简介
- 简介
- 从训练机器人行走开始
- 什么是强化学习
- actor-critic
- llm与强化学习
- Policy Gradient(策略梯度)
- PPO(Proximal Policy Optimization)
- Group Relative Policy Optimization(群体相对策略优化)
- GSPO
- 其它
强化学习的目标是找到一个「策略」,所谓策略,就是「在某个环境状态下,需要采取某个动作」。这里的「学习」二字,可以借由「机器学习」的概念去理解,你可以笼统地认为为是「用一个函数去逼近这个策略」。而「神经网络」就可以看做是这个函数逼近器。而「强化」二字,可以借由「控制系统」的概念去理解,RL 算法是构建一个「闭环控制系统」,其目标是通过与环境的交互来优化决策。在不断地「采样-评估-更新」过程中,找到或逼近解一个高维动态规划问题的「最优策略」,其本质是求解由随机过程和不完全信息耦合所带来的高维优化问题。在这个视角下,RL的数学本质可以概括为:构建闭环的学习系统,利用反馈信息去逼近策略函数。PS:「闭环」是控制系统中的概念,具有反馈环节,能够感知系统输出的变化,并根据输出的变化进行调整。与之相对的是「开环」概念,没有反馈环节。
PS:单单是rl 强化学习本身的推导就是一门很厚的知识,搞明白actor-critic 就有百分之七八十了,之后是ppo 针对actor-critic 的一些调整,可以直接看PPO理论推导+代码实战
从训练机器人行走开始
策略梯度法入门—强化学习该例是要设计一个两腿机器人,使其能自动的行走。机器人左右腿的跨、膝、踝共有6个关节,都装有小电机,希望能自动控制它的6个小电机,使机器人能和人一样正常的行走。
强化学习需要一个软件系统,其基本组成包括:
- 代理(Agent智能体):是个软件,相当于机器人的大脑,是强化学习的核心。它可以接受环境状态的信息,还可以将计算的结果传输给环境。其中,负责计算的是个函数,称作策略(policy),是强化学习最重要的部分。
-
环境(Environment):代理以外的部分都是环境。和通常的环境概念不同,机器人所处的周边当然是环境,不同的是,机器人的躯体四肢都在代理之外,也都归于环境,比如躯干的高度,各个腿及各个关节的位置、速度等。此例中,环境状态使用31个观测值。包括
- 躯干沿Y和Z轴方向的坐标值,
- 躯干沿X、Y和Z方向的速度,
- 躯干旋转的角度和角速度,
- 6个关节的角度和角速度,
- 脚和地面之间的接触力。
- 状态(State):指环境的状态。机器人一直在移动,所以,周围环境的状态,以及自身各关节的状态也在不断的变化。
- 行动(Action):指代理根据当前状态采取的动作,比如机器人向左或向右,向前或向后移动等。
- 奖励(Reward):代理在当前状态下,采取了某个行动之后,会获得环境的反馈,称作奖励。但可能是奖励,也可能是惩罚,实际是代理对行动的评价。在强化学习中,奖励非常重要,因为样本没有标签,所以奖励起到引领学习的作用。
使机器人正常行走要做的工作。让两腿机器人正常行走,要做的工作是,用正确的指令控制每个关节,使机器人的腿和躯干正确的移动,这需要有六个关节的扭矩指令。在给定的环境状态下,如何得到正确的指令,这就是强化学习要做的工作。用传统方法开发机器人的行走程序,要人工设计逻辑、循环、控制器及参数等等,需要很多的环路,非常复杂。而强化学习的思想极为简单,它不考虑整个过程的具体步骤,不进行一步步的具体设计,而是把这一切复杂工作都塞到一个函数里,这个函数称作策略函数。策略收到环境传来的31个状态值,会自动计算出6个可供执行的指令,指令正确,机器人就会正常的行走。可以看出,强化学习中,机器人能正常行走的关键,就是这个策略函数。
所以下面的重点是:智能体里的策略函数是什么形式?它如何进行学习?如何通过环境状态值计算出6个正确的指令,使机器人能正常的行走。
- 策略是个函数,因其过于复杂,很难用显性的公式来表式。对于这种连续且复杂的问题,强化学习是采用功能强大的神经网络来近似这个函数。这里策略神经网络是用的多层感知机(最基本的前馈神经网络),并以此为例进行说明。
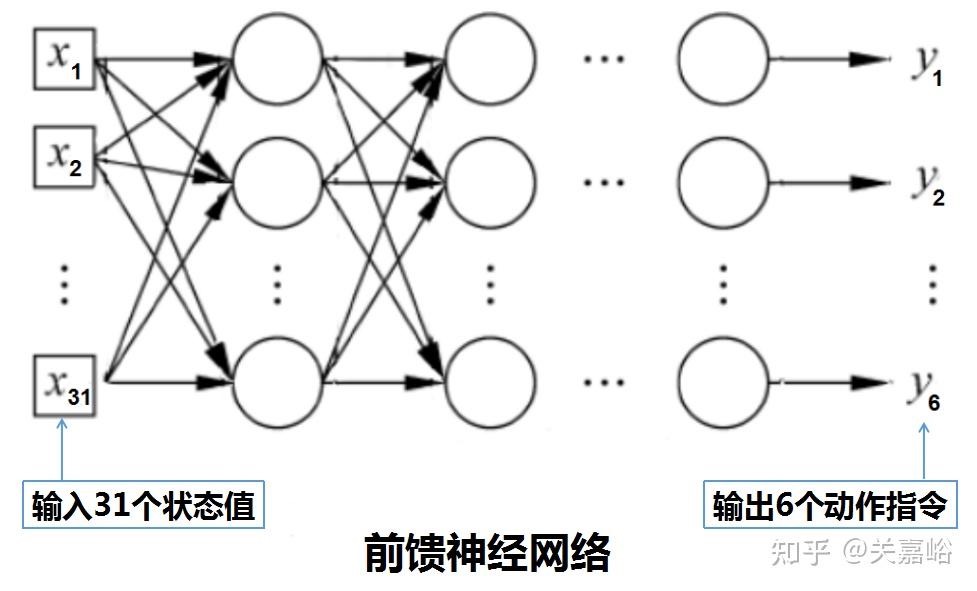 神经网络包含多个隐藏层,每层都有数百个神经元,没有足够多的神经元,网络无法拟合这么复杂的非线性函数,不可能将31个观察值正确的映射到6个动作。但是,神经元过多,将花费更多的时间训练,还容易得到过拟合的逻辑。所以,如何选择网络结构,包括网络层的数量,各层如何连接,以及每层神经元的数量等等,需要丰富的经验和知识找到最佳平衡点,使训练即可行又有效。
神经网络包含多个隐藏层,每层都有数百个神经元,没有足够多的神经元,网络无法拟合这么复杂的非线性函数,不可能将31个观察值正确的映射到6个动作。但是,神经元过多,将花费更多的时间训练,还容易得到过拟合的逻辑。所以,如何选择网络结构,包括网络层的数量,各层如何连接,以及每层神经元的数量等等,需要丰富的经验和知识找到最佳平衡点,使训练即可行又有效。 - 神经网络的学习过程。策略函数的学习过程,可以选择仿真或真实行走的方式。方法是让机器人不断的行走,不断的调整策略函数里的参数w和b,直至得到能使机器人正常行走的网络模型(策略函数)。一般前馈网络的学习,样本都有标签(标准答案),在一次前向传播后,计算出结果,先求计算结果与标签的误差(损失函数),再求损失函数对各个节点的偏导数(梯度),然后求出损失函数对各个参数w和b的偏导数,用这些参数的偏导数来调整各个参数。但是,强化学习是以状态观测值作为输入(样本),没有标签,当然也就没有损失函数,那么求谁的梯度(偏导数)?没有梯度怎么修改参数w和b?强化学习的作法是设计一个奖励函数,用动作的奖励函数作准则,来调整网络的参数。强化学习里奖励函数的作用,相当于一般神经网络里的损失函数。做法是,每输入31个环境状态值,用策略函数计算出6个动作指令,然后执行这6个动作指令,当然这会改变了环境的状态值,包括躯干和6个关节的位置和速度等,然后再计算这个动作的奖励函数值,通过提高奖励函数值来调整网络的各个参数w和b。注意,不是像一般前馈网络学习那样,通过减小损失函数来调整参数w和b。
- 奖励函数。奖励函数是人工精心设计的,其作用相当于前馈网络或循环网络的标签,是引导机器人正常行走的根据。此例已经设计好的奖励函数是$ r_t = v_x -3y^2 - 50z^2 + 25xx - 0.22xx $,其中 $v_x$ 是前进速度,$v_x$ 越大,机器人走得越快。y是侧向位移,使机器人沿着一条直线移动,不向左右偏移,越小越好。z是机器人重心的垂直位移,是要机器人的躯干保持一定的高度,不摔倒、不跳跃或蹲着走路,越小越好。其余设置,这里不逐一深究。总之,这个奖励函数值越大,机器人走的就越好。奖励函数非常重要,但其设置是个难点,需要丰富的经验和专业知识。
- 策略函数的学习过程。现在,策略函数是一个神经网络(多层感知机),策略能否做出正确的动作指令,取决于网络里的所有参数w和b。而评价一个动作优劣的标准,是这个动作的奖励函数,奖励函数的值越高,该动作就越好。所以,强化学习是求出奖励函数对各个参数w和b的梯度,让参数w和b沿着奖励函数的梯度方向调整,这样奖励函数值就会升高,下一次遇到同样的环境状态,策略计算出的指令就会更好。就这样,反复的调整参数w和b,最终得到一个可以时时做出正确指令的神经网络。
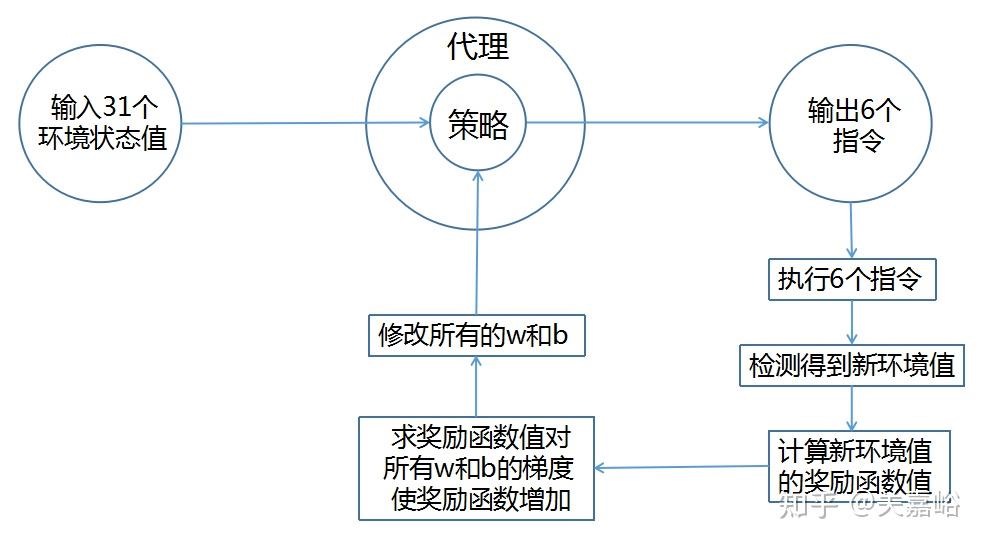 具体作法大意是
具体作法大意是
- 输入31个环境值;
- 网络计算得到6个指令,执行指令改变了环境,检 测得到了31个新环境值;
- 用检测到的31个新环境值,求奖励函数对各个参数w和b的梯度(偏导数),即反向传播;
- 修改网络所有的参数w和b;
- 返回到1,进行下一循环学习。 就这样,代理不断与环境交互,不断修改策略的参数,最终,在任何状态情况下,它都会采取最有利的行动。强化学习的过程,就是不断优化这个策略的过程,整个过程,是计算机自己在学习正确的参数,实际是个反复优化完善网络的过程。上述2执行6个指令后得到的新环境状态值,是环境检测出来的,和策略网络没有连在一起,用它求奖励函数值没问题,直接代入就行。但用这个新环境状态值对各个参数w和b求偏导数,就有问题了,因为它和策略网络根本没连接上。
PS: rl和dl都是在想办法,算一个loss,优化w和b。
什么是强化学习
强化学习(Reinforcement Learning, RL)是一种机器学习方法,模型通过与环境的交互来学习决策策略。模型在每一步的选择中会得到奖励或惩罚,目标是最大化长期的累积奖励。在自然语言处理(NLP)中,强化学习可以用于优化模型的输出,使其更符合期望的目标。强化学习算法主要以原来的训练结果为基础,只是不断调整新的处理结果与目标问题(强化学习算法本身的专业术语叫“环境”)之间的偏差(专业术语叫“奖励”)。
RL包含行动、 环境、观察、奖励机制等模块,奖励机制是RL 具有特色的模块,在奖励机制出现之前,众多机器学习算法是通过损失函数的梯度更新来进行模型学习的,这种损失函数优化效果带来的是模型直接收益反馈,然而不同于传统机器学习任务的单一任务分析,针对复杂环境的分析以及任意动作的带来的奖励反馈极为动态,比如我们在驾驶场景,方向盘多转动5度所带来的奖励收益是极为复杂的,这也让众多传统机器学习算法无法对上述任务进行建模。如何设计良好的奖励机制,是强化学习系统算法建模之前就要想清楚的问题。RLHF的做法是不再像原有RL依赖机器计算奖励反馈,而是利用人工计算奖励反馈,所以该算法框架才被定义为基于人类反馈的强化学习框架。
强化学习是一种机器学习方法,它通过让智能体在环境中执行动作,以获得反馈或奖励信号,从而学习最优策略。通过不断地试错和调整策略,智能体逐渐找到能够最大化长期回报的行为路径。这种学习方法常用于需要决策和动态环境交互的任务,如游戏、机器人导航和自动化控制系统。想象一下,你有一只机器狗,它已经在基本的狗行为上进行了初步训练,比如行走和听从简单的命令。
- 微调就像是对这只机器狗进行进一步的训练以适应特定的任务环境。比如说,你希望这只机器狗能够在公园里捡回特定种类的球。通过微调,你可以在原有的训练基础上,用一组特定的数据集(比如各种颜色和大小的球)来调整其行为,使其在新环境中表现得更好。
- 强化学习训练则有点像是教这只机器狗通过尝试和错误来学习新技能(通常不依赖于预定义的数据集,而是依赖于与环境的持续交互。)。在这种情况下,你没有直接告诉它应该怎么做,而是为它设定一个目标,比如尽可能快地找到并捡起一只球。机器狗每完成一次任务都会获得奖励,然后它将通过调整自己的行为来最大化获得的奖励。例如,如果机器狗发现跑直线能更快地找到球,它可能会在未来的尝试中更倾向于这样做。
o1核心作者MIT演讲:激励AI自我学习,比试图教会AI每一项任务更重要
- 激励AI自我学习比试图教会AI每一项具体任务更重要。如果尝试以尽可能少的努力解决数十个任务,那么单独模式识别每个任务可能是最简单的;如果尝试解决数万亿个任务,通过学习通用技能(例如语言、推理等)可能会更容易解决它们。“授人以鱼不如授人以渔”,用一种基于激励的方法来解决任务。Teach him the taste of fish and make him hungry.(教AI尝尝鱼的味道,让他饿一下)然后AI就会自己出去钓鱼,在此过程中,AI将学习其他技能,例如耐心、学习阅读天气、了解鱼等。其中一些技能是通用的,可以应用于其他任务。面对这一“循循善诱”的过程,也许有人认为还不如直接教来得快。但在Hyung Won看来:对于人类来说确实如此,但是对于机器来说,我们可以提供更多的计算来缩短时间。换句话说,面对有限的时间,人类也许还要在专家 or 通才之间做选择,但对于机器来说,算力就能出奇迹。
- 此外,他还认为当前存在一个误区,即人们正在试图让AI学会像人类一样思考。但问题是,我们并不知道自己在神经元层面是如何思考的。机器应该有更多的自主性来选择如何学习,而不是被限制在人类理解的数学语言和结构中。在他看来,一个系统或算法过于依赖人为设定的规则和结构,那么它可能难以适应新的、未预见的情况或数据。造成的结果就是,面对更大规模或更复杂的问题时,其扩展能力将会受限。
PPO理论推导+代码实战 建议细读。
从目标到梯度
强化学习整体流程
- 强化学习的两个实体:智能体(Agent)与环境(Environment)
- 强化学习中两个实体的交互:
- 状态空间S:S即为State,指环境中所有可能状态的集合
- 动作空间A:A即为Action,指智能体所有可能动作的集合
- 奖励R:R即为Reward,指智能体在环境的某一状态下所获得的奖励。
RL的目标是什么?$max J = E_\tau[R]$,$\tau$是轨迹, $R$是该轨迹得到的奖励之和。这个定义简单易懂:我们需要在可达轨迹的分布下最大化能得到的奖励。 $R$有多种表现形式。
- 最简单的形式是折扣奖励 $R=\sum \gamma^tr_t$,其中t是离初始状态的距离,r是从上一步转移到当前状态的奖励。
- R也可以被定义为价值函数V,这种情况下E的下标要变成初始状态$s_0$,即初态的稳态分布。
智能体与环境的交互过程如下:
- 在 t 时刻,环境的状态为 $S_{t}$ ,达到这一状态所获得的奖励为 $R_{t}$
- 智能体观测到 $S_{t}$ 与 $R_{t}$ ,采取相应动作 $A_{t}$
- 智能体采取 $A_{t}$ 后,环境状态变为 $S_{t+1}$,得到相应的奖励 $R_{t+1}$。
$R_{t}$ 表示环境进入状态 $S_{t}$ 下的即时奖励。但如果只考虑即时奖励,目光似乎太短浅了:当下的状态和动作会影响到未来的状态和动作,进而影响到未来的整体收益。所以,一种更好的设计方式是:t时刻状态s的总收益 = 身处状态s能带来的即时收益 + 从状态s出发后能带来的未来收益。写成表达式就是:$V_t = R_t + \gamma V_{t+1}$。其中:
- $V_{t}$ : t 时刻的总收益,注意这个收益蕴涵了“即时”和“未来”的概念。
- $R_{t}$ : t 时刻的即时收益
- $V_{t+1}$ : t+1 时刻的总收益,注意这个收益蕴涵了“即时”和“未来”的概念。而 $V_{t+1}$ 对 $V_{t}$ 来说就是“未来”。
- $\gamma$:折扣因子。它决定了我们在多大程度上考虑将“未来收益”纳入“当下收益”。 上帝视角的客观收益我们是不知道的,只能用已知事实数据去逼近它,所以我们就用 $R_t + \gamma V_{t+1}$ 来做近似。
如果从当前状态$s_t$出发,状态和动作交替构成的序列,用 $\tau$表示,$ \tau = (s_t,a_t,s_{t+1},a_{t+1},s_{t+2},a_{t+2},…)$,则$R(\tau ) = r_{t+1}+ \gamma r_{t+2} + \gamma^2 r_{t+3} + \gamma^3 r_{t+4} + … = \sum_{k=0}^{\infty} \gamma^kr_{t+k+1}$,从某一时刻开始的所有未来奖励的累积,一般使用累积折扣奖励作为回报$G_t$,即$G_t=\sum_{k=0}^{\infty} \gamma^kr_{t+k+1}$
机器学习广泛地运用梯度求极值。那么$J$的梯度该如何计算?速通RL基础
算法分类
强化学习就是在与环境的交互中获得反馈,不断更新模型,最大化整个过程的累积奖励(的期望,关于轨迹的回报的期望,期望一定是关于概率分布的)。但是具体到底怎样让智能体选择合适的动作来最大化期望奖励呢,根据对环境的了解情况,可以分成两个部分:Model-based 以及 Model-free.
- Model-based:环境是一个白盒(每种状态对应的反馈已知、转移概率已知,等等),可以基于此设置策略。行为因此也受限于对环境的认知。Model-based 一族有 Value iteration, Policy iteration 等算法。
- Model-free:环境是一个黑盒,只能通过环境基于的反馈进行学习。大多数常用的 RL 算法,譬如说 Q-learning, Policy gradient,都属于 Model-free。
Model-free 具体分为
- 其中 Value-based 方法不需要一个具体的策略,而是让状态$V_{\pi}(s)$ -动作值函数 $Q_{\pi}(s,a)$ 充当隐式地承担起制定策略的角色,而不是直接优化策略。找到一个最优的价值函数,可以得到一个最优策略(只要衡量出每个动作的价值大小,自然可以采取策略)。PS:value-based 也可以用来筛选训练数据。
- $V_{\pi}(s) = E_{\pi}[G_t \mid S_t =s]$
- $Q_{\pi}(s,a) = E_{\pi}[G_t \mid S_t =s, A_t = a]$
- 优点,学习过程通常更稳定。收敛速度较快,通过贪婪策略可以间接得到最优策略。
- 缺点,只能处理离散且有限的动作空间,并且可能只能找到局部最优解。
- 而 policy-based 方法有一个显式的策略,直接对策略$\pi(a \mid s)$进行建模和优化,这是在给定状态$s$下选择动作$a$的概率分布。让策略和环境交互多次,采样足够多的轨迹数据,来评估策略的价值,再据此决定策略的迭代方向。通过直接训练策略来找到最优策略。策略通常由参数化函数表示,如神经网络$\pi_{\theta}(a \mid s)$,其中$\theta$ 是需要学习的参数,通过最大化预期累积奖励$G_t$,对$\theta$进行优化。
- 优点,能够学习随机策略;适用于高维或连续的动作空间;通常能找到全局最优解。
- 缺点,通常收敛速度较慢,且评估策略的效果(如通过蒙特卡洛方法)可能具有高方差,导致学习过程不稳定。
- actor-critic(比如PPO)结合了基于策略和基于价值的优点
- actor 代表策略部分,负责生成动作。actor直接建模策略$\pi(a \mid s)$,并根据 Critic 的反馈调整策略参数,以优化长期奖励。
- critic,代表价值部分,负责评估采取的动作。actor根据 Critic 的反馈调整策略参数,以优化长期奖励。
Actor-Critic架构为什么要有Critic呢?这就涉及强化学习的算法稳定性问题。与监督学习(SL)相比,RL实际上是很难稳定的一类训练机制。大致的原因如下:
- RL本身是处理动态系统的最优控制问题,而SL是处理一个静态优化问题。动,就比静更难处理。
- 加上RL的数据非稳态,Env-agent交互机制的数据采集量少,这使得梯度计算的方差更大,方差一大就容易偏离预期目标,算法就容易跑飞了。主流的强化学习算法是怎么解决这一问题的呢?加上Critic,使用State-value function或者Action-value function稳定策略梯度的计算过程。更高级一些的算法是采用Advantage Function,也就是加上了Baseline,增加梯度计算的稳定性。这是AC算法总是优于REINFORCE算法的原因之一。
- 如果没有Critic,PPO只能使用蒙特卡洛的完整轨迹回报(高方差)或单纯依赖即时奖励(短视),导致训练低效甚至失败。Critic的引入使得PPO能通过时序差分(TD)学习高效地估计价值,平衡偏差与方差。 PS: 配套的actor-critic 架构就得有actor model 和critic model
The Definitive Guide to Policy Gradients in Deep ReinforcementLearning:Theory, Algorithms and Implementations Policy Gradient 论文综述。
actor-critic
PPO理论推导+代码实战 建议细读。
actor_loss 演变过程
在深度强化学习(Deep RL)中,actor通常是一个神经网络$\pi_{\theta}$,输入是状态$s$,输出动作空间$A$ 中的某个动作, $\theta$是需要学习优化的网络参数,相较于规则定义的actor,神经网络具有比较好的泛化性。
在训练过程中,怎么定义一个策略 $\pi$: state -> action 的好坏呢?自然地,可以根据强化学习的目标得到下式:
\[\theta^* = \underset{\theta}{\arg\max} J_{\pi_{\theta}}\] \[J_{\pi_{\theta}} = E_{\tau \sim \pi_{\theta}} \left[ \sum_{t = 0}^{\infty} \gamma^t r_t \right] = E_{\tau \sim \pi_{\theta}} [R(\tau)] = \sum_{\tau} R(\tau) P(\tau | \pi_{\theta})\]我们定义策略和状态转移都是随机的,优化目标是最大化累积折扣奖励的期望,对应着训练过程中我们需要采样多次轨迹,在足够多的样本基础上评估策略的好坏。
轨迹序列 $\tau$ 是在使用策略 $\pi_{\theta}$ 的情况下采样出来的,由于策略和状态转移都有随机性,$\tau \sim \pi_{\theta}$ 隐藏的完整含义为:
\[a_t \sim \pi_{\theta} (\cdot | s_t)\] \[s_{t + 1} \sim P (\cdot | s_t, a_t)\] \[r_t = R(s_t, a_t, s_{t + 1})\]我们对优化目标计算梯度可以表示为: \(\begin{align*} \nabla J_{\pi_{\theta}} &= \sum_{\tau} R(\tau) \nabla P(\tau|\pi_{\theta}) \\ &= \sum_{\tau} R(\tau) P(\tau|\pi_{\theta}) \frac{\nabla P(\tau|\pi_{\theta})}{P(\tau|\pi_{\theta})} \\ &= \sum_{\tau} R(\tau) P(\tau|\pi_{\theta}) \nabla \log P(\tau|\pi_{\theta}) \\ &= E_{\tau \sim \pi_{\theta}} [R(\tau) \nabla \log P(\tau|\pi_{\theta})] \end{align*}\)
依据定义方式,策略和状态转移都是随机的,同时我们设一条轨迹有 (T) 个 timestep,则有 \(P(\tau|\pi_{\theta}) = p(s_0) \prod_{t = 0}^{T - 1} P(s_{t + 1}|s_t, a_t) \pi_{\theta}(a_t|s_t)\)
其中只有 (\pi_{\theta}(a_t|s_t)) 与 (\theta) 有关,据此我们继续推出: \(\begin{align*} \nabla \log (P(\tau|\pi_{\theta})) &= \nabla \left[ \log p(s_0) + \sum_{t = 0}^{T - 1} \log P(s_{t + 1}|s_t, a_t) + \sum_{t = 0}^{T - 1} \log \pi_{\theta}(a_t|s_t) \right] \\ &= \sum_{t = 0}^{T - 1} \nabla \log \pi_{\theta}(a_t|s_t) \end{align*}\)
综上所述,策略的梯度表达式为 \(\begin{align*} \nabla J_{\pi_{\theta}} &= E_{\tau \sim \pi_{\theta}} [R(\tau) \nabla \log P(\tau|\pi_{\theta})] \\ &= E_{\tau \sim \pi_{\theta}} \left[ R(\tau) \sum_{t = 0}^{T - 1} \nabla \log \pi_{\theta}(a_t|s_t) \right] \end{align*}\)
在实践中,我们可以通过采样足够多的轨迹来估计这个期望。假设采样N条轨迹,N足够大,每条轨迹涵盖$T_n$步,则上述梯度可以再次被写成:
\[\begin{align*} \nabla J(\pi_{\theta}) &= E_{\tau \sim \pi_{\theta}} \left[ \sum_{t = 0}^{T - 1} R(\tau) \nabla \log \pi_{\theta}(a_t | s_t) \right] \\ &\approx \frac{1}{N} \sum_{n = 1}^{N} \sum_{t = 0}^{T_n - 1} R(\tau_n) \nabla \log \pi_{\theta}(a_t | s_t) \end{align*}\]其中$R(\tau_n)$是一条轨迹的累积奖励。由于 $\nabla log \pi_{\theta}(a_t \mid s_t) = \frac{\nabla\pi_{\theta}(a_t \mid s_t)}{\pi_{\theta}(a_t \mid s_t)} $,$\nabla log$ 相当于在每一个动作的梯度下除以采样到这个动作的概率。这样就避免了在采样过程中采到很多奖励值很低但是出现频次高的动作,造成模型对这种低奖励值高频次动作的偏好。 整体而言,相当于用$\pi_{\theta}(a_t \mid s_t)$做了某种归一化。
但并不是表示动作价值的优选,首先,它并没有告诉我们轨迹中某个单独的动作到底好不好,其次,我们在之前提到过由于采样具有随机性,有些动作只是没被采样到,并不代表它们不好,可以减去一个baseline来控制。
Actor loss,我们来另一个直观的loss设计方式:
- Actor接收到当前上文 $S_t$ ,产出token $A_t$ ( $P(A_t \mid S_t)$ )
- Critic根据 $S_t$,$A_t$,产出对总收益的预测$V_t$
- 那么Actor loss可以设计为: $ actor_loss = -{\textstyle\sum_{t \in response_timestep}} V_{t}log P(A_{t} \mid S_{t}) $,求和符号表示我们只考虑response部分所有token的loss。
为了表达简便,我们先把这个求和符号略去(下文也是同理),也就是说:$actor_loss = -V_{t}log P(A_{t} \mid S_{t})$,我们希望minimize这个actor_loss。这个loss设计的含义是,对上下文 $S_t$而言,如果token $A_t$产生的收益较高( $V_t > 0$),那就增大它出现的概率,否则降低它出现的概率。
对NLP任务来说,如果Critic对 $A_{t}$ 的总收益预测为 $V_{t}$ ,但实际执行 $A_{t}$ 后的总收益是 $R_{t} + \gamma * V_{t+1}$,我们就定义优势/Advantage为: $Adv_{t} = R_{t} + \gamma * V_{t+1} - V_{t} $,我们用 $Adv_{t}$ 替换掉 $V_{t}$ ,则此刻actor_loss变为: $actor_loss = -Adv_{t}log P(A_{t} \mid S_{t})$。
$Adv_{t} = R_{t} + \gamma * V_{t+1} - V_{t} $这个就是单步TD误差,本质上是对优势函数 $Adv_{t}$的无偏估计。在RL算法中,常使用TD误差作为优势函数的估计,因为实际上用Critic model,很难提供真实的预期回报$V_{t}$,因为critic model只是用来拟合的一个网络,肯定有偏差。所以可通过多步TD误差的加权平均(GAE) 进一步降低方差。
PS:一些文章提到 critic_model 目的是计算优势值,就是每个action(生成不同token)的相对于baseline(也是critic_model 提供的)的优势。 用优势(相对值)而不是绝对值也更合理,毕竟critic_model不代表客观判断。actor_loss 还在演进,这里没有写完。总归是我们知道,可以给action model 每个token算loss 了。进而是不是可以可以理解为rlhf和sft的反馈粒度都是token?
critic_loss 演化过程
PPO理论推导+代码实战 不如这里详细。
关于critic_loss 第一想法是: $critic_loss =(R_t + \gamma * V_{t+1} - V_{t})^2 $
最小化TD Error(TD误差就是预测误差:实际观察到的和预测的差距)就可以训练一个预测状态价值的Critic model,critic优化是:
\[\arg \min_{V_{\pi}} L(V_{\pi}) = E_t[(r_t + \gamma V_{\pi}(s_{t+1} - V_{\pi}(s_t))^2)]\]Reward Model提供环境的基础反馈信号(即$r_t$),是Critic学习的输入。Critic Model将即时奖励转化为长期价值估计,指导策略优化方向。
- 只有Reward Model:只能提供即时奖励信号(如生成完整句子后的总分数),但无法评估每个 token 或部分响应的长期价值,使策略更倾向于选择长期回报更高的动作。
- 只有Critic Model:若奖励函数未知(如逆强化学习),Critic无法凭空学习价值函数。 在PPO中,Reward Model提供基础的真实反馈,而Critic Model将其转化为长期价值估计,两者缺一不可。
重要性采样
李宏毅深度强化学习 未看
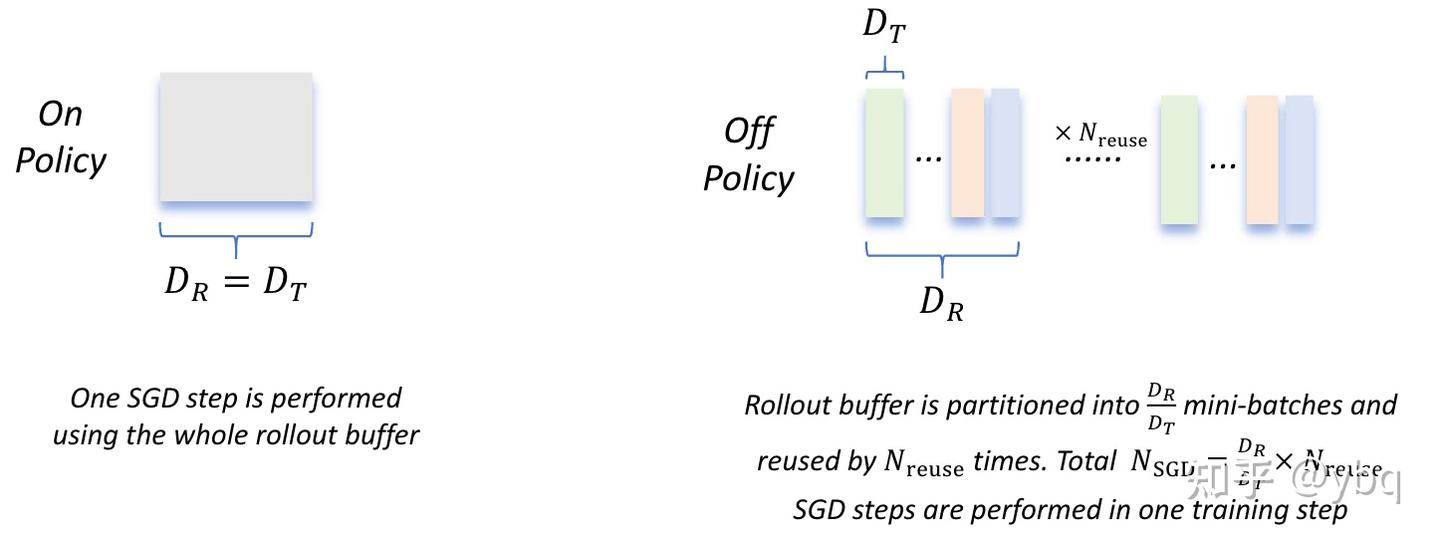
在实践中,我们为了降低采样成本,提升训练效率(采样是训练所需的,主要是不想对新的策略采样到的轨迹再计算奖励和优势),我们希望对得到的一批“经验”进行多次训练,过程如下:
- 假设某次更新完毕后,我们得到策略 $\pi_{old}$
- 我们用$\pi_{old}$和环境交互,得到一批经验数据(主要是状态价值、优势、回报)。
- 我们将把这一批回合数据重复使用k次:即我们先把这批数据喂给 $\pi_{old}$,更新得到$\pi_{\theta_0}$,我们再把同一批数据喂给$\pi_{\theta_0}$,更新得到$\pi_{\theta_1}$;以此类推,做k次更新后,我们得到$\pi_{\theta}$。
- 我们管这个过程叫off-policy(产出数据的策略和用这批数据做更新的策略不是同一个)。
- 在这k次更新后,我们令$\pi_{old} = \pi_{\theta}$。重复上面的过程,直到达到设定的停止条件为止。
但是在我们训练的过程中,由于策略已经发生了改变,采样出来的分布已经变了。正常来说,当我们有两个分布$p(x)$和$q(x)$,但是又无法直接从 $p(x)$采样,我们可以这么描述$x \sim p(x)$下 的期望:$E_{x \sim p(x)}[f(x)] = \int \frac{p(x)}{q(x)} f(x) dx = E_{x \sim q(x)}[\frac{p(x)}{q(x)} f(x)]$,据此我们应该将新的策略梯度调整为:
\[\nabla J(\pi_{\theta}) = \underset{\tau \sim \pi_{\theta_{old}}}{E_t} [ \frac{\pi_{\theta}(a_t | s_t)}{\pi_{old}(a_t | s_t)} A_{\pi}(s_t, a_t) \nabla log \pi_{\theta}(a_t | s_t) ]\]GAE
在训练开始阶段, $V_{\pi}$很有可能无法刻画真实的状态价值,我们可以选择少信任$V_{\pi}$的计算结果,将 $V_{\pi}(s_{t+1})$展开得:
\[r_t + \tau V_{\pi}(s_{t+1}) - V_{\pi}(s_t) = -V_{\pi} + \sum_{l=0}^{\infty} \gamma^l r_{t+l}\]其中,$r_t,r_{t+1},r_{t+2},…$都是我们某次采样得到的即时奖励数据。如果$V_{\pi}$不准,那就信任实际采样结果,这样至少不会对优势函数的估计出现偏差。
\[A_t^{GAE} = \sum_{l=0}^{\infty} (\gamma^{\lambda})^l \delta_{t+l}\]\(\delta_{t+l} = r_t + \tau V_{\pi}(s_{t+1}) - V_{\pi}(s_t)\) 当 $\lambda$ 接近0时,$A_t^{GAE}$ 退化成一步TD误差:$r_t + \tau V_{\pi}(s_{t+1}) - V_{\pi}(s_t)$。当 $\lambda$ 接近1时$A_t^{GAE}$ 变成 $-V_{\pi} + \sum_{l=0}^{\infty} \gamma^l r_{t+l}$ GAE 使用整个剩余奖励序列来估计优势。记这种引入了GAE方法的单步优势为 $A_t^{GAE}(s_t,a_t)$,新的策略梯度调整为:
\(\nabla J(\pi_{\theta}) = \underset{\tau \sim \pi_{\theta_{old}}}{E_t} \left[ \frac{\pi_{\theta}(a_t | s_t)}{\pi_{old}(a_t | s_t)} A_{\pi}^{GAE}(s_t, a_t) \nabla log \pi_{\theta}(a_t | s_t) \right]\) 由于 $\nabla f(x) = f(x) \nabla log f(x)$,上式可以改写为: \(\nabla J(\pi_{\theta}) = \underset{\tau \sim \pi_{\theta_{old}}}{E_t} \left[ \frac{\nabla \pi_{\theta}(a_t | s_t)}{\pi_{old}(a_t | s_t)} A_{\pi}^{GAE}(s_t, a_t) \right]\) 我们的优化目标变成: \(\arg\max_{\pi_{\theta}} J(\pi_{\theta}) = \underset{\tau \sim \pi_{\theta_{old}}}{E_t} \left[ \frac{\pi_{\theta}(a_t | s_t)}{\pi_{\theta old}(a_t | s_t)} A_{\pi}^{GAE}(s_t, a_t) \right]\)
llm与强化学习
- 宏观层
- 教 vs 发掘:这可能是大部分人对SFT和RL的直觉,一个要老师手把手教,一个追求自我探索,上限可想而知。
- 非唯一解:如果你有绝对的最佳答案,那用SFT应该是又快又好。但很多问题是没有唯一答案的,所以SFT面临泛化性挑战,或者说涌现不出智能。
- 规模化:监督数据是很难规模化的,难以收集方方面面的高质量标注数据。从‘人类模拟器’的角度,RL有望通过探索来扩展训练数据,甚至获得未知数据,比如LLM用于科研领域。
- 微观层
- Token-level vs Output-level:SFT可以看成一种token level的反馈,通过交叉熵损失函数计算每个位置的误差。而RL是output level,会评估整体输出的好坏。例子:
- sft:输入 “春暖花_“,参考输出为”开”,模型若生成 “谢”,则该token产生损失梯度。
- rl:输入 “写一首关于春天的诗”,给生成的诗句进行综合评分(如4.5/5分),对每个token都会估计全局收益。
- 定性和定量的偏好:SFT通过离线数据处理流程获得了高质量的样本,因此LLM学到了我要按照xyz这种方式说话;但RL中会引入优势值,计算当前答案比baseline好多少,根据优势值得到梯度,因此模型可能更清楚不同层次答案的差异。并且能够通过策略梯度支持数值化的奖励,而不只是偏序。从这个角度看,DPO也是只能做到定性,a比b好,但没有建模好多少;
- Token-level vs Output-level:SFT可以看成一种token level的反馈,通过交叉熵损失函数计算每个位置的误差。而RL是output level,会评估整体输出的好坏。例子:
RL4LMs/rl 与llm
RL for LLM本质理解大型语言模型的演进,长期以来依赖于标准的监督学习(Supervised Learning)范式,主要体现在预训练(Pretrain)和指令微调(SFT)两个阶段。该范式的核心在于,模型需要依赖人类给出的、从输入到输出的完整监督信号进行学习。若要仅凭此路径达到通用人工智能(AGI)的高度,必须满足两个近乎理想化的前提条件:
- 监督数据的无限性与完备性:数据量级需趋于无穷,且其分布能覆盖所有可能遇到的问题,以确保模型的全知性。
- 监督信号的绝对完美性:所有监督数据必须准确无误,不存在任何错误或偏见,以确保模型的正确性。 然而,在现实中,这两点均难以实现。一方面,高质量的人类标注数据已出现“数据瓶颈”,其生产成本高昂且效率有限(我们已经用完了几乎所有的互联网信息,把人类历史上所有的数据都压缩到了模型之中,现在我们已经只能依靠标注数据和合成数据勉强提升模型的性能了)。另一方面,人类知识本身存在边界(如许多科学未解之谜),且在标注过程中不可避免地会引入错误和主观偏见。因此,探索一种能够突破上述局限性的新扩展方法(scaling method)势在必行。这种新方法需要满足:
- 数据能够以更高效、低成本的方式进行规模化扩展。
- 对监督信号的依赖可以放宽,不再要求“专家级别”的完美答案。
RL之所以被视为LLM持续进化的关键,源于其两个显著特征:
- 数据由模型与环境交互自发生成:这从根本上解决了数据来源的限制,为模型的持续学习提供了近乎无限的原材料。
- 监督信息从“生成式”退化为“验证式”:RL的核心是奖励信号(reward),它不要求监督者提供完美的“专家答案”,而只需对模型生成的答案进行有效性或质量的“验证”。基于“验证答案的难度远低于生成答案”这一基本事实,RL大幅降低了对监督信息质量和标注难度的要求
图解大模型RLHF系列之:人人都能看懂的PPO原理与源码解读 文章后半部分没有跟上。
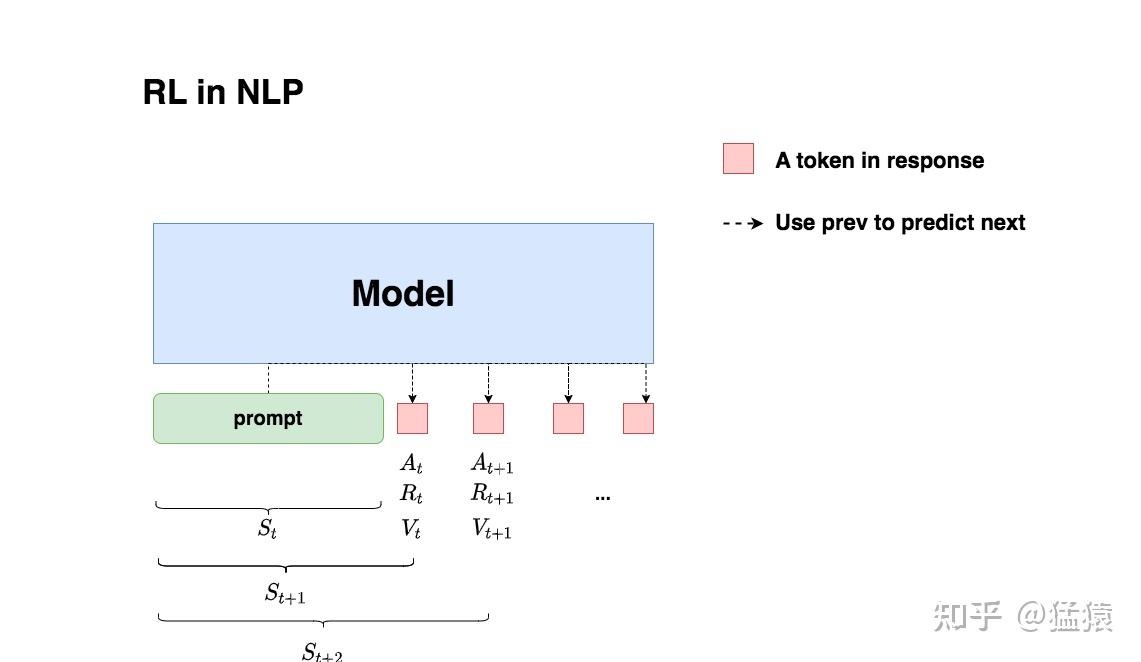 强化学习在LLM中的应用:给定prompt,调整policy,生成符合人类喜好(RM偏序信号)的response
强化学习在LLM中的应用:给定prompt,调整policy,生成符合人类喜好(RM偏序信号)的response
- 状态S:输入prompt
- 在t时刻,模型根据上文,产出一个token,这个token即对应着强化学习中的动作,我们记为$A_t$。因此不难理解,在llm语境下,强化学习任务的动作空间就对应着词表。
- 在 t时刻,模型产出token $A_t$ 对应着的即时收益为 $R_{t}$,总收益为$V_{t}$ ,这个收益即可以理解为“对人类喜好的衡量”。此刻,模型的状态从 $S_{t}$变为$S_{t+1}$,也就是从“上文”变成“上文 + 新产出的token”
- 在llm语境下, 智能体是语言模型本身,环境则对应着它产出的语料
PS:在强化学习中,模型的输出概率被称为模型的策略。无论我们如何训练LLM,不变的部分是其输入空间(提示词的字符串)和输出空间(所有token组成的词表)。在有了RLHF这一步之后,llm就不仅仅是统计模型。
汇总
没有强化学习基础也能看懂的PPO & GRPO 建议细读。
- 只有Reward时的朴素做法:为什么会有问题?奖励信号波动很大,PS:激励一直为正
- 引入 Critic,引入价值函数当参考线(baseline),从“只用 Reward” 进化成“用 Advantage 来衡量进步”
- 加入 Clip 与 min 操作:防止更新过度。比如 $\frac{P(A_t \mid S_t)}{P_{old}(A_t \mid S_t)}$ 设置一个范围,例如(0.8 ,1.2),也就是如果这个值一旦超过1.2,那就统一变成1.2;一旦小于0.8,那就统一变成0.8。相当于在超过约束范围时,我们停止对Actor模型进行更新。
- Reference Model:防止作弊、极端策略,新的行为不能和这个初始策略差太远,否则就要受到 KL惩罚。Actor 不会为了短期 Reward 而脱离原本合理的策略范畴,保证策略在演化过程中不至于“作弊”或偏得太离谱。
- PS:题外话,有文章提到KL_loss 初期基本没影响,训得久了之后(750 step 往后)就让模型训不动了。KL_loss 一直以来被诟病的就是“reference_model 为什么不定期更新一下”。都过了几千、几万step 了,还要被原始的模型来约束,非常不合理,现在很多强化工作确实也都选择不用 KL_loss 了。
- Critic(价值函数)通常需要跟 Actor 同等大小的网络去估计,否则很难评估到位,成本很高,而且有些场景(比如只在回答末尾才有一个整体 Reward)并不太适合训练出精细的价值函数。用同一问题的多条输出做平均,得到一个“相对评分”,再做标准化后作为 Advantage。
Policy Gradient(策略梯度)
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
一些基础概念(LLM训练任务下好理解版):
- $\pi$(Policy,策略):即LLM模型
- $\theta$(Parameter,参数):即模型参数
- $\tau$(Trajectory,轨迹):即输出序列,此处可以理解为输出的一整个句子,每一个输出token即为action。
- s(State,交互状态):即上文,初始状态即为$s_1$
- a(Action,交互行为):即输出的token,可以简单理解为每个字符。(实际上一个字不等于一个token)
那么,我们可以得到模型参数$\theta$ 下生成序列$\tau$ 的概率如下:
\[p_\theta(\tau) = p(s_1) p_\theta(a_1|s_1) p(s_2|s_1, a_1) \ldots = p(s_1) \prod_{t=1}^{T} p_\theta(a_t|s_t) p(s_{t+1}|s_t, a_t)\]Reward Function(奖励函数定义,即输出序列$\tau$ 能获得的奖励),用于评估某个状态/动作序列的好坏:
\[R(\tau) = \sum_{t=1}^{T} r_t\]因此可得,模型参数 ( \theta ) 下的Expected Reward(期望奖励):
\[\overline{R}_\theta = \sum_{\tau} R(\tau) p_\theta(\tau)\]综上,我们希望调整模型参数 $ \theta $ 使这个期望奖励越大越好,因此可得Policy Gradient公式如下,期望做gradient ascent最大化期望奖励:
\[\nabla \overline{R}_\theta = \sum_{\tau} R(\tau) \nabla p_\theta(\tau)\]\(= \sum_{\tau} R(\tau) p_\theta(\tau) \nabla \log p_\theta(\tau) \quad \text{\# Note: } \nabla f(x) = f(x) \nabla \log f(x)\) \(= E_{\tau \sim p_\theta(\tau)} [R(\tau) \nabla \log p_\theta(\tau)]\) \(\approx \frac{1}{N} \sum_{n=1}^{N} R(\tau^n) \nabla \log p_\theta(\tau^n) \quad \text{\# 实际上就是N个轨迹近似期望,使期望reward最大化}\) \(= \frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T_n} R(\tau^n) \nabla \log p_\theta(a_t^n | s_t^n) \quad \text{\# 环境无法作用gradient 所以可以移除}\)
直观理解:在某个state(上文)下执行某个action(token)使得最后整个输出$ \tau$ 的reward是正的时候,我们应该增加这个输出的几率,反之减少。PS:rl就是,判断哪个输出更好,把这个输出的概率提高多少,还是算loss并反向传播。
但是,如果仔细看上述公式,会发现 $ R(\tau) $ 即reward恒为正的情况,那会导致一直在增加任何token的输出概率。但我们实际操作中是用sample的方式来训练,这就导致某些项实际上因为没被sample到而导致输出概率下降(实际ground truth是要提升)。所以我们希望引入一个baseline(b)让reward不是恒为正。公式变成如下:
\[\nabla \overline{R}_\theta = \frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T_n} (R(\tau^n) - b) \nabla \log p_\theta(a_t^n \mid s_t^n)\]通常我们可以将baseline设置为reward的期望值,即 $ b \approx E[R(\tau)] $。我们知道最终输出的是一个序列 ( \tau ),且在算reward时是以 $ \tau $ 的粒度计算的。即使整体的reward是正的,也不意味着序列中的每一个action都是有收益的(如:说了一串废话,最后才说对结果)。因此,更合理的做法是我们需要给每一个action合适的credit。
首先,我们会有一些假设(注意:并不一定什么情况下都适用,应根据具体情况使用不同的reward function):
-
reward应单独为每个action计算(前面的)
\[R(\tau^n) \rightarrow \sum_{t'=t}^{T_n} r_{t'}^n \quad \text{\# 计算当前action后所有reward的总和作为当前action的reward}\] -
越快完成任务应越重要,距离越远贡献越小
\[R(\tau^n) \rightarrow \sum_{t'=t}^{T_n} r_{t'}^n \rightarrow \sum_{t'=t}^{T_n} \gamma^{t'-t} r_{t'}^n \quad \text{\# } \gamma \text{为时间衰减函数}\]
实际上 $R(\tau^n) - b$ 这一项其实是在算在某个state下执行某个action比执行其他action有多好,也就是我们常说的Advantage Function,可以表示为 $A^\theta(s_t, a_t)$ ,因此综上公式可以写作:
\(\nabla \overline{R}_\theta \approx \frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T_n} A^\theta(s_t, a_t) \nabla \log p_\theta(a_t^n \mid s_t^n)\) \(= E_{(s_t, a_t) \sim \pi_\theta} [A^\theta(s_t, a_t) \nabla \log p_\theta(a_t^n \mid s_t^n)]\)
PPO(Proximal Policy Optimization)
在 LLM 应用环境中,我们应用 PPO 算法,是把 LLM 当成智能体,但什么是环境呢?似乎不像下围棋、玩游戏这种传统 RL 场景中那样容易定义,奖励从何而来呢?那我们就训练一个 RM 来充当这样角色(RM 扮演的是「环境」),它最主要的目标就是给 LLM 这个智能体以外部的 「奖励信号」,这个奖励代表了 LLM 的决策(输出响应)有多符合人类的期望或偏好。
其中 Critic 的作用就是计算 优势函数 (Advantage Function),从而减少策略梯度估计的方差,使训练更稳定、高效。RM 是 外部的奖励信号,是外部环境给与智能体的真实响应——虽然在 LLM 的这个场景里,我们没有特别准确的外部环境建模,退而求其次用另一个训练好的 RM 模型来代替了——而 Critic 是智能体内心对自己答案的评价。打个不准确的比方,你做一套卷子,Critic 是你自己检查自己的答案,给出的自我评价;而 RM 是老师用标准答案给你打分。这样看来,不要 Critic 是不是也行?无非就是我自己「莽」一点,自己不评估自己的答案,反正 RM(环境)会给我反馈,牵引我改进。确实可以,GRPO其实在 Actor-Critic 框架之前,RL 算法就是这样的,不要「基线」了而已。代价就是方差比较大,训练不稳定。其实是通过另一种更简单的「估算基线」的方法,取代了 Critic:就是采样多次,用 RM 评价的平均值来充当这个「基线」。Critic 不是提供额外的奖励来源,而是通过学习预测未来的期望回报,提供了一个动态的基准,用来校准 RM 提供的原始奖励信号,生成更稳定、信息量更大的 Advantage 信号,从而稳定并加速 PPO 的训练。GRPO其实是通过另一种更简单的「估算基线」的方法,取代了 Critic:就是采样多次,用 RM 评价的平均值来充当这个「基线」。
为什么ppo算法中引入critic model可以降低方差?经典的蒙特卡洛策略梯度算法,例如REINFORCE,通过直接优化参数化策略进行学习,但其核心缺陷在于梯度估计的高方差。这种高方差主要源于其对完整样本轨迹回报的依赖,导致策略更新过程不稳定且收敛效率低下。为解决这一关键问题,PPO算法引入了Critic(评论家)模型作为一项核心改进。Critic通过学习状态价值函数充当一个动态的基线(baseline),其目标正是显著降低策略梯度估计的方差,从而提升学习的稳定性和效率。
- 什么是高方差?为什么它是个问题?想象一下,你正在努力学习如何投篮。如果你仅仅根据多轮投篮后整场比赛的输赢(类似于 RL 中的蒙特卡洛回报)来判断,那么你对每一次投篮的反馈就会非常嘈杂。也许你投出了一个好球,但你的队伍由于其他因素仍然输了比赛。或者,也许一个运气球进了,尽管你的姿势并不好。这与像 REINFORCE 这样的基本策略梯度方法中发生的情况类似。它们基于在整个回合(episode)中累积的总奖励来估计动作的“好坏”。即使动作或环境的随机性只有微小的变化,这些奖励也可能会剧烈波动。反馈(梯度估计)中的这种高方差意味着:
- 不稳定的更新: 策略可能会在每次更新时被随机地推向不同的方向。
- 缓慢的收敛: 从嘈杂的信号中辨别出动作的真实、潜在质量需要很长时间。
- Critic 登场:理性的声音。评估 Actor 所采取的动作,或者更常见地,它估计一个特定状态有多好。它学习一个价值函数,通常是状态价值函数 $V(s)$,表示智能体从状态 $s$开始并遵循当前策略可以获得的预期未来总奖励。这个由 Critic 学到的 $V(s)$充当了一个智能的基线 (baseline)。
PPO 不仅仅着眼于原始的、嘈杂的回报$G_t$(从时间$t$开始的折扣奖励之和),而是利用 Critic 的基线来计算所谓的优势函数 (Advantage function) $A(s_t,a_t)$。其核心思想是确定在状态$s_t$下采取动作 $a_t$比该状态下的平均预期要好多少。估算优势的一种常见方法是:$A(s_t,a_t) \approx G_t - V(s_t)$,这里:
- $G_t$,从状态 $s_t$开始直到回合结束所收到的实际(采样)累积折扣奖励。
- $ V(s_t)$,Critic 对从状态 $s_t$开始的预期累积折扣奖励的估计。
然后,PPO(以及一般的 Actor-Critic 方法)中的策略梯度更新使用这个优势:鼓励 Actor 采取导致正优势的动作,而不鼓励采取导致负优势的动作。
直观理解:为什么减去基线有效?把它想象成按曲线给考试评分。教授不仅仅看你的原始分数$G_t$,还会考虑班级在该难度考试中的平均分$ V(s_t)$。你的“优势”就是你比平均水平好(或差)多少。这种相对衡量通常比原始分数更能稳定地反映你的理解程度,因为原始分数可能会受到考试异常简单或困难的影响。类似地,从 $G_t$中减去 $ V(s_t)$
- 中心化奖励: 如果智能体处于一个通常较好的状态($ V(s_t)$较高),即使是一个不错的动作也可能导致回报$G_t$ 很高,但不会远高于 $ V(s_t)$。优势 $A(s_t,a_t)$会很小,正确地表明该动作对于那个好状态来说只是“平均水平”。
- 减少状态价值方差的影响: 某些状态本质上比其他状态更有价值。通过减去状态的价值,我们将学习信号集中在动作本身的后果上,而不是状态的内在价值。如果一个好状态下的所有动作都会导致高回报,那么仅使用 $G_t$无法清楚地区分哪个动作是最佳的。优势函数有助于做出这种区分。 这使得学习信号(优势)的噪声更小,更专注于动作的相对质量,从而带来更稳定和高效的学习。
方差降低背后的数学原理。策略梯度定理允许我们将预期总奖励$J(\theta)$关于策略参数 $\theta$的梯度写为:
\[\nabla_{\theta}J(\theta) = \mathbb{E}_{\tau \sim \pi_{\theta}} [ \sum_{t=0}^{T-1} \psi_t \nabla_{\theta} \log \pi_{\theta}(a_t | s_t) ]\]在这里,$ \psi_t$ 是衡量在状态 $ s_t $ 下动作 $ a_t $“好坏” 的某种指标。在 REINFORCE 中,$\psi_t = G_t $(从时间 $t$ 开始的回报)。在像 PPO 这样的 Actor-Critic 方法中,$\psi_t = A(s_t, a_t) \approx G_t - V(s_t)$
从Policy Gradient到REINFORCE++,万字长文梳理强化学习最新进展
PPO另一个版本,目标函数
\[\mathrm{objective}(\phi)={E}_{(x,y)\sim D_{\pi_{\phi}^{\mathrm{RL}}}}[r_{\theta}(x,y)- \beta\log(\pi_{\phi}^{\mathrm{RL}}(y \mid x) / \pi^{\mathrm{SFT}}(y \mid x))] + \gamma {E}_{x \sim D_{\mathrm{pretrain}}} [\log(\pi_{\phi}^{\mathrm{RL}}(x))]\]- 第一项 ${E}{(x,y)\sim D{\pi_{\phi}^{\mathrm{RL}}}}[r_{\theta}(x,y)]$ ,这里 $(x,y)\sim D$ ,是我们用于RLHF训练的数据集,输入(x),y是模型对应的输出。目标函数是奖励模型r_θ(x,y)在训练数据上的期望值。所以这里是试图最大化之前训练的奖励模型预测的奖励。
- 第二项,同样,x是提示,y是模型输出。 $\pi_{\phi}^{\mathrm{RL}}(y \mid x)$ 是我们正在训练的当前模型的预测概率,而 $\pi^{\mathrm{SFT}}(y \mid x)$ 是我们开始时的基础模型的预测概率,令$p=\pi_{\phi}^{\mathrm{RL}}(y \mid x)$ ,$q=\pi^{\mathrm{SFT}}(y \mid x)$,$- \beta {E}{(x,y)\sim D{\pi_{\phi}^{\mathrm{RL}}}}\log(p / q)]$,这个期望值是两个分布p和q之间的Kullback-Leibler散度(KL散度),它表示两个分布的差异程度。通过对差异施加惩罚,确保在训练模型时,其输出概率与基础模型中的输出概率(预训练+指令微调后的模型)保持相近。
- 最后一项 $\gamma {E}{x \sim D{\mathrm{pretrain}}} [\log(\pi_{\phi}^{\mathrm{RL}}(x))]$,这里 $x\sim D_{pretrain}$ 是回到预训练数据集 $D_{pretrain}$ ,这一项形式上和之前下一个token的预测采用的损失函数是一样的,只是乘以一个常数$\gamma $添加这一项的目的是进行RLHF时,保持在预训练数据上预测下一个token的良好性能。
这个就是PPO,”proximal”是因为我们保持接近基础模型,”policy optimization”是因为在强化学习中,模型的输出概率被称为模型的策略。
浅谈 RL 里面的 KL 散度个人认为,RL与SFT的区别在于,SFT是token level的0/1奖励,RL是句子level的离散奖励。当然,RL也可以往过程奖励(PRM)或者规则奖励(rule-based)去走。往过程奖励走,无非是引入一个sub-sentence level的监督信号,介于整句(或者说答案)与单个词之间的监督信息。往规则走,是希望整体系统不要被Reward Model所束缚,如果数据质量足够高+基座足够优秀,那么就不需要花里胡哨的reward形式,直接使用rule-based reward就行。这里的reward大多是(-1、0.2、1)这种三段式设计,本质上和SFT的0/1是差不多的。如果我们对(-1, 0.2, 1)做一次softmax,那么就变成了(0.08, 0.26, 0.64)。从某个视角来说,也算是one-hot label的平滑形式。大家都喜欢说,RL是泛化的,SFT是记忆的。我觉得,之所以造成这种现象,是因为RL学的比较难,所以聚焦于方法论,而SFT学的比较简单,那么就容易掉入过拟合陷阱,也就是SFT记住但无泛化。正是因为RL学的比较难,那么RL的acc涨的是比较慢的,好处但是就是,真的往解题的技巧上学。
深挖PPO,聊聊前身TRPO PPO的目标函数与Reinforce算法的目标函数还是有一定差异的,尤其是它采用了 $\pi_{\theta_{old}}$ 来采样数据并在目标函数中引入重要性采样 $\frac{\pi_{\theta}}{\pi_{\theta_{old}}}$ ,这其实并不直观,我们明明推导的是基于蒙特卡洛采样的Policy Gradient,怎么目标函数中有这么多不同的策略网络呢?为什么采样的策略和执行更新的策略不一样呢?为什么长得这么不一样的目标函数也可以算作蒙特卡洛采样呢?这篇文章就要来梳理这个问题,首先从TRPO说起。TRPO(Trust Region Policy Optimization)和PPO(Proximal Policy Optimization)的作者是同一人,TRPO也是PPO的前身工作。
补充
一个典型的 PPO 算法流程是这样的:
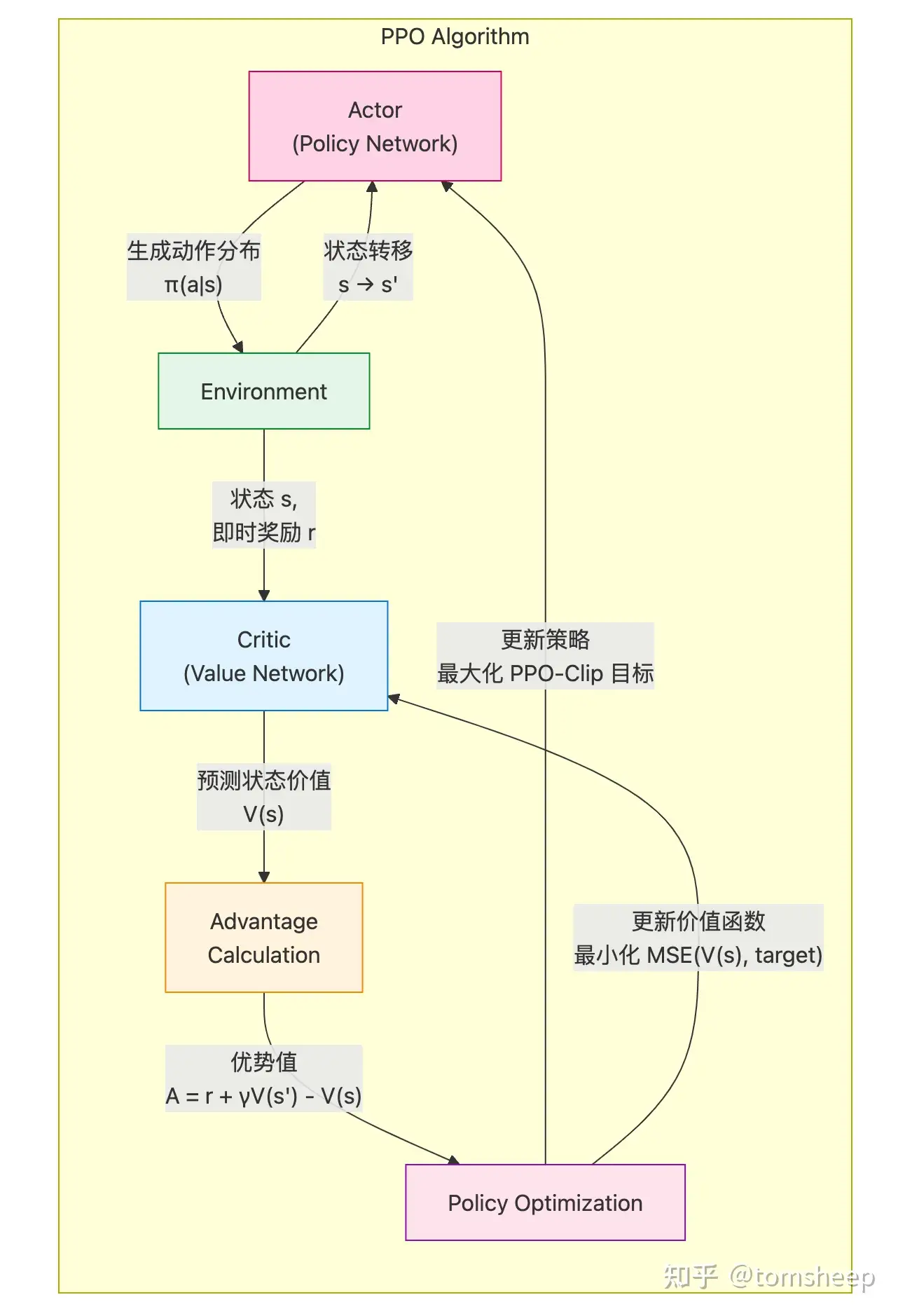 actor model 的输入是prompt(今天天气怎么样?),输出是response(今天天气很好,适合出去玩。)。reference model的输入是prompt + actor_response,Reference Model 通过前向传播,为每个 token 计算概率分布。假设 Reference Model 的输出概率分布如下:
actor model 的输入是prompt(今天天气怎么样?),输出是response(今天天气很好,适合出去玩。)。reference model的输入是prompt + actor_response,Reference Model 通过前向传播,为每个 token 计算概率分布。假设 Reference Model 的输出概率分布如下:
- 对于 token “今天”,概率分布为
[0.4, 0.3, 0.2, 0.1],其中 “今天” 的概率为 0.4。 - 对于 token “天气”,概率分布为
[0.1, 0.5, 0.3, 0.1],其中 “天气” 的概率为 0.5。 - 对于 token “很好”,概率分布为
[0.2, 0.3, 0.4, 0.1],其中 “很好” 的概率为 0.3。 - 对于 token “适合”,概率分布为
[0.3, 0.2, 0.4, 0.1],其中 “适合” 的概率为 0.4。 - 对于 token “出去”,概率分布为
[0.1, 0.2, 0.6, 0.1],其中 “出去” 的概率为 0.6。 - 对于 token “玩”,概率分布为
[0.2, 0.3, 0.4, 0.1],其中 “玩” 的概率为 0.4。 计算每个 token 的对数概率: - “今天” 的对数概率:ln(0.4)
- “天气” 的对数概率:ln(0.5)
- “很好” 的对数概率:ln(0.3)
- “适合” 的对数概率:ln(0.4)
- “出去” 的对数概率:ln(0.6)
- “玩” 的对数概率:ln(0.4)
整个回复的参考对数概率为这些对数概率的总和:
ln(0.4) + ln(0.5) + ln(0.3) + ln(0.4) + ln(0.6) + ln(0.4)
PS: 这个算是回答了 $p_{\theta}(a_t \mid s_t)$ 或 $\pi_{\theta}(a_t \mid s_t)$如何算
Group Relative Policy Optimization(群体相对策略优化)
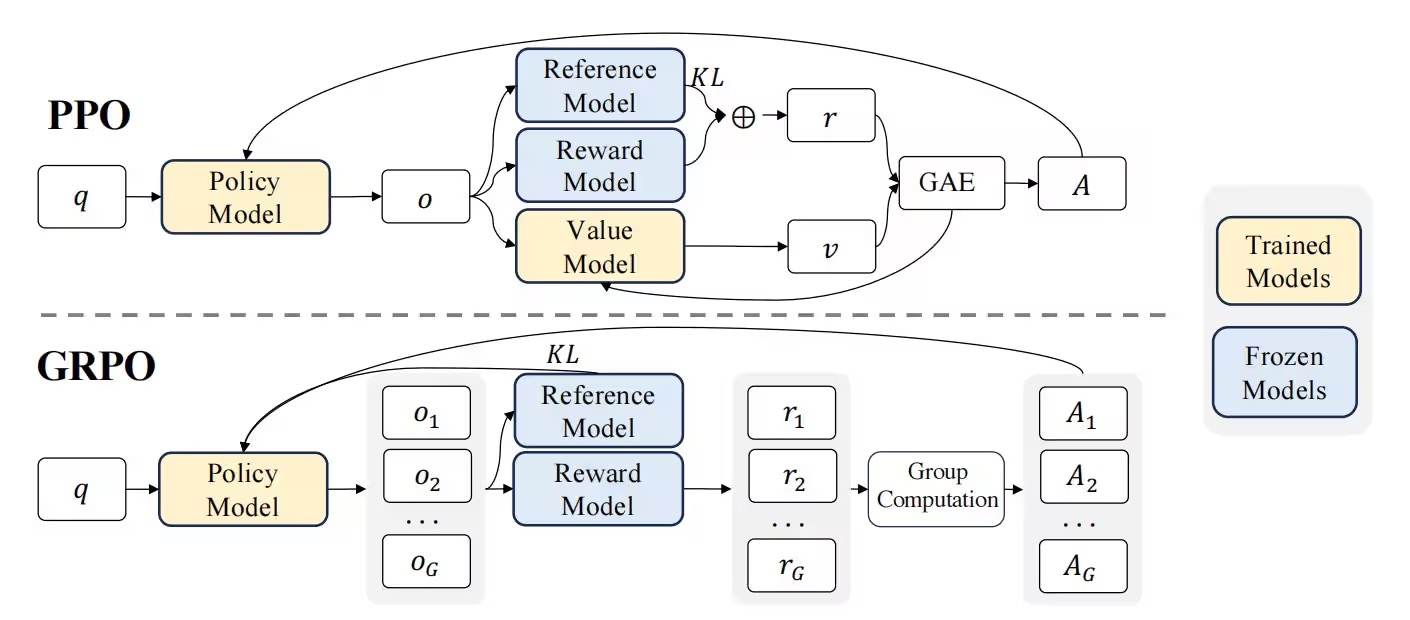
图中有以下几个关键点:
- 没有 Value Model(仅保留 Reward Model 作为监督的依据) 和输出 v(value)
- 同一个 q 得出了一组的 o(从 1 到 G)
- 计算 A(Advantage) 的算法从 GAE 变成了 Group Computation
- KL 散度计算不作用于 Reward Model,而是直接作用于 Policy Model
GRPO舍弃了传统PPO算法中的Critic模型(通常与策略模型大小相同)部分,转而通过直接从群体得分中估算baseline。在训练大语言模型llm时,一个最大的问题是中间状态很难评估(PPO的critic model总是试图精细地预测每个步骤的价值),由于语言生成是一个自回归式的序列决策过程,我们很难直接判断某个中间状态的好坏,——它是否能最终生成一个高质量答案,往往是不确定的。这就带来了一个核心问题:PPO中使用的critic model(即计算价值函数value function 用的模型)到底有没有用?它的意义有多大?准不准?这都是很难确定的。所以,PPO中critic model的意义虽然存在,但它的准确性是个大问题,限制了整体方法的可靠性。相比之下,GRPO采取了一种截然不同的思路:它直接让llm多次sample,生成完整的响应,然后用显式的奖励来评价这些最终结果。正因为一把梭哈,直接生成结果,完全跳过了对中间状态的评估,直接聚焦于完整输出的质量。既然中间状态这么难评估,那就干脆不评估,生成结果出来后自然可以通过设计好的奖励机制来判断好坏。这样一来,GRPO省去了预测中间状态价值的麻烦,直接依赖最终输出的奖励信号。更重要的是,这种方式可以通过显式设计reward奖励信号,而且必然是有效的。因为奖励是针对完整响应计算的,这种清晰的反馈比PPO中模糊的价值函数预测要可靠得多。
具体来说,对于每一个问题 $ q $ ,GRPO会从旧的策略模型参数 $ \pi_{\theta_{\text{old}}} $ 中采样一组输出 $ {o_1, o_2, o_3, \ldots, o_G} $,然后通过最大化GRPO目标函数以优化当前策略模型参数 $ \pi_\theta $。
辅助理解:不同的策略模型 $\pi$ 实际上是一个模型在不同参数阶段下的版本。
具体可以按如下理解,
- $ \pi_{\theta_{\text{old}}} $:上一轮模型参数的模型,可以理解为 $ \pi_\theta $ 上一个iteration的模型。
- $ \pi_\theta $:最新的模型参数的模型(正在更新的)。
- $ \pi_{\theta_{\text{ref}}} $:初始模型参数。
原文公式如下图所示:
\[\mathcal{J}_{\text{GRPO}}(\theta) = E [ q \sim P(Q), \{o_i\}_{i=1}^G \sim \pi_{\theta_{\text{old}}}(O \mid q) ]\] \[\frac{1}{G} \sum_{i=1}^G ( \min ( \frac{\pi_\theta(o_i \mid q)}{\pi_{\theta_{\text{old}}}(o_i \mid q)} A_i, \text{clip} ( \frac{\pi_\theta(o_i \mid q)}{\pi_{\theta_{\text{old}}}(o_i \mid q)}, 1-\varepsilon, 1+\varepsilon ) A_i ) - \beta D_{KL} ( \pi_\theta \mid \mid \pi_{\text{ref}} ) ),\] \[D_{KL} ( \pi_\theta \mid \mid \pi_{\text{ref}} ) = \frac{\pi_{\text{ref}}(o_i \mid q)}{\pi_\theta(o_i \mid q)} - \log \frac{\pi_{\text{ref}}(o_i \mid q)}{\pi_\theta(o_i \mid q)} - 1,\]$ \varepsilon $ 控制学习步长上限,保证每一轮学习不至于与上一轮偏移过大。主要是防止策略崩溃。
$ \beta $ 控制原始能力偏移惩罚的程度。主要是缓解灾难性遗忘的问题。
DeepSeek的GRPO算法是什么? - 梦想成真的回答 - 知乎最核心的就是$\frac{\pi_\theta(o_i \mid q)}{\pi_{\theta_{\text{old}}}(o_i \mid q)}A_i$
- q 表示此次的问题
- $o_i$ 表示旧的policy model 的第i个输出策略
- $\pi_\theta(o_i \mid q)$ 表示给定问题q,policy model 输出$o_i$的概率
- $\pi_{\theta_{\text{old}}}(o_i \mid q)$ 表示给定问题q,旧的上一轮梯度下降后的 policy model 输出$o_i$的概率
进而,我们知道了$\frac{\pi_\theta(o_i \mid q)}{\pi_{\theta_{\text{old}}}(o_i \mid q)}$其实就是policy 模型学习过程中的偏移程度,很明显,loss中要最大化$\frac{\pi_\theta(o_i \mid q)}{\pi_{\theta_{\text{old}}}(o_i \mid q)}$,然这不能无上限的 maximize,因为PPO其实是希望模型一点一点学,每一次不能偏移过多,因此clip项就是在做梯度剪裁,KL散度也在进行正则。$\frac{\pi_\theta(o_i \mid q)}{\pi_{\theta_{\text{old}}}(o_i \mid q)}$越大,比如说大于1,那么说明新的策略模型更倾向于输出$o_i$这个策略。
我们再说优势函数 (Advantage Function) $A_i$,R1中非常简单直接,就是reward score 做个标准化,得到的$A_i$就是第i个决策在多个决策中相比较baseline 好多少或者坏多少。如果$A_i$>0,那么就是正向激励,否则,$A_i$< 0 就是负向激励。
通过如下公式计算出:
\[A_i = \frac{r_i - \text{mean} ( \{r_1, r_2, \cdots, r_G\} )}{\text{std} ( \{r_1, r_2, \cdots, r_G\} )}.\]我们现在可以讲解 $\frac{\pi_\theta(o_i \mid q)}{\pi_{\theta_{\text{old}}}(o_i \mid q)}A_i$ 为啥要把这两项乘到一起?其实原因很简单,$\frac{\pi_\theta(o_i \mid q)}{\pi_{\theta_{\text{old}}}(o_i \mid q)}$就是第i个输出的策略倾向,$A_i$可以理解为一种激励。如果新的策略模型$\pi_\theta(o_i \mid q)$比旧的策略模型$\pi_{\theta_{\text{old}}}(o_i \mid q)$更加希望输出$o_i$ 的策略,并且优势函数$A_i$> 0,也就是获得的reward score好于平均值,那么当然值得鼓励了,所以最大化这一项没有问题。如果$A_i$< 0,说明使用这种策略反倒效果不好,此时$\frac{\pi_\theta(o_i \mid q)}{\pi_{\theta_{\text{old}}}(o_i \mid q)}A_i$是一个负数,最大化负数不就是减少$\frac{\pi_\theta(o_i \mid q)}{\pi_{\theta_{\text{old}}}(o_i \mid q)}$,也就是减少输出 $o_i$的策略的概率吗?对于一堆候选策略,当你做的比别人好,我鼓励你,当你做的比别人差,我尽量减少这种情况再次出现,模型就一步一步朝着更好的优化方向走了。PS:$A_i$ 是Response 粒度的Advantage,如何转为每个 token 的loss?计算新策略和旧策略的概率比,将概率比与相对优势相结合$\frac{\pi_\theta(o_i \mid q)}{\pi_{\theta_{\text{old}}}(o_i \mid q)}A_i$,并加上 KL 正则项,算作每个 token 的损失。
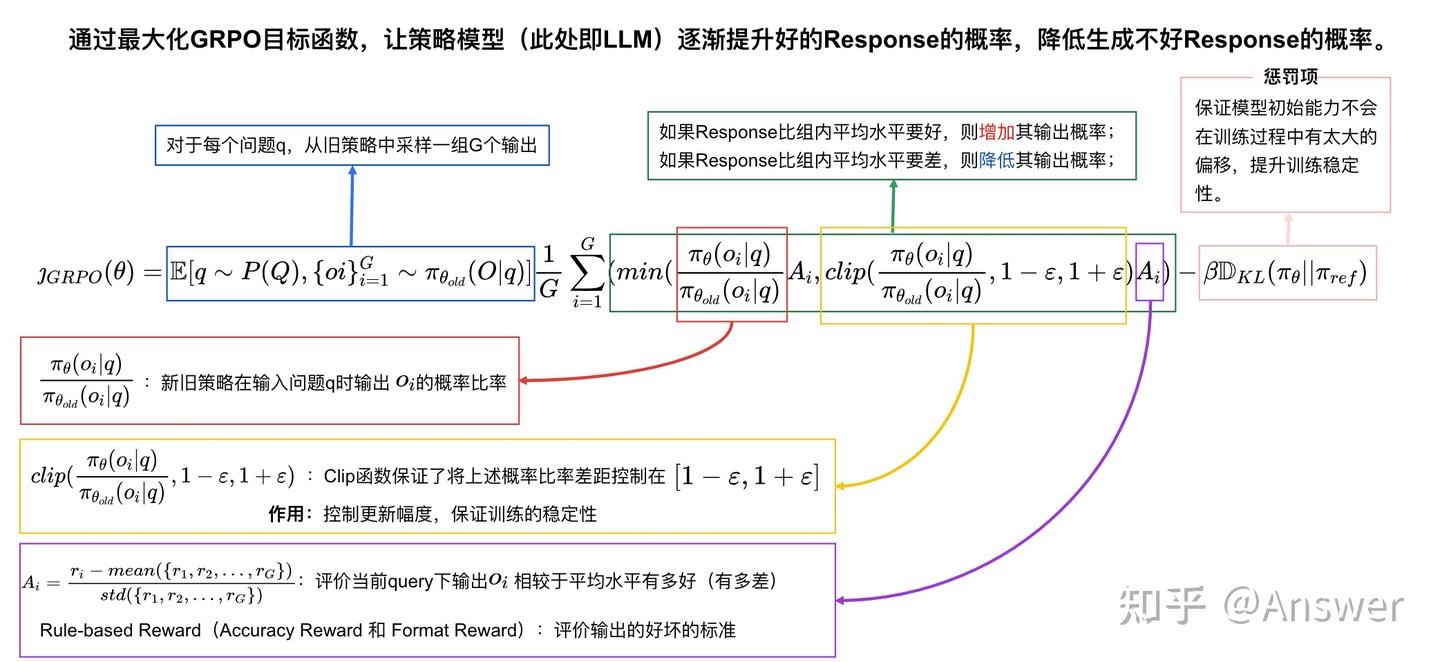
接下来说clip,$ \text{clip} ( \frac{\pi_\theta(o_i \mid q)}{\pi_{\theta_{\text{old}}}(o_i \mid q)}, 1-\varepsilon, 1+\varepsilon )A_i $,clip( ) 这一项表示把 $ \frac{\pi_\theta(o_i \mid q)}{\pi_{\theta_{\text{old}}}(o_i \mid q)}$ 限制在 $1-\varepsilon$ 到 $1+\varepsilon$ 之间,类似梯度剪裁。$\varepsilon$ 是一个超参数。很简单,GRPO并不希望新的策略模型更新的太快,本身强化学习就不好训练,容易训飞。
GRPO希望 $ D_{KL} ( \pi_\theta \mid \mid \pi_{\text{ref}} ) = \frac{\pi_{\text{ref}}(o_i \mid q)}{\pi_\theta(o_i \mid q)} - \log \frac{\pi_{\text{ref}}(o_i \mid q)}{\pi_\theta(o_i \mid q)} - 1 $ 尽量变小一点。需要注意的是,这并不是标准的KL散度,让 $ D_{KL} ( \pi_\theta \mid \mid \pi_{\text{ref}}) $ 变小就是让 $ \frac{\pi_{\text{ref}}(o_i \mid q)}{\pi_\theta(o_i \mid q)} $ 变小。 $\pi_{\text{ref}}(o_i \mid q) $ 是上一个epoch训练好的 $\pi_\theta(o_i \mid q)$,新的epoch中保持不变,而 $\pi_\theta(o_i \mid q) $ 是新的epoch正在训练的策略模型。这意味着这个kl变体损失项是为了让分子和分母基本上相同,当x=1的时候(参考 $ x-lnx-1 $ 的曲线),kl变体损失项最小为0。
我们稍微总结下GRPO:GRPO去掉了value model,仅仅只训练policy model,并且使用reward score标准化的方式作为baseline,让模型找到更优的解法,为了更稳定的训练,clip项和KL散度变种都是辅佐让模型不要训飞,一步步慢慢学的手段。
- 训练后的模型推理能力依然极度依赖base model。输出概率的改变大部分都发生在连接词、推理流程影响的词,而在单步公式、数字、推理这些基本能力上,模型输出几乎还是在沿用base模型认为最好的路径,说明这些基础能力几乎完全来自base model。这里还做了一个训练时间太长,已经训练崩溃了的checkpoint的可视化,可以看到一旦离base模型太远,正常输出都没法进行下去了,会出现重复、乱码等情况。同时可以看到,这个崩溃的实验其实还没有完全崩溃,输出的前面一段还是正常的,只是训练到了后期,才开始出现模式坍塌。从这个实验的观察可以推出,RL是不能远离base模型太多的,一旦把模型训练偏得多了一些,模型的输出就会崩溃,中断。导致无法输出最终答案,所有rollout的reward分数都是0,模型就没有正确的方向了。总之,目前的Math RL是强依赖一个非常强大的base model:不同大小的模型,相同算法RL后,提升的上限有很大的不同,RL可以通过激发base模型的长推理模式,充分发挥base模型的潜在推理能力。这意味着,想要获得最好的推理效果,就必须要在最好的base模型上面训练。
- base模型中本来概率很高的token,依然在GRPO中被不断加强,在训练后likelihood变得更接近1,也就是进行了过度自信的优化。这样的优化对模型的生成准确率能力基本是没有帮助的,但是会导致对模型的修改,产生额外的学习税。并且在token的prob都被推高的情况下,也会影响模型的探索的可能,例如prob在比较高的情况下,例如0.99时,在同一个context下,做16次rollout还有15%的可能出现非最高的token,相当于每7个这种token,rollout 16次中会有一个非最高token被探索,但是如果prob推高至0.999,概率就会降低为1.6%。这些token的探索就会几乎不存在。
-
从模型的演变角度来说,对一个大模型做RL,是从base/SFT模型作为ref开始,逐渐训练远离这个ref模型,同时获得越来越高的reward的过程。但是与此同时,RL又不能离ref模型太远,否则轻则无法继续训练、重则模型崩溃,而且离ref模型渐行渐远的过程,模型会忘掉前面学过的知识,降智交智商税。在这两层看似矛盾的要求下,要想RL训练的好,大家提出了很多tricks。
- 第一种是让训练过程对ref模型修改的又快又好,这样可以最大限度保留原始模型的能力。
- 另一个思路是在模型训练的过程中,持续恢复智商。 目前证明有效的都是要让训练又快又好的tricks,而对于恢复智商类的tricks目前基本是没有用的。主要原因我认为是这些策略虽然初衷是好的,但是在LLM的训练过程中起到了拖后腿的作用,无脑将模型往回拉。
rollout 是一个强化学习专用词汇,指的是从一个特定的状态按照某个策略进行一系列动作和状态转移,在 LLM 语境下,“某个策略”就是 actor model 的初始状态,“进行一系列动作”指的就是推理,即输入 prompt 输出 response 的过程。跟着 verl 的代码梳理GRPO
GSPO
详解Qwen3-GSPO和DeepSeek-GRPO两大强化学习算法的区别Qwen3 GSPO强化学习方法,把奖励计算从token级别 改成了sequence 级别,解决了LLM 过多的关注token导致训练不稳定的问题。PS:建议细读,文章给的例子非常惊喜。
GRPO 的Loss的计算过程
- 算优势:每个句子的奖励减去组内平均奖励,得到相对优势(好句子为正,差句子为负),也就是A。
- 当前模型生成 token 的概率 ÷ 旧模型生成相同 token 的概率(importance ratio),也就是 $\pi_\theta \mid \pi_{\theta_{old}} $
- 概率比剪辑:把概率比限制在 [0.8, 1.2] 之间,防止更新太激进
- 算基础损失:对每个 token 计算 概率比*优势= $\pi_\theta \mid \pi_{\theta_{old} * A},再加负号。让好句子(优势大)的损失为小,坏句子(优势小)的损失大。PS:token-level的加权优势。
- 加正则项(可选):加入 KL 散度,防止模型和初始版本差太远
- 总损失:Group的所有损失的平均值
GRPO 和 GSPO Loss的计算关键差异
其中最主要的差异在重要性计算那一步,GRPO是计算每个token的概率比
log_ratio = per_token_logps - old_per_token_logps # 每个token的log概率差
log_importance_weights = log_ratio # 保留token级粒度
coef_1 = torch.exp(log_importance_weights) # 每个token的概率比
而GSPO是计算整个句子的平均概率比
log_ratio = per_token_logps - old_per_token_logps # 每个token的log概率差
# 按句子平均:总log概率差 / 有效token数(避免padding影响)
log_importance_weights = (log_ratio * completion_mask).sum(-1) / completion_mask.sum(-1).clamp(min=1.0)
log_importance_weights = log_importance_weights.unsqueeze(-1) # 扩展为(batch_size, 1)
coef_1 = torch.exp(log_importance_weights) # 整个句子的平均概率比
GSPO 把奖励,优化,和加权的“尺度”统一了(都是sequence)
GRPO(token 级) 更关注每个 token 的精细优化,适合需要精准控制生成细节的任务(如机器翻译、代码生成),但可能受异常 token 影响较大。GSPO(sequence 级) 通过句子级平均平滑了 token 级波动,训练更稳定,适合以句子整体质量为导向的任务(如摘要生成、问答),但牺牲了部分 token 级优化精度。所以GSPO 还有一个GSPO-token的版本,是为了去解决多轮对话中一些,特殊token的生成效果问题。
其它
强化学习在LLM训练中的作用的思考 建议细看下,不可避免的要与sft 对比。
- RL方法共享相同的更新原则:即通过对目标函数进行梯度更新来调整模型参数。最简单的形式表示为:$\theta \leftarrow \theta + \alpha\nabla J$。其中 $\theta$代表模型参数,$\alpha$是学习率,$\nabla J$是目标(通常是期望奖励)的梯度。然而,这个梯度的计算方式以及包含哪些项在不同方法之间可能有很大差异。
- 近端策略优化(PPO)是一种策略梯度方法,它在优化目标的同时,确保策略更新与之前的策略保持”近端”。它通过计算概率比率来实现:$r(\theta) =\frac{\pi_\theta(a \mid s)}{\pi_{\theta_{\text{old}}}(a \mid s)}$,这个比率然后乘以优势估计(通常使用广义优势估计或GAE计算),并应用裁剪操作以防止更新过于偏离旧策略。由此对精心设计的目标进行更新,使得策略变化较大时提供稳定性。
- 人类反馈的强化学习(RLHF)就是在PPO方法的基础上集成了人类偏好数据的一种方法。首先使用人类评注者提供的成对的比较或评分来训练奖励模型。随后的RL阶段使用这个奖励信号来优化模型,通常将其与PPO的技术如裁剪和KL散度惩罚结合起来,以确保渐进的更新。
- DeepSeek-R1的GRPO进一步修改了这一思想,消除了对之前PPO单独价值函数的使用。不依赖于状态价值的外部估计,而是就每个提示词生成一组回复,标准化得到的奖励分之后来计算群体相对优势,简化了架构并减少了计算开销,同时仍能捕获组内回复的差异性。
online/offline policy
在强化学习中,策略可以根据它们与数据生成策略的关系被分类为 on-policy 或 off-policy。这两种方法在处理经验数据和更新策略时有所不同,
- On-policy 方法直接从目标策略(即当前学习和评估的策略)中采样数据,它要求学习算法和行为策略是一致的,即生成数据的策略必须是当前优化的策略。比如用当前模型对一批问题生成回答,然后根据这些回答的质量(奖励)来调整模型参数,让它下次说得更好。这里的数据和模型是 “同步” 的 —— 数据来自 “现在的模型”,优化的也是 “现在的模型”。
- Off-policy 方法允许从与目标策略不同的行为策略中采样数据。比如训练时用的数据不是当前模型生成的,而是来自 “别人”(比如人类专家写的回答、更强的模型生成的回答,或者过去版本的模型留下的回答)。虽然这些回答不是当前模型自己说的,但可以帮它更快学到正确的模式。 on-policy 和 off-policy 的区别,主要体现在对数据的使用上,off-policy 的训练效率会明显更高一些。一方面,off-policy 可以不等所有的 response 生成完毕,就启动模型训练;另一方面,off-policy 可以多次使用同一条数据,提高数据利用率,on-policy 则不可以。 off-policy 的模型快速熵坍缩( on-policy缓慢熵坍缩)。防止熵坍缩:加入熵 loss 和 clip higher 。