
简介
- 预训练模型是一个未加控制的“怪物”,因为其训练数据来源于对互联网内容的无差别抓取,其中可能包括点击诱导、错误信息、政治煽动、阴谋论或针对特定人群的攻击等内容。
- 在使用高质量数据进行微调后,例如StackOverflow、Quora或人工标注,这个“怪物”在某种程度上变得可被社会接受。
- 然后通过RLHF进一步完善微调后的模型,使其更符合客户的需求,例如,给它一个笑脸。 你可以跳过这三个阶段中的任何一个阶段。例如,你可以直接在预训练模型的基础上进行RLHF,而不必经过SFT(Supervised Fine-Tuning,监督微调)阶段。然而,从实证的角度来看,将这三个步骤结合起来可以获得最佳性能。预训练是资源消耗最大的阶段。对于InstructGPT模型,预训练阶段占据了整体计算和数据资源的98%。可以将SFT和RLHF视为解锁预训练模型已经具备、但仅通过提示难以触及的能力。
流程
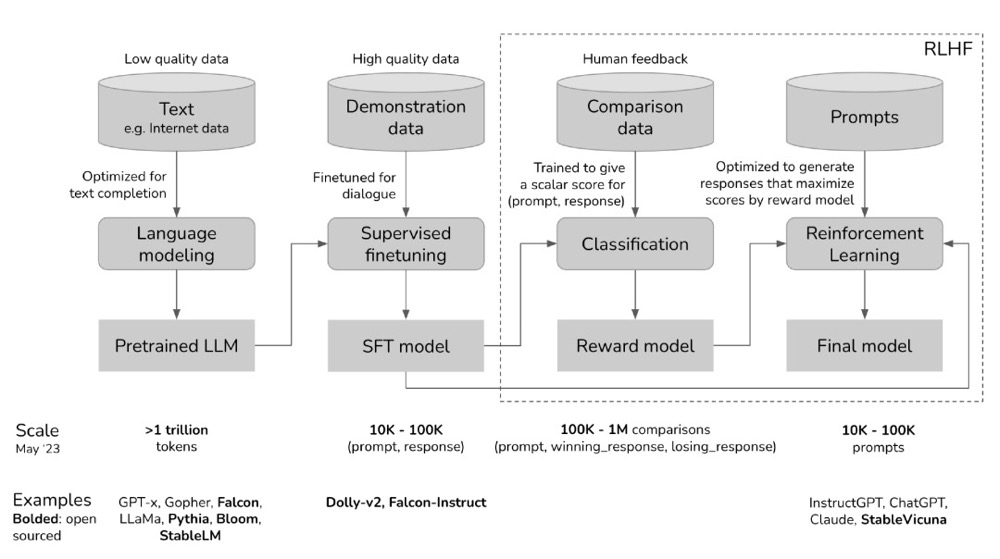
图解大模型RLHF系列之:人人都能看懂的PPO原理与源码解读
RLHF——让大模型对齐人类偏好预训练主要针对补全能力,但不一定是“有用”的补全。RLHF优化模型所涉及的三个步骤
- 指令微调(SFT):模型会模仿其训练数据,使用精选的人类回答数据集来微调预训练的大语言模型以应对各种查询。这让模型获得了优异的指令理解和意图识别能力,模型的输出也更符合人类的期待,胜过通用文本生成模型,弥补了 LLMs预测下一个单词目标与用户遵循指令目标之间的差距,指令的作用是约束模型的输出,使其符合预期的响应特征或领域知识,为人类干预模型的行为提供一个通道。PS: chat 模型就是SFT 过的模型
- 指令微调SFT(Supervised fine-tuning)的数据集是问答对,即(prompt,answer)对,prompt我们可以理解为指令或问题,answer就是针对该指令或问题的高质量答案。SFT就是在预训练模型基础上利用这些人工标注的数据进一步微调
- IFT可以算作SFT的一个子集,或者说先驱步骤,IFT的主要目的是让模型适应并听从人类的指令,比如当指令prompt出现”summarize”时,模型就应该知道现在的任务是总结任务。经过IFT之后,模型学会了听从指令,但是其生成的内容却不一定安全可靠。所以为了提升大模型的帮助性、降低有害性,人们会继续做SFT,通过高质量的数据给模型展示无害的、有帮助性的回答,规训模型的生成内容。
- 奖励模型训练(RW):使用一个包含人类对同一查询的多个答案打分的数据集训练一个奖励模型。或者说,就是一个打分模型,标注者对大量的SFT模型输出进行投票,哪个更好,哪个更差,由此创建了一个由比较数据组成的新数据集。相比监督微调,这种方法的优势在于不需要标注者编写回答,只需要为模型生成的几个回答打分,大幅提高了标注效率。
- 训练RM的数据集包含同一提示的不同输出,其中query表示提示信息或者说指令信息,chosen为标注后排序分数较高的答案,即针对提示选择的答案;rejected为标注后排序分数较低的答案,即针对提示拒绝的答案。
{ "query": "联合国总部在哪里?", "chosen": "联合国总部大楼位于纽约曼哈顿东侧,属于xxx", "rejected": "联合国的15个专门机构都没有设在总部,然而,xx" } - 训练RM是一个排序任务,不是直接对文本标注分数来训练奖励模型,因为不同的研究人员对同一个句子可能有不一样的评分,这样会导致大量的噪声出现,如果改成排序,则会大大降低噪声。不同的排名结果将被归一化为用于训练的标量奖励值。针对query,输入chosen和rejected答案,训练目标尽可能的使得chosen答案和rejected答案的差值更大。
- 奖励模型可以利用预训练模型进行初始化,或者也可以进行随机初始化。训练奖励模型的基本目标是获得一个模型,该模型接收一系列的文本,之后返回每个文本对应的标量奖励,该奖励会在数字值的大小上代表人类偏好,越大表示越接近人类偏好,越小表示越脱离人类偏好。
- 训练RM的数据集包含同一提示的不同输出,其中query表示提示信息或者说指令信息,chosen为标注后排序分数较高的答案,即针对提示选择的答案;rejected为标注后排序分数较低的答案,即针对提示拒绝的答案。
- RLHF 训练:人类反馈强化学习/近端策略优化算法(PPO),根据 RW 模型的奖励反馈进一步微调 SFT 模型。
总结一下:我们通过比较容易获得的公开无标签数据,来训练一个大语言模型/预训练模型,然后,通过人工编写的问答对,来生成高质量的监督对话数据,来优化大语言模型的对话能力。在得到了这个优化后模型(sft model)之后,标注者便在给定问题上可以基于模型生成的答案,对回答进行排序,并用排序数据训练一个reward model对回答的结果排序打分,用来评估回答的质量。最后,也是强化学习中最重要的一步,就是用你的“奖励模型”来提升 SFT model的效果。PS:在得到一个sft model之后,如何进一步优化sft model?一种办法是准备更多的“问题回答对“,但这个成本很高,再一个准备的多了,也可能会有价值观等问题,所以干脆训练一个专门的reward model来做这个事儿,用它来对sft model 生成的内容打分,进而继续“微调”sft model。这个很像家长、老师会告诉我们做事的正确答案,但是教的不多,到社会上,没人告诉你对错,只能通过别人的脸色、反应来判断自己做的对错。
PPO
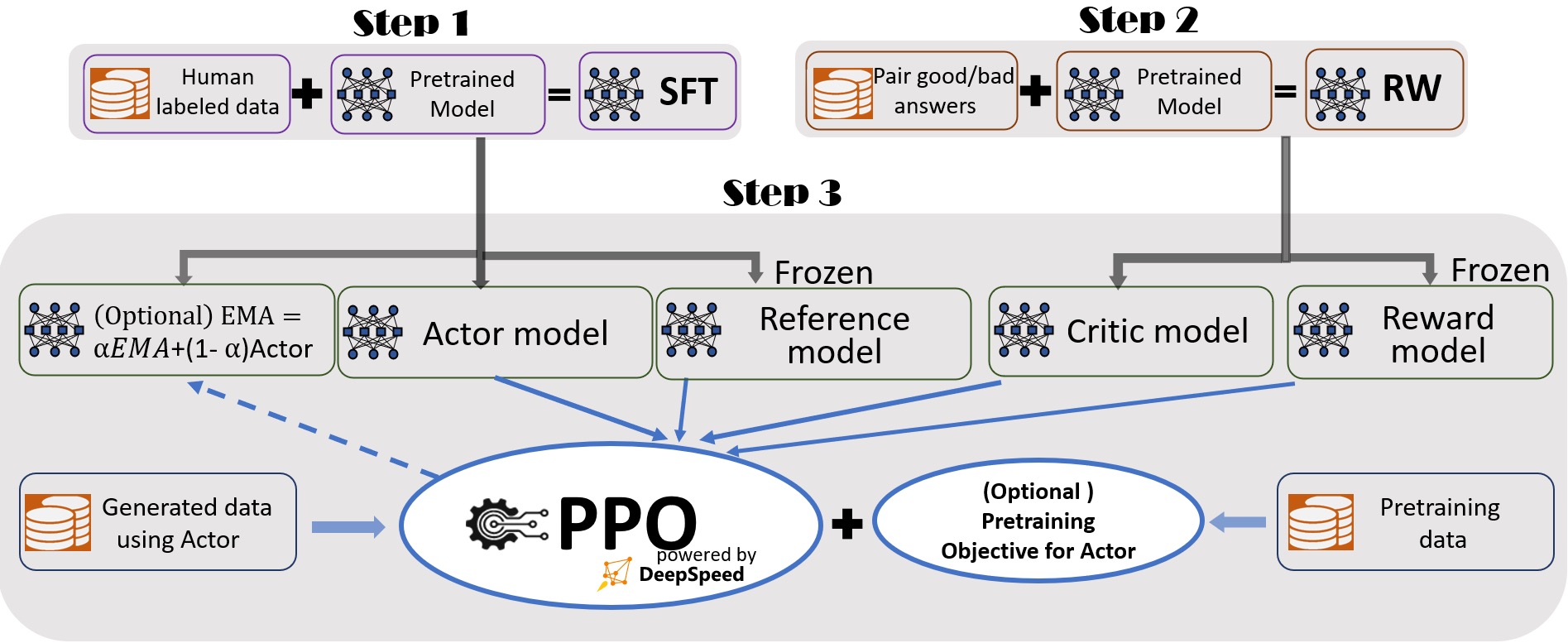
利用PPO算法,根据RW模型的奖励反馈进一步微调 sft model。经过强化学习后,LLM 给出的回答会越来越逼近那些在奖励模型中得分比较高的回答。包含actor model、reference模型/ref_model、reward model和critic model。actor model是我们想通过强化学习微调的大模型,但是强化学习过程很容易把模型训练“坏”,因此需要另外一个不会参数更新的 ref_model来当作标的,别让actor model跑偏太远。为什么PPO不直接使用reward model?虽然reward model可以提供每个状态或状态动作对的即时奖励信号,但它并不能直接提供对应的价值估计。奖励信号只反映了当前动作的即时反馈,critic model的作用是估计状态或状态动作对的长期价值,也称为状态值函数或动作值函数。critic model能够学习和预测在当前状态下采取不同动作所获得的累积奖励,它提供了对策略改进的指导。PPO算法使用critic model的估计值来计算优势函数,从而调整策略的更新幅度,使得更有利于产生更高长期回报的动作被选择。PS: actor model 和 ref_model是同一个模型的两个副本,reward model和critic model也是同一个模型的两个副本,且起源都是base model。拆解大语言模型RLHF中的PPO算法 原理与代码并重,值得细读。
DPO
- RLHF算法包含奖励模型(reward model)和策略模型(policy model,也称为演员模型,actor model),基于偏好数据以及强化学习不断迭代优化策略模型的过程。RLHF常使用PPO作为基础算法,整体流程包含了4个模型,且通常训练过程中需要针对训练的actor model进行采样,因此训练起来,稳定性、效率、效果不易控制。
- DPO算法不包含奖励模型和强化学习过程,直接通过偏好数据进行微调,将强化学习过程直接转换为SFT过程,因此整个训练过程简单、高效,主要的改进之处体现在于损失函数。DPO算法仅包含RLHF中的两个模型,即演员模型(actor model)以及参考(reference model),且训练过程中不需要进行数据采样。DPO算法的目的是最大化奖励模型(此处的奖励模型即为训练的策略),使得奖励模型对chosen和rejected数据的差值最大,进而学到人类偏好。
偏好数据,可以表示为三元组(提示语prompt, 良好回答chosen, 一般回答rejected)。
技术
RLHF开源框架主要有DeepspeedChat、Trlx、ColossalAI-Chat,同时在这些框架中会包括一些常用的节省GPU资源,加快训练速度的框架例如Accelerate、PEFT等。在整个RLHF的优化训练中,少则涉及2个模型,多则涉及4个模型(base-model,sft-model,reward-model,ppo-model),超参数较多,训练优化存在较多不确定性。还有一个需要关注的问题,就是RLHF的优化训练耗时较多,少则半月,多则数月才会训练完成,训练资源成本较多。
一键式 RLHF 训练 DeepSpeed Chat(一):理论篇ChatGPT模型的训练是基于InstructGPT论文中的RLHF方式。这与常见的大语言模型的预训练和微调截然不同,目前仍缺乏一个支持端到端的基于人工反馈机制的强化学习(RLHF)的规模化系统,为使RLHF训练真正普及到AI社区,DeepSpeed-Chat应运而生。 一键式RLHF训练 DeepSpeed Chat(二):实践篇 值得细读
PAI-ChatLearn :灵活易用、大规模 RLHF 高效训练框架(阿里云最新实践)
开启训练之旅: 基于Ray和vLLM构建70B+模型的开源RLHF全量训练框架 DeepSpeedChat和LLaMA Factory这些框架往往是基于 ZeRO 等并行方式,将 RLHF 算法中的四个模型切片后放到同一个 GPU 上。在模型规模越来越大的今天,这种调度方式无法满足 70B+ 甚至仅 13B+模型的全量 RLHF 训练,必须通过合并 Actor Critic 模型或者使用 LoRA 等方式妥协内存使用量。而这些PEFT的方式往往意味着模型效果的妥协。
数据集格式
基于 LoRA 的 RLHF: 记一次不太成功但有趣的百川大模型调教经历 非常经典。 PS:大模型统一的一个好处是input字段统一,进而数据集格式统一。这不像以前的专有模型,input字段各式各样。数据集格式是什么样子,就侧重训练模型哪些方面的能力。
- sft 数据集/Instruction 数据集。
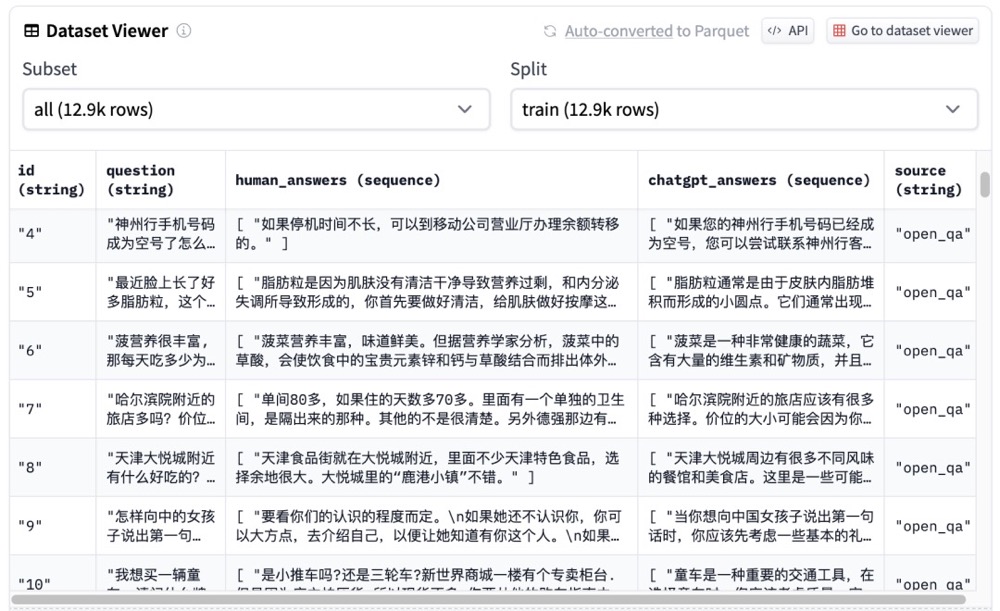
- sft训练之后的大概效果是这样的:
输入: "你是谁开发的啊" 原始 baichuan-7B: "我就是你,我是你自己。(自性)" ChatBaichun-HC3: "我是一个计算机程序,由一个人或一群人编写。我的目的是帮助人们解决问题和回答问题。" - rl 数据集,这个是训练reward model 用的,不是训练sft model 用的。
解析大模型中的Scaling Law在大模型的研发中,通常会有下面一些需求:
- 计划训练一个10B的模型,想知道至少需要多大的数据?
- 收集到了1T的数据,想知道能训练一个多大的模型?
- 老板准备1个月后开发布会,能用的资源是100张A100,那应该用多少数据训一个多大模型最终效果最好?
- 老板对现在10B的模型不满意,想知道扩大到100B模型的效果能提升到多少?
代码
SFT是指令学习, 而RM和PPO合在一起用于RLHF的对齐, 先做SFT,再做RM,最后做PPO
# 训练
experience_list = []
for i in range(epoch):
# 生成模型所需的input_ids
input_ids = tokenizer.batch_encode_plus(prompt_list, return_tensors="pt",...)["input_ids"]
experience = make_experience(args, actor_model, critic_model,ref_model,reward_model,input_ids, ...)
experience_list.append(experience)
mr = np.mean(np.array(mean_reward))
actor_model.train()
critic_model.train()
ppo_step = update_model(args, experience_list, actor_model, actor_optimizer, critic_model,critic_optimizer, tb_write, ppo_step)
# 模型保存
actor_model.save_pretrained(os.path.join(args.output_dir, "checkpoint-{}".format(ppo_step)))
tokenizer.save_pretrained(os.path.join(args.output_dir, "checkpoint-{}".format(ppo_step)))
def make_experience(args, actor_model, critic_model, ref_model,reward, reward_model, input_ids, generate_kwargs):
actor_model.eval()
critic_model.eval()
with torch.no_grad():
# 获取prompt内容长度
prompt_length = input_ids.shape[1]
# 使用动作模型通过已有提示生成指定内容,其中:seq_outputs为返回序列,包含prompt+生成的answer
seq_outputs, attention_mask = actor_model.generate(input_ids, **generate_kwargs)
# 通过动作模型和原始模型同时计算生成结果对应的log_probs
action_log_probs = actor_model(seq_outputs, attention_mask)
base_action_log_probs = ref_model(seq_outputs, attention_mask)
# 通过评判模型计算生成的answer的分值
value, _ = critic_model(seq_outputs, attention_mask, prompt_length)
value = value[:, :-1]
# 通过奖励模型计算生成奖励值,并对奖励值进行裁剪
_, reward_score = reward_model.forward(seq_outputs, attention_mask, prompt_length=prompt_length)
reward_clip = torch.clamp(reward_score, -args.reward_clip_eps, args.reward_clip_eps)
# reward_clip = reward_score
# 对动作模型和原始模型的log_probs进行kl散度计算,防止动作模型偏离原始模型
kl_divergence = -args.kl_coef * (action_log_probs - base_action_log_probs)
rewards = kl_divergence
start_ids = input_ids.shape[1] - 1
action_mask = attention_mask[:, 1:]
ends_ids = start_ids + action_mask[:, start_ids:].sum(1)
batch_size = action_log_probs.shape[0]
# 将奖励值加到生成的answer最后一个token上
for j in range(batch_size):
rewards[j, start_ids:ends_ids[j]][-1] += reward_clip[j]
# 通过奖励值计算优势函数
advantages, returns = get_advantages_and_returns(value, rewards, start_ids, args.gamma, args.lam)
experience = {"input_ids": input_ids, "seq_outputs": seq_outputs, "attention_mask": attention_mask,
"action_log_probs": action_log_probs, "value": value, "reward_score": reward_score,
"advantages": advantages, "returns": returns}
return experience
def update_model(args, experience_list, actor_model, actor_optimizer, critic_model, critic_optimizer, tb_write,ppo_step):
# 计算actor模型损失值
actor_loss = actor_loss_function(experience["action_log_probs"][:, start_ids:],...)
# actor模型梯度回传,梯度更新
actor_loss.backward()
actor_optimizer.step()
actor_optimizer.zero_grad()
# 计算critic模型损失值
# critic模型梯度回传,梯度更新
小结
流程与技术放在一起如下图
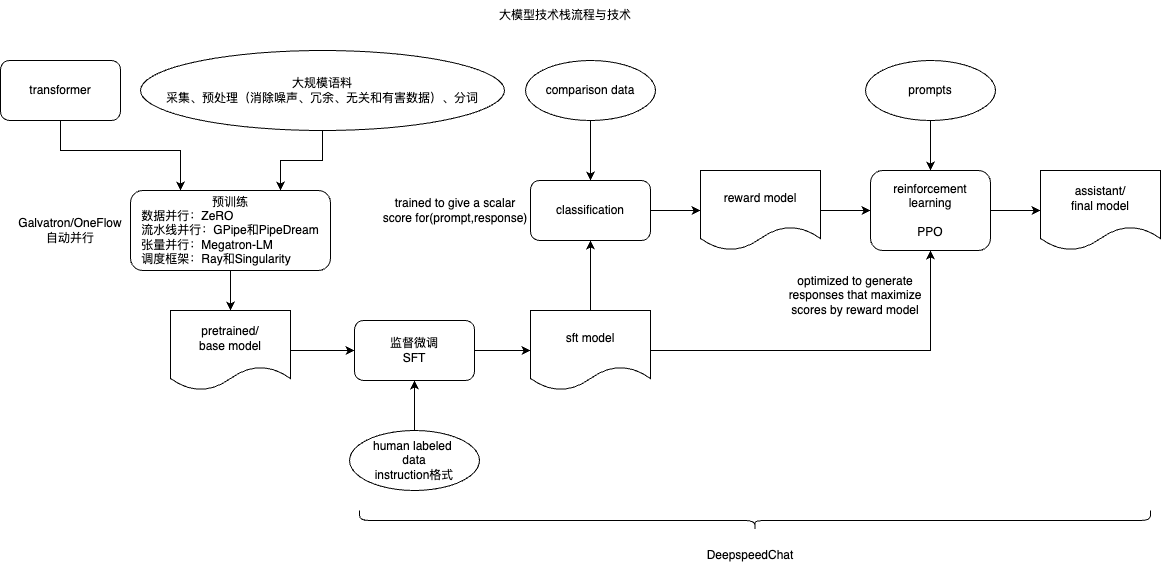
BaiChuan2技术报告细节分享&个人想法 当产出一个新的模型结构时,可以从以上视角、阶段来一一对比。PS: 提示词在不同模型之间,还是有细微差别的,那想要提示词效果比较好,自然需要了解对应模型的细节。
大模型RLHF中PPO的直观理解 未读,有几个图不错。