并提供有效的奖励信号,进一步提升模型性能。如果说 reject sampling 是一种静态的监督增强(即离线产生数据之后不会随模型训练而变化),那么在 RLHF 中,可以认为是一种动态的监督的方式。由于 RLHF 训练成本的高昂,后续的研究对此做了一些精简,比较经典的就是 DeepSeek 的 GRPO,该方法抛弃了 Value Model 而仅保留 Reward Model 作为监督的依据,同样可以采用两种监督方式,概括而言:
- 结果监督:对于每个输入产生多个输出,使用 Reward Model 打分并标准化,然后计算每个输出的分数与均值的差异,再进行策略优化;
- 过程监督:与上述方法不同的是,过程监督对结果的每一步进行打分,最后优势函数的计算即所有步骤优势的和,再进行策略优化。
- 推理性能增强。除了作用于训练过程,奖励模型还可以作用于推理过程,通过结合 sampling,Best-of-N,MCTS 等策略,选择奖励模型判断得分最高的回答,通过花费多步和更多的推理时间产生更好的结果。
RM 其实扮演的是rl概念下的「环境」,在使用RL训练LLM的一个限制是奖励的计算。在模型输出可通过代码或某种测试验证的场景下,奖励更容易定义,我们可以提示模型,给出答案,让它运行并找到解决方案。这让RL无限训练模型成为可能,从而产生神奇效果。在输出不易验证的开放领域,我们通常训练奖励模型来判断输出。有不少研究表明这会导致”Reward Hacking”现象,模型学会输出内容以获得高奖励,而输出并不是我们想要的。这种情况下就不能使用RL训练模型。
训练
reward_loss
reward_loss为排序中常见的 pairwise ranking loss。其中$r_{\theta}$是奖励模型的输出标量,$y_w$是一对回答中相对较好的那个; $y_l$是相对较差的那个回答,$\sigma$ 是sigmoid函数。
\[loss(\theta)=-\frac{1}{\binom{K}{2}} \mathbb{E}_{(x, y_w, y_l) \sim D}[\log (\sigma(r_{\theta}(x, y_w)-r_{\theta}(x, y_l)))]\]也有的文章公式是
\[loss(\theta)=-\log (\sigma(r_{\theta}(x, y_w)-r_{\theta}(x, y_l)))\]PS: 这意思就是 $y_w$ 评分比 $y_l$ 大的越多,loss越小。此外,reward model只在t=T的时候打分,其余时间步t的时候应该是用默认值0,也就是典型的稀疏奖励,如果要改成不稀疏,需要做奖励塑形,比如每一个 token 将奖励乘上一个折扣传递给前一个 token。
ORM 的训练
PRM 的训练
DeepSeek-GRM
过去几个月 DeepSeek-R1 引领的 RL 训练范式,基本上是基于 Rule-based 奖励的,也就是说,奖励模型(RM)本身非常简单,这存在一定的局限性——对数学这类有标准答案的任务比较友好,但泛化到其他领域有难度。最近,DeepSeek 发布了新论文,尝试找到一个更「通用」的 RM 训练方法:
- 提出采用「逐点生成式奖励模型」(Pointwise Generative Reward Modeling)范式,因为它在处理不同输入类型时更灵活,并具有推理时扩展的潜力。
- 核心贡献是一种名为「自我原则化批判调优」(Self-Principled Critique Tuning, SPCT)的新学习方法。SPCT 利用在线强化学习(RL),训练 GRM 自适应地生成「原则」(Principles)来指导评分标准,并生成「批判」(Critiques)来给出具体评分,从而提高了奖励的质量和可扩展性。
- 此外,论文还提出了通过并行采样和引入「元奖励模型」(Meta RM)来指导投票过程,以更有效地利用增加的推理计算。
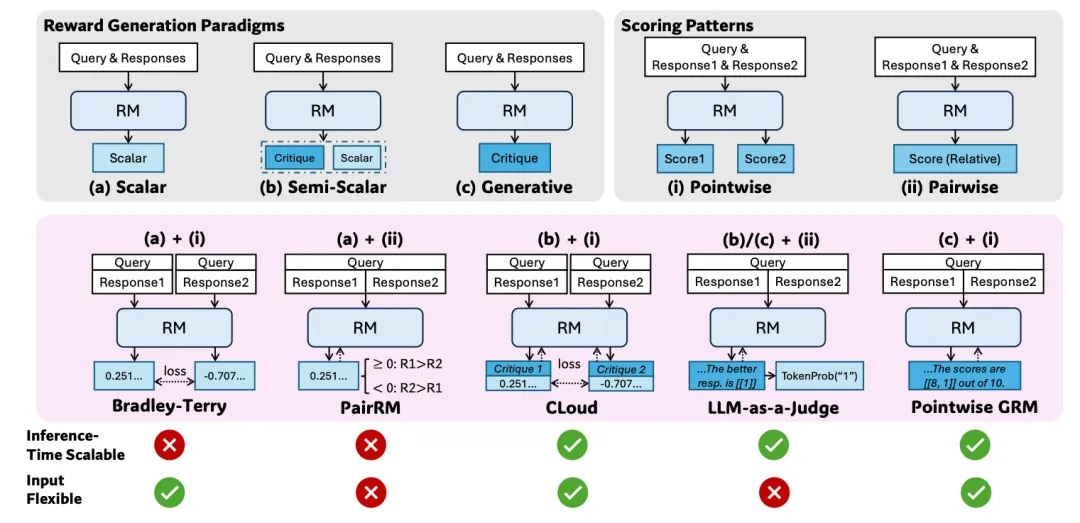
对于强化学习, 核心是评判多个答案的好坏, 因此Reward Model的设计就很关键了,作者将Reward生成的范式(Reward Generation Paradigms)分为了3类,
- 标量(Scalar): 这种范式对给定的Query & Response计算出一个标量分数作为奖励.
- 半标量(Semi-Scalar):这种范式类似于购物软件的评论, 不光要采用标量值打分,还有一段评论, 可以用来提取给出该打分的原因.
- 生成式(Generative): 这种方式会生成一段文本式的评论(Critique)作为奖励, 奖励值可以从文本内提取, 当然也可以通过一些格式要求,把奖励的分值写在评论中. 然后是评分模式(Scoring Pattens)
- PointWise: 独立的给每一个回复评分
- Pairwise: 对两个回复之间进行相对比较评分.
然后是这几种方法的组合, 其实最关键的是最后两行. 基于标量的区分度有限, 无法做到Inference-Time Scale, 然后对于回复的多种情况(单个/多个评分)即Input Flexible, 而在搜索的过程中Pair-Wised无法实现对单个和多个回复(两两Pair-wised也很复杂)的比较. 基于这些原则最后选择了PointWise GRM(c)+(i)的方式.
核心洞察:原则 (Principles) 的重要性。研究者发现,如果能提供「好的」原则(评价标准),即使是现有的 LLM 也能更好地生成奖励判断。这启发了他们:提升 RM 性能和可扩展性的关键可能在于提升 原则生成 的质量和 基于原则进行批判 (Critique) 的准确性。让 GRM 自己学会根据输入的查询和回答,动态地生成合适的原则,并基于这些原则生成准确的批判。
- 思路 : 把原则的生成也看作是模型生成任务的一部分。然后设计一套学习流程来优化这个「生成原则 + 生成批判」的过程。
- 实现可扩展性:
- 通过 SPCT 训练,模型学会了生成原则和批判。在推理时,可以通过多次采样,让模型生成多套不同的原则和相应的批判。
- 直觉 : 如果每次采样都能从略微不同的角度(原则)来审视回答,那么综合多次采样的结果(通过投票或更复杂的聚合方式),就能得到更全面、更鲁棒、更细粒度的最终评分,从而实现推理时性能的提升。
Self-Principled Critique Tuning (SPCT):
- 阶段一:拒绝式微调 (Rejective Fine-Tuning - Cold Start)
- 目的 : 让模型先学会生成符合格式要求、覆盖多种输入的原则和批判。
- 数据 : 通用指令数据 + 从预训练 GRM 采样生成的「轨迹」(包含原则 + 批判 + 分数)。
- 采样策略 : 对每个查询和回答,采样 $N_{RFT}$ 次。
- 拒绝策略 (Rejection Strategy):
- 拒绝那些预测分数与真实标签不一致的轨迹(判断错误)。
- 拒绝那些所有 $N_{RFT}$ 次采样都预测正确的样本(太简单,模型已掌握)。
- 提示采样 (Hinted Sampling): 对于模型难以正确评分的样本,在输入中提示哪个回答是最好的,期望模型能生成与提示一致的批判。这有助于产生更多「正确」的训练数据,但也可能导致模型「抄近路」(shortcut learning),不去真正理解而是依赖提示。
- 阶段二:基于规则的在线强化学习 (Rule-Based Online RL)
- 目的: 进一步优化 GRM,使其生成的原则和批判能更有效地区分最佳回答,并学习可扩展的行为。
- 算法: 使用 GRPO
- 奖励信号 : RL 的奖励不是来自人类,而是来自一个简单的规则:如果 GRM 生成的批判所对应的分数能够正确地识别出哪个回答是最好的(根据数据集的真实标签),则给予正奖励 (+1),否则给予负奖励 (-1)。
- KL 惩罚: 加入 KL 散度惩罚项,防止模型在 RL 训练中偏离原始模型太远,保持生成的多样性和遵循指令的能力,避免模式崩溃 (mode collapse) 和严重偏见。作者发现需要较大的 KL 系数 ($\beta=0.8$) 来保证稳定性。
SPCT:DeepSeek 的「通用」奖励模型训练方法 给出了详细解读和伪代码