
简介(未完成)
作为开发者,我如何提高任务型大模型应用的响应性能 减少输出token、选择合适尺寸的模型以及采用流式输出。
长文本生成
融合LLM和RL来生成Hidden COT(后续移到专门一文)
先聊一个问题,在知识掌握层面上,sft 后的模型为什么不如 pretrain 模型效果好?或者说,为什么 sft 后的模型在知识掌握上会有幻觉?
- sft 在做什么?在找一条捷径,让 pretrain 模型可以直接说出答案,而不是续写一堆 token 后再总结出答案。
- 为什么走捷径会产生幻觉呢,我举个例子:中国的首都是哪里呢?
- pretrain 模型:这个问题问得好…… 中国最早的首都是…… 中国现在的首都是……
- sft 模型:北京。
- pretrain 模型有没有这个知识?一定有。pretrain 模型需要多少个 token 才能说出这个知识?不知道。运气好的时候续写一百个 token 就提到了北京,运气不好的时候续写一千个、一万个都有可能。那么问题来了,sft 模型走捷径而抛弃的这一千个 token,到底有没有信息量呢?到底是不是推导出中国的首都是北京的关键 cot 过程呢?大概率是有的,一旦学会了这种走捷径的方式,并且把这种捷径泛化到其他知识上,模型的幻觉也就产生了。这里,一定不能总是用人思考的方式来揣摩机器思考的方式,我们认为“中国的首都是北京”是天经地义的几个 token 就学会的知识,模型可能是从《北京的发展史》这一本几万 token 的书籍中才学到的这个知识。然后我就猜测:把 prompt 喂给 pretrain 模型,先续写 1W 个 token,再总结这 1W 个 token 得到 response,训练和推理的时候都不省略这 1W 个 token,这种方式估计大概率不会让模型产生幻觉,因为模型根本没学会走捷径。这就有点o1 的味道了。
- 所谓捷径就是极其稀少的语言或者文本相关性分布,和原有分布不一致。所以模型无所适从,就是幻觉。
RL从未走远
LLM的范式转移:RL带来新的 Scaling Law2018 年,Lex Fridman 邀请 Ilya 来 MIT 客座讲一节课,Ilya 选择的主题是 RL 和 self-play,因为他认为这是通往 AGI 的路上最关键的方法之一。Ilya 在讲座中用一句话概括了强化学习:让 AI 用随机路径去尝试一个新的任务,如果效果超出预期,就更新神经网络的权重让 AI 记得多使用成功的实践,然后开始下一次尝试。这个概括中可以看到强化学习和其他 AI 范式的重要区别,经典三大范式(监督学习、非监督学习、强化学习)中只有强化学习的假设是让 AI 进行自主探索、连续决策,这个学习方式最接近人类的学习方式,也符合我们想象中的 AI agent 应该具备的自主行动能力。强化学习的核心在于”探索”(Explore)和”利用”(Exploit)之间的权衡。LLM 在”利用”现有知识上做到了现阶段的极致,而在”探索”新知识方面还有很大潜力,RL 的引入就是为了让 LLM 能通过探索进一步提升推理能力。在实现 RL 的过程中,有两个核心组件。他们之间一直在反复交互,agent 在环境中执行 action,并且根据环境的变化评估 reward:
- Environment:AI 探索完成任务的环境,当 Alphago 下围棋时,环境就是 19x19 的棋盘。环境会发生变化,AI 会从环境变化中收到 reward value 判断过去的那一系列探索是否有明显的收益,例如距离下围棋胜利是否更接近了。
- Agent:agent 会根据对环境的观测和感知来输出一个动作,目标是得到更高的 reward。agent 这个概念最早就是来自强化学习。 PS: Environment ==> reward ==> agent ==> action ==> environment ==> reward ==> agent ==> action ==> … 如果把这里的 agent 主体换成 LLM,那么会在探索的过程中做很多 LLM inference。因此这里 RL 在 LLM 中应用的思路本质是用 inference time 换 training time,来解决模型 scale up 暂时边际收益递减的现状。LLM 直接生成是可以类比系统 1 的慢思考。而 RL 就为 LLM 带来了系统 2 慢思考。
RLHF下一步 O1
思维链让LLM初步学会了像人类System 2一样的思考复杂问题的模式,但这还远远不够。一个明显的gap是:LLM在训练过程中并没有足够多的包含思维链的训练数据,但却在推理阶段被要求以思维链的方式思考问题。如果在训练阶段使用包含更多含思维链的数据,那么模型在需要推理的任务上的表现会更好。由此,一条提升LLM性能的道路清晰可见:构造包含思维链的数据,将其用于LLM的训练阶段以提升LLM的推理能力,使其降低幻觉。
万字长文解析OpenAI o1 Self-Play RL技术路线OpenAI o1 可以通过 Self-Play 的方式提升模型 Reasoning 的能力,o1 是怎么实现这样的能力呢,纯粹从推理态来看是 inference time thinking 做到的,就是在回答用户问题之前,模型会陷入一个思考的过程。逐步思考,提出假设,并且反思,以实现 Reasoning 能力。这里面的 thinking 流程是模型和其他大模型最大的不同,在这中间经历了相当长时间的思考阶段。思考的内容,目前在 ChatGPT 的客户端中可以做了隐藏(防止被蒸馏)。虽然不清楚背后实现的具体逻辑,但是从目前已有的接口来看,o1 至少已经能够实现:提出假设,验证思路,反思过程这三种主要的逻辑推理能力。
大语言模型的主要学习策略从 RLHF 的巨大成功之后,也出现过摇摆。以 next token prediction 作为代表的 Behavior Clone 思路主要的手段是预训练和 SFT 为主的,主要强调从海量知识中自监督学习加上专家数据的示教。但是这一条路径遇到了很大的困难,我们如今已经几乎耗尽了几乎所有互联网上所有的语料,但是极强的智能也没有出现。同时 SFT 作为 Behavior Clone 的上限是比较低的,大多数情况下需要堆叠大量高质量语料,成本几乎成为了垂直领域难以负担的问题。更大的问题在于 SFT 几乎无法囊括负例的示教,对于 trial-n-error 的自我博弈智能来说,只能利用其中比例极低的正例。所以祖师爷 John Schulman 的 PPO 加上 RLHF 力挽狂澜,把 GPT-3 拉出黑暗,直接进化到 InstructGPT,用人类反馈进行建模引爆了整个领域。但是我们现在又到了一个十字路口,大模型看起来好像是一个死记硬背的书呆子,推理能力迟迟没有见到突飞猛进的变化,大模型 Self-Play 能否通过部分领域示教数据,模型通过自我博弈持续提升策略?这里面需要有两个先决条件:Generator 和 Verifier 都要足够强。语言和游戏在这个方面是截然相反的,游戏中的行为生成是困难的而价值评判是简单的:对于路边看棋大爷下好一步棋很难,但是判断这一步下的好不好他还是可以的。语言模型生成行为是容易的,但是判断生成的好坏是困难的,1B 的模型都可以滔滔不绝证明哥德巴赫猜想,但是判断每一步是否正确却非常困难。
这一切正在悄然改变,Reward 数据正在越变越多,作为 Verifier 的 Reward Model(RM)也在变得越来越强。我们看到了越来越多的证据,新的的 scaling 趋势呈现在了生成式 RM 上2。这种 Reward Model 相比于传统的方法来说,对于大语言模型的判别已经不是一锤子买卖了。它更像是人类标注员的思路,对问题和答案会和传统生成式模型一样也能够进行 CoT。他会对于一个问题和答案,首先按照生成式模型的方法给出自然语言的判断,然后再给出 RL 所需要的标量数值,彻底摆脱了判别式 RM 中 BT 假设的枷锁。所以随着 Reward Model 思考的深入,其准确度也会不断上涨。同时更重要的是,verifer 和 generator 之间也可以通过信息密度更高的自然语言的方式进行互动。相当于 RM 监督 policy 的时候,不仅告诉了每条答案的评分还详细给出了错误的原因。这种以自然语言作为交互模式的对抗 + 合作的模式可以随着计算资源的增长获得明显的增长(推演的更多,反思的更细)。其中的对抗是,大语言模型要经历生成更好的回答让 RM 无法挑出问题,而 RM 也要自己增长能力以发现大语言模型的更多漏洞。合作则在于,最终两者的博弈并不是零和的,两者的同步增长会使得我们的大语言模型拥有真正的长思考能力,并有机会往全领域泛化。
那么第二个问题是:Verifier 判别出来的正例和负例是不是同时能够利用起来,答案是比较正面的。而且强化学习中,引入负例可以更有效地提升大语言模型的推理强度。数据利用效率更是达到了仅使用正例的八倍,这个结论是非常好理解的,对于推理来说一个巨大的采用空间内,做错的可能性在起初要大大高于能够做对的概率。如果无法充分利用负例的数据价值,学习效率就会大打折扣。
从推理时的较为确定的 Self-Play 方式出发,我们可以反向推演一下 o1 的可能技术路线(声明一下这些都是推演)。假设 Generator 和 Verifier 是两个相互配合的模型,部署的时候使用两个模型组成的系统,那么就可以使用 actor-critic 的方式加 TD-error 来更新 generator model 和 verifier model。PS: 细节可以看原文,有点get 到 self-play 啥意思了。
LLM scaling up 的边际收益开始递减,用 RL self-play + MCTS 提升 LLM 推理能力成为下一个技术范式。在新范式下,LLM 领域的 scaling law 会发生变化:计算量变大仍会带来模型智能的提升,但会从模型参数量变大,转移到 inference-time compute 增加,也就是模型进行更多 RL 探索。要让 RL 算法能够在连续推理任务上做到最好,理解 self-play + MCTS 的思路是最重要的。放到 LLM 语境下,self-play 是让 LLM 同时扮演一个或多个 agent model 去做推理任务,并由另一个 LLM 作为 reward model 来给出打分评价,一定次数后更新 LLM 权重让其多记住做得好的推理方式。Self-play RL 是要在好的策略上持续探索,怎么定义“好”就尤其重要。因此, Reward model(奖励模型) 是 RL 中最关键的模块之一,有两个关键的卡点是需要解决的,那就是 reward model 的泛化性和连续性。Self-play RL 在棋牌、电子游戏、数学竞赛上之所以有效,是因为这些领域都有明确的胜负标准,可以作为 reward model 的基础。有了 LLM 的 in-context learning,我们相信代码、数学是可以通过 LLM + self-play RL 来持续进步的。根据 The information 报道,strawberry 目前能力最强的领域就在 math 和 code 上,Sonnet 3.5 在代码的提升也是很好的佐证。这两个领域具有准确、快迭代的评判标准,使得模型能够获得明确的反馈:我们可以把 code script 放进 Python Interpreter/ compiler(如果不成功,报错信息也能帮助 AI 自己去发现和理解错误在哪里),把 math proof 放进 Lean(Lean 是一种编程语言,通过计算机验证数据定理,广泛用在 AI 形式化数学证明中帮助 AI 理解数学题),就能自动验证其准确性。
reward model 对其他领域的泛化性并不明确。物理、医药有明确的标准答案,但需要很长的实验验证周期。法律、金融的问题往往没有通用解法,很难用通用的 reward model 实现。文字创意领域的 reward 很多时候不符合马尔可夫模型,也就是其 reward 常常会有跳变。一本好的小说、剧本,会讲究反转,试想 LLM next-token prediction 到一个反转之前其 reward 函数还很低,一个精彩的反转让 reward 函数突然大幅提升,self-play RL 很难捕捉这个突然的变化。因此这里孕育着新范式下的第二个创业机会:垂直领域的 reward model。而要让 reward function 能捕捉到更多的信号,在垂直领域之外泛化,最重要的方向就是怎么用好 LLM 作为 reward model,并同时输出数字和文字评估。
LLM as a PRM (process reward model):通往泛化的重要路线。在传统 RL 中,我们按照最终结果评分,其评分模型称为 ORM(outcome reward model);而通过专门训练 LLM 成为 process verifier ,新的评分模型叫做 PRM,往往是使用娇小 LLM fine-tune 得到。PRM (Process reward model) 是奖励好的推理步骤,而不仅仅是正确的结果。这更接近人类的学习和推理方式。而且在 process supervision 过程中,reward 的形式也不止限于数值,文字评价也可以作为指导模型继续行动的 reward。
左脚踩右脚真能上天?谷歌提出自我纠正RL提升LLM光靠模型自己给自己打分,较难获得新的信息增量提升效果,要么需要多个模型,要么依赖于更高级的模型或其他形式的监督(如RAG提供外部输入)。但最强的那个模型要怎么继续进步呢?光靠模型自己反思真的不行吗?谷歌DeepMind团队提出多轮在线强化学习方法 SCoRe,完全使用自生成的数据进行训练,不需要任何外部反馈模型/信号,就能实现内在自我修正策略以“即时”修正自己的错误,提升了模型的推理能力。我们理性的看,这种“自我反思”要有效果,有一个重要前提,是当前LLMs已经压缩了和问题答案相关的信息/知识,但还无法很灵活的使用,需要更高效的策略帮它提取&运用起来。
未定
Reverse-o1:OpenAI o1原理逆向工程图解本文以相对容易理解的方式来对o1做些技术原理分析,试图回答下列问题:
- 除了复杂逻辑推理能力获得极大增强,o1还有其它什么重要意义?
- o1的完整训练过程大致会是怎样的?
- o1是单个模型,还是多个模型?
- O1中的RL状态空间如何定义?行为空间如何定义?会用何种Reward Model?可能用何种训练数据?LLM和RM融合后的模型结构可能会是怎样的?
训练过程

- “预训练”阶段应该是重新训练的,不太可能是在GPT 4o上通过继续预训练得到。 证据很好找,OpenAI官方一再宣称o1 mini逻辑推理能力极强,但在世界知识方面很弱。如果是在其它模型上魔改的,世界知识不会比GPT 4o mini更弱,所以侧面说明了是重新训练的;另外,这也说明了o1这类侧重逻辑推理的模型,在预训练阶段的数据配比方面,应该极大增加了逻辑类训练数据比如STEM数据、代码、论文等的比例,甚至我都怀疑o1 mini是否引入了通用数据都不好说,否则不需要老强调知识方面能力弱。
- 在“后训练”阶段,应该有一个环节是用来增强LLM模型的指令遵循能力的,也就是说RLHF阶段应该是有的。因为o1在遵循指令方面能力并不弱,而且生成的Hidden COT片段里明显也包含很多指令性的内容,如果遵循指令能力比较弱,估计对于生成Hidden COT也有负面影响。所以,推断起来这个环节大概在“思考”阶段之前。(但是RLHF阶段未必有RM和PPO)。大概率也会极大增强逻辑推理类的指令遵循数据比例,以此进一步加强基座模型的逻辑推理能力,原因我们等会专门说明。接下来的阶段,就是o1最大的特点,所谓引入了“系统2”的慢思考能力。ClosedAI只说用了RL强化学习,其它任何都没提,技术保密工作一流。由此,我们只能推断出o1融合了LLM和RL来实现模型“先想后说”的Think能力。
- 在模型推理(Inference)阶段,o1体现出了“先思考再发言”的特点,分为三个阶段:首先通过思考,根据用户Prompt的问题生成能体现思考过程的Hidden COT数据,因为很多Hidden COT很长,于是引入了“COT摘要”阶段,从很长的Hidden COT里提取一些关键思考环节展示给用户看看,最后根据COT输出答案。
从上面内容可看出,o1无论在训练还是模型inference阶段,和传统的LLM应该还是有很大区别的。此外,我在这里再展开讲讲两个事情。
- 想要仿造模型来达到类似o1的效果,一个很容易想到的取巧的方式是:既不去专门增强基座模型的逻辑推理能力(比如大幅增加预训练中逻辑类数据占比),也不做“慢思考”阶段的RL训练(因为不知道怎么做的),只是侧重在模型inference阶段加入“Think”的过程,比如想办法引入最简单的Best-of-N Sampling这种树拓展策略,再写写Prompt提醒让LLM自己要自我思考、自我反思,两者相结合,也可以让模型自己写Hidden COT。这样做,也能一定程度上提升模型的推理效果。但是,这种做法效果提升的天花板比较低,就是说你模型逻辑推理能力看着提高了一些,然后就会被卡住,即使再增加inference阶段的算力(就是把采样数量N比如从10个拓展到50个,类似这种。Inference-time Scaling law大概其实很可能就是这个意思,您觉得这做法是law还是不law呢?)其实也没用。这是因为对于简单或中等难度的问题,模型在inference的时候很可能给出答案中的大部分步骤都是对的(或者多次采样中多数是对的),只有个别步骤错误,导致最终回答错误。通过比如Best-of-N Sampling这种简单树搜索方法来增加输出的多样性,再加上靠谱的Verifier筛一筛,是比较容易把这个小错误修正过来的。但对于高难度的逻辑问题,因为模型输出内容中大部分步骤可能都是错的(或者多次采样中大多数都是错的,这种情况你投个票采取多数人意见看看,结果估计很悲催),你想靠inference-time增加算力无力回天。我自己也是根据上述思考,才进一步反推出上面讲的o1可能的训练过程的:OpenAI o1的基座模型,不论是Pre-training还是Post-training阶段,大概率极大增强了基座模型的复杂逻辑推理能力,这是它能在后续inference-time增加算力解决复杂问题的根基。所以关于这个点的结论应该是这样的:只靠inference-time增加算力,仅对容易和中等难度的逻辑问题有用,想要不断提升模型的复杂推理能力,还需要继续在Pre-Train和Post-Training阶段下功夫。
- o1应由多个模型构成。从o1的System Card可以明确看出,o1除了一个主模型外,至少还有一个相对独立的“Hidden COT摘要模型”(参考上图),它的作用是根据用户输入问题及生成的Hidden COT,提供一份简洁且内容安全的COT摘要。所以,o1至少由两个模型构成。那么,问题是:除了主模型和摘要模型,还有其它模型存在吗?我觉得大概率是有的。(推理过程忽略)o1模型大概由三部分构成(参考上图):一个主模型,一个摘要模型,还有一类可灵活配置个数的跟树搜索相关的模型池子。
OpenAI O1可能采用的训练数据
- 人工标注数据。训练o1肯定会人工标注一批COT思考过程,就是说拿到一批
<问题,答案>数据,通过人工把解决问题的思考过程和步骤写下来,形成<问题,思考过程(包括思考过程中出现的错误及错误修正过程),答案>。如果没有人工标注过程,那么COT里出现的:Hmm,wait,…这种,如果是纯靠LLM自己产生的,那估计LLM已经有意识了,这个概率很小,这些大概率最初来自于人工标注数据。可以用这些数据SFT一下o1初始的模型,启动模型的输出模式,让它熟悉这种表达方式,但是仅靠SFT肯定是不够的。 - 合成数据。人工标注难度大、成本高,所以人工标注的COT数据数量不会太多,人工标注的问题是可扩展性太差,优点是质量比较高;之后可以采用合成数据的模式,一种最直观的合成数据的方式就类似上面提到制作PRM标注数据的模式:从人工标注的COT里面截取一段人工标注片段,然后使用MCTS树搜索方式去补齐后续推理过程,每个片段跑多次,有的最后答案正确有的错误,无论是正确还是错误,都可以作为合成数据来训练o1模型。有一种极大拓展代码COT数据的办法:我们有大量现成的各种代码,可以教会大模型试着从代码反向生成Hidden COT的推理步骤,这个应该是可行的,并能极大拓展Coding类型的COT数据。
RL的关键要素及如何将RL与LLM融合:在Hidden COT场景下RL的关键要素:状态空间(State Space)、行为空间(Action Space)、奖励模型(Reward Model)。
- 关于o1的RL状态空间,首先的问题是:这个状态空间是离散的还是连续的?大概率是连续状态空间,或者说最好把它看成是连续状态空间。O1由LLM和RL组合而来,当用户输入问题时,很自然的,这些组成问题的Token序列作为一个整体可以看成第一个状态(State1),State1的Token序列作为o1模型的输入,o1在行为空间里选择某个行为(至于行为空间如何定义后面再谈),先不管这个行为是什么,反正选择这个行为后,o1会输出一个Token序列片段(不会是完整的Hidden COT,应该是其中的某个片段)。之后,o1把新生成的Hidden COT片段内容追加到State1之后,形成State2,再次作为o1的新输入,o1根据新输入选择新的行为,输出新的Token序列片段…..如此往复,直到Hidden COT输出结束。基本是这么个过程。
- O1中RL的可能行为空间:“思考因子(Thought-Factor)”离散行为空间。O1的RL技术方案,其中最关键的环节很有可能是如何定义行为(Action)空间。OpenAI 01的Hidden COT产生过程,本质上是在让机器模仿人在解决复杂问题产生的思考过程,而人在思考复杂问题时,有比较固定且数量并不太多的“思考模式”或者可以叫“思考因子”。比如拿到一个复杂问题,我们一般会首先明确这个问题的目标是什么,然后把复杂问题拆解成几个环节或者步骤,为了得到某一个具体步骤的解法,可能会提出一个假设,然后验证这个假设是否成立,如果不成立,那么继续提出新的假设,直到解决这个子问题…..我们也可能在过程中会进行验算并发现某些中间环节出现错误,并把错误修正过来。在我的设想中,一个合理的方法是归纳出人类思考复杂问题的隐含的“思考因子”,以此作为候选的行为集合,比如:“拆解问题”、“复述目标”、“检查结果”、“修正错误”、“提出假设”等等,总体数量应该不会太多,即使划分得细致一些的话,估计也就几十到上百种。而针对每个具体的“思考因子”,可以产生符合对应分布概率的Token片段,比如行为若是“提出假设”因子,则生成“Alternatively”这个Token的概率就比较大(通过PPO从训练数据里学到的)。也就是说,OpenAI的Hidden COT的原始内容或者训练数据,在形式上有可能是这样的二级结构:
<ACT_Proposer-Start> Alternatively, perhaps combine the numbers in some way. <ACT_Proposer-End> (提出假设) <ACT_RephraseTarget-Start> Overall Task: Write a bash script that takes one argument (the string representing the matrix) and outputs its transpose in the same format.<ACT_RephraseTarget-End> (复述目标) <Think_Start> (Hidden COT起始标记) …… <ACT-1_Start>token token token…..<ACT-1_End> (思考因子1) <ACT-2_Start>token token token…..<ACT-2_End> (思考因子2) <ACT-3_Start>token token token…..<ACT-3_End> (思考因子3) …… <ACT-n_Start>token token token…..<ACT-n_End> (思考因子n) <Think_End> (Hidden COT结束标记)这种层级的hidden COT结构,能体现出RL和LLM的优势结合,离散行为空间比如估算给定状态S采取何种行为,即函数Q(S,A)的估算,这是RL擅长做的事情,而思考因子标签中的Token生成则是LLM擅长的事情,LLM可以根据对应“思考因子”的类型,学习调整因子标签内部Token的生成概率。在生成Hidden COT的过程中,输入和输出都带有ACT行为Token的起始和结束符号,首先,O1根据当前的问题和已经生成的Hidden COT片段,预测下一个最可能采取的“思考因子”,以决定后面要采取怎样的具体思考模式,然后在这个“思考因子”指导下,LLM生成具体的Token序列,以“思考因子”的结束Token作为这种思维模式的结束标记。并将本步输出的Token序列并入输入,来循环往复地生成下一步思考的对应行为及Token序列。PS:训练时,吐出xxtoken ==> 归属于哪个”思考因子“ ==> rl 对“思考因子”给出奖励。推理时,当确定某一步的“思考因子”后,token的生成概率受本步所属“思考因子”的影响
- 目前常用的Reward模型有两种(参考上图):结果奖励模型(ORM,Output Reward Model)和过程奖励模型(PRM,Process Reward Model )。ORM的意思是训练一个模型,不管推导过程有多少步,只对最后结果打分。如果对照Hidden COT看的话,意思是只有o1把Hidden COT完整地写完了,ORM才给出一个奖励信号,模型结果若和标准答案对上了,给奖励1,如果答案错误,给奖励-1,类似这种。很明显,ORM的优点是反馈信号准确,比如对于数学题,模型要么做对了,要么做错了,很明确,所以反馈信号就精准;但ORM的缺点是反馈稀疏,意思就是反馈信号少,这个很直观,哪怕你推导过程写10页纸,反正最后只有一个反馈信号(OpenAI 训练大模型时RLHF阶段的RM模型,就属于ORM)。PRM的含义是训练一个模型,能对中间每个过程都给予反馈信号,这样在推导过程中错在哪个步骤就很清楚,不用等到最后,所以它的特点是反馈信号丰富不稀疏。但问题来了,要训练PRM就需要有每一步有标注的数据,这么多标注信号怎么来?常规做法是靠人工标注,比如去年很火的OpenAI的PRM工作“Let’s Verify Step by Step”,就是靠人工标注了80万中间步骤反馈信号的数学题推导过程,而且证明了PRM效果要比ORM好。所以,PRM的优点是反馈多效果好,但是训练数据制作成本太高,一般人做不了。那么OpenAI o1在训练过程会采用ORM还是PRM呢?我估计两者都会用。ORM精准,PRM反馈丰富,两者各有优点,结合起来效果应会更好。
对于AlphaZero来说,其本质其实还是MCST蒙特卡洛树搜索。围棋之所以看着难度大难以克服,主要是搜索空间实在太大,单纯靠暴力搜索完全不可行。如果我们假设现在有个机器无限强大,能够快速遍历所有搜索空间,那么其实单纯使用MCST树搜索,不依靠RL,机器也能达到完美的博弈状态。AlphaGo Zero通过自我对弈以及深度增强学习主要达到了能够更好地评估棋盘状态(V)和落子质量(P),优先选择走那些赢面大的博弈路径,这样能够舍弃大量的劣质路径,从而极大减少了需要搜索的空间,自我进化主要体现在评估棋面状态(P和V)越来越准,所以能越来越快地找到赢面最大的落子位置。而之所以能够通过自我对弈产生大量训练数据,是因为下棋是个规则定义很清晰的任务,到了一定状态就能够赢或者输,无非这种最终的赢或者输来得晚一些,不是每一步落子就能看到的。PS:MCST是主体,RL起到了加速搜索速度的作用。
如何融合LLM和RL两个模型,来获得一个同时混合LLM和RL两者功能的完整网络结构。
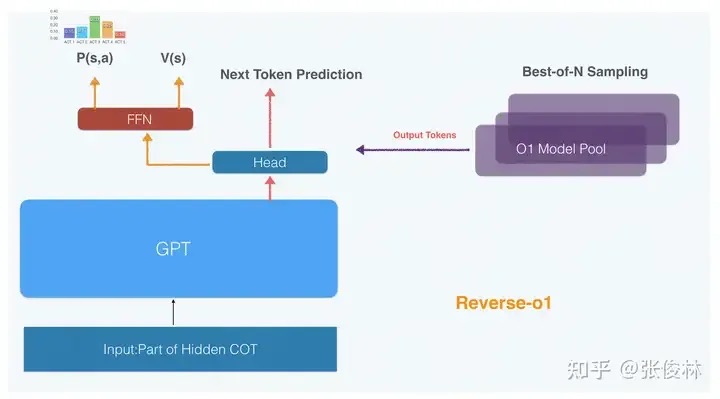
上图给出了一个我设想中的结构:主体仍然是基于Transformer的LLM模型,,当输入“问题+已经生成的部分Hidden COT”(也就是由连续Token序列组成的当前状态S)之后,经GPT网络对当前状态进行编码。在LLM 输出Head之上,可分化出两个子结构:一个用于常规的LLM 预测Next Token,这与通常的LLM一致;在Head之上,可以搭建RL模型结构,这里参考了AlphaZero的思路,一个网络两个输出。比如可以用FFN网络结构,一方面输出策略网络P结果(P(S,a)),代表在当前状态S下,下一步Action“思考因子”的分布概率pai,某个“思考因子”概率越大,则下一步这个Action被选中执行可能性越大;另外一方面会输出价值网络V结果(V(S)),代表当前状态S通向最终正确答案的概率大小,概率越大说明当前状态S质量越高,意味着目前已输出的这部分Hidden COT整体质量较高。到了这一步,当Hidden COT处于某个状态S的时候,经过网络可知下一步应该采取什么动作,也获得了当前状态S通向成功答案的概率。但目前仍缺少一部分内容,即在已知下一步“思考因子”行为后,对应的Hidden COT 一系列输出的Tokens。
一种简单的方法是用LLM head之上的LLM部分持续输出后续Tokens(有人工数据训练的时候,可以用PPO来增加对应Token的输出概率),在输出后续Token的时候并不考虑RL的输出,直到LLM输出到<ACT_i-End>之后,再去判断RL的输出选择动作…..持续此过程,结合LLM和RL输出Hidden COT的模型就能运转起来。在已知下一步“思考因子”后,不由主模型来生成后续Tokens,为了增加后续生成COT的质量,可采用Best-of-N Sampling的思路,由多个复制的Reverse-o1模型(不同副本可以设置不同的温度参数,增加输出的多样性)各自给出一个Token序列,然后由离线训练好的PRM作为评委打分,选择得分最高的Token序列,作为本次“思考因子”后续的输出Tokens。选出最佳内容后,可同步给主模型,主模型执行一次类似Prefill的操作,即可同步输出最佳内容,然后开始下一轮的输出……可如此办理,这么做明显生成的Token序列质量会更高。
PS:比较受教的是提出“思考因子”这个概念,这样搜索空间是一系列“思考因子”(比如人类总结的几百种思考因子),下一步action 先确定到“思考因子”粒度,然后再llm + “思考因子” 生成next token 到token粒度。具体的说,假设思考因子一共有100种,可以根据当前input + hiddencot,得到了下一步采信每个思考因子的概率,选取概率最高的那个“思考因子”(比如A),然后用比如10个模型,input + hiddencot <ACT-A_Start> 每个模型输出token 直到<ACT-A_End>,这10个候选token序列传入主模型,判断得到正确答案的概率更高,就选哪个token序列。训练数据是 <问题,思考过程(思考因子列表),答案>。o1创新的使用了强化学习,让大模型自己生成CoT,从而让大模型在很多领域具备了推理能力,实现了质的飞跃。
重要意义
o1这条技术方向不仅增强了模型的复杂逻辑能力,由此可能引发大模型研发很多重要方向的革新。
- o1给大模型带来了自我反思与错误修正能力,我觉得这点价值特别大。 GPT 4这类模型,因为在输出答案的时候是逐个Token输出,当输出长度较长的时候,中间某些Token出错是一定会发生的,但即使LLM后来知道前面输出的Token错了,它也得将错就错往下继续编(这也是大模型幻觉的来源之一,为了看上去逻辑合理,LLM得用100个错误来掩盖前面的第一个错误),因为落Token无悔,没有机制让它去修正前面的错误。而o1在“思考”也就是生成Hidden COT的过程中,如果你分析过OpenAI官网给出的Hidden COT例子的话,会发现它确实能意识到之前犯错了,并能自动进行修正。这种自我错误识别与修正对于LLM能做长链条思考及解决复杂任务非常重要,相当于越过了一个锁住LLM能力的很高的门槛。
- 所谓新型的RL的Scaling law。o1的RL大概率要么用了相对复杂的、类似AlphaGo的MCTS树搜索,要么用了简单树结构拓展,比如生成多个候选,从中选择最好的(Best-of-N Sampling),这种策略如果连续用,其实也是一种简单的树搜索结构。也有可能两者一起用。不论怎样,树搜索结构大概率是用了,COT是线性的不假,但这是产出结果,不代表内部思考过程就一定是线性的,我觉得靠线性思维推导过程很难解决复杂问题,树形结构几乎是不可避免的(我没有证据,但是可以推断)。无法忽视的是这种方法的可扩展性极好,无论是在RL训练阶段,还是LLM的Inference阶段,只要改下参数配置来增加树搜索的宽度和深度,就能通过增加算力提升效果,可扩展性好且方式灵活。。从这点讲,o1确实具有重要意义,因为这证明了它把怎么融合LLM和树搜索这条路走通了,LLM模型能够达到AGI的上限就被提高了一大截。
- 在o1之后,小模型大行其道真正成为可能。小模型最近大半年也比较火,但从能力获取角度看,其实还是有上限锁定的,这个锁定小模型上限的就是逻辑推理能力。小模型的能力特点是:语言能力很强不比大模型弱、世界知识不如大模型但是可以通过给更多数据持续提升、受限于模型规模,逻辑推理能力能提升但比较困难。
- o1可能会引发“安全对齐”新的范式。 O1在做安全对齐方面,大概采用了类似Anthropic的“AI宪法”的思路,就是说给定一些安全守则,指明哪些行为能做,哪些不能做,在o1逻辑推理能力提高之后,它遵循这些法则的能力也获得了极大增强,安全能力比GPT 4o强很多。这可能引发安全对齐新的模式:大家可以先把模型的逻辑推理能力加强,然后在此之上采取类似“AI宪法”的思路,因为OpenAI o1证明这种模式可极大增强大模型的安全能力。
- “强化学习+LLM”的领域泛化能力,可能不局限于理科领域。 强化学习适合解决Reward比较明确的复杂问题,典型的是数理化、Coding等有标准答案的学科,所以很多人会质疑o1是否能泛化到更宽的领域。确实,o1的思考能力能否泛化到没有明确标准答案、Reward不好量化的领域是它发展的关键,泛化得好,则打开阳光大道,泛化得不好,领域局限性就会比较强。我推测OpenAI可能已经找到了一些非数理学科的Reward定义方法,并将这个方法通过RL拓展到更多领域。既然o1可以读懂并遵循安全规则,以 “AI宪法”的思路解决安全问题,我觉得由此可以推导出一种针对模糊标准的Reward赋予方法:就是说针对不好量化的领域,通过写一些文字类的判断标准或规则,让大模型读懂并遵循它,以此来作为是否给予Reward的标准,符合标准则Reward高,否则Reward低。例如,针对写作文,就可以列出好文章的标准(结构清晰、文笔优美等规则),让大模型据此来给Reward。如此就能拓展到很多领域。当然,想要这么做可能要分步骤,先用好给Reward的数理问题增强模型的复杂推理能力到一定层级,这样它就能看懂规则了,然后再做那些不好量化Reward的领域。(这都是我的猜测,没有依据)
- 无论如何,给LLM纠错的机会,对于效果的提升都是可以预期的。LLM生成token的过程中,生成的序列越长,产生错误token的概率自然也会越高,后面模型为了自洽往往会用一百个谎言来掩盖第一个谎言,最后就彻底逻辑失控了。那么给LLM更多隐式COT和修正错误token的机会,总归可以一定程度提高质量。无论是在训练时候利用修正的结果去调整模型,还是在推理阶段把错误结果消除掉。
- 但要做到Scaling,这是一个需要深入思考的问题:大模型Self-play能否通过自我博弈持续提升?“持续”是非常重要的,本质问题是这样的提升是不是会快速收敛?这里不仅仅要考虑算法本身的持续可扩展性,也包括算法所需要的各个环节的输入的可扩展性。持续提升代表的是一个非常具有诱惑力的未来,也就是可以很快在深度思考和逻辑上不收敛地提升,快速超越人类。但如果存在不可扩展的地方,那会很快停在一个大概率上限也就是接近全人类平均水平的位置。强化学习本身的可扩展性是比较好的。强化学习第一性的核心就是policy和reward,policy负责输出具体行动,强化学习最终也是希望优化policy的行动策略来获得更多reward。各种强化学习算法虽然纷繁复杂,但本质上也是让policy随机尝试,如果尝试结果获得正向reward,那就调整参数让policy多往这个方向尝试,反之亦然。过去很多大多数强化学习任务都是建立在游戏类型的任务上,不过游戏有一个巨大的优势,就是reward获取极其容易,虽然相比监督学习而言,reward已经非常稀少了,毕竟一局游戏就能至少有一次输赢的reward。强化学习整体上发展到今天,整个工具箱已经挺完善了,基于这样密度的reward已经足够类似AlphaGo在16年就已经展现出惊人的可扩展性。
- 搜索的Scaling也不是问题。今天关于o1的大多数论文和分析解读都在深入研究各种搜索的花活。不管是简单粗暴的Best of N这种朴素的并行搜索,还是展开成树状用类似蒙特卡洛方法在思考深度上尝试用各种优先级多路径尝试,或者更花活一点做成一个图一样的结构进行更动态的搜索。其实这些方法没有非常本质的区别,Scaling都很容易,越简单粗暴的方式越有效,可以默念一遍The Bitter Lesson。很多人理解的Scaling就是在policy的搜索尝试上有巨大的空间,但reward的可扩展性才是最大的问题。无论哪种搜索方式,在每个搜索路径上给出reward反馈都是必不可少的。但reward的可扩展性就是语言最大的困境。语言和游戏不同,无论什么游戏,游戏本体都有输赢的reward,哪怕一局游戏给一个明确的输赢这种看起来非常稀疏的reward对语言而言都已经非常稠密了。试想一下,每次思考完一个问题都有对错的反馈实际上是非常奢侈的。语言实际上很多时候根本没有可扩展的reward方法,往往只有极少数domain才能有。采用人工标注的数据不仅仅是人力成本的可扩展性问题,更是上限也往往会封死在人类水平的reward上,无法做到不收敛地持续提升。合成数据同样如此,本质上也就是个离线的reward。一定程度上强化学习就是建立在高质量的reward基础上的,在游戏领域,精准的reward几乎是天然唾手可得的。LLM所面临的领域是完全开放的,通用可扩展的reward是比搜索方法本身更核心的问题。基础的RL概念体系一定是需要接近ground truth的reward的。
- Reward的可扩展性是不仅仅是数量上可扩展,也包括强度上可扩展。数量上可扩展很容易,我们可以用一些离线reward数据训练监督训练一个reward model来提供无穷无尽的reward,但这些reward的强度仍然是受限于有限的离线reward数据的。但如果policy的强度已经上来了,每次都是走的reward model评价最高的解,那么policy就没法继续提升了。游戏领域无论policy策略水平到达什么高度,游戏本体都可以精准地给出玩家最终的胜负或者得分,因此这样的reward是可以支撑policy持续提升的,因为这个reward本质上就是问题的ground truth。用LLM自己作为reward model是o1所代表的一类方式,但大多数情况下还是把LLM当作一个verifier,而不是真正推动整个系统不断调优的reward model。比如让policy LLM和verifier LLM相互对抗,看起来就像LLM自我对抗,self-play,产生大量的并行尝试,实际上目前已有的论文和分析基本最后还是需要一个额外的表示ground truth的真reward model来在这大量并行的尝试中给出偏好,从而校准无论是policy LLM还是verifier LLM。这里的verifier其实起到的作用感觉混杂了actor-critic框架下value model的作用,但也混杂了一部分reward model的作用。(强化学习概念就是多……)Value model本质上是QLearning体系下引入的对长期reward的一个短期近似。比如一局游戏最后有个输赢或者得分的reward,但是需要policy走非常多步才能得到,反馈给policy路径太长了,于是找一个中间的势能来描述每一步对最终长期reward的短期预估,从而更及时地给policy进行反馈,但同样的,value model也需要根据最终的reward不断调整这个短期近似的准确度,并不能真正意义上脱离最终的reward而直接把value model当作ground truth。
- 实际上我对新Scaling Law的存在并不悲观。但不是从RL视角,而是语言本身。语言所表征的概念空间是一个非常独特且迷人的代表思维的空间,我们不纠结语言是否等于思维还是语言只是思维空间的一种表征这种形而上的问题。但今天大模型所涌现出来的一切ICL能力、COT能力包括海量的常识、世界模型等等都是这个独特的概念空间所带来的。语言,或者说思维本身的特殊性可能反而可以带来持续增强,而不是RL。思维的对抗甚至不一定非要是LLM作为Policy和LLM作为Value/Reward之间的对抗,LLM作为生成式模型,本身可以作为任何一种角色进行相互对抗。只不过RL恰好提供了一套基础的Policy、Reward这样的概念可以将LLM套进去进行对抗。例如问黎曼猜想是对的还是错的,LLM中间强行推理一大堆,最后瞎蒙一个对的也能获得reward。而且即使我们获得黎曼猜想是对/错的ground truth,比如告诉大家这个猜想是对的,也很难激励大家找到证明他的方法。相反,即使最终没有获得答案,但证明过程产生大量推论,也是巨大的价值。光这两种情况的reward都是不一样的,我们其实也很难简单通过一些domain问题的ground truth来很好地奖励这两类不同的行为。reward cheating的空间太大了,不会就选C可能比学会做题更容易获得reward。靠RL支撑新的Scaling大概率会卡在reward的Scaling上,但语言不一样,语言本身具有自我增强的机会(这可能是个信念的问题了)。只是如何在语言中学到的这个思维空间如何探索,还需要很多研究来支撑,Scaling的关键更多是减少靠与人类对齐的方式,找到真正利用这个思维空间自举的潜力找到这个思维空间自由探索的能力。
另一份材料
当大家在网上探索o1是如何训练时,肯定会看到以下几个热点词:
- Test/Inference-Time scaling law,通过增加推理阶段的算力提升模型的推理能力
- Post Training,通过后训练提升模型的推理能力
- PRM/ORM:基于过程/结果的奖励模型
- CoT:思维链
- 强化学习、self-play(自我博弈)与MCTS(使用蒙特卡洛搜索树寻找最佳答案)
什么是Test/Inference-time Scaling Law
OpenAI o1模型的本质优势是什么? - 猛猿的回答 - 知乎设想一下,当我们手里有一个基础模型(我们称其为generator),但是这个模型的逻辑推理能力(比如解数学题的能力)较差时,我们该怎么改进它?再说的具体点,不考虑数据集相关的成本,假设我手头的gpu算力(FLOPs)是有限的,我该怎么利用它,能让我的模型最终能推理出更好的结果?一个比较直接的想法是:把算力花在它的pretain阶段,给模型注入更多数理逻辑的预训练知识。例如用更好、更多的代码数学等数据,或者扩展模型的参数规模。这个做法启发自大家都很熟悉的scaling law(更具体地说是pretrain-time scaling law)。但是,当我们研读openai o1的技术报告时,我们会发现,它把这个算力更多地用在了2个地方:
- 用在了rlhf的训练上(post training)
- 用在了模型的推理阶段上(Test/Inferece) 正如pretrain scaling law受到模型参数和训练数据的影响一样,Test/Inferece scaling law也必然受某些因素影响,而这些因素是什么,又是怎么影响的?不过等等,此时你肯定想问:
- 一般来说,一个模型的效果是由它的训练阶段决定的,所以如果这里说通过pretrain或者post training来提升模型的推理能力,我都能理解。但是inference阶段是怎么提升模型的推理能力的?你说的把算力用在inference阶段到底是什么意思?
- post training和inferece是两种独立的提升模型推理能力的方法吗?它们可以结合在一起使用吗?
把算力用在inference阶段,也就是说,在不变动pretrain阶段的情况下,只通过推理等层面的优化,来提升模型最后的生成效果。这里又分成两种情况。
- 优化推理输入:prompt。这个方法大家应该非常熟悉了。例如,原来你的模型吃一个问题,直接吐给你回答。但是现在为了让模型能更好模拟人类的思考方式,你希望【模型在步步思考后再给出回答,也就是模型的生成结果里包含思考步骤+答案】,那么你可以选择在prompt中给模型相应的例子,或者在多轮对话中引导模型think step by step,来实现这个目标。你的prompt给的越细节,你的多轮引导给的越多,模型或许就能产出更好的结果。比如DSPy 的APE。难点是,要么一个问题给一个这样的prompt,要么所有问题共用一个这样的prompt。
- 优化推理输出:revise output distribution。可是,优化推理输入的方法还是不够直接。难道对于每一个问题,我需要精心设计prompt,或者手动诱导模型think step by step才行。所以能不能让模型吃下一个问题后,自动化地去做CoT的过程呢?也就是说,现在我们希望模型在吃下一个问题后,能自主产生以下输出:
attempt1 -> attempt2 -> attempt3 -> ...-> attempti -> answer,其中,每个attempt包含“多个中间步骤steps + 最终结果”,也就是它在模拟人类的思考过程:先做一次attempt,然后发现问题,在此基础上在做别的attempt,直到找到最终答案。那么我要怎么让模型做到这点呢,一个直观的方法就是,如果我有:problem -> attempt1 -> ... -> attempti -> answer这种带标签的数据,那我不就能直接训练了?训练的方法也有很多,例如: - 我直接做sft,把最正确的attempt放在输入序列最后,当作label进行训练即可
- 我用类似rlhf的方法,先有一个奖励模型,它能对每一个思考步骤做评估,然后利用这个评估结果,指引模型步步搜索,每一步都找到最佳的思考步骤,最后不就能找到答案了? PS:Inference-time体现在,当用户输入一个问题之后,o1要花费更长的时间进行「思考」,其实也就是在生成最终答案之前,先生成了很多reasoning tokens。所以就得训练llm不要直接给答案(心直口快),得养成step by step(甚至带上反思)的”本能“
这两种解法,仅从训练方法上来说,都可以算成是post-training,也就是我们通过把算力花在post-training上来提升模型的逻辑推理能力。可是,本文的标题不是【把算力花在inference上】吗?inference在哪里呢?我们再重新端详这2种解法:
- 假设我们使用解法1或者解法2 post training好了模型,现在我们拿它做推理。模型吃一个问题,产出一系列中间结果和答案,但是你能保证,这些中间结果和答案一定是最好的吗?
- 所以此时,一方面,我们可以考虑优化推理阶段,即使用一个能够评估中间步骤的verifier,在推理时指引模型搜索出最佳答案。例如,我们对一个问题采样多个attempts链,从中找最好的。或者在单个attempts中找到最好的attempt,诸如此类。
- 而另一方面,我们可以考虑在post-training阶段,使用这个verifier来指导模型自动化生产高质量的数据(这是个inference步骤),基于这些数据我们再做对齐。如果这个流程做得好,我们甚至可以直接信任post-training后模型的结果 所以,【优化推理输出】这一部分,你可以把算力全部花在post-training上,也可以花在post-training+inference上,从o1的技术报告上看,它应该选择了后者,同时post-training选择了某种基于强化学习的方法(其实o1在pretrain阶段应该也有变动,具体的分析我们在后文中会通过实验数据给出猜想)。至此,我们就把问题1和问题2都回答清楚了。
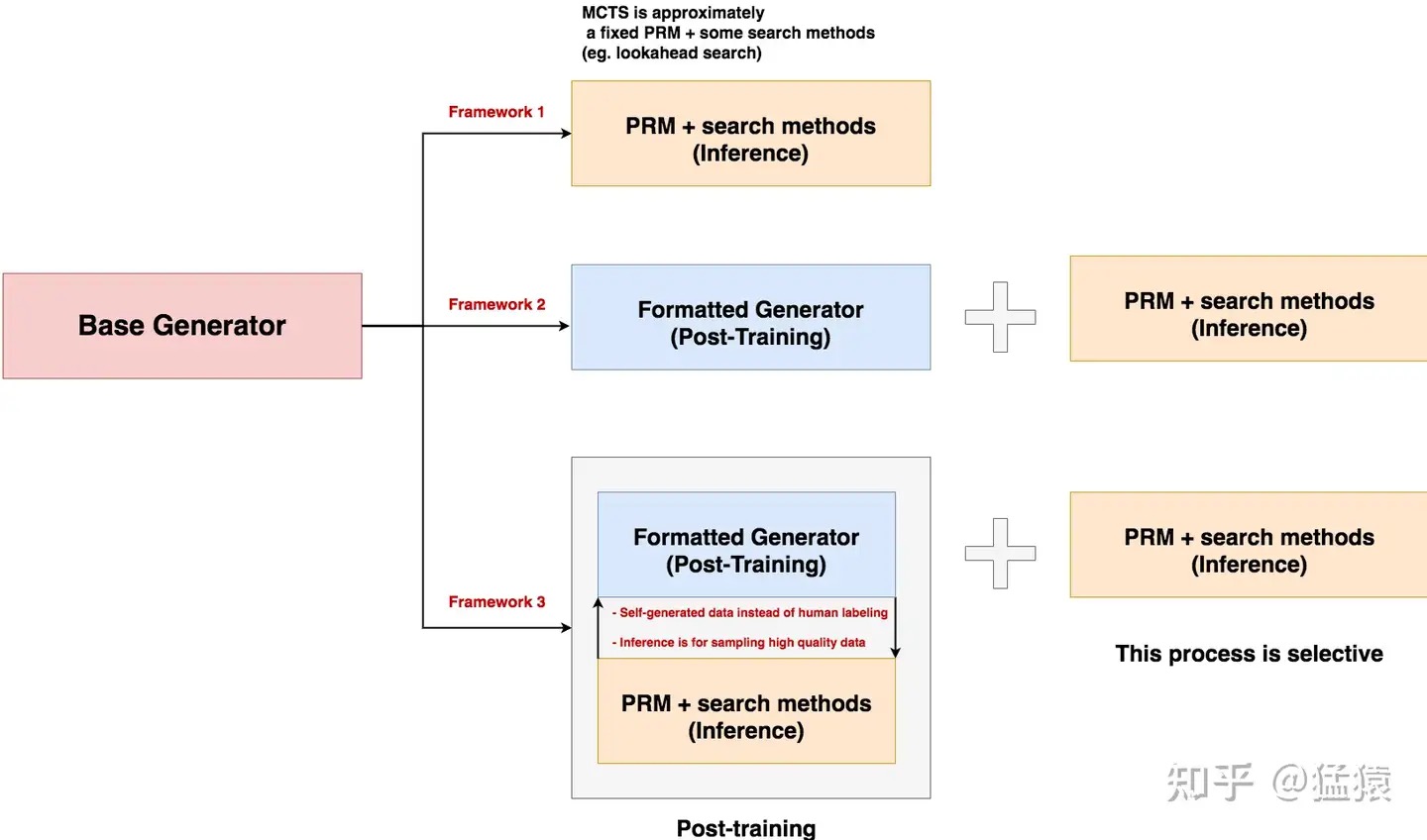
一个能按照格式,产出中间思考步骤的模型(generator),但中间思考步骤质量得不到保证。一个能对中间思考步骤进行评估的奖励模型PRM(verifier)。而现在我们想做的事情是:如何在不对generator继续做任何训练的情况下,使用verfier,来引导generator搜索出最佳的“steps + answer”?
- 使用PRM指导搜索过程。
- 直接改变模型的输出分布
另一份材料
OpenAI o1模型的前世今生一种可能的技术路线推测
- 在Pre-Training阶段:o1重新训练了一版Base Model,使用了大量的代码、数学等STEM领域语料以及一些CoT语料,但是较少使用含有世界知识的语料,主要关注Base Model的推理、对话能力。
- 在Post-Training阶段:首先进行RLHF,提高模型的对话能力以及指令跟随能力;然后进行Self-Play的RL,通过自举的方式生成CoT,RM为一个LLM的PRM,RL过程中二者可以通过NL对话;最后进行Safety的相关训练。
- 在Inference阶段:o1直接生成CoT,然后再对CoT总结,将总结内容输出给用户。
Post-Training: SFT,获得的Base Model并不能直接用于强化学习,这是因为Base Model几乎没有在Zero-shot Prompt下生成CoT的能力,此时应该使用大量的带有CoT的数据进行SFT,使Base Model获得基本的CoT能力。什么样的CoT是一条好的CoT呢?o1的基础贡献者Hunter Lightman在其论文Let’s verify step by step中开源的PRM800K数据集有明显的独特风格,学术界普遍认为o1是该工作的继续。
- 风格一:表述口语化,更像是自我对话。
- 风格二:频繁使用换行。Let’s verify step by step中为了方便解析generator生产的推理过程,将其CoT设置成频繁换行的格式,这样一句话就是一个思维链的step或process,方便人工打标。
- 风格三:思考行为的关键词相似。强行将模型的思考行为定义在一个闭集里,找到对应的关键词,试图找出模型思考时的口头禅,思考行为可以用不同的关键词来显示明确。 |思考行为| 关键词| |—|—| |提出假说| Idea:| |否定假说| No.| |改换假说| Alternatively,| |强化问题| So the user is requesting …| |自我纠正| Wait, earlier I missed …| |拆解问题| Approach:|
- 风格四:过程进展缓慢,充满废话和冗余。其希望生成的CoT在不重复过去内容的情况下越长越好,这可能是因为CoT越长则每一步越具体,模型会做更多的思考,整套CoT的逻辑性越好。
明确了CoT的标准后,那么如何构造CoT数据呢?STaR核心思想是:利用LLM已有的推理能力,迭代式Bootstrap模型产生合理推理过程(Rationales)的能力,并将Rationales融入训练过程内,让模型学会推理,教会模型内部深入思考问题和答案的关联。其方法的步骤如下
- 推理:对于一个数据集中所有的问题和答案pair,形如
<Question, Answer>,让模型M去根据问题生成中间推理过程和答案,得到<Question, Rationales, Answer>。 - 过滤:如果生成的答案是正确的,则将推理过程加入到原有数据集中;如果生成的答案是错误的,则尝试在给出正确答案前提下再次生成推理过程,这时正确的答案作为Hint。用最终生成正确答案的推理构建一个微调数据集对模型M进行微调。
- 迭代:重复这个过程,每次获得一个新的数据集,都在原始的模型上进行微调,防止过拟合。
经过SFT之后的模型初步具备了推理能力,面对一个问题,模型可以通过成CoT来拆分、解决问题。这也是为什么OpenAI要求用户在使用o1时无需精心设计Prompt,更无需添加”Let’s think step by step”来显式调用CoT,只需描述清楚问题即可。但是此时模型的推理能力还不够强,需要通过强化学习进一步增强其推理能力。
在游戏领域进行Self-Play时,Verifier通常很强大,因为规则是清晰和固定的,而且有无限的奖励数据可以用来训练验证器,但Generator一般比较薄弱;相反的,在LLM领域,Generator的能力通常很强大,而Verifier通常比较薄弱,这是因为自然语言的复杂性和主观性导致的,此外奖励数据也很稀缺。但是现在时代变了,LLM领域的verifier也可以的很强,首先是奖励数据的增加,其次在特定领域其实是很好打分的,比如o1很擅长的STEM领域。Self-Play的可以看作是Generator和Verifier的对抗,有点类似GAN的思想。所以Verifier可以使用LLM-as-a-Judge模式,这样Verifier的就有了初步可以与Generator对抗的能力。此外,Verifier和Generator要同时更新,防止Reward Hacking。但是仅仅使用与Generator同参数级别的LLM作为Verifier还不够,传统的生成式Reward Model(GenRM)利用fine-tuned LLM的predict next token的能力通过预测下一个单词是”Yes”还是”No”来判断一个 <Problem, Solution> pair对是否正确。而GenRM-CoT在verify过程中加入了CoT的思想,不仅评估解决方案的正确性,还通过生成中间推理步骤来详细解释为什么一个解决方案是正确或错误的。这种链式推理过程除了提升了整体推理的准确性和可解释性,还可以与Generator进行自然语言形式的交互,这种交互类似外交官游戏,方法整体很像人类标注员的思路,摆脱了判别式RM中黑盒假设的枷锁。PS:如何训练一个牛逼的Verifier?
为什么要在Post-training阶段大做文章呢?有以下几个原因:
- LLM例如GPT-4都是自回归模型,都使用Predict Next Token的逻辑,所以会一直Look Ahead,无法学会自我纠正。例如在数理推断问题上即使增大模型参数也无明显效果提升,所以要在Post-trainig阶段引入强化学习;
- 根据Pre-training Scaling Law,目前提升预训练阶段的投入,模型性能的边际收益会递减;
- 根据Post-training Scaling Law,RL Training阶段的计算量和Test Time计算量的提升可以更有效率地带来模型性能的提升。
- Post-training阶段的Scaling Law:当不受其他因素制约时,模型的性能与强化学习(训练时计算量)、思考时间(测试时计算量)之间也呈现幂律关系。
MCTS
- 为什么要将 LLM 与 MCTS 结合起来?
- 为什么 LLM 可以与 MCTS 结合起来?
- LLM 要如何与 MCTS 有效结合起来?
- LLM + MCTS 是终极方案么,有何局限性?
OpenAI明确表明 o1的训练借鉴了AlphaGo的强化学习思路,而AlphaGo主要使用了Self-Play和蒙特卡洛搜索(MCTS)。根据围棋的规则,棋子可以在19 X 19的棋盘上选择落点。如果使用暴搜法,那么将有 361!种可能,即使去除其中不合法的情况,可能性仍比宇宙中的原子个数$10^80$高出20个数量级。此时,可以使用MCTS来近似暴搜的结果,MCTS是一种用于决策过程的启发式搜索算法,它包含四个步骤:

- 选择(Selection): 从根节点开始,根据某种策略(如上置信区间 UCB),选择一个最优的子节点,直到到达一个尚未完全展开或终止的节点。
- 扩展(Expansion): 如果所选节点不是终端节点,从该节点中随机选择一个未被访问过的子节点,添加到搜索树中。
- 模拟(Simulation): 从新扩展的节点开始,进行随机模拟(也称为“Playout”,通常使用随机策略),直到达到游戏的终局状态。根据终局状态的结果(如胜负或得分),评估该模拟。
- 反向传播(Backpropagation): 将模拟的结果反向传播到所有经过的节点,更新各个节点的统计信息(如胜率、访问次数),以便未来的决策可以基于更精确的估计。PS:类似于前人某条路走了xx次,胜率xx,后人可以参考
简单通俗地讲,AlphaGo包括两部分:一个CNN卷积神经网络和MCTS算法,CNN相当于人类的”棋感“系统,它负责根据当前棋盘上的形式给出下一步可能的落点的集合;MCTS相当于理性思考,可以在CNN给出的候选落点集合里找到胜率最高的位置。提升的CNN可以找到更好的落点,MCTS的性能也会提升,MCTS性能的提升的结果反馈给CNN,则CNN的性能会再次提升,整个过程形成正反馈循环。AlphaGo首先在人类棋手的棋谱上进行监督学习,然后自我博弈(Self-Play),即在每一局自我对弈中,AlphaGo 的不同版本与自己对战,并根据对局结果更新模型的策略网络和价值网络,通过自我对弈,AlphaGo不再依赖人类棋谱,能够探索新的战术和策略,超越人类棋手的水平。
OpenAI o1模型的前世今生MCTS多在Action为闭集的场景下使用。笔者认为o1没有使用MCTS,甚至没有使用搜索算法,而是使用类似STaR方法中的。其实MCTS在除了下棋以外的场景上基本没有成功的案例,尤其是在自然语言组成的几乎无限空间的场景上。
阿里Marco-o1推理大模型技术报告解读由论文内容推理MTCS和LLM的算法流程,具体来说:
- 在选择阶段,从根节点开始,算法根据特定的策略(如UCT策略)导航到最有潜力的子节点,直到到达叶节点。
- 节点的选择基于其累计奖励(置信度得分)和访问次数,优先选择奖励较高的路径。具体选择标准是从当前节点出发的推理步骤中,挑选出奖励分数 较高的节点,即具有较高累计置信度的路径。
- 在扩展阶段,在叶节点处,除非它代表游戏的终止状态,否则会添加一个或多个新的子节点来表示未来的可能移动。
- 在选择阶段到达一个尚未完全展开的节点后,将其子节点扩展到搜索树中。从当前节点输入 LLM,生成潜在的下一步推理输出,这些输出被作为新节点添加到搜索树。生成的子节点代表不同的推理方向(例如下一步的逻辑步骤或不同的解法路径)。扩展过程通常生成多个候选输出,例如基于 LLM 前 5 个置信度最高的候选 token,从而捕获可能的推理分支。
- 在模拟阶段,从新添加的节点开始,算法进行随机模拟(通常称为“rollouts”),选择随机移动直到游戏结束,从而评估节点的潜力。
- 模拟由 LLM 完成,执行一个完整的推理链展开。在每一步中,LLM生成的 token 置信度通过 softmax 计算得出。整个模拟路径的总体奖励v是所有 token 置信度得分的平均值。模拟结束的条件可以是推理链完成、达到预设长度或模型预测的终止标记。
- 在回溯更新阶段,模拟结束后,结果(赢、输或平局)被反向传播回根节点,更新每个遍历节点的统计数据(如赢、输次数),以指导未来的决策。
- 将模拟结果(奖励v)沿路径从当前节点反向传播,更新父节点及祖先节点的统计信息。每个节点更新其累计奖励和访问次数:奖励:$w_i <- w_i + v$ ,访问次数:$n_i <- n_i +1$ 。奖励值v是 roll-out 路径的置信度得分的平均值,表示路径推理质量。回溯更新确保整个搜索树能够动态调整,未来的搜索倾向于奖励较高的路径。PS:有一个推理llm 生成一个推理路径,有一个对推理路径评分的模型,进而优化推理llm的参数。 MTCS的用处是扩展了搜索空间,呈现类似TOT的效果 通过反复迭代这些阶段,MCTS逐步构建决策树,优化在状态空间庞大且难以直接计算最佳策略的场景中的决策。
推理动作策略。
- 动作选择。研究者观察到,以动作作为蒙特卡洛树搜索(MCTS)的粒度较为粗糙,这种方式往往导致模型忽视解决复杂问题所需的关键推理路径。为了解决这一问题,研究者尝试了不同粒度的搜索单元。起初,研究者使用完整的“步骤”作为搜索的基本单位。随后,为了进一步扩展模型的搜索空间并提升其解决问题的能力,研究者尝试将步骤细化为更小的单元,即每32或64个Token组成的“微步骤(mini-step)”。这种更细粒度的划分使模型能够以更高的精度探索推理路径。尽管在理论上,以Token级别为单位的搜索能够提供最大的灵活性和精细化,但由于计算资源的高昂需求以及构建有效奖励模型的难度,目前在实践中尚不可行。在实验中,研究者在MCTS框架下实现了以下策略:
- 步骤(Step)作为动作(Action):允许模型生成完整的推理步骤作为动作,每个MCTS节点代表一个完整的思维过程或行动标签。这种方法在探索效率上具有优势,但可能忽略解决复杂问题时需要的更细粒度的推理路径。
- 微步骤(Mini-step)作为动作(Action):将32或64个Token作为一个微步骤的动作单元。这种更细的粒度扩大了问题解决的空间,通过在搜索过程中引入更多细微步骤,增强了模型应对复杂推理任务的能力。在这一粒度水平上探索解决方案空间,能够帮助模型发现以较大动作单元可能忽略的正确答案。 研究结果表明,采用更细粒度的MCTS搜索策略可以显著提升模型的推理能力,从而更有效地解决复杂问题。
- 反思机制。研究者引入了一种反思机制,通过在每次推理过程末尾添加短语“等等!也许我犯了一些错误!我需要从头开始重新思考。”来促使模型进行自我反思并重新评估推理步骤。这种机制显著提高了解题的准确性,特别是在原始模型初始错误解决的复杂问题上表现尤为突出。加入反思机制后,大约有一半此类困难问题能够被正确解决。从自我批评的角度来看,这一方法使模型能够充当自己的批评者,从而识别推理中的潜在错误。通过明确提示模型质疑其初始结论,这一机制鼓励模型重新表达并优化其思维过程。自我批评机制充分利用了模型检测自身输出中不一致性或错误的能力,从而提升了解题的准确性和可靠性。反思步骤作为一个内部反馈循环,有效增强了模型在没有外部干预情况下的自我纠错能力。这一机制不仅显著提升了模型解决复杂问题的能力,还强化了其解题的准确性和鲁棒性。
MCT Self-Refine (MCTSr)的算法(包含代码理解) 代码层级的理解看这里。
从人类决策习惯来看
如何提升大模型的“深度思维能力” 人类的思维过程始终在动态平衡中运行:一方面,通过联想、查阅资料、与他人交流等方式“增加”信息;另一方面,通过筛选、排除、归纳等方式“减少”信息,逐步聚焦于可行的选项。这种“增-减”的循环贯穿于大部分推理和决策。从信息论的角度看,人类决策的核心目标是降低信息熵。信息熵代表了系统的不确定性程度。在高熵情况下,所有选项看似差异不大,决策难以推进;在低熵情况下,选项变得更加明确,决策变得轻松。以旅游计划为例,假如我们同时考虑了数十个景点,而它们在吸引力、距离等方面差异不大,就会产生高信息熵的困境。为了突破这一困境,人类通常会引入更多信息,如“当前季节的景色特点”“附近是否有知名餐厅”等,以逐步拉开选项间的差距,最终让决策变得明确。
既然人类是通过增-减信息以降低信息熵的,那么同样的模式能否应用到大模型上呢?我们先观察信息熵是否对大模型而言同样适用。大模型通过预测下一个词生成文本:
- 当下一个词非常确定,则显然的概率被集中在少数甚至一个答案上,这时其信息熵较低,模型对于结果比较有信心。
- 当下一个词的概率分布高度分散、每个词看起来几乎等概率时,也是信息熵极高的情况,模型实际上处于一种无法判断的状态。需要注意的是,这种“无法判断”不是简单地回答“我不知道”,而是连是否该选择“我不知道”都不确定。
- 从结果看,信息熵能代表模型的准度,尽管这一准度的评委似乎是模型自己,这本身似乎陷入了“循环论证”的过程,然而大模型本身也是对人类逻辑的拟合,实际上人类也在试图“解释”现象以降低信息熵,提高一致性,数据的一致性越高,模型拟合到的推理过程的一致性就越高。我们暂且搁置实际执行过程中可能存在的“循环论证”的问题,转而做一些观察,我们看看增-减信息以降低信息熵的方式,能否让模型本身准度有所提高:
- 对于增加论据的模式,COT应用的成功也证明了增加相关“证据”并逐渐接近答案,能让模型的准确率显著提高,增加足够多的论述过程,会让模型更倾向于得到这些论据所论述的答案。
- 对于减少噪声的模式,可以观察到的一点是,尽管拥有强大的注意力机制,但当上下文过长或信息过于复杂时,模型的预测精度也会显著下降。适时总结前文继续往下推理的模式,也是能让模型精度有所提升的。
根据之前探讨的内容,模型的语料中缺乏思维能力,甚至有很多相互矛盾的内容,这样的语料内在逻辑并不自洽,我们会尝试探讨如何像人一样重新“思考”一遍这些语料,并把思考过程的信息补充进去,以得到一个逻辑自洽的语料,从而降低信息熵,增加模型准确度,并且使得模型具备看上去的“思维能力”。 我们需要对于符号做一些简单的约定,我们用大写字母表示“证据/结论”:
- 推导过程用“->”符号表示,例如“杭州->适合旅游”,这意味着模型看到杭州这个词推导出适合旅游这个结论。
- 共同作用的推导过程“()->”表示,例如(充足的阳光,定期浇水)->植物健康生长,同理更多的条件时以(A,B,C,D)->E表示。
在增加信息以获取更强大模型能力的角度看,多步推理是一个非常重要的场景,典型的形式是A → B → C → D的链式推理。然而,现实语料中,面对复杂问题我们往往看到A → D的简化结论,例如“如何评价xxx公司的未来发展”,大模型往往倾向于直接“背诵”已有的分析结果,这是因为语料中对于这类复杂问题更多是结果性的内容,推理路径的缺失成为模型学习复杂逻辑的主要障碍。这引出了一个核心问题:如何合成逻辑自洽的推理路径,提升大模型的思维能力?
- 路径生成。生成推理路径的难点在于路径的多样性与逻辑自洽。对于同一个问题,可能存在多条不同的合理解法。以数学为例,一个定理往往可以通过多种证明方式得到结果;而在自然语言中,推理链条的表达可能更加多样化,语义上的灵活性让问题更加复杂。在数学问题上,CoT技术是非常成功的应用,通过CoT产生更多的中间推理过程数据,从而用以训练能使得模型可以逐步生成逻辑清晰的中间步骤,直到最终答案。这其中很关键的两个要素在于下一个论据的可枚举以和可验证,对于一般任务而言任务,我们可以采取更宽松的方式,例如通过大模型本身(或专为此任务微调的模型)结合人工定制策略扩充推理数据,另一种思路是直接借鉴已有人工设计的推理链条,尤其是在特定领域已经实践的人工编排策略,这种方法可以快速生成高质量的推理语料。
- 推理粒度与压缩。生成多步推理路径的另一个关键问题是:在什么情况下直接从A → D更有效?什么时候需要完整的A → B → C → D路径?这实际上涉及到语言模型的压缩原理。语言模型的本质是学习词与词、句与句之间的关系,并将这些知识压缩进模型。如果在语料中,A → D的频次足够高,模型学习这一关系的代价会远低于生成A → B、B → C、C → D三个关系之和。此时,从“压缩效率”的角度看,直接记忆A → D更优。然而,当A → D的出现频率较低,或者需要推理的任务复杂性更高时,模型会倾向于依赖A → B → C → D等逐步推理过程。从人类的角度来看,这种现象也有迹可循。我们的深度思考(“System 2”)会将高频推理结论沉淀为直觉(“System 1”)。例如,在日常生活中,我们很少再去逐步推导“重力会让物体下落”这一结论,而是直接将其作为常识。对于大模型,类似的压缩机制也可能自然发生,尤其是在A → D的频率足够高时。一个关键的启发是,“论据”粒度的选择需要基于全局视角。对于高频结论,直接学习A → D是一种高效选择,因为它减少了推理链条的存储和计算开销。对于低频结论或复杂任务,生成完整路径A → B → C → D则显得尤为重要。这不仅能提升模型的泛化能力,还能为任务提供更高的可解释性。这种粒度选择需要结合语料的统计分布和推理任务的目标。理想情况下,模型应能够根据任务需求动态调整推理路径的粒度:在需要效率时,优先使用简化结论;在需要逻辑完备时,生成详细路径。
- 多结论问题。在数据中的表现为同时存在A → B和A → C的语料,当模型学这种语料中学习时,遇到A为前提的问题,无法判断答案应该是B还是C,亦或者错误答案C的语料多,而正确答案B的语料少,在缺乏更多信息的情况下,模型很难给出正确答案。这种情况下,真实逻辑可能的是:(A, D) → B 和 (A, E) → C,也就是说,隐藏的条件D或E对推理结果起到了决定性作用。这种现象实际上颇为常见,例如同样是给出行程安排的情况,一些猎奇博主给出的旅行方案可能全篇都是猎奇的,而美食博主则可能更多关注美食,如果能把贯穿始终的风格提前识别出来并注入语料,能让模型更多以更一致的视角回答问题,降低信息熵,提高模型准度。对于一般的“错误和偏见”问题,例如“三亚这人虽然不多,但是太热了,不适合来玩”,可能是因为“现在是夏天,而夏天是淡季”,这种类似人类阅读直觉的,能让语料本身的逻辑更加自洽。除此之外类似小说创作先列出大纲,笑话先写出笑点,对于创造的稳定性而言都是显著的增加。
- 降低信息/噪声。在人类的逻辑语言中,经常在同一篇文章中会存在大量不相关的内容,越是长的论述中,越容易出现这种现象,因为人类在做深度思维时,总会习惯性的拆分出多个子问题,以分开论述,例如(A, B) → C,在逐步证明A和B的过程中,会引入大量的过程论述,一直递归到足以回答问题为止。然而这一过程也为整个文本注入了大量的噪声,例如当我们论述B时,A的论述过程对B而言是噪声。类似的现象还有很多,例如当我们让大模型帮我们写一本小说时,我们会列好大纲,也可能是多级的大纲,然而当我们考虑把大纲中某一章节展开细节时,前文大量的过程都我们而言都是噪音,亦或是大纲的形态也可能是双线叙事,另一条故事线的很多细节也是对于本故事线而言也是噪音,我们只会关注交织点或者可能的共同点等。
可以看到,不管是增加信息还是减少信息,其过程都对语料全局的统计信息有所依赖,例如单步推理的合理性评估、对文本目的性的识别、路径颗粒度的合理程度等等,对于统计信息的依赖,一个比较容易的路径就是利用现有的大模型,因为现有大模型已经对整体语料“学习”过一遍,再对其进行针对性微调,模型在很大程度上能胜任这些任务。也就是说,通过当前模型的弱推理、弱规划能力,逐步强化数据以达到更强的推理、规划能力。 对于模型如何学习“人类思考过程”还有很多可以探讨的内容,限于篇幅,太多细节不便展开。人类在“阅读”知识的时候,会持续加入自身理解和判断,主动聚焦和拆解问题,而目前大部分语料并不具备这样的过程记录。对于大模型而言,通过对人类学习过程的模拟来加深模型的思考能力,能很大程度提高其推理能力。深度思考能力是人类解决复杂问题能力的核心,甚至是通往AGI的必经之路,通过预训练语料的修正只是其中一环,如何与真实世界链接,如何建立类人的反馈机制,这些问题一步步解决,似乎让我们能够瞥见AGI一眼。 PS:让llm有思维能力,一个是预训练 数据就得有体现思维的数据让llm“见识”过,再一个就是微调的时候对推理过程有评价,让llm被“知错就改、刻意练习”过。