
简介(未完成)
RLHF流程
RLHF的基本思想是将人类价值观和偏好纳入AI系统的学习过程中。仅仅让LLM预测下一个单词是不够的——它需要生成有用、安全、真实且符合人类意图的回答。但”有用性”和”有帮助性”等概念很难用传统的数学目标函数来表达。RLHF提供了一种方法,让AI可以从人类对其输出的评价中直接学习这些复杂的价值观。

图解大模型RLHF系列之:人人都能看懂的PPO原理与源码解读
RLHF——让大模型对齐人类偏好预训练主要针对补全能力,但不一定是“有用”的补全。RLHF优化模型所涉及的三个步骤,sft ==> RM ==> RL
- 指令微调(SFT):模型会模仿其训练数据,使用精选的人类回答数据集来微调预训练的大语言模型以应对各种查询。这让模型获得了优异的指令理解和意图识别能力,模型的输出也更符合人类的期待,胜过通用文本生成模型,弥补了 LLMs预测下一个单词目标与用户遵循指令目标之间的差距,指令的作用是约束模型的输出,使其符合预期的响应特征或领域知识,为人类干预模型的行为提供一个通道。PS: chat 模型就是SFT 过的模型
- 指令微调SFT(Supervised fine-tuning)的数据集是问答对,即(prompt,answer)对,prompt我们可以理解为指令或问题,answer就是针对该指令或问题的高质量答案。SFT就是在预训练模型基础上利用这些人工标注的数据进一步微调
- IFT可以算作SFT的一个子集,或者说先驱步骤,IFT的主要目的是让模型适应并听从人类的指令,比如当指令prompt出现”summarize”时,模型就应该知道现在的任务是总结任务。经过IFT之后,模型学会了听从指令,但是其生成的内容却不一定安全可靠。所以为了提升大模型的帮助性、降低有害性,人们会继续做SFT,通过高质量的数据给模型展示无害的、有帮助性的回答,规训模型的生成内容。
- 奖励模型训练(RW):由于人的反馈需要思考,是非常慢的,肯定跟不上fine-tune 中网络的训练,我们不能让人类对模型的所有输出进行ranking。所以chatgpt 设计了一个reward predictor 模块,通过学习人类的历史行为来预估人的feedback。使用一个包含人类对同一查询的多个答案打分的数据集训练一个奖励模型。或者说,就是一个打分模型,标注者对大量的SFT模型输出进行投票,哪个更好,哪个更差,由此创建了一个由比较数据组成的新数据集。相比监督微调,这种方法的优势在于不需要标注者编写回答,只需要为模型生成的几个回答打分,大幅提高了标注效率。
- RM 模型的数据构造是对 LLM 模型输入同一个提示采样多个不同输出,生成多个 pair 对。之后人类专家会对这些 pair 对进行质量排序,生成数据集,,然后提供给模型进行 pair-loss 偏好训练。其中query表示提示信息或者说指令信息,chosen为标注后排序分数较高的答案,即针对提示选择的答案;rejected为标注后排序分数较低的答案,即针对提示拒绝的答案。
{ "query": "联合国总部在哪里?", "chosen": "联合国总部大楼位于纽约曼哈顿东侧,属于xxx", "rejected": "联合国的15个专门机构都没有设在总部,然而,xx" } - 训练RM是一个排序任务,不是直接对文本标注分数来训练奖励模型,因为不同的研究人员对同一个句子可能有不一样的评分,这样会导致大量的噪声出现,如果改成排序,则会大大降低噪声。不同的排名结果将被归一化为用于训练的标量奖励值。针对query,输入chosen和rejected答案,训练目标尽可能的使得chosen答案和rejected答案的差值更大。
- 奖励模型可以利用预训练模型进行初始化,或者也可以进行随机初始化。训练奖励模型的基本目标是获得一个模型,该模型接收一系列的文本,之后返回每个文本对应的标量奖励,该奖励会在数字值的大小上代表人类偏好,越大表示越接近人类偏好,越小表示越脱离人类偏好。
- 对于rm模型来说,采用sft模型进行参数初始化,将原来的lm输出层替换成一个线性全连接层,在接受提示和响应作为输入后,输出一个标量奖励值。在训练过程中,采用pair-wise方法进行模型训练,即对于同一个提示内容x来说,比较两个不同的回答$y_w$和$y_l$之间的差异,假设$y_w$在真实情况下好于$y_l$,那么希望$x+y_w$经过模型后的分数比$x+y_l$经过模型后的分数高,反之亦然。
- RM 模型的数据构造是对 LLM 模型输入同一个提示采样多个不同输出,生成多个 pair 对。之后人类专家会对这些 pair 对进行质量排序,生成数据集,,然后提供给模型进行 pair-loss 偏好训练。其中query表示提示信息或者说指令信息,chosen为标注后排序分数较高的答案,即针对提示选择的答案;rejected为标注后排序分数较低的答案,即针对提示拒绝的答案。
- RLHF 训练/rlhf-ppo:人类反馈强化学习/近端策略优化算法(PPO),根据 RW 模型的奖励反馈进一步微调模型以最大化reward model的score。
- 设计对齐模型的优化目标:这个优化目标不仅考虑到奖励模型的得分,也尽量让对齐模型参数更新后输出的分布不要偏移sft模型太远,防止模型越训越差。
- 我们让对齐模型根据prompt自生成回答,并采用训练好的奖励模型对回答进行打分,对齐模型会根据评分结果不断调整自己的输出分布。
总结一下RLHF=rm+ppo:我们通过比较容易获得的公开无标签数据,来训练一个大语言模型/预训练模型,然后,通过人工编写的问答对,来生成高质量的监督对话数据,来优化大语言模型的对话能力。在得到了这个优化后模型(sft model)之后,标注者便在给定问题上可以基于模型生成的答案,对回答进行排序,并用排序数据训练一个reward model对回答的结果排序打分,用来评估回答的质量。最后,也是强化学习中最重要的一步,就是用你的“奖励模型”来提升 SFT model的效果。PS:在得到一个sft model之后,如何进一步优化sft model?一种办法是准备更多的“问题回答对“,但这个成本很高,再一个准备的多了,也可能会有价值观等问题,所以干脆训练一个专门的reward model来做这个事儿,用它来对sft model 生成的内容打分,进而继续“微调”sft model。这个很像家长、老师会告诉我们做事的正确答案,但是教的不多,到社会上,没人告诉你对错,只能通过别人的脸色、反应来判断自己做的对错。
大模型对齐技术,各种什么O:PPO,DPO, SimPO,KTO,Step-DPO, MCTS-DPO,SPO 推荐细读。PS:建议捋一下。
RLHF通俗理解 代码级的理解看这里。
小红书基于 PPO 的多模态大模型 RLHF 系统的设计与优化 未细读
梳理
LLM+RL 文章提到
- RLHF 的本质是什么,及其与 RL 和有监督学习(SL)的关系
- 当前的各种优化方法的优化点是什么,其立足角度和收益如何
- 使用 RL 训练逻辑推理模型,有哪些经验及注意事项
生成token $A_t$和对应收益 $R_{t}$、$V_{t}$的并不是一个模型。那么在RLHF中到底有几个模型?他们是怎么配合做训练的?而我们最终要的是哪个模型?
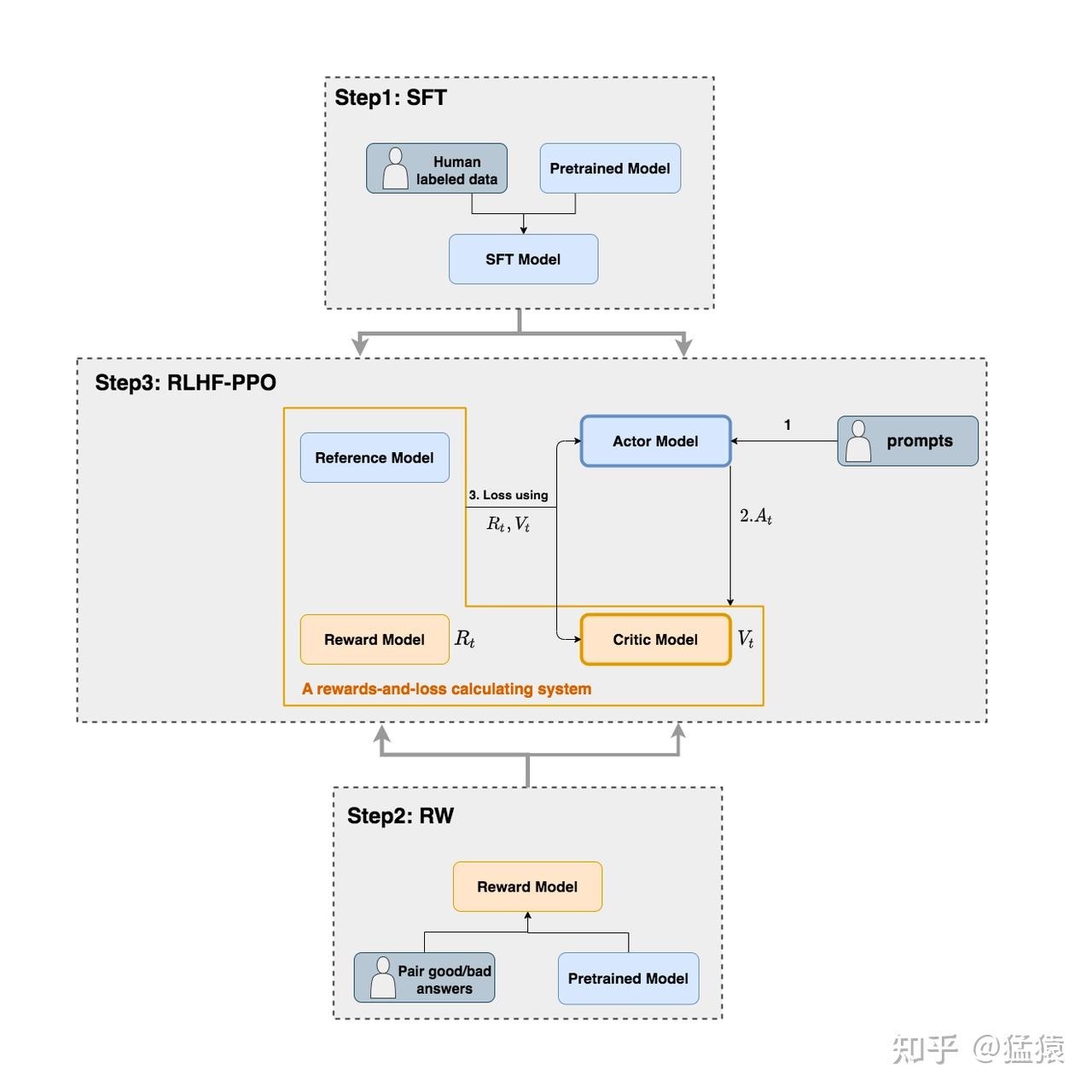
在RLHF-PPO阶段,一共有四个主要模型,分别是:
- Actor Model:演员模型,这就是我们想要训练的目标语言模型。一般用SFT阶段产出的SFT模型来对它做初始化。
- Critic Model:评论家模型,它的作用是预估总收益 $V_{t}$。Critic Model的设计和初始化方式有很多种,deepspeed-chat的实现是从RW阶段的Reward Model初始化而来(毕竟输入都一样,也有critict 从actor 初始化而来的)。我们前文讨论$V_{t}$(即时 + 未来)时,我们是站在上帝视角的,也就是这个$V_{t}$就是客观存在的、真正的总收益。但是我们在训练模型时,就没有这个上帝视角加成了,也就是在 t时刻,我们给不出客观存在的总收益$V_{t}$,我们只能训练一个模型去预测它。也就是我们不仅要训练模型生成符合人类喜好的内容的能力(Actor),也要提升模型对人类喜好量化判断的能力(Critic)。
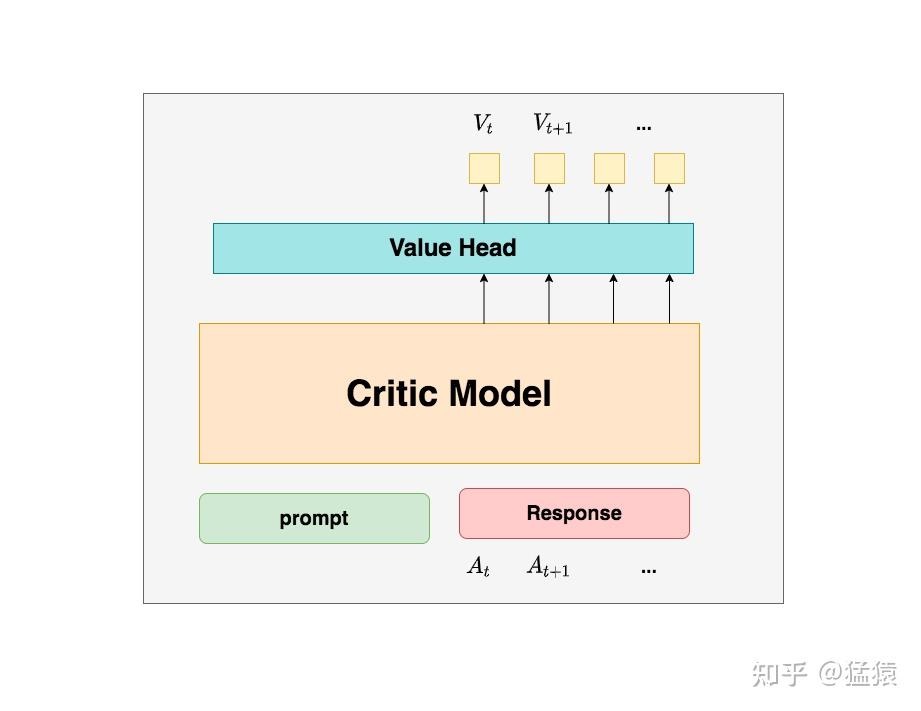 Critic在最后一层增加了一个Value Head层(全连接层),该层是个简单的线形层,让每个 token 对应一个标量,用于将原始输出结果映射成单一的$V_{t}$值。
Critic在最后一层增加了一个Value Head层(全连接层),该层是个简单的线形层,让每个 token 对应一个标量,用于将原始输出结果映射成单一的$V_{t}$值。 - Reward Model:奖励模型,它的作用是计算即时收益 $R_{t}$。PS:reward model 可以对response 做出评价(至少训练时是这样),那这个评价如何对应到token level loss上?有分配策略把reward分配到每个token上。
- 有了critic 为何还要reward?$V_t = R_t + \gamma V_{t+1}$ 告诉我们,我们当前可以用两个结果来表示t时刻的总收益:Critic模型预测的$V_t$ ; Reward模型预测的$R_t$和critic模型预测的 $V_{t+1}$。那么哪一个结果更靠近上帝视角给出的客观值呢?当然是结果2,因为结果1全靠预测,而结果2中的$R_t$是事实数据。换个视角,有了reward 为何还要critic?为了防止模型在短期收益上过拟合。某种程度上算是提供了一个baseline。
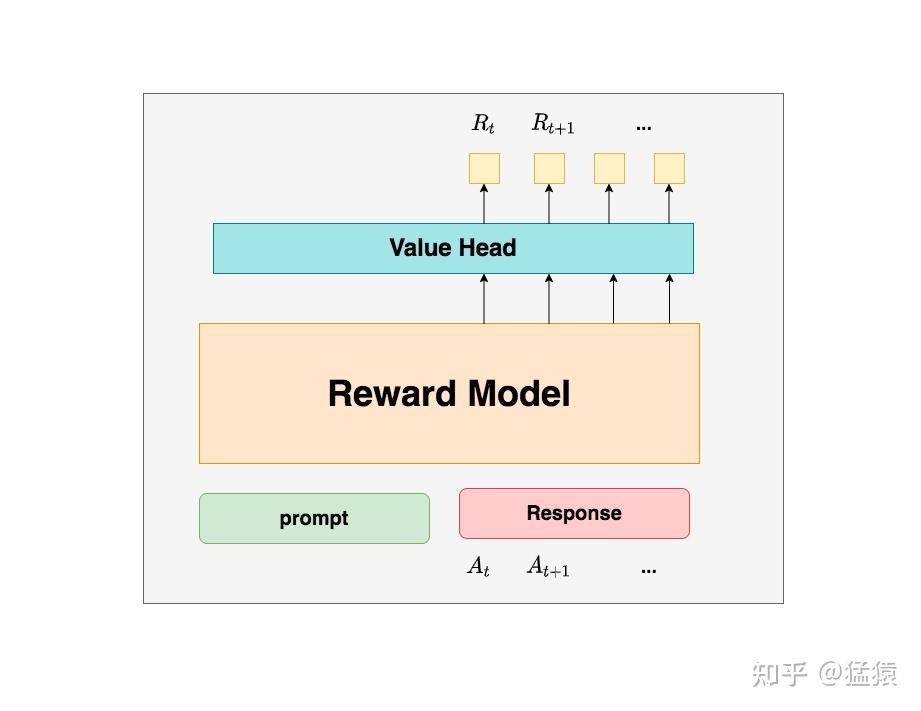
- 有了critic 为何还要reward?$V_t = R_t + \gamma V_{t+1}$ 告诉我们,我们当前可以用两个结果来表示t时刻的总收益:Critic模型预测的$V_t$ ; Reward模型预测的$R_t$和critic模型预测的 $V_{t+1}$。那么哪一个结果更靠近上帝视角给出的客观值呢?当然是结果2,因为结果1全靠预测,而结果2中的$R_t$是事实数据。换个视角,有了reward 为何还要critic?为了防止模型在短期收益上过拟合。某种程度上算是提供了一个baseline。
- Reference Model:参考模型,它的作用是在RLHF阶段给语言模型增加一些“约束”,防止语言模型训歪(朝不受控制的方向更新,效果可能越来越差)。一般也用SFT阶段得到的SFT模型做初始化
其中:
- Actor/Critic Model在RLHF阶段是需要训练的(图中给这两个模型加了粗边,就是表示这个含义);而Reward/Reference Model是参数冻结的。
- Critic/Reward/Reference Model共同组成了一个“奖励-loss”计算体系,我们综合它们的结果计算loss,用于更新Actor和Critic Model,也就是loss也分成2个:Actor loss(用于评估Actor是否产生了符合人类喜好的结果) 和 Critic loss(用于评估Critic是否正确预测了人类的喜好)
我们的最终目的是让Actor模型能产生符合人类喜好的response。所以我们的策略是,先喂给Actor一条prompt (这里假设batch_size = 1,所以是1条prompt),让它生成对应的response。然后,我们再将“prompt + response”送入我们的“奖励-loss”计算体系中去算得最后的loss,用于更新actor。PS: grpo 是一个prompt 生成多个response。
与sft 对比
为什么需要RLHF?SFT不够吗?为什么要强化学习,而不是传统的监督学习。
- 监督学习依赖直接的监督信号。在llm中,SFT的训练的目标就是,给定prompt,拟合repsonse。换句话说,提升给定prompt的条件下,repsonse出现的概率。
- 使用强化学习来对齐,先训练个奖励模型。reponse答案的好坏靠奖励模型或奖励函数判断。然后,在RL的训练过程中,不断采样prompt,随机生成response。那么LLM在奖励函数和对应的累积奖励最大目标的引导下,就会逐步调高好response的概率,调低坏repsonse的概率(同时反过来就会提升其他reponse的出现的概率)。最后呢,效果就是模型会尽量出它认为累计奖励最大的答案。在RLHF的PPO的一种实现中,使用结果奖励模型,给整个reponse打个分。那么response中,每一个token的奖励使用Actor和Reference模型的KL散度作为奖励,仅仅最后一个token再加上整个response的奖励得分。
有一种说法是,为什么用rlhf,因为靠reward model,用rl就可以学到负反馈。其实这也不太全面,或者还不太够。
- 有了Chosen和Reject样本,是不是可以基于打分给每个token的交叉熵损失加权了。甚至最好将打分归一化,这样有正有负,SFT的负反馈不就来了嘛。所以负反馈不是为什么一定要用RL算法的原因。或者说RL并不是简单的负反馈。
- 如果是sft,那么理论上针对不同的情况,都得有充足的高质量样本,来做监督微调。碰到回答质量不够、范围覆盖不够、没有拒识等情况,通通继续标注。但实际情况存在用户输入多种多样,都要覆盖,标注成本巨大。似乎如果只靠sft,总有覆盖不到的地方。
- sft和rlhf实际主要的差别就在于强化学习训练中的样本,说白了就是模型不断地通过采样回答来探索,带来了样本与回答的多样性。相比sft,actor模型在RL训练的过程中,看到训练样本在回答的多样性的纵深维度上要深得多。有不同形式、不同质量的回答。在奖励函数的指导下,模型的各种多样性的答案都得到了正负反馈,并在最大化累计奖励的目标下,逐步调节了Actor的参数。所以泛化性会好。至于怎么累积奖励最大,而且在不断采样的情况下还保证模型能正常收敛,那就涉及每个token的优势的估计计算以及critic的训练。