上下文记忆——AI Agent native 的任务存储机制
简介
LLM本质上就是一个具有数十亿到千亿级别参数的无状态函数,比如可以这样
\[y=f(\theta)=Decoder(Attention(Embed(x)*W_q,Embed(x)*W_k,Embed(x)*W_v);\theta)\]每次调用都像一次“短暂失忆”(金鱼记忆),就很容易变成一个每天重新认识你的客服:昨天刚聊完人生理想,今天又问请问您贵姓。为了让 AI Agent真正理解上下文、具备个性化交互和任务持续性,引入记忆系统至关重要。记忆的本质:创建真正个性化体验/“千人千面”。记忆的作用是提供上下文,它是将过去的经历与当下的行为连接起来的桥梁。PS:记忆增强RAG。
什么是记忆
把”学到的东西”抽象成一个对输出分布有影响的对象,它有两种经典承载方式:
- 参数化记忆(parametric memory):经验被写进模型权重。训练 / 微调就是把历史数据编译进权重的过程,推理时直接用更新后的模型,不需要额外检索。
- 非参数化记忆(non-parametric memory):经验被写在外部状态里(ledger + views + skill pool + 索引结构)。写入由 policy 决定写哪些、怎么写;推理时通过检索、汇聚、注入等环节让外部状态影响输出。 两者的差别不在”有没有存储”,而在适应算子写在哪里。参数化把”写入成本”前置在训练阶段;非参数化把”写入成本”分摊到在线(commit)与推理(retrieve + inject)阶段。
- Memory 不是”存储”,而是可被决策利用的外部状态(external state)。Memory 的价值不在于”存了多少历史”,而在于这条从历史到当前决策的通道是否有效。
- Memory 的最小闭包不是”文档块”,而是 (Ledger, Views, Policy) 三件套
- Raw Ledger(权威记录):追加式记录每次写入/更新/删除发生了什么(以及当时的输入、时间、scope 等)。
- Derived Views(派生视图):面向检索/推理的派生状态(向量索引、keyword/hybrid、KG/TKG(时序知识图谱, Temporal Knowledge Graph)、timeline、skill index 等)。views 可以多、可以 lossy,但必须可回指到 Raw Ledger。
- Policy(控制层):决定何时读、读多少、何时写、如何更新、如何遗忘;并且这些决策必须显式化为可记录/可回放的 Action 序列(ADD/UPDATE/DELETE/NONE…),而不是”靠 prompt 里一句话暗示”。
- Memory 的基本单位应当是 event 序列,但”直接用 event 流”不等于可用系统。把 Raw Ledger 建模成 event 序列是合理的,因为协议里所有可审计性都依赖”事件闭包”。 event 序列是”真相来源”,但它太底层。如果只存 event,你得到的是可审计的历史,不是可用的记忆能力;真正把历史变成能力的是 views(对 event 的重组织/压缩/索引/时序化/技能化)和 policy(决定什么时候触发哪些 view、怎么更新 view)。换句话说:event 是 Ledger 的数据形态;views/policy 是能力形态。
与存储对比
为了更好地理解智能体记忆的工作原理,我们首先需要区分“存储”和“记忆”的概念。
- 存储:通常指数据的保存与管理。程序通过文件系统、数据库或内存等手段来存储数据。存储是被动的,数据仅在被明确调用时才会被取用。
- 记忆:记忆不仅是对数据的保存,它还包含了对过去事件、知识、经验的主动回忆与调用。记忆是有目的性的,通过上下文或条件触发,能够帮助智能体在适当的场景下自动检索相关信息。PS:api还是靠 openai messages 参数,大模型的请求调用本身一个无状态的
- 用户偏好:记录用户的习惯和喜好,使后续交互更加个性化
- 历史交互:保存过去的对话和任务执行记录,提供上下文连贯性
- 中间结果:存储任务执行过程中的临时数据,支持复杂任务的分步执行
class MemorySystem: def __init__(self): self.user_profile = UserVector() # 用户偏好向量 self.history_db = ChromaDB() # 交互历史数据库 self.cache = LRUCache() # 短期记忆缓存在智能体系统中,“存储”更多对应的是持久化数据的保存,而“记忆”则对应智能体对过去交互的“理解”与“回忆”。也就是说,智能体的记忆是一种主动系统,它能够通过交互学习、累积知识,进而优化后续对话或决策。
举例说明
- 存储:当一个智能体被设计来存储用户的信息,如用户的地址或偏好,智能体只需在数据库中保存这些数据即可,后续用户查询时直接检索数据库即可。
- 记忆:智能体能够自动记住用户过去的交互内容,比如用户之前提到自己喜欢的编程语言是Python,下一次用户询问推荐书籍时,智能体可以根据这个记忆推荐Python相关书籍。
当LangGraph遇上Mem0:如何让你的AI Agent具有更智能的记忆与个性化的体验?
有哪些——分类/分层次
根据智能体在不同场景下记忆的功能和用途,智能体记忆可以划分为以下几种主要类型:
- 程序性记忆(知道“怎么做”)。程序性记忆类似于人类大脑中的“核心指令集”,即智能体记住如何执行任务。它是关于“如何做某事”的记忆,涵盖了智能体执行任务的规则和流程。举例:人类的程序性记忆体现在学会如何骑自行车,而智能体的程序性记忆则可能体现在如何处理某类任务,比如如何在Excel中自动生成特定的图表。
- 语义记忆(Semantic Memor,知道“是什么”,陈述性记忆?)。语义记忆是智能体的长期知识库,类似于人类的长期知识记忆。它存储了世界上各类事实和信息,防止常识性幻觉。智能体可以通过语义记忆来回答特定问题或在对话中调用相关信息。举例:人类的语义记忆包含了学校里学到的知识,智能体的语义记忆则可以包括用户喜欢的电影类型或编程语言。
- 情景记忆(Episodic Memory)。情景记忆是指回忆特定事件或过去的经历。在智能体中,情景记忆用于记住某个特定的用户交互过程,帮助智能体在相似的场景下应用相同的解决方案。比如记住是和谁互动(这个不见的“who”代表的是user,也可能是agent)、讨论了什么、何时发生等。PS:是否也意味着使用时按情景召回。 PS: 什么东西可以作为记忆,肯定是跟用户个人相关的东西,因为客观知识完全可以作为知识库存在。此外,各种记忆框架的实现都体现了“情节记忆”(偏细节)和“语义记忆”(偏抽象)两类。
智能体记忆的几个显著特点:
- 智能体的记忆可以分为长期记忆和短期记忆。短期记忆通常用于在当前会话中保存最近的交互信息,而长期记忆则用于跨会话的知识累积和历史信息的存储。
- 短期记忆:主要应用在对话中,决定了Agent在微观任务上的即时表现。智能体能够记住当前会话中的内容,通常包括用户与系统之间最近 5-10 轮交互,它确保单次互动会话内的对话连贯性。例如,在用户与客服机器人的交谈中,短期记忆允许智能体记住用户在会话中的请求或问题,以确保下一次回复更加准确。
- 精确保留近期交流内容
- 通过滑动窗口机制自动管理。
- 流程:Input(输入)→ Encode(编码)→ Store(存储)→ Erase(清除)
class Memory(BaseModel): messages: List[Message] = Field(default_factory=list) max_messages: int = Field(default=100) - 长期记忆:智能体在多次交互中积累知识,跨越多次对话的客户关键信息、偏好和交互模式(所有行为、习惯、失败/成功路径的累计认知),决定了Agent在宏观时间尺度上的智能深度和个性化水平。例如,一个购物推荐系统可以记住用户过去购买的产品偏好,以便将来推荐相关产品。流程:Receive(接收)→ Consolidate(整合)→ Store(存储)→ Retrieve(提取)。 PS:也就是短期记忆技术上是session维度,可能做一下增量summary(summary + user + ai + user + ai);长期记忆是uid维度,会走提取+融合等pipeline。CLAUDE.md。
- 关注模式和偏好而非具体对话内容
- 与客户数据平台和 CRM 系统集成
- 持久性以月或年计
- 短期记忆:主要应用在对话中,决定了Agent在微观任务上的即时表现。智能体能够记住当前会话中的内容,通常包括用户与系统之间最近 5-10 轮交互,它确保单次互动会话内的对话连贯性。例如,在用户与客服机器人的交谈中,短期记忆允许智能体记住用户在会话中的请求或问题,以确保下一次回复更加准确。
- 上下文相关性。智能体的记忆并不是被动的存储,而是与上下文强相关的。它能够通过当前的对话或环境条件触发相关记忆。也就是说,智能体在不同的情境下能够检索和应用不同的记忆。
- 自我更新与学习。智能体的记忆具有学习能力。它能够根据与用户的交互不断更新自身的记忆,逐步积累更多的知识,从而为用户提供更个性化的服务。比如一个智能体帮助用户处理财务报表,它可以记住用户之前的操作习惯,比如每次生成报表的具体格式、常用的过滤条件等。在后续操作中,智能体可以基于这些记忆自动优化用户体验。
记忆的存在形态/如何形成记忆:记忆系统不是单纯的存储原始对话,而是提取和索引关键实体与事件。这种方法实现了相关先前交互的精确回溯,同时避免用无关历史数据淹没上下文窗口。记忆的结构化示例:
{
"memory_id": "mem_78912",
"memory_type": "technical_issue",
"primary_entity": "smartphone_model_xyz",
"related_entities": ["camera_app", "battery_performance"],
"information": "设备遇到电池消耗和相机应用冻结问题",
"context": "客户尝试重启和应用重装但未解决",
"resolution_status": "unresolved",
"resolution_attempts": ["restart", "app_reinstallation"],
"customer_sentiment": "frustrated",
"timestamp": "2023-05-15T14:30:00Z",
"importance_score": 0.85
}
这种结构化方法实现了:
- 上下文相关检索:基于当前对话相关性检索记忆
- 模式识别:识别跨客户的相似问题
- 个性化:根据过往交互调整响应策略
- 持续学习:追踪解决方案有效性
可以理解为,让大模型去理解对话中的含义,并且抽取其中的实体和事务,然后针对性的完成 短期 中期 长期的对应存储方式,这样做的好处并不是一味的将历史信息大量灌入上下文窗口,而是先理解问题,选择预置匹配的记忆来补充。
记忆的存取
短期记忆管理策略。随着对话的进行,短期记忆(对话历史)会不断增长,可能会超出LLM的上下文窗口,导致请求调用失败,或者使LLM反应变慢、变差。这时,就需要对记忆进行管理了。常见的解决办法有:
- 修剪消息(trim messages):移除前 N 条或后 N 条消息(在调用 LLM 之前)。最简单直接,但信息丢失严重,适合短期任务、无状态问答机器人、近期上下文最重要的应用。
- 删除消息(delete messages):从LangGraph状态中永久删除消息。可以精确的控制移除内容,但需要自定义逻辑来判断哪些消息需要删除,适合用于移除不再需要的冗余系统消息、工具输出或错误信息。
- 总结消息(summarize messages):汇总历史记录中的早期消息并将其替换为摘要。保留了核心语义信息,但计算成本高,实现相对复杂,适合用于长期连续对话、需要维持深度长期上下文的智能体。
- 自定义策略:例如消息过滤等。
从工程上来考虑
- 哪些内容需要保存成长期记忆?
- 什么时候保存?由谁来判断?
- 未来如何召回?召回粒度是多少?
- 如何修剪、更新、合并?
实现方式
- 物理外挂:即外置数据库和 RAG,需要检索当前query相关的内容,例如:Mem0、ACE。好处是即插即用,坏处是不够end-to-end
- Memory as Reasoning / Tool:通过训练Reasoning或Tool的方式动态更新context,例如:MemAgent、memory-R1。好处是更接近end-to-end,但不是很灵活。
- 参数更新:LLM本身就是一个Memory体,所有参数都是它的Memory,通过更新参数来更新记忆,这种方式是最本质的,但也是最难实现的。
记忆的写入
“记忆” 其实包含两步。第一步是 “我要把某次交互存成记忆”;第二步是 “我需要的时候把记忆取出来”。记忆的提取?第二步很容易教会模型,只要取出来真的有帮助就给奖励。但 “存储记忆” 复杂多了,因为奖励要看后面一系列动作的表现,而不是当前这一步。所以训练时得做很多完全不同情境下的采样,才能给到信号。就是训练时既要让模型学会 “写入记忆”,又要做后续采样,去 “读取记忆” 并根据效果回传奖励。
记忆的更新是智能体记忆系统中的关键部分。智能体的记忆更新可以分为两种主要方式:热路径更新和后台更新。
- 热路径更新是指在智能体生成响应之前直接更新记忆。它是在每次交互中显式触发的更新方式,通常用于即时性的反馈。例如,用户输入的信息在经过智能体处理后,直接保存为长期记忆,供下次交互时调用。
- 优点:及时更新,无需等待。
- 缺点:增加了每次交互的处理延迟,影响响应速度。
- 后台更新则是在交互结束后,由后台进程在不影响用户体验的情况下自动更新记忆。这种方式能够减少前台处理的压力,但需要设计合理的触发机制来启动后台进程。
- 优点:不影响实时响应速度,能够在交互结束后自动完成记忆更新。
- 缺点:可能存在更新延迟,记忆不能立刻在下一次交互中生效。
- 用户反馈驱动的更新。智能体也可以通过用户反馈来优化记忆更新。用户可以标记特定的交互为“有帮助”或“无帮助”,帮助智能体调整记忆的优先级和更新策略。 在一个在线客服系统中,用户多次询问如何申请退款,智能体每次都会提供不同的解决方案。在热路径更新的情况下,智能体可以即时记住用户喜欢的解决方案并在下次交互中优先使用。而在后台更新的模式下,客服结束后,系统会自动分析用户的反馈,决定是否更新记忆。
记忆的读取(未完成)
记忆需要根据时间和热度召回,需要具备遗忘机制。
与历史人工会话的关系
历史人工会话如何用在RAG也是一个比较难的命题,信息挖掘存在几个难点,其一为数据源较杂乱,不同于标准化的书面文本,其中掺杂了较多口语化内容,且格式不一,其挖掘难度大;其二为关键信息关联性低,往往用户的问题是通过多轮交互后才能得到解决方案,解决方案较为分散;其三为信息准确度要求高,若挖掘出来的信息准确率较低,在后续的检索中会削弱模型性能,降低智能问答效率。在历史会话的挖掘上,我们也在调研后考虑了两个方案。
- 初期调研时,针对大部分历史会话的探索基本上还是微调大模型对会话进行总结和摘要的能力。但在我们的场景下,一些研发平台的人工答疑链路会很长,直接利用整个总结数据灌入知识库又回到了Query-Document匹配难的问题。这里要解决也可以再进行细粒度query抽取,从总结里再生成问题和对应答案。但整体方案这样看起来会有个误差累积的风险,所以我们在构思,是不是也可以直接微调一版能够从历史会话中直接抽取有效问答对的模型。
- 历史会话问答对挖掘。如上述思路,我们将方案转变到历史会话的问答对直接挖掘。下图为利用会话问答对大模型对历史工单进行问答对抽取的推理流程。第一个核心模块是会话问答对大模型,这里我们利用了多尺度的问答对提取策略。针对会话问题中多轮回答的复杂性,单步提示难以让模型同时感知到全局和局部的知识。我们设计了一种分步提示(Multi-Step Prompting)策略,该生成策略用于训练数据准备、训练任务构造及大模型推理三个部分。本策略将针对历史会话的问答对抽取分解为两层子任务,分别构建不同的提示词prompt,包括全局层和局部层。
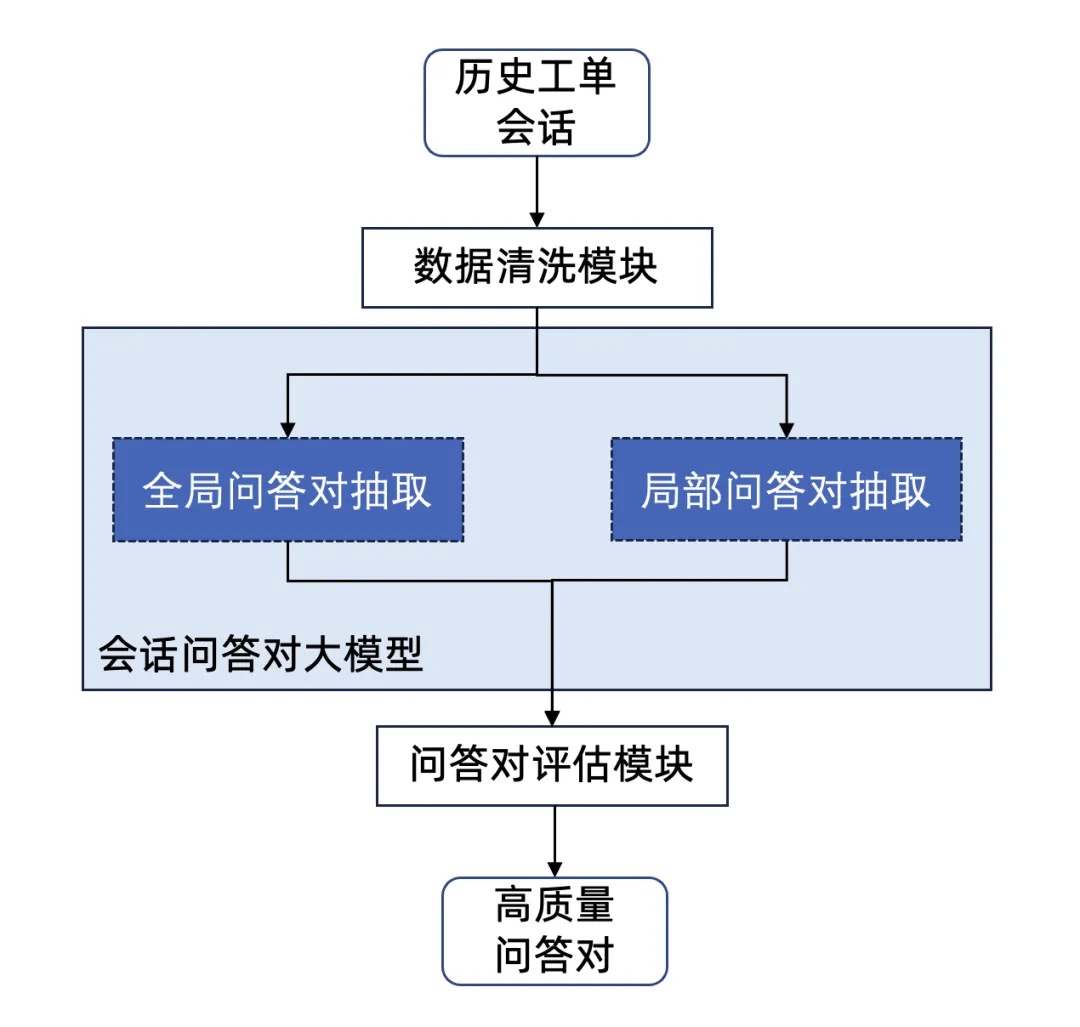
- 全局问答对抽取:由于往往一个历史会话工单中用户有最初进入提问的主要问题,而该类主要问题的解决方案往往横跨了整个对话。因此在全局层,首先要求大模型熟悉会话全文并理解全文判断会话中客服是否解决了用户所提出的主要问题,若解决了,则输出全局的问答对。
- 局部问答对抽取:考虑到内部研发问题的复杂度往往较高,在多轮对话中往往存在多个衍生子问题,该类问题对于知识库建设也起着较为关键的作用。因此在局部层,要求大模型从局部出发,判断用户可能提出的业务问题及客服是否有解决方案,若有解决方案,则输出多个局部问答对。 针对上下两层子任务,我们分别设计了相应的提示词,基于这个策略我们借用开源模型抽取+人工检验标注了基于2000+个会话的问答对数据,最终可用数据有1300条。我们用这批数据lora微调了Qwen-14b的模型。为了保证问答对抽取的完整性,并未限制抽取的问答对的数量,因此局部抽取模块的问答对抽取自由度较高,导致可能会有脏数据产生。我们也利用大模型对抽取的问答对作质量评估,将质量较低的问答对筛选掉。由于前文所述的会话问答对大模型在经过对话数据微调后,对于对话有相应理解能力,此处我们仅用该大模型作简单的评估即可对部分无关问题进行剔除。我们抽取问答对的可用率在试点租户上可达70%。
随着对话进行,messages 会不断累积,很快就超出大语言模型(LLM)的上下文限制。在不依赖外部存储(如数据库)的前提下,我尝试用一个总结节点(summarizer node)来压缩上下文。然而这引出了一个致命的悖论,我们试图用一个本身需要大量上下文的 LLM 调用,去解决上下文过长的问题。我们设定 LangGraph 每 5 轮对话总结一次,或当 Token 长度超过 1500 时总结。但问题依然存在:
- 卡在阈值: 假设当前 1490 Token,新消息进来变 1510。此时触发总结,summarizer 依然要处理这超长的 1510 Token,极易超时或卡死。
- 累积盲区: 在总结触发前(比如第 1-4 轮),消息仍在累积。如果某轮出现超长内容,Agent 依然会“爆掉”。 简言之,当对话过长,系统把全部的、超长的对话历史(比如 6000+ Token)交给 summarizer,summarizer 再把它塞给 LLM。LLM 处理巨大请求耗时过久,导致请求“卡住”。要彻底解决这个问题,我们需要升级 Agent 的记忆管理:引入滚动摘要机制。将 Agent 的对话状态拆分为两部分: • summary: 迄今为止所有对话的精炼总结。 • messages: 自上次总结以来,最新的几条消息。
# 伪代码
class AgentState {
summary: string; // 滚动摘要
messages: Array<string>; // 最新消息列表
// ... 其他状态
}
summarizer 不再处理全部历史,只接收旧摘要和最新消息。它的任务是:合并两者,生成新的、更新后的摘要。完成后,清空 messages 数组。
据此,升级“协调器”(Orchestrator)的提示词。orchestrator(Agent 的“大脑”)的决策依据不再是超长原始对话,而是:summary + messages,这样,orchestrator 总是能基于精炼、关键的信息做出判断。PS: 不再是单纯的history
逐步总结所提供对话内容,压缩记忆信息。
基于先前的记忆概要,返回新的记忆概要,必须使用中文回答。
先前的记忆概要为:
{summary}
新一轮对话:
{new_lines}
要求:
生成的新的概要,总体字数不超过{max_tokens}个字符。
记忆的使用
作为领域知识
先验知识扩充-领域型知识抽取许多模型预先并不知道一些领域内的先验知识,单凭检索出来的相关内容进行回答总会有效果不好的问题。因此,也有许多领域化的探索想方设法将领域化知识传入大模型中。这类探索也大致可以归纳成以下两类。
- 将领域型知识内化进大模型。将领域型知识内化进大模型也就是让大模型在回答前就已经学习了相关的领域类知识,最常用的就是领域化数据微调方案。一开始都会去尝试微调,但我们前期的微调效果不佳,后续没有再走这条路的原因有几个:
- 数据收集对我们来说难度高,需要有业务的同学帮忙去整理一些领域高质量数据,同时领域化数据也需要配比一些通用型数据进行微调,数据质量也很影响最终的;
- 不同研发平台的领域化概念可能不同,为每个平台都定制领域化微调模型并部署,这个资源上是完全不可行的;
- RAG做到后面,其实生成部分用的开源大模型的更迭是很快的,我们不太可能及时去训新开源的模型,换更新的大模型的收益又比用微调后的原有模型增益高。
- 如果后续能有一些知识编辑的策略,可以低成本地将我们内部的所有的研发文档输入到模型的某个记忆单元,在模型层面也就相当于做了增量的预训练。但短期内,在落地上更有效的方案还是将领域型知识显示地灌入大模型。
- 将领域型知识显式给大模型,实际落地上,我们暂时没法让模型长期记忆里存储领域型知识,于是选择的方案是对query进行知识检索的同时也去检索一遍相关领域专有知识,类似于MemoRAG的机制去建立我们的领域Memo Model。这套方案的核心也是在于领域的Memo Model如何构建。在这里,我们构建了基于领域图谱的MemoRAG。由于我们在构建领域图谱的时候,大模型遍历了整个知识库,它能获取的领域关联在一次次遍历和总结时候的可用率是非常高的。
- 构建领域图谱的具体步骤如下: step1: 模型会先多次读取文档分块,从中提取出领域实体(可结合不同场景规定实体类型)。 step2: 在遍历完所有文档分块后,模型会再多次遍历提取出的领域实体,将其中的相似相关实体进行合并再总结。 step3: 对合并后的实体,模型再根据文本块去提取实体之间的关联。 step4: 对抽取的实体和关联做社区发现,并对所聚集的社区做报告摘要
- 因此,在一整个链路后,模型能够获取跨文档完整的领域实体相关知识。对每个实体,模型也会做社区发现,生成社区报告。这类实体和社区报告,在这里完全可以作为Memo Model的重要组成。query进来后,我们首先对query分词去我们的领域Memo Model中检索属于该租户的相关领域线索,并后续一并给模型,显式地将领域知识灌入模型。PS:MemoRAG 和图谱结合还能这么玩,做图谱的时候,本来就要搞一些总结,不做白不做。
与graph的结合
人类的记忆不是一盘散沙。我们不会把具体的情节(比如“我今天早上吃了一个苹果”)和抽象的知识(比如“苹果是一种水果”)分开存储。记忆不是简单地堆砌在一起,而是被组织成一个以实体为中心的多模态图谱。这个图谱就像一个复杂的思维导图,把出现的每一个“实体”(比如人、杯子、桌子)都作为中心节点,然后把与这个实体相关的所有情节记忆和语义记忆都连接起来。通过这种方式,Agent 对环境的理解变得更有深度和一致性。当它需要回答一个问题时,它不再是漫无目的地搜索,而是在这个结构化的知识网络中,快速找到最相关的记忆片段。
一些实践(未完成)
- 根据记忆的寿命(瞬时,短期,长期)、读写频率、访问延迟需求选介质;
- 根据查询方式(键值检索,语义相似度,结构化查询,顺序重放)选数据库模型;
- 最好能用统一的记忆编排层抽象读写接口,屏蔽底层异构存储差异。写入时自动路由到对应存储;读取时支持级联:先 STM 到LTM 到 语义 / 图谱。
PS:langchain-ai/langgraph-memory 也出了。
Memory Bank
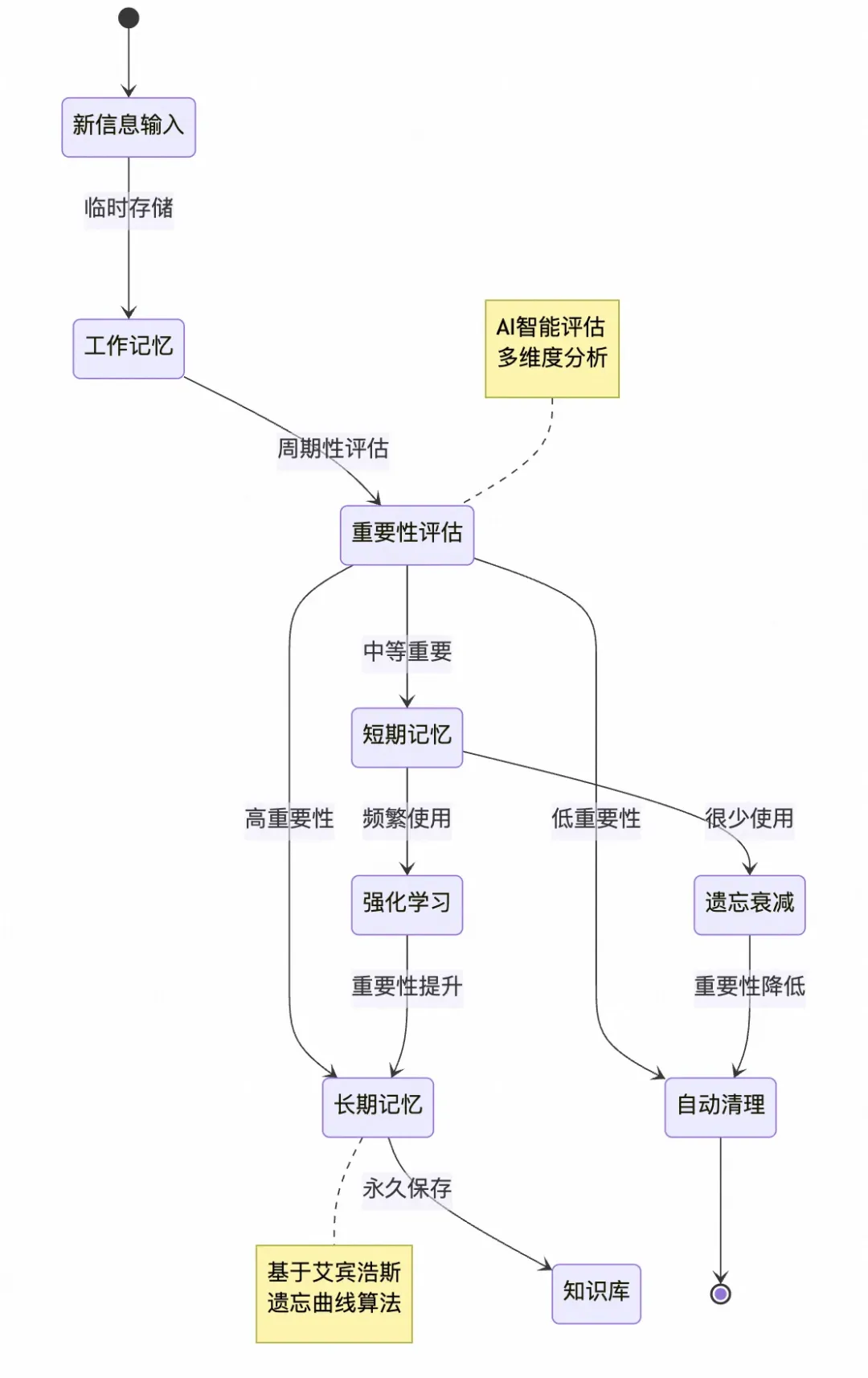
Memory Bank作为一种长期记忆机制,通过分层存储和动态更新策略显著提升了大型语言模型(LLM)在处理长上下文和跨会话任务中的表现。其核心设计理念源于对人类记忆系统的模仿,将信息划分为短期记忆和长期记忆,引入心理学理论(艾宾浩斯遗忘曲线)实现选择性记忆强化与遗忘机制(简单的说就是经常被使用的记忆会升级为长期记忆,而短期记忆会随着时间遗忘),并通过分层架构优化存储与检索效率。
Monica
Monica 的记忆功能,当用户浏览推荐的记忆条目时,若点击了“采纳为事实”,这些内容就会写入记忆数据库,供后续对话中调用;而用户不采纳的,则不会被强记。这种“反馈 → 选择性吸收 → 下一轮调优”的机制,就是对传统 Prompt + Chat 模式的增强。
 Monica 会通过用户特征的持续学习,提升需求理解的精度和响应准确性。本质是在对话式交互中重建了上下文感知机制。就好像人与人之间交流,相处时间越长,越熟悉彼此,越能理解对方所表达的。
Monica 会通过用户特征的持续学习,提升需求理解的精度和响应准确性。本质是在对话式交互中重建了上下文感知机制。就好像人与人之间交流,相处时间越长,越熟悉彼此,越能理解对方所表达的。
ChatGPT
逆向工程:ChatGPT 的记忆是如何工作的ChatGPT的记忆并非单一系统,而是主要由两大部分构成:“可保存记忆(Saved Memory)”和“聊天历史(Chat History)”。
- 可保存记忆 (Saved Memory),就是用户可以主动控制、让ChatGPT记住一些关于你的事实。比如你可以明确告诉它:“记住,我喜欢简洁的技术解释”,或者“记住,我是个素食主义者”。这些信息会被ChatGPT存起来,并在后续对话中作为背景知识(注入系统提示)使用。用户还可以通过一个简单的界面查看和删除这些记忆条目。
- 聊天历史 (Chat History):复杂且强大的“幕后功臣”,虽然名字叫“聊天历史”,实际上可能包含了三个子系统,并且是提升助手响应质量的主要功臣
- 当前会话历史 (Current Session History): 这部分记录了用户在其他对话中最近发送的少量消息(比如过去一天内,少于10条)。
- 对话历史 (Conversation History): ChatGPT能够从过去的对话中提取相关上下文,甚至能直接引用你在其他对话中发送过的消息!实验表明,它能准确引用长达两周前的消息。超过两周后,虽然不能精确引用,但也能提供消息的摘要。这暗示着消息检索系统同时基于对话摘要和消息内容进行索引。
- 用户洞察 (User Insights): 堪称“可保存记忆”的自动化、高级版。根据Eric“套”出来的ChatGPT上下文信息,这些洞察是这样的格式:
> “用户在Rust编程方面拥有丰富的经验和知识,尤其是在异步操作、线程和流处理方面” > “用户在2024年底至2025年初的几次对话中,多次询问关于Rust编程的详细问题,包括异步行为、trait对象、serde实现和自定义错误处理” > “置信度=高”技术实现猜想:向量数据库、聚类与LLM的巧妙配合
- 可保存记忆: 可能通过一个类似“bio”工具的函数实现。用户说“记住XX”,就调用这个工具,LLM将用户消息转化为事实列表,进行简单的检查后存入数据库。这些事实随后会被注入到系统提示中
- 当前会话历史: 实现起来相对简单,可能就是对聊天消息表按时间筛选用户最近的消息
- 对话历史: 这部分就复杂了。Eric推测使用了向量数据库。消息被嵌入(embedding)后存入,一个库按消息内容索引,另一个按对话摘要索引。当用户发送新消息时,系统会查询这两个向量空间,找出两周内的相似内容。对于更早的对话,则可能查询一个存储了对话摘要和消息摘要的第三个向量空间
- 用户洞察: 这是最复杂也最核心的部分。Eric认为这可能是一个批处理任务,比如每周运行一次的定时任务(cron job):
```
- 找出过去一周活跃的用户。
- 对每个用户运行一个“洞察更新”程序。
- 这个程序的核心可能是对用户的消息历史(嵌入表示)进行聚类分析(比如k-NN算法),目标是找到一些有意义的消息簇。
- 然后,将每个簇内的消息文本喂给一个LLM,用特定提示词(prompt)让LLM生成洞察摘要,并附上时间戳和置信度。
- 最后,这些洞察被存起来,并在用户与ChatGPT对话时加载到上下文中。 ```
Memory-R1
Memory-R1智能体的自适应记忆管理 从录入和检索两个角度优化两个模型。
自更新memory
之前的Memory实践可能还停留在用一段提示词从上下文中总结信息然后更新Memory,但是OpenClaw的实践带来了一种新的可能——让Agent自行去通过文本编辑工具修改写入Memory. 这也是自迭代的Agent一部分。
- 何时保存
- 如何保存,两个流派
- embeddings
- 文件系统
- 按领域分文件夹:tech/、business/、experience/;
- 文件名要清晰:让 ls 出来的列表就有语义;
- 内容是 Markdown:最自然的文本格式
- 给 AI 赋予 grep、find、ls 能力,通过文件结构和关键词自己找到答案。
- 如何加载
工程框架
Graph如何用于多模态Agent记忆增强 未读 M3-Agent:把多模态数据也转化成记忆 未读,重点是记忆图的结构定义
mem0
- Mem0(发音为mem-zero),通过专门的记忆提取和更新模块从对话中提取、评估和管理突出信息。
- 提取阶段处理消息和历史上下文,以创建新的记忆。
- 更新阶段评估这些提取得到的记忆与现有相似记忆,对每个候选事实与现有记忆进行评估,以保持一致性并避免冗余。对于每个事实,系统首先使用数据库中的向量嵌入检索前s个语义相似的记忆。利用LLM的推理能力直接根据候选事实与现有记忆之间的语义关系选择适当的操作,即执行的四种不同操作之一:当不存在语义相等的记忆时,使用ADD创建新的记忆;使用UPDATE与补充信息增强现有记忆;当新信息与之前记忆产生矛盾时使用DELETE移除记忆;当候选事实不需要修改知识库时使用NOOP。
- 异步摘要生成模块,定期刷新对话摘要。
- 多层记忆系统
- 用户层记忆:记录个人偏好、工作习惯、历史决策
- 会话层记忆:维护单次对话的上下文状态
- 智能体层记忆:储存系统级的知识和能力
- Mem0g,通过基于图的记忆表示增强基础架构,将记忆存储为带有实体节点和关系边的有向标记图。通过显式地建模实体及其关系,Mem0g支持跨多个记忆中需要穿越复杂关系路径的查询的更高级推理。
- 提取阶段使用LLMs将对话消息转换为实体和关系三元组。
- 更新阶段在将新信息集成到现有知识图中时采用冲突检测和解决机制。
支持向量存储与图存储两种模式,两者可组合使用,形成混合记忆系统。
- 当添加记忆时,LLM提取关键事实(知识、决策等),并做向量存储
- 如果启用Graph,LLM会同时提取实体与关系,并存储到图数据库
- 写入记忆时Mem0会自动进行冲突检测,避免重复记忆或矛盾记忆
- 根据检测结果,Mem0决定是添加新记忆,还是更新或者删除旧记忆
#从文本中提取并添加新的记忆
memory.add(
"林峰于2022年创办了星辰智能科技。这家总部位于深圳的公司专注于人工智能领域,其核心产品是名为“星语”的智能对话助手",
user_id="aUser")
#基于文本比对,从记忆库中检索出与文本相关的记忆
relevant_memories = memory.search(query="星辰智能科技的创始人是谁", user_id="aUser")
# 示例的输出
memories:
- 星辰智能科技专注于人工智能领域
- 星辰智能科技总部位于深圳
- 林峰于2022年创办了星辰智能科技
- 星辰智能科技的核心产品是名为“星语”的智能对话助手
relations:
- 林峰-founded-星辰智能科技
- 星辰智能科技-headquarters_located_in-深圳
- 星辰智能科技-specializes_in-人工智能
- 星辰智能科技-core_product-星语
说白了都是给LLM外挂一个存储层,只是RAG一般叫做知识库,mem0里面叫做记忆。当然mem0也不是简单的换个概念就完了,它在传统RAG的基础上做了一些重要的改进:
- 利用LLM对外部数据进行针对性的提炼归纳,形成事实摘要。这样实际上是对本地知识做了一次过滤和总结,避免了RAG直接在大量原始外部数据中进行检索,由于噪声干扰导致效果不佳的问题。
- 引入了动态的记忆更新机制,这个是mem0的核心。不断产生的新的事实和知识可以通过一定的机制更新原有记忆,避免了记忆膨胀和新旧记忆冲突导致的事实矛盾。
- 借鉴GraphRAG,实现了记忆图谱用于增强表示记忆中实体与实体间的关系,对于多跳及时序问题有显著的加强。graphiti 图谱记忆工具,未细看。
让我们逐条来进行分析,在调用memory.add时,mem0内部的流程大致是这样:
- 首先将当前上下文中的所有消息拼接成一整个字符串,包括system,user,assistant的消息,传入到配置的LLM中提取事实摘要。(add函数有一个infer参数,传入false的时候会直接将原始消息文本作为事实存储下来,这样不会使用LLM,也不会有后续的动态更新,这种方式就是简单的RAG检索,这里不做讨论)抽取的系统提示词节选如下(一部分):
You are a Personal Information Organizer, specialized in accurately storing facts, user memories, and preferences. Your primary role is to extract relevant pieces of information from conversations and organize them into distinct, manageable facts. This allows for easy retrieval and personalization in future interactions. Below are the types of information you need to focus on and the detailed instructions on how to handle the input data. Types of Information to Remember: 1. Store Personal Preferences: Keep track of likes, dislikes, and specific preferences in various categories such as food, products, activities, and entertainment. 2. Maintain Important Personal Details: Remember significant personal information like names, relationships, and important dates. 3. Track Plans and Intentions: Note upcoming events, trips, goals, and any plans the user has shared. 4. Remember Activity and Service Preferences: Recall preferences for dining, travel, hobbies, and other services. 5. Monitor Health and Wellness Preferences: Keep a record of dietary restrictions, fitness routines, and other wellness-related information. 6. Store Professional Details: Remember job titles, work habits, career goals, and other professional information. 7. Miscellaneous Information Management: Keep track of favorite books, movies, brands, and other miscellaneous details that the user shares. Here are some few shot examples: Input: Hi. Output: facts Input: There are branches in trees. Output: facts Input: Hi, I am looking for a restaurant in San Francisco. Output: facts Input: Yesterday, I had a meeting with John at 3pm. We discussed the new project. Output: facts ......后续省略 - 针对新抽取的事实摘要,通过向量语义检索,检索出向量库中与新事实相近的记忆;
- 将新的事实和相关联的已存在记忆,再次传入到LLM中,由LLM综合判断应该对这些数据进行何种操作,具体的操作类型有4种:
- ADD(新增独立事实),也就是原有记忆中不存在的新事实,需要添加到记忆库;
- UPDATE(补充现有记忆),合并新事实和旧的记忆,比如之前的记忆是用户喜欢吃冰淇淋,新的事实是用户喜欢吃烧烤,那么两个事实就可以合并,变成用户喜欢吃冰淇淋和烧烤
- DELETE(移除矛盾记忆),如果新旧事实冲突了,就要移除旧的记忆。比如之前的记忆是喜欢吃冰淇淋,现在又提到不喜欢吃冰淇淋,那么喜欢吃冰淇淋的那个记忆就要移除掉;
- NOOP(不采取任何操作),这个没啥好解释的,可能只是用于引导LLM的选择(如果只有ADD,UPDATE,DELETE, LLM在不需要操作时可能也不得不选择一个操作)
- 最后就是根据LLM返回的事实以及操作类型对底层的向量数据库进行相关操作即可。
- 如果全局配置中配置了graph_store,还会利用LLM从会话上下文中抽取实体以及实体间的关系,即所谓的图结构记忆,记忆以有向标签图 G=(V,E,L) 存储。
```
- 节点 (V):实体名称(如
小明) - 边 (E):实体间关系(如
lives_IN) - 标签 (L):实体类型(如
Person) ``` 记忆图谱也是会根据新的输入进行动态更新的,实现方式类似于第三步记忆事实的更新。通过图结构能够将记忆中的不同实体进行关联查询,在多跳推理等场景中有较好的表现。
- 节点 (V):实体名称(如
问题
- 记忆更新的结果非常不稳定。仅仅是新增记忆问题不大,基本能成功处理。但是当我陈述一些与记忆矛盾的事实的时候,模型的输出就不太稳定了,有时能够正确的更新,有时候直接返回了两个矛盾的结果都让系统新增,比如Name is David 和 Name is Lily。当然这个锅可能不该给mem0,毕竟决定agent上限的还是模型本身的能力。
- 由于借助了LLM对数据进行增强解析,导致解析速度上实在是很慢,虽然mem0针对性的做了一些优化,比如并行处理等,但一段简单的对话处理仍然需要等待近10秒钟(开启记忆图谱),这个对于实时聊天场景肯定很难接受,不过可以用在一些离线的批处理场景上,比如定期根据用户会话记录更新个性化记忆。
- 一次性记忆会长期占据记忆库的空间,在记忆召回时产生噪声。
理想状态
谈2026年的Agent设计(1):学习能力与演化Agent能够独立从与一个用户的交互中学习/熟悉这个用户。就像一个人类秘书能够从与老板的交互中熟悉这个老板。实现路径展望
- 首先SFT是不行的。用户并没有那么大量的数据。即使是我已经写作这么多,但试图用SFT的方式来学习我的已有文章来熟悉我还是非常困难的。学习表达习惯方式可以,但要学习和认知几乎不可能。
- RAG也是不行的。还是用我之前总举的一个例子,pretrain阶段没有学习过量子色动力学的LLM和它构成的Agent,不可能只靠RAG学会量子色动力学。
- 目前唯一可行的方式只有在in-context内进行表达和学习,也就是说,所有对于单个用户的认知都需要表达为文本。但Agent对于一个用户的认知大概率不能表达为一个用户profile文本,由于数据量和目前LLM的context window能力,对于用户的profile必然有很多信息需要外溢到外部的memory存储中,按需召回进入每次请求的context中。
- 进一步展望的话,在这之后有可能通过RFT(强化微调)的方式,对于每个用户去训练一个特化模型/LORA来更进一步地学习/熟悉该用户。但还没学会走的时候就去学跑是不太现实的。
llm memory不是传统数据库的延续,而是新的系统范式。传统 DB 是给程序员写 SQL 用的,强调 schema、字段、索引、事务。Agentbase DB 则是面向 LLM,“Memory 是 agent 可以理解、可以问、可以操控的对象”,所以它需要是语义驱动 / 任务驱动的。Agentbase 的 Memory store 未来很可能具有这三点特性:
- 多模态(Multimodal):不只是文本记忆,还要支持图像、语音、甚至视频行为链(比如教育场景中 AI 教练对学员的长期反馈)
- 自编排(Self-orchestrated):Agent 会动态选择:哪些 memory 激活、哪些工具调用、哪些路径最优(plan routing) → 这需要 memory store 提供状态感知和调度接口
- 自治(Autonomous):系统能根据 memory 反馈自己优化 agent 的行为(比如强化成功路径、屏蔽失败路径)。 长期来看,落地 Agentbase 将传统数据抽象成“Agent可理解的语义 API”,并与 Agent 的任务计划机制打通(Plan → Tool → Data Interface)。也就是说,这种“面向 LLM 的老数据访问”只是过渡,最终会转向 Plan-native / Tool-native 的数据结构。
留下评论