
简介
Paul Graham: 代码中任何外加的形式都是一个信号,表明我对问题的抽象还不够深入,也经常提醒我,自己正在手动完成的事情,本应该写代码通过宏的扩展自动实现。
魔法函数
魔法函数。允许你在类中自定义函数(函数名格式一般为__xx__),并绑定到类的特殊方法中。比如在类A中自定义__str__()函数,则在调用str(A())时,会自动调用__str__()函数,并返回相应的结果。Python中的魔法函数可以大概分为以下几类(看到魔法函数 就可以去查表):
- 类的构造、删除:
object.__new__(self, ...)object.__init__(self, ...)object.__del__(self) - 二元操作符: 加减乘除等,比如 + 对应
object.__add__(self, other)。矩阵乘法matrix multiplication a @ b 对应object.__matmul__(self, other)。 - 扩展二元操作符:+=/-=
- 一元操作符:取负等
- 比较函数:<=/>
- 类的表示、输出:
str()len() - 类容器:in 操作等
类的魔术方法:__init__/__new__/__call__/__del__,魔术方法一般由解释器调用(除了__init__),除非涉及大量元编程。如需调用魔术方法,最好调用相应的内置函数,比如len/iter/str等。借助魔术方法,自定义对象的行为可以像内置对象一样,符合社区所认可的python风格。魔术方法最重要的用途
- 模拟数值类型
- 对象的字符串表示形式。对应
__str__和__repr__ - 对象的布尔值。对应
__bool__ - 实现容器
支持运算符重载,这或许是python 在数据科学领域取得巨大成功的关键原因。在python中,函数调用()(__call__) 、属性访问.(__getattr__) 以及项访问和切片[]也是运算符。
yield和生成器
如果函数的内部出现了 yield 关键字,那么它就不再是普通的函数了,而是一个生成器函数,调用之后会返回一个生成器对象。
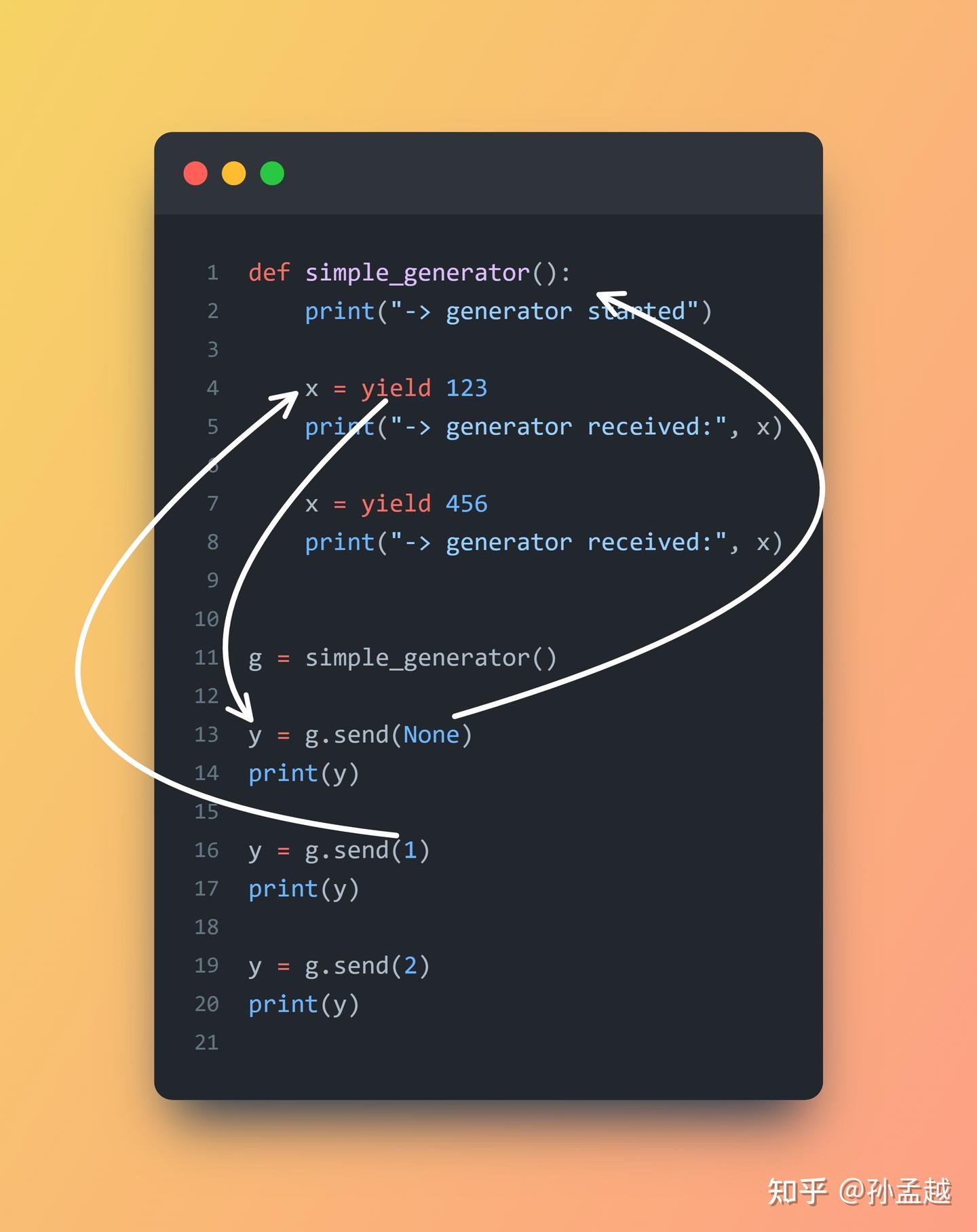
生成器在很多常用语言中,并没有相对应的模型。调用生成器函数(带有yield关键字的函数),返回一个生成器对象 generator(由python编译器构建,提供了·next`方法实现),也就是说,生成器函数是generator工厂。generator 实现了Iterator 接口,因此generator 也可以迭代。生成器函数中的return 语句触发generator抛出StopIteration 异常。生成器是懒人版本的迭代器,在你调用 next() 函数的时候,才会生成下一个变量。生成器并不会像迭代器一样占用大量内存,只有在被使用的时候才会调用。
- next(generator) 调用生成器的
__next__()方法,每次遇到 yield 时函数会暂停并保存当前所有的运行信息,返回 yield 的值后挂起, 并在下一次执行 next(generator) 方法时从当前位置继续运行。 - Python 引入生成器的最初目的是作为迭代器的替代。Python 中,可以迭代处理(比如在 for 循环中)的对象称为可迭代对象,可迭代对象实现了
__iter__()特殊方法,返回一个迭代器。生成器允许用户使用 yield 关键字,将函数作为迭代器,而不用定义类并实现对应的特殊方法。Python 会自动帮用户填充特殊方法,使生成器变成迭代器。- 生成器不仅仅有
__next__方法,它还有 send 和 throw 方法 - 生成器永远在 yield 处暂停,并将 yield 后面的值返回。如果想驱动生成器继续执行,可以调用
__next__或 send,会去寻找下一个 yield,然后在下一个 yield 处暂停。依次往复,直到找不到 yield 时,抛出 StopIteration,并将返回值包在里面。
- 生成器不仅仅有
- 生成器以懒加载模式按需返回值,因而更节约内存空间(甚至可以用于生成无限序列 ==> 迭代器是一个有限集合,生成器则可以成为一个无限集),可以暂停(只能将控制权移交给调用者next 函数)和恢复(被next 调用)。
class Sentence:
def __init__(self, text):
self.text = text
self.words = self.text.split()
def __iter__(self):
return SentenceIterator(self.words)
class Sentence:
def __init__(self, text):
self.text = text
self.words = self.text.split()
# __iter__ 返回一个generator(也是一个Iterator)
def __iter__(self):
for word in self.words:
yield word
return和yield异同
- 相似的是:yield 和 return 都可以在一个函数里将值返回给调用方;
- 不同的是:return 后,函数运行就终止了,而 yield 则只是暂停运行。 含有 yield 的函数,不再是普通的函数,直接调用含有 yield 的函数,返回的是一个生成器对象(generator object)。可以使用 for 循环(实际还可以使用 list 或者 next 函数)来遍历该生成器对象,将 yield 的内容一个一个打印出来。
当函数内部出现了 yield 关键字,那么它就是一个生成器函数,对于 yield from 而言亦是如此。这两者之间有什么区别呢?yield 对后面的值没有要求,会直接将其返回。而 yield from 后面必须跟一个可迭代对象(否则报错),然后每次返回可迭代对象的一个值。其它表现和 yield 是类似的。
yield from 表达式句法可把一个生成器的工作委托给一个子生成器。引入 yield from 之前,如果一个生成器根据另一个生成器的值产出值,则需要使用for 循环。
def sub_gen():
yield 1.1
yield 1.2
def gen():
yield 1
for i in sub_gen():
yield i
yield 2
def gen():
yield 1
yield from sub_gen()
yield 2
CPython中 PyGenObject 是生成器的结构体, PyCoroObject 是协程的结构体。这两个对象的内部都持有完整的程序栈帧,也会记录字节码运行到哪一条,以及一些额外的状态信息。CPython 把 await 编译到相对应的字节码指令, 遇到的时候就直接切进那个栈帧, 然后执行那个栈帧,然后返回结果。 这个过程和生成器的 yield 语句很像。
闭包/Closures
在虚拟机中,函数机制的实现都离不开 FunctionObject 和 FrameObject 这两个对象。有了 FunctionObject,一个函数就可以像普通的整数或者字符串那样,作为参数传递给另外一个函数,也可以作为返回值被传出函数。所以,在 Python 语言中,函数也和整数类型、字符串类型一样,是第一类公民(first class citizen)。把函数作为第一类公民,使新的编程范式成为可能,但它也引入了一些必须要解决的问题,例如自由变量和闭包的问题。
def func():
x = 2
def say():
print(x)
return say
f = func()
f()
当 say 函数在 func 函数的定义之外执行的时候,依然可以访问到 x 的值。这就好像在定义 say 函数的时候,把 x(更准确的说是x的reference) 和 say 打包在一起了,我们把这个包裹叫做闭包(closure)。
在 Python 字节码中,外部函数中定义并且被内部函数使用的变量被记录在 cell_vars 中,我们把它叫做 cell 变量。而对于内部函数,这些变量就是自由变量。自由变量是指在某个作用域内使用的变量,但该变量在这个作用域内并没有被定义或赋值,它的定义存在于当前作用域的外部。在函数中查找变量的时候,遵循 LEBG 规则。其中 L 代表局部变量,E 代表闭包变量(Enclosing),G 代表全局变量,B 则代表虚拟机内建变量。但不管什么变量,虚拟机在编译时便知道应该如何访问指定的内存。
注意,只有嵌套在其它函数中的函数才可能需要处理不在全局作用域中的外部变量,这些外部变量位于外层函数的局部作用域内。
装饰器
古明地觉:装饰器本质上就是高阶函数加上闭包,只不过给我们提供了一个优雅的语法糖,所以理解装饰器(decorator)的关键就在于理解闭包(closure)。装饰器存在的最大意义就是可以在不改动原函数的代码和调用方式的情况下,为函数增加一些新的功能。PS:在java里,用注解方式给一个方法加点功能,有点麻烦,得spring ioc支持,写一个专门的切面类,再配置spring ioc 把这个切面加到特定的方法上。而在python里,切面用一个函数实现就行。此外,不仅是可以给和函数加一点新功能,还可以捕获方法的参数,在函数的执行前后对这个方法参数干点事情,比如有一个db参数,则函数func执行完后,wrap_func 触发下db.commit。
fluent python:装饰器是一种可调用对象,其参数是另一个函数(被装饰的函数),本质上就是一个高阶函数。装饰器可能会对被修饰的函数做些处理,然后返回函数,或者把函数替换成另一个函数或可调用对象(也就是类)。装饰器在加载模块时立即执行,通常是在导入时,即使这些函数或方法还没有被显式调用。很多python框架会使用这样的装饰器把函数添加到某个中央注册处,比如注册http handler。严格来说,装饰器只是语法糖。
所谓的装饰器,其实就是通过装饰器函数,来修改原函数的一些功能,使得原函数不需要修改。装饰器通常返回在装饰器内部定义的函数,取代被装饰的函数。Python装饰器(decorator)在实现的时候,被装饰后的函数其实已经是另外一个函数了(函数名等函数属性会发生改变 ==> 函数签名变了),为了不影响,Python的functools包中提供了一个叫wraps的decorator来消除这样的副作用。
简单示例
def func():
...
def timer(func, *args, **kwargs):
def decorated(*args, **kwargs):
st = time.perf_counter()
ret = func(*args, **kwargs)
print('time cost: {} seconds'.format(time.perf_counter() - st))
return ret
# 返回一个函数指针,这样才能赋值给func
return decorated
func = timer(func1)
# func = timer(func1) 这样的写法麻烦且不具有共通性,所以python提供了一种装饰器的标准用法
def timer(func):
"""装饰器:打印函数耗时"""
def decorated(*args, **kwargs): # 一般把 decorated 叫作“包装函数”,接收任意数目的可变参数 (*args, **kwargs),主要通过调用原始函数 func 来完成工作。在包装函数内部,常会增加一些额外步骤,比如打印信息、修改参数等。
st = time.perf_counter()
ret = func(*args, **kwargs)
print('time cost: {} seconds'.format(time.perf_counter() - st))
return ret
return decorated
装饰器是一种特殊类型的函数,它接受一个函数作为参数并返回一个新的函数。这意味着你可以在修饰器内部访问和操作这个被传入的函数。装饰器将额外增加的功能,封装在自己的装饰器函数或类中;当使用 @decorator 语法应用装饰器到一个函数上的时候,Python 会用装饰器返回的新函数来替换原始函数。这样一来,每当尝试调用原始函数的时候,实际上是调用了装饰器返回的那个新函数。修饰器不过是类似函数调用add = call_cnt(add)的一种语法上的简写、语法糖。在vm实现,如果一个方法被装饰器修饰,则函数调用的字节码会从CALL_FUNCTION改为CALL_FUNCTION_EX,解释器会帮忙将add 调用改为 add=call_cnt(add) 后的add。PS:所以是不是可以认为,语法糖的实现都有解释器帮忙?
类装饰器
类装饰器:类中一个非常特殊的实例方法,即 __call__()。该方法的功能类似于在类中重载 () 运算符,使得类实例对象可以像调用普通函数那样,以对象名()的形式使用。PS:可以看做python 对象和函数都实现了 Callable 接口,因此在()这个场景可以互相替换,在很多场合函数被包装成了一个对象。
绝大多数情况下,我们会选择用嵌套函数来实现装饰器,但这并非构造装饰器的唯一方式。事实上,某个对象是否能通过装饰器(@decorator)的形式使用只有一条判断标准,那就是 decorator 是不是一个可调用的对象。类同样也是可调用对象。类装饰器主要依赖于 __call__ 方法,当一个类的实例被当作函数调用时,__call__ 方法就会被执行。PS: 把函数变成了一个类
class Count:
def __init__(self, func): # 初始化时传入原函数 func()
self.func = func
self.num_calls = 0
def __call__(self, *args, **kwargs):
self.num_calls += 1
print('num of calls is: {}'.format(self.num_calls))
return self.func(*args, **kwargs)
@Count
def example():
print("hello world")
example()
# 输出
num of calls is: 1
hello world
example()
# 输出
num of calls is: 2
hello world
...
参数化装饰器
python 会把被装饰的函数作为第一个参数传给装饰器函数,那么如何让装饰器接受其他参数呢?答案是创建一个装饰器工厂函数来接受那些参数,然后再返回一个装饰器,应用到被装饰的函数上。
registry = set()
def register(active=True):
def decorate(func)
print('running register(%s)' % func)
if active:
registry.add(func)
return func
return decorate
@register(active=False)
def f1():
print('running f1()')
@register() # 注意此处是 register() 而不是 register。 装饰器是decorate
def f2():
print('running f2()')
cur1 = register(active=True)
cur2 = decorate(func)
cur2()
带属性的装饰器
如果你是一个程序员,你面临一个变动很频繁的业务,你无法预知之后的需求情况,想要代码有足够大的机动余地,这个时候可以利用强大的setattr给程序留一个“后门”,方便后面临时修改。比如在装饰器当中定义一个dict,用来存储自定义的函数。再实现一个set_func方法将自定义的函数存储进这个dict当中,只有就可以通过参数,在不修改装饰器的情况下自由变更装饰器内的逻辑了。
def decorate(func):
func_dict = {}
@wraps(func)
def wrapper(*args, **kwargs):
# 通过key来选择应该调用哪一个函数作为装饰器的逻辑
if kwargs.get('key') is not None:
func_dict[kwargs['key']](*args, **kwargs)
return func(*args, **kwargs)
# 将函数名和函数作为参数传入,存储在dict中
@attach(wrapper)
def set_func(func_name, func):
nonlocal func_dict
func_dict[func_name] = func
return wrapper
来看一个使用的例子:
def test(*args, **kw):
print('test')
add.set_func('test', test)
add(3, 4, key='test')
一般情况下我们用不到这样的骚操作,但是能够写出来或者说看懂这样的功能。
装饰一个类
from functools import wraps
def injectable(lifetime: str = "singleton"):
"""更简洁的服务注册装饰器"""
def decorator(cls):
@wraps(cls) # 保留原始类的元数据
def wrapped_cls(*args, **kwargs):
instance = cls(*args, **kwargs)
return instance
setattr(wrapped_cls, "__injectable__", True)
setattr(wrapped_cls, "__lifetime__", lifetime)
return wrapped_cls
return decorator
@injectable(lifetime="singleton")
class UserService:
def __init__(self, repository: UserRepository):
self.repository = repository
decorator库
原始的装饰器一般简单写法是两层嵌套,如果使用decorator库,将原始嵌套的写法改造成单层的写法,两层的参数合并了,且使用decorator库实现的装饰器实现了签名不变。
def log(func):
def wrapper(*args, **kw):
print 'before run'
return func(*args, **kw)
return wrapper
###########################
from decorator import decorator
@decorator
def log(func, *args, **kw):
print 'before run'
return func(*args, **kw)
with和上下文管理器
with 是一种不常见的控制流功能, 目的是简化常用的一些try/finally结构,
with 语句对一段定义在上下文管理器的代码进行包装(封装 try-catch-finally),当对象使用 with 声明创建时,上下文管理器允许类做一些设置和清理工作。上下文管理器的行为由下面两个魔法方法所定义: __enter__() 和__exit__()。PS:魔术方法的支持下的一种语法糖。
with 语句适用于对资源进行访问的场合,确保不管使用过程中是否发生异常都会执行必要的“清理”操作,释放资源。类似于java的 try(xx){...} 或 try...finally...
with open('path','读写模式‘) as f:
do something
等价于
f = open('path','读写模式')
do something
f.close()
要使用 with 语句,首先要明白上下文管理器 以及 上下文管理协议(Context Management Protocol):
- 在有两个相关的操作需要在一部分代码块前后分别执行的时候,可以使用 with 语法自动完成。
__enter__()方法会在with的代码块执行之前执行,__exit__()会在代码块执行结束后执行。如果使用了 as 子句,则将 enter() 方法的返回值赋值给 as 子句中的 target。 - 使用 with 语法可以在特定的地方分配和释放资源
基于类的上下文管理器
class FileManager:
def __init__(self, name, mode):
print('calling __init__ method')
self.name = name
self.mode = mode
self.file = None
def __enter__(self):
print('calling __enter__ method')
self.file = open(self.name, self.mode)
return self.file
def __exit__(self, exc_type, exc_val, exc_tb):
print('calling __exit__ method')
if self.file:
self.file.close()
with FileManager('test.txt', 'w') as f:
print('ready to write to file')
f.write('hello world')
## 输出
calling __init__ method
calling __enter__ method
ready to write to file
calling __exit__ method
某些时候,如果只有很少的上下文需要管理,那么定义一个类便会有些麻烦。可以使用装饰器 contextlib.contextmanager将一个生成器函数转换为上下文管理器,来定义自己所需的基于生成器的上下文管理器,用以支持 with 语句。使用@contextmanager 能减少创建上下文管理器的样板代码,不用编写一个完整的类来定义__enter__() 和__exit__() 方法,而只需实现一个含有yield 语句的生成器,生成想让__enter__() 方法返回的值。yield 把函数主体分为两部分:在yield 之前的所有代码在调用__enter__() 方法时执行,yield 之后的代码在调用__exit__() 方法时执行。
from contextlib import contextmanager
@contextmanager
def file_manager(name, mode):
try:
f = open(name, mode)
yield f
finally:
f.close()
with file_manager('test.txt', 'w') as f:
f.write('hello world')
通过 contextlib 模块详细复习一下 with 语句的用法手动实现 contextmanager 函数,contextlib 中实现的比较复杂,主要是最后对异常进行了很多的检测。我们可以适当简化,把主要的逻辑实现一下。PS: 把函数变成了一个类,还给它加了方法
from functools import wraps
def contextmanager(func):
class GeneratorContextManager:
def __init__(self, func, *args, **kwargs):
self.gen = func(*args, **kwargs)
def __enter__(self):
try:
assert hasattr(self.gen, "__next__")
return next(self.gen)
except AssertionError:
raise RuntimeError("函数中必须出现、且只能出现一个yield")
def __exit__(self, exc_type, exc_val, exc_tb):
try:
next(self.gen)
except StopIteration:
return False
else:
raise RuntimeError("函数中必须出现、且只能出现一个yield")
@wraps(func)
def inner(*args, **kwargs):
return GeneratorContextManager(func, *args, **kwargs)
return inner
@contextmanager
def foo(name, where):
print(f"我的名字是: {name}, 居住在: {where}")
yield "baka⑨"
print(f"{where}是一个很美的地方")
with foo("古明地觉", "地灵殿") as f:
print(f.upper())
"""
我的名字是: 古明地觉, 居住在: 地灵殿
BAKA⑨
地灵殿是一个很美的地方
"""
需要注意的是,当我们用 with 语句执行上下文管理器的操作时,一旦有异常抛出,异常的类型、值等具体信息,都会通过参数传入“exit()”函数中。你可以自行定义相关的操作对异常进行处理,而处理完异常后,也别忘了加上“return True”这条语句。如果 exit 方法最后返回了一个布尔类型为 True 的值,那么会把塞进嘴里的异常吞下去,程序不报错正常执行。如果返回布尔类型为 False 的值,则会在执行完 exit 方法之后再把异常吐出来,引发程序崩溃。
动态语言
java里面增强已有代码,几乎只有动态代理一个手段。注解加在方法、类上,实际是proxy_instance在干活儿,在方法前、后搞点事情。而python的世界就自由多了,对类加方法、字段直接加,都不带拐弯的。对于已有方法,直接加个装饰器,这个方法就变得“妈都不认识了”,真正用的时候,可能是新方法,也可能是个类(大家都是callable),如果这个类还额外实现了其他方法,比如上下文管理器方法,你还可以拿这个方法当上下文管理器用。
动态属性
PS:在java 里得用reflect包,在python里好家伙直接 setattr/getattr,都懒得用反射
# 动态调用方法
class MyClass:
def greet(self, message):
print(message)
my_instance = MyClass()
method_name = "greet"
getattr(my_instance, method_name)("Hello, World!")
# 使用装饰器修改类定义
def add_attribute(attr_name, attr_value):
def decorator(cls):
setattr(cls, attr_name, attr_value)
return cls
return decorator
@add_attribute('my_attr', 'My Value')
class MyClass:
pass
print(MyClass.my_attr)
# 使用sys模块获取模块信息
import sys
module_info = sys.modules[__name__]
print(f"Module Name: {module_info.__name__}")
print(f"Module Docstring: {module_info.__doc__}")
在python 中,数据属性和方法统称属性 attribute,方法是可调用的attribute,动态属性的接口与数据属性一样(obj.attr),不过按需计算。 在python 中实现动态属性有以下几种
- @property
__getattr__。对于my_obj.x 表达式,python会检查my_obj 实例有没有名为x的属性,如果没有,就到类(my_obj.__class__)中查找,如果还没有,就会沿着继承图继续向上查找,如果依旧找不到,则调用my_obj所属的类中定义的__getattr__方法,传入self 和属性名称的字符串形式(例如’x’)。大多数时候,定义了__getattr__也要定义__setattr__
我们通常把__init__ 称为构造方法,这是从其他语言借鉴过来的术语,__init__ 第一个参数是self,可见在解释器调用__init__ 时,对象已存在。调用类创建实例时,python 调用的特殊方法是 __new__,这是一个类方法,以特殊方法对待,因此不必使用@classmethod装饰器。python 创建对象的过程用伪代码可以概括为
def make(the_class,some_arg):
new_object = the_class.__new__(some_arg)
if isinstance(new_object, the_class):
new_object.__init__(some_arg)
return new_object
# 以下两个语句的作用基本相同
x = Foo('bar')
x = make(Foo, 'bar')
在python中,函数和类通常可以互换,因为二者都是可调用对象,而且python没有实例化对象的new 运算符,调用构造函数和调用工厂函数没有区别。此外,只要能返回新的可调用对象,取代被装饰的函数,二者都可以用作装饰器。
__init_subclass__ 是python面向对象编程里的一个魔法方法,它在初始化子类时被调用。在 __new__ 函数的内部,会检测要创建的类所继承的父类,有没有定义 __init_subclass__。如果有,则执行。可用于检查子类的定义是否符合要求,比如要求子类必须实现某个方法
动态方法
猴子补丁,在运行时修改类或模块,而不改变源码。
def set_card(deck, position, card): # python 方法说到底就是普通函数,第一个参数命名为self 只是约定
deck._cards[position] = card
FrenchDeck.__setitem__ = set_card
# 等同于
class FrenchDeck:
def set_card(self,position, card):
deck._cards[position] = card
在抽象基类上调用register 方法,注册的类就成了抽象基类的虚拟子类。issubclass 能够识别这种关系。类的继承关系是在一个名为 __mro__的特殊类属性中指定的,它会按顺序列出类及其超类,python 会按这个顺序搜索方法。
A.register(B)
@A.register # A.register 也可以作为装饰器使用
class B:
slots
__slots__关键字究竟是做什么的呢?
- 限制用户的使用。我们都知道Python是一门非常灵活的动态语言,很多在其他语言看起来完全不能容忍的事情在Python当中是可行的,这也是Python的设计理念,为了灵活和代码方便牺牲了效率。比如类的成员甚至可以在类创建好了之后动态创建。这在静态语言当中是绝对不行的,我们只能调用类当中已有的属性,是不能或者很难添加新属性的,从一方面来看,这当然非常灵活,但是另一方面,这也留下了隐患。如果用户随意添加属性,可能会导致未知的问题,尤其在复杂的系统当中。所以有些时候为了严谨,我们会不希望用户做这种动态的修改。__slots__正是用来做这个的。
class Exp: def __init__(self): self.a = None self.b = None if __name__ == "__main__": exp = Exp() exp.c = 3 # 运行了之后它会将c添加进这个实例当中 print(exp.c) class Exp: __slots__ = ['a', 'b'] # 运用__slots__这个关键字当中定义的成员,对于没有定义的成员不能随意创建,这样就限制了用户的使用。 def __init__(self): self.a = None self.b = None if __name__ == "__main__": exp = Exp() exp.c = 3 # 得到一个报错,提示你Exp这个对象当中并没有c这个成员 print(exp.c) - 节省内存。虽然现在大部分人使用这个关键字都是报着第一个目的,但是很遗憾的是,Python创建者的初衷其实并不是这个。如果了解过Python底层的实现原理,你会发现在Python当中为每一个实例都创建了一个字典,就是大名鼎鼎的__dict__字典。正是因为背后有一个字典,所以我们才可以创造出原本不存在的成员,也才支持这样动态的效果。使用dict来维护实例,会消耗大量的内存,额外存储了许多数据,而使用__slots__之后,Python内部将不再为实例创建一个字典来维护,而是会使用一个固定大小的数组,这样就节省了大量的空间。这个节省可不是一点半点,一般可以节省一半以上。也就是说牺牲了一定的灵活性,保证了性能。
property
作为一个前Java程序员为类当中所有变量加上get和set方法几乎成了政治正确,但是这是不对的,加上property是非常耗时的,所以如非必要不要这么做,那么我们又为什么要用到property呢?为了校验变量类型。由于Python是动态语言,并且是隐式类型的,所以我们拿到变量的时候并不知道它究竟是什么类型,也不知道用户为给它赋值成什么类型。所以在一些情况下我们可能会希望做好限制,告诉用户只能将这个变量赋值成这个类型,否则就会报错。通过使用property,我们可以很方便地做到这点。
class Exp:
def __init__(self, param):
self.param = param
@property
def param(self):
return self._param
@param.setter
def param(self, value):
if not isinstance(value, str):
raise TypeError('Want a string')
self._param = value
对于 setattr和getattr,我们不禁有一个问题,我们通过.操作不香吗,为什么还要搞一个setattr和getattr出来呢?如果我们自己写代码写着玩,当然是用.操作更方便,但如果是实际的开发场景。很有可能我们需要添加的属性的名称是个变量,而不是写死的,也就是说是可配置的。这个时候就不能通过.了。
描述器/Descriptor
Descriptor允许我们自定义对象属性的访问方式。简单来说,描述器就是一个实现了描述器协议的类,让我们能够在获取、设置或删除属性时自动触发这些特殊方法。描述器协议定义了四个关键方法:
__get__(self, obj, objtype=None): 当获取属性时调用
__set__(self, obj, value): 当设置属性时调用
__delete__(self, obj): 当删除属性时调用
__set_name__(self, owner, name): 在类创建时调用,用于获取描述器在类中的名称
使用描述器时需要注意以下几点:
- 描述器应该是类属性,而不是实例属性。
- 注意数据描述器和非数据描述器的优先级差异
- 合理使用 set_name 方法来获取描述器的名称
- 避免在描述器中保存实例相关的状态
- 使用 dict 存储实例特定的数据
- 考虑使用 weakref 来避免内存泄漏
未搞懂:比装饰器更适合处理需要维护状态的场景。
元类
在Python中“一切皆对象”,类也是对象,所有的类的根本来源就是type,当你创建一个类而没有显式指定元类,则默认使用 type 元类。也就是说Python当中的每一个类都是type的实例。type是Python当中内置的元类,我们也可以自己创建我们需要的元类。通过元类,我们创建的对象也是一个类,而不是一个实例。
因为类也是对象,你可以在运行时动态的创建它们,就像其他任何对象一样。
>>> def choose_class(name):
… if name == 'foo':
… class Foo(object):
… pass
… return Foo # 返回的是类,不是类的实例
… else:
… class Bar(object):
… pass
… return Bar
…
>>> MyClass = choose_class('foo')
>>> print MyClass # 函数返回的是类,不是类的实例
<class '__main__'.Foo>
但这还不够动态,因为你仍然需要自己编写整个类的代码。由于类也是对象,所以它们必须是通过什么东西来生成的才对。当你使用class关键字时,Python解释器自动创建这个对象。但就和Python中的大多数事情一样,Python仍然提供给你手动处理的方法。这里,type有一种完全不同的能力,除了使用 class 关键字正常创建类,它能动态的创建类。type可以接受一个类的描述作为参数,然后返回一个类。
# 创建一个类常规方式
class Duck(object): # 继承自object,通常object也可以不写
def quack(self):
print("GaGaGa!")
# 通过type实例化创建一个类,type函数接收3个参数,分别是类型的名称,父类的元组(实现类的继承),以及一个字典。
def quack(self):
print("GaGaGa!")
Duck = type("Duck", (object, ), {'a': 1, 'quack': quack}) # 注意,type返回的结果是一个类,而不是一个实例。创建出来的类与上面等价。
duck = Duck()
也就是说,我们可以先把函数实现,然后再根据任务的需要把这些函数组装成新的类。显然,这和传统的C++以及Java这些静态类型的语言相比,要灵活得多。
当你定义一个类时,Python 会查看该类定义中是否有指定的元类,如果没有显式指定,则默认使用 type 元类。type 不仅仅是一个内置函数,它还是所有类的默认元类。为什么使用元类? 元类的主要用途包括:
- 动态地修改类(比如添加或改变类的属性和方法)
- 控制实例创建过程
- 实现类级别的插件机制
- 确保类遵守特定接口或规则(类的模板)
创建对象的过程
在Python当中__init__并不是构造函数,__new__才是。如果__new__才是构造函数,那么为什么我们创建类的时候从来不用它呢?首先我们回顾一下__init__的用法,我们随便写一段代码:
class Student:
def __init__(self, name, gender):
self.name = name
self.gender = gender
我们换一个问题,我们在Python当中怎么实现单例(Singleton)的设计模式呢?怎么样实现工厂呢?从这个问题出发,你会发现只使用__init__函数是不可能完成的,因为__init__并不是构造函数,它只是初始化方法。也就是说在调用__init__之前,我们的实例就已经被创建好了,__init__只是为这个实例赋上了一些值。如果我们把创建实例的过程比喻成做一个蛋糕,__init__方法并不是烘焙蛋糕的,只是点缀蛋糕的。那么显然,在点缀之前必须先烘焙出一个蛋糕来才行,那么这个烘焙蛋糕的函数就是__new__。我们来看下__new__这个函数的定义,我们在使用Python面向对象的时候,一般都不会重构这个函数,而是使用Python提供的默认构造函数,Python默认构造函数的逻辑大概是这样的:
def __new__(cls, *args, **kwargs):
return super().__new__(cls, *args, **kwargs)
从代码可以看得出来,函数当中基本上什么也没做,就原封不动地调用了父类的构造函数。这里隐藏着Python当中类的创建逻辑,是根据继承关系一级一级创建的。根据逻辑关系,我们可以知道,当我们创建一个实例的时候,实际上是先调用的__new__函数创建实例(如果没写则用父类的__new__方法),然后再调用__init__对实例进行的初始化(自己有就用自己的,没有就用父类的)。那么我们重载__new__函数可以做什么呢?一般都是用来完成__init__无法完成的事情,比如前面说的单例模式,通过__new__函数就可以实现。我们来简单实现一下:
class SingletonObject:
def __new__(cls, *args, **kwargs):
if not hasattr(SingletonObject, "_instance"):
SingletonObject._instance = object.__new__(cls)
return SingletonObject._instance
def __init__(self):
pass
当然,如果是在并发场景当中使用,还需要加上线程锁防止并发问题,但逻辑是一样的。除了可以实现一些功能之外,还可以控制实例的创建。因为Python当中是先调用的__new__再调用的__init__,所以如果当调用__new__的时候返回了None,则实例的__init__方法不会被执行,最后得到的结果也是None。通过这个特性,我们可以控制类的创建。比如设置条件,只有在满足条件的时候才能正确创建实例,否则会返回一个None。除此之外,另一个经常使用__new__场景是元类。PS: 在java中,工厂模式一般伴随着构造方法私有化,即用private修饰构造方法。
在Python中“一切皆对象”,object是一切类的父类(包括type这个类),所有的类都直接或间接地继承自object,当你创建一个简单的类而不指定父类时,它隐式地继承自object。它是所有Python对象的共同祖先,确保了所有对象具有一些最基本的方法和属性,比如__str__, __repr__, __del__等。object的存在为Python的所有对象提供了一个统一的基础,使得所有对象可以共享一些基本行为。它也是面向对象编程中多态性的基石之一,因为所有对象都可以被视为object的实例。
class Foo(Bar):
pass
那么是不是说类其实也是一个对象呢?类也是对象(类对象),生成类对象的类可称之为元类。所以,元类就是来创建类对象的,可称之为类工厂。创建类的时候(定义class Foo的时候),Python会在内存中通过metaclass创建一个名字为Foo的类对象(我说的是类对象,请紧跟我的思路)。如果Python没有找到metaclass,它会继续在Bar(父类)中寻找metaclass属性,并尝试做和前面同样的操作。如果Python在任何父类中都找不到metaclass,Python就会用内置的type来创建这个类对象。也就是调用了元类/type的__new__方法为这个类分配内存空间,创建好了之后再调用元类/type的__init__方法初始化(做一些赋值等)。所以metaclass的所有magic其实就在于这个__new__方法里面了。简单来说,我们比较熟悉的流程是”类创建对象”,在引入元类后就变成”元类创建类,类再创建对象”。我们实例化一个类时(执行foo=Foo() 的时候),调用其元类的__call__方法。因此,元类对类和对象都有控制力:元类的__new__方法可实现在元类创建类的过程中加工类,元类的__call__方法可实现在元类创建的类创建对象的过程中加工对象。
| 类 | 对象 | |
|---|---|---|
| 创建 | 元类/type.new/init | 类.new/init |
| 执行 | 类() ==> 元类/type.call | 对象() ==> 类.call |
一般来说,定义的元类应该重新实现__init__()与__new__()方法。
- 如果需要修改类的属性,使用元类的
__new__方法 - 如果只是做一些类属性检查的工作,使用元类的
__init__方法。
class AddInfo(type):
def __new__(cls, name, bases, attr):
attr['info'] = 'add by metaclass'
return super().__new__(cls, name, bases, attr)
class Test(metaclass=AddInfo):
pass
根据上面的逻辑,Test类在创建的时候就被赋予了类属性info。
事实上,__metaclass__实际上可以被任意调⽤,它只是规定了类“按照什么样的规则去生成”,并不需要是⼀个正式 的类。比如,我们有一个比较二的需求:你决定在你的模块⾥,所有的类的属性都应该是⼤写形式。
>>> def upper_attr(future_class_name, future_class_parents, future_class_attr):
... """遍历属性字典,把不是__开头的属性名字变为⼤写"""
... newAttr = {}
... for name,value in future_class_attr.items():
... if not name.startswith("__"):
... newAttr[name.upper()] = value
... return type(future_class_name, future_class_parents, newAttr)
>>> class Foo(object, metaclass=upper_attr):
... bar= 'bip'
其实在开头引用TimPeters的话(元类就是深度的魔法,99%的⽤户应该根本不必为此操⼼。如果你想搞清楚 究竟是否需要⽤到元类,那么你就不需要它。那些实际⽤到元类的⼈都⾮常 清楚地知道他们需要做什么,⽽且根本不需要解释为什么要⽤元类。)就说明,不要随意在生产代码中使用元类,而且现有的编码规范也极不推荐使用。代码可读性不高,不易维护。
PS:改变已有代码类的行为,java一般是创建代理类(直接干活儿的类已经被换掉了),python更绝一点,直接改类的字段、方法成员。在哪里改呢?python是通过继承某个父类即可,而java 则只能通过spring ioc在初始化bean的时候玩花活儿。
以ORM为例
元类的作用:比如ORM框架是后端工程师常用的一个框架,它的英文全称是Object Relational Mapping,即对象-关系映射框架。ORM框架做的事情是将这些关系映射成类,这样我们可以将这张表当中增删改查的功能抽象成类当中的方法。这样我们就可以通过调用类的方式来操作数据库了,从而达到高度抽象业务逻辑、降低用户使用难度的目的。
class User(Model):
# 定义类的属性到列的映射:
id = IntegerField('id')
name = StringField('username')
email = StringField('email')
password = StringField('password')
我们希望User类型的实例就对应User表当中的一条记录,并且我们可以通过调用实例当中的方法,来操作这张表进行增删改查。
# 创建一个实例:
u = User(id=12345, name='Michael', email='test@orm.org', password='my-pwd')
# 保存到数据库:
u.save()
最关键的部分就是Model类的实现。我们先来分析一下我们希望Model这个类拥有的功能,由于它是我们定义出来的每一张表的父类,所以它应该能够获取子类当中的字段,并且将它存放在一个容器当中。由于我们需要存储的是字段名和类型的映射,所以将它存储在dict当中比较合理。另外一个功能是我们希望它能够提供增删改查的接口,能够根据子类当中定义的字段自动生成相应的SQL语句去调用数据库。这个也是ORM框架的意义所在。
第一个功能有些麻烦,它也是元类的意义所在。因为父类当中的方法是无法获取子类中定义的类属性的,只能通过元类,在构建类的时候可以拿到属性的信息。
class ModelMetaclass(type):
def __new__(cls, name, bases, attrs):
# 创建model类的时候不做任何处理
if name=='Model':
return type.__new__(cls, name, bases, attrs)
# 打印表名的信息
print('Found model: %s' % name)
# mappings用来存储字段的信息
mappings = dict()
for k, v in attrs.items():
# 判断v的类型,只有是Field的子类才会存储起来
if isinstance(v, Field):
print('Found mapping: %s ==> %s' % (k, v))
mappings[k] = v
# 将mappings当中的数据从类属性当中移除,防止关键字冲突
for k in mappings.keys():
attrs.pop(k)
attrs['__mappings__'] = mappings # 保存属性和列的映射关系
attrs['__table__'] = name # 假设表名和类名一致
return type.__new__(cls, name, bases, attrs)
为Model 新增crud 方法
class Model(dict, metaclass=ModelMetaclass):
def __init__(self, **kw):
# 由于Model的基类是dict,所以创造Model的字段会被解析成dict的构造参数
# 也就是说字段名和字段值的映射会存储在dict当中
super(Model, self).__init__(**kw)
def __getattr__(self, key):
try:
return self[key]
except KeyError:
raise AttributeError(r"'Model' object has no attribute '%s'" % key)
def __setattr__(self, key, value):
self[key] = value
def save(self):
fields = []
params = []
args = []
for k, v in self.__mappings__.items():
# fields存储字段名
fields.append(v.name)
# params填充问号
params.append('?')
# 获取字段的值
args.append(getattr(self, k, None))
sql = 'insert into %s (%s) values (%s)' % (self.__table__, ','.join(fields), ','.join(params))
print('SQL: %s' % sql)
print('ARGS: %s' % str(args))
在整个ORM框架实现的过程当中,最重要的是我们对Model这个类创建了元类,但是真正应用的地方却是在Model的子类。实际上在实际创建User类的时候,解释器会先搜索User内部是否定义了元类,如果没有,会上一层去往User的父类也就是Model类搜索元类,如果找到了元类,就会使用元类来创建User。相当于元类被隐形地继承了下来,但是我们在使用子类的时候却感知不到。
元类的概念和动态类、动态语言的概念有关,如果我们把Python的元类和装饰器做一个类比的话,会发现两者的核心逻辑是很类似的。本质上都是在原有的逻辑之外封装新的逻辑,只不过装饰器针对的是一段逻辑,而元类针对的是类的属性和创建过程。
其它
在Lisp或Dylan中, 23个设计模式中有16个的实现方式比在C++中更简单,而且能保持同等质量。 有时,设计模式或API要求组件实现单方法接口,而该方法有一个很宽泛的名称,例如execute、run、do_it。在python中,这些模式或api通常可以使用作为一等对象的函数实现,从而减少样板代码。
classmethod 最常见的用途是定义备选构造函数,staticmethod 修饰的函数就是普通函数,只是碰巧位于类的定义体中,而不是在模块层定义。