
简介
从最早的Transformer架构来看, Attention Block的计算量为$N^2d$, MLP Block的计算量为$Nd^2$。 针对模型规模扩大下的算法优化自然就盯着这两个block来做了。例如针对Attention Block的MHA,DeepSeek MLA以及Stepfun MFA等。 很多的优化主要是前期针对长文本的优化。而针对MoE的优化, 开源的生态上主要是以Mistral的Mixtral 8x7B开始的,但是很遗憾几个大厂一开始的阶段都选择了Dense的MLP.
moe
在构建MoE语言模型时,通常会将Transformer中的某些FFN替换为MoE层(MOE FFN,陆续还出现了MOE Attention)。具体来说,MoE层由多个专家组成,每个专家的结构与标准的FFN相同。每个token会被分配给一个或两个专家。MoE模型的推理过程主要包含三个阶段:
- 路由计算:通过路由器计算专家选择概率
- 专家选择:基于概率选择Top-K个专家
- 并行计算:选中的专家并行处理输入并聚合结果
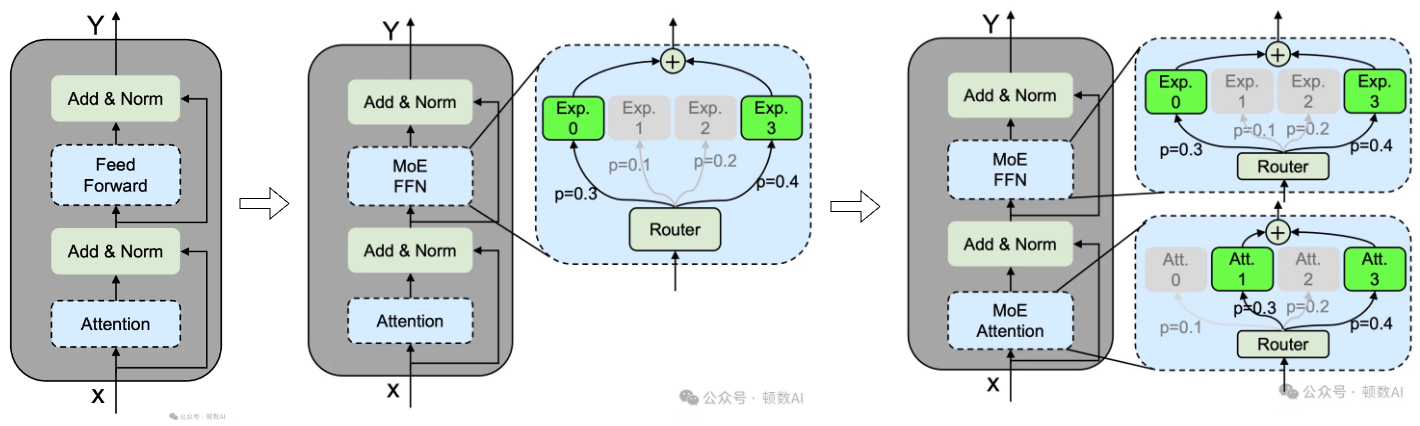
MoE架构的主要优势在于其能够通过激活部分专家来降低计算成本,从而在扩展模型参数的同时保持计算效率。然而,现有的MoE架构在专家专业化方面面临挑战,具体表现为知识混杂和知识冗余。这些问题限制了MoE模型的性能,使其无法达到理论上的性能上限。
- 知识混杂(Knowledge Hybridity):现有的MoE实践通常使用较少的专家(例如8或16个),因此分配给特定专家的token可能涵盖多种知识。这导致每个专家需要在其参数中学习多种不同类型的知识,而这些知识难以同时被有效利用。
- 知识冗余(Knowledge Redundancy):分配给不同专家的token可能需要一些共同的知识,导致多个专家在其参数中收敛于共享知识,从而造成专家参数的冗余。 PS:训练不稳定、负载不均衡
分析一下DeepSeek每一代MoE的演进 建议细读。
苏剑林 MoE环游记:1、从几何意义出发
- 一个常规的Dense模型FFN,可以等价改写为n个Expert向量$v_1,v_2,…,v_n$之和;
- 为了节省计算量,我们试图挑出k个向量求和来逼近原本的n个向量之和;
- 转化为数学问题求解后,我们发现挑选规则是模长最大的k个向量;
- 直接去算n个Expert的模长然后选k个实际上是不省计算量的,所以要重新设计Expert;
- 将$v_i$归一化得到$e_i$,然后用另外的小模型(Router)预测模长$p_i$,最终的Expert为$p_ie_i$;
- 此时,我们就可以先算全体$p_i$,挑出k个后才去计算$e_i$,达到节省计算量的目的。
deepseek
论文 模型架构;优化方法;基础设施。
边际创新
- 无辅助损失的负载均衡策略(Auxiliary-loss-free Load Balancing Strategy)
- 多头潜在注意力架构(Multi-head Latent Attention, MLA)
- DeepSeekMoE架构
- FP8混合精度训练框架
- 跨节点混合专家(MoE)训练的通信与计算重叠
首次验证
- 多标记预测训练目标(Multi-Token Prediction, MTP)对模型性能的显著提升
- FP8训练在超大规模模型上的可行性及有效性
- 强化学习可完全激励LLMs的推理能力(无SFT依赖)
- 蒸馏后的小型密集模型性能优于直接强化学习的小模型
DeepSeek-V3
- 模型架构设计:MLA、DeepSeekMoE;创新的负载均衡策略(优化MoE训练);MTP
- 并行策略:大量专家并行(EP)、不使用TP;Dualpipe流水线并行;ZeRO-1(DP)并行策略
- 通信优化:MoE All2All优化
- 显存优化:FP8低精度训练;选择重计算;EMA显存优化;头尾参数共享(emebedding & lm_head)。 DeepSeek 的优化策略分为两大类。第一类是底层优化,即在已知算法模型和底层硬件的情况下,通过软件优化来提升硬件效率,比如通信优化或内存优化。这些优化不会改变程序执行的正确性,但能显著提升性能。第二类是协同优化,包括混合精度、量化和 MLA 等技术,这些优化不仅涉及原有算法模型的修改,还可能需要调整底层硬件,从而扩展硬件优化的空间。
漫谈DeepSeek及其背后的核心技术 对上面技术有细节介绍,未细读。
R1训练过程
先前的大型语言模型(LLMs)相关的很多工作里都依赖大量的人工标注的数据去提升模型性能。但在Deep Seek R1这篇论文中指出:模型的推理能力(reasoning capabilities)可以通过大规模的强化学习(Reinforcement learning)来提升,甚至不需要用SFT(supervised fine-tune)来完成冷启部分的工作。PS. 通过少量的SFT完成模型的冷启(cold-start)可以进一步提升模型表现。
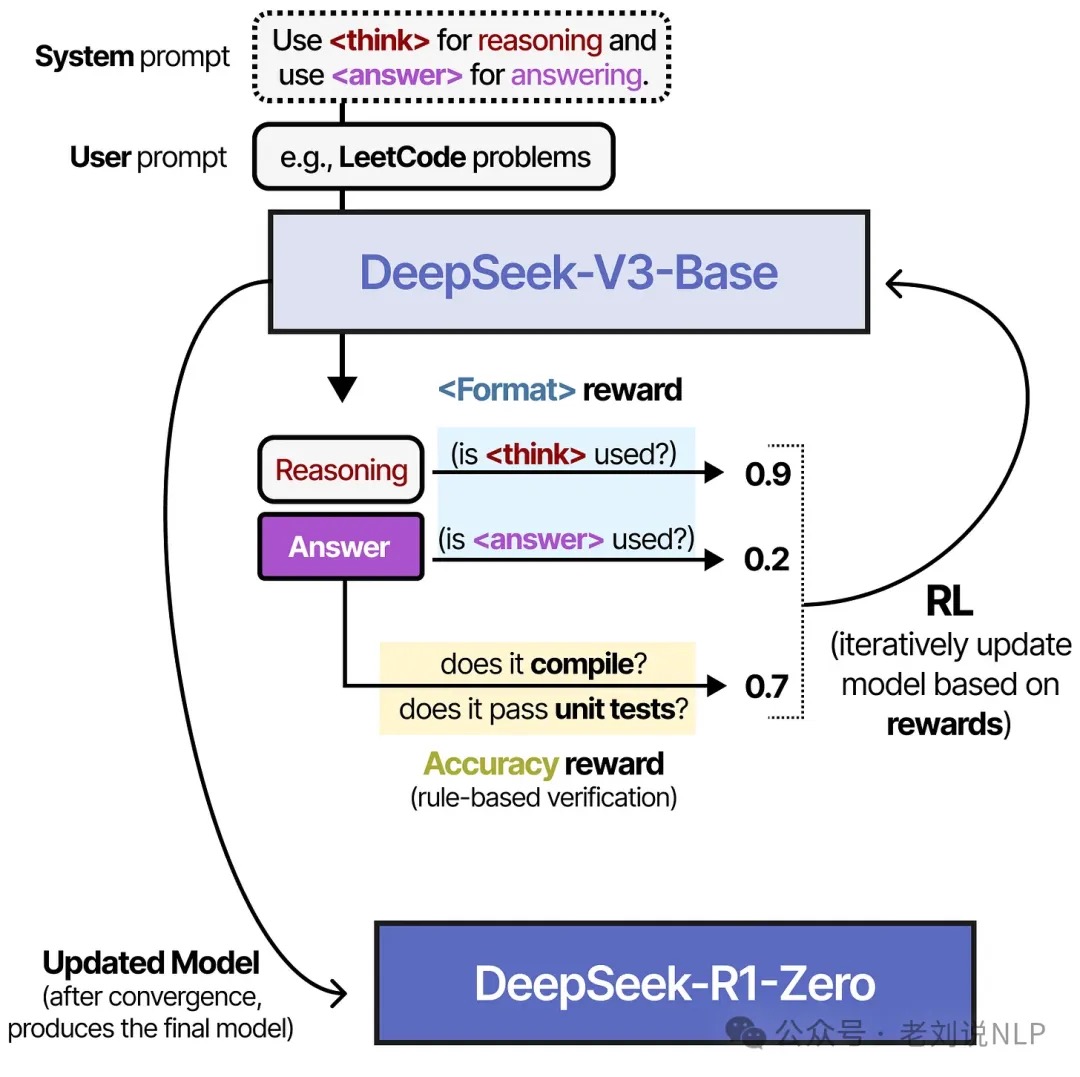
迭代式训练: PS: base-> rl -> sft 数据集 -> sft base-> rl -> sft 数据集。论文提到包含2个rl 过程和2个sft过程。
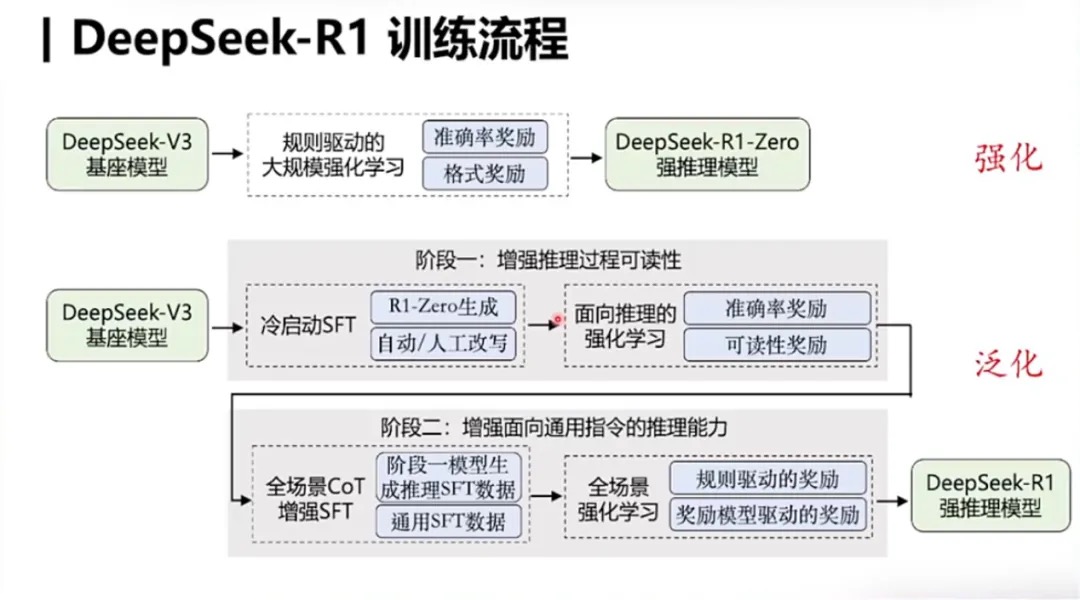
- 先收集了一部分高质量冷启动数据(约几千条),使用该数据fine-tune DeepSeek-V3-Base模型,记为模型A。PS: 最开始没有冷启动这个步骤,而是直接对DeepSeek-V3-Base进行了GRPO训练,发现虽然CoT能力提升比较大,但是回复的内容鱼龙混杂,甚至有多个语言同时出现的情况
- 使用A模型用GRPO训练(论文用了一个词 reasoning-oriented RL),使其涌现推理能力,收敛的模型记为B
- 使用B模型产生高质量SFT数据,并混合DeepSeek-V3产生的其他领域的高质量数据,形成一个高质量数据集
- 使用该数据集训练原始DeepSeek-V3-Base模型,记为模型C
- 使用C模型重新进行步骤2,但是数据集变为所有领域(常规的rl,常规的reward model,提高helpfulness and harmlessness),收敛后的模型记为D,这个模型就是DeepSeek-R1
- 训练C模型的数据对小模型做蒸馏,效果也非常好
这个训练过程是不需要任何监督数据的,只需要准确评估最终结果。GRPO的reward并没有采用PRM,而是使用了基于正则的ORM。其中包括了两个点:
- 评估最终答案是否正确。包含最终结果比对、代码运行结果等
- 格式奖励:模型需要将CoT过程放在
<think></think>之间
有人说sft不存在了。不可能的,最多是人类标注的sft不存在了。那么取而代之的是什么呢?ai标注的sft。模型rl得到的思维链做sft训练新模型,大模型的思维链训练小模型。
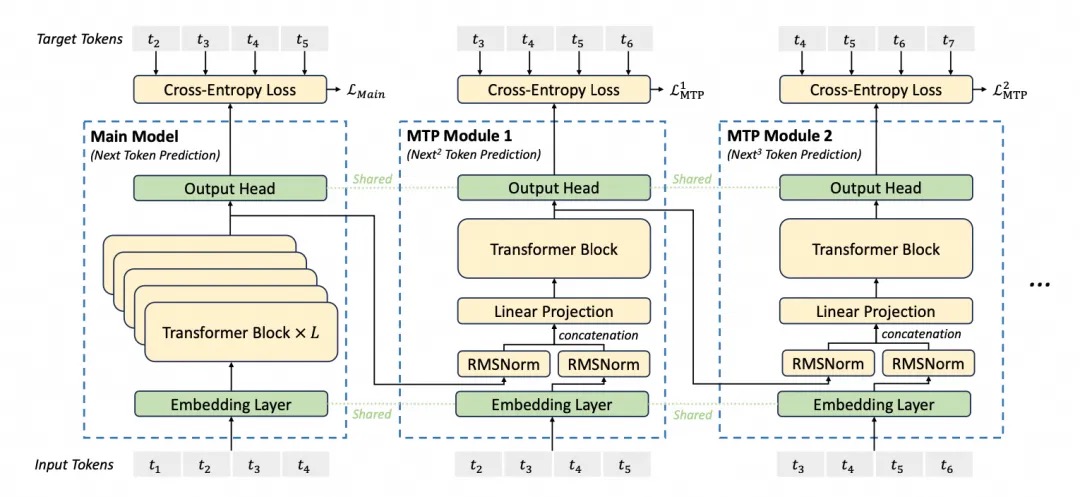
MTP(Multi-Token Prediction)
与之对应的是DeepSeek-V3 发布之前业界普遍使用的单令牌预测(Single - Token Prediction,STP),STP 一次仅预测一个Token,而 MTP 可同时预测多个 Token。为什么要做MTP? 当前主流的大模型(LLMs)都是decoder-base的模型结构,也就是无论在模型训练还是在推理阶段,对于一个序列的生成过程,都是token-by-token的。每次在生成一个token的时候,都要频繁跟访存交互,加载KV-Cache,再通过多层网络做完整的前向计算。对于这样的访存密集型的任务,通常会因为访存效率形成训练或推理的瓶颈。
MTP核心思想:通过解码阶段的优化,将1-token的生成,转变成multi-token的生成,从而提升训练和推理的性能。具体来说,在训练阶段,一次生成多个后续token,可以一次学习多个位置的label,进而有效提升样本的利用效率,提升训练速度;在推理阶段通过一次生成多个token,实现成倍的推理加速来提升推理性能。
蒸馏/distilled
知识蒸馏本质上是一种模型压缩的方法,其核心思想是利用一个大模型(教师模型)来指导小模型(学生模型)的训练。蒸馏有几种方法,每种方法都有各自的优点:
- 一种是数据蒸馏,在数据蒸馏中,教师模型生成合成数据或伪标签,然后用于训练学生模型。这种方法可以应用于广泛的任务,即使是那些 logits 信息量较少的任务(例如开放式推理任务)。
- 一种是Logits蒸馏,Logits 是应用 softmax 函数之前神经网络的原始输出分数。在 logits蒸馏中,学生模型经过训练以匹配教师的 logits,而不仅仅是最终预测。这种方法保留了更多关于教师信心水平和决策过程的信息。
- 一种是特征蒸馏,特征蒸馏将知识从教师模型的中间层转移到学生。通过对齐两个模型的隐藏表示,学生可以学习更丰富、更抽象的特征。
考虑一个输出三类别概率的神经网络模型。假设教师模型输出以下logits值: [1.1, 0.2, 0.2], 经过softmax函数转换后得到: [0.552, 0.224, 0.224]。 此时,类别0获得最高概率,成为模型的预测输出。模型同时为类别1和类别2分配了较低的概率值。这种概率分布表明,尽管输入数据最可能属于类别0,但其特征表现出了与类别1和类别2的部分相关性。在传统的模型训练中,仅使用独热编码标签(如[1, 0, 0])会导致模型仅关注正确类别的预测。这种训练方式通常采用交叉熵损失函数。而知识蒸馏技术通过引入教师模型的软标签信息,为学生模型提供了更丰富的学习目标。
低概率信息的利用价值:在传统分类任务中,由于最高概率(0.552)显著高于其他概率值(均为0.224),次高概率通常会被忽略。而知识蒸馏技术的创新之处在于充分利用这些次要概率信息来指导学生模型的训练过程。以动物识别任务为例,当教师模型处理一张马的图像时,除了对”马”类别赋予最高概率外,还会为”鹿”和”牛”类别分配一定概率。这种概率分配反映了物种间的特征相似性,如四肢结构和尾部特征。虽然马的体型大小和头部轮廓等特征最终导致”马”类别获得最高概率,但模型捕获到的类别间相似性信息同样具有重要价值。
其它
让base model 生成推理过程的prompt
A conversation between User and Assistant. The user asks a question, and the Assistant solves it.
The assistant first thinks about the reasoning process in the mind and then provides the user
with the answer. The reasoning process and answer are enclosed within <think> </think> and
<answer> </answer> tags, respectively, i.e., <think> reasoning process here </think>
<answer> answer here </answer>. User: {question}. Assistant: