
简介(未完成)
Naive RAG方法在处理简单问题时表现良好,然而,当面对更复杂的问题时,Naive RAG的局限性就显现出来了。
- 总结性问题:例如,“给我一个公司10K年度报告的总结”,Naive RAG难以在不丢失重要信息的情况下生成全面的总结。
- 比较性问题:例如,“Milvus 2.4 与Milvus 2.3 区别有哪些”,Naive RAG难以有效地进行多文档比较。
- 结构化分析和语义搜索:例如,“告诉我美国表现最好的网约车公司的风险因素”,Naive RAG难以在复杂的语义搜索和结构化分析中表现出色。
- 一般性多部分问题:例如,“告诉我文章A中的支持X的论点,再告诉我文章B中支持Y的论点,按照我们的内部风格指南制作一个表格,然后基于这些事实生成你自己的结论”,Naive RAG难以处理多步骤、多部分的复杂任务。
Naive RAG上述痛点的原因
- 单次处理:Naive RAG通常是一次性处理查询,缺乏多步骤的推理能力。
- 缺乏查询理解和规划:Naive RAG无法深入理解查询的复杂性,也无法进行任务规划。
- 缺乏工具使用能力:Naive RAG无法调用外部工具或API来辅助完成任务。
- 缺乏反思和错误纠正:Naive RAG无法根据反馈进行自我改进。
终于让Agentic RAG工作流正常运行了Agentic RAG(代理型 RAG) 是与 AI 智能体架构一起使用的 RAG(检索增强生成)。
- 首先,它需要具有一定的自主决策能力,如果你编写了一个执行一系列步骤的程序,其中一步是调用 LLM——恭喜你!你已经构建了一个调用 LLM 的程序工作流,只是不要称它为 AI 智能体。
- AI 智能体还需要有某种与环境交互的方式。对于软件来说,这意味着进行 API 调用、检索数据、向 LLM 发送提示等。大多数 LLM 仅支持一种类型的工具:函数。
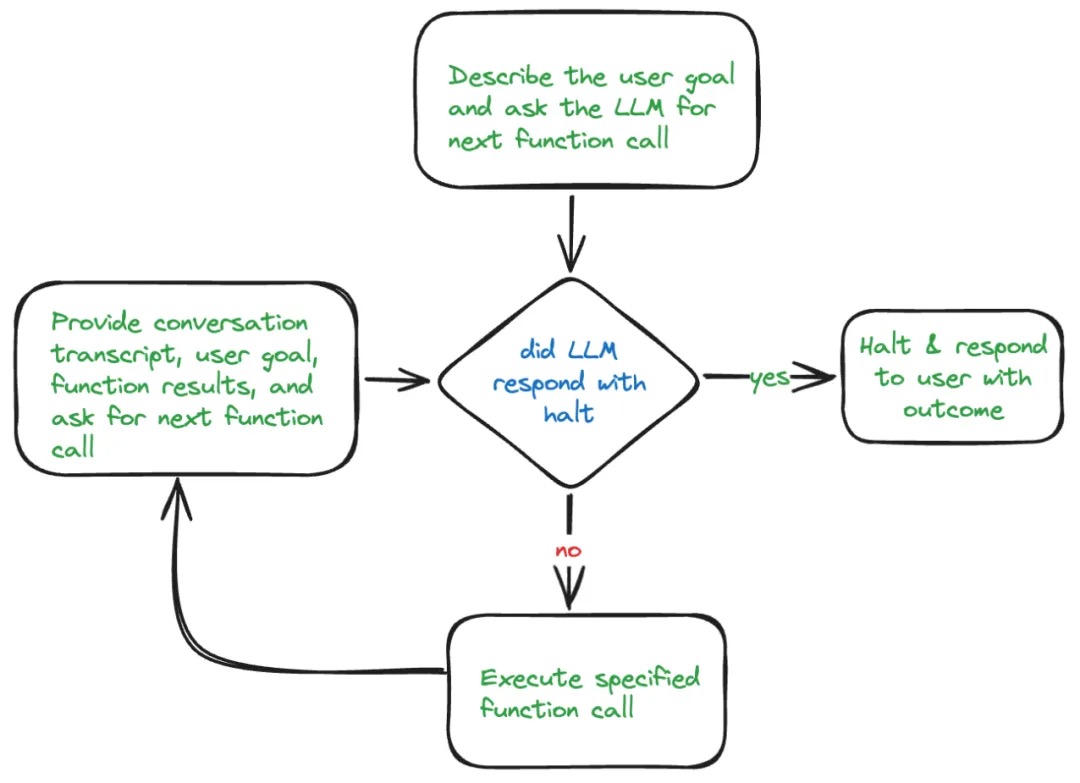
multistep
一般过程:通过多个模型,或者本模型自己的回归方式来实现多步分解问题进而拆解,进而逐步解决。
笔者曾微调模型(要准备要给微调数据集),实践了一下ircot,通过与检索器进行多轮对话,系统地规划检索和细化查询,以获取有价值的知识,,这个过程一直持续到收集到足够的外部信息为止。但这一块其实很不可控,由于检索器和检索语料库的限制,在某些情况下可能无法获取回答问题的必要知识,导致无限次迭代。另一个是这个底层是依赖于大模型的判定能力,在每次迭代中,LLM根据当前状态进行推理,确定是否需要进一步的检索以及检索的具体信息。LLM生成查询并根据检索到的文档进行信息提取和答案推断。细分下来就是:
- 检索规划能力,LLM需要明确识别解决查询所需的知识和进一步检索的具体信息。这意味着LLM在每次迭代开始时,都会评估当前已有知识的不足,并决定需要检索哪些新信息。
- 信息提取能力,一旦LLM收到检索到的文档,它需要从中提取解决问题的关键信息。这一步骤类似于人类在阅读文档时的信息筛选过程,旨在去除无关信息,保留有用内容。
- 答案推断能力,在收集到所有相关信息后,LLM使用推理来形成最终答案。这一步骤确保LLM能够基于现有信息生成准确且合理的答案,避免生成虚假信息。
路由 vs agent
- 路由 + 多链路,路由是最简单的Agent推理形式,路由器识别出来问题属于哪种,然后使用对应的链路来解决。
- 训练专门的分类器 https://github.com/starsuzi/Adaptive-RAG/ EfficientRAG
- 对于复杂问题,复杂问题的处理链路仍需单独训练。
- agentic chat,有一个很牛逼的 agent llm(难点也在这),未来新的链路是一个tool。实际上揉和了规划、调用、总结到一个llm。
- 从分层的角度将,最下层/基础的能力是一系列的tool,所以要有caller,上层是对问题的拆分(也就是规划)和汇总(summary)。
- 对于单步骤问题,tool的回答已经可以作为答案了,所以规划器除了输出final Answer也可以ignore_summary 来决定是否调用summary。
{ action: "ignore_summary" action_input: "tool1_name" # 表示只用tool1的输出作为answer就行了,不必再summary了。 }
agentic chat 优化
多智能体微调实践:α-UMi 开源它要求LLM不仅要准确理解用户的查询意图,还要具备高超的任务规划能力、精准的工具选择与调用技巧,以及出色的总结归纳技能。其中,任务规划依赖于模型的逻辑推理能力;工具的选择与调用,则考验模型能否准确无误地编写请求;而工具调用结果的总结,则是对模型归纳总结技能的一次全面检验。传统的方法往往试图在单个开源LLM框架内整合所有这些复杂的能力,这一做法在面对容量更小的小型开源LLM时,其性能局限性尤为突出。更为严峻的是,现实世界中的工具更新迭代速度极快,这意味着一旦外部工具发生变化,整个LLM系统可能都需要重新训练和调整,这不仅耗费大量资源,也给模型的维护和升级带来了前所未有的挑战。因此,如何设计出既能保持灵活性和适应性,又能有效应对工具更新带来的挑战的LLM代理系统,成为了当前研究亟待解决的关键问题。为了应对上述的挑战,通义实验室提出了一种名为“α-UMi”的多LLM工具调用智能体框架。“α-UMi”将单一LLM的能力分解为三个部分模型执行:规划器、调用器和总结器。每个部分由单个LLM执行,专注于特定的功能。规划器依据系统当前状态生成策略,决定是否选择调用器或总结器生成后续输出。调用器根据策略调用具体工具,而总结器则在规划器的指导下,根据执行轨迹构建最终的用户答案。这些组件协同工作,共同完成任务。与先前的方法相比,α-UMi框架具有三大优势:
- 每个组件针对特定角色进行训练,确保了各自功能的优化。
- 其次,模块化设计允许各组件按需独立更新,保证了系统的适应性和维护效率。
- 由于每个组件聚焦于单一功能,缓解了模型等容量限制,意味着可以在小型LLM对工具调用智能体进行部署。 PS: 好想法,就是工作量有点大,训练时为每个模型准备单独的样本?文中给出了代码框架和 基于一个base 模型微调后的规划器、调用器和总结器模型。caller 用一个function-call 来训练应该问题不大。
Agentic RAG: 构建自主决策型检索增强系统 与顺序式简单 RAG 架构相比,代理式 RAG 架构的核心是代理。Agentic RAG架构
- 单代理 RAG(路由器),最简单的形式是,agentic RAG 是一个路由器。
- 多代理 RAG 系统,单代理RAG仅限于一个代理,集推理、检索和答案生成于一体。agentic rag 起码得是一个两层agent。
实施 Agentic RAG,要构建代理 RAG 管道,有两种选择:具有函数调用的语言模型或代理框架。取决于您想要的控制和灵活性。
- 具有函数调用的语言模型
- 代理框架
CoRAG
multistep 是单一的链式结构,链式结构中间的一个step的判断错误或者偏离了问题的本质,导致最终的输出会长且错(当然这里也会通过经过self-correct等训练方式来补救)
在 CoRAG 中
- 候选链生成,CoRAG 会同时生成多个「查询-子答案链条」(检索链),每个链条是一个候选样本。
- 计算接受概率(评估链条质量),根据当前链条的子答案质量、预测得分(模型给出的概率)等指标,模型可以评估某条链条是否可能通向正确答案。
- 筛选有效链条(拒绝不好的链条),如果某条链的得分很低,或者生成的子答案不合理(比如与目标问题无关),模型会直接丢弃这条链,重新探索新的链条。
- 选最优答案,通过拒绝那些“不可能得出正确答案”的链条,模型最终能保留较优解,避免浪费计算资源。 这个最好的链是怎么选的呢?需要你对模型LLM进行训练。优化学习更好生成子查询,更好生成子回答,更好生成最终答案。 PS:微调模型来提高拆解子问题的能力。