
前言
大模型由以下两个关键部分构成:一个是 参数集,另一个是 执行代码。
- 参数集:这是模型的”大脑”,包含了通过训练学习到的神经网络权重。
- 执行代码:这是模型的”引擎”,包含用于运行参数集的软件代码,可以采用任何编程语言实现。
NLP Course 官方教程,建议从头到尾细看一下。
Transformers快速入门Hugging Face 专门为使用 Transformer 模型编写了一个 Transformers 库,建立在 Pytorch 框架之上(Tensorflow 的版本功能并不完善),所有 Transformer 模型都可以在 Hugging Face Hub 中找到并且加载使用,包括训练、推理、量化等。
![]()
使用
pipelines
开箱即用的 pipelines,它封装了预训练模型和对应的前处理和后处理环节。
- 预处理 (preprocessing),Transformer模型无法直接处理原始文本字符串;具体地,我们会使用每个模型对应的分词器 (tokenizer) 来进行。 PS: 有点类似于tf的各种FeatureColumn
- 将输入切分为词语、子词或者符号(例如标点符号),统称为 tokens;
- 根据模型的词表将每个 token 映射到对应的 token 编号/id;映射通常是通过创建文本语料库中标记的词汇表,并根据每个标记在语料库中的出现频率为其分配一个整数值来执行的。最常见的tokens被分配较低的整数值,而不太常见的标记被分配较高的值。
- 根据模型的需要,添加一些额外的输入。比如tokens补齐和截断操作,填充是指在短序列的末尾添加额外的令牌(通常是一个特殊的令牌,如[PAD])以使它们具有相同的长度的过程。这样做是为了使模型可以同时处理批处理中的所有序列。另一方面,截断是指切断较长序列的末端,如果输入序列比最大长度长,标记器将从右侧截断输入序列。
- 将处理好的输入送入模型;
- 对模型的输出进行后处理 (postprocessing),将其转换为人类方便阅读的格式。
![]()
from transformers import pipeline
classifier = pipeline("sentiment-analysis") # 情感分析
result = classifier("I've been waiting for a HuggingFace course my whole life.")
print(result)
from transformers import pipeline
generator = pipeline("text-generation") # 文本生成
results = generator("In this course, we will teach you how to")
print(results)
基础组件
transformers开源库的核心组件包括3个:Configuration、Tokenizer、Model
- 「Configuration」:配置类,通常继承自「PretrainedConfig」,保存model或tokenizer的超参数,例如词典大小,隐层维度数,dropout rate等。配置类主要可用于复现模型。
- 「Tokenizer」:Model只能处理数字,因此Tokenizer需要将我们的文本输入转换为数字。总体上做三件事情:分词;扩展词汇表;识别并处理特殊token。
- 通常继承自「PreTrainedTokenizer」,主要存储词典(也就是
from_pretrained()的部分),token到index映射关系等。 - 此外,还会有一些model-specific的特性,如特殊token,
[SEP],[CLS]等的处理,token的type类型处理,语句最大长度等,因此tokenizer通常和模型是一对一适配的。
- 通常继承自「PreTrainedTokenizer」,主要存储词典(也就是
- 「Model」: 模型类。封装了预训练模型的计算图过程,遵循着相同的范式,如根据token ids进行embedding matrix映射(将token的one-hot编码转换成更dense的embedding编码),紧接着多个self-attention层做编码,最后一层task-specific做预测。 针对上述三大类,transformer还额外封装了AutoConfig, AutoTokenizer,AutoModel,可通过模型的命名来定位其所属的具体类,比如’bert-base-cased’,就可以知道要加载BERT模型相关的配置、切词器和模型。
# Building the config
config = BertConfig()
# Building the model from the config,使用随机值对其进行初始化
model = BertModel(config)
print(config)
BertConfig {
[...]
"hidden_size": 768, # 定义了hidden状态向量的大小
"intermediate_size": 3072,
"max_position_embeddings": 512,
"num_attention_heads": 12,
"num_hidden_layers": 12, # 定义了Transformer模型的层数
[...]
}
# 加载已经训练过的Transformers模型
model = BertModel.from_pretrained("bert-base-cased")
# 加载与保存分词器
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
tokenizer.save_pretrained("./models/bert-base-cased/")
# 加载与保存模型
from transformers import AutoModel
# 所有存储在 HuggingFace Model Hub 上的模型都可以通过 Model.from_pretrained() 来加载权重,参数可以是 checkpoint 的名称,也可以是本地路径(预先下载的模型目录)
model = AutoModel.from_pretrained("bert-base-cased")
model.save_pretrained("./models/bert-base-cased/") # 保存模型
inputs = tokenizer(["来到美丽的大自然,我们发现"], return_tensors="pt")
# {'input_ids': tensor([[ 1, 68846, 68881, 67701, 67668, 98899, 91935]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1]])}
gen_kwargs = {"max_length": 128, "top_p": 0.8, "temperature": 0.8, "do_sample": True, "repetition_penalty": 1.1}
output = model.generate(**inputs, **gen_kwargs)
# decode the new tokens
output = tokenizer.decode(output[0].tolist(), skip_special_tokens=True)
print(output)
针对每个模型输入,模型会分别得到对应的高维向量特征(动态词向量,而word2vec是静态词向量)。Transformer的基础架构(无论是编码器、解码器还是seq2seq),将输入张量转换为隐状态向量。这些基础架构是整个模型的一部分。对于不同任务,还有不同的head架构,他们将隐状态输出为任务需要的输出变量。不同任务有相同的Transformer基础架构,但是它们的head架构往往是不同的,具体架构与任务相关。
在Transformers(Transformers库多了一个s,而transformer模型没有s)库中,有许多模型架构,他们一般有基础Transformer架构加上不同的head模块组成,部分例子如下:
- *Model (retrieve the hidden states):只输出隐状态
- *ForCausalLM:常规语言模型,典型的有GPT系列
- *ForMaskedLM:掩码语言模型,典型的有BERT、RoBERTa、DeBERTa
- *ForMultipleChoice:多项选择模型
- *ForQuestionAnswering:问答模型,一般是抽取式问答
- *ForSequenceClassification:序列分类模型
- *ForTokenClassification:token分类模型,如命名实体识别和关系抽取
![]()
Dataset
from datasets import load_dataset
raw_datasets = load_dataset("glue", "mrpc")
print(raw_datasets)
# 包含训练集、验证集和测试集。每一个集合都包含几个列(sentence1, sentence2, label, and idx)以及一个代表行数的变量
#DatasetDict({
# train: Dataset({
# features: ['sentence1', 'sentence2', 'label', 'idx'],
# num_rows: 3668
# })
# validation: Dataset({
# features: ['sentence1', 'sentence2', 'label', 'idx'],
# num_rows: 408
# })
# test: Dataset({
# features: ['sentence1', 'sentence2', 'label', 'idx'],
# num_rows: 1725
# })
#})
load_dataset函数返回的是DatasetDict对象,它类似Python的Dict。DatasetDict里的不同key代表了数据集的不同split(默认的split是train),比如glue数据集包含”train”、”validation”和”test”三个split。DatasetDict的value是Dataset对象,它包含了一个split的全部数据。
为了预处理数据集,我们需要将文本转换为模型能够理解的数字,使用Dataset.map()方法
# example 是一个dict,对应数据集的每个元素,并返回一个包含input_ids、attention_mask 和token_type_ids为key的新dict
# 在机器学习任务中,一个example通常定义为模型的输入(也成为特征集合)
def tokenize_function(example):
return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
print(raw_datasets)
#DatasetDict({
# train: Dataset({
# features: ['attention_mask', 'idx', 'input_ids', 'label', 'sentence1', 'sentence2', 'token_type_ids'],
# num_rows: 3668
# })
# validation: Dataset({
# features: ['attention_mask', 'idx', 'input_ids', 'label', 'sentence1', 'sentence2', 'token_type_ids'],
# num_rows: 408
# })
# test: Dataset({
# features: ['attention_mask', 'idx', 'input_ids', 'label', 'sentence1', 'sentence2', 'token_type_ids'],
# num_rows: 1725
# })
#})
为了解决句子长度统一的问题,我们必须定义一个collate函数,该函数会将每个batch句子填充到正确的长度。
from datasets import load_dataset
from transformers import AutoTokenizer, DataCollatorWithPadding
raw_datasets = load_dataset("glue", "mrpc")
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
def tokenize_function(example):
return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
加载本地数据集
from datasets import load_dataset
#{
# "data": [
# {
# "title": "Terremoto del Sichuan del 2008",
# "paragraphs": [{...}]
# }
# ],
# "version": "1.1"
#}
squad_it_dataset = load_dataset("json", data_files="SQuAD_it-train.json", field="data")
print(squad_it_dataset) # 加载本地文件会创建一个带有train的DatasetDict 对象
# DatasetDict({
# train: Dataset({
# features: ['title', 'paragraphs'],
# num_rows: 442
# })
#})
data_files = {"train": "SQuAD_it-train.json", "test": "SQuAD_it-test.json"}
squad_it_dataset = load_dataset("json", data_files=data_files, field="data")
print(squad_it_dataset) # 包括 train 和 test 的 DatasetDict 对象
#DatasetDict({
# train: Dataset({
# features: ['title', 'paragraphs'],
# num_rows: 442
# })
# test: Dataset({
# features: ['title', 'paragraphs'],
# num_rows: 48
# })
#})
与 Pandas 类似,transformers Datasets 提供了几个函数来操作 Dataset 和 DatasetDict 对象
- rename_column 重命名DatasetDict中的列
- filter 过滤一些行
- 为数据集中的所有行创建新的数据列
def compute_review_length(example): return {"review_length": len(example["review"].split())} drug_dataset = drug_dataset.map(compute_review_length) - 用于预训练 GPT-2 的 WebText 语料库包含超过 800 万个文档和 40 GB 的文本,全加载到计算机内存吃不消,
pubmed_dataset_streamed = load_dataset("json", data_files=data_files, split="train", streaming=True),streaming=True 返回的对象是一个 IterableDataset
多轮对话怎么转化为模型接受的input和用于计算loss的label
预训练
通常,我们把经过预训练(pretrain)阶段得到的模型称为base模型。这个阶段主流的数据组织方式叫packing。在不采用packing的时候,为了将不同长度的句子组成一个batch tensor,我们需要进行填充(pad),这个填充过程既可以按照batch内最长句子填充,也可以按照模型最长输入长度填充。为了防止一个batch内存在许多的<pad>token,浪费计算资源,packing直接采取多条示例的拼接方法。下图是传统方法和packing的对比:
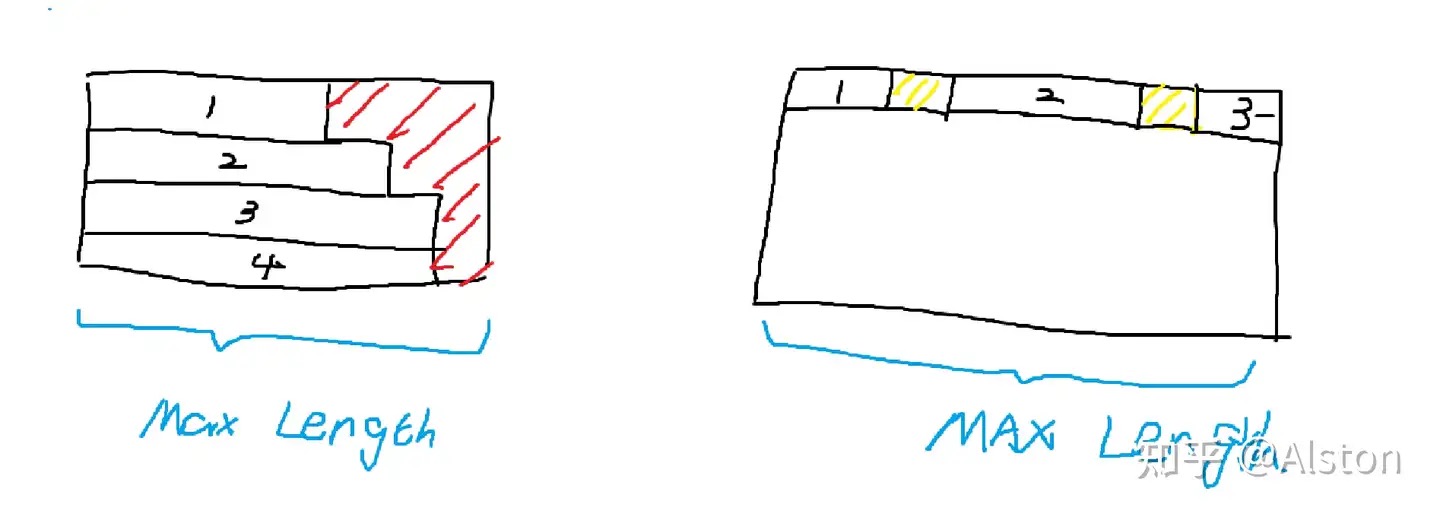
左侧是传统的padding做法,右侧是packing,其中红色部分代表pad token,黄色部分代表sep token。为了区分不同的训练示例,我们在不同示例之间加上一个分割标记sep token,注意力窗口不会跨示例。这个注意力模式叫块对角矩阵(BlockDiagonalMask)【本质上是在示例内的下三角矩阵】,而不是传统的全局下三角矩阵。由此,就消除了对pad token的需要,所以开源大模型刚问世的时候(2023-3那阵子),存在很多base model放出来的tokenizer并没有pad token,比如llama-base。需要注意,packing时示例3可能会被截断,这个行为在预训练时是可以接受的。注意,这个时候的学习模式非常的简单,就是next token prediction。
指令微调
指令微调不仅仅考虑了对人类指令和多任务的适应性,更是希望能将角色系统融入大模型中,从而让大模型变成chat模型,指令微调并不直接产生chat model,只是其中必不可少的一步。其中比较特殊的数据形式就是多轮对话。对话里必不可少的存在“角色”这个概念,因为和大模型的对话仅限于用户和模型,所以极大多数的对话模板(template)里都只考虑了两个角色——user和assistant。注意,对话模板只有非base模型才需要,所以很多的base模型的tokenizer里并不携带chat_template。
举个例子,比如:LLAMA2-chat的对话模板中user标识 是 [INST] , assistant 标识是[/INST],下面是一个单轮的例子
chat_dict = [
{"role": "user", "content": 你好},
{"role": "assistant", "content": 你也好},
]
因为模型输入只能是非结构化的,我们利用模板将其非结构化。得到的字符串就是[INST]你好[/INST]你也好。那么假如我们现在获得了一个现成的训练数据
chat_dict = [
{"role": "user", "content": U1},
{"role": "assistant", "content": A1},
{"role": "user", "content": U2},
{"role": "assistant", "content": A2},
]
模型的input_ids和对应的labels应该是什么呢?最常规的做法应该是在每一轮首尾用[BOS]和[EOS]包裹,轮次内部正常用模板非结构化就行。上例可以转换为input_ids= [BOS][INST]U1[\INST]A1[EOS][BOS][INST]U2[\INST]A2[EOS],难点在于LABELS应该是什么呢? 我们可以根据学习模式来确定LABELS。
-
在推理场景下,假如是第一轮对话开始,我们会输入给模型[BOS][INST]U1[\INST],那么我们希望模型吐出的是什么呢?是A1和[EOS],A1是模型自己的回答,EOS是为了告诉解码系统生成结束了,否则模型将一直生成到最大长度才会停止。我们获得了一个初步的学习模式需求,就是根据
[BOS][INST]U[\INST] → A[EOS]。 |input|[BOS]|[INST]|U|[/INST]|A| |—|—|—|—|—|—| |label|-100|-100|-100|A|[EOS]|在多轮的场景下,也只是复制这个过程。
input [BOS][INST]U [/INST]A [EOS][BOS][INST]U2 [/INST]A2 label -100 -100 -100 A [EOS]X X X X A2 [EOS] -
在llama factory里有一个参数叫 Efficient EOS,所谓efficient eos并不代表是一个新的token,而是一个特殊的input和label的设计方式。 多轮对话的训练过程详解
源码分析
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
sequences = ["I've been waiting for a HuggingFace course my whole life.", "So have I!"]
tokens = tokenizer(sequences, padding=True, truncation=True, return_tensors="pt")
print(tokens)
#{
# 'input_ids': tensor([
# [ 101, 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172,2607, 2026, 2878, 2166, 1012, 102],
# [ 101, 2061, 2031, 1045, 999, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
# ]),
# 'attention_mask': tensor([
# [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
# [1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
# ])
#}
output = model(**tokens)
print(output)
# SequenceClassifierOutput(
# loss=None,
# logits=tensor([[-1.5607, 1.6123],[-3.6183, 3.9137]], grad_fn=<AddmmBackward0>),
# hidden_states=None,
# attentions=None
#)
output = model(**tokens) 对于文本分类来说,整段文本输入返回一个标签,也就是SequenceClassifierOutput.logits,那么对于文本生成来说,整段文本输入返回CausalLMOutputWithPast, 对于 input_ids = [v1,v2,v3] 输出为 [v20,v30,v4]。 v20 是根据v1 生成的下一个token(大概率跟真实的v2 不一样),v4 是根据v1,v2,v3 生成的。
- 生成式模型的训练是并行的,靠的attention mask操作。训练的时候只需要调用一次即可,因为attention mask的机制可以保证当前token的loss不包含后面的token。inputs 则是一个dict,包含input_ids 和 attention_mask。
- 推理的时候,只能一个字一个字的推理,所以会调用多次。 output = model(inputs) 或者 output = model.forward(inputs)的时候,inputs 其实也不需要包含 attention_mask,inputs 仅仅是token 就可以
model(xx) ==> Module.__call__ ==> Module.forward/model.forward,几乎每一个llm 都会自定义forward 方法,如果向forward 方法传入 labels,还会自动计算loss。
class Module:
__call__ : Callable[..., Any] = _call_impl
def _call_impl(self, *args, **kwargs):
forward_call = (self._slow_forward if torch._C._get_tracing_state() else self.forward)
...
result = forward_call(*args, **kwargs) # dict 可以作为kwargs参数传入
... # 涉及到动态图的构建
return result
class PreTrainedModel(nn.Module, ModuleUtilsMixin, GenerationMixin, PushToHubMixin, PeftAdapterMixin):
def save_pretrained(...)
@classmethod
def from_pretrained(...)
class GenerationMixin:
def generate(inputs,...):> Union[GenerateOutput, torch.LongTensor]:
...
outputs = self(model_input_ids,attention_mask=model_attn,...)
...
class ChatGLMPreTrainedModel(TorchModel, PreTrainedModel):
...
class ChatGLMModel(ChatGLMPreTrainedModel):
def forward(self,input_ids,attention_mask,...):
...
class GPT2PreTrainedModel(PreTrainedModel):
...
class GPT2LMHeadModel(GPT2PreTrainedModel):
def __init__(self, config):
...
self.transformer = GPT2Model(config)
self.lm_head = nn.Linear(config.n_embd, config.vocab_size, bias=False)
...
def forward(self,input_ids,attention_mask,labels,...):
transformer_outputs = self.transformer(input_ids,attention_mask,...)
hidden_states = transformer_outputs[0]
lm_logits = self.lm_head(hidden_states)
loss = None
if labels is not None:
labels = labels.to(lm_logits.device) # move labels to correct device to enable model parallelism
shift_logits = lm_logits[..., :-1, :].contiguous() # Shift so that tokens < n predict n
shift_labels = labels[..., 1:].contiguous()
loss_fct = CrossEntropyLoss()
loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
return ((loss,) + output) if loss is not None else output
一些细节
- Models expect a batch of inputs。当你试图将两个(或更多)句子组合在一起时,它们的长度可能不同。为了解决这个问题,我们将使用填充使张量具有矩形。Padding通过在值较少的句子中添加一个名为Padding token的特殊单词来确保我们所有的句子长度相同。当要求处理更长的序列时
model = AutoModelForSequenceClassification.from_pretrained(checkpoint) batched_ids = [ [200, 200, 200], [200, 200, tokenizer.pad_token_id], ] attention_mask = [ [1, 1, 1], [1, 1, 0], ] outputs = model(torch.tensor(batched_ids), attention_mask=torch.tensor(attention_mask)) print(outputs.logits) - attention_mask ,self-attention使用,shape和input_ids一致。
- Encoder中的Mask。模型训练和预测基本都是批量化处理的,处理多个序列时,在attention的时候,不去attend被mask掉的部分。 作用是告诉模型一个batch的数据里哪些是padding的,从而可以忽略掉那些padding的部分,也叫padding mask ,比如下图的例子:
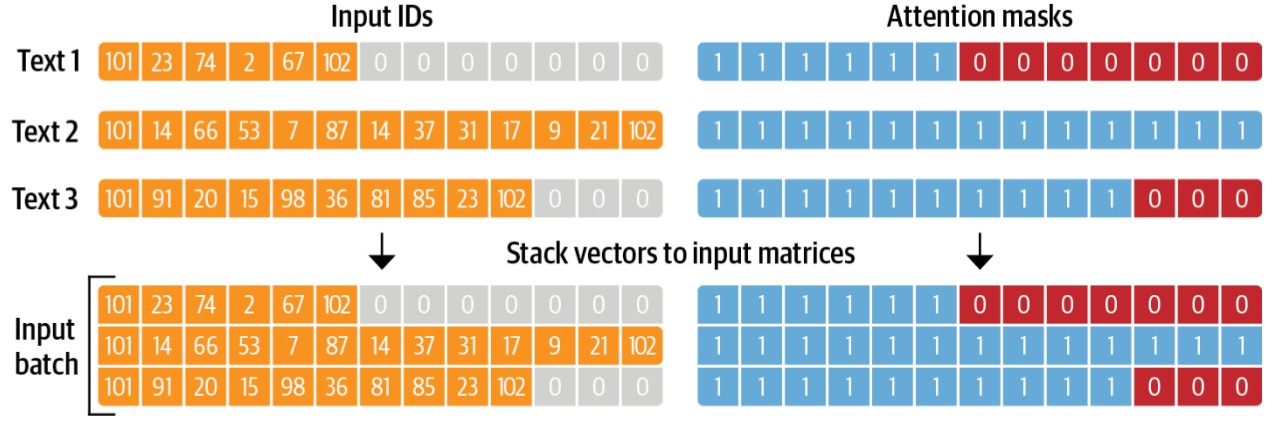
- decoder中的mask。用于在训练过程中解码的时候掩盖掉当前时刻之后的信息;也叫sequence mask
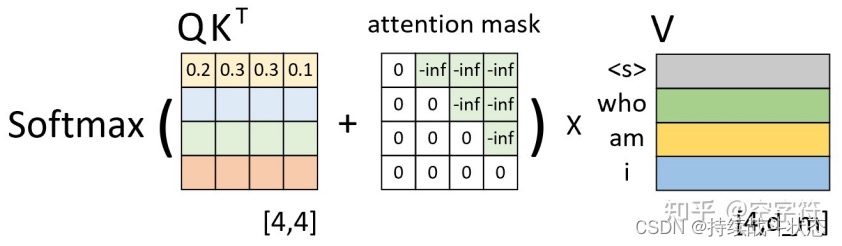
- 为什么Attention Mask不是0和1构成的矩阵,而是0和负无穷构成的?在 Transformer 模型中通常用于指示模型哪些位置是有效的输入,哪些位置是填充的。它的主要目的是确保模型在计算注意力分数时不会考虑到填充的位置。在大多数实现中,当我们说“mask”时,我们通常是指一个由0和1组成的矩阵,其中1表示“考虑这个位置”而0表示“不考虑这个位置”。但在实际的注意力机制计算中,这种简单的0和1的表示方法并不直接适用。Transformer中的注意力机制涉及到softmax函数,该函数会将输入的原始分数转换为概率分布。为了确保某些位置在softmax之后的概率为0,我们需要在softmax之前为这些位置赋予一个非常小的分数,通常是负无穷。这样,经过softmax转换后,这些位置的概率会接近于0。
- Encoder中的Mask。模型训练和预测基本都是批量化处理的,处理多个序列时,在attention的时候,不去attend被mask掉的部分。 作用是告诉模型一个batch的数据里哪些是padding的,从而可以忽略掉那些padding的部分,也叫padding mask ,比如下图的例子:
推理/generate实现
def generate(self,
prompt_tokens: List[List[int]], # 输入的提示
max_gen_len: int, # 最大生成长度
temperature: float = 0.6, # 影响生成文本的随机性
top_p: float = 0.9, # 用于决定采样过程中保留的 token 集合的概率阈值
logprobs: bool = False, # 是否返回每个 token 的对数概率
echo: bool = False, # 是否返回输入的提示
) -> Tuple[List[List[int]], Optional[List[List[float]]]]:
# ---------------------------初始化长度为 total_len tokens张量,并填充 pad_id----------------------------------
params = self.model.params
bsz = len(prompt_tokens)
assert bsz <= params.max_batch_size, (bsz, params.max_batch_size)
min_prompt_len = min(len(t) for t in prompt_tokens)
max_prompt_len = max(len(t) for t in prompt_tokens)
assert max_prompt_len <= params.max_seq_len
total_len = min(params.max_seq_len, max_gen_len + max_prompt_len)
pad_id = self.tokenizer.pad_id
tokens = torch.full((bsz, total_len), pad_id, dtype=torch.long, device="cuda")
# 将prompt_tokens中的token复制到tokens张量中。
for k, t in enumerate(prompt_tokens):
tokens[k, : len(t)] = torch.tensor(t, dtype=torch.long, device="cuda")
if logprobs: # 是否返回每个 token 的对数概率
# 创建一个与tokens相同形状的token_logprobs张量,并用0填充
token_logprobs = torch.zeros_like(tokens, dtype=torch.float)
prev_pos = 0
eos_reached = torch.tensor([False] * bsz, device="cuda")
input_text_mask = tokens != pad_id
# -------------------------------------------------------------
for cur_pos in range(min_prompt_len, total_len):
# 调用模型的forward方法获取logits
logits = self.model.forward(tokens[:, prev_pos:cur_pos], prev_pos)
if logprobs: # 是否返回每个 token 的对数概率
# 计算token level的logprobs
token_logprobs[:, prev_pos + 1: cur_pos + 1] = -F.cross_entropy(
input=logits.transpose(1, 2),
target=tokens[:, prev_pos + 1: cur_pos + 1],
reduction="none",
ignore_index=pad_id,
)
# 根据温度参数和top_p参数对logits进行softmax和采样,得到下一个token
if temperature > 0:
# sample_top_p函数对probs进行采样
probs = torch.softmax(logits[:, -1] / temperature, dim=-1)
next_token = sample_top_p(probs, top_p)
else:
# 将logits中概率最大的token作为下一个token。
next_token = torch.argmax(logits[:, -1], dim=-1)
next_token = next_token.reshape(-1)
# only replace token if prompt has already been generated
next_token = torch.where(
input_text_mask[:, cur_pos], tokens[:, cur_pos], next_token
)
# tokens张量更新
tokens[:, cur_pos] = next_token
eos_reached |= (~input_text_mask[:, cur_pos]) & (
next_token == self.tokenizer.eos_id
)
prev_pos = cur_pos
# 检查是否已经生成了所有的eos token,如果是则停止生成
if all(eos_reached):
break
if logprobs:
# token_logprobs列表化
token_logprobs = token_logprobs.tolist()
out_tokens, out_logprobs = [], []
for i, toks in enumerate(tokens.tolist()):
# cut to max gen len
# 对于 tokens 张量中的每一行(即每一个生成的序列),如果 echo 参数为假,则去掉提示部分
start = 0 if echo else len(prompt_tokens[i])
toks = toks[start: len(prompt_tokens[i]) + max_gen_len]
probs = None
if logprobs:
probs = token_logprobs[i][start: len(prompt_tokens[i]) + max_gen_len]
# cut to eos tok if any
# 存在结束标记,则去掉结束标记之后的部分
if self.tokenizer.eos_id in toks:
eos_idx = toks.index(self.tokenizer.eos_id)
toks = toks[:eos_idx]
probs = probs[:eos_idx] if logprobs else None
out_tokens.append(toks)
out_logprobs.append(probs)
# 返回生成的tokens和对数概率(如果logprobs参数为真)
return (out_tokens, out_logprobs if logprobs else None)
推理的时候不使用mask,要串行执行,只有得到前一个单词,重新进入decoder模块,通过模型推理才能得到下一个输出。
以LLAMA为例,快速入门LLM的推理过程 建议细读。
解码策略
可以把解码器文本Transformer模型理解为一个函数,它以词元作为输入并生成一个概率数组,用于表示词汇表中所有词元的概率,然后,程序根据这些概率从所有词元中进行采样,以指导采样过程,并生成下一个词元,这一过程会重复进行。在GPT模型最后一层之前,推理的对象是以向量形式表征的语义,输出的是代表语义的一个“模糊”的向量。此处“模糊”指的是,这一向量或许并不对应任何一个已知的词。因此,整个模型最后需要再做一个推测,基于这个“模糊”的向量所包含的语义信息,在词表中寻找最符合这些特征的词,来作为真正的输出。在 transformer 中,最后的输出是一个概率分布,表示每一个词匹配这一“模糊”向量的概率。
一网打尽文本生成策略(beam search/top-k/top-p/温度系数)假设我们输入 “I am a”,GPT会对这个序列进行编码得到embedding,并预测下一个单词的概率。“I am a”作为输入,编码后也会得到三个token对应的embedding。GPT会使用输入序列最后一个token对应的embedding做预测,也就是说,”a”经过编码后的embedding会被映射到整个词表上,得到下一个单词的概率。因为GPT是使用masked attention的,每个token在编码时都只会和他前面的token交互。那么最后一个token自然就包括了当前序列的所有信息,因此用于预测下一个token是最合理的。
Transformer中的解码策略解码(Decoding)就是在词表中抓阄。具体而言:模型根据下一个词的概率分布,从词表中选择下一个词。这个选择的策略就是解码策略,也称解码算法、解码方法等。
- 贪心搜索(Greedy Search)
- Beam search,保留num_beams个概率较大的句子,最后从num_beams个句子中输出最大概率的句子。当输入为“I am a”, 设置num_beams=2,beam search的过程可表达为:假设A,B,C对应的概率分别为0.5,0.2,0.3。那么此时选择每个token并组成序列的概率分别为:
“I am a A”: 0.5 “I am a B”: 0.3 “I am a C”: 0.2beam search会选择概率最大的num_beams=2个序列,参与后续的生成。因此“I am a A”和“I am a B”会参与下一个token的预测。假设得到六个可能序列对应的概率。此时再保留num_beams=2个最大概率的序列,比如是”I am a A C”=0.25, ”I am a B C”=0.27,再把这两个序列送到下一个token的预测中。上述步骤会一直重复,直到遇到结束符或指定的长度。最终,会有num_beams个序列被预测出来。此时可以对这几个概率最大的序列做进一步的处理,例如选一个概率最大的作为最终的输出,或者根据概率做个采样作为输出。beam search有什么好处呢?相比于每次都选最大的贪心,beam search显然增大了搜索空间。而且更重要的是,beam search会防止潜在概率很大的序列被过早的抛弃。例如”I am a B C”,在预测到B的时候序列的概率还是不大的,但是到C就变得更大了。当num_beams=1时,beam search等价于贪心。
- Top-k sampling,就是每一步只考虑概率最大的k个token,并且把这k个token的概率做重归一化,并随机采样得到预测的token。假设在一步中,ABC对应的概率ligits是[5,3,2],k设置为2。那么会选出字母A,B,并把其对应的概率logits[5,3]进行重新归一化softmax([5,3]) = [0.88,0.12]。随后基于归一化后的概率随机选A或B,拼接到“I am a”后面,并进行下一个token的预测,如此反复。top-k和beam search有什么区别呢?top-k自始至终只有一个序列进行预测,k只用于规定采样的范围,每步只采样一个token作为结果。而beam search会保留num_beams个序列进行预测。
- top-p sampling,Top-p采样中的p表示累积概率。这种策略会把token的概率按照递减的次序累加,直到累加的概率值超过了阈值p,在这些token中做采样得到预测。假设p=0.7,ABC在第一步预测的概率分布为[0.5,0.3,0.2]。那么A和B的概率值加起来超过了0.7,第一步就会在A,B中采样得到预测。假设第二步概率分布为[0.3,0.3,0.4],那么ABC三个加起来才会超过0.7,此时第二步就会在这三个里面采样,如此反复。可以看出top-p的每一步实际上会在一个动态长度的范围里做采样。这样的优点是可以排除一些概率不高的单词,例如分布为[0.9,0.05,0.05]时,只考虑第一个就足够了,而top-k还是会考虑前k个。并且在分布相对均衡时,top-p会增加输出的多样性。
-
温度系数,在上面提到的归一化中,我们还可以引入温度系数调整概率分布
\[Softmax(x_i) = \frac{e^{x_i}/T}{\sum_j e^{x_j}/T}\]T越大归一化后的概率分布越均匀,而T越小概率分布越陡峭。因此大的T会增加模型输出的随机性,而小的T则会让模型的输出更加固定。这也是“温度系数影响模型创造性”说法的原因。
以上策略体现在代码上 就是:经过多个AttentionLayer hidden_states,Normalization之后得到 outputs.logits,将 logits 传递给 logits_processor 和 logits_warper(包含TopKLogitsWarper/TopPLogitsWarper等),最后,使用 softmax 函数将经过预处理的 logits 转换为概率分布,并利用 multinomial 方法从中采样得到下一个 token。
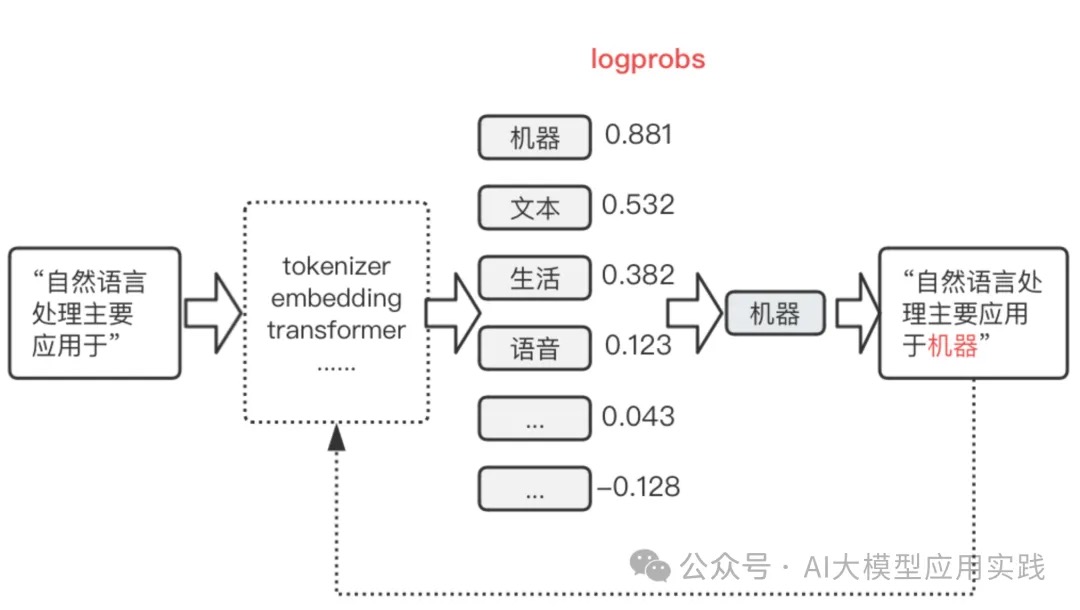
在transformers库中,其【Generationmixin.generate()】实现了各种解码策略。generate与forword的区别主要有:
- generate只用于推理场景,forward既用于推理场景,也用于训练场景。
- generate是基于forward实现的。
- generate利用各种解码策略,生成文本;而forward最主要的作用就是提供logits(未归一化的分布)。
- 解码策略对于文本的生成是非常重要的。我们可以不使用generate,而直接根据forward的logits进行解码,只要自己实现各类解码策略即可。这在自定义解码策略时非常有用。
forward实现
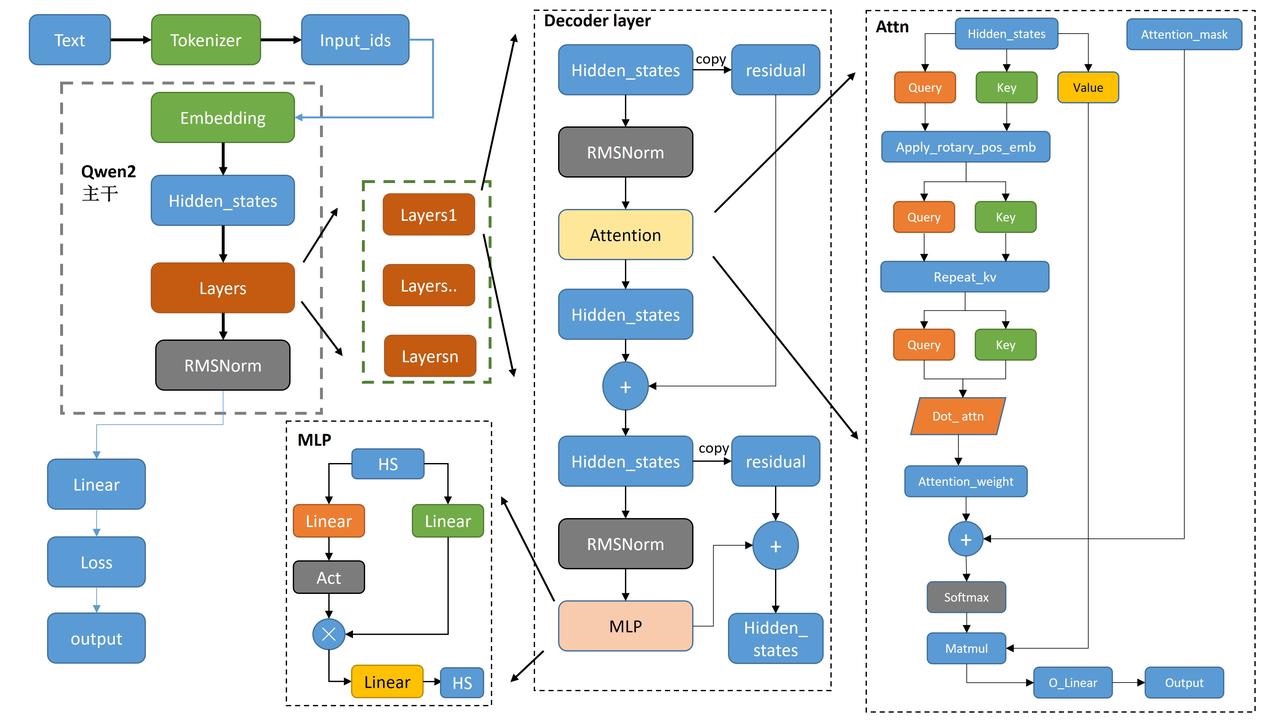
Qwen整体介绍 以代码组织的视角来看下 transformer的设计图。
def run_qwen2():
qwen2config = Qwen2Config(vocab_size=151936,...)
qwen2model = Qwen2Model(config=qwen2config)
input_ids = torch.randint(0,qwen2config.vocab_size,(4,30))
res = qwen2model(input_ids)
print(type(res))
Qwen2Model 干活的三个主力(3个成员):嵌入层(embed_tokens)、解码器层(layers)、归一化层(norm)。Qwen2Model 及其成员都是一个 nn.Module。最上层是Qwen2Model.forward 最底层是pytorch 运算,中间是一系列 nn.Module 用于抽象和复用,上一层的nn.Module.forward 通过驱动其成员的forward 干活儿。
class Qwen2Model(Qwen2PreTrainedModel):
def __init__(self, config: Qwen2Config):
super().__init__(config)
self.padding_idx = config.pad_token_id
self.vocab_size = config.vocab_size
self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
self.layers = nn.ModuleList(
[Qwen2DecoderLayer(config, layer_idx) for layer_idx in range(config.num_hidden_layers)]
)
self.norm = Qwen2RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
self.gradient_checkpointing = False
# Initialize weights and apply final processing
self.post_init()
def forward(input_ids,attention_mask,position_ids,...) -> Union[...]:
inputs_embeds = self.embed_tokens(input_ids)
# embed positions
hidden_states = inputs_embeds
for idx, decoder_layer in enumerate(self.layers):
# 将所有的hidden_states保存成tuple
if output_hidden_states:
all_hidden_states += (hidden_states,)
# 将hs送入每一层decoder_layer
layer_outputs = decoder_layer(
hidden_states,
attention_mask=attention_mask,
position_ids=position_ids,
past_key_value=past_key_value,
output_attentions=output_attentions,
use_cache=use_cache,
)
# 取出上一层decoder_输出的hs,再传入下一个layer
# 只要第一个,第二个是cache的一个类,然后进入下一个layer
hidden_states = layer_outputs[0]
# 将最后layers输出后的hidden_states进行标准化
hidden_states = self.norm(hidden_states)
# 加上最后一层的hidden_states
if output_hidden_states:
all_hidden_states += (hidden_states,)
重点转到了 Qwen2DecoderLayer,三件套对应3个成员:attn+MLP+norm。forward逻辑:首先复制一份hidden_states为residual,然后将hidden_states送入Norm,再送入attn模块。得到attn的输出后,再复制一份residual,再将hidden_states送入Norm,mlp,再与residual进行相加。最后输出的就是这个hidden_states啦。
# 为了提高性能,ATTENTION layer 有一些优化实现,比如flash attention,sdpa
QWEN2_ATTENTION_CLASSES = {
"eager": Qwen2Attention, # 一般情况下是这个
"flash_attention_2": Qwen2FlashAttention2,
"sdpa": Qwen2SdpaAttention,
}
class Qwen2DecoderLayer(nn.Module):
def __init__(self, config: Qwen2Config):
super().__init__()
self.hidden_size = config.hidden_size
self.self_attn = QWEN2_ATTENTION_CLASSES[config._attn_implementation](config, layer_idx)
self.mlp = Qwen2MLP(config)
# input_layernorm和post_attention_layernorm内容是一样的,只是应用的顺序不一样。
self.input_layernorm = Qwen2RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
self.post_attention_layernorm = Qwen2RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
def forward(hidden_states,attention_mask,position_ids,...) -> Union[...]:
residual = hidden_states
# 标准化后送入attn
hidden_states = self.input_layernorm(hidden_states) # RMSNorm标准化
# Self Attention
hidden_states, self_attn_weights, present_key_value = self.self_attn(
hidden_states=hidden_states,
attention_mask=attention_mask,
position_ids=position_ids,
past_key_value=past_key_value,
output_attentions=output_attentions,
use_cache=use_cache,
**kwargs,
)
# 残差与新的hidden_states相加
hidden_states = residual + hidden_states
# Fully Connected
residual = hidden_states
# 同样的RMSNorm标准化
hidden_states = self.post_attention_layernorm(hidden_states)
hidden_states = self.mlp(hidden_states)
hidden_states = residual + hidden_states
outputs = (hidden_states,)
return outputs
重点转到 Qwen2Attention,forward逻辑:首先将hidden_states送入Linear中得到query、key与value。使用旋转位置嵌入操作rotary_emb,使用了旋转位置嵌入的余弦和正弦部分,将他们与query和key相乘,并将结果相加,从而实现旋转位置嵌入的效果。将key_states和value_states重复group次,再执行dot attn操作。在dot attn操作后得到attn_weights,加上attention_mask从而实现读取掩盖操作,在经过softmax与value_states相乘。得到attn_output。再将上述的attn_output进行reshape操作,送入o_proj,得到最终的输出。
class Qwen2Attention(nn.Module):
"""Multi-headed attention from 'Attention Is All You Need' paper"""
def __init__(self, config: Qwen2Config):
super().__init__()
self.config = config
self.layer_idx = layer_idx
self.hidden_size = config.hidden_size
self.num_heads = config.num_attention_heads
self.head_dim = self.hidden_size // self.num_heads
self.num_key_value_heads = config.num_key_value_heads # 键值对的头数
self.num_key_value_groups = self.num_heads // self.num_key_value_heads # 键值对的组数
self.max_position_embeddings = config.max_position_embeddings
self.rope_theta = config.rope_theta
self.is_causal = True
self.attention_dropout = config.attention_dropout
if (self.head_dim * self.num_heads) != self.hidden_size:
raise ValueError(
f"hidden_size must be divisible by num_heads (got `hidden_size`: {self.hidden_size}"
f" and `num_heads`: {self.num_heads})."
)
# 后续LoRa也基本都对q_proj/k_proj/v_proj/o_proj 四个Linear操作动的刀子
self.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=config.attention_bias)
self.k_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=config.attention_bias)
self.v_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=config.attention_bias)
self.o_proj = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=config.attention_bias)
self.rotary_emb = Qwen2RotaryEmbedding(
self.head_dim,
max_position_embeddings=self.max_position_embeddings,
base=self.rope_theta,
)
def forward(hidden_states,attention_mask,position_ids,...) -> Union[...]:
# 获取形状信息,hidden_states输入的为(bs,T,hd)
bsz, q_len, _ = hidden_states.size()
# 对hidden_states进行Linear生成query、key、value
query_states = self.q_proj(hidden_states)
key_states = self.k_proj(hidden_states)
value_states = self.v_proj(hidden_states)
# reshape多头处理--分块--(bs,T,heads,hd_d)
query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
value_states = value_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
# 将旋转位置嵌入应用于查询和键张量。使用了旋转位置嵌入的余弦和正弦部分,将它们与查询和键张量相乘,并将结果相加,从而实现旋转位置嵌入的效果
cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
# 先将key_states和value_states重复了num_key_value_groups次
key_states = repeat_kv(key_states, self.num_key_value_groups)
value_states = repeat_kv(value_states, self.num_key_value_groups)
# 使用dot attn实现q*kT/hd_d^0.5
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
# 然后 attn_weights 加上 attention_mask,实现读取顺序
attn_weights = attn_weights + attention_mask
# softmax + dropout + values_states相乘
attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
attn_weights = nn.functional.dropout(attn_weights, p=self.attention_dropout, training=self.training)
attn_output = torch.matmul(attn_weights, value_states)
# 转置,修改形状等reshape操作
attn_output = attn_output.transpose(1, 2).contiguous()
attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
# 最后在进行一次o_proj
attn_output = self.o_proj(attn_output)
# 返回结果
return attn_output, attn_weights, past_key_value
Qwen2 MLP 输入hidden_state并行送入两个Linear层,其中一个激活一下,再与另一个相乘,最终再经过一个Linear,输出最终结果。
class Qwen2MLP(nn.Module):
def __init__(self, config):
super().__init__()
# 这俩不必多说
self.config = config
self.hidden_size = config.hidden_size
self.intermediate_size = config.intermediate_size
# 三个全连接层
self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
self.up_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)
self.act_fn = ACT2FN[config.hidden_act]
def forward(self, x):
down_proj = self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))
return down_proj
Qwen2RMSNorm
class Qwen2RMSNorm(nn.Module): # 标准化层
def __init__(self, hidden_size, eps=1e-6):
"""
Qwen2RMSNorm is equivalent to T5LayerNorm
"""
super().__init__()
self.weight = nn.Parameter(torch.ones(hidden_size))
self.variance_epsilon = eps
def forward(self, hidden_states):
input_dtype = hidden_states.dtype
hidden_states = hidden_states.to(torch.float32)
variance = hidden_states.pow(2).mean(-1, keepdim=True)
hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
return self.weight * hidden_states.to(input_dtype)
训练/Trainer
transformer 支持自定义dataset,自定义model实现forward(forward 支持的参数均可以作为dataset的column),forward 过程中还计算loss,模型的差异性基本已经兜住了,这也是为何 只要提供包含特定column的dataset,剩下的训练代码都可以交给trainer封装掉。
在我们定义 Trainer 之前首先要定义一个 TrainingArguments 类,它将包含 Trainer用于训练和评估的所有超参数,也内置了Accelerate和deepspeed等支持。唯一必须提供的参数是保存训练模型的目录,以及训练过程中的检查点。对于其余的参数,可以保留默认值。
from transformers import TrainingArguments
raw_datasets = load_dataset("glue", "mrpc")
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
def tokenize_function(example):
return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
training_args = TrainingArguments("test-trainer")
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
trainer = Trainer(
model,
training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
)
trainer.train()
不用trainer,纯手工实现训练过程,也是trainer帮我们自动化的部分
raw_datasets = load_dataset("glue", "mrpc")
# data preprocessing
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
def tokenize_function(example):
return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
tokenized_datasets = tokenized_datasets.remove_columns(["sentence1", "sentence2", "idx"])
tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
tokenized_datasets.set_format("torch")
## tokenized_datasets column_names: ["attention_mask", "input_ids", "labels", "token_type_ids"]
train_dataloader = DataLoader(
tokenized_datasets["train"], shuffle=True, batch_size=8, collate_fn=data_collator
)
eval_dataloader = DataLoader(
tokenized_datasets["validation"], batch_size=8, collate_fn=data_collator
)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
optimizer = AdamW(model.parameters(), lr=3e-5)
## put our model and our batches on GPU
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
model.to(device)
num_epochs = 3
num_training_steps = num_epochs * len(train_dataloader)
lr_scheduler = get_scheduler( # the learning rate scheduler
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps,
)
progress_bar = tqdm(range(num_training_steps))
model.train()
for epoch in range(num_epochs):
for batch in train_dataloader:
batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
GPT-2养成记
Training and Fine-Tuning GPT-2 and GPT-3 Models Using Hugging Face Transformers and OpenAI API 非常经典,入门必读。
- it does not implement neural networks from scratch(从头开始) but relies on lower-level frameworks PyTorch, TensorFlow, and FLAX.
- it heavily uses Hugging Face Hub, another Hugging Face project, a hub for downloadable neural networks for various frameworks.
- Model is a valid PyTorch model with some additional restrictions and naming conventions introduced by the transformers framework.
- Neural networks are not able to work with raw text; they only understand numbers. We need a tokenizer to convert a text string into a list of numbers. But first, it breaks the string up into individual tokens, which most often means “words”, although some models can use word parts or even individual characters. Tokenization is a classical natural language processing task. Once the text is broken into tokens, each token is replaced by an integer number called encoding from a fixed dictionary. Note that a tokenizer, and especially its dictionary, is model-dependent: you cannot use Bert tokenizer with GPT-2, at least not unless you train the model from scratch. Some models, especially of the Bert family, like to use special tokens, such as
[PAD],[CLS],[SEP], etc. GPT-2, in contrast, uses them very sparingly.
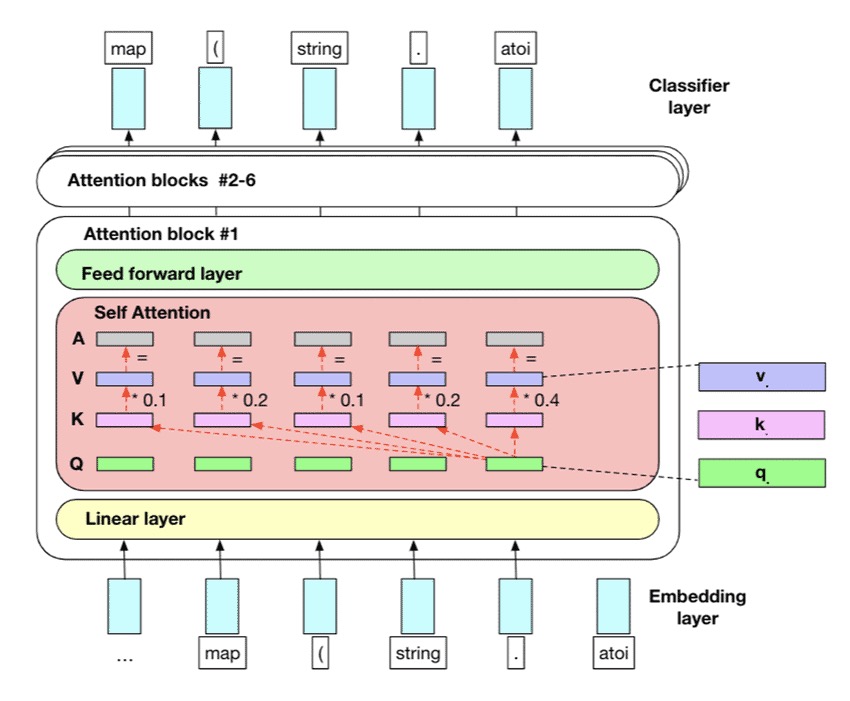
different GPT versions differ pretty much only in size, minor details, and the dataset+training regime. If you understand how GPT-2 or even GPT-1 works, you can, to a large extent, understand GPT-4 also. PS: 不同的gpt从模型结构上差别不大。
以GPT-2 为例
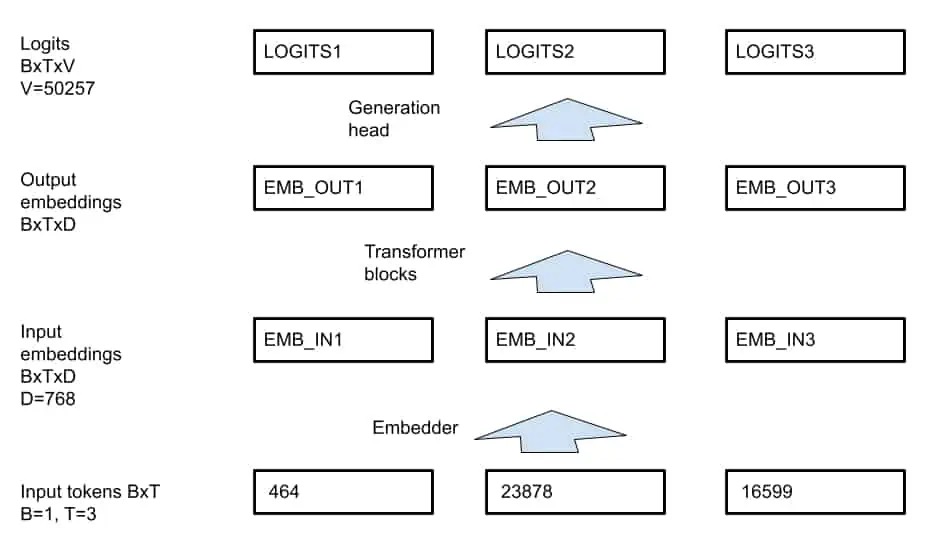
- The transformer itself works with a D-dimensional vector at every position, for GPT-2 D=768.
- V=50257 is the GPT-2 dictionary size.
GPT-2 model使用
config = transformers.GPT2Config.from_pretrained(MODEL_NAME)
config.do_sample = config.task_specific_params['text-generation']['do_sample']
config.max_length = config.task_specific_params['text-generation']['max_length']
# print(config)
model = transformers.GPT2LMHeadModel.from_pretrained(MODEL_NAME, config=config)
# Tokenizer
tokenizer = transformers.AutoTokenizer.from_pretrained(MODEL_NAME)
# Tokenize the input
enc = tokenizer(['The elf queen'], return_tensors='pt')
print('enc =', enc)
print(tokenizer.batch_decode(enc['input_ids']))
input_ids = enc['input_ids']
attention_mask = torch.ones(input_ids.shape, dtype=torch.int64)
# predicts the next token at each position. 也就是 input_ids = [v1,v2,v3] 输出为 [v20,v30,v4]]。 v20 是根据v1 生成的下一个token,大概率跟v2 不一样,v4 是根据v1,v2,v3 生成的。
out = model(input_ids=input_ids, attention_mask=attention_mask)
logits = out['logits']
# -1 在python list 里表示最后一个元素。
new_id = logits[:, -1, :].argmax(dim=1)
print(new_id)
print(tokenizer.batch_decode(new_id))
GPT2 源码解析 建议细读
input_ids = enc['input_ids']
for i in range(20):
attention_mask = torch.ones(input_ids.shape, dtype=torch.int64)
logits = model(input_ids=input_ids,attention_mask=attention_mask)['logits']
new_id = logits[:, -1, :].argmax(dim=1) # Generate new ID
input_ids = torch.cat([input_ids, new_id.unsqueeze(0)], dim=1) # input_ids 加入新生成的字符
| i | input_ids | decoded text | next token |
|---|---|---|---|
| 0 | [464,23878,16599] | the elf queen | 11 |
| 1 | [464,23878,16599,11] | the elf queen, | 508 |
| 2 | [464,23878,16599,11,508] | the elf queen,who | 550 |
微调GPT-2 model
GPT models are trained in an unsupervised way on a large amount of text (or text corpus). The corpus is broken into sequences, usually of uniform size (e.g., 1024 tokens each). PS: 预训练素材通常被切成特定长度的句子。The model is trained to predict the next token (word) at each step of the sequence. For example (here, we write words instead of integer encodings for clarity) :
| position | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| input_ids | The | elf | queen | was | wearing | a | cloak | . | [END] |
| labels | elf | queen | was | wearing | a | cloak | . | [END] | [-1] |
The labels are identical to input_ids, but shifted to one position to the left. Note that for GPT-2 in Hugging Face transformers this shift happens automatically when the loss is calculated, so from the user perspective, the tensor labels should be identical to input_ids. PS:常规深度模型的训练输入是 feature1,feature2,...,label,LLM也是,不过label 有时是由input_id得到的。
There are two ways to train Hugging Face transformers models: with the Trainer class or with a standard PyTorch training loop. We start with Trainer. PS: 下面代码基于GPT-2 已有的参数微调GPT-2,感觉模型微调 跟model = load_checkpoint(xx) 断点重训没啥区别,侧重点在于讲Transformers库原理。
class MyDset(torch.utils.data.Dataset):
"""A custom dataset that serves 1024-token blocks as input_ids == labels"""
def __init__(self, data: list[list[int]]):
self.data = []
for d in data:
input_ids = torch.tensor(d, dtype=torch.int64)
attention_mask = torch.ones(len(d), dtype=torch.int64)
self.data.append({'input_ids': input_ids, 'attention_mask': attention_mask, 'labels': input_ids})
def __len__(self):
return len(self.data)
def __getitem__(self, idx: int):
return self.data[idx]
def break_text_to_pieces(text_path: str, tokenizer: transformers.PreTrainedTokenizer, block_len: int = 512) -> list[str]:
"""Read a file and convert it to tokenized blocks, edding <|endoftext|> to each block"""
with open(text_path) as f:
text = f.read()
chunk_len0 = block_len - 1 # Leave space for a TOKEN_ENDOFTEXT
tokens = tokenizer.encode(text) # 原文本直接弄,够粗暴
blocks = []
pos = 0
while pos < len(tokens):
chunk = tokens[pos: pos + chunk_len0]
chunk.append(TOKEN_ENDOFTEXT)
blocks.append(chunk)
pos += chunk_len0
if len(blocks[-1]) < block_len:
del blocks[-1]
return blocks
def train_val_split(data: list[str], ratio: float):
n = len(data)
assert n >= 2
n_val = max(1, int(n * ratio))
return data[n_val:], data[:n_val]
def prepare_dsets(text_path: str, tokenizer: transformers.PreTrainedTokenizer, block_len: int):
"""Read the text, prepare the datasets """
data = break_text_to_pieces(text_path, tokenizer, block_len)
data_train, data_val = train_val_split(data, 0.2)
return MyDset(data_train), MyDset(data_val)
# Load model and tokenizer
model = transformers.GPT2LMHeadModel.from_pretrained(MODEL_NAME)
tokenizer = transformers.AutoTokenizer.from_pretrained(MODEL_NAME)
training_args = transformers.TrainingArguments(output_dir="idiot_save/", learning_rate=1e-3,...)
# 传给trainer 的必须是预处理好的dataset(包含input_ids 等column)
trainer = transformers.Trainer(model=model,args=training_args,train_dataset=dset_train,eval_dataset=dset_val)
trainer.train()
# Save the model if needed
model.save_pretrained('./trained_model/')
tokenizer.save_pretrained('./trained_model/')
# Now our model is trained, try the generation
text = 'Natural language understanding comprises a wide range of diverse tasks'
batch = tokenizer([text], return_tensors='pt')
for k, v in batch.items():
batch[k] = v.to(DEVICE)
out = model.generate(input_ids=batch['input_ids'], attention_mask=batch['attention_mask'], max_length=20)
print('GENERATION=', tokenizer.batch_decode(out.cpu()))
一把情况下 you are not allowed to train a model from scratch. Neither are you allowed to fine-tune on a text corpus or fine-tune with additional heads. The only type of fine-tuning allowed is fine-tuning on prompt+completion pairs, represented in JSONL format, for example:
{"prompt":"banana is ","completion":"yellow"}
{"prompt":"orange is ","completion":"orange"}
{"prompt":"sky is ","completion":"blue"}
How exactly is GPT-3 trained on such examples? We are not exactly sure (OpenAI is very secretive), but perhaps the two sequences of tokens are concatenated together, then GPT-3 is trained on such examples, but the loss is only calculated in the “completion” part. PS: 终于知道为何要分成两段,而不是喂一个文本就算了。labels 中prompt部分的位置都置为-100,-100表示在计算loss的时候会被忽略,这个由任务性质决定。